1 简介
Voxelized GICP(VGICP) 是对经典 GICP(Generalized ICP) 的改进:不再对每个点做昂贵的最近邻查找,而是在体素(voxel)层上进行"分布到分布"(distribution-to-distribution)的配准。论文算法通过对点云进行体素化、在每个体素上汇总统计量(均值与协方差),把 GICP 的点级 d2d(distribution-to-distribution)思想推广到体素级,从而大幅降低对应搜索复杂度并便于并行实现(CPU 多线程 / GPU)。作者在论文与实现中报告:在 CPU 上可处理 15k 点/帧 达 30 Hz,在 GPU 上达 120 Hz,同时保持与原始 GICP 相当的精度。
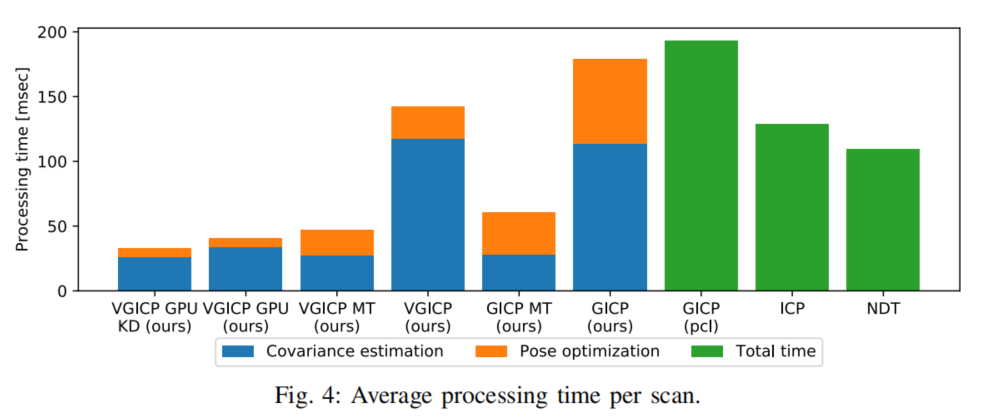
2 算法背景
- ICP 家族:经典 ICP(点到点、点到面)需要逐点最近邻搜索,速度受限于近邻查找(kd-tree)开销且对噪声、平坦区域不够稳健。
- GICP(Generalized ICP):把点看成局部分布(带协方差的高斯),通过最小化两个分布间的 Mahalanobis 距离得到更鲁棒、更准确的配准(结合点到点与点到面信息)。但 GICP 仍然需要对每个源点找目标最近邻,因此在大点云或高频率场景下计算量大。
- NDT(Normal Distributions Transform)/ voxel-based 方法:将地图或点云划分体素并在体素内建分布,用分布匹配减少配准成本,但 NDT 对体素分辨率敏感(精度与速度的 trade-off)。
VGICP 的思想是"把 GICP 的优点(分布到分布的精度)与 voxel-based data association 的效率结合起来",以达到"既快又准且便于并行"的目标。
3 文章主要贡献
- Voxelization + GICP 框架结合:提出在体素层上对点集合做均值与协方差估计,并在体素级别进行 GICP 风格的分布到分布配准,从而避免每点最近邻搜索同时保留 GICP 的几何约束。
- 高效并行实现(CPU 多线程 & GPU):提出了便于并行的数据组织与代价函数构造,使得实现能够在 CPU/GPU 上高效运行(论文给出具体帧率结果)。
4 需解决的关键问题
- 如何在体素上构造能代表局部几何的分布(均值、协方差),并保证该近似不会造成明显精度损失?
- 如何高效地建立体素间的对应(data association)------即把源体素与目标体素配对,避免昂贵的最近邻搜索?
- 在体素级别做配准后如何保持对细节的精确对齐(多尺度或细化策略)?
- 如何把上述流程并行化以在 CPU/GPU 上取得实际的速度收益?
