更多内容:XiaoJ的知识星球
目录
-
- 4.预训练语言模型(PLMs,Pre-trained Langue Models)
-
- 4.1 两种范式:
- 4.2 GPT(Generative Pre-trained Transformer)
- 4.3 BERT(Bidirectional Encoder Representations from Transformers)
-
- 4.3.1 BERT介绍
- 4.3.2 Masked Language Model(MLM)
- 4.3.3 Next Sentence Prediction(NSP)
- 4.3.4 BERT输入
- 5.Transformers Tutorial
-
- 5.1 Pipeline API
- 5.2 `AutoModel`和`AutoTokenizer`
- 5.3 Transformers fine-tune Demo
.
4.预训练语言模型(PLMs,Pre-trained Langue Models)
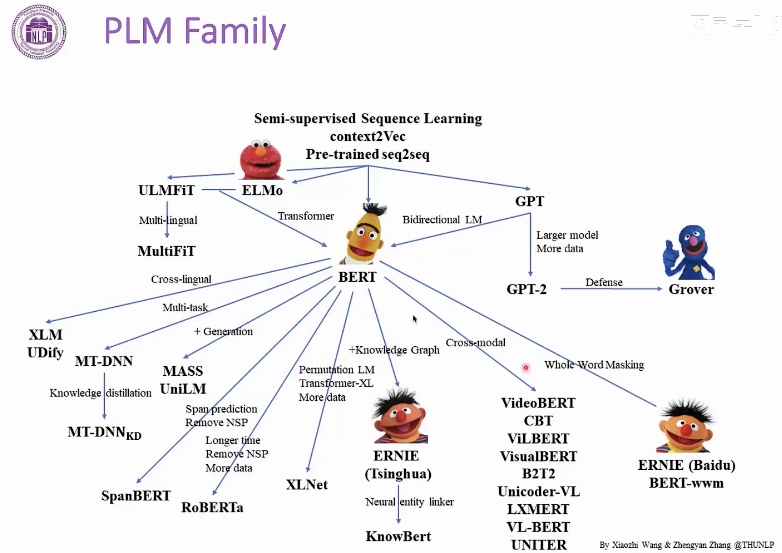
几个PLMs:word2vec(第一个PLM),GPT,BERT,...
PLMs具有强大可移植性。
如今基于Transformer的PLM非常流行,如BERT。
.
4.1 两种范式:
-
Feature-based approaches(基于特征的方法)
-
最具代表性的是 word2vec。
-
使用PLM的输出作为下游模型的输入。
-
-
Fine-tuning approaches(微调的方法)
-
最具代表性的是 BERT。
-
语言模型也将是下游模型,它们的参数将被更新。
-
.
4.2 GPT(Generative Pre-trained Transformer)
GPT(Generative Pre-trained Transformer,生成式预训练变换器):
- 是由OpenAI开发的一种大型语言模型,它通过在大量文本数据上进行预训练,学习语言的模式和结构,从而具备强大的文本生成和理解能力。
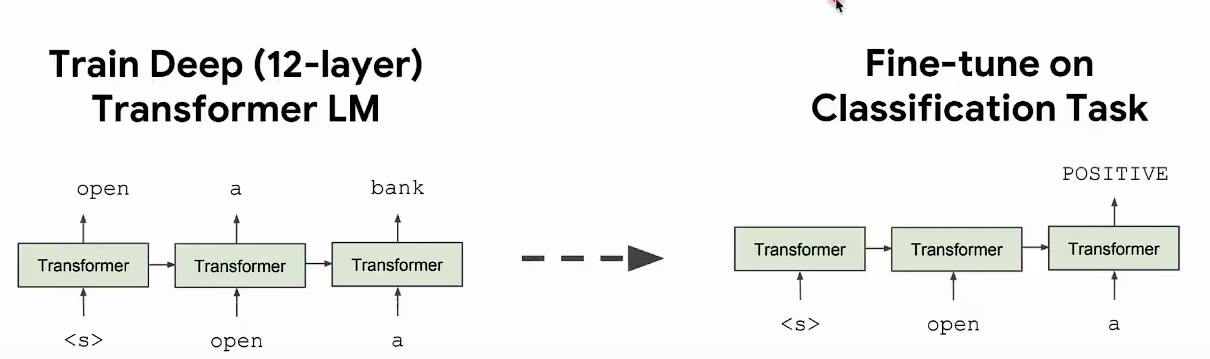
GPT具有Zero-Shot Learning能力。
Zero-Shot Learning(ZSL,零样本学习):
- 一种让模型能够在没有直接训练数据的情况下,对新的类别进行识别或分类的技术。
GPT总结:
-
一个非常强大的生成模型
-
在下游任务上也取得了非常好的迁移学习结果
- 显著超越了ELMo
-
成功的关键
-
大数据(大型无监督语料库)
-
深度神经模型(Transformer)
-
.
