文章目录
-
- 算法
- [1.Extending Diffusion Stitching 在视频生成领域所面临的挑战](#1.Extending Diffusion Stitching 在视频生成领域所面临的挑战)
- 2.通用视频模型已支持拼接
- 3.Stochasticity是必要的,但不足以保持一致性
- [4.OMNI GUIDANCE 提升一致性](#4.OMNI GUIDANCE 提升一致性)
- [5.通过Cyclic Conditioning 实现长期一致性](#5.通过Cyclic Conditioning 实现长期一致性)
标题:GENERATIVE VIEW STITCHING
来源:MIT CSAIL ;RunwayML
项目:https://andrewsonga.github.io/gvs
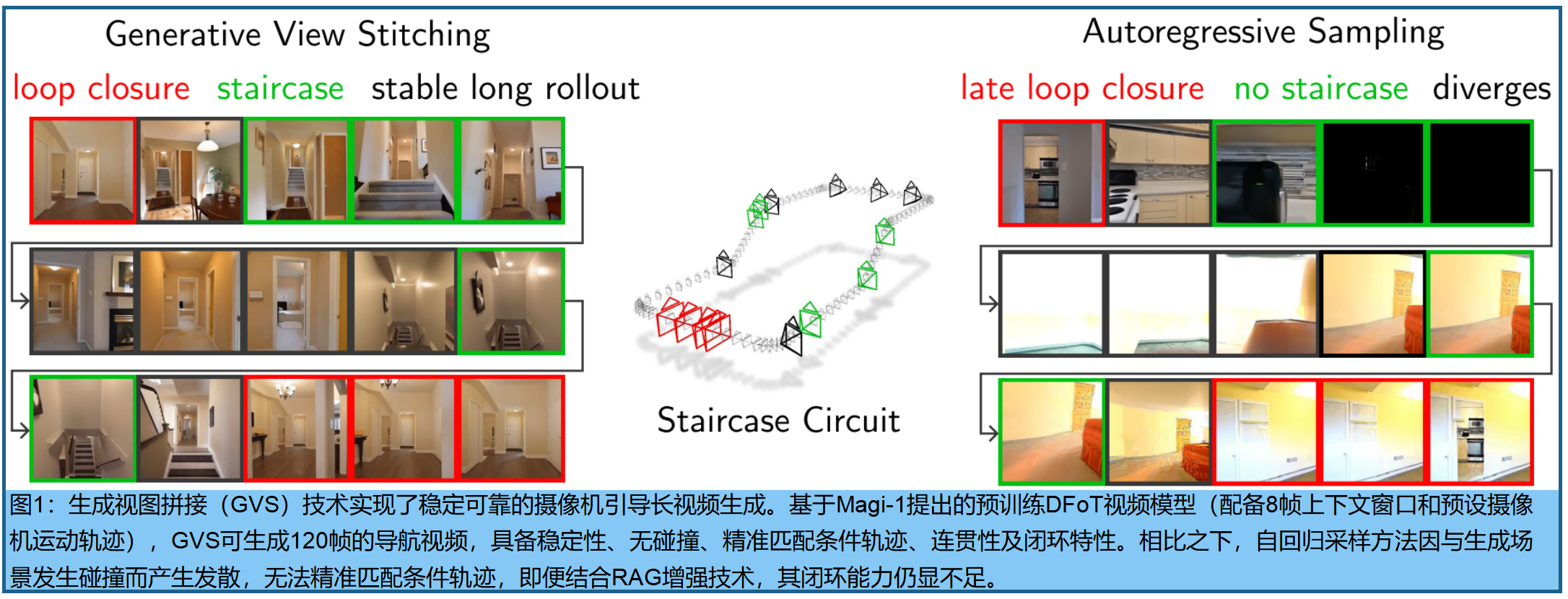
自回归视频扩散模型能够生成稳定且与历史数据保持一致的长序列视频,但无法通过未来条件引导当前帧生成。在使用预定义摄像机轨迹进行摄像机引导的视频生成中,这种局限性会导致生成场景与轨迹发生冲突,进而导致自回归模型迅速崩溃。为解决这一问题,我们提出生成式视图拼接(GVS)技术,通过并行采样整个序列,确保生成场景忠实于预定义摄像机轨迹的每个部分 。我们的核心贡献在于开发了一种采样算法,将机器人规划领域的扩散拼接技术拓展至视频生成领域。虽然这类拼接方法通常需要专门训练的模型,但GVS兼容所有使用扩散强制训练的现成视频模型------这种主流的序列扩散框架已具备拼接所需的必要条件。我们随后提出Omni Guidance技术,该技术通过结合历史数据与未来预测,显著提升拼接过程的时间一致性,并为实现长距离连贯性提供了闭环机制。总体而言,GVS生成的摄像机引导视频具备稳定性、无碰撞、帧间一致性等优势,且能为多种预设摄像机路径(包括奥斯卡·路透斯瓦德的《不可能的楼梯》)实现闭环控制。