VGICP 针对这些问题提出了对应机制(体素统计、基于体素格的查找而非 kd-tree、并行实现与多尺度/细化策略),下面在算法流程中详细展开。
5 算法总体流程(高层步骤)
-
体素化(Voxelization)
- 对源点云与目标点云分别划分到相同的体素网格(固定 voxel size)。
- 在每个非空体素内计算点的均值 μ \mu μ 和 协方差矩阵 Σ \Sigma Σ(即把体素内的多点分布近似为高斯)。
-
数据关联(Voxel-level association)
- 根据当前变换估计 T T T(旋转和平移),把源体素的中心(或均值)变换到目标坐标系中,然后直接在目标体素网格中按体素索引查找对应体素(常数时间查找),得到目标体素的 μ ′ , Σ ′ \mu',\Sigma' μ′,Σ′。不存在对应时跳过或作置信度处理。
-
构造代价函数(distribution-to-distribution)
- 对每一对对应体素(源与目标),建立残差与协方差并构造 Mahalanobis 型的代价值,类似 GICP 的配准代价:
r = μ s − R μ t − t r = \mu_s - R\mu_t - t r=μs−Rμt−t
C = Σ s + R Σ t R ⊤ C = \Sigma_s + R \Sigma_t R^\top C=Σs+RΣtR⊤
代价项为:
E = ∑ r ⊤ C − 1 r E = \sum r^\top C^{-1} r E=∑r⊤C−1r
- 对每一对对应体素(源与目标),建立残差与协方差并构造 Mahalanobis 型的代价值,类似 GICP 的配准代价:
-
迭代求解
- 用 Gauss--Newton / Levenberg--Marquardt 线性化上式并求解增量变换(旋转参数可用李代数 s e ( 3 ) \mathfrak{se}(3) se(3) 表示并线性化)。
- 更新 T T T,重复数据关联与优化直至收敛或达到迭代上限。
-
多尺度 / 局部细化(可选)
- 可先用较大体素粗配准,然后逐步细化体素大小以恢复细节(论文或后续工作有类似策略的讨论 / 扩展)。
6 核心方法细节与关键公式
6.1 相关点云配准算法
A. GICP
经典 ICP 算法有许多变体,例如 Trimmed ICP 和 Normal ICP 。GICP 是最常用的 ICP 变体之一。GICP 将经典 ICP 算法扩展为一种 分布到分布(distribution-to-distribution) 的匹配方式。尽管其精度较高,但该算法(以及其他 ICP 变体)在很大程度上依赖于最近邻搜索来建立点之间的对应关系。尽管通常采用基于 KD-tree 的高效搜索,但最近邻搜索常常成为瓶颈,使得当点的数量较大时算法无法实时运行。此外,基于最近邻搜索的方法不适合在 GPU 上进行优化,因为它大量使用条件分支,这会显著降低 GPU 的性能。
B. NDT
NDT 采用了一种基于体素的关联方法,而不是精确的最近邻搜索。该算法首先将输入点云划分为一组体素,并为每个体素中的点拟合一个正态分布。然后,它通过寻找使输入点在这些体素分布下似然最大化的变换,将另一点云与体素化后的点云对齐。由于 NDT 避免了代价高昂的最近邻关联,因此通常比 ICP 变体算法快得多。D2D-NDT(Distribution-to-Distribution NDT) 是 NDT 的一种扩展,它将源点云和目标点云都进行体素化,并计算源体素与目标体素分布之间的距离。其比较方式与 GICP 类似,8 指出 D2D-NDT 在精度上优于经典的 NDT。
然而,NDT 及其变体的精度依赖于体素大小的选择。为了获得最佳性能,需要根据传感器和环境的特性仔细选择合适的体素大小。一些研究提出了方法以提升 NDT 对超参数变化的鲁棒性(例如,多分辨率方法 9 和三线性体素平滑 3)。然而,这些扩展通常会对 NDT 的处理速度产生负面影响。
C. 基于特征的配准
基于特征的配准方法首先从输入点云中提取一些具有代表性的特征,然后通过特征对应关系来估计变换。用于点云配准的特征有很多,例如基本的平面和边缘特征 10, 4,快速点特征直方图(FPFH)11,以及方向直方图特征(SHOT)12。这些特征能够较为鲁棒地找到点云之间的对应关系,因此基于特征的方法通常对初始位姿误差更为鲁棒(某些方法甚至不需要初始猜测)。然而,由于基于特征的方法仅使用有限数量的特征(通常远小于输入点数),其精度往往不如基于点的方法。因此,在典型应用中,通常在基于特征的方法之后再进行基于点的精配准。基于特征和基于点的配准方法是正交的,两者应结合使用以互为补充。
