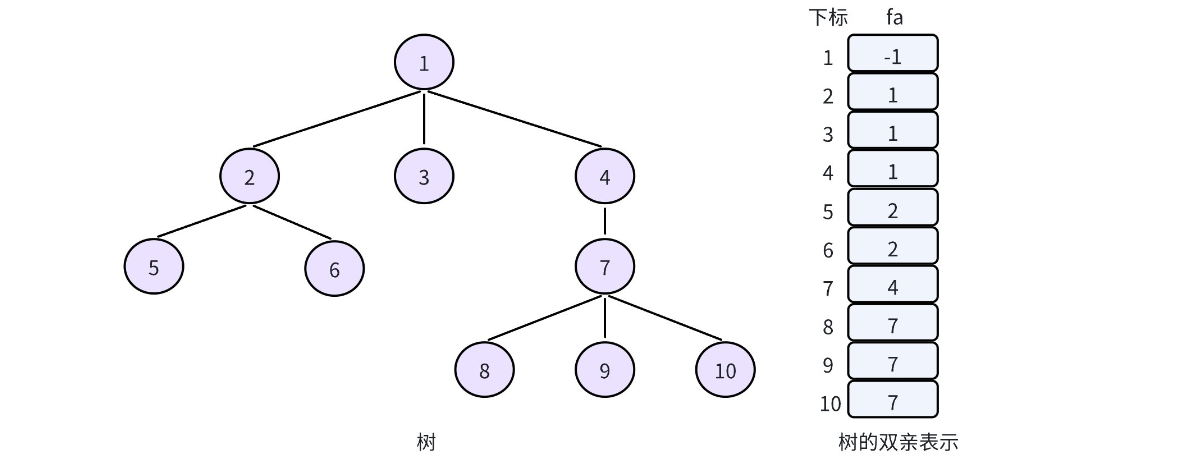
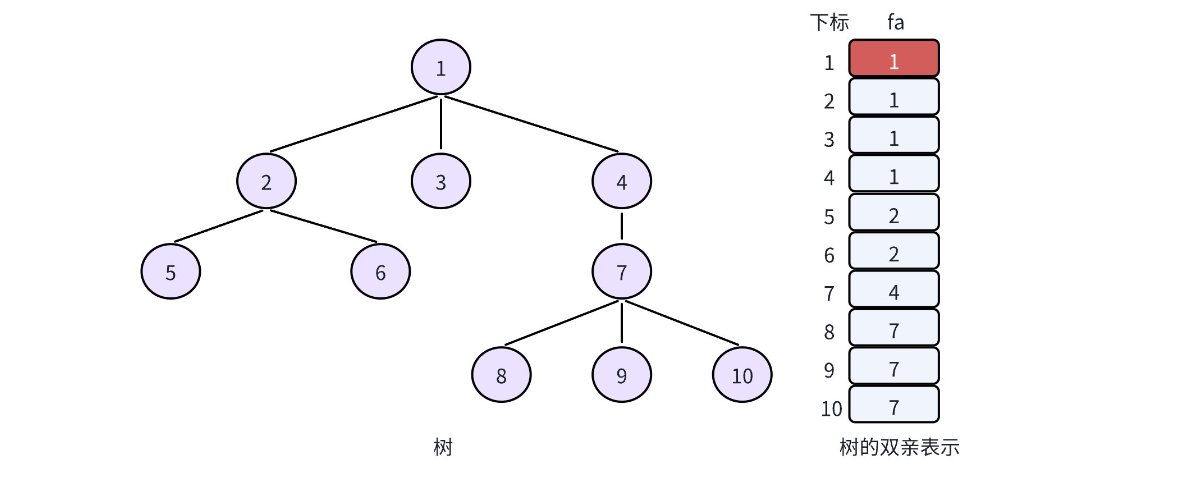
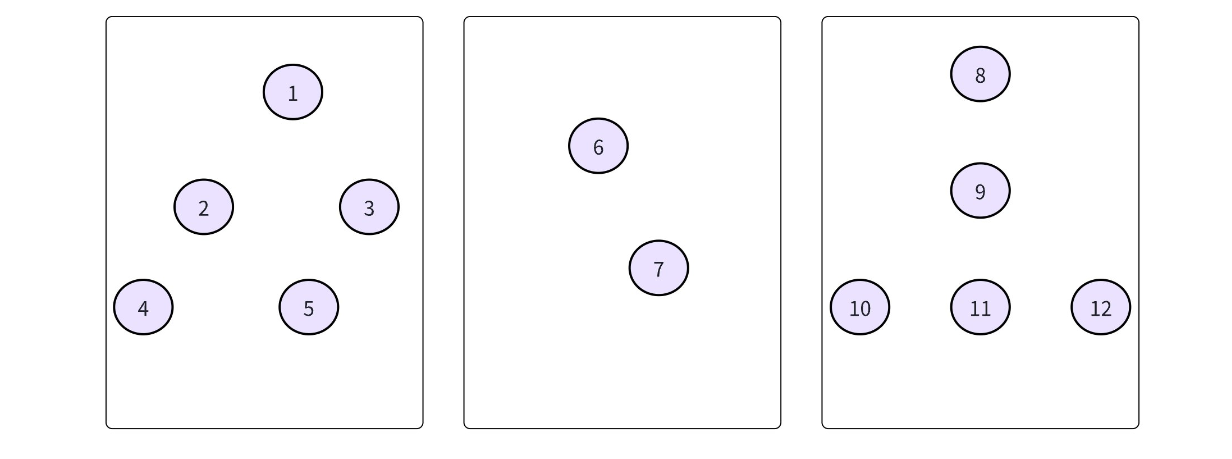
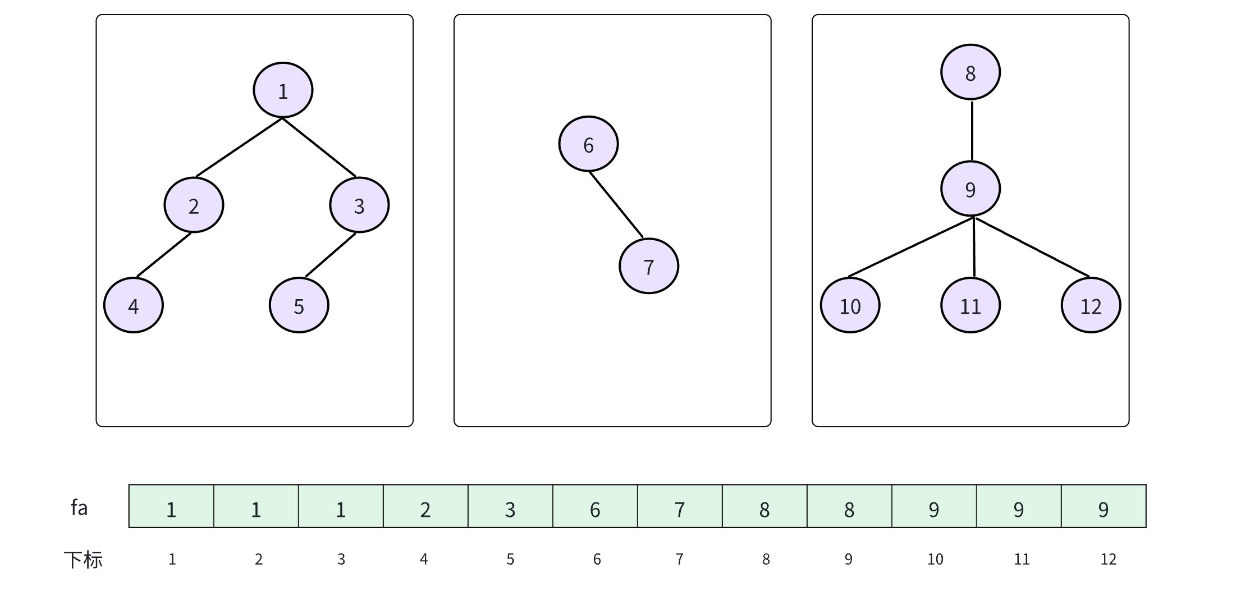
在学习树这个数据结构的时,我们直到树的存储方式有很多种:孩子表示法,双亲表示法、孩子双亲表示法以及孩子兄弟表示法等。对一棵树而言,除了根节点外,其余每个结点一定有且仅有一个双亲,双亲表示法就是根据这个特点存储树的,也就是把每个结点的双亲存下来。因此,我们可以采用数组来存储每个结点的父亲结点的编号,这就实现了双亲表示法 so easy。
由于最近的降雨,水在农夫约翰的田地里积聚了。田地可以表示为一个 N × M N \times M N×M 的矩形( 1 ≤ N ≤ 100 1 \leq N \leq 100 1≤N≤100; 1 ≤ M ≤ 100 1 \leq M \leq 100 1≤M≤100)。每个方格中要么是水(W),要么是干地(.)。农夫约翰想要弄清楚他的田地里形成了多少个水塘。一个水塘是由连通的水方格组成的,其中一个方格被认为与它的八个邻居相邻。给定农夫约翰田地的示意图,确定他有多少个水塘。
【输入格式】
第 1 1 1 行:两个用空格分隔的整数: N N N 和 M M M。
第 2 2 2 行到第 N + 1 N+1 N+1 行:每行 M M M 个字符,表示农夫约翰田地的一行。
考虑一个约束满足问题的简化版本:假设 x 1 , x 2 , x 3 , ⋯ x_1,x_2,x_3,\cdots x1,x2,x3,⋯ 代表程序中出现的变量,给定 n n n 个形如 x i = x j x_i=x_j xi=xj 或 x i ≠ x j x_i\neq x_j xi=xj 的变量相等/不等的约束条件,请判定是否可以分别为每一个变量赋予恰当的值,使得上述所有约束条件同时被满足。例如,一个问题中的约束条件为: x 1 = x 2 , x 2 = x 3 , x 3 = x 4 , x 4 ≠ x 1 x_1=x_2,x_2=x_3,x_3=x_4,x_4\neq x_1 x1=x2,x2=x3,x3=x4,x4=x1,这些约束条件显然是不可能同时被满足的,因此这个问题应判定为不可被满足。