扩散模型。扩散模型是一种生成模型,其核心在于通过一系列降噪步骤将目标分布的数据样本逐步转化为白噪声。噪声项ϵ服从正态分布N(0,I)。扩散建模的核心目标是通过学习评分函数 ϵ θ ( x k , k ) ϵ_θ(x^k,k) ϵθ(xk,k),实现对白噪声的逆向降噪,从而将噪声逐步还原为目标分布的样本( σ k σ_k σk用于控制随机性水平,即每个降噪步骤中注入的随机噪声 ϵ ∼ N ( 0 , I ) ϵ∼N(0,I) ϵ∼N(0,I)的强度):
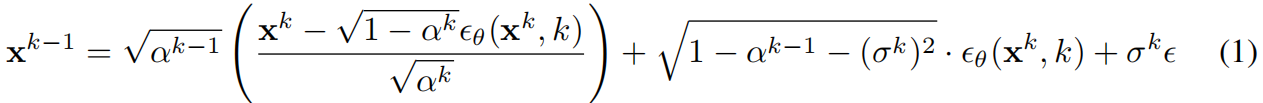
长视频生成技术 。当前视频扩散模型在内容分辨率(尤其是时间分辨率)方面存在明显短板,生成的视频通常仅有5到10秒 (Runway Gen-4、Luma AI的Dream Machine、Google DeepMind的Veo、阿里巴巴的通义万相Wan 2.1) 。究其原因,传统扩散模型架构采用的注意力层会随着输入token数量呈二次方增长。为解决这一问题,可采取两种策略:一是筛选出与每帧生成相关的特定token进行注意力聚焦 ( 《Mixture of contexts for long video generation》《One-minute video generation with test-time training》《Mixture of contexts for long video generation》 );二是将历史信息压缩为隐藏状态 ( 《One-minute video generation with test-time training》《Test-time training done right》)。当前,训练大容量上下文模型已成为研究热点,而像GVS这样的测试时拼接方法,正是通过利用这类骨干模型,实现了对更长序列的自然延伸与内容外推延。 GVS的一个重要特性:它仅调整采样方法,无需专门的模型架构或训练范式。
Diffusion Forcing与自回归扩展。Diffusion Forcing(DF)是训练序列扩散模型的主流框架 《Oasis:A universe in a transformer》《Magi-1: Autoregressive video generation at scale》《History-guided video diffusion》 。