目录
- 一.图的基本概念
-
- 1.图的定义
- 2.图、树、线性表的联系与区别
-
- [2.1 核心联系](#2.1 核心联系)
- [2.2 核心区别](#2.2 核心区别)
- 二.图的分类
-
- 1.按边的方向分类
- 2.按边的权重分类
- [3 .按顶点和边的数量分类](#3 .按顶点和边的数量分类)
- [4 .按连通性分类(针对无向图)](#4 .按连通性分类(针对无向图))
- [5 .按强连通性分类(针对有向图)](#5 .按强连通性分类(针对有向图))
- [6 .其他特殊类型](#6 .其他特殊类型)
- 7.顶点的度(补充)
- 8.路径及相关长度概念(补充)
-
- [8.1 路径](#8.1 路径)
- [8.2 路径长度(无权图)](#8.2 路径长度(无权图))
- [8.3 带权路径长度(带权图)](#8.3 带权路径长度(带权图))
- [8.4 核心区别对比](#8.4 核心区别对比)
- 三.邻接矩阵
- 四.邻接表
- 五.链式前向星
Hello,小伙伴们!又到了咱们一起捣鼓代码的时间啦!💪 把生活调成热情模式,带着满满的能量钻进编程的奇妙世界吧------今天也要写出超酷的代码,冲鸭!🚀

我的博客主页:喜欢吃燃面
我的专栏:《C语言》,《C语言之数据结构》,《C++》,《Linux学习笔记》
感谢你点开这篇博客呀!真心希望这些内容能给你带来实实在在的帮助~ 如果你有任何想法或疑问,非常欢迎一起交流探讨,咱们互相学习、共同进步,在编程路上结伴成长呀!
一.图的基本概念
1.图的定义
图(Graph) 是一种非线性的数据结构,由顶点集合(Vertex) 和边集合(Edge) 组成,用于表示多个对象之间的多对多关系。
其形式化定义为:
一个图 G G G 可以表示为二元组 G = ( V , E ) G=(V, E) G=(V,E)
- V V V 是非空的顶点集合 ,其中的每个元素称为顶点 (或节点),记为 v i v_i vi;
- E E E 是边的集合 ,其中的每个元素称为边 ,记为 e j e_j ej,边用于连接 V V V 中的两个顶点。
2.图、树、线性表的联系与区别
三者都属于数据结构 ,核心是存储数据及数据间的关系,且线性表 ⊂ 树 ⊂ 图 ,是从简单到复杂、从一对一到多对多的关系扩展。
| 特性 | 线性表 | 树 | 图 |
|---|---|---|---|
| 数据关系 | 一对一(除首尾元素,每个元素仅有一个前驱和一个后继) | 一对多(每个节点有且仅有一个父节点,可多个子节点) | 多对多(任意两个顶点间可存在边) |
| 结构约束 | 有明确的先后顺序,是线性结构 | 无环的连通结构,是层次结构 | 可带环、可连通/非连通,无严格约束 |
| 典型代表 | 数组、链表、栈、队列 | 二叉树、红黑树、B树 | 有向图、无向图、带权图(网) |
| 核心特点 | 结构简单,遍历顺序唯一(从头到尾) | 无环,遍历方式多(前/中/后序、层序) | 最灵活,可表示任意复杂关系 |
2.1 核心联系
- 包含关系
- 线性表是最简单的结构,可以看作是特殊的树(树中每个节点只有一个子节点,退化为线性表)。