4.3 BERT(Bidirectional Encoder Representations from Transformers)
以前方法的问题
-
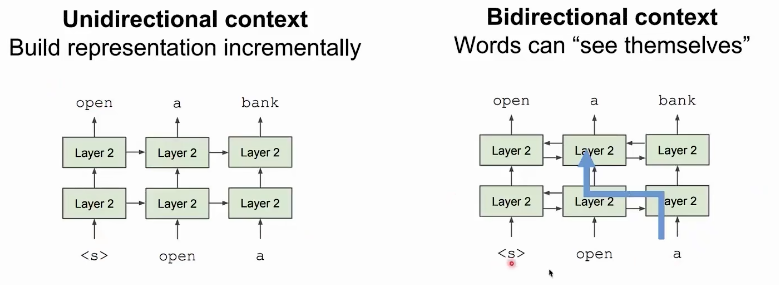
问题:语言模型 只使用左侧上下文或右侧上下文,但语言理解是双向的。
-
为什么LM(语言模型)是单向的?
-
原因1:需要单向性,来拆解长文本。
-
原因2:双向编码会发生信息泄露。
-
4.3.1 BERT介绍
BERT(Bidirectional Encoder Representations from Transformers,Transformer的双向编码器表示)是一种基于Transformer架构的深度学习模型。
BERT的核心特点包括:
-
双向编码:BERT使用双向Transformer编码器,即模型会同时考虑输入序列中,每个词的左侧和右侧上下文。这与传统的单向模型不同,后者只能从左到右或从右到左处理文本。
-
预训练:BERT通过在大量文本数据上进行预训练来学习语言表示。
-
预训练任务包括:Masked Language Model(MLM)和 Next Sentence Prediction(NSP)
-
MLM:随机遮蔽输入序列中的一些词,然后让模型预测这些被遮蔽的词。
-
NSP:预测两个句子是否是连续的文本。
-
-
微调:在预训练完成后,BERT可以在特定任务上进行微调。这意味着模型可以调整其权重以适应特定的NLP任务,如文本分类、命名实体识别、问答系统等。
-
Transformer架构:BERT基于Transformer模型,这是一种依赖于自注意力机制的架构,能够处理长距离依赖关系。
4.3.2 Masked Language Model(MLM)
Masked Language Model(MLM,掩蔽语言模型):
-
让模型学会预测文本中被随机掩蔽的词。有助于模型学习到词与词之间的上下文关系,从而更好地理解语言的复杂性。一般掩蔽15%的词。
-
MLM解决信息泄露的问题。
问题1:
- 在双向模型中所有单词可见,对于多次出现的词,模型可能会直接使用已经的含义,不利于语言模型的学习。
解决方案:
- BERT采用了MLM技术来掩盖一些词语,让它更好的学习。
问题2:
-
Mask token不会出现在下游任务。
-
会造成预训练和反训练(微调)有很大差异,模型效果变差。
解决方案:
-
在Mask掉的15%的单词中,组成如下:
-
80%使用Mask的词;
-
10%替换成随机词;
-
10%保持原本的词。
-
4.3.3 Next Sentence Prediction(NSP)
Next Sentence Prediction(NSP,下一句预测):
-
让模型学会预测两个句子是否是连续的文本。
-
为了生成训练数据,BERT从大规模的文本数据中随机挑选一对句子,并在输入中加入特殊的标记来指示两个句子的边界。
4.3.4 BERT输入

BERT模型处理输入数据:
-
BERT使用一个包含30,000个词的WordPiece词汇表来处理输入。
-
每个token的表示是三个嵌入的总和:
-
Token Embeddings(词嵌入);
-
Segment Embeddings(段落嵌入);
-
Position Embeddings(位置嵌入)。
段落嵌入用于区分两个句子,而位置嵌入则提供单词在句子中的位置信息。
-
CLS和SEP是特殊标记,分别用于表示句子的开始和结束。
.
