准备
- 下载 tar.gz
- 解压
- 配置 jdk
shell
vim .bash_profile
export ES_JAVA_HOME=/home/fox/elasticsearh-8.14.3/jdk
export ES_HOME=/xxx
source .bash_profile- 配置 ES 和 JVM 大小
shell
vi elasticsearch.yaml
# 开启远程支持
network.host: 0.0.0.0
# d安节点,跳过引导检查
discovery.type: single-node
# 关闭安全认证
xpack.security.enabled: false
vi config/jvm.options
# 调整堆内存大小
-Xms4g
-Xmx4g- 启动 ES
shell
./bin/elasticsearch -d- 安装 ES 浏览器插件
- Elasticsearch Head
- Elasticsearch Tools
- Elasticvue
使用
索引
shell
{
"analyzer":"ik_max_word",
"text":"道学先生凯迪拉克卷发;的激发了时代峰峻是大连房价阿杜里斯;反抗精神独立开发建设独立开发建设的拉开副驾驶的六块腹肌"
}
POST + /index/_mapping
{
"properties":{
"content":{
"type":"text",
"analyzer":"ik_max_word",
"search_analyzer": "ik_smart"
}
}
}| 插入文档 | POST | /my_index/_create/1 | curl -XPOST xxxx:9200/index/_create/1 -H "Content-Type:application/json" -d'{"content":"xxxxxxx"}' |
|---|---|---|---|
| 插入索引 | PUT | /my_index | |
| 插入文档 | POST | /my_index/_doc | plain POST /my-index/_doc { "id": "park_rocky-mountain", "title": "Rocky Mountain", "description": "Bisected north to south by the Continental Divide, this portion of the Rockies has ecosystems varying from over 150 riparian lakes to montane and subalpine forests to treeless alpine tundra." } |
| 根据索引搜索文档 | GET | /my_index/_search?q="rocky mountain" | shell GET /my-index/_search?q="rocky mountain" { "query": {"match":{"content":"xx"}}, "highlight":{ "pre_tags": ["<tag1">,"<tag2>"], "post_tags":["</tag1>","</tag2>"], "fileds":{"content":{}} } } |
kibana
- 下载解压 tar.gz
- 配置
shell
vim config/kibana.yml
# 端口号
serer.port: 5601
# 主机地址,默认监听本地网卡
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://localhost:9200"]
# 默认英文en。改成zh-CN中文
i18n.locale: "zh-CN"- 启动
shell
nohup bin/kibana &
tail -f nohup.out- 在集成工具写代码
| 创建索引 查看索引 删除索引 修改索引(settings/mapping/aliases) | PUT GET DELETE PUT | /my_index /student_index /student_index /student_index/{_settings/_mapping} | shell PUT /student_index { "settings": { "number_of_replicas": 1, "number_of_shards": 1 }, "mappings": { "properties": { "name":{ "type": "text" }, "age":{ "type": "integer" }, "enrolled_date":{ "type": "date" } } } } #修改索引 PUT /student_index/_settings { "index":{ "number_of_replicas":"2" } } PUT /student_index/_mapping { "properties":{ "grade":{ "type":"text" } } } #别名,可以直接通过别名访问 PUT /myindex { "aliases":{ "teacher_index":{} }, "settings": { "refresh_interval": "30s", "number_of_replicas": 0 , "number_of_shards": 1 } } |
|---|---|---|---|
| 修改索引 创建 mapping 修改 settings | POST | /my_index/_mapping /student_index/_settings | plain POST /index/_mapping { "properties":{ "content":{ "type":"text", "analyzer":"ik_max_word", "search_analyzer":"ik_smart" } } } |
| 插入文档 | POST (无需指定 ID) PUT(需要指定 ID) | /index/_doc /index/_create/1 /index/_doc/1 | plain POST /index/_create/1 {"content":"原神,你玩原神吗,这是米哈游的游戏"} POST /index/_create/2 {"content":"崩坏~星穹铁道,也是老米的"} POST /index/_create/3 {"content":"还有绝区零呢,也是米桑的"} POST /index/_create/4 {"content":"最近有一个星罗布谷,米哈游的"} |
| 查找所有文档 | GET | /my_index/_search | GET /index/_search shell GET /index/_search { "query": { "match_all": {} } } |
| 根据文档条件查找 | GET | /my_index/_search {"query":{ "match":{"content":"xxx"}}} | plain GET /index/_search { "query":{ "match":{ "content":"米" } } } |
| 添加索引 | POST | shell POST /_aliases { "actions":[ {"add":{ "index":"myindex", "alias":"teacher_all_index" }}] } |
别名
可以通过设置别名进行快速查找多个索引的数据,相当于物理索引的软链接,一个别名可以链接多个物理
shell
GET /teacher_index
# 添加别名
POST /_aliases
{
"actions":[
{"add":{
"index":"myindex",
"alias":"teacher_all_index"
}}]
}
GET teacher_all_index
# 不使用别名:使用逗号分割、多个索引合起来查询
POST xxx,ttt,yyy,zzz/_search
# 不使用别名:使用通配符进行检索
POST xxx_*./_search
POST aaa*/_search
# 使用别名:别名关联已有索引
PUT xxx
PUT test1
PUT yyy
POST _aliases
{
"actions": [
{
"add":{
"index":"xxx",
"alias":"tlmall_logs_2025"
}},
{
"add": {
"index": "test1",
"alias": "tlmall_logs_2025"
}
},
{
"add":{
"index":"yyy",
"alias":"tlmall_logs_2025"
}
}
]
}
# 使用别名:使用别名进行检索
GET tlmall_logs_2025
POST tlmall_logs_2025/_search文档
增加
shell
# 文档操作(增删改查 + 实践)
# POST增加,自动生成唯一ID,有幂等性问题
POST /xxx/_doc
{
"hello":"world",
"bye":"text"
}
POST /yyy/_doc
{
"word":"abc",
"key":"op"
}
# PUT增加,需要指定ID,ID不存在久新建,存在就替换
PUT /xxx/_doc/1
{
"hello":"world"
}
PUT /yyy/_doc/1
{
"word":"efg"
}
# 批量操作:index批量创建文档/替换文档,update:更新现有文档,delete:删除指定文档,create创建文档,已存在报错
POST /_bulk
{"index":{"_index":"xxx","_id":"4"}}
{"原神":"启动","mi崩铁":"启动"}
{"index":{"_index":"yyy","_id":"4"}}
{"原神":"启动","mi崩铁":"启动"}
{"index":{"_index":"test1","_id":"4"}}
{"原神":"启动","mi崩铁":"启动"}更新
PUT更新整个文档内容,POST可以通过_update更新文档中的特定字段,不替换整个文档
shell
POST /employee/_update/2
{
"doc":{
"age":25
}
}查找
shell
GET /xxx/_doc/1文档实战
shell
# 实战
# 1.创建索引并设置settings和mappings
PUT /employee
{
"settings":
{
"number_of_replicas":1,
"number_of_shards": 1
},
"mappings": {
"properties": {
"name":{
"type": "keyword"
},
"sex":{
"type":"integer"
},
"age":{
"type": "integer"
},
"address":{
"type":"text",
"analyzer": "ik_max_word",
"fields":{
"keyword":{
"type":"keyword"
}
}
},
"remark":{
"type":"text",
"analyzer": "ik_smart",
"fields":{
"keyword":{
"type":"keyword"
}
}
}
}
}
}
# 2.批量导入数据
POST /_bulk
{"index":{"_index":"employee","_id":1}}
{"name":"琴","sex":2,"age":24,"address":"蒙德地区","remark":"蒙德西风骑士团代理团长"}
{"index":{"_index":"employee","_id":2}}
{"name":"迪卢克","sex":1,"age":22,"address":"蒙德地区","remark":"晨曦酒庄主人"}
{"index":{"_index":"employee","_id":3}}
{"name":"可莉","sex":2,"age":10,"address":"蒙德地区","remark":"西风骑士团火花骑士"}
{"index":{"_index":"employee","_id":4}}
{"name":"钟离","sex":1,"age":10000,"address":"璃月地区","remark":"往生堂客卿"}
{"index":{"_index":"employee","_id":5}}
{"name":"甘雨","sex":2,"age":200,"address":"璃月地区","remark":"月海亭秘书"}
{"index":{"_index":"employee","_id":6}}
{"name":"胡桃","sex":2,"age":19,"address":"璃月地区","remark":"往生堂堂主"}
{"index":{"_index":"employee","_id":7}}
{"name":"雷电将军","sex":2,"age":1000,"address":"稻妻地区","remark":"稻妻幕府将军"}
{"index":{"_index":"employee","_id":8}}
{"name":"神里绫华","sex":2,"age":17,"address":"稻妻地区","remark":"神里家大小姐"}
{"index":{"_index":"employee","_id":9}}
{"name":"八重神子","sex":2,"age":500,"address":"稻妻地区","remark":"鸣神大社宫司"}
{"index":{"_index":"employee","_id":10}}
{"name":"纳西妲","sex":2,"age":500,"address":"须弥地区","remark":"须弥小吉祥草王"}
# 3.查询文档
GET /employee/_search
GET /employee/_doc/1
# 批量id查找
GET /employee/_mget
{
"ids":[1,2,3,4,"5"]
}
# 文本字段匹配
GET /employee/_search
{
"query":{
"match": {
"address":"蒙"
}
}
}
# 查看分词效果
POST _analyze
{
"analyzer": "ik_max_word",
"text":"蒙德地区"
}
# 精准匹配
GET /employee/_search
{
"query":{
"term":{
"address":"地区"
}
}
}
# 范围匹配gte:greater/lte:little
GET /employee/_search