综上所述,现有点云配准方法大体可以分为三类:基于点的 ICP 及其变体 、基于体素分布的 NDT 类方法 、以及 基于特征的方法 。其中,ICP 及其改进方法(如 GICP)具有较高的精度,但严重依赖最近邻搜索,计算开销大,且难以在 GPU 上高效并行;NDT 通过体素建模避免了最近邻搜索,通常在速度上优于 ICP,但其精度对体素大小高度敏感,且扩展方法往往牺牲实时性;基于特征的配准方法在大位姿误差或缺乏初始估计的情况下表现鲁棒,但由于仅利用有限数量的特征,往往需要与点基方法结合以提升精度。由此可见,如何在 精度、速度与鲁棒性之间取得平衡,仍是点云配准研究中的关键问题。
6.2 VGICP算法
首先介绍 GICP 算法,然后将其扩展为 一对多分布对应(one-to-multiple distribution correspondence) 的形式,从而推导出VGICP 算法。
A. GICP 算法
考虑估计变换矩阵 T T T,用于将点集 A = { a 0 , ⋯ , a N } A = \{a_0, \cdots, a_N\} A={a0,⋯,aN}(源点云)与另一点集 B = { b 0 , ⋯ , b N } B = \{b_0, \cdots, b_N\} B={b0,⋯,bN}(目标点云)对齐。按照经典 ICP 算法的做法,假设点集 A 和 B 之间的对应关系由最近邻搜索给出,即 b i = T a i b_i = T a_i bi=Tai。
GICP 算法 将采样点所在的表面建模为高斯分布:
a i ∼ N ( a ^ i , C i A ) , b i ∼ N ( b ^ i , C i B ) 。 a_i \sim \mathcal{N}(\hat{a}_i, C_i^A), \quad b_i \sim \mathcal{N}(\hat{b}_i, C_i^B)。 ai∼N(a^i,CiA),bi∼N(b^i,CiB)。
然后,定义变换误差为:
d ^ i = b ^ i − T a ^ i 。 (1) \hat{d}_i = \hat{b}_i - T \hat{a}_i。 \tag{1} d^i=b^i−Ta^i。(1)
根据高斯分布的可重生性(reproductive property),误差 d i d_i di 的分布为:
d i ∼ N ( b ^ i − T a ^ i , C i B + T C i A T T ) , (2) d_i \sim \mathcal{N}(\hat{b}_i - T \hat{a}_i, C_i^B + T C_i^A T^T), \tag{2} di∼N(b^i−Ta^i,CiB+TCiATT),(2)
= N ( 0 , C i B + T C i A T T ) 。 (3) = \mathcal{N}(0, C_i^B + T C_i^A T^T)。 \tag{3} =N(0,CiB+TCiATT)。(3)
GICP 算法通过最大化式 (3) 的对数似然来求解变换矩阵 T T T:
T = arg max T ∑ i log ( p ( d i ) ) , (4) T = \arg \max_T \sum_i \log(p(d_i)), \tag{4} T=argTmaxi∑log(p(di)),(4)
等价于最小化以下代价函数:
T = arg min T ∑ i d i T ( C i B + T C i A T T ) − 1 d i 。 (5) T = \arg \min_T \sum_i d_i^T (C_i^B + T C_i^A T^T)^{-1} d_i。 \tag{5} T=argTmini∑diT(CiB+TCiATT)−1di。(5)
每个点的协方差矩阵通常通过其 k k k 个邻居估计(例如 k = 20 k = 20 k=20)。按照 1 的建议,每个协方差矩阵通过将其特征值替换为 ( 1 , 1 , ϵ ) (1, 1, \epsilon) (1,1,ϵ) 进行正则化。该正则化使得 GICP 退化为 面到面 ICP(plane-to-plane ICP) 的形式,从而提升了算法的鲁棒性和收敛性。
B. 体素化 GICP 算法
为了推导体素化 GICP(VGICP)算法,首先将公式 (1) 扩展,使其计算点 a i a_i ai 与其邻域点集合 { b j ∣ ∣ a i − b j ∣ < r } \{b_j \mid |a_i - b_j| < r\} {bj∣∣ai−bj∣<r} 之间的距离,如下所示:
d ^ i 0 = ∑ j ( b ^ j − T a ^ i ) 。 (6) \hat{d}_i^0 = \sum_j (\hat{b}_j - T \hat{a}_i)。 \tag{6} d^i0=j∑(b^j−Ta^i)。(6)
该公式可以理解为对目标点分布的一种平滑处理。然后,类似于公式 (3), d ^ i 0 \hat{d}_i^0 d^i0 的分布为:
d ^ i 0 ∼ ( μ d i , C d i ) , (7) \hat{d}i^0 \sim (\mu{d_i}, C_{d_i}), \tag{7} d^i0∼(μdi,Cdi),(7)
μ d i = ∑ j ( b ^ j − T a ^ i ) = 0 , (8) \mu_{d_i} = \sum_j (\hat{b}_j - T \hat{a}_i) = 0, \tag{8} μdi=j∑(b^j−Ta^i)=0,(8)
C d i = ∑ j ( C j B + T C i A T T ) 。 (9) C_{d_i} = \sum_j (C_j^B + T C_i^A T^T)。 \tag{9} Cdi=j∑(CjB+TCiATT)。(9)
算法通过最大化公式 (7) 的对数似然来估计变换矩阵 T T T:
T = arg min T ∑ i ( d ~ i T C ~ i − 1 d ~ i ) , (10) T = \arg \min_T \sum_i \left( \tilde{d}_i^T \tilde{C}_i^{-1} \tilde{d}_i \right), \tag{10} T=argTmini∑(d~iTC~i−1d~i),(10)
d ~ i = ∑ j ( b j − T a i ) , (11) \tilde{d}_i = \sum_j (b_j - T a_i), \tag{11} d~i=j∑(bj−Tai),(11)
C ~ i = ∑ j ( C j B + T C i A T T ) (12) \tilde{C}_i = \sum_j \left( C_j^B + T C_i^A T^T \right) \tag{12} C~i=j∑(CjB+TCiATT)(12)
为了高效地计算上述公式,将其修改为:
T = arg min T ∑ i N i d ~ i T C ~ i − 1 d ~ i , (13) T = \arg \min_T \sum_iN_i \tilde{d}_i^T \tilde{C}_i^{-1} \tilde{d}_i, \tag{13} T=argTmini∑Nid~iTC~i−1d~i,(13)
d ~ i = ∑ j b j N i − T a i , (14) \tilde{d}_i = \frac{\sum_j b_j}{N_i} - T a_i, \tag{14} d~i=Ni∑jbj−Tai,(14)
C ~ i = ∑ j C j B N i + T C i A T T 。 (15) \tilde{C}_i = \frac{\sum_j C_j^B}{N_i} + T C_i^A T^T。 \tag{15} C~i=Ni∑jCjB+TCiATT。(15)
其中, N i N_i Ni 是邻域点的数量。公式 (13) 表明,可以通过将点 a i a_i ai 周围的分布均值( b j b_j bj 和 C j C_j Cj)代替公式 (5) 中的 b i b_i bi 和 C i B C_i^B CiB,并以 N i N_i Ni 作为权重,从而高效地计算目标函数。
可以自然地将该公式应用于基于体素的计算,通过在每个体素中存储 b ˉ i = ∑ j b j / N \bar{b}_i = \sum_j b_j / N bˉi=∑jbj/N 和 C ˉ i = ∑ j C j B / N \bar{C}_i = \sum_j C_j^B / N Cˉi=∑jCjB/N。
图 1 展示了 GICP、NDT 以及我们 VGICP 使用的对应关系模型。

- GICP 采用最近邻分布到分布(nearest distribution-to-distribution)对应模型,该方法合理,但依赖代价高昂的最近邻搜索。
- 为了实现快速配准,NDT 使用点到体素分布(point-to-voxel-distribution)对应模型。然而,要计算 3D 协方差矩阵至少需要 4 个点(实际中通常超过 10 个点)。如果体素中的点数较少,协方差矩阵将会失真。