- 树是特殊的图 :树是无环的连通无向图,且满足 "n个顶点对应n-1条边" 的条件。
- 遍历逻辑相通
三者的遍历都依赖迭代或递归,比如线性表的顺序遍历、树的深度优先遍历、图的深度优先遍历,核心思想都是"按规则访问每个元素一次"。
2.2 核心区别
- 关系复杂度不同
- 线性表:一对一,像排队的人,每个人只和前后的人有关系。
- 树:一对多,像家族族谱,一个父节点可以有多个子节点,但不能反过来。
- 图:多对多,像城市交通网,任意两个城市之间可以有道路,还能有环路。
- 结构约束不同
- 线性表必须是线性的、无分支。
- 树必须无环 ,且只有一个根节点。
- 图可以有环、有多个孤立顶点,没有根节点的概念。
二.图的分类
1.按边的方向分类
1.1 无向图
- 边没有方向,连接顶点 u u u 和 v v v 的边记为 ( u , v ) (u,v) (u,v),且 ( u , v ) = ( v , u ) (u,v) = (v,u) (u,v)=(v,u)。
- 示例:无向社交网络(A和B是朋友等价于B和A是朋友)、双向公路地图。
1.2 有向图
- 边有方向,连接顶点 u u u 到 v v v 的边记为 < u , v > <u,v> <u,v>, u u u 是起点, v v v 是终点,且 < u , v > ≠ < v , u > <u,v> \neq <v,u> <u,v>=<v,u>。
- 示例:有向社交关注(A关注B不等于B关注A)、单行道地图、任务依赖关系。
2.按边的权重分类
2.1 无权图
- 边仅表示顶点间的连接关系,没有附加数值。
- 示例:仅记录"是否相连"的拓扑图。
2.2 带权图(网)
- 每条边都带有一个数值权重(如距离、成本、时间)。
- 示例:带距离的城市交通图、带成本的通信网络。
3 .按顶点和边的数量分类
3.1 稀疏图
- 边数远小于顶点数的平方( E ≪ V 2 E \ll V^2 E≪V2),顶点间连接稀疏。
- 示例:现实中的社交网络、路网。
3.2 稠密图
- 边数接近顶点数的平方( E ≈ V 2 E \approx V^2 E≈V2),顶点间连接紧密。
- 示例:完全图、稠密的通信拓扑。
3.3 完全图
- 无向完全图:任意两个顶点间都有一条边,边数为 V ( V − 1 ) 2 \frac{V(V-1)}{2} 2V(V−1)。
- 有向完全图:任意两个顶点间都有两条方向相反的边,边数为 V ( V − 1 ) V(V-1) V(V−1)。
4 .按连通性分类(针对无向图)
4.1 连通图
- 任意两个顶点之间都存在路径,整个图是一个连通分量。
4.2 非连通图
- 存在至少两个顶点之间没有路径,图包含多个连通分量。
5 .按强连通性分类(针对有向图)
5.1 强连通图
- 任意两个顶点 u u u 和 v v v 之间,既存在 u u u 到 v v v 的路径,也存在 v v v 到 u u u 的路径。
5.2 弱连通图
- 将有向边改为无向边后是连通图,但本身不是强连通图。
5.3 非连通图
- 将有向边改为无向边后仍是非连通图。
6 .其他特殊类型
6.1 无环图