{
"query":{
"range":{
"age":{
"gte":18,
"lte":30
}
}
}
}
# 查找所有
GET /employee/_search
{
"query":{
"match_all": {}
}
}
# 4. 删除文档
DELETE /employee/_doc/1
GET /employee/_doc/1
# 批量删除文档
POST _bulk
{"delete":{"_index":"employee","_id":3}}
{"delete":{"_index":"employee","_id":4}}
{"delete":{"_index":"employee","_id":5}}
POST /employee/_bulk
{"delete":{"_id":6}}
{"delete":{"_id":7}}
{"delete":{"_id":8}}
GET /employee/_doc/7
# 5. 更新文档 POST+_update是更新,不然就是替换,PUT为替换
POST /employee/_update/2
{
"doc":{
"age":25
}
}
# 批量更新
POST /employee/_bulk
{"update":{"_id":1}}
{"doc":{"sex":0}}
{"update":{"_id":2}}
{"doc":{"sex":1}}
{"update":{"_id":3}}
{"doc":{"sex":0}}
{"update":{"_id":4}}
{"doc":{"sex":1}}
{"update":{"_id":5}}
{"doc":{"sex":0}}
{"update":{"_id":6}}
{"doc":{"sex":0}}
{"update":{"_id":7}}
{"doc":{"sex":0}}
{"update":{"_id":8}}
{"doc":{"sex":0}}
{"update":{"_id":9}}
{"doc":{"sex":0}}
{"update":{"_id":10}}
{"doc":{"sex":0}}
# 查找并更新
GET /employee/_search
{"query":{
"match_all":{}
}
}
}
POST /employee/_update_by_query
{
"query":{
"match_all":{}
},
"script": {
"source": "ctx._source.remark=ctx._source.address+'-'+ctx._source.remark",
"lang": "painless"
}
}
# 更新保证线程安全:使用if_seq_no和if_primary_term进行判断
# 版本_seq_no,根据版本来同一时间一个用户进行更改-乐观锁
GET /employee/_doc/1
POST /employee/_doc/1?if_seq_no=167&if_primary_term=1
{
"name":"琴1"
}
POST /employee/_doc/1?if_seq_no=167&if_primary_term=1
{
"name":"琴2"
}文档建模实践
shell
# 创建索引
PUT /product_info
{
"settings": {
"number_of_replicas": 1,
"number_of_shards": 1
},
"mappings": {
"properties": {
"productName":{
"type":"text",
"analyzer": "ik_smart"
},
"annual_rate":{
"type":"keyword"
},
"describe":{
"type":"text",
"analyzer": "ik_smart"
}
}
}
}
# 导入数据
POST /_bulk
{"index":{"_index":"product_info","_id":1}}
{"productName":"蒙德苹果派","annual_rate":"25摩拉","describe":"用新鲜苹果和酥脆面皮制成,香甜而不腻,是蒙德城居民的经典甜点。"}
{"index":{"_index":"product_info","_id":2}}
{"productName":"璃月蜜酱叉烧","annual_rate":"50摩拉","describe":"选用肥瘦相间的猪肉,配上甜蜜蜜的酱汁慢烤,入口香而不油。"}
{"index":{"_index":"product_info","_id":3}}
{"productName":"稻妻海鳗寿司","annual_rate":"60摩拉","describe":"新鲜海鳗经过炙烧,配上醋饭与紫菜卷制而成,口感柔软,伴有海香。"}
{"index":{"_index":"product_info","_id":4}}
{"productName":"璃月清心豆腐汤","annual_rate":"40摩拉","describe":"豆腐与清心花同煮,汤色清澈、香气清雅,据说有助于宁神。"}
{"index":{"_index":"product_info","_id":5}}
{"productName":"蒙德南瓜浓汤","annual_rate":"35摩拉","describe":"香甜的南瓜与奶油调和成细腻汤汁,在寒冷的日子里格外受欢迎。"}
{"index":{"_index":"product_info","_id":6}}
{"productName":"须弥香料炖肉","annual_rate":"70摩拉","describe":"加了多种香料的炖肉,层次丰富的味道让人食欲大增。"}
{"index":{"_index":"product_info","_id":7}}
{"productName":"稻妻红豆团子","annual_rate":"20摩拉","describe":"细腻红豆包裹在糯米团内,外形小巧,甜而不腻。"}
{"index":{"_index":"product_info","_id":8}}
{"productName":"璃月脆皮鱼","annual_rate":"55摩拉","describe":"鲜鱼裹上薄面糊炸至金黄,脆香外皮与鲜嫩鱼肉融合。"}
{"index":{"_index":"product_info","_id":9}}
{"productName":"蒙德蜂蜜烤鸡翅","annual_rate":"45摩拉","describe":"烤鸡翅表面涂抹蜂蜜与香草汁,香气四溢。"}
{"index":{"_index":"product_info","_id":10}}
{"productName":"须弥花果沙拉","annual_rate":"30摩拉","describe":"混合多种热带水果与花瓣的清爽沙拉,伴有淡淡的花香。"}
# 全文检索
GET /product_info/_search
{
"query": {
"match": {
"productName": "璃月蒙德沙拉"
}
}
}
GET /product_info/_search
{
"query": {
"range": {
"annual_rate": {
"gte": "10",
"lte": "50"
}
}
}
}

限制创建字段
shell
# 严格限制mapping:dynamic:strict
PUT /user
{
"mappings":{
"dynamic":"strict",
"properties":{
"name":{"type":"text"},
"address":{"type":"object","dynamic":"true"}
}
}
}
# 避免空值:空值变0:null_value:0
# aggs取平均值:aggs-avg-avg
全文/精准匹配
match_all匹配所有文档、精确匹配、全文检索、组合查询、highlight高亮显示、地理空间位置查询、ES8向量检索
全文匹配 :match_all
精准匹配:term/terms/range + exists/ids/prefix/wildcard/fuzzy/regexp/term set
全文检索: match分词查询\multi_match多字段查询\match_phrase短语查询\query_string与或非表达式查询\simple_query_string
全文检索需要分析,进行匹配:适用于评论、文章等非结构化文本数据
组合查询:布尔查询,按照布尔条件:按照max_score:搜索上下文must/should,filter:过滤上下文无需算分filter/must_not
term一般在filter过滤上下文
must:and算分,should:or多个条件算分,filter不算分,must_not不算分
shell
# 搜索:match_all匹配所有文档、**精确匹配、全文检索、组合查询**、highlight高亮显示、地理空间位置查询、ES8向量检索
# 相当于match_all
GET /blog/_search
# 可以设置size,进行分页
GET /blog/_search
{
"query": {
"match_all": {}
},
"size":3
}
# 数据大的话会超过1万进行拆除
GET /blog/_search
{
"query": {
"match_all": {}
},
"from":3,
"size":3
}
# 可以结合sort排序 sort:[{"":desc/asc}]
# _source返回指定字段
GET /blog/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"time": "asc"
}
],
"from":2,
"size":5,
"_source":["time","content"]
}
GET /employee/_search
# 精确匹配:term/terms/range + exists/ids/prefix/wildcard/fuzzy/regexp/term set
# term单字段
# 可以多值(数组)匹配
# # "address":{
# "type":"text",
# "analyzer": "ik_max_word",
# "fields":{
# "keyword":{
# "type":"keyword"
# }
# }
# },
GET /employee/_search
{
"query":{
"term":{
"address.keyword":{
"value":"蒙德地区"
}
}
},
"size":2
}
# (可以通过filter减少计算max_score,提高性能(将query转为filter)),max_score为1,精确值不需要算分
GET /employee/_search
{
"query": {
"constant_score":{
"filter":{
"term": {
"address.keyword": "蒙德地区"
}
}
}
}
}
# terms多值匹配 query-terms-field_name- v1/v2/v3/v4
GET /employee/_search
GET /employee/_search
{
"query": {
"terms": {
"address.keyword": [
"蒙德地区",
"璃月地区"
]
}
}
}
# range范围
GET /employee/_search
{
"query": {
"range": {
"age": {
"gte": 10,
"lte": 200
}
}
}
}
# 日期查询,1分片0副本,
PUT /notes
{
"settings":{
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings":{
"properties":{
"title":{"type":"text"},
"content":{"type":"text"},
"created_at":{"type":"date","format":"yyyy-MM-dd HH:mm:ss"}
}
}
}
POST /_bulk
{"index":{"_index":"notes","_id":1}}
{"title":"2025原神年度更新展望","content":"预计2025年将开放全新大陆与剧情篇章,增加独特的环境机关和探索任务。","created_at":"2025-01-08 09:00:00"}
{"index":{"_index":"notes","_id":2}}
{"title":"新角色前瞻","content":"2025年可能会推出融合多元素的复合战斗角色,给战斗策略带来全新思路。","created_at":"2025-02-15 14:30:00"}
{"index":{"_index":"notes","_id":3}}
{"title":"周年庆猜想","content":"在2025年的周年庆,或将有跨国度的大型协作副本,以及全球玩家共同参与的活动。","created_at":"2025-03-20 12:00:00"}
{"index":{"_index":"notes","_id":4}}
{"title":"元素反应新机制","content":"官方可能会在2025年强化元素反应系统,增加更多独特的元素联动效果。","created_at":"2025-04-05 16:45:00"}
{"index":{"_index":"notes","_id":5}}
{"title":"新地图风景","content":"2025年新地图或将融合沙漠与海岛两种风格,为玩家带来截然不同的探索体验。","created_at":"2025-05-10 10:10:00"}
{"index":{"_index":"notes","_id":6}}
{"title":"多人模式升级","content":"在2025年多人合作模式可能会引入跨服匹配及更多团队战术副本。","created_at":"2025-06-01 18:20:00"}
{"index":{"_index":"notes","_id":7}}
{"title":"须弥支线补完","content":"预计会扩展须弥地区的支线任务,揭示部分角色未解的背景故事。","created_at":"2025-07-14 08:50:00"}
{"index":{"_index":"notes","_id":8}}
{"title":"新武器系统","content":"可能会引入灵活的武器属性调整机制,让装备搭配更加多样化。","created_at":"2025-08-25 21:40:00"}