- VGICP 利用体素内 单点到多分布(single-to-multiple distributions) 的对应关系,即便体素内只有少量点,也能稳健处理。由于 VGICP 是从点分布计算体素分布,即便体素内只有一个点,也能得到合理的协方差矩阵。
C. 实现细节
算法 1 详细描述了 VGICP 的配准流程。如上所述,VGICP 算法在优化过程中 无需进行代价高昂的最近邻搜索,因此能够充分利用 CPU 和 GPU 的并行处理能力。
在位姿优化方面,我们选择使用高斯--牛顿(Gauss--Newton)优化器,因为它收敛速度快,且不像拟牛顿(quasi-Newton)方法那样需要超参数。
论文作者实现了 VGICP 算法的三种版本:单线程、 多线程以及 GPU 处理版本。
- 所有版本首先使用基于 KD-tree 的最近邻搜索 13 来估计每个点的协方差矩阵。
- 在多线程和 GPU 版本中,该协方差估计过程实现了并行化。
- 我们还实现了基于 GPU 的暴力最近邻搜索(brute-force nearest neighbor search)。
作为对照,除了 VGICP 之外还实现了 GICP 算法。
- GICP 的实现同样通过 CPU 多线程进行并行化,但由于依赖 KD-tree 最近邻搜索,因此 未在 GPU 上实现,因为这种搜索方式不适合 GPU 并行计算。
6.3 算法 1 VGICP 算法
输入:
- 点云: A = { a 0 , ... , a N } , B = { b 0 , ... , b M } \mathcal{A} = \{a_0, \dots, a_N\}, \mathcal{B} = \{b_0, \dots, b_M\} A={a0,...,aN},B={b0,...,bM}
- 协方差矩阵: C A = { C 0 A , ... , C N A } , C B = { C 0 B , ... , C M B } C^A = \{C^A_0, \dots, C^A_N\}, C^B = \{C^B_0, \dots, C^B_M\} CA={C0A,...,CNA},CB={C0B,...,CMB}
- 初始估计变换: T ~ \tilde{T} T~
输出:
- 最优变换矩阵 T T T
主要流程 VGICP(A, B, C^A, C^B, T ~ \tilde{T} T~)
-
将初始变换 T ← T ~ T \gets \tilde{T} T←T~
-
对目标点云进行体素化: V ← VOXELIZATION ( B , C B ) \mathcal{V} \gets \text{VOXELIZATION}(B, C^B) V←VOXELIZATION(B,CB)
-
迭代直到收敛:
-
初始化误差和协方差集合 e = , J = e = \[\], J = \[\] e=\[\],J=\[\]
-
对每个源点 a i a_i ai:
- 计算点所在体素索引 voxel_index = ⌊ a i / voxel_resolution ⌋ \text{voxel\_index} = \lfloor a_i / \text{voxel\_resolution} \rfloor voxel_index=⌊ai/voxel_resolution⌋
- 如果 a i a_i ai 不在体素内,跳过
- 计算残差和雅可比矩阵 e i , J i ← Cost ( T , a i , C i A , v . μ , v . C , v . N ) e_i, J_i \gets \text{Cost}(T, a_i, C_i^A, v.\mu, v.C, v.N) ei,Ji←Cost(T,ai,CiA,v.μ,v.C,v.N)
- 将当前点的残差和雅可比加入集合: e ← e ∪ e i , J ← J ∪ J i e \gets e \cup e_i, J \gets J \cup J_i e←e∪ei,J←J∪Ji
-
使用 Gauss--Newton 更新:
δ T ← − ( J T J ) − 1 J T e \delta T \gets - (J^T J)^{-1} J^T e δT←−(JTJ)−1JTe
T ← T ⊕ δ T T \gets T \oplus \delta T T←T⊕δT
-
-
返回最优变换 T T T