- 不包含环路的图,常见的如 有向无环图(DAG),用于表示任务调度、表达式求值等。
6.2 二分图
- 顶点可分为两个不相交的集合,每条边的两个顶点分别属于不同集合,无同集合内的边。
- 示例:用户-商品的购买关系图。
7.顶点的度(补充)
顶点的度是衡量顶点与其他顶点连接紧密程度的指标,在无向图和有向图中的定义不同。
- 无向图中的度
一个顶点的度 = 与该顶点相连的边的数量 ,记为 d ( v ) d(v) d(v)。- 示例:无向图中顶点 A A A 连接了 3 条边,则 d ( A ) = 3 d(A)=3 d(A)=3。
- 性质:无向图所有顶点的度之和 = 2 × 2 \times 2× 边数(每条边贡献 2 个度)。
- 有向图中的度
有向图的度分为入度 和出度 ,两者之和为顶点的总度 。- 入度 ( d i n ( v ) d_{in}(v) din(v)):以该顶点为终点的有向边数量。
- 出度 ( d o u t ( v ) d_{out}(v) dout(v)):以该顶点为起点的有向边数量。
- 性质:有向图所有顶点的入度之和 = 所有顶点的出度之和 = 边数。
8.路径及相关长度概念(补充)
8.1 路径
路径是图中从一个顶点到另一个顶点的顶点序列,核心定义与属性如下:
- 定义
给定图 G = ( V , E ) G=(V,E) G=(V,E),从顶点 v 0 v_0 v0 到 v k v_k vk 的路径是一个顶点序列 v 0 , v 1 , v 2 , . . . , v k v_0,v_1,v_2,...,v_k v0,v1,v2,...,vk,满足任意相邻两个顶点 v i − 1 v_{i-1} vi−1 和 v i v_i vi 之间都有边相连。 - 关键属性
- 路径长度 :路径中包含的边的数量。
- 简单路径 :路径中所有顶点不重复出现(无环路)。
- 回路(环) :起点和终点为同一个顶点 的路径;若除起点终点外其他顶点不重复,则称为简单回路。
- 示例
- 无向图中顶点序列 A → B → C A \to B \to C A→B→C 是一条简单路径,长度为 2。
- 序列 A → B → C → A A \to B \to C \to A A→B→C→A 是一条简单回路,长度为 3。
8.2 路径长度(无权图)
- 定义 :在无权图 中,路径长度指路径中包含的边的数量,与边的权重无关。
- 计算公式 :若路径顶点序列为 v 0 → v 1 → v 2 → ⋯ → v k v_0 \to v_1 \to v_2 \to \dots \to v_k v0→v1→v2→⋯→vk,则路径长度 = k k k。
- 示例 :无向图中路径 A → B → C A \to B \to C A→B→C 包含 2 条边,路径长度为 2 ;回路 A → B → C → A A \to B \to C \to A A→B→C→A 包含 3 条边,路径长度为 3。
8.3 带权路径长度(带权图)
- 定义 :在带权图(网)中,带权路径长度指路径中所有边的权重之和,是带权图的核心指标。