{"index":{"_index":"notes","_id":9}}
{"title":"宠物互动玩法","content":"2025年或将开放宠物系统,玩家可以收集、培养并与宠物互动。","created_at":"2025-09-12 13:15:00"}
{"index":{"_index":"notes","_id":10}}
{"title":"交互界面优化","content":"版本更新可能会对UI布局进行优化,让冒险信息一目了然。","created_at":"2025-10-30 17:55:00"}
GET /notes/_search
{
"query": {"range":{
"created_at": {
"gte": "2025-02-01 00:00:00",
"lte": "2025-05-30 23:59:59"
}
}},
"_source": ["title","content","created_at"]
}
# now当前,now-1d前一天,d天day,w星期week,M月Month,y年year,h小时hour ,+后,-前
GET /notes/_search
{
"query": {"range":{
"created_at": {
"gte": "now-3M",
"lte": "now"
}
}},
"_source": ["title","content","created_at"]
}
# exists是否存在、ids一组id,
# exists:query-exists-field:是否存在的字段
GET /notes/_search
{
"query": {
"exists": {
"field": "title"
}
}
}
# ids:根据一组id查询
GET /notes/_search
{
"query": {
"ids":{"values":[1,2,3,4]}
}
}
# 模糊匹配:prefix前缀、wildcard通配符、fuzzy编辑距离、regexp正则、term set多值字段
# prefix不会分词,传入的前缀就是要找的前缀,max_score=1
GET /employee/_search
# keyword为空,因为不是德开头的
GET /employee/_search
{
"query": {
"prefix": {
"address.keyword": {
"value": "德"
}
}
}
}
# 不为空,因为分词了
GET /employee/_search
{
"query": {
"prefix": {
"address": {
"value": "德"
}
}
}
}
# wildcard 通配符匹配,*代表0或多个字符,?表示1个字符,任意单个字符,有较高计算负担,最好别用
GET /employee/_search
{
"query": {
"wildcard": {
"remark.keyword": {
"value": "*大*"
}
}
}
}
# regexp正则,(.*)任意字符串
GET /employee/_search
{
"query": {
"regexp": {
"remark.keyword": {
"value": ".*大.*"
}
}
}
}
# fuzzy编辑距离的模糊查询,可能输入错误字符串,hello,helle的fuzziness距离1,github,guthub的fuzziness距离2
# fuzziness为0/1/2/AUTO,prefix_length为前缀长度,默认0代表整个词
GET /employee/_search
{
"query": {
"fuzzy":{
"address.keyword": {
"value": "稻妻地区",
"fuzziness": 2,
"prefix_length": 0
}
}
}
}
# term_set 多值,一个字段多个词,支持字段minimum_should_match:[匹配多少个number]、minimum_should_match_field和脚本minimum_should_match_script
DELETE /movies
PUT /movies
{
"mappings": {
"properties": {
"title":{
"type": "text"
},
"tags":{
"type":"keyword"
},
"tags_count":{
"type":"integer"
}
}
}
}
POST /_bulk
{"index":{"_index":"movies","_id":1}}
{"title":"斗罗大陆","tags":["国漫","玄幻","热血"],"tags_count":3}
{"index":{"_index":"movies","_id":2}}
{"title":"一人之下","tags":["国漫","都市","超能力"],"tags_count":3}
{"index":{"_index":"movies","_id":3}}
{"title":"狐妖小红娘","tags":["国漫","爱情","奇幻"],"tags_count":3}
{"index":{"_index":"movies","_id":4}}
{"title":"火影忍者","tags":["日漫","热血","忍者"],"tags_count":3}
{"index":{"_index":"movies","_id":5}}
{"title":"海贼王","tags":["日漫","冒险","热血"],"tags_count":3}
{"index":{"_index":"movies","_id":6}}
{"title":"进击的巨人","tags":["日漫","奇幻","战斗"],"tags_count":3}
{"index":{"_index":"movies","_id":7}}
{"title":"鬼灭之刃","tags":["日漫","奇幻","战斗"],"tags_count":3}
{"index":{"_index":"movies","_id":8}}
{"title":"名侦探柯南","tags":["日漫","推理","悬疑"],"tags_count":3}
{"index":{"_index":"movies","_id":9}}
{"title":"镇魂街","tags":["国漫","奇幻","热血"],"tags_count":3}
{"index":{"_index":"movies","_id":10}}
{"title":"灌篮高手","tags":["日漫","体育","校园"],"tags_count":3}
{"index":{"_index":"movies","_id":10}}
{"title":"凡人修仙传","tags":["国漫","奇幻","战斗"],"tags_count":1}
# 使用match,直接指定值
GET /movies/_search
{
"query": {
"terms_set":{
"tags":{
"terms":["奇幻","国漫"],
"minimum_should_match":2
}
}
}
}
# 根据字段值的值匹配,可以动态化
GET /movies/_search
{
"query": {
"terms_set":{
"tags":{
"terms":["国漫","热血","奇幻"],
"minimum_should_match_field": "tags_count"
}
}
}
}
#根据脚本
GET /movies/_search
{
"query": {
"terms_set":{
"tags":{
"terms":["国漫","热血"],
"minimum_should_match_script":{
"source":"2"
}
}
}
}
}
# 脚本获取tag_count动态匹配
GET /movies/_search
{
"query": {
"terms_set":{
"tags":{
"terms":["国漫","热血","奇幻"],
"minimum_should_match_script":{
"source":"doc['tags_count'].value*0.7"
}
}
}
}
}
# 全文检索:match分词查询\multi_match多字段查询\match_phrase短语查询\query_string与或非表达式查询\simple_query_string
# 全文检索需要分析,进行匹配:适用于评论、文章等非结构化文本数据
# match:分词查询:分词-匹配计算-结果返回
GET /movies/_search
GET /movies/_search
{
"query": {
"match": {
"title": "人修"
}
}
}
# multi_match多字段查询 ,默认是or
GET /movies/_search
{
"query": {
"multi_match": {
"query": "凡人",
"fields": ["tags","title"],
"operator": "and"
}
}
}
GET /movies/_search
{
"query": {
"multi_match": {
"query": "凡人",
"fields": ["tags","title"],
"operator": "or"
}
}
}
GET /employee/_search
GET /employee/_search
{
"query": {
"match": {
"address": {
"query":"蒙璃",
"minimum_should_match":1
}
}
}
}
GET /employee/_search
{
"query": {
"match": {
"address": {
"query": "蒙德璃月",
"operator": "and"
}
}
}
}
# match_phrase短语查询:顺序,不仅匹配整个短语,还考虑顺序和位置
POST _analyze
{
"analyzer":"ik_max_word",
"text":"蒙德地区-西风骑士团火花骑士"
}
GET /employee/_search
GET /employee/_search
{
"query": {
"match_phrase": {
"remark":"蒙德地区-西风骑士"
}
}
}
# slop代表相隔多远视为匹配
GET /employee/_search
{
"query": {
"match_phrase": {
"remark":{
"query":"蒙德地区-西风骑士",
"slop": 2
}}
}
}
GET /employee/_search
{
"query": {
"match_phrase": {
"remark": "蒙德地区-西风骑士团"
}
}
}
# query_string用于高级搜索、数据分析、特定需求,要求支持与或非表达式的复杂查询任务,记得大写
# 多条件:+AND. |OR. -NOT
GET /employee/_search
{
"query": {
"query_string": {
"default_field": "address",
"query": "(蒙德 OR 稻妻) AND 地区"
}
}
}
# 单一条件
GET /employee/_search
{
"query": {
"query_string": {
"default_field": "remark",
"query": "璃月 AND 往生堂 "
}
}
}
GET /_analyze
{
"analyzer":"ik_max_word",
"text":"璃月地区-月海亭秘书"
}
# 多条件+多字段
GET /employee/_search
{
"query": {
"query_string": {
"fields": ["remark","name"],
"query": "(璃月 AND 钟离) OR 蒙德 "
}
}
}
# simple_query_string 简化的querystring
GET /employee/_search
{
"query": {
"simple_query_string": {
"query": "璃月",
"fields": ["name","address"],
"default_operator": "AND"
}
}
}
GET /employee/_search
{
"query": {
"simple_query_string": {
"query": "璃 + 月",
"fields": ["name","address"]
}
}
}
GET /employee/_search
{
"query": {
"simple_query_string": {
"query": "璃 + 月",
"fields": ["name","address"]
}
}
}
# 组合查询:布尔查询,按照布尔条件:按照max_score:搜索上下文must/should,filter:过滤上下文无需算分filter/must_not
# term一般在filter过滤上下文
# must:and算分,should:or多个条件算分,filter不算分,must_not不算分
PUT /books
{
"settings": {
"number_of_replicas": 1,
"number_of_shards": 1
},
"mappings": {
"properties": {
"id":{"type":"long"},
"title":{"type":"text","analyzer":"ik_max_word"},
"language":{"type":"keyword"},
"author":{"type":"keyword"},
"price":{"type":"double"},
"publish_time":{"type":"date","format":"yyyy-MM-dd"},
"description":{"type":"text","analyzer":"ik_max_word"}
}
}
}
POST /_bulk
{"index":{"_index":"books","_id":"1"}}
{"id":1,"title":"Java编程思想","language":"java","author":"Bruce Eckel","price":70.20,"publish_time":"2007-10-01","description":"Java学习必读经典,殿堂级著作!赢得了全球程序员的广泛赞誉。"}
{"index":{"_index":"books","_id":"2"}}
