文章目录
- [一、 参数](#一、 参数)
- [二、 返回值](#二、 返回值)
- [三、 代码](#三、 代码)
- 完整代码
一、 参数
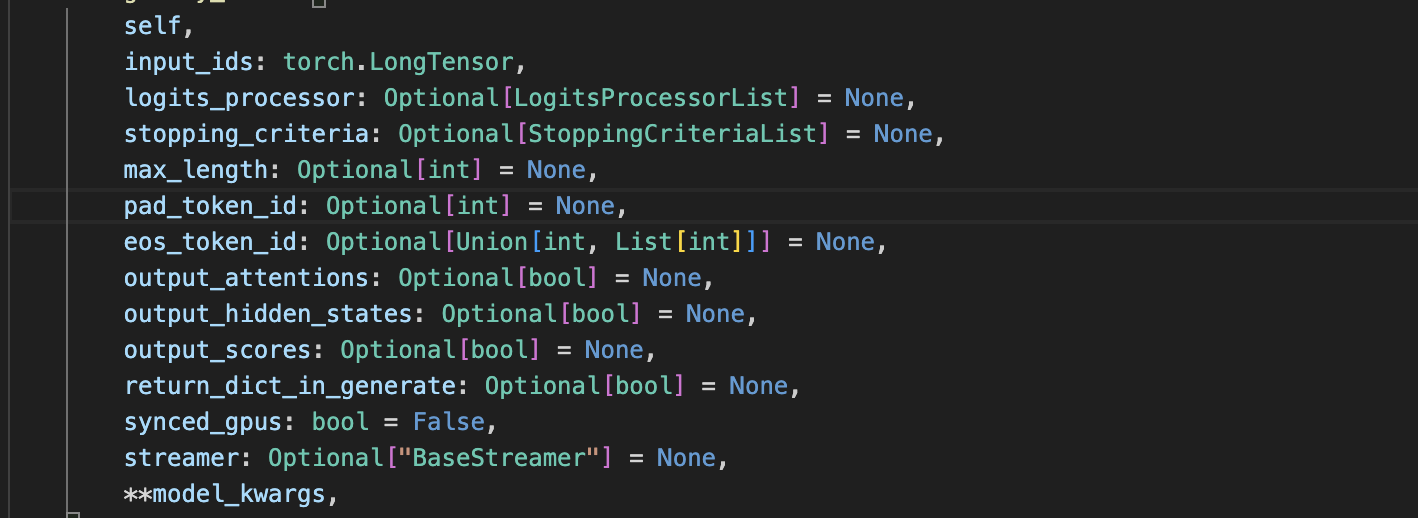
self:由于这个方法是一个GenerationMixin类的方法,所以这里第一个参数是selfinput_ids:经过tokenizer的inputlogits_processor:对生成的logits进行处理的列表stopping_criteria:停止标准,包含了所有需要停止生成的标准max_length:这个参数已经弃用了,应该使用stopping_criteria或者logits_processor来控制最大长度。pad_token_id:用于padding的tokeneos_token_id:序列结束标志output_attentions:用于控制是否返回attentions矩阵output_hidden_states:是否返回hidden_states隐藏层的状态output_scores:是否返回最终的logitsreturn_dict_in_generate:是否返回一个字典类还是一个output_ids的tuplesynced_gpus:gpu同步才会用到的参数streamer:流式输出用到的参数model_kwargs:一些forward中使用到的额外参数
二、 返回值
greedy_search的返回值和GenerationMixin的generate的返回值是一样的,因为实际上generate函数是通过调用greedy_search来生成内容的。可以看到如果参数return_dict_in_generate为False,那么返回的内容应该就是一个生成的input_ids的tuple,如果为True,那么会将scores、hidden_states、attentions封装成一个字典类返回。
三、 代码
python
# init values
logits_processor = logits_processor if logits_processor is not None else LogitsProcessorList()
stopping_criteria = stopping_criteria if stopping_criteria is not None else StoppingCriteriaList()
if max_length is not None:
warnings.warn(
"`max_length` is deprecated in this function, use"
" `stopping_criteria=StoppingCriteriaList([MaxLengthCriteria(max_length=max_length)])` instead.",
UserWarning,
)
stopping_criteria = validate_stopping_criteria(stopping_criteria, max_length)
pad_token_id = pad_token_id if pad_token_id is not None else self.generation_config.pad_token_id
eos_token_id = eos_token_id if eos_token_id is not None else self.generation_config.eos_token_id
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
eos_token_id_tensor = torch.tensor(eos_token_id).to(input_ids.device) if eos_token_id is not None else None
output_scores = output_scores if output_scores is not None else self.generation_config.output_scores
output_attentions = (
output_attentions if output_attentions is not None else self.generation_config.output_attentions
)
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.generation_config.output_hidden_states
)
return_dict_in_generate = (
return_dict_in_generate
if return_dict_in_generate is not None
else self.generation_config.return_dict_in_generate
)初始化一些需要用到的内包括logits_processor、stopping_criteria、pad_token_id、eos_token_id
python
# init attention / hidden states / scores tuples
scores = () if (return_dict_in_generate and output_scores) else None
decoder_attentions = () if (return_dict_in_generate and output_attentions) else None
cross_attentions = () if (return_dict_in_generate and output_attentions) else None
