文章结尾部分有CSDN官方提供的学长 联系方式名片
关注B站,有好处!
编号: F049
视频
F049-学习水印版
1 系统简介
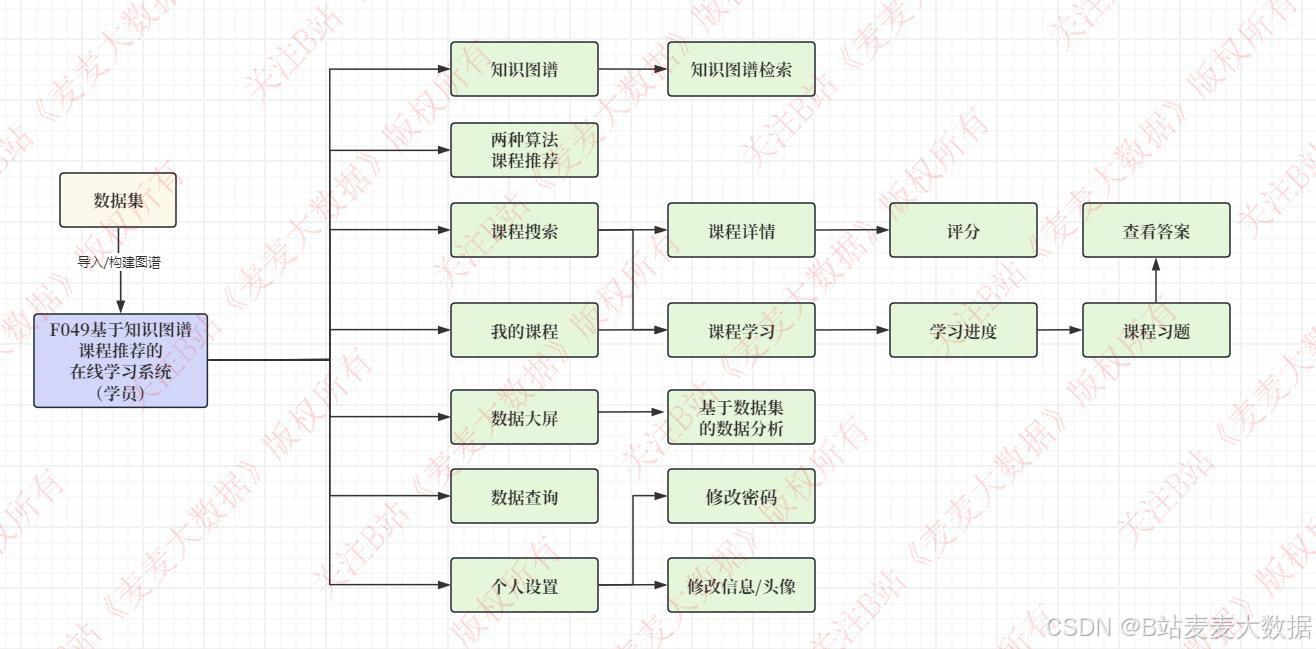
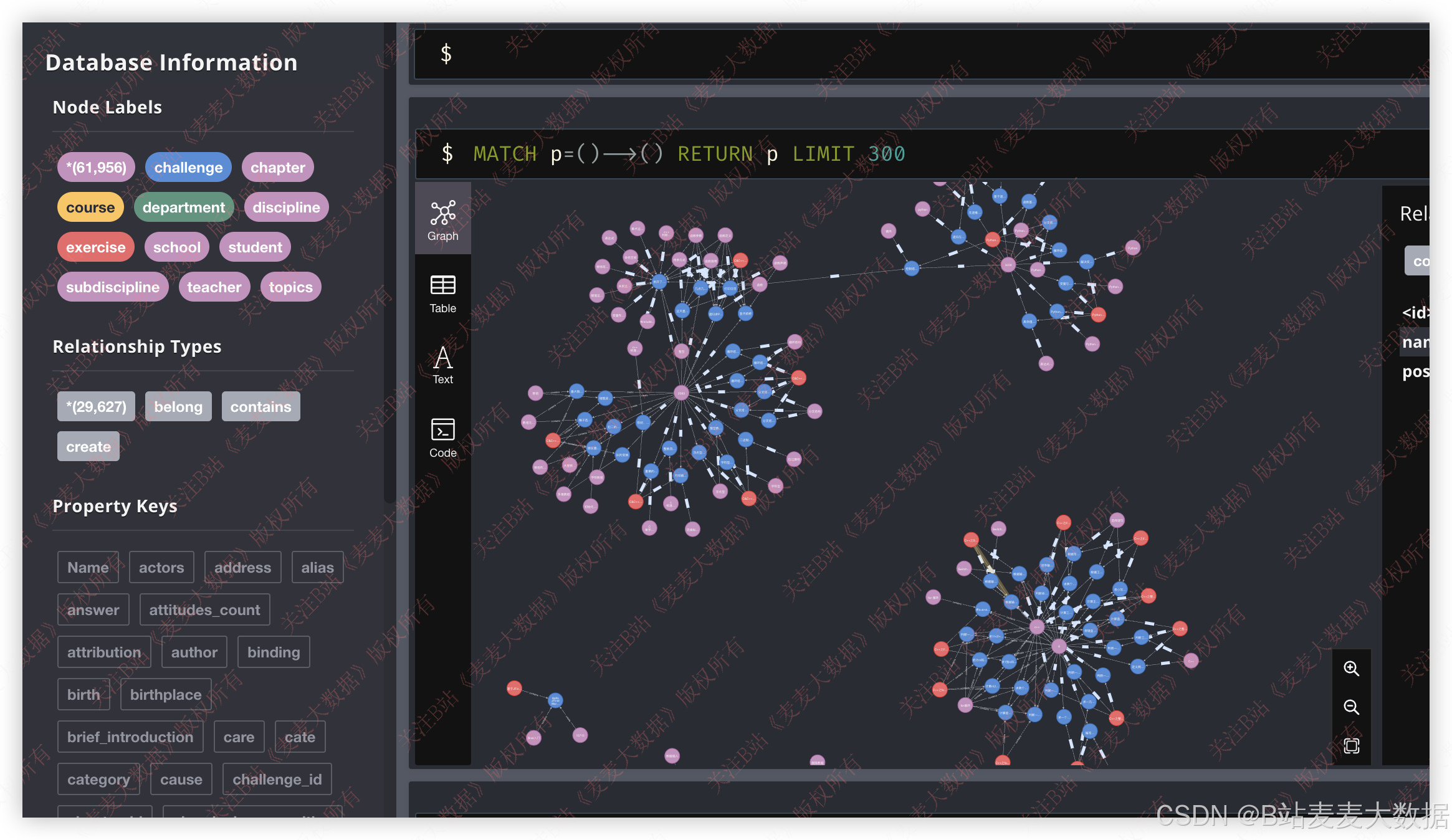
系统简介:本系统是一个基于Vue+Flask+Neo4j构建的在线学习知识图谱双算法推荐系统。其核心功能围绕知识图谱构建、课程推荐、学习管理以及用户交互展开。