在自动驾驶场景下,摄像头 + 激光雷达的传感器融合方案是最常见的感知技术路线,目标是充分利用二者的互补性:
- 摄像头优势:分辨率高、纹理丰富、颜色信息齐全,有利于识别语义信息(车道线、交通灯、行人类别等)。
- 激光雷达优势:天然地具有深度信息,直接测得高精度距离和稠密点云,有利于构建 3D 几何结构和检测障碍物。
融合方式大致分为三类:前融合、中融合、后融合。
1. 前融合
前融合,是指把各个传感器的数据采集后,经过数据同步后,对这些原始数据进行融合,因此也称为数据级融合。将摄像头图像与激光雷达点云在几何空间对齐,例如把 3D LiDAR 点云投影到 2D 图像上, 然后检查点云是否属于 2D 边界框。前融合展示如下图:
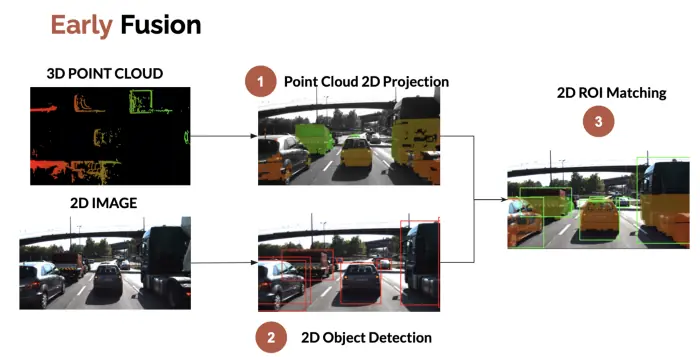
前融合可以从整体上来处理信息,让数据更早做融合,整体处理信息,让数据更有关联性,把激光雷达点云和摄像头像素级数据进行融合,信息损失比较少;但前融合也会存在一些问题,例如:点云数据和像素数据坐标系不同,直接融合效果差;需要处理的数据量大,对算力要求较高;对融合策略要求也比较高,目前业内应用的比较少。
2. 后融合
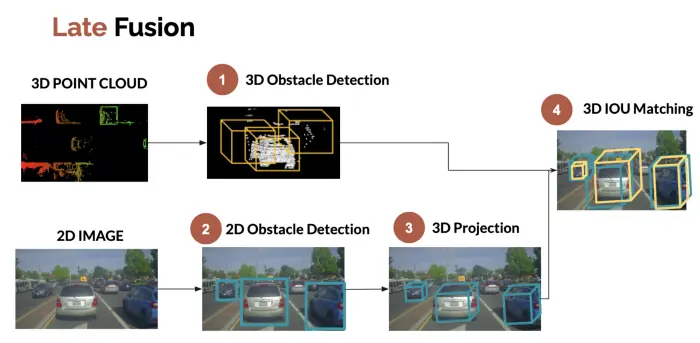
后融合是指摄像头和激光雷达等各传感器独立完成感知任务(如检测、分割),最后在结果层面进行融合(如加权,IOU 匹配等),因此也称之为目标级融合。例如,可以将摄像头的 2D 边界框投影到 3D 边界框,然后将这些边界框与 LiDAR 检测过程中获得的边界框进行融合。
后融合的优点是传感器独立识别,解耦性好,易于扩展。缺点是会损失中间信息影响精度;rule-based 融合规则有局限性,难以充分利用跨模态互补信息。
后融合展示如下图:
3. 中融合
中融合,是指先将各个传感器通过神经网络模型提取中间层特征(即有效特征),再融合有效主要特征,也称为特征级融合,典型的是对有效特征在 BEV 空间进行融合。相比于前融合与后融合,在 BEV 空间进行中融合有如下优点:
- 跨摄像头融合和多模融合更容易实现,因为统一了数据空间,不需要处理规则关联不同传感器的感知结果,算法实现更加简单;