- 计算公式 :若路径顶点序列为 v 0 → v 1 → v 2 → ⋯ → v k v_0 \to v_1 \to v_2 \to \dots \to v_k v0→v1→v2→⋯→vk,每条边的权重为 w ( v i − 1 , v i ) w(v_{i-1},v_i) w(vi−1,vi),则带权路径长度 = ∑ i = 1 k w ( v i − 1 , v i ) \sum_{i=1}^k w(v_{i-1},v_i) ∑i=1kw(vi−1,vi)。
- 示例 :带权图中路径 A → B → C A \to B \to C A→B→C 的边权重分别为 w ( A , B ) = 3 w(A,B)=3 w(A,B)=3、 w ( B , C ) = 5 w(B,C)=5 w(B,C)=5,则带权路径长度 = 3 + 5 = 8 3+5=8 3+5=8。
8.4 核心区别对比
| 特性 | 路径长度 | 带权路径长度 |
|---|---|---|
| 适用图类型 | 无权图 | 带权图(网) |
| 计算依据 | 边的数量 | 边的权重之和 |
| 典型应用 | 路径步数统计 | 最短路径算法(如 Dijkstra 算法) |
三.邻接矩阵
1.邻接矩阵
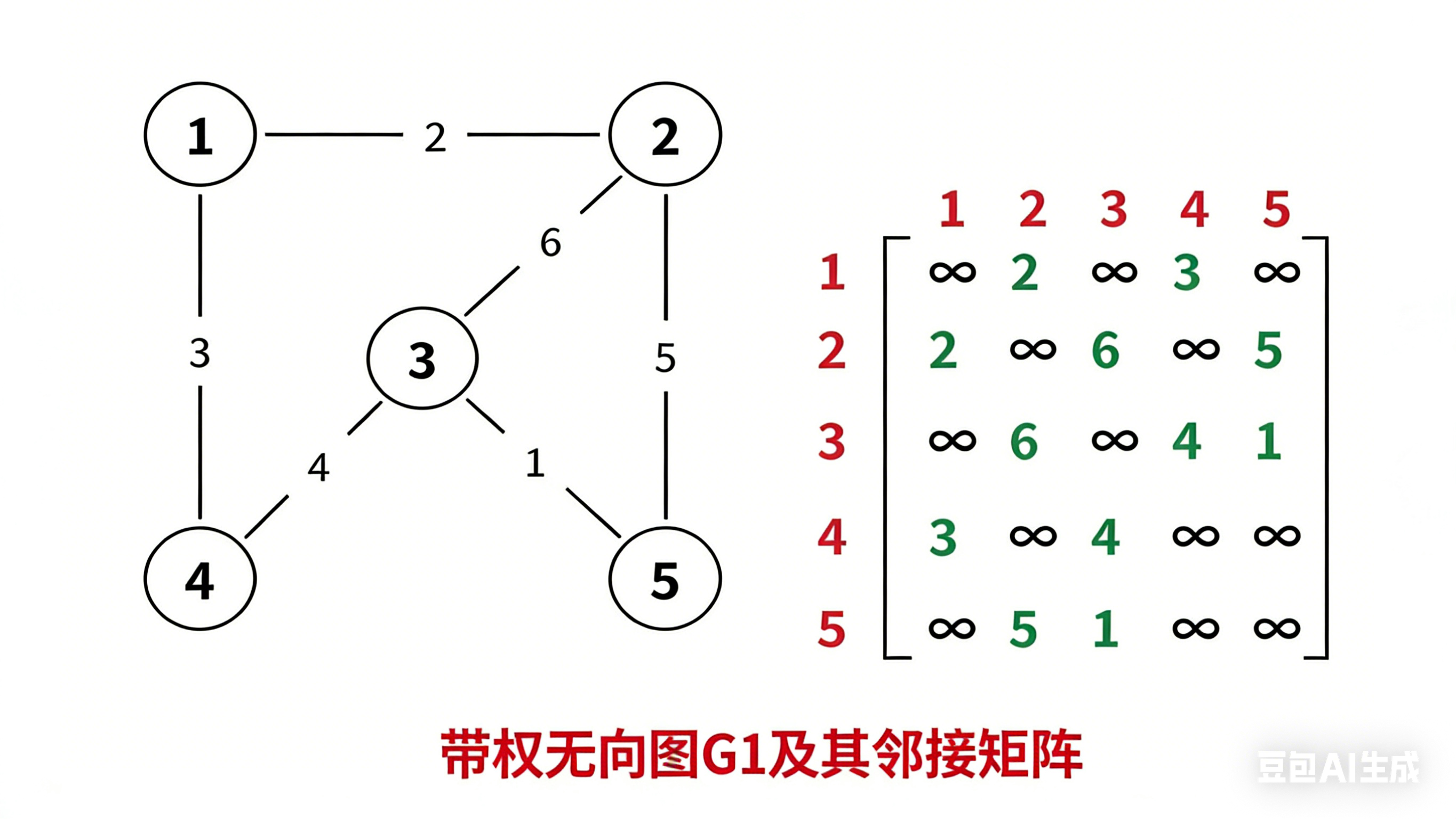
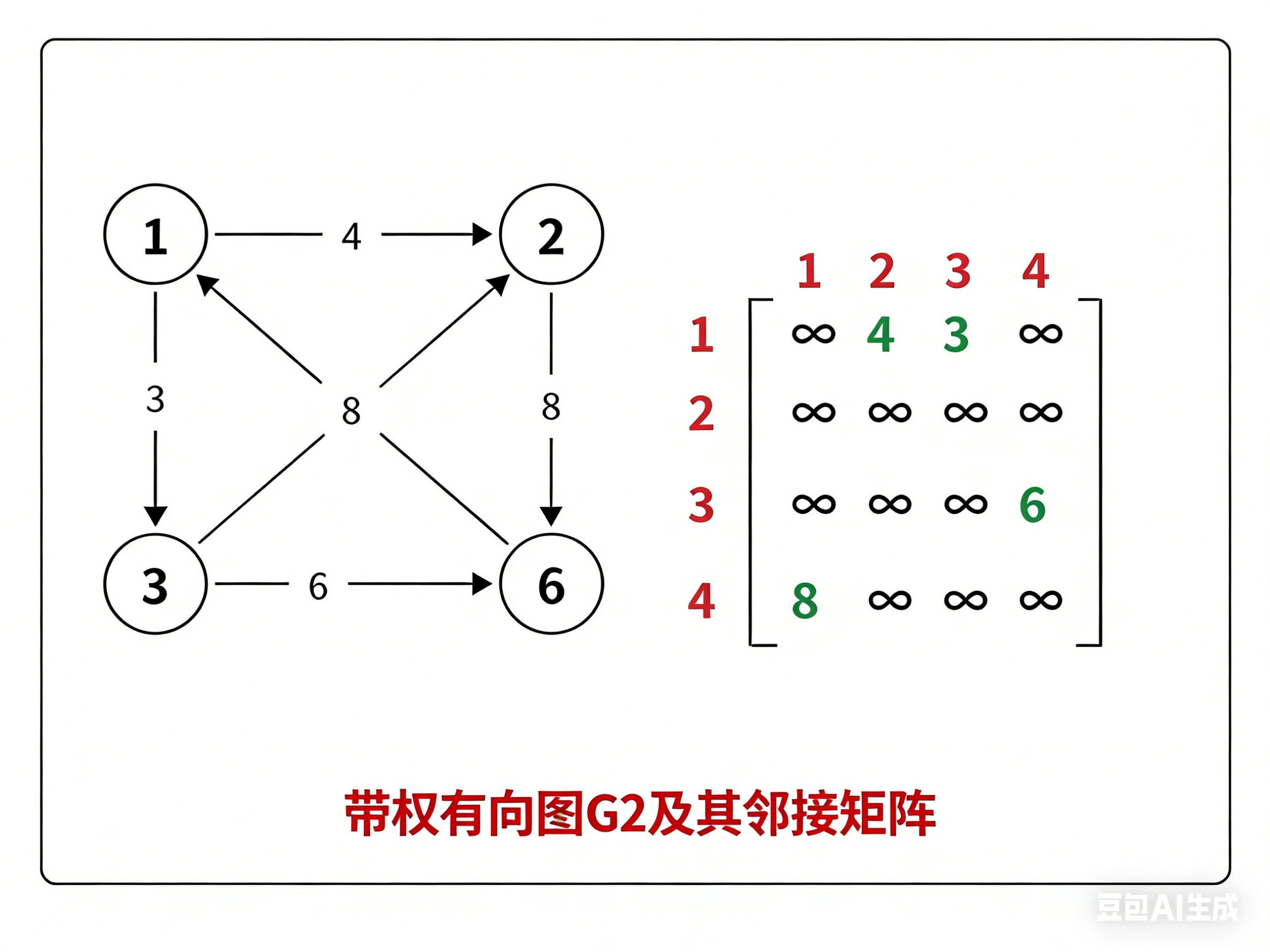
邻接矩阵,指用一个矩阵(即二维数组)存储图中边的信息(即各个顶点之间的邻接关系),存储顶点之间邻接关系的矩阵称为邻接矩阵。
对于带权图而言,若顶点 v i v_i vi 和 v j v_j vj 之间有边相连,则邻接矩阵中对应项存放着该边对应的权值,若顶点 v i v_i vi 和 v j v_j vj 不相连,则用 ∞ \infty ∞ 来代表这两个顶点之间不存在边。
对于不带权的图,可以创建一个二维的 bool 类型的数组,来标记顶点 v i v_i vi 和 v j v_j vj 之间有边相连。
【注意】
矩阵中元素个数为 n 2 n^2 n2,即空间复杂度为 O ( n 2 ) O(n^2) O(n2), n n n 为顶点个数,和实际边的条数无关,适合存储稠密图。
cpp
#include<iostream>
#include<cstring>
#include<queue>
using namespace std;
const int N = 110;
// 邻接矩阵存储定义
int edges[N][N]; // edges[a][b]表示a到b的边权(-1表示无边)
int n, m; // n:顶点数,m:边数
bool st[N]; // 访问标记数组
// 邻接矩阵版DFS
void dfs_matrix(int u)
{
cout << u << endl;
st[u] = true;
// 遍历所有邻接顶点(1~n)
for (int v = 1; v <= n; v++)
{
if (edges[u][v] != -1 && !st[v])
dfs_matrix(v);
}
}
// 邻接矩阵版BFS
void bfs_matrix(int u)
{
queue<int> q;
q.push(u);
st[u] = true;