{"id":2,"title":"Java程序性能优化","language":"java","author":"葛一鸣","price":46.5,"publish_time":"2012-08-01","description":"让你的Java程序更快、更稳定。"}
{"index":{"_index":"books","_id":"3"}}
{"id":3,"title":"深入理解计算机系统","language":"c","author":"Randal E.Bryant","price":85.00,"publish_time":"2016-05-10","description":"系统性介绍计算机内部工作原理。"}
{"index":{"_index":"books","_id":"4"}}
{"id":4,"title":"Effective Java","language":"java","author":"Joshua Bloch","price":66.00,"publish_time":"2018-01-01","description":"Java开发最佳实践集合。"}
{"index":{"_index":"books","_id":"5"}}
{"id":5,"title":"Python数据分析","language":"python","author":"Wes McKinney","price":59.00,"publish_time":"2019-03-15","description":"基于Pandas和NumPy的数据分析指南。"}
GET /books/_search
GET /books/_search
{
"query":{
"bool":{
"must":[
{"match":{"title":"Java"}},
{"match":{"description":"Java"}}
]
}
}
}
GET /books/_search
{
"query":{
"bool":{
"should":[
{"match":{"title":"Java"}},
{"match":{"description":"Java"}}
]
}
}
}
GET /books/_search
{
"query":{
"bool":{
"filter":[
{"term":{"language":"java"}},
{"range":{"price":{
"lte":100
}}}
]
}
}全文检索
全文检索会进行算分,filter 不会算分,此类算分的检索,用于非结构文本数据,比如文章和评论等。
- match 分词匹配,只能查找一个字段,可以使用 opertor 设置 AND /OR(在字段名后加上 query 和 operator), / minimum_should_match 设置匹配至少多少个
- multi_match 多字段查询,字段太多性能下降,方便一次查多个字段
- match_phrase 短语查询,精确匹配词组,查找范围严格,需要按照顺序,可以用 slop,在字段后加上 kv:slop 和 query
- query_string 与或非表达式,功能最强,单语法错误会报错,记得大写 AND OR NOT
- simple_query_string 功能类似
<font style="color:rgb(13, 18, 57);">query_string</font>,但不会因为语法错误而直接报错,非常适合用户输入不可控的场景(<font style="color:rgb(13, 18, 57);">+</font>必须包含<font style="color:rgb(13, 18, 57);">-</font>排除)
shell
GET _search
{
"query": {
"match_all": {}
}
}
PUT /blog
{
"mappings": {
"properties": {
"content":{
"type": "text"
},
"time":{
"type": "date"
},
"user":{
"properties": {
"city":{
"type":"text"
},
"userid":{
"type":"long"
},
"username":{
"type": "keyword"
}
}
}
}
}
}
POST /products/_bulk
{"index":{"_index":"products","_id":1}}
{"name":"原神主题抱枕","description":"印有原神角色图案的舒适抱枕"}
{"index":{"_index":"products","_id":2}}
{"name":"原神桌面鼠标垫","description":"适合游戏玩家的防滑鼠标垫"}
{"index":{"_index":"products","_id":3}}
{"name":"明日方舟徽章","description":"印有明日方舟角色图案的金属徽章"}
{"index":{"_index":"products","_id":4}}
{"name":"原神周边茶杯","description":"原神主题的陶瓷茶杯,礼盒包装"}
GET /products/_search
{
"query": {
"match": {
"description": "原神"
}
}
}
GET /products/_search
{
"query": {
"match": {
"description":{
"operator": "and",
"query":"原神抱枕"
}
}
}
}
GET /products/_search
{
"query": {
"match": {
"description":{
"query":"原神抱枕",
"minimum_should_match": 1
}
}
}
}
GET /products/_search
{
"query": {
"match": {
"description":{
"operator": "or",
"query":"原神抱枕"
}
}
}
}
GET /products/_search
{
"query": {
"multi_match": {
"query": "原神",
"fields": ["name", "description"]
}
}
}
GET /_analyze
{
"analyzer": "ik_smart",
"text":"原神主题的陶瓷茶杯,礼盒包装"
}
GET /products/_search
{
"query": {
"match_phrase": {
"description": "原神的主题"
}
}
}
GET /products/_search
{
"query": {
"match_phrase": {
"description":{
"query": "原神的主题",
"slop": 4
}
}
}
}
GET /products/_search
{
"query": {
"query_string": {
"query": "原神 AND 周边 OR 抱枕 NOT 鼠标垫"
}
}
}
GET /products/_search
{
"query": {
"query_string": {
"query": "原神 AND 周边 OR 抱枕 NOT 鼠标垫",
"default_field": "name"
}
}
}
GET /products/_search
{
"query": {
"query_string": {
"query": "原神 AND 周边 OR 抱枕 NOT 鼠标垫",
"fields": ["name", "description"]
}
}
}
GET /products/_search
{
"query": {
"simple_query_string": {
"query": "原神 +周边 -鼠标垫",
"fields": ["name", "description"],
"default_operator": "and"
}
}
}组合查询
- 布尔查询
搜索上下文(算分)和过滤上下文(不算分)
算: must:均满足/should:一个满足,shoul 可以结合minimum_should_match 加上可以匹配最少多少个,默认 1
不算: filter:过滤均满足/must_not:均不满足
query-bool-must/should/filter/must_not---match/multi_match/range/term
shell
# 组合查询
PUT /genshin_posts
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"analysis": {
"analyzer": {
"my_ik": {
"type": "ik_max_word"
}
}
}
},
"mappings": {
"properties": {
"title": { "type": "text", "analyzer": "my_ik" },
"content": { "type": "text", "analyzer": "my_ik" },
"region": { "type": "keyword" },
"element": { "type": "keyword" },
"created_at": { "type": "date", "format": "yyyy-MM-dd" }
}
}
}
POST /_bulk
{"index":{"_index":"genshin_posts","_id":1}}
{"title":"钟离护盾体验","content":"测试钟离的岩元素护盾,非常适合探索和打世界BOSS","region":"璃月","element":"岩","created_at":"2024-07-10"}
{"index":{"_index":"genshin_posts","_id":2}}
{"title":"胡桃与夜兰配队","content":"胡桃的高爆发配合夜兰,打精英怪效果拔群","region":"璃月","element":"火","created_at":"2024-07-11"}
{"index":{"_index":"genshin_posts","_id":3}}
{"title":"雷电将军BOSS战","content":"挑战雷电将军的周本,需要灵活闪避和及时输出","region":"稻妻","element":"雷","created_at":"2024-05-18"}
{"index":{"_index":"genshin_posts","_id":4}}
{"title":"纳西妲探索草原","content":"草元素的纳西妲在须弥探索效率极高","region":"须弥","element":"草","created_at":"2024-04-03"}
{"index":{"_index":"genshin_posts","_id":5}}
{"title":"神里绫华冰冻控制","content":"冰元素绫华配合申鹤,深渊控制能力很强","region":"稻妻","element":"冰","created_at":"2024-06-22"}
POST /_bulk
{"index":{"_index":"genshin_posts","_id":6}}
{"title":"温迪风场探索技巧","content":"原神中温迪的风元素技能可短时间制造上升气流,帮助快速登高与探索秘境","region":"蒙德","element":"风","created_at":"2024-03-12"}
{"index":{"_index":"genshin_posts","_id":7}}
{"title":"魈跳跃攻击","content":"魈的风元素跃击在原神世界探索中既炫酷又实用","region":"璃月","element":"风","created_at":"2024-02-20"}
{"index":{"_index":"genshin_posts","_id":8}}
{"title":"刻晴雷斩测试","content":"刻晴的雷元素瞬移与斩击能快速切入战斗","region":"璃月","element":"雷","created_at":"2024-01-15"}
{"index":{"_index":"genshin_posts","_id":9}}
{"title":"雷泽野外战斗","content":"雷泽的雷元素技能搭配狼魂,适合原神野外清怪","region":"蒙德","element":"雷","created_at":"2024-07-01"}
{"index":{"_index":"genshin_posts","_id":10}}
{"title":"香菱火锅派对","content":"香菱的火元素技能配合锅巴,既能战斗也能烹饪","region":"璃月","element":"火","created_at":"2024-06-05"}
{"index":{"_index":"genshin_posts","_id":11}}
{"title":"安柏火箭射术","content":"安柏的火元素箭雨在原神任务中清理敌群效果不错","region":"蒙德","element":"火","created_at":"2024-05-11"}
{"index":{"_index":"genshin_posts","_id":12}}
{"title":"重云冰刀测试","content":"重云的冰元素领域在深渊环境下非常稳定","region":"璃月","element":"冰","created_at":"2024-04-21"}
{"index":{"_index":"genshin_posts","_id":13}}
{"title":"七七治疗能力","content":"七七的冰元素治疗可在原神战场快速为队友补血","region":"璃月","element":"冰","created_at":"2024-07-02"}
{"index":{"_index":"genshin_posts","_id":14}}
{"title":"行秋雨剑","content":"行秋的水元素技能让战斗更安全,原神玩家必练","region":"璃月","element":"水","created_at":"2024-03-10"}
{"index":{"_index":"genshin_posts","_id":15}}
{"title":"珊瑚宫心海治疗实验","content":"心海的水元素治疗配合冰元素角色可轻松控场","region":"稻妻","element":"水","created_at":"2024-06-06"}
{"index":{"_index":"genshin_posts","_id":16}}