现在给出一些约束满足问题,请分别对它们进行判定。
【输入格式】
输入的第一行包含一个正整数 t t t,表示需要判定的问题个数。注意这些问题之间是相互独立的。
对于每个问题,包含若干行:
第一行包含一个正整数 n n n,表示该问题中需要被满足的约束条件个数。接下来 n n n 行,每行包括三个整数 i , j , e i,j,e i,j,e,描述一个相等/不等的约束条件,相邻整数之间用单个空格隔开。若 e = 1 e=1 e=1,则该约束条件为 x i = x j x_i=x_j xi=xj。若 e = 0 e=0 e=0,则该约束条件为 x i ≠ x j x_i\neq x_j xi=xj。
【输出格式】
输出包括 t t t 行。
输出文件的第 k k k 行输出一个字符串 YES 或者 NO(字母全部大写),YES 表示输入中的第 k k k 个问题判定为可以被满足,NO 表示不可被满足。
【示例一】
输入
复制代码
2
2
1 2 1
1 2 0
2
1 2 1
2 1 1
输出
复制代码
NO
YES
【示例二】
输入
复制代码
2
3
1 2 1
2 3 1
3 1 1
4
1 2 1
2 3 1
3 4 1
1 4 0
输出
复制代码
YES
NO
【说明/提示】
样例解释1
在第一个问题中,约束条件为: x 1 = x 2 , x 1 ≠ x 2 x_1=x_2,x_1\neq x_2 x1=x2,x1=x2。这两个约束条件互相矛盾,因此不可被同时满足。
在第二个问题中,约束条件为: x 1 = x 2 , x 1 = x 2 x_1=x_2,x_1 = x_2 x1=x2,x1=x2。这两个约束条件是等价的,可以被同时满足。
样例说明2
在第一个问题中,约束条件有三个: x 1 = x 2 , x 2 = x 3 , x 3 = x 1 x_1=x_2,x_2= x_3,x_3=x_1 x1=x2,x2=x3,x3=x1。只需赋值使得 x 1 = x 2 = x 3 x_1=x_2=x_3 x1=x2=x3,即可同时满足所有的约束条件。