decoder_hidden_states = () if (return_dict_in_generate and output_hidden_states) else None初始化这些元组,用于存储需要返回的数据
python
# if model is an encoder-decoder, retrieve encoder attention weights and hidden states
if return_dict_in_generate and self.config.is_encoder_decoder:
encoder_attentions = model_kwargs["encoder_outputs"].get("attentions") if output_attentions else None
encoder_hidden_states = (
model_kwargs["encoder_outputs"].get("hidden_states") if output_hidden_states else None
)这是处理关于encoder-decoder架构模型的一些内容我不关心这部分内容
python
# keep track of which sequences are already finished
unfinished_sequences = torch.ones(input_ids.shape[0], dtype=torch.long, device=input_ids.device)考虑到我们是按batch去生成内容,不同的sequence可能停止的时间是不一样的,所以需要记录每个sequence是否已经完成生成了。
python
while True:
if synced_gpus:
# Under synced_gpus the `forward` call must continue until all gpus complete their sequence.
# The following logic allows an early break if all peers finished generating their sequence
this_peer_finished_flag = torch.tensor(0.0 if this_peer_finished else 1.0).to(input_ids.device)
# send 0.0 if we finished, 1.0 otherwise
dist.all_reduce(this_peer_finished_flag, op=dist.ReduceOp.SUM)
# did all peers finish? the reduced sum will be 0.0 then
if this_peer_finished_flag.item() == 0.0:
break
# prepare model inputs
model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
# forward pass to get next token
outputs = self(
**model_inputs,
return_dict=True,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
)
if synced_gpus and this_peer_finished:
continue # don't waste resources running the code we don't need
next_token_logits = outputs.logits[:, -1, :]
# pre-process distribution
next_tokens_scores = logits_processor(input_ids, next_token_logits)
# Store scores, attentions and hidden_states when required
if return_dict_in_generate:
if output_scores:
scores += (next_tokens_scores,)
if output_attentions:
decoder_attentions += (
(outputs.decoder_attentions,) if self.config.is_encoder_decoder else (outputs.attentions,)
)
if self.config.is_encoder_decoder:
cross_attentions += (outputs.cross_attentions,)
if output_hidden_states:
decoder_hidden_states += (
(outputs.decoder_hidden_states,)
if self.config.is_encoder_decoder
else (outputs.hidden_states,)
)
# argmax
next_tokens = torch.argmax(next_tokens_scores, dim=-1)
# finished sentences should have their next token be a padding token
if eos_token_id is not None:
if pad_token_id is None:
raise ValueError("If `eos_token_id` is defined, make sure that `pad_token_id` is defined.")