主要功能模块包括:课程知识图谱可视化,通过图数据库Neo4j构建课程、主题、知识点等实体的关联关系,并提供模糊搜索功能;双协同过滤推荐算法,基于用户行为和课程内容推荐相关课程;课程学习模块,支持课程浏览、习题练习、学习进度跟踪等功能;数据大屏,通过ECharts展示学习行为分析和知识点分布;用户管理模块,包含注册、登录、角色管理及权限控制;个人信息管理模块,允许用户修改个人信息、头像和密码,确保系统的安全性和个性化体验。
2 功能设计
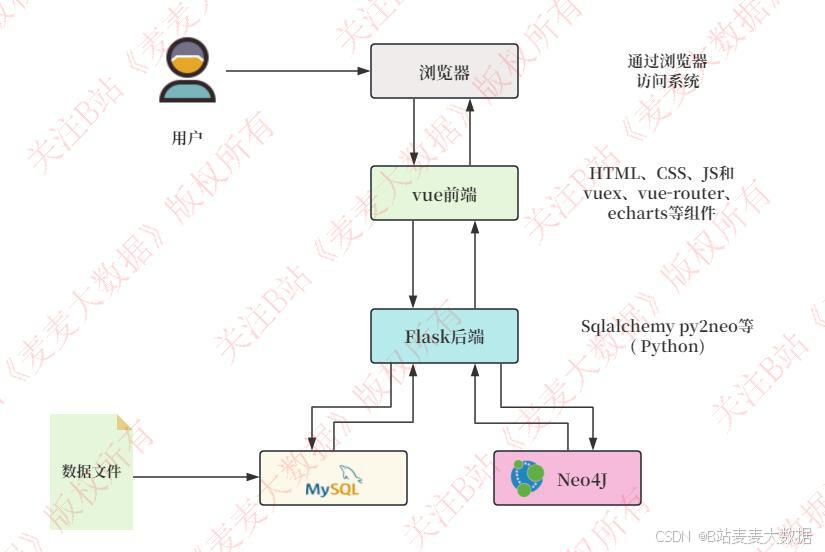
该系统采用前后端分离的B/S架构模式,基于Vue+Flask+Neo4j+MySQL技术栈实现。前端通过Vue.js框架搭建响应式界面,结合Vuetify组件库提供友好的用户交互体验,使用Vue-Router进行页面路由管理,Axios实现与后端的异步数据交互。Flask后端负责构建RESTful