DF通过为每个token设置独立噪声level来训练序列扩散模型 。采样过程中,DF模型可选择性地用噪声覆盖部分上下文窗口,从而实现对可变数量上下文token(即历史信息)的条件约束。DF还催生了 history guidance 《Magi-1》 ,该技术能生成稳定且一致的超长镜头引导自回归视频。然而,这些研究中展示的长序列生成仅因实时用户控制的摄像机轨迹而成为可能------这种轨迹能有效避免与生成场景元素发生碰撞。根据预设摄像机轨迹进行自回归采样会导致模型在生成内容时对未来的摄像机轨迹缺乏认知,从而引发摄像机与生成场景的碰撞(见图1和图6)。我们提出了一种基于拼接的替代方案,该方案(1)兼容所有DF模型,(2)生成的视频能完整保留摄像机轨迹,从而实现无碰撞且稳定的生成效果。
算法
生成视图拼接(GVS)是一种用于相机引导视频生成的扩散拼接方法,能够克服自回归采样技术的局限性。
-
首先,介绍CompDiffuser拼接方法及其对定制训练模型的需求(3.1节)。
-
随后,由于 DF 训练的视频模型本身就具备支持拼接的必要能力,并提出了一种无需额外训练的拼接方法(3.2节)。
-
通过结合 maximum stochasticity (《Stochsync: Stochastic diffusion synchronization
for image generation in arbitrary spaces》ICLR 2025)(该方法仍显不足,3.3节)与
-
创新的全向引导技术(通过强化对过去和未来的条件约束来增强时间一致性,3.4节),成功解决了时间一致性问题。
-
全向引导技术还进一步实现了闭环机制,为视频生成提供了长距离连贯性支持(3.5节)。
1.Extending Diffusion Stitching 在视频生成领域所面临的挑战
