python
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import DataLoader, Dataset
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import accuracy_score, confusion_matrix
import seaborn as sns
import os
# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 创建MNIST数据目录
mnist_dir = './data/MNIST/raw'
os.makedirs(mnist_dir, exist_ok=True)
# 1. 数据预处理和加载
class MNISTTransformerDataset(Dataset):
def __init__(self, dataset, patch_size=4, flatten=True):
self.dataset = dataset
self.patch_size = patch_size
self.flatten = flatten
def __len__(self):
return len(self.dataset)
def __getitem__(self, idx):
img, label = self.dataset[idx]
# 将图像转换为patches
if self.flatten:
# 方法1: 将图像展平为序列
img_tensor = img.view(-1) # (784)
patches = img_tensor.unsqueeze(0) # (1, 784)
else:
# 方法2: 创建图像patches
img_np = img.squeeze().numpy()
h, w = img_np.shape
patches = []
for i in range(0, h, self.patch_size):
for j in range(0, w, self.patch_size):
patch = img_np[i:i+self.patch_size, j:j+self.patch_size]
if patch.shape == (self.patch_size, self.patch_size):
patches.append(patch.flatten())
patches = torch.tensor(np.array(patches), dtype=torch.float32)
return patches, label
# 2. Transformer模型定义
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() *
(-np.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
return x + self.pe[:x.size(0), :]
class TransformerClassifier(nn.Module):
def __init__(self, input_dim=784, d_model=128, nhead=8,
num_layers=3, num_classes=10, dropout=0.1):
super(TransformerClassifier, self).__init__()
self.d_model = d_model
# 输入投影层
self.input_projection = nn.Linear(input_dim, d_model)
# 位置编码
self.pos_encoding = PositionalEncoding(d_model)
# Transformer编码器
encoder_layer = nn.TransformerEncoderLayer(
d_model=d_model,
nhead=nhead,
dim_feedforward=512,
dropout=dropout,
activation='gelu'
)
self.transformer = nn.TransformerEncoder(encoder_layer, num_layers)
# 分类头
self.classifier = nn.Sequential(
nn.LayerNorm(d_model),
nn.Linear(d_model, 256),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(256, num_classes)
)
# [CLS] token
self.cls_token = nn.Parameter(torch.randn(1, 1, d_model))
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# x shape: (batch_size, seq_len, input_dim) 或 (batch_size, input_dim)
if len(x.shape) == 2:
x = x.unsqueeze(1) # (batch_size, 1, input_dim)
batch_size = x.size(0)
seq_len = x.size(1)
# 输入投影
x = self.input_projection(x) # (batch_size, seq_len, d_model)
# 添加CLS token
cls_tokens = self.cls_token.expand(batch_size, -1, -1)
x = torch.cat([cls_tokens, x], dim=1) # (batch_size, seq_len+1, d_model)
# 位置编码
x = x.transpose(0, 1) # (seq_len+1, batch_size, d_model)
x = self.pos_encoding(x)
# Transformer编码
x = self.transformer(x) # (seq_len+1, batch_size, d_model)
# 取CLS token的输出用于分类
cls_output = x[0] # (batch_size, d_model)
# 分类
output = self.classifier(cls_output)
return output
# 3. 训练函数
def train_epoch(model, dataloader, criterion, optimizer, device):
model.train()
running_loss = 0.0
all_preds = []
all_labels = []
for batch_idx, (data, target) in enumerate(dataloader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
# 前向传播
output = model(data)
loss = criterion(output, target)
# 反向传播
loss.backward()
optimizer.step()
running_loss += loss.item()
# 计算准确率
pred = output.argmax(dim=1, keepdim=True)
all_preds.extend(pred.cpu().numpy())
all_labels.extend(target.cpu().numpy())
if batch_idx % 100 == 0:
print(f'训练批次: {batch_idx}/{len(dataloader)}, 损失: {loss.item():.6f}')
accuracy = accuracy_score(all_labels, all_preds)
avg_loss = running_loss / len(dataloader)
return avg_loss, accuracy
def validate_epoch(model, dataloader, criterion, device):
model.eval()
running_loss = 0.0
all_preds = []
all_labels = []
with torch.no_grad():
for data, target in dataloader:
data, target = data.to(device), target.to(device)
output = model(data)
loss = criterion(output, target)
running_loss += loss.item()
pred = output.argmax(dim=1, keepdim=True)
all_preds.extend(pred.cpu().numpy())
all_labels.extend(target.cpu().numpy())
accuracy = accuracy_score(all_labels, all_preds)
avg_loss = running_loss / len(dataloader)
return avg_loss, accuracy, all_preds, all_labels
# 4. 主训练流程
def main():
# 超参数
batch_size = 128
learning_rate = 0.001
epochs = 10
d_model = 128
nhead = 8
num_layers = 3
# 数据变换
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
# 加载数据
train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST('./data', train=False, transform=transform)
# 创建Transformer数据集
train_transformer_dataset = MNISTTransformerDataset(train_dataset, flatten=True)
test_transformer_dataset = MNISTTransformerDataset(test_dataset, flatten=True)
train_loader = DataLoader(train_transformer_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_transformer_dataset, batch_size=batch_size, shuffle=False)
print(f"训练样本数: {len(train_dataset)}")
print(f"测试样本数: {len(test_dataset)}")
# 初始化模型
model = TransformerClassifier(
input_dim=784,
d_model=d_model,
nhead=nhead,
num_layers=num_layers,
num_classes=10,
dropout=0.1
).to(device)
print(f"模型参数量: {sum(p.numel() for p in model.parameters()):,}")
# 损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=0.01)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=epochs)
# 训练历史记录
train_losses = []
train_accuracies = []
val_losses = []
val_accuracies = []
# 训练循环
print("开始训练...")