while (q.size())
{
auto a = q.front();
q.pop();
cout << a << endl;
// 遍历所有邻接顶点(1~n)
for (int b = 1; b <= n; b++)
{
if (edges[a][b] != -1 && !st[b])
{
q.push(b);
st[b] = true;
}
}
}
}
// 邻接矩阵初始化
int main()
{
memset(edges, -1, sizeof(edges)); // 初始化:-1表示无边
cin >> n >> m;
// 输入边数据
for (int i = 1; i <= m; i++)
{
int a, b, value;
cin >> a >> b >> value;
edges[a][b] = value;
// 无向图需添加:edges[b][a] = value;
}
// 测试遍历
cout << "邻接矩阵DFS结果:" << endl;
dfs_matrix(1);
memset(st, false, sizeof(st)); // 重置标记
cout << "\n邻接矩阵BFS结果:" << endl;
bfs_matrix(1);
return 0;
}四.邻接表
不懂邻接表和链式前向星请查看:算法竞赛中的树
cpp
#include<iostream>
#include<cstring>
#include<vector>
#include<queue>
using namespace std;
const int N = 110;
// 邻接表存储定义
typedef pair<int, int> PII; // <邻接顶点, 边权>
vector<PII> edges_list[N]; // edges_list[a]存储a的所有邻接边
int n, m;
bool st[N];
// 邻接表版DFS
void dfs_list(int u)
{
cout << u << endl;
st[u] = true;
// 遍历u的所有邻接边
for (auto &e : edges_list[u])
{
int v = e.first;
if (!st[v])
dfs_list(v);
}
}
// 邻接表版BFS
void bfs_list(int u)
{
queue<int> q;
q.push(u);
st[u] = true;
while (q.size())
{
auto a = q.front();
q.pop();
cout << a << endl;
// 遍历a的所有邻接边
for (auto &e : edges_list[a])
{
int b = e.first;
if (!st[b])
{
q.push(b);
st[b] = true;
}
}
}
}
// 邻接表初始化
int main()
{
cin >> n >> m;
// 输入边数据
for (int i = 1; i <= m; i++)
{
int a, b, value;
cin >> a >> b >> value;