Diffusion Stitching方法是一类采样方法,能够突破主干扩散模型上下文窗口的限制,实现更广泛的组合泛化。这类方法通常将目标序列 x x x划分为 T T T个重叠的片段 { x t x_t xt} t = 0 T − 1 {t=0}^{T-1} t=0T−1,通过同步中间输出,实现去噪过程的相互交织。特别值得一提的是,专为goal-conditioned planning设计的缝合方法CompDiffuser,将每个目标片段 x t x_t xt建模为仅依赖其时间邻近片段 x t − 1 x{t−1} xt−1和 x t + 1 x_{t+1} xt+1,从而形成以下组合轨迹分布:
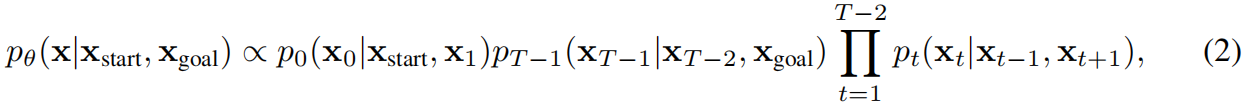
x s t a r t x_{start} xstart和 x g o a l x_{goal} xgoal表示预定义的起始状态和目标状态。但要实现这一点,CompDiffuser必须训练一个定制化的去噪网络 ϵ θ ( x t k , k ∣ x t − 1 k , x t + 1 k ϵ_θ(x_t^k,k|x^k_{t−1},x^k_{t+1} ϵθ(xtk,k∣xt−1k,xt+1k),该网络根据co-evolving, noisy neighboring chunks,生成目标chunk 。条件chunks被作为独立的条件输入,通过特殊编码器嵌入后,再通过自适应层归一化注入主干模型。由于需要定制模型,CompDiffuser无法直接应用于现成模型 (训练定制模型的成本高)。公式表明联合概率由一系列条件概率构成,描述了一种序列生成的依赖关系和条件关系。在扩散模型中,这通常通过协同去噪来实现。
2.通用视频模型已支持拼接
为了开发一种无需训练的拼接方法,使其能与现成的视频模型兼容,采用了Diffusion Forcing(DF)。与CompDiffuser类似,采用组合方式表示摄像机引导视频的分布:
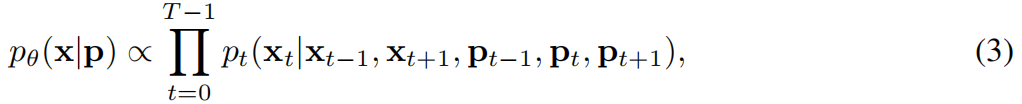