API服务,通过Py2neo连接Neo4j图数据库,管理知识图谱中的节点和关系,利用SQLAlchemy操作MySQL数据库存储用户信息、学习记录等结构化数据,PyMySQL作为MySQL驱动支持。系统通过JWT实现用户认证与权限控制,确保数据安全。
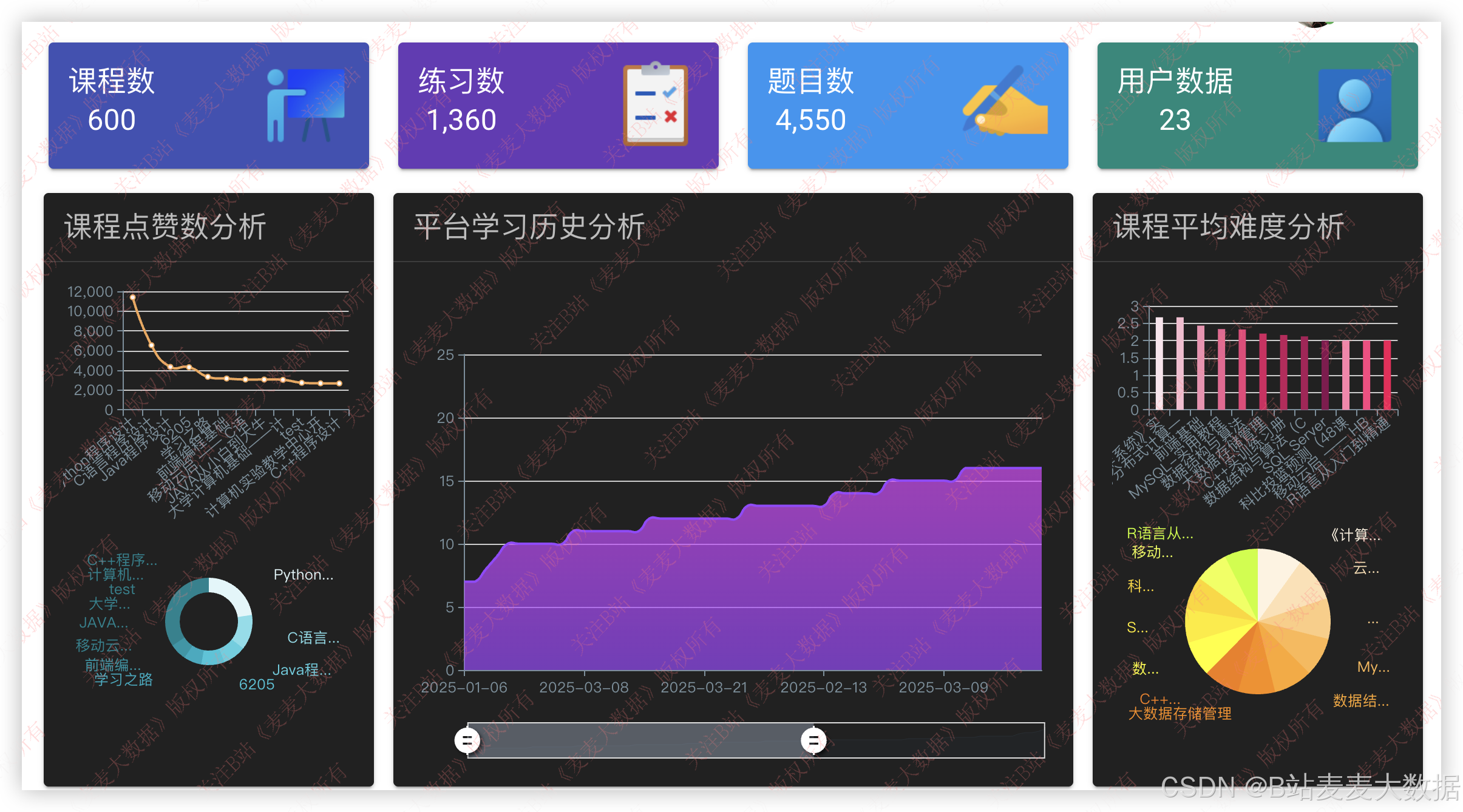
在推荐功能方面,系统采用双协同过滤算法,结合用户行为数据和课程内容特征,提供个性化的课程推荐。