edges_list[a].push_back({b, value});
// 无向图需添加:edges_list[b].push_back({a, value});
}
// 测试遍历
cout << "邻接表DFS结果:" << endl;
dfs_list(1);
memset(st, false, sizeof(st));
cout << "\n邻接表BFS结果:" << endl;
bfs_list(1);
return 0;
}五.链式前向星
cpp
#include<iostream>
#include<cstring>
#include<queue>
using namespace std;
const int N = 110;
// 链式前向星存储定义
int h[N]; // h[a]:a的第一条边的编号
int e[N * 2]; // e[id]:编号id的边的终点
int ne[N * 2]; // ne[id]:编号id的边的下一条边
int w[N * 2]; // w[id]:编号id的边的权值
int id; // 边的自增编号
int n, m;
bool st[N];
// 链式前向星添加边
void add(int a, int b, int value = 0)
{
e[++id] = b;
w[id] = value;
ne[id] = h[a];
h[a] = id;
}
// 链式前向星版DFS
void dfs_star(int u)
{
cout << u << endl;
st[u] = true;
// 遍历u的所有边
for (int i = h[u]; i; i = ne[i])
{
int v = e[i];
if (!st[v])
dfs_star(v);
}
}
// 链式前向星版BFS
void bfs_star(int u)
{
queue<int> q;
q.push(u);
st[u] = true;
while (q.size())
{
auto a = q.front();
q.pop();
cout << a << endl;
// 遍历a的所有边
for (int i = h[a]; i; i = ne[i])
{
int b = e[i];
if (!st[b])
{
q.push(b);
st[b] = true;
}
}
}
}
// 链式前向星初始化
int main()
{
memset(h, 0, sizeof(h)); // 初始化头节点数组为0
cin >> n >> m;
// 输入边数据
for (int i = 1; i <= m; i++)
{
int a, b, value;
cin >> a >> b >> value;
add(a, b, value);
// 无向图需添加:add(b, a, value);
}
// 测试遍历
cout << "链式前向星DFS结果:" << endl;
dfs_star(1);
memset(st, false, sizeof(st));
cout << "\n链式前向星BFS结果:" << endl;
bfs_star(1);
return 0;
}