体素化过程 VOXELIZATION(B, C^B)
-
初始化体素集合 V ← \mathcal{V} \gets \[\] V←\[\]
-
对每个目标点 b j b_j bj:
- 计算体素索引 voxel_index = cast_to_int ( b j / voxel_resolution ) \text{voxel\_index} = \text{cast\_to\_int}(b_j / \text{voxel\_resolution}) voxel_index=cast_to_int(bj/voxel_resolution)
- 如果体素不存在,初始化该体素 ( μ = 0 , C = 0 , N = 0 ) (\mu = 0, C = 0, N = 0) (μ=0,C=0,N=0)
- 更新体素的均值 μ ← μ + b j \mu \gets \mu + b_j μ←μ+bj
- 更新体素的协方差 C ← C + C j B C \gets C + C_j^B C←C+CjB
- 体素内点计数 N ← N + 1 N \gets N + 1 N←N+1
-
对每个体素 v ∈ V v \in \mathcal{V} v∈V:
- 计算平均值 μ ← μ / N \mu \gets \mu / N μ←μ/N
- 计算平均协方差 C ← C / N C \gets C / N C←C/N
-
返回体素集合 V \mathcal{V} V
-
核心思想:
- 将目标点云进行体素化,每个体素存储点分布的均值和协方差。
- 源点与体素内的多点分布进行对应,而不是单点对应,从而实现 单点到多分布的匹配(single-to-multiple distribution)。
-
优化过程:
- 通过累积残差和雅可比矩阵,使用 高斯--牛顿法 更新变换。
- 避免了代价高昂的最近邻搜索,适合 CPU/GPU 并行计算。
-
优势:
- 即使某个体素内只有少量点,也能稳定计算协方差矩阵。
- 算法对大规模点云和实时应用友好。

7 算法优势
- 显著加速:避免对每个点做最近邻搜索,数据关联只需基于体素索引,便于并行化(CPU 多线程 / GPU)。论文中给出具体帧率实验。
- 保持 GICP 精度风格:因为仍在分布层面使用协方差与 Mahalanobis 距离,VGICP 在很多场景下能达到接近 GICP 的精度,而比 NDT 更不敏感于体素分辨率(论文中讨论了鲁棒性)。
- 工程友好 / 可替换接口:作者实现与 PCL registration 接口兼容,可作为现有系统中 GICP 的高效替代实现(见开源仓库)。
8 局限与注意事项
- 体素分辨率的选择:太大体素会丢失细节、太小则降低速度并接近逐点方法;有时需多尺度策略来平衡粗配准与局部细化。论文/后续工作讨论了多尺度扩展。
- 低重叠 / 极端噪声场景:如同多数基于局部最优化的方法,若初始位姿很差或重叠极小可能陷入局部最优;VGICP 也依赖合理的初值或粗配准策略。
- 体素内分布近似误差:把多个点用一个高斯近似可能在复杂曲面或多层结构下造成信息损失;这在一定程度上通过体素大小与滤波策略调整得到控制。
9 工程实践建议
- 若目标是替换现有 GICP:优先试
fast_gicp的多线程版本(简单替换接口),先在采样后点云(10k--30k 点)上评估精度与速度。 - 若需要更强鲁棒性:在 VGICP 基础上采用 多尺度体素化(先用大体素做粗配准,再缩小体素细化)或融合基于特征的粗配准步骤(RANSAC + FPFH 等)。
- 对 GPU 实现:注意内存布局与并行原语(体素哈希表或规则栅格),论文实现与仓库可以作为实现参考。
10 参考文献
- Kenji Koide, Masashi Yokozuka, Shuji Oishi, Atsuhiko Banno, "Voxelized GICP for Fast and Accurate 3D Point Cloud Registration", ICRA 2021 (preprint PDF).
fast_gicp--- GitHub repository (Koide) ------ 多线程 / GPU 实现,PCL 接口。 (GitHub)- 参考背景:GICP 原始方法 & NDT、Voxel-based registration 的综述 / 扩展文献(参见论文参考文献列表和后续工作如 MVGICP 等)。
GICP算法参考:点云配准算法之-Generalized-ICP( GICP)