知识图谱构建模块从MOOC教育数据集中提取课程、主题、知识点等信息,通过Py2neo将数据导入Neo4j,构建多层次的知识网络,并支持模糊搜索和可视化展示。课程学习模块支持"添加到我的课程"、"取消学习"、"查看学习进度"等功能,学习记录同步更新MySQL和Neo4j数据库。数据分析模块通过ECharts生成数据大屏,展示学习行为和知识点关联强度等信息,为管理员提供数据支持。管理员界面实现用户管理、角色管理,个人中心支持修改信息、头像和密码,确保系统的安全性和用户体验。
2.1系统架构图
2.2 功能模块图
(用户模块 )
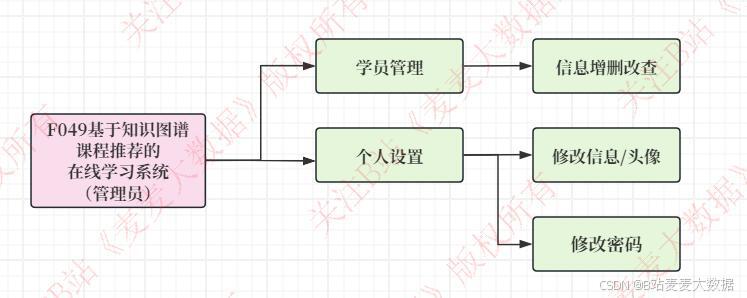
(管理员模块 )
3 功能展示
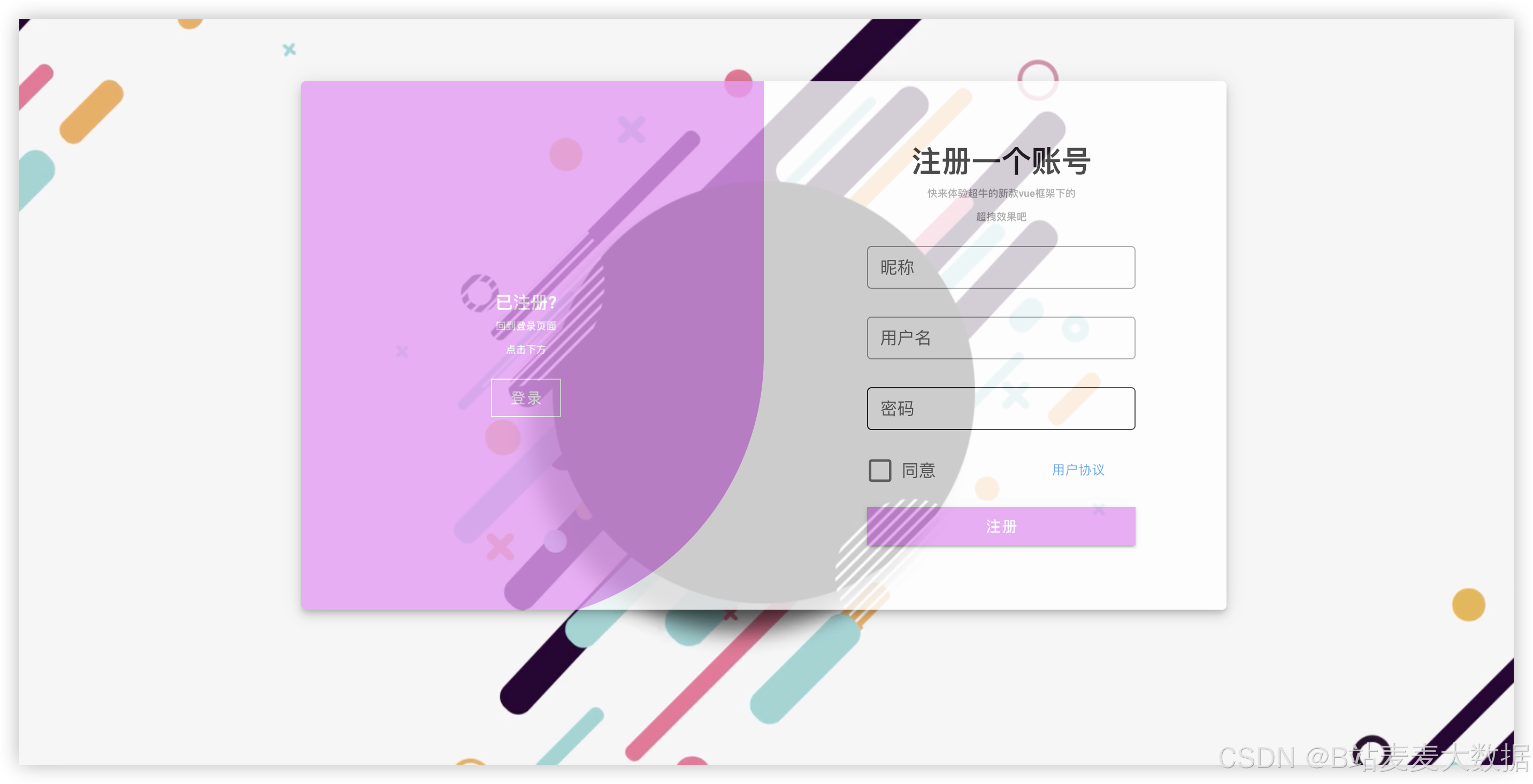
3.1 登录 & 注册
登录注册做的是一个可以切换的登录注册界面,点击去登录后者去注册可以切换。登录需要验证用户名和密码是否正确,如果不正确会有错误提示 。