next_tokens = next_tokens * unfinished_sequences + pad_token_id * (1 - unfinished_sequences)
# update generated ids, model inputs, and length for next step
input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
if streamer is not None:
streamer.put(next_tokens.cpu())
model_kwargs = self._update_model_kwargs_for_generation(
outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder
)
# if eos_token was found in one sentence, set sentence to finished
if eos_token_id_tensor is not None:
unfinished_sequences = unfinished_sequences.mul(
next_tokens.tile(eos_token_id_tensor.shape[0], 1).ne(eos_token_id_tensor.unsqueeze(1)).prod(dim=0)
)
# stop when each sentence is finished
if unfinished_sequences.max() == 0:
this_peer_finished = True
# stop if we exceed the maximum length
if stopping_criteria(input_ids, scores):
this_peer_finished = True
if this_peer_finished and not synced_gpus:
breakwhile循环是具体处理自回归的逻辑
这段代码是用来同步gpu的,我只在单卡上推理不关心这个操作。
python
if synced_gpus:
# Under synced_gpus the `forward` call must continue until all gpus complete their sequence.
# The following logic allows an early break if all peers finished generating their sequence
this_peer_finished_flag = torch.tensor(0.0 if this_peer_finished else 1.0).to(input_ids.device)
# send 0.0 if we finished, 1.0 otherwise
dist.all_reduce(this_peer_finished_flag, op=dist.ReduceOp.SUM)
# did all peers finish? the reduced sum will be 0.0 then
if this_peer_finished_flag.item() == 0.0:
break这是准备模型需要的输入,这里后面调试的时候看一下对于具体模型这个model_inputs中到底是什么内容。
python
# prepare model inputs
model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)这段代码是调用模型前向传播一次,得到一次前向传播的logits
python
# forward pass to get next token
outputs = self(
**model_inputs,
return_dict=True,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
)这是多gpu的,我不关心多卡
python
if synced_gpus and this_peer_finished:
continue # don't waste resources running the code we don't need获得最后一个token的logits,并对最后一个logits进行一些处理。
python
next_token_logits = outputs.logits[:, -1, :]
# pre-process distribution
next_tokens_scores = logits_processor(input_ids, next_token_logits)
python
# Store scores, attentions and hidden_states when required
if return_dict_in_generate:
if output_scores:
scores += (next_tokens_scores,)
if output_attentions:
decoder_attentions += (
(outputs.decoder_attentions,) if self.config.is_encoder_decoder else (outputs.attentions,)
)
if self.config.is_encoder_decoder:
cross_attentions += (outputs.cross_attentions,)
if output_hidden_states:
decoder_hidden_states += (
(outputs.decoder_hidden_states,)
if self.config.is_encoder_decoder
else (outputs.hidden_states,)
)处理返回值,如果要求返回内容以字典的形式,那么就是将需要返回的内容打包成字典的形式。
python
# argmax
next_tokens = torch.argmax(next_tokens_scores, dim=-1)贪心解码,拿到top1
python
# finished sentences should have their next token be a padding token
if eos_token_id is not None:
if pad_token_id is None:
raise ValueError("If `eos_token_id` is defined, make sure that `pad_token_id` is defined.")