{"title":"九条裟罗雷羽","content":"九条裟罗的雷元素增伤技能非常适合爆发队伍","region":"稻妻","element":"雷","created_at":"2024-05-23"}
{"index":{"_index":"genshin_posts","_id":17}}
{"title":"宵宫焰火","content":"宵宫的火元素技能在原神夜景下格外绚丽","region":"稻妻","element":"火","created_at":"2024-08-12"}
{"index":{"_index":"genshin_posts","_id":18}}
{"title":"早柚风滚草","content":"早柚的风元素翻滚可以快速移动与探索","region":"稻妻","element":"风","created_at":"2024-07-19"}
{"index":{"_index":"genshin_posts","_id":19}}
{"title":"鹿野院平藏格斗技巧","content":"平藏的风元素与近战技能在原神战斗中很独特","region":"稻妻","element":"风","created_at":"2024-06-26"}
{"index":{"_index":"genshin_posts","_id":20}}
{"title":"提纳里射击测试","content":"提纳里的草元素蓄力箭在须弥探险高效","region":"须弥","element":"草","created_at":"2024-05-09"}
{"index":{"_index":"genshin_posts","_id":21}}
{"title":"柯莱投掷攻势","content":"柯莱的草元素飞叶技能适合中距离攻击","region":"须弥","element":"草","created_at":"2024-04-28"}
{"index":{"_index":"genshin_posts","_id":22}}
{"title":"艾尔海森双剑测试","content":"艾尔海森的草元素双技能在原神中兼顾爆发与持续","region":"须弥","element":"草","created_at":"2024-02-14"}
{"index":{"_index":"genshin_posts","_id":23}}
{"title":"白术治疗实验","content":"白术的草元素治疗可配合护盾提高生存率","region":"璃月","element":"草","created_at":"2024-07-04"}
{"index":{"_index":"genshin_posts","_id":24}}
{"title":"申鹤冰增伤研究","content":"申鹤的冰元素增伤让冰队伤害倍增","region":"璃月","element":"冰","created_at":"2024-06-15"}
{"index":{"_index":"genshin_posts","_id":25}}
{"title":"迪卢克大剑爆发","content":"迪卢克的火元素爆发技能适合快速击杀BOSS","region":"蒙德","element":"火","created_at":"2024-05-30"}
GET /genshin_posts/_search
{
"query": {
"bool": {
"must": [
{ "match": { "content": "原神" } },
{ "match": { "content": "护盾" } }
]
}
}
}
GET /genshin_posts/_search
{
"query": {
"bool": {
"should": [
{ "match": { "content": "冰冻" } },
{ "match": { "content": "控制" } }
],
"minimum_should_match": 1
}
}
}
GET /genshin_posts/_search
{
"query": {
"bool": {
"must": { "match": { "content": "队伍" } },
"filter": [
{ "term": { "region": "稻妻" } },
{ "term": { "element": "雷" } }
]
}
}
}
GET /genshin_posts/_search
{
"query": {
"bool": {
"must": { "match": { "content": "原神" } },
"must_not": [
{ "term": { "element": "冰" } }
]
}
}
}高亮
highlight 关键字可以让符合条件的关键词高亮:
ES 高亮默认只高亮 query 匹配的字段,
- pre_rags:前缀:"*""""**"***
- post_tags:后缀:""""""
- tags_schema:设置 style
- require_field_match:多字段需要 设置为 false,true 默认代表搜索 query 字段高亮,false,没有 query 只要匹配就高亮, multi_match 或跨字段搜索时用,当你使用 multi_match 或跨字段搜索时,建议
<font style="color:rgb(13, 18, 57);">require_field_match: false</font>,这样所有包含关键词的字段都会高亮,方便前端一次性渲染。如果你只想高亮用户指定查询的字段,保留<font style="color:rgb(13, 18, 57);">true</font>。
<font style="color:rgb(13, 18, 57);">true</font>:只高亮正在搜索的字段(更精准),只有 query+fields 里面的会高亮,*代表 query 里面的字段<font style="color:rgb(13, 18, 57);">false</font>:所有字段只要包含匹配词,就高亮(更宽松),fields 里面的都会被高亮,*所有字段- highlight-filelds:*代表前面的 query,可以指定 k(字段名)v({})
shell
# 高亮
GET /genshin_posts/_search
{
"query": {
"bool": {
"must": { "match": { "content": "原神" } },
"must_not": [
{ "term": { "element": "冰" } }
]
}
},
"highlight": {
"fields": {
"*":{}
},
"require_field_match": "true"
}
}
GET /genshin_posts/_search
{
"query": {
"bool": {
"must": [
{ "match_phrase": { "content": "夜景" } }
],
"filter": [
{ "match_phrase": { "region": "稻妻" } }
]
}
},
"highlight": {
"pre_tags": ["<em style='color:red'>"],
"post_tags": ["</em>"],
"fields": {
"title": {},
"content": {}
},
"require_field_match": "false"
}
}
GET /genshin_posts/_search
{
"query": {
"bool": {
"should": [
{ "match": { "content": "爆发" } },
{ "match": { "content": "控制" } }
],
"minimum_should_match": 1
}
},
"highlight": {
"pre_tags": ["<mark>"],
"post_tags": ["</mark>"],
"fields": {
"title": {},
"content": {}
}
}
}
GET /genshin_posts/_search
{
"query": {
"bool": {
"must": [
{ "match": { "content": "原神" } }
],
"must_not": [
{ "term": { "element": "冰" } }
]
}
},
"highlight": {
"pre_tags": ["<strong style='color:blue'>"],
"post_tags": ["</strong>"],
"fields": {
"title": {},
"content": {}
}
}
}
GET /genshin_posts/_search
{
"query": {
"match": {
"content": "火"
}
},
"highlight": {
"require_field_match": false,
"fields": {
"*": {}
}
}
}
GET /genshin_posts/_search
{
"query": {
"match": {
"content": "火"
}
},
"highlight": {
"require_field_match": true,
"fields": {
"*": {}
}
}
}地理空间位置
- geo_point 支持
<font style="color:rgb(13, 18, 57);">geo_distance</font>(圆范围)、<font style="color:rgb(13, 18, 57);">geo_bounding_box</font>(矩形)、<font style="color:rgb(13, 18, 57);">geo_polygon</font>(多边形)等查询。- 场景:附近 NPC/商店、怪物刷新点、交通点位等。
- 如果是地图可视化,可以输出到 kibana map 或前端地图组件。
geo_distance 是一个地理距离查询,允许指定一个距离和一个点的坐标
distance 时查询最大距离,单位 m 或 km
distance_type :arc 弧长/plane 直线距离为单位,建议 arc
location:参考点,包含经度纬度足疗
圆形范围:query - bool - filter - geo_distance - distance(value)/location(lat/lon) 位置距离排序:query/match_all. + sort - **_geo_distance** - location(lat/lon) / order(asc) / unit(km) / distance_type(arc)
矩形:query - geo_bounding_box - location - top_left(lat/lon) / bottom_right(lat/lon)
多边形:query - geo_polygon - location - points -{lat/lon}/{lat/lon}/{lat/lon}
shell
# 地理空间位置查询 mappings - properties - location - type:"geo_point"
PUT /genshin_locations
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"name": { "type": "text" },
"region": { "type": "keyword" },
"element": { "type": "keyword" },
"location": { "type": "geo_point" }
}
}
}
POST /_bulk
{"index":{"_index":"genshin_locations","_id":1}}
{"name":"蒙德城广场","region":"蒙德","element":"风","location":{"lat":48.1351,"lon":11.5820}}
{"index":{"_index":"genshin_locations","_id":2}}
{"name":"璃月港口","region":"璃月","element":"岩","location":{"lat":29.5539,"lon":106.5678}}
{"index":{"_index":"genshin_locations","_id":3}}
{"name":"稻妻城中心","region":"稻妻","element":"雷","location":{"lat":35.6528,"lon":139.8395}}
{"index":{"_index":"genshin_locations","_id":4}}
{"name":"须弥雨林遗迹","region":"须弥","element":"草","location":{"lat":4.2105,"lon":101.9758}}
{"index":{"_index":"genshin_locations","_id":5}}
{"name":"雪山龙脊","region":"蒙德","element":"冰","location":{"lat":30.6586,"lon":104.0648}}
GET /genshin_locations/_search
{
"query": {
"bool": {
"filter": {
"geo_distance": {
"distance": "300km",
"location": {
"lat": 30.657,
"lon": 104.066
}
}
}
}
}
}
GET /genshin_locations/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance": {
"location": {
"lat": 30.657,
"lon": 104.066
},
"order": "asc",
"unit": "km",
"distance_type": "arc"
}
}
]
}
GET /genshin_locations/_search
{
"query": {
"geo_bounding_box": {
"location": {
"top_left": {
"lat": 50,
"lon": 105
},
"bottom_right": {
"lat": 25,
"lon": 110
}
}
}
}
}
GET /genshin_locations/_search
{
"query": {
"geo_polygon": {
"location": {
"points": [
{ "lat": 30, "lon": 103 },