在第二个问题中,约束条件有四个: x 1 = x 2 , x 2 = x 3 , x 3 = x 4 , x 4 ≠ x 1 x_1=x_2,x_2= x_3,x_3=x_4,x_4\neq x_1 x1=x2,x2=x3,x3=x4,x4=x1。由前三个约束条件可以推出 x 1 = x 2 = x 3 = x 4 x_1=x_2=x_3=x_4 x1=x2=x3=x4,然而最后一个约束条件却要求 x 1 ≠ x 4 x_1\neq x_4 x1=x4,因此不可被满足。
数据范围
所有测试数据的范围和特点如下表所示:
离散化 + 并查集
读完这道题,很明显能想到用并查集来解决,相等条件就是把两个值所在集合合并成一个集合,不等条件就是要判断两个值是否处于一个集合中。由于这道题的 i 和 j 过大,我们没法开 1 0 9 10^9 109 那么大的数组去存储这些数值,但是我们发现数据量 n n n 并不是很大,所以我们可以采用离散化处理之后,再用并查集解决。
另外还有一个细节,在处理约束条件的时候,有可能是相等和不等条件交叉给出的,而我们需要先把所有的相等的信息维护完之后,再来判断不等的条件 ,这样才能判断正确。比如 x 1 = x 2 x_1 = x_2 x1=x2, x 2 ≠ x 3 x_2 \ne x_3 x2=x3, x 3 = x 1 x_3 = x_1 x3=x1,如果从前往后依次判断的话输出 Yes,但是实际上条件矛盾了,我们应该把相等的信息处理完之后,再来判断不等的信息是否与已知的矛盾。那么如何处理这个问题呢?我们可以开一个数组,数组里面存结构体,结构体里面保存 i i i、 j j j、 e e e 的信息即可。
cpp复制代码
// 离散化 + 并查集
#include<iostream>
#include<unordered_map>
#include<algorithm>
using namespace std;
const int N = 1e5 + 10;
struct node{ int x, y, e; } a[N]; // 把每一组的 i, j, e 保存起来
int disc[2 * N]; // 离散化数组
int pa[2 * N]; // 并查集数组
int t, n;
unordered_map<int, int> id; // <原始值, 离散化后的值>
void init(int n)
{