for epoch in range(epochs):
print(f"\nEpoch {epoch+1}/{epochs}")
print("-" * 50)
# 训练
train_loss, train_acc = train_epoch(model, train_loader, criterion, optimizer, device)
# 验证
val_loss, val_acc, val_preds, val_labels = validate_epoch(model, test_loader, criterion, device)
# 学习率调度
scheduler.step()
# 记录结果
train_losses.append(train_loss)
train_accuracies.append(train_acc)
val_losses.append(val_loss)
val_accuracies.append(val_acc)
print(f"训练损失: {train_loss:.4f}, 训练准确率: {train_acc:.4f}")
print(f"验证损失: {val_loss:.4f}, 验证准确率: {val_acc:.4f}")
print(f"学习率: {scheduler.get_last_lr()[0]:.6f}")
# 5. 结果可视化
plot_results(train_losses, val_losses, train_accuracies, val_accuracies, val_preds, val_labels)
# 保存模型
torch.save(model.state_dict(), 'transformer_mnist.pth')
print("模型已保存为 'transformer_mnist.pth'")
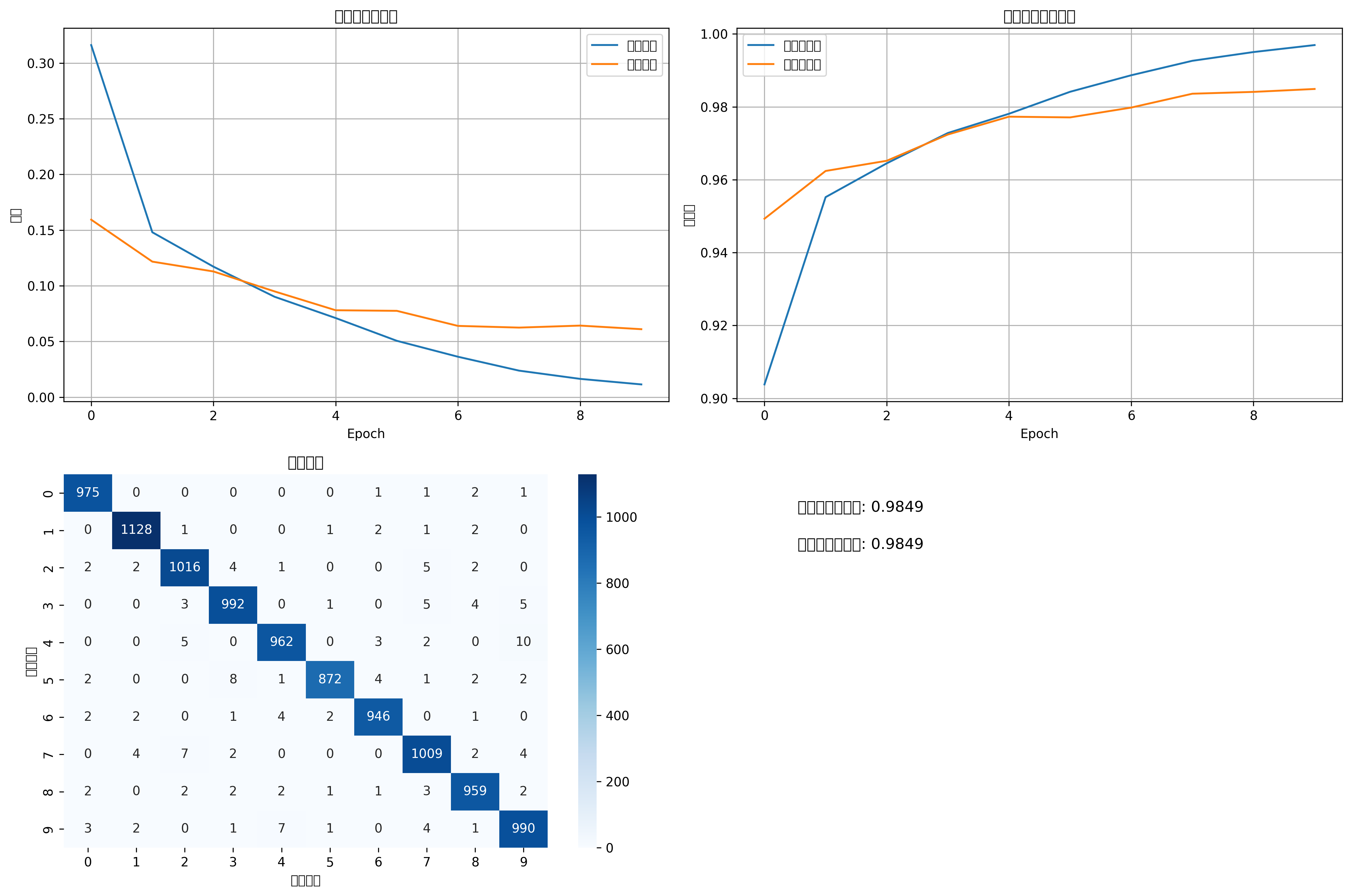
def plot_results(train_losses, val_losses, train_accuracies, val_accuracies, val_preds, val_labels):
"""绘制训练结果"""
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2, figsize=(15, 10))
# 损失曲线
ax1.plot(train_losses, label='训练损失')
ax1.plot(val_losses, label='验证损失')
ax1.set_title('训练和验证损失')
ax1.set_xlabel('Epoch')
ax1.set_ylabel('损失')
ax1.legend()
ax1.grid(True)
# 准确率曲线
ax2.plot(train_accuracies, label='训练准确率')
ax2.plot(val_accuracies, label='验证准确率')
ax2.set_title('训练和验证准确率')
ax2.set_xlabel('Epoch')
ax2.set_ylabel('准确率')
ax2.legend()
ax2.grid(True)
# 混淆矩阵
cm = confusion_matrix(val_labels, val_preds)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', ax=ax3)
ax3.set_title('混淆矩阵')
ax3.set_xlabel('预测标签')
ax3.set_ylabel('真实标签')
# 显示一些预测样本
ax4.axis('off')
ax4.text(0.1, 0.9, f'最终测试准确率: {val_accuracies[-1]:.4f}',
transform=ax4.transAxes, fontsize=12)
ax4.text(0.1, 0.8, f'最佳测试准确率: {max(val_accuracies):.4f}',
transform=ax4.transAxes, fontsize=12)
plt.tight_layout()