{ "lat": 31, "lon": 105 },
{ "lat": 29, "lon": 106 }
]
}
}
}
}向量检索
比如通过 KNN 算法支持向量近邻检索(用于机器学习、数据分析、推荐系统等领域)
基本思路是,将文档表示为高维向量,并使用这些向量执行相似性搜索,在 ES 中,这些向量被存储在 dense_vector 类型的字段中,使用 KNN 算法来找到与给定向量最相似的其它向量
shell
#dims: 向量维度(这里为了演示设 4,真实 NLP 模型一般是 384、768、1536)。
#index: true: 启用向量索引。
# similarity: 相似度算法(cosine / l2_norm / dot_product)
DELETE /genshin_vectors
PUT /genshin_vectors
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"title": { "type": "text" },
"content": { "type": "text" },
"region": { "type": "keyword" },
"element": { "type": "keyword" },
"vector": {
"type": "dense_vector",
"dims": 4,
"index": true,
"similarity": "cosine"
}
}
}
}
POST /_bulk
{"index":{"_index":"genshin_vectors","_id":1}}
{"title":"钟离的护盾","content":"钟离的岩元素护盾抗击打能力超强","region":"璃月","element":"岩","vector":[0.12,0.85,0.33,0.20]}
{"index":{"_index":"genshin_vectors","_id":2}}
{"title":"胡桃的爆发","content":"胡桃的火元素高爆发适合快速击杀","region":"璃月","element":"火","vector":[0.88,0.11,0.22,0.31]}
{"index":{"_index":"genshin_vectors","_id":3}}
{"title":"雷电将军的攻击节奏","content":"雷电将军的雷元素攻击节奏稳定,适合长时间输出","region":"稻妻","element":"雷","vector":[0.34,0.67,0.12,0.33]}
{"index":{"_index":"genshin_vectors","_id":4}}
{"title":"神里绫华冰冻控制","content":"绫华的冰元素配合申鹤,形成强冰冻控制","region":"稻妻","element":"冰","vector":[0.20,0.33,0.85,0.18]}
POST /genshin_vectors/_knn_search
{
"knn": {
"field": "vector",
"query_vector": [0.10,0.80,0.30,0.25],
"k": 2,
"num_candidates": 4
},
"_source": ["title","content","region","element"]
}
GET /genshin_vectors/_search
{
"query": {
"script_score": {
"query": { "match_all": {} },
"script": {
"source": "cosineSimilarity(params.query_vector, 'vector') + 1.0",
"params": {
"query_vector": [0.10,0.80,0.30,0.25]
}
}
}
},
"_source": ["title","content","region","element"]
}权重
使用 "fields": "title\^2", "content" 或者{"match":{"title":{"query":"原神","boost":3}}} 可以增加权重
shell
GET /csdn_blogs/_search
{
"query": {
"multi_match": {
"query": "原神",
"fields": ["title^2", "content"]
}
},
"highlight": {
"fields": {
"*": {}
},
"require_field_match": false
}
}
{ "match": { "title": { "query": "原神", "boost": 3 } } }csdn 搜索实战
shell
# 实战-csdn的搜索
# 1.创建索引,文章和标题一定要分词,为text
PUT csdn_blogs
{
"settings": {
"number_of_replicas": 1,
"number_of_shards": 1
},
"mappings": {
"properties": {
"title":{
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"content":{
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"author":{
"type": "keyword"
},
"tags":{
"type":"keyword"
},
"date":{
"type":"date",
"format": "yyyy-MM-dd HH:mm:ss"
}
}
}
}
POST /_bulk
{"index":{"_index":"csdn_blogs","_id":1}}
{"title":"Elasticsearch 高亮显示原神关键词实践","content":"本文详细讲解如何在Elasticsearch中使用IK分词器对原神相关内容进行搜索和高亮显示,同时对搜索上下文和过滤上下文做了对比。","author":"gamer101","tags":["Elasticsearch","原神","搜索"],"date":"2024-07-15 10:12:00"}
{"index":{"_index":"csdn_blogs","_id":2}}
{"title":"原神角色数据批量导入到Elasticsearch","content":"通过Bulk API将原神角色信息批量导入ES索引,并结合must、should等查询条件实现灵活检索。","author":"dev_cat","tags":["Elasticsearch","原神","BulkAPI"],"date":"2024-07-14 09:30:00"}
{"index":{"_index":"csdn_blogs","_id":3}}
{"title":"向量搜索结合原神语义匹配实例","content":"利用dense_vector存储原神角色描述的向量,并通过KNN实现语义搜索,找到最相似的攻略帖子。","author":"data_master","tags":["Elasticsearch","原神","向量搜索"],"date":"2024-07-13 14:20:00"}
{"index":{"_index":"csdn_blogs","_id":4}}
{"title":"Elasticsearch过滤上下文性能优化","content":"介绍如何在原神攻略搜索中利用filter上下文提高性能,例如按地区或元素进行快速过滤。","author":"tech_pro","tags":["Elasticsearch","过滤上下文","性能优化"],"date":"2024-07-12 20:10:00"}
{"index":{"_index":"csdn_blogs","_id":5}}
{"title":"原神地理位置索引与附近地点搜索","content":"通过geo_point类型存储原神地图上的坐标信息,实现附近地点搜索功能。","author":"map_lover","tags":["Elasticsearch","原神","地理位置"],"date":"2024-07-12 12:00:00"}
{"index":{"_index":"csdn_blogs","_id":6}}
{"title":"Elasticsearch 多字段搜索实战","content":"利用multi_match查询实现原神相关数据在标题和正文的双字段搜索,提升检索覆盖率。","author":"search_guru","tags":["Elasticsearch","multi_match","原神"],"date":"2024-07-11 11:45:00"}
{"index":{"_index":"csdn_blogs","_id":7}}
{"title":"Query String 查询原神攻略","content":"用query_string实现原神攻略的复杂与或非查询,满足进阶搜索需求。","author":"syntax_maniac","tags":["Elasticsearch","原神","query_string"],"date":"2024-07-10 10:10:00"}
{"index":{"_index":"csdn_blogs","_id":8}}
{"title":"原神短语搜索与高亮","content":"通过match_phrase实现原神短语的精准匹配,并对匹配词进行高亮展示。","author":"phrase_hunter","tags":["Elasticsearch","原神","match_phrase"],"date":"2024-07-09 22:50:00"}
{"index":{"_index":"csdn_blogs","_id":9}}
{"title":"原神周边商品搜索","content":"结合Elasticsearch keyword字段查询原神周边商品标签,实现精确匹配与分类统计。","author":"market_dev","tags":["Elasticsearch","原神","电商"],"date":"2024-07-09 09:20:00"}
{"index":{"_index":"csdn_blogs","_id":10}}
{"title":"原神跨字段高亮与搜索结合","content":"同时在标题和内容字段高亮原神关键词,让搜索结果更醒目。","author":"frontend_magic","tags":["Elasticsearch","原神","高亮"],"date":"2024-07-08 16:40:00"}
GET /csdn_blogs/_search
GET /csdn_blogs/_search
{
"query": {
"multi_match": {
"query": "原神",
"fields": ["title","content^5"]
}
},
"highlight": {
"fields": {
"*":{}
},
"require_field_match": "false"
}
}
GET /csdn_blogs/_search
{
"query": {
"bool": {
"must": [
{"multi_match": {
"query": "原神",
"fields": ["tiele","content"]
}},
{
"range": {
"date": {
"gte": "2024-07-12 10:12:00",
"lte": "2024-07-16 10:12:00"
}
}
},
{
"term": {
"tags": {
"value": "Elasticsearch"
}
}
}
]
}
}
}相关性
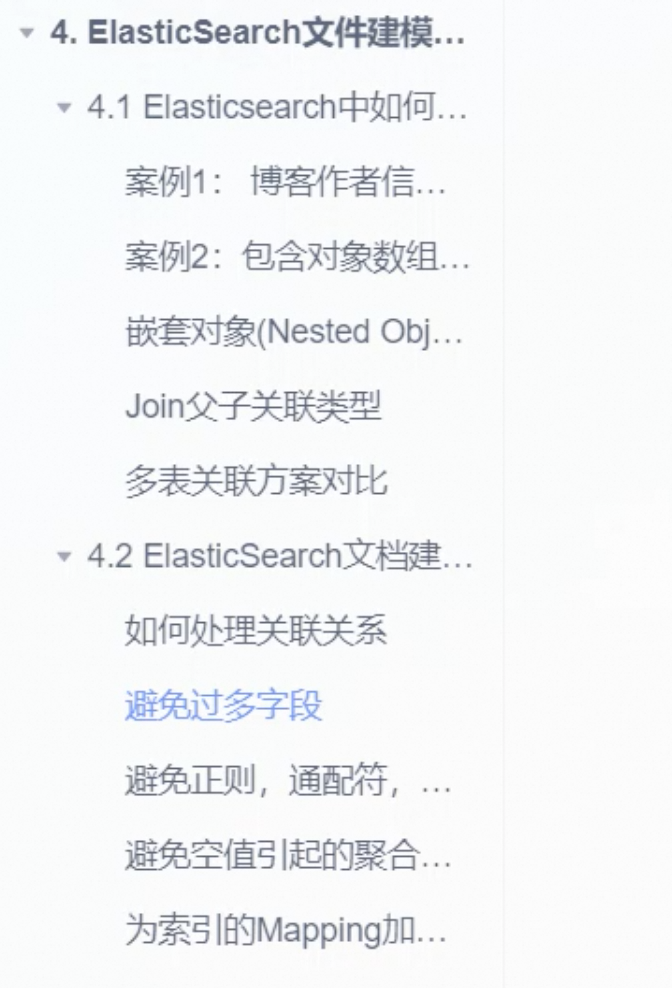
es5 之前是使用 TF-IDF 实现,5 之后,使用改进的 Okapi BM25
TF-IDF:
- 分词词频越高相关性越高
- 逆向频率检索词在索引中频率越低相关性越高
- 检索次在内容越短的字段中相关性越高
BM25:
- TF无限增加跨度太大,BM25算分会趋于一个数值(归一值)
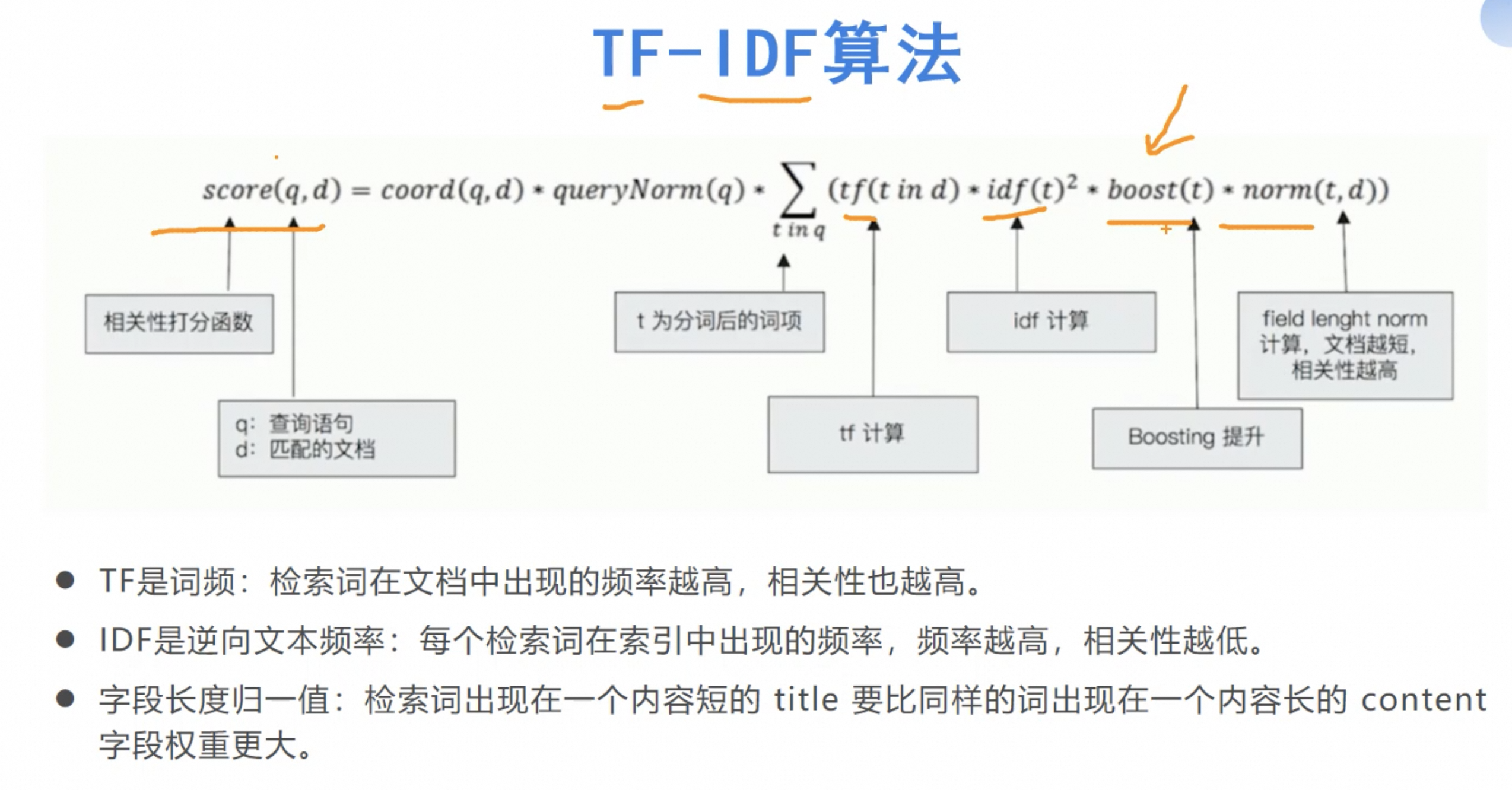
BM25:TF无限增加跨度太大,BM25算分会趋于一个数值(归一值)
shell
GET /csdn_blogs/_search
{
"query": {"match": {
"title": "原神"
}},
"explain": true
}
GET /csdn_blogs/_explain/2
{
"query":{
"match":{
"title":"原神"
}
}
}自定义评分
indices_boost 索引级加权 跨索引搜索时给某个索引整体加权。
query - boosting - positive/negative 文档提高/降低 同时包含正向条件和负向条件,负向只降分不排除。
negative_boost 文档下降 Boosting Query的参数,用来降低负向文档分数。
query - function_score/boost_mode /functions - filter/weight 修改计算公式 _score 用函数和条件自定义分数逻辑,非常灵活。
rescore - window_size/query_weight/rescore_query_weight/(query - rescore_query - match_phrase - k:v) 二次打分 结果集先查出来,再精细匹配重新打分。
- Index Boost:跨索引搜索时给某个索引整体加权。
- Boosting Query:同时包含正向条件和负向条件,负向只降分不排除。
- negative_boost:Boosting Query的参数,用来降低负向文档分数。
- Function Score:用函数和条件自定义分数逻辑,非常灵活。
- Rescore:结果集先查出来,再精细匹配重新打分。
ES自定义评分:修改评分修改文档相关性
Index Boost在索引层面修改相关性、boosting修改文档相关性、negative_boost降低相关性、function_score自定义评分、rescore_query查询后二次打分
索引层面
shell
# ES自定义评分:修改评分修改文档相关性
# Index Boost在索引层面修改相关性、boosting修改文档相关性、negative_boost降低相关性、function_score自定义评分、rescore_query查询后二次打分
PUT /my_index100
{
"mappings": {