p p p 表示预定义的摄像机运动轨迹, p − 1 ≜ p 0 p_{−1}≜p_0 p−1≜p0且 p T ≜ p T − 1 p_T≜p_{T−1} pT≜pT−1, x − 1 x_{−1} x−1和 x T x_T xT是用于填充的纯噪声帧。为简洁起见,省略摄像机运动轨迹的描述。CompDiffuser需要自定义骨干模型进行拼接,因为其通过专用条件路径处理相邻片段。我们提出的新方案是:将目标chunk x t k x^k_t xtk与其时间邻近chunk x t − 1 k 、 x t + 1 k x^k_{t−1}、x^k_{t+1} xt−1k、xt+1k作为同一输入序列的一部分进行联合去噪,如图2 。将目标视频 x x x分割为 T T T个非重叠chunk{ x t x_t xt} t = 0 T − 1 {t=0}^{T−1} t=0T−1,长度均短于上下文窗口,从而腾出空间对条件chunk进行联合去噪。实际应用中,仅有部分相邻片段能完全适配上下文窗口。模型输出时,会采用去噪后的目标片段 x t k − 1 x_t^{k−1} xtk−1来更新拼接序列的噪声估计值,而去噪后的条件片段 x t − 1 k − 1 x^{k−1}{t−1} xt−1k−1和 x t + 1 k − 1 x^{k−1}_{t+1} xt+1k−1则被舍弃。这种被称为"vanilla GVS"的拼接方法,可与任何设计用于条件信号与目标信号联合去噪的DF视频模型兼容。
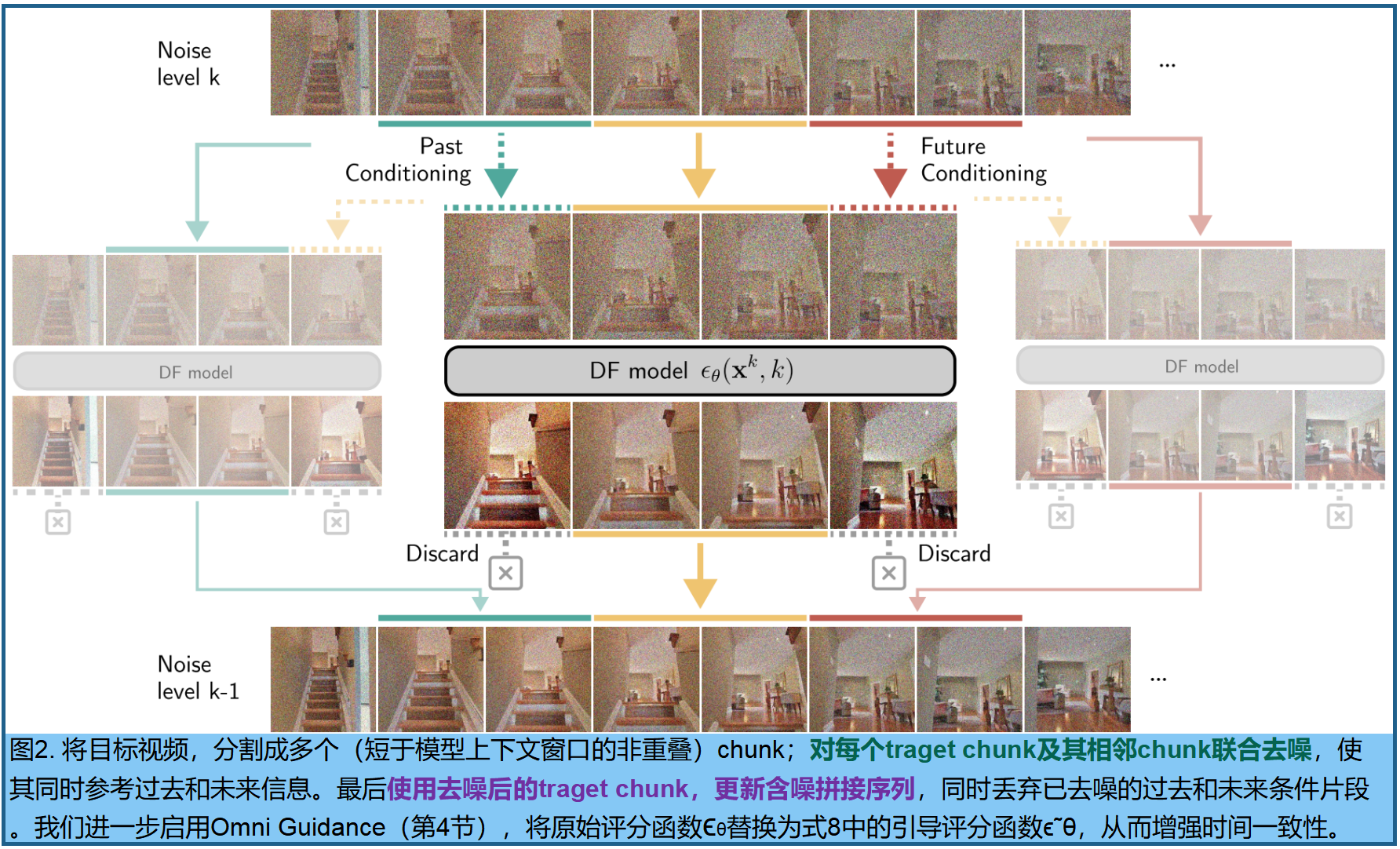
虽然vanilla GVS算法实现简单,但其时间一致性表现欠佳,如图3第一行 。我们认为这源于vanilla GVS采用联合分布 p ( x t − 1 , x t , x t + 1 ) p(x_{t−1},x_t,x_{t+1}) p(xt−1,xt,xt+1)的评分函数来消除目标帧 x t k x^k_t xtk的噪声,而非方程3中原本设计的条件分布 p ( x t ∣ x t − 1 k , x t + 1 k ) p(x_t|x^k_{t−1},x^k_{t+1}) p(xt∣xt−1k,xt+1k)。在自回归采样中,目标帧通常基于噪声显著降低的过往上下文进行条件生成,而vanilla GVS却要求目标帧 x t k x^k_t xtk与其条件邻居 x t − 1 k 、 x t + 1 k x^k_{t−1}、x^k_{t+1} xt−1k、xt+1k具有同等噪声水平,这种设计导致条件信号较弱。