注册需要验证用户名是否存在 ,如果错误会有提示。
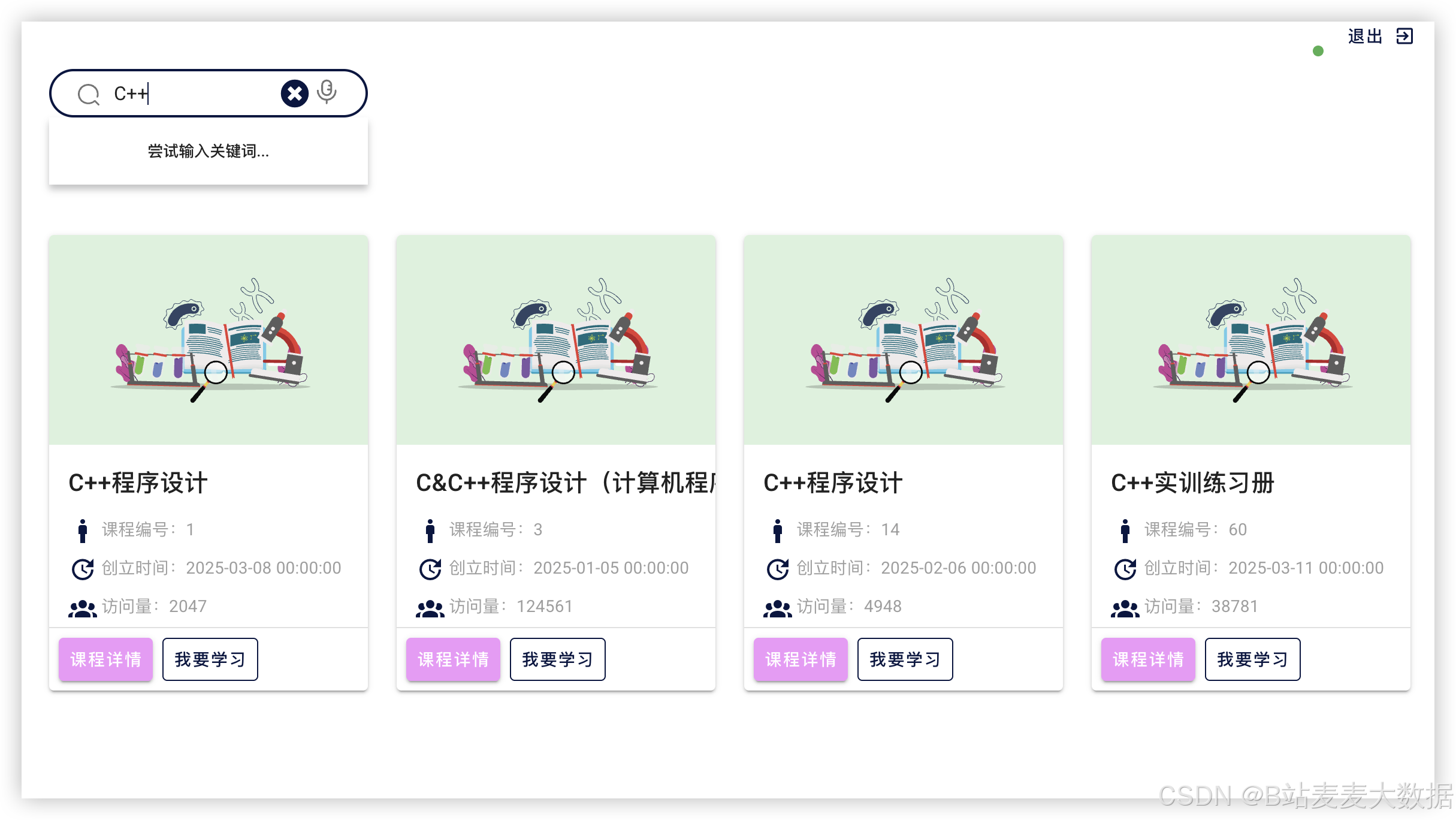
3.2 主页 & 课程搜索
主页的布局采用了左侧是菜单,右侧是操作面板的布局方法,右侧的上方还有用户的头像和退出按钮,如果是新注册用户,没有头像,这边则不显示,需要在个人设置中上传了头像之后就会显示。
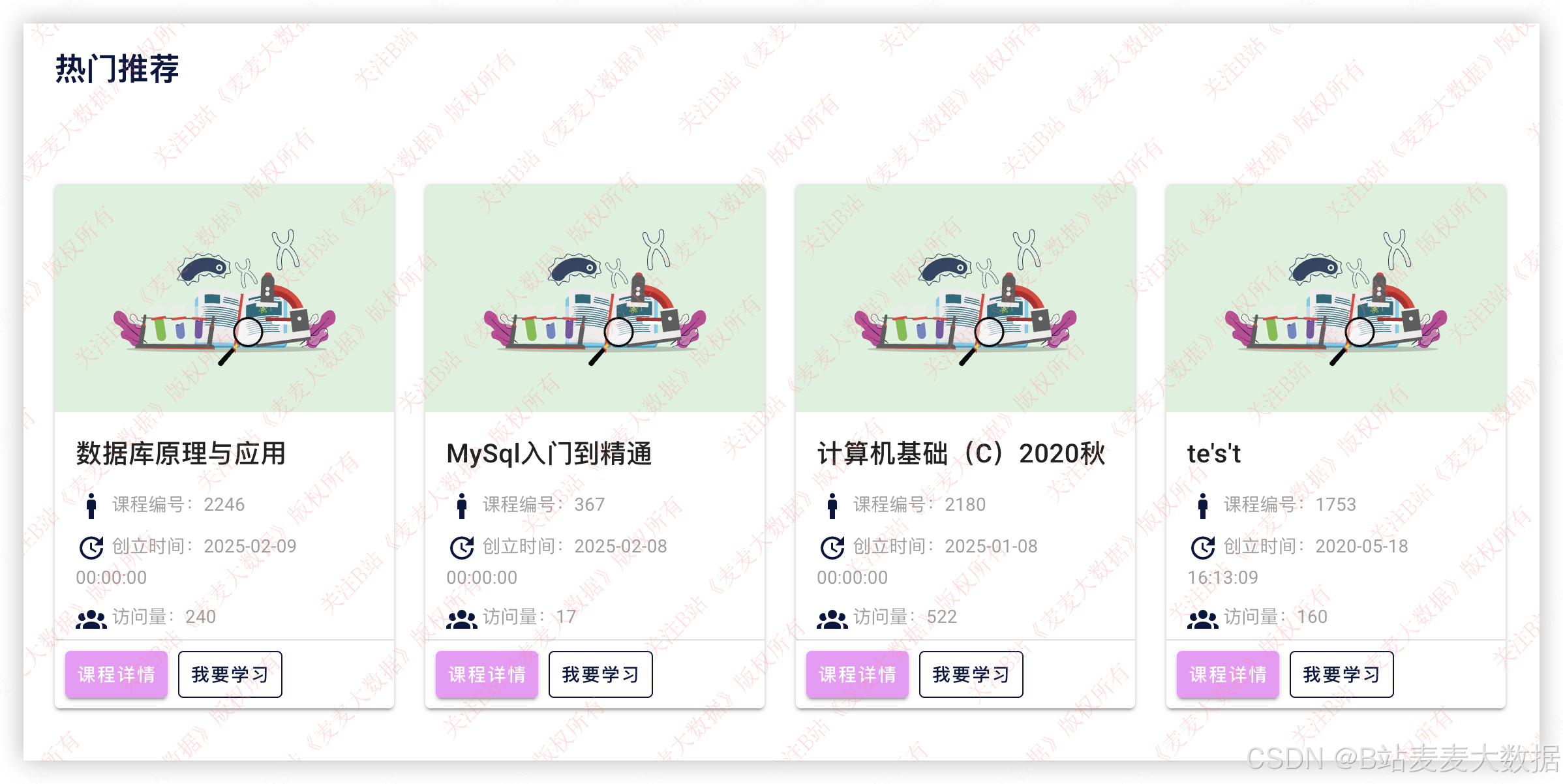
3.3 课程推荐