"properties":{
"subject":{
"type":"keyword"
}
}}
}
PUT /my_index101
{
"mappings": {
"properties":{
"subject":{
"type":"keyword"
}
}}
}
PUT /my_index102
{
"mappings": {
"properties":{
"subject":{
"type":"keyword"
}
}}
}
POST /_bulk
{"index":{"_index":"my_index100","_id":1}}
{"subject":"subject 1"}
{"index":{"_index":"my_index101","_id":1}}
{"subject":"subject 1"}
{"index":{"_index":"my_index102","_id":1}}
{"subject":"subject 1"}
GET /my_index*/_search
{
"query": {
"term": {
"subject": {
"value": "subject 1"
}
}
}
}
# indices_boost 设置索引的相关性 ,值为权重
GET /my_index*/_search
{
"indices_boost": [
{
"my_index100": 2
},
{
"my_index101": 3
},
{
"my_index102": 1
}
],
"query": {
"term": {
"subject": {
"value": "subject 1"
}
}
}
}文档层面修改相关性
shell
# boost设置文档的权重
GET /my_index*/_search
{
"query": {
"bool": {
"should": [
{"match":{
"title":{
"query":"",
"boost":4
}
}},
{
"match":{
"content":{
"query": "",
"boost":1
}
}
}
]
}
}
}降低文档negative_boost
0-1 降低,大于 1 增加
shell
# negative 降低文档相关性 / bool - [must / must_not]也能排除
GET /my_index*/_search
{
"query": {
"bool": {
"must": [
{"content":"apple"}
],
"must_not": [
{"content":"pin"}
]
}
}
}
# query-boosting - postitive/negative/negative_boost(仅对negative生效+一般取值0-1,比如0.3,会乘法计算)
GET /my_index*/_search
{
"query": {
"boosting": {
"negative": {
"match": {
"FIELD": "TEXT"
}
},
"positive": {
"match": {
"FIELD": "TEXT"
}
},
"negative_boost": 0.2
}
}
}自定义 function_score
shell
# function_score自定义评分 query-function_score -- (query -- match_all)/(script_score -- script -- source)
GET /csdn_blogs/_search
{
"query": {
"function_score": {
"query": {
"match": { "content": "原神" }
},
"boost_mode": "sum",
"functions": [
{
"filter": { "term": { "tags": "Elasticsearch" } },
"weight": 2
},
{
"filter": { "range": { "date": { "gte": "2024-07-10" } } },
"weight": 1.5
}
]
}
}
}
GET /csdn_blogs/_search
GET /csdn_blogs/_search
{
"query": {
"function_score": {
"query": {"match_all": {}},
"script_score": {
"script": "_score * doc['f'].value + doc['sales'].value"
}
}
}
}二次打分 rescore
rescore- query-(rescore_querty /rescore_query_weight / query_weight ) / window_size
window_size:50 😕/ 只重新评分前50条
rescore_query: 二次算分的查询条件
#rescore_query_weight:二次算分的权重
query_score : 一开始算分的权重0.7
shell
#二次算分:只针对结果进行算分,在检索结果基础上增加更复杂的评分逻辑,提供更准确的结果排序,但也会增加查询的计算成本和响应时间
# window_size:50 :// 只重新评分前50条
# rescore_query: 二次算分的查询条件
#rescore_query_weight:二次算分的权重
# query_score : 一开始算分的权重0.7
GET /csdn_blogs/_search
{
"query": {
"match": {
"FIELD": "TEXT"
}
},
"rescore": {
"query": {
"rescore_query":{
"match":{}
},
"rescore_query_weight":1.2,
"query_weight":0.7
},
"window_size": 50
}
}
GET /csdn_blogs/_search
{
"query": {
"match": {
"content": "原神 搜索 高亮"
}
},
"rescore": {
"window_size": 50,
"query": {
"rescore_query": {
"match_phrase": { "content": "原神 搜索 高亮" }
},
"query_weight": 0.7,
"rescore_query_weight": 1.2
}
}
}多字段搜索场景优化
dis_max:只取最大的
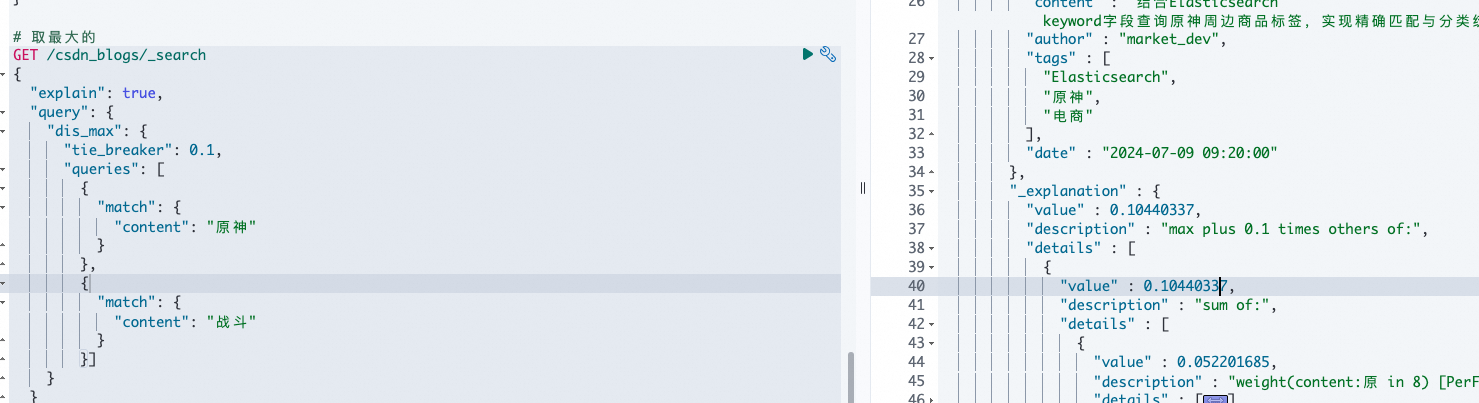
tie_breaker:其它字段匹配分数乘这个再加到最佳分(用于 dis_max 实现平衡,两个字段匹配分相加,让匹配更多字段的文档的分更高) - 评分求和
tie_breaker:0为最佳匹配,1代表都很重要,(获得最佳-- 将其他不是最佳的与tie_breaker相乘,最佳和相乘后的其他求和并规范化)
最终 = 最佳得分 + 其他匹配字段得分 * tie_breaker
multi_match 就是默认 best_fields,可以指定 tie_breaker
shell
# 多字段搜索场景优化
#最佳best:多个字段返回评分最高
#多数字段most:多字段返回字段评分和
#混合字段Cross:都显示
GET /csdn_blogs/_search
# 取最大的
# tie_breaker:0为最佳匹配,1代表都很重要,(获得最佳-- 将其他不是最佳的与tie_breaker相乘,最佳和相乘后的其他求和并规范化)
# 最终 = 最佳得分 + 其他匹配字段得分 * tie_breaker
GET /csdn_blogs/_search
{
"explain": true,
"query": {
"dis_max": {
""tie_breaker": 0.7,
"boost": 1.2,
"queries": [
{
"match": {
"FIELD": "TEXT"
}
},
{
"match": {
"FIELD": "TEXT"
}
}]
}
}
}
#会把多个字段的分词结果像一个大字段一样匹配
#适合搜索时标题和内容互补,比如标题里有 Elasticsearch,正文里有 原神,也能匹配出来
#operator:"and" 保证所有词都要匹配(跨字段组合也行)
GET /csdn_blogs/_search
{
"explain": true,
"query": {
"multi_match": {
"query": "Elasticsearch 原神",
"type": "cross_fields",
"fields": ["title^2", "content"],
"operator": "and"
}
}
}
# best_fields :最佳字段的得分,最终=其他*0.1 + 最佳,默认就是best_fields,不用指定,等价于dis_max
POST /csdn_blogs/_search
{
"query": {
"multi_match": {
"query": "原神启动",
"fields": ["title","body"],
"tie_breaker":0.2
"type":"best_fields"
}
}
}
# 取最多:most_fields:所有should撇配的字段分数相加,匹配更多字段的文档排得更前,适合多字段同时重要的情况
#直接用 bool/should,它会把多个 should 的匹配分数合起来
#全求和,每个字段对于最终评分的贡献可以通过自定值boost来控制fields:["title^10"]
GET /csdn_blogs/_explain/3
{
"query":{
"multi_match":{
"query":"讲解 原神 对比",
"type":"most_fields",
"fields":["title","content"]
}
}
}
GET /csdn_blogs/_search
{
"explain": true,
"query": {
"bool": {
"should": [
{
"match": {
"title": "Elasticsearch"
}
},
{
"match": {
"content": "原神"
}
}
]
}
}
}
# cross_fields,支持and,就把字段都必须匹配到
GET /csdn_blogs/_search
{
"explain": true,
"query": {
"multi_match": {
"query": "Elasticsearch 原神",
"type": "cross_fields",
"fields": ["title^2", "content"],
"operator": "and"
}
}
}
# copy_to 将多个字段值复制到组字段中,然后将其作为单个字段进行查询
PUT /address
{
"mappings": {
"properties": {
"province":{
"type":"keyword",
"copy_to": "full_address"
},
"city":{
"type":"text",
"copy_to": "full_address"
}
}
}
}
POST /address/_bulk
{"index":{"_index":"address","_id":1}}
{"province":"浙江省","city":"杭州市"}
{"index":{"_index":"address","_id":2}}
{"province":"广东省","city":"深圳市"}
{"index":{"_index":"address","_id":3}}
{"province":"北京市","city":"北京市"}
{"index":{"_index":"address","_id":4}}
{"province":"四川省","city":"成都市"}
# 可以搜,但是看不到,只能用于搜索,额外增加存储空间,但是省掉了multi_matc
GET /address/_search
{
"query": {
"match": {
"full_address": "浙江 杭州"
}
}
}聚合
聚合:指标聚合(count)、桶聚合(group)、管道聚合(上一次结果用于下次输入)
指标聚合(Metrics Aggregations)
→ 统计字段的最大、最小、平均、总和等指标
桶聚合(Bucket Aggregations)
→ 分组统计,比如按元素类型分组、按地区分组、按星级区间分布
管道聚合(Pipeline Aggregations)
→ 对上一步聚合的结果做二次计算,比如最大值、百分比、排序等
同级: (max/min/avg/sum) bucket/(stats/extended status)bucket /percentiles bucket
父子:derivative求导/cumultive sum累计求和/moving function 移动平均值
累计求和:cumulative_sum必须是父子关系,且父亲是histogram, date_histogram or auto_date_histogram as parent
看结果:aggregations
shell
# 聚合:指标聚合(count)、桶聚合(group)、管道聚合(上一次结果用于下次输入)
指标聚合(Metrics Aggregations)min、max、avg、sum、stats、extended_stats、percentiles
→ 统计字段的最大、最小、平均、总和等指标:# aggs/{k}/{min/max/...}
桶聚合(Bucket Aggregations)aggs/{k}/{文本terms需开启fieldata/数字range、datarange、histogram、date histogram}可以嵌套(桶里还有桶)
→ 分组统计,比如按元素类型分组、按地区分组、按星级区间分布
直方图aggs/{key}/histogram/[field,interval,extend_bounds]
管道聚合(Pipeline Aggregations)
→ 对上一步聚合的结果做二次计算,比如最大值、百分比、排序等
同级: (max/min/avg/sum) bucket/(stats/extended status)bucket /percentiles bucket
父子:derivative求导/cumultive sum累计求和/moving function 移动平均值
累计求和:cumulative_sum必须是父子关系,且父亲是histogram, date_histogram or auto_date_histogram as parent
PUT /genshin_chars
{
"mappings": {