next_tokens = next_tokens * unfinished_sequences + pad_token_id * (1 - unfinished_sequences)这是对batch的处理,因为句子上下文不同,可能有些sequence会在5个token时结束生成,有些sequence仍没有结束,为了保证不再继续生成一些无用的token同时保证对齐张量,就会选择给结束的地方填充上pad_token_id。
python
# update generated ids, model inputs, and length for next step
input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)next_tokens[:, None]这里是numpy、pytorch中的一个小技巧,是给next_token增加一个维度。
上面这段代码就是将新生成的token合并到input_ids上。
python
if streamer is not None:
streamer.put(next_tokens.cpu())这段代码是流式输出用到的,目前我用不到,所以先搁置不关心。
python
model_kwargs = self._update_model_kwargs_for_generation(
outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder
)这段代码是管理自归回生成过程中的状态具体可以看一下_update_model_kwargs_for_generation这个函数
python
def _update_model_kwargs_for_generation(
self,
outputs: ModelOutput,
model_kwargs: Dict[str, Any],
is_encoder_decoder: bool = False,
standardize_cache_format: bool = False,
) -> Dict[str, Any]:
# update past_key_values
model_kwargs["past_key_values"] = self._extract_past_from_model_output(
outputs, standardize_cache_format=standardize_cache_format
)
if getattr(outputs, "state", None) is not None:
model_kwargs["state"] = outputs.state
# update token_type_ids with last value
if "token_type_ids" in model_kwargs:
token_type_ids = model_kwargs["token_type_ids"]
model_kwargs["token_type_ids"] = torch.cat([token_type_ids, token_type_ids[:, -1].unsqueeze(-1)], dim=-1)
if not is_encoder_decoder:
# update attention mask
if "attention_mask" in model_kwargs:
attention_mask = model_kwargs["attention_mask"]
model_kwargs["attention_mask"] = torch.cat(
[attention_mask, attention_mask.new_ones((attention_mask.shape[0], 1))], dim=-1
)
else:
# update decoder attention mask
if "decoder_attention_mask" in model_kwargs:
decoder_attention_mask = model_kwargs["decoder_attention_mask"]
model_kwargs["decoder_attention_mask"] = torch.cat(
[decoder_attention_mask, decoder_attention_mask.new_ones((decoder_attention_mask.shape[0], 1))],
dim=-1,
)
return model_kwargs可以看到这个函数会先去更更新模型参数重的"past_key_values",关于这个self._extract_past_from_model_output函数它的具体实现先按下不表,它的作用就是返回kv cache
python
if getattr(outputs, "state", None) is not None:
model_kwargs["state"] = outputs.state这是一个反射,用于获取对象outputs是否含有state属性,如果含有那么就将这个也作为模型的参数。
python
if not is_encoder_decoder:
# update attention mask
if "attention_mask" in model_kwargs:
attention_mask = model_kwargs["attention_mask"]
model_kwargs["attention_mask"] = torch.cat(
[attention_mask, attention_mask.new_ones((attention_mask.shape[0], 1))], dim=-1
)
else:
# update decoder attention mask
if "decoder_attention_mask" in model_kwargs:
decoder_attention_mask = model_kwargs["decoder_attention_mask"]