使用双协同过滤推荐算法UserCF+ItemCF进行课程推荐:

3.4 课程详情
在课程卡片上点击

3.5 课程学习


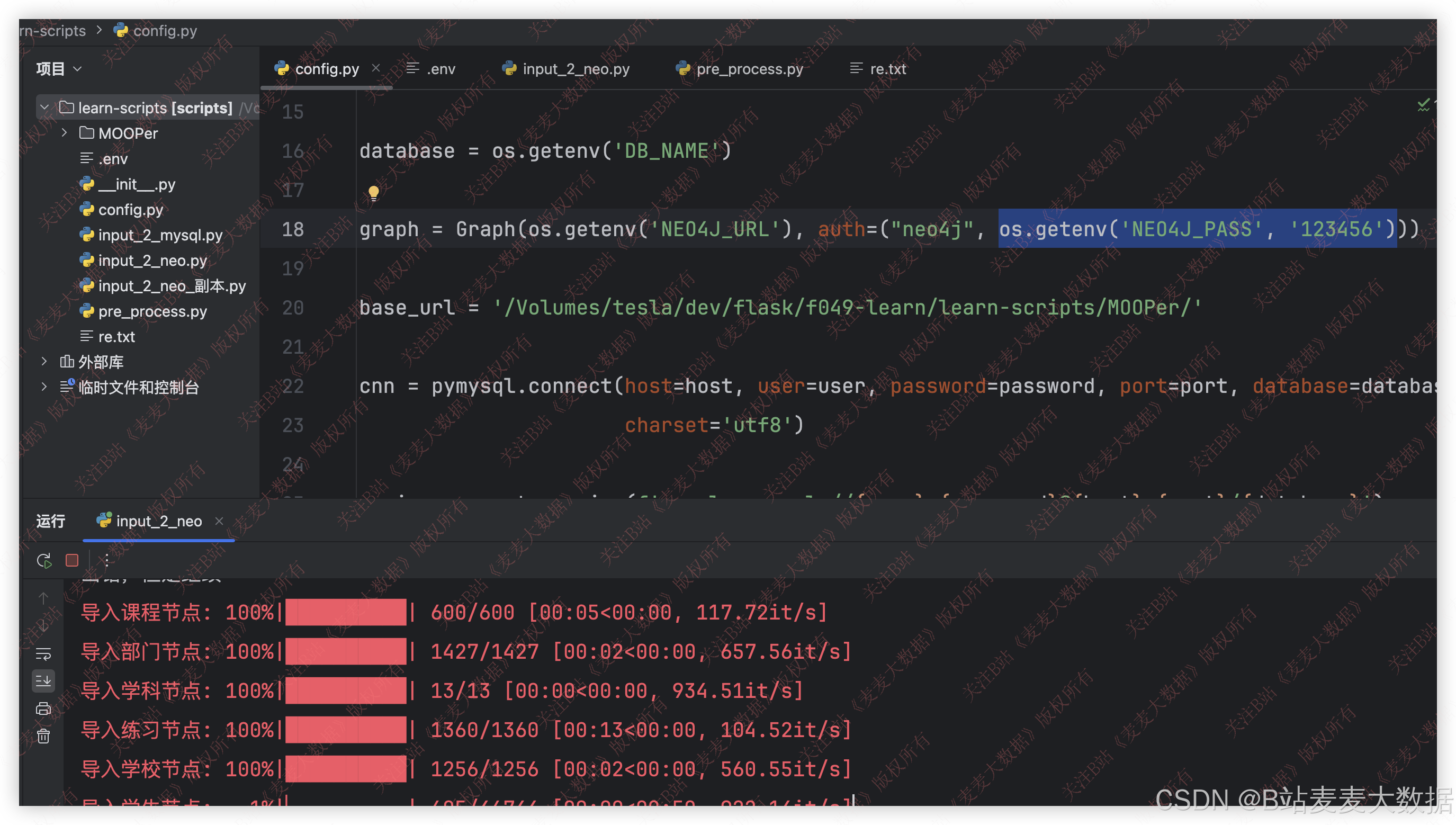
3.6 知识图谱构建
利用python代码进行知识图谱的构建
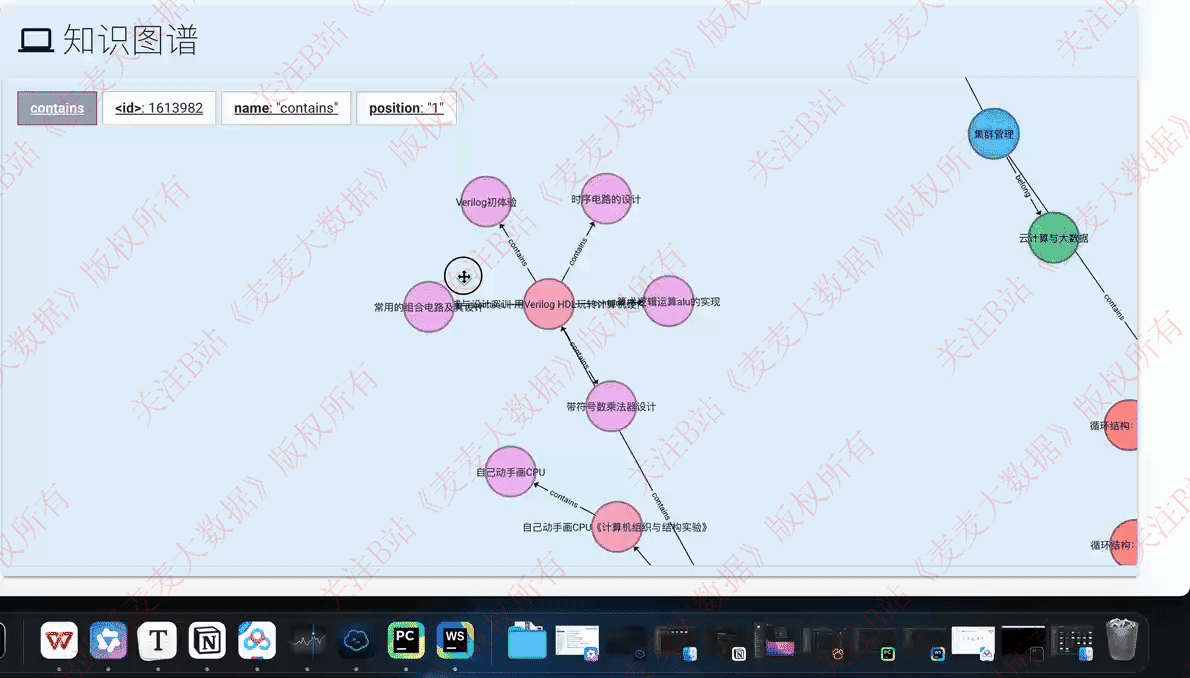
3.7 知识图谱可视化
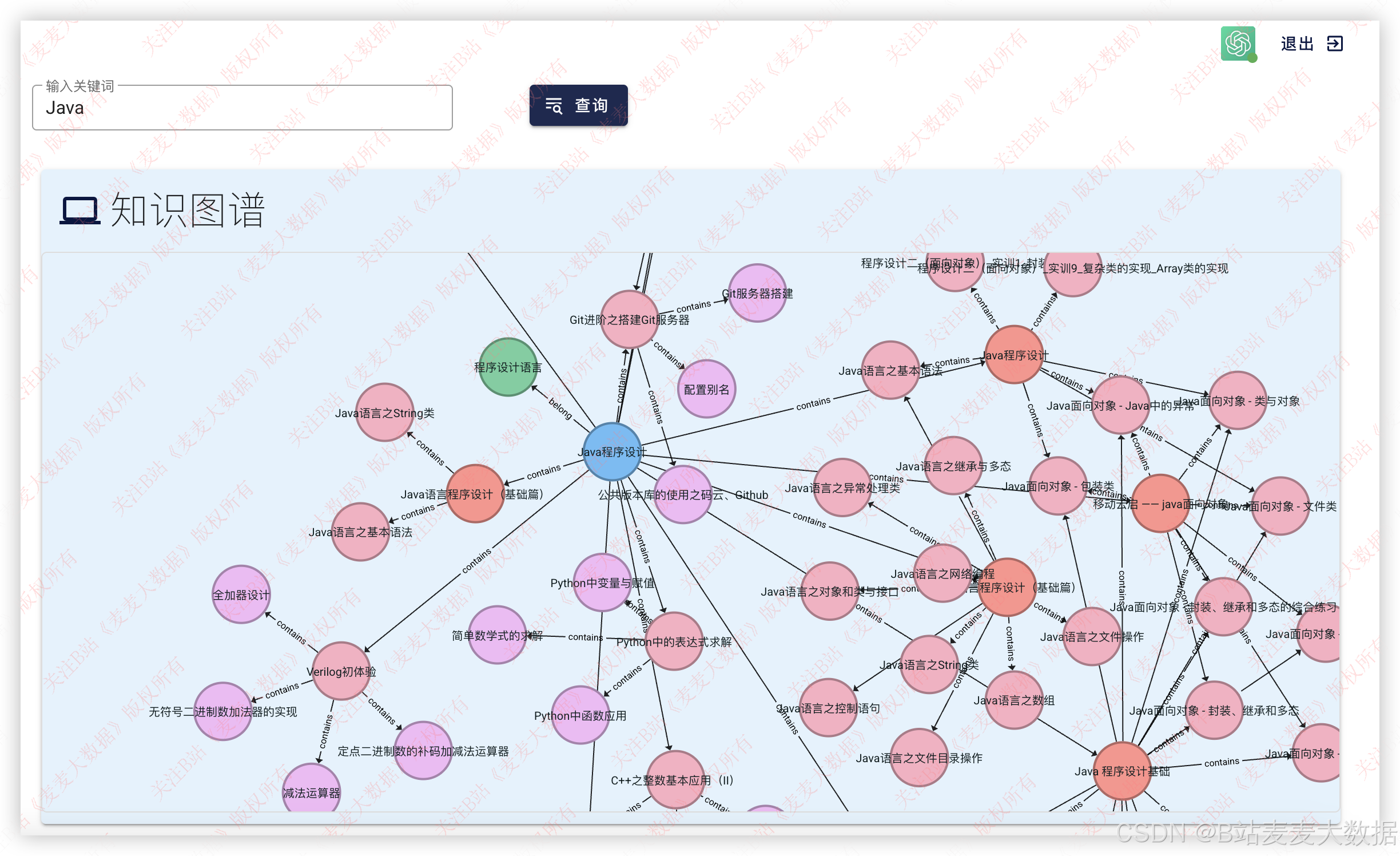