for(int i = 1; i <= n; i++) pa[i] = i;
}
int find(int x)
{
if(pa[x] == x) return x;
return pa[x] = find(pa[x]);
}
void uni(int x, int y)
{
int fx = find(x);
int fy = find(y);
pa[fx] = fy;
}
bool issame(int x, int y)
{
return find(x) == find(y);
}
int main()
{
cin >> t;
while(t--)
{
id.clear(); // 记得清空数据
cin >> n;
int pos = 0;
// 读入数据, 把 i 和 j 存入离散化数组
for(int i = 1; i <= n; i++)
{
cin >> a[i].x >> a[i].y >> a[i].e;
disc[++pos] = a[i].x;
disc[++pos] = a[i].y;
}
// 这里离散化的方式采用:排序 + 哈希表
sort(disc + 1, disc + 1 + pos);
int cnt = 0; // 记录去重后的数据个数
for(int i = 1; i <= pos; i++)
{
int t = disc[i];
if(id.count(t)) continue;
id[t] = ++cnt;
}
init(cnt); // 用离散化后的数据初始化并查集数组
// 把所有相等的信息,用并查集维护起来
for(int i = 1; i <= n; i++)
{
node& nd = a[i];
if(nd.e == 1) uni(id[nd.x], id[nd.y]);
}
// 合并完之后,再把不相等的信息拿出来判断是否合法
int flag = 1;
for(int i = 1; i <= n; i++)
{
node& nd = a[i];
if(nd.e == 0)
{
bool t = issame(id[nd.x], id[nd.y]);
if(t) flag = 0;
}
}
if(flag) cout << "YES" << endl;
else cout << "NO" << endl;
}
return 0;
}