model_kwargs["decoder_attention_mask"] = torch.cat(
[decoder_attention_mask, decoder_attention_mask.new_ones((decoder_attention_mask.shape[0], 1))],
dim=-1,
)这段代码主要是在更新attention_mask,对于decoder-only架构模型主要执行的是if中的逻辑
这是由于自回归生成了一个新的token,对于batch而言就是生成了batch个token,现在需要加上就是给这个新生成的token加上attention_mask
python
if "attention_mask" in model_kwargs:
attention_mask = model_kwargs["attention_mask"]
model_kwargs["attention_mask"] = torch.cat(
[attention_mask, attention_mask.new_ones((attention_mask.shape[0], 1))], dim=-1
)综上_update_model_kwargs_for_generation这个函数主要就干了两件事,一件事是更新kv cache,一件事是延长attention_mask
python
# if eos_token was found in one sentence, set sentence to finished
if eos_token_id_tensor is not None:
unfinished_sequences = unfinished_sequences.mul(
next_tokens.tile(eos_token_id_tensor.shape[0], 1).ne(eos_token_id_tensor.unsqueeze(1)).prod(dim=0)
)
# stop when each sentence is finished
if unfinished_sequences.max() == 0:
this_peer_finished = True这段代码的作用主要是判断这个batch的所有sentence是否都已经完成生成,如果都已经完成了就将this_peer_finished,上面的张量处理比较复杂,具体而言就是判断新生成的tokens中是否含有eos_token,如果有那么这个句子就会被标记为0表示已经完成了生成,如果没有就取决于上一次token是否完成。
python
if this_peer_finished and not synced_gpus:
break如果batch中的所有句子都已经生成完成了,并且我们没有多卡那么就代表本次generate的完成就break出while。
python
# stop if we exceed the maximum length
if stopping_criteria(input_ids, scores):
this_peer_finished = True这段代码主要是判断是否sentence已经生成超过了规定长度,我们在生成的时候往往会传入一个类似max_length限制生成长度。
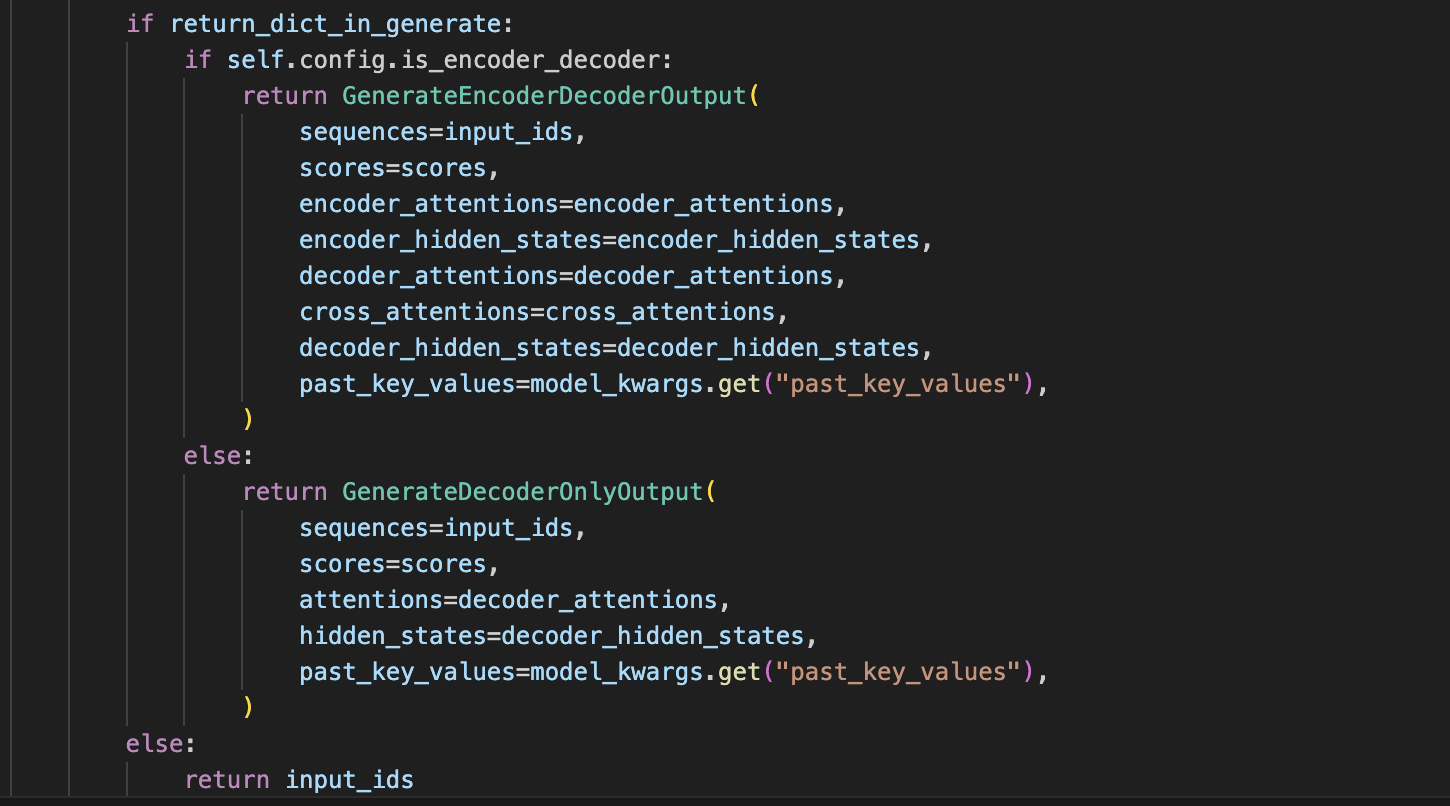
break出while后需要将生成的内容返回,这里会判断是否传入了return_dict_in_generate这个参数,如果传入了这个参数,那么就讲返回一个字典类,如果没有传入就直接返回input_ids
python
if return_dict_in_generate:
if self.config.is_encoder_decoder:
return GenerateEncoderDecoderOutput(
sequences=input_ids,
scores=scores,
encoder_attentions=encoder_attentions,
encoder_hidden_states=encoder_hidden_states,
decoder_attentions=decoder_attentions,
cross_attentions=cross_attentions,
decoder_hidden_states=decoder_hidden_states,
past_key_values=model_kwargs.get("past_key_values"),
)
else:
return GenerateDecoderOnlyOutput(
sequences=input_ids,
scores=scores,
attentions=decoder_attentions,
hidden_states=decoder_hidden_states,
past_key_values=model_kwargs.get("past_key_values"),
)
else:
return input_ids完整代码
python
def greedy_search(
self,
input_ids: torch.LongTensor,
logits_processor: Optional[LogitsProcessorList] = None,
stopping_criteria: Optional[StoppingCriteriaList] = None,
max_length: Optional[int] = None,
pad_token_id: Optional[int] = None,
eos_token_id: Optional[Union[int, List[int]]] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
output_scores: Optional[bool] = None,
return_dict_in_generate: Optional[bool] = None,