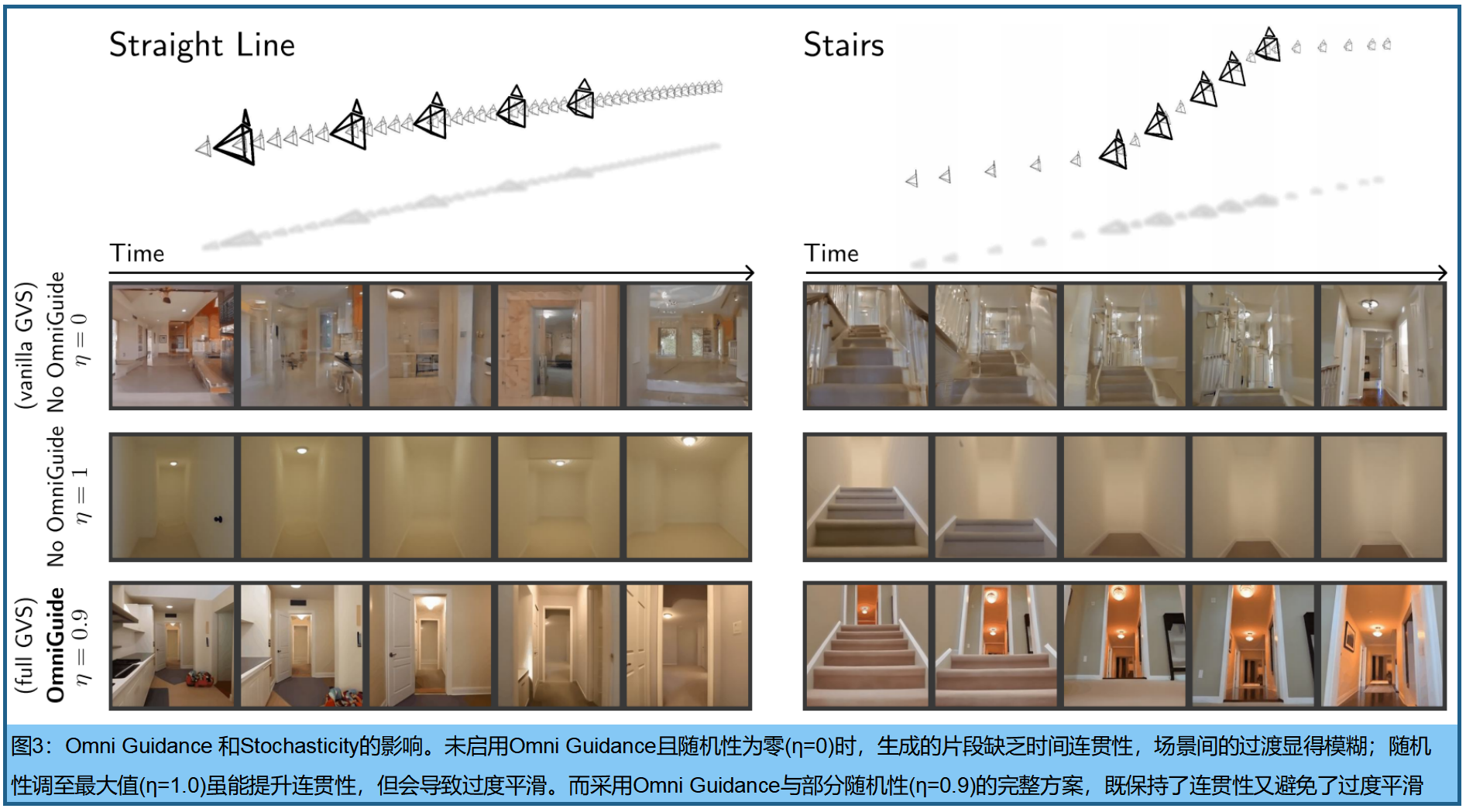
3.Stochasticity是必要的,但不足以保持一致性
先前的缝合研究中,StochSync提出随机性机制以增强一致性。该方法引入最大随机性 σ k = ( 1 − α k − 1 ) σ^k=\sqrt{(1−α^{k−1})} σk=(1−αk−1) ,通过消除预测噪声项并最大化公式1中去噪方程的随机噪声项,作为纠错机制。我们发现最大随机性在时间一致性方面对vanilla GVS也有提升作用(见表2),但如图3所示,往往会导致过度平滑的生成结果。

4.OMNI GUIDANCE 提升一致性
为解决随机性缺陷,Omni Guidance通过强化对历史数据和未来数据的条件约束,引导原始联合分布的评分函数趋近于目标条件分布的评分函数。
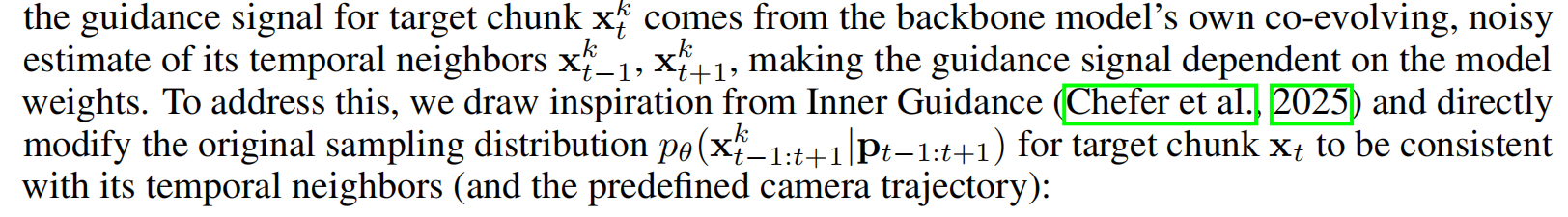
一个难点在于,拼接技术打破了标准classifier-free 引导(《Classifier-free diffusion guidance》)的核心假设------即条件信号与模型权重相互独立 (解释:Classifier-Free Guidance的文本条件 c 是一个外部输入信号,它与模型本身的权重是相互独立的;Stitching 技术需要邻近 chunk的信息作为"引导信号"。其不再是像文本提示那样一个固定的、外部的条件 c,而是由模型自身对邻近 chunk 的噪声估计计算而来的。)。在GVS中,target chunk x t k x_{t}^{k} xtk 的引导信号来自骨干模型自身对时间邻近chunk x t − 1 k x_{t-1}^k xt−1k和 x t + 1 k x_{t+1}^k xt+1k的协同演化噪声估计,这使得引导信号依赖于模型权重。受Inner Guidance启发,直接调整原始采样分布 p θ ( x t − 1 : t + 1 k ∣ p t − 1 : t + 1 ) p_θ(x^k_{t−1:t+1}|p_{t−1:t+1}) pθ(xt−1:t+1k∣pt−1:t+1),使target chunk x t x_{t} xt 与其时间邻域(以及预设摄像机轨迹)保持一致:
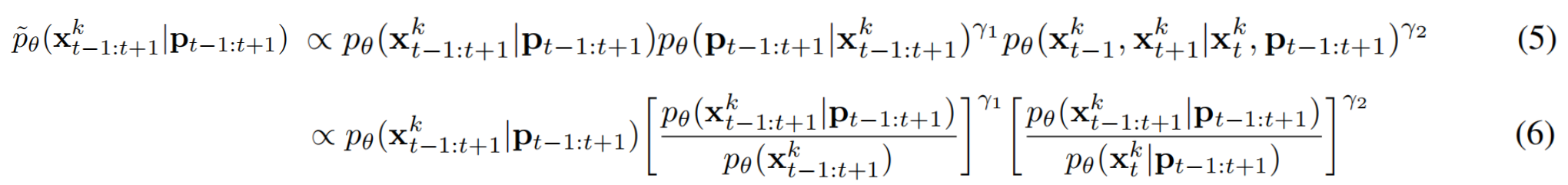
解释如下:

相当于对原始评分函数 ϵ θ ( x t − 1 : t + 1 k ∣ p t − 1 : t + 1 ) ϵ_θ(x^k_{t−1:t+1}|p_{t−1:t+1}) ϵθ(xt−1:t+1k∣pt−1:t+1)进行如下调整:
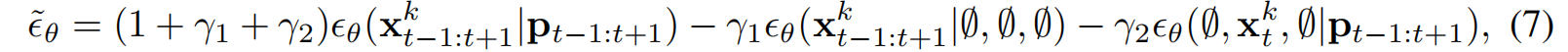
∅ ∅ ∅表示零条件,引导尺度 γ 1 γ_1 γ1 和 γ 2 γ_2 γ2 分别调节对预设摄像机轨迹的遵循程度 ,以及目标chunk与其时间邻域的一致性。公式6->7的解释:

实际应用中,将由单一 γ γ γ 调控的引导项合并:
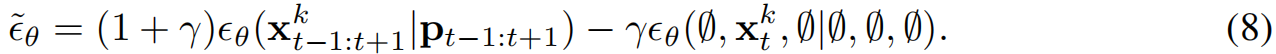
第一项是标准的条件生成 ,确保内容符合相机轨迹。第二项是一个特殊的"无条件"生成 。它只对目标块 x t k x_t^k xtk 进行"无条件"生成,而将其邻居块用纯高斯噪声替代(即 ∅ 并设置为最大噪声水平)。效果: 引导信号 ϵ θ ( ∅ , x t k , ∅ ∣ ∅ , ∅ , ∅ ) ϵ_θ(∅,x_{t}^k,∅|∅,∅,∅) ϵθ(∅,xtk,∅∣∅,∅,∅)不再依赖于模型对邻居块的"良好"估计,而是依赖于一个被严重破坏的、充满噪声的邻居版本 。这就在鼓励目标块 x t k x_t^k xtk 自身具有高度的独立性和一致性,因为它的邻居提供的上下文信息是混乱的。这种"在噪声中保持自身结构"的要求,间接地迫使目标块与其(在去噪过程中逐渐清晰的)真值邻居保持一致。引导项 ϵ θ ( ∅ , x t k , ∅ ∣ ∅ , ∅ , ∅ ) ϵ_θ(∅,x_{t}^k,∅|∅,∅,∅) ϵθ(∅,xtk,∅∣∅,∅,∅)的计算方法是:通过将含噪邻近片段替换为纯高斯噪声,并将其噪声水平设为最大值(该方法基于Diffusion Forcing)。这可视为Fractional History Guidance(Song,2025)的推广版本,其核心区别在于:在缝合过程中,条件邻近片段的噪声水平会动态调整,而历史引导自回归采样中的噪声水平则保持固定。