.
5.Transformers Tutorial
Transformer Tutorial -- hugging-face:
Transformers 是一个由 Hugging Face 开发的开源库,它提供了大量预训练的模型,支持多种不同的任务,包括文本、图像和音频的处理。这个库使得开发者可以轻松地加载预训练模型,并在特定任务上进行微调。
- 模型架构:支持多种模型架构,如BERT、GPT、T5等。
主要特点
-
多模态支持:不仅支持文本,还支持图像和音频任务。
-
简化的API :提供了
pipelineAPI,可以快速使用模型进行推理。 -
社区支持:Hugging Face Hub上有一个活跃的社区,提供了许多共享的模型和项目
.
5.1 Pipeline API
1)简单示例:
使用 Transformers 的pipeline API 进行情感分析的简单示例:
Python
from transformers import pipeline
# 创建一个用于情感分析的pipeline
classifier = pipeline('sentiment-analysis')
# 使用pipeline进行预测
result = classifier("We are very happy to introduce pipeline to the transformers repository.")
print(result)这将输出情感分析的结果,例如:
JSON
[{'label': 'POSITIVE', 'score': 0.9996980428695679}]2)更多参考:
使用管道进行推理:https://hugging-face.cn/docs/transformers/pipeline_tutorial
.
5.2 AutoModel和AutoTokenizer
Transformers 还提供了AutoModel和AutoTokenizer类,可以自动加载预训练模型和对应的分词器。例如:
Python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")AutoModelForSequenceClassification.from_pretrained()
Python
# Tokenize the texts
inputs = tokenizer("Hello World!", return_tensors='pt')
# Run the model
outputs = model(**inputs)
# Save the fine-tuned model in one line
model.save_pretrained("path_to_save_model")这样,你就可以使用模型进行更复杂的操作,比如自定义的训练和fine-tuning(微调)。
简单训练:Train the model with Trainer
Python
trainer = Trainer(
model,
args,
train_dataset=encoded_dataset["train"],
eval_dataset=encoded_dataset["validation"],
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
trainer.train() # Start training!
trainer.evaluate()Trainer 类是 Hugging Face Transformers 库中的一个工具,它简化了模型的训练过程。你需要提供以下参数:
-
model:要训练的模型。 -
args:训练参数,通常是一个TrainingArguments类的实例。 -
train_dataset:用于训练的数据集。 -
eval_dataset:用于评估模型性能的验证数据集。 -
tokenizer:用于数据预处理的分词器。 -
compute_metrics:一个函数,用于计算和返回评估指标。
trainer.train() 方法启动训练过程,而 trainer.evaluate() 方法则在训练完成后评估模型的性能。
.
5.3 Transformers fine-tune Demo
参考视频:https://www.bilibili.com/video/BV1rS411F735?p=40
参考文档:https://hugging-face.cn/docs/transformers/training
大致流程:
准备:datasets、transformers库
fine-tune方式一:pipline使用fine-tune好的模型,完成下游任务。
fine-tune方式二:在下游任务上进行fine-tune。
-
load datasets
-
load metric(加载评估指标)
-
metric_compute计算模型表现。
-
进行tokenization
- 通过preprocess_function,将tokenization的数据传给hugging facec处理。
-
构建模型,进行fine-tune
-
使用Traniner类:传参数
-
使用Traniner类:train开始训练
-
.
声明:资源可能存在第三方来源,若有侵权请联系删除!