synced_gpus: bool = False,
streamer: Optional["BaseStreamer"] = None,
**model_kwargs,
) -> Union[GenerateNonBeamOutput, torch.LongTensor]:
r"""
Generates sequences of token ids for models with a language modeling head using **greedy decoding** and can be
used for text-decoder, text-to-text, speech-to-text, and vision-to-text models.
<Tip warning={true}>
In most cases, you do not need to call [`~generation.GenerationMixin.greedy_search`] directly. Use generate()
instead. For an overview of generation strategies and code examples, check the [following
guide](../generation_strategies).
</Tip>
Parameters:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
The sequence used as a prompt for the generation.
logits_processor (`LogitsProcessorList`, *optional*):
An instance of [`LogitsProcessorList`]. List of instances of class derived from [`LogitsProcessor`]
used to modify the prediction scores of the language modeling head applied at each generation step.
stopping_criteria (`StoppingCriteriaList`, *optional*):
An instance of [`StoppingCriteriaList`]. List of instances of class derived from [`StoppingCriteria`]
used to tell if the generation loop should stop.
max_length (`int`, *optional*, defaults to 20):
**DEPRECATED**. Use `logits_processor` or `stopping_criteria` directly to cap the number of generated
tokens. The maximum length of the sequence to be generated.
pad_token_id (`int`, *optional*):
The id of the *padding* token.
eos_token_id (`Union[int, List[int]]`, *optional*):
The id of the *end-of-sequence* token. Optionally, use a list to set multiple *end-of-sequence* tokens.
output_attentions (`bool`, *optional*, defaults to `False`):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more details.
output_hidden_states (`bool`, *optional*, defaults to `False`):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more details.
output_scores (`bool`, *optional*, defaults to `False`):
Whether or not to return the prediction scores. See `scores` under returned tensors for more details.
return_dict_in_generate (`bool`, *optional*, defaults to `False`):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
synced_gpus (`bool`, *optional*, defaults to `False`):
Whether to continue running the while loop until max_length (needed for ZeRO stage 3)
streamer (`BaseStreamer`, *optional*):
Streamer object that will be used to stream the generated sequences. Generated tokens are passed
through `streamer.put(token_ids)` and the streamer is responsible for any further processing.
model_kwargs:
Additional model specific keyword arguments will be forwarded to the `forward` function of the model.