Omni Guidance技术通过部分随机性 σ k = η 1 − α k − 1 σ^k= η\sqrt{1−α^{k-1}} σk=η1−αk−1 实现(其中 η ∈(0,1)),二者协同作用既能有效抑制过度平滑,又能保持相似的一致性水平。
5.通过Cyclic Conditioning 实现长期一致性
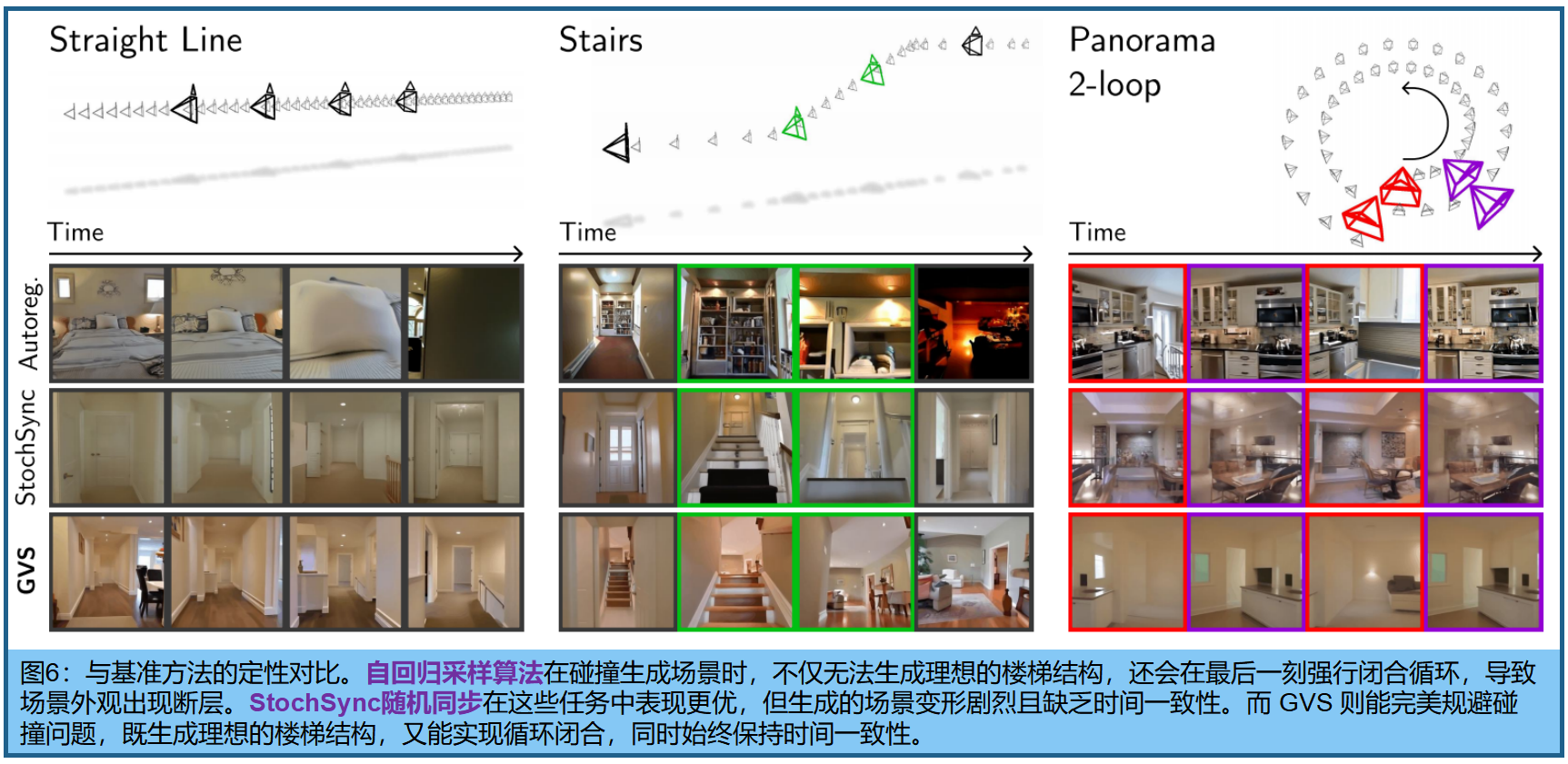
理论上讲,第2至4节所述的拼接方法具有全局上下文特性------随着每个降噪步骤的进行,各片段的理论感受野会持续扩展,这与卷积神经网络(CNN)沿深度方向的感知野增长机制颇为相似。因此,可以合理推测GVS能够实现零样本闭合环路,即一种全局一致性形式。但在实际应用中,我们发现虽然GVS显著提升了时间一致性,却未能实现全局强制。图4显示,即使生成超长片段,视觉上也难以"回到原点",这表明信息在拼接视频中的传播范围并未达到必要程度。
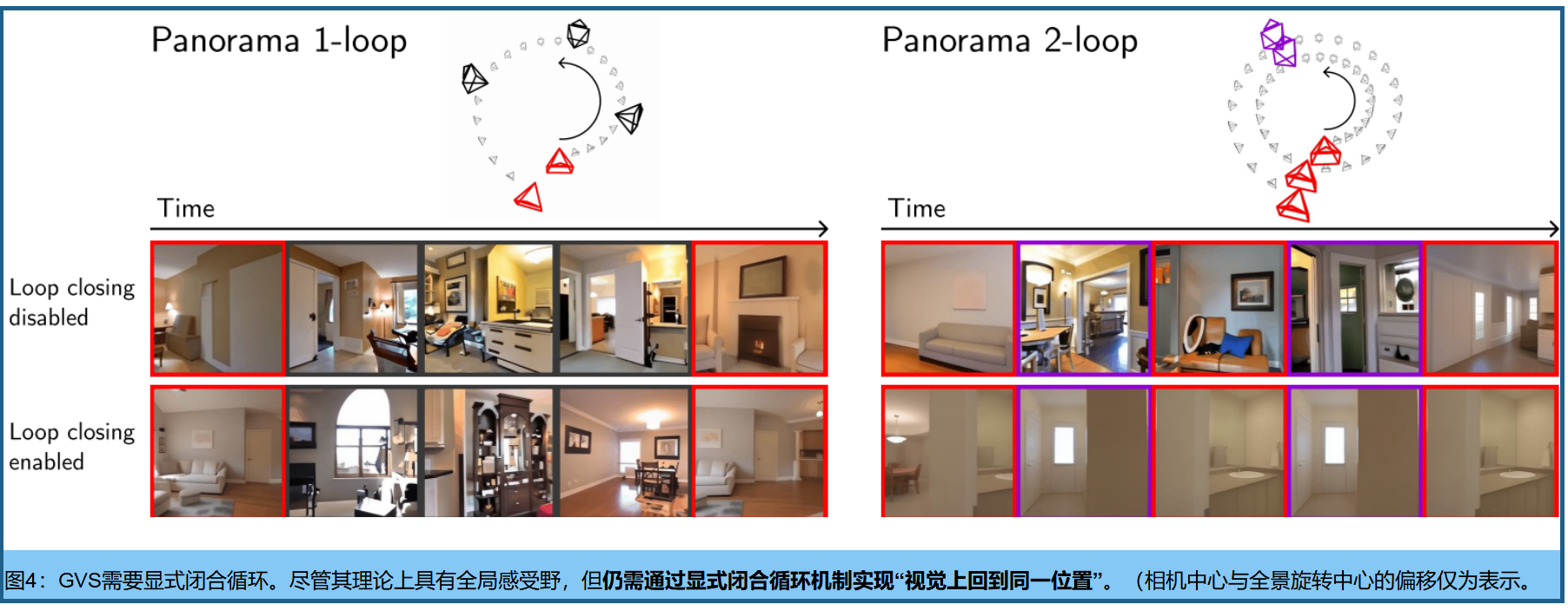
为实现循环闭合,在等式3的组合分布中添加更多因素 (通过去噪包含时间上相隔但空间上邻近的片段的额外扩散窗口)。例如,如图5所示,包含全景1-环轨迹末端帧的片段 通过两个扩散窗口进行去噪:一个根据其时间邻近片段(时间窗口)进行条件化,另一个根据其空间邻近片段(空间窗口)进行条件化 。建议在每个去噪步骤中交替使用这两组上下文窗口,这一过程称为循环条件化。因此,在整个去噪过程中,目标片段的生成会同时受到其空间和时间邻近片段的条件影响,从而实现成功的循环闭合。图8中可视化了每个轨迹的完整空间窗口集。

Benchmarks 。为评估长时域摄像机引导视频生成技术在预设轨迹中的表现,我们构建了包含多种挑战性条件轨迹的数据集(详见表1) 。这些轨迹专门设计用于测试视频模型的多项核心能力,包括视频长度外推、闭环控制及碰撞规避等关键功能。