"properties": {
"name": { "type": "keyword" },
"element": { "type": "keyword" },
"region": { "type": "keyword" },
"rarity": { "type": "integer" },
"hp": { "type": "integer" },
"atk": { "type": "integer" },
"def": { "type": "integer" }
}
}
}
POST /_bulk
{"index":{"_index":"genshin_chars","_id":1}}
{"name":"温迪","element":"风","region":"蒙德","rarity":5,"hp":10531,"atk":263,"def":669}
{"index":{"_index":"genshin_chars","_id":2}}
{"name":"钟离","element":"岩","region":"璃月","rarity":5,"hp":14495,"atk":251,"def":738}
{"index":{"_index":"genshin_chars","_id":3}}
{"name":"胡桃","element":"火","region":"璃月","rarity":5,"hp":15552,"atk":106,"def":876}
{"index":{"_index":"genshin_chars","_id":4}}
{"name":"甘雨","element":"冰","region":"璃月","rarity":5,"hp":9797,"atk":335,"def":630}
{"index":{"_index":"genshin_chars","_id":5}}
{"name":"刻晴","element":"雷","region":"璃月","rarity":5,"hp":13103,"atk":323,"def":799}
{"index":{"_index":"genshin_chars","_id":6}}
{"name":"香菱","element":"火","region":"璃月","rarity":4,"hp":10875,"atk":225,"def":669}
{"index":{"_index":"genshin_chars","_id":7}}
{"name":"行秋","element":"水","region":"璃月","rarity":4,"hp":10222,"atk":202,"def":758}
{"index":{"_index":"genshin_chars","_id":8}}
{"name":"宵宫","element":"火","region":"稻妻","rarity":5,"hp":10164,"atk":323,"def":615}
{"index":{"_index":"genshin_chars","_id":9}}
{"name":"雷电将军","element":"雷","region":"稻妻","rarity":5,"hp":12907,"atk":337,"def":789}
POST /_bulk
{"index":{"_index":"genshin_chars","_id":11}}
{"name":"琴","element":"风","region":"蒙德","rarity":5,"hp":14695,"atk":239,"def":729}
{"index":{"_index":"genshin_chars","_id":12}}
{"name":"迪卢克","element":"火","region":"蒙德","rarity":5,"hp":12981,"atk":311,"def":671}
{"index":{"_index":"genshin_chars","_id":13}}
{"name":"魈","element":"风","region":"璃月","rarity":5,"hp":12773,"atk":349,"def":799}
{"index":{"_index":"genshin_chars","_id":14}}
{"name":"阿贝多","element":"岩","region":"蒙德","rarity":5,"hp":11347,"atk":303,"def":876}
{"index":{"_index":"genshin_chars","_id":15}}
{"name":"枫原万叶","element":"风","region":"稻妻","rarity":5,"hp":13348,"atk":298,"def":753}
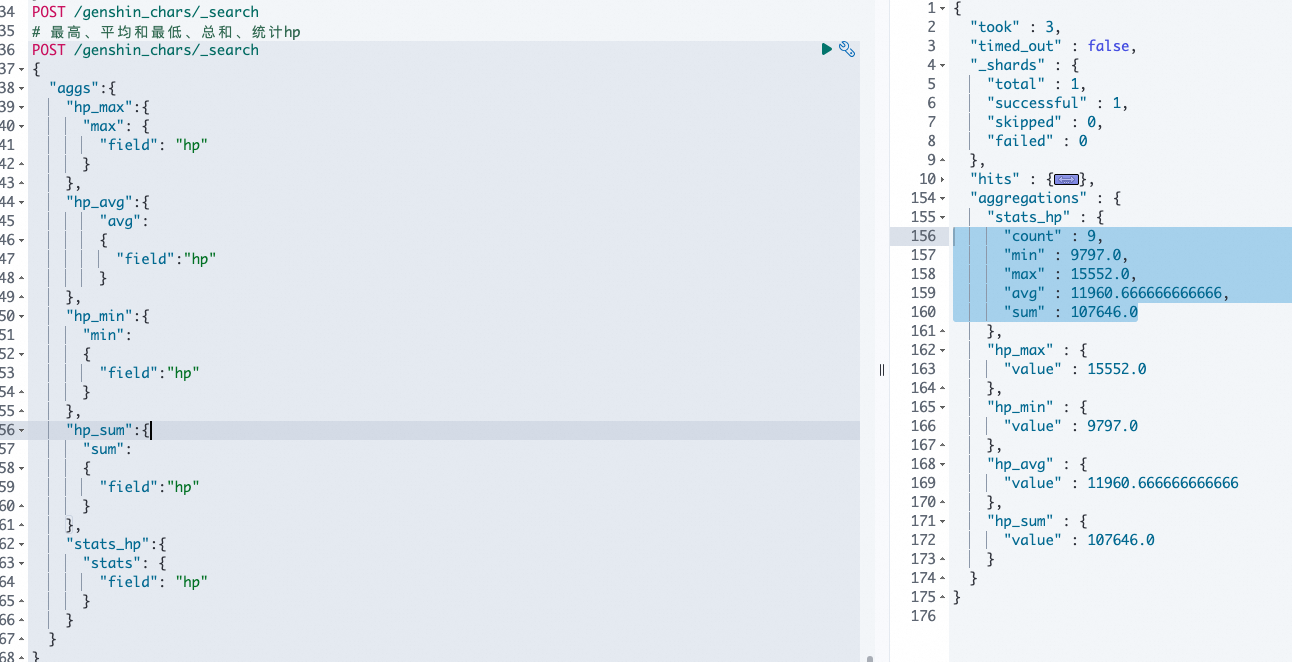
# 指标聚合:min、max、avg、sum、stats、extended_stats、percentiles
# 单值min/max/avg/sum/Cardinality(类似distinct Count)
# 多值stats/extended stats / percentile/percentile rank /top hits
POST /genshin_chars/_search
# 最高、平均和最低、总和、统计hp和按照元素去重
# size:0,可以不显示文档
GET /genshin_chars/_search
{
"size":0,
"aggs":{
"hp_max":{
"max": {
"field": "hp"
}
},
"hp_avg":{
"avg":
{
"field":"hp"
}
},
"hp_min":{
"min":
{
"field":"hp"
}
},
"hp_sum":{
"sum":
{
"field":"hp"
}
},
"stats_hp":{
"stats": {
"field": "hp"
}
},
"cardinate":{
"cardinality": {
"field": "element"
}
},
"order_elemnt":{
"terms": {
"field": "element",
"size": 3,
"order": {
"_count": "desc"
}
}
}
}
}
# aggs/{k}/stats/min/max
GET /genshin_chars/_search
{
"size": 0,
"aggs": {
"atk_stats": {
"stats": { "field": "atk" }
}
}
}
#
# agg/{k}/terms/field,size:0表示不显示字段
# 按照element进行分组
# 设置order可以进行排序
# size:可以进行显示排序后的前3条数据
GET /genshin_chars/_search
{
"size": 0,
"aggs": {
"by_element": {
"terms": {
"field": "element",
"size": 3,
"order": {
"_count": "desc"
}
}
}
}
}
# 如果text分组失败了,需要打开fieldata
PUT /csdn_blogs/_mapping
{
"properties":{
"NAME":{
"type":"text",
"fieldata":true
}
}
}
GET /genshin_chars/_search
{
"size": 0,
"aggs": {
"by_rarity": {
"terms": { "field": "rarity" },
"aggs": {
"avg_atk": { "avg": { "field": "atk" } }
}
}
}
}
# 可以设置key进行显示,默认是from-to,默认*
GET /genshin_chars/_search
{
"size": 0,
"aggs": {
"atk_ranges": {
"range": {
"field": "atk",
"ranges": [
{ "to": 200 },
{ "from": 200, "to": 300 },
{ "from": 300 }
]
}
}
}
}
# 直方图aggs/{key}/histogram/[field,interval,extend_bounds]
GET /genshin_chars/_search
{
"size":0,
"aggs": {
"test_graph": {
"histogram": {
"field": "hp",
"interval": 5000,
"extended_bounds": {
"min": 1000,
"max": 15000
}
}
}
}
}
# 各组攻击力平均值的最大值 :按照element分组,在分组里面再算平均值,根据平均值计算最大值
GET /genshin_chars/_search
{
"size": 0,
"aggs": {
"by_element": {
"terms": { "field": "element" },
"aggs": {
"avg_atk1": { "top_hits": { "sort":
[ {"atk":
{"order":"desc"}
}
] ,"size":1} }
}
}
}
}
# 指定size2,找出不同元素中血量hp最大的:先按照element分组,然后获取hp进行降序,size获取前2
POST /genshin_chars/_search
{
"size": 0,
"aggs": {
"by_element": {
"terms": {
"field": "element"
},
"aggs": {
"hp_max": {
"top_hits": {
"size": 2,
"sort": [
{
"hp":{
"order": "desc"
}
}]
}
}
}
}
}
}
# 统计各个地区hp
GET /genshin_chars/_search
{
"size":0,
"aggs": {
"state_by_region": {
"terms": {
"field": "region"
},
"aggs": {
"region_stats": {
"stats": {
"field": "hp"
}
}
}
}
}
}
# 统计各地区+各个元素的hp,嵌套3层
GET /genshin_chars/_search
{
"size": 0,
"aggs": {
"by_region": {
"terms": {
"field": "region"
},
"aggs": {
"by_element": {
"terms": {
"field": "element"
},
"aggs": {
"hp_stats": {
"stats": {
"field": "hp"
}
}
}
}
}
}
}
}
#元素分组 + 每组攻击力 & 生命值平均 + 找出攻击力平均最高的元素
GET /genshin_chars/_search
{
"size": 0,
"aggs": {
"by_element": {
"terms": { "field": "element" },
"aggs": {
"avg_atk": { "avg": { "field": "atk" } },
"avg_hp": { "avg": { "field": "hp" } }
}
},
"max_avg_atk_group": {
"max_bucket": { "buckets_path": "by_element>avg_atk" }
}
}
}
# 管道聚合-对聚合分析的结果,再次进行聚合
# 同级: (max/min/avg/sum) bucket/(stats/extended status)bucket /percentiles bucket
# 父子:derivative求导/cumultive sum累计求和/moving function 移动平均值
# 元素分组--获取组内平均攻击力--找出最高的攻击力---结果在max_avg_atk里面,结果是冰:335,stats_avg_atk统计平均攻击力的各个指标,percentiles_bucket是进行百分位统计
GET /genshin_chars/_search
{
"size": 0,
"aggs": {
"by_element": {
"terms": { "field": "element" },
"aggs": {
"avg_atk": { "avg": { "field": "atk" } }
}
},
"max_avg_atk": {
"max_bucket": { "buckets_path": "by_element>avg_atk" }
},
"stats_avg_atk": {
"stats_bucket": { "buckets_path": "by_element>avg_atk" }
},
"percentiles_avg_atk":{
"percentiles_bucket": {
"buckets_path": "by_element>avg_atk"
}
}
}
}
# 累计求和:cumulative_sum必须是父子关系,且父亲是histogram, date_histogram or auto_date_histogram as parent
POST /genshin_chars/_search
{
"size":0,
"aggs": {
"hp_histogram": {
"histogram": {
"field": "hp",
"interval": 1000,
"min_doc_count": 0
},
"aggs": {
"avg_atk": {
"avg": {
"field": "atk"
}
},
"cumulative_atk":{
"cumulative_sum": {
"buckets_path": "avg_atk"
}
}
}
}
}
}
优化





报错
- 报错说咱们集群太 low 了:
shell
# 索引文件
vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096
#线程
vim /etc/security/limits.d/20-nrpoc.conf
* soft nproc 4096
# 内存
vim /etc/sysctl.conf
vm.max_map_count=262144
sysctl -p
# 缺少节点配置
vim config/elasticsearch.yml
discovery.seed_hosts: ["127.0.0.1"]
cluster.initial_master_nodes: ["node-1
# 或者直接单节点
discovery.type: single-node