If model is an encoder-decoder model the kwargs should include `encoder_outputs`.
Return:
[`~generation.GenerateDecoderOnlyOutput`], [`~generation.GenerateEncoderDecoderOutput`] or
`torch.LongTensor`: A `torch.LongTensor` containing the generated tokens (default behaviour) or a
[`~generation.GenerateDecoderOnlyOutput`] if `model.config.is_encoder_decoder=False` and
`return_dict_in_generate=True` or a [`~generation.GenerateEncoderDecoderOutput`] if
`model.config.is_encoder_decoder=True`.
Examples:
```python
>>> from transformers import (
... AutoTokenizer,
... AutoModelForCausalLM,
... LogitsProcessorList,
... MinLengthLogitsProcessor,
... StoppingCriteriaList,
... MaxLengthCriteria,
... )
>>> tokenizer = AutoTokenizer.from_pretrained("gpt2")
>>> model = AutoModelForCausalLM.from_pretrained("gpt2")
>>> # set pad_token_id to eos_token_id because GPT2 does not have a PAD token
>>> model.generation_config.pad_token_id = model.generation_config.eos_token_id
>>> input_prompt = "It might be possible to"
>>> input_ids = tokenizer(input_prompt, return_tensors="pt").input_ids
>>> # instantiate logits processors
>>> logits_processor = LogitsProcessorList(
... [
... MinLengthLogitsProcessor(10, eos_token_id=model.generation_config.eos_token_id),
... ]
... )
>>> stopping_criteria = StoppingCriteriaList([MaxLengthCriteria(max_length=20)])
>>> outputs = model.greedy_search(
... input_ids, logits_processor=logits_processor, stopping_criteria=stopping_criteria
... )
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
["It might be possible to get a better understanding of the nature of the problem, but it's not"]
```"""
# init values
logits_processor = logits_processor if logits_processor is not None else LogitsProcessorList()
stopping_criteria = stopping_criteria if stopping_criteria is not None else StoppingCriteriaList()
if max_length is not None:
warnings.warn(
"`max_length` is deprecated in this function, use"
" `stopping_criteria=StoppingCriteriaList([MaxLengthCriteria(max_length=max_length)])` instead.",
UserWarning,
)
stopping_criteria = validate_stopping_criteria(stopping_criteria, max_length)
pad_token_id = pad_token_id if pad_token_id is not None else self.generation_config.pad_token_id
eos_token_id = eos_token_id if eos_token_id is not None else self.generation_config.eos_token_id
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
eos_token_id_tensor = torch.tensor(eos_token_id).to(input_ids.device) if eos_token_id is not None else None
output_scores = output_scores if output_scores is not None else self.generation_config.output_scores
output_attentions = (
output_attentions if output_attentions is not None else self.generation_config.output_attentions
)
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.generation_config.output_hidden_states
)
return_dict_in_generate = (
return_dict_in_generate
if return_dict_in_generate is not None
else self.generation_config.return_dict_in_generate
)
# init attention / hidden states / scores tuples
scores = () if (return_dict_in_generate and output_scores) else None
decoder_attentions = () if (return_dict_in_generate and output_attentions) else None
cross_attentions = () if (return_dict_in_generate and output_attentions) else None
decoder_hidden_states = () if (return_dict_in_generate and output_hidden_states) else None
# if model is an encoder-decoder, retrieve encoder attention weights and hidden states
if return_dict_in_generate and self.config.is_encoder_decoder:
encoder_attentions = model_kwargs["encoder_outputs"].get("attentions") if output_attentions else None
encoder_hidden_states = (
model_kwargs["encoder_outputs"].get("hidden_states") if output_hidden_states else None
)
# keep track of which sequences are already finished
unfinished_sequences = torch.ones(input_ids.shape[0], dtype=torch.long, device=input_ids.device)
this_peer_finished = False # used by synced_gpus only
while True:
if synced_gpus:
# Under synced_gpus the `forward` call must continue until all gpus complete their sequence.
# The following logic allows an early break if all peers finished generating their sequence
this_peer_finished_flag = torch.tensor(0.0 if this_peer_finished else 1.0).to(input_ids.device)
# send 0.0 if we finished, 1.0 otherwise
dist.all_reduce(this_peer_finished_flag, op=dist.ReduceOp.SUM)
# did all peers finish? the reduced sum will be 0.0 then
if this_peer_finished_flag.item() == 0.0:
break
# prepare model inputs
model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
# forward pass to get next token
outputs = self(
**model_inputs,
return_dict=True,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
)
if synced_gpus and this_peer_finished:
continue # don't waste resources running the code we don't need
next_token_logits = outputs.logits[:, -1, :]
# pre-process distribution
next_tokens_scores = logits_processor(input_ids, next_token_logits)
# Store scores, attentions and hidden_states when required
if return_dict_in_generate:
if output_scores:
scores += (next_tokens_scores,)
if output_attentions:
decoder_attentions += (
(outputs.decoder_attentions,) if self.config.is_encoder_decoder else (outputs.attentions,)
)
if self.config.is_encoder_decoder:
cross_attentions += (outputs.cross_attentions,)
if output_hidden_states:
decoder_hidden_states += (
(outputs.decoder_hidden_states,)
if self.config.is_encoder_decoder
else (outputs.hidden_states,)
)
# argmax
next_tokens = torch.argmax(next_tokens_scores, dim=-1)
# finished sentences should have their next token be a padding token
if eos_token_id is not None:
if pad_token_id is None:
raise ValueError("If `eos_token_id` is defined, make sure that `pad_token_id` is defined.")
next_tokens = next_tokens * unfinished_sequences + pad_token_id * (1 - unfinished_sequences)
# update generated ids, model inputs, and length for next step
input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
if streamer is not None:
streamer.put(next_tokens.cpu())
model_kwargs = self._update_model_kwargs_for_generation(
outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder
)
# if eos_token was found in one sentence, set sentence to finished
if eos_token_id_tensor is not None:
unfinished_sequences = unfinished_sequences.mul(
next_tokens.tile(eos_token_id_tensor.shape[0], 1).ne(eos_token_id_tensor.unsqueeze(1)).prod(dim=0)
)
# stop when each sentence is finished
if unfinished_sequences.max() == 0:
this_peer_finished = True
# stop if we exceed the maximum length
if stopping_criteria(input_ids, scores):
this_peer_finished = True
if this_peer_finished and not synced_gpus:
break
if streamer is not None:
streamer.end()
if return_dict_in_generate:
if self.config.is_encoder_decoder:
return GenerateEncoderDecoderOutput(
sequences=input_ids,
scores=scores,
encoder_attentions=encoder_attentions,
encoder_hidden_states=encoder_hidden_states,
decoder_attentions=decoder_attentions,
cross_attentions=cross_attentions,
decoder_hidden_states=decoder_hidden_states,
past_key_values=model_kwargs.get("past_key_values"),
)
else:
return GenerateDecoderOnlyOutput(
sequences=input_ids,
scores=scores,
attentions=decoder_attentions,
hidden_states=decoder_hidden_states,
past_key_values=model_kwargs.get("past_key_values"),
)
else:
return input_ids