plt.savefig('training_results.png', dpi=300, bbox_inches='tight')
plt.show()
# 6. 模型测试和推理
def test_single_image(model_path='transformer_mnist.pth'):
"""测试单张图像"""
# 加载模型
model = TransformerClassifier(
input_dim=784,
d_model=128,
nhead=8,
num_layers=3,
num_classes=10,
dropout=0.1
).to(device)
model.load_state_dict(torch.load(model_path, map_location=device))
model.eval()
# 加载测试集的一张图像
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
test_dataset = datasets.MNIST('./data', train=False, transform=transform)
test_transformer_dataset = MNISTTransformerDataset(test_dataset, flatten=True)
# 随机选择一张图像
idx = np.random.randint(0, len(test_dataset))
image, true_label = test_transformer_dataset[idx]
# 预测
with torch.no_grad():
image = image.unsqueeze(0).to(device) # 添加batch维度
output = model(image)
prediction = output.argmax(dim=1).item()
probabilities = F.softmax(output, dim=1).cpu().numpy()[0]
# 显示结果
original_image = test_dataset[idx][0].squeeze().numpy()
plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plt.imshow(original_image, cmap='gray')
plt.title(f'真实标签: {true_label}, 预测: {prediction}')
plt.axis('off')
plt.subplot(1, 2, 2)
bars = plt.bar(range(10), probabilities, color='skyblue')
bars[prediction].set_color('red')
plt.xlabel('数字')
plt.ylabel('概率')
plt.title('预测概率分布')
plt.xticks(range(10))
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
print(f"真实标签: {true_label}")
print(f"预测结果: {prediction}")
print(f"预测概率: {probabilities[prediction]:.4f}")
if __name__ == "__main__":
# 运行训练
#main()
# 测试单张图像
print("\n测试单张图像...")
test_single_image()上述代码在配置环境之后可以直接执行
requirements.txt
torch==1.10.0
torchvision==0.11.0
torchaudio==0.10.0
numpy==1.24.3
pillow==10.4.0
matplotlib==3.7.5
seaborn==0.13.2
scikit-learn==1.3.2
scipy==1.10.1
pandas==2.0.3
opencv-python==4.12.0.88
tqdm==4.67.1
创建虚拟环境之后,pip上述依赖包,即可运行!
训练结果曲线