- 可以很容易地融合时序信息,形成 4D 空间,感知网络可以更好地实现一些感知任务,如测速等;
- 可"脑补"出被遮挡区域目标,在 BEV 空间,给予先验知识,对被遮挡的区域进行预测;
- 感知和预测在统一空间(BEV 空间)内完成,可以通过神经网络直接做端到端优化,并行出结果,既可以避免误差累积,也可以减少人工逻辑,让感知网络通过数据驱动的方式自学习,从而更好地实现功能迭代。
目前使用最多的是中融合方案。
BEVFusion
BEVFusion 是典型的中融合方法,将来自相机和 LiDAR 的原始输入编码到同一个 BEV 空间。如下图所示,BEVFusion 主要由相机流、激光雷达流、动态融合模块和检测头组成,分别简单看下
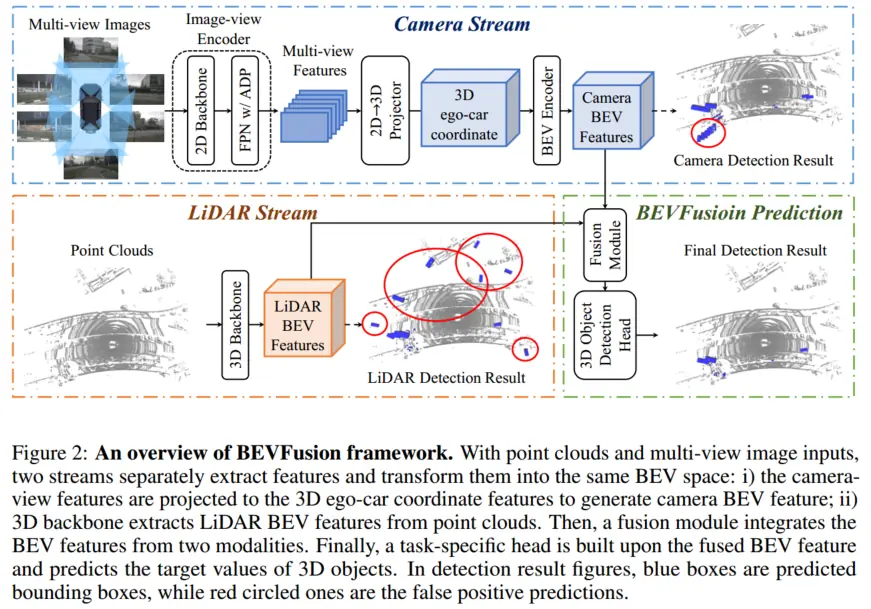
相机流将多视角图像转到 BEV 空间,由图像编码器、视觉投影模块、BEV 编码器组成。
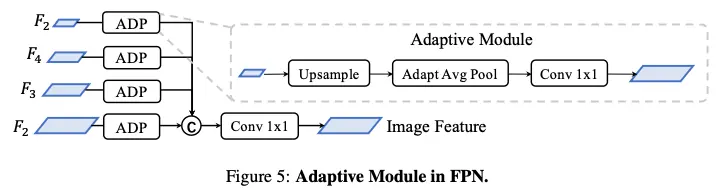
图像编码器旨在将输入图像编码为语义信息丰富的深度特征,它由用于基本特征提取的 2D backbone 和用于多尺度特征提取的 FPN 组成,并采用了一个简单的功能自适应模块 ADP 来完善上采样功能,如下图所示:
视觉投影模块采用 LSS,将图像特征转换到自车坐标系的 3D 表示。该方法以图像视图为输入,通过离散分类的方式密集预测深度;随后结合相机外参与预测深度,生成伪体素表示。
BEV 编码模块采用空间到通道(S2C)操作将 4D 伪体素特征编码到 3D BEV 空间,从而保留语义信息并降低成本。然后使用四个 3 × 3 卷积层缩小通道维度,并提取高级语义信息。
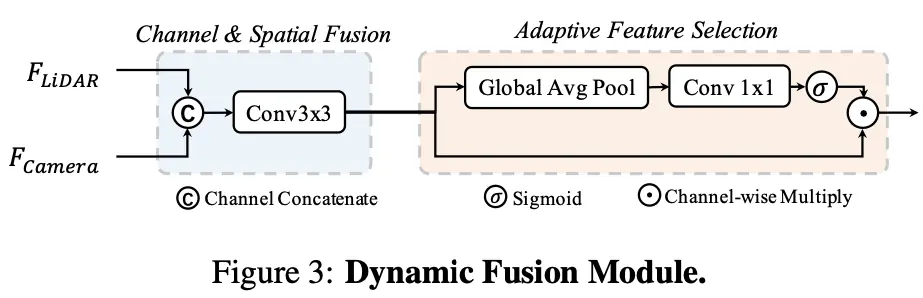
动态融合模块的作用是将 concat 后的 相机、 LiDAR 的 BEV 特 进行有效融合,BEVFusion 应用一个简单的通道注意力模块来选择重要的融合特征,网络结构图如下所示:
LiDAR 流将激光雷达点转换为 BEV 空间,BEVFusion 采用 3 种流行的方法,PointPillars、CenterPoint 和 TransFusion 作为激光雷达流,从而展示模型框架的优秀泛化能力。