大模型-详解 Vision Transformer (ViT) (2)
1.可学习的嵌入 (Learnable Embedding)
2.位置嵌入 (Position Embeddings)
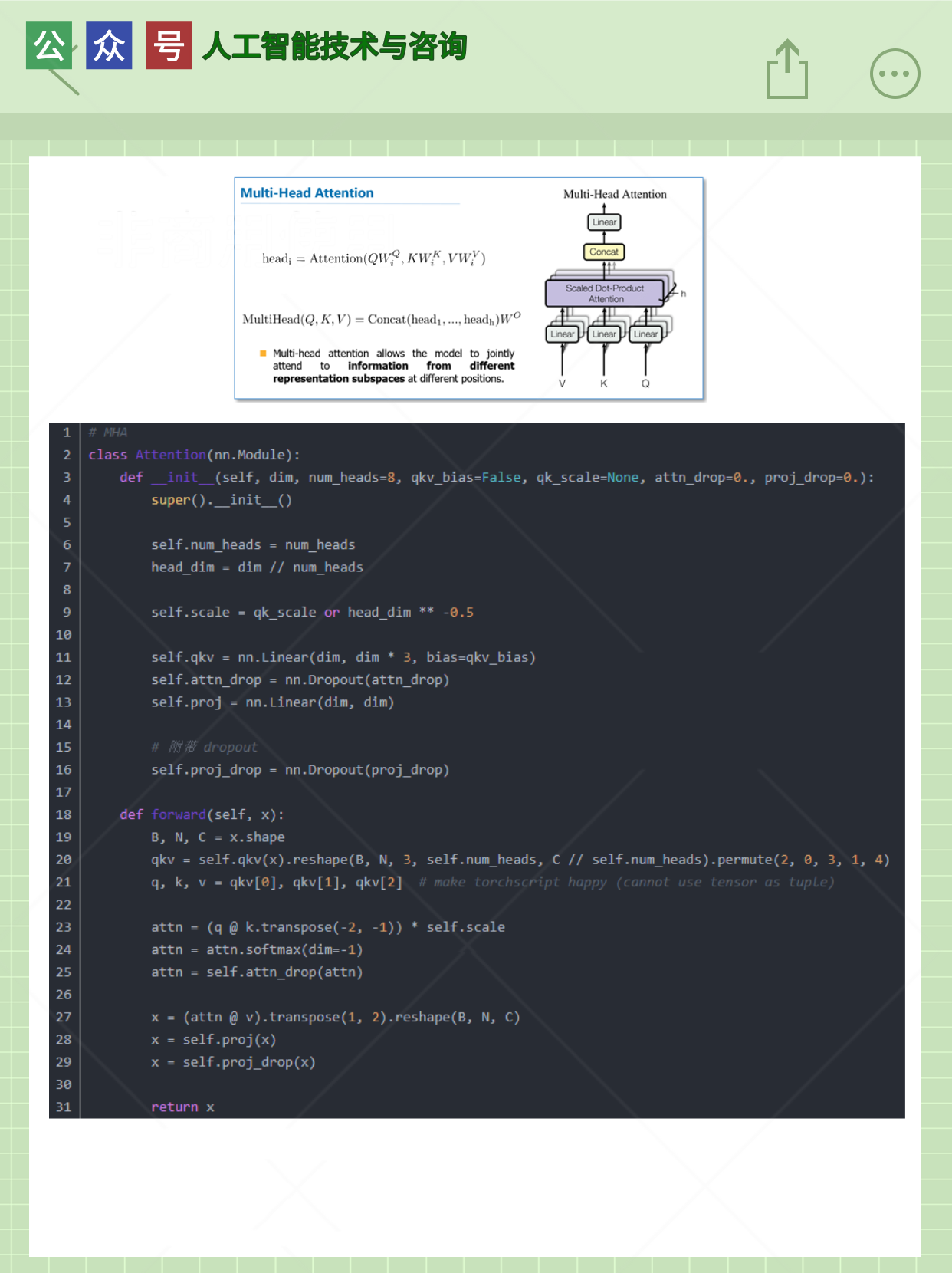
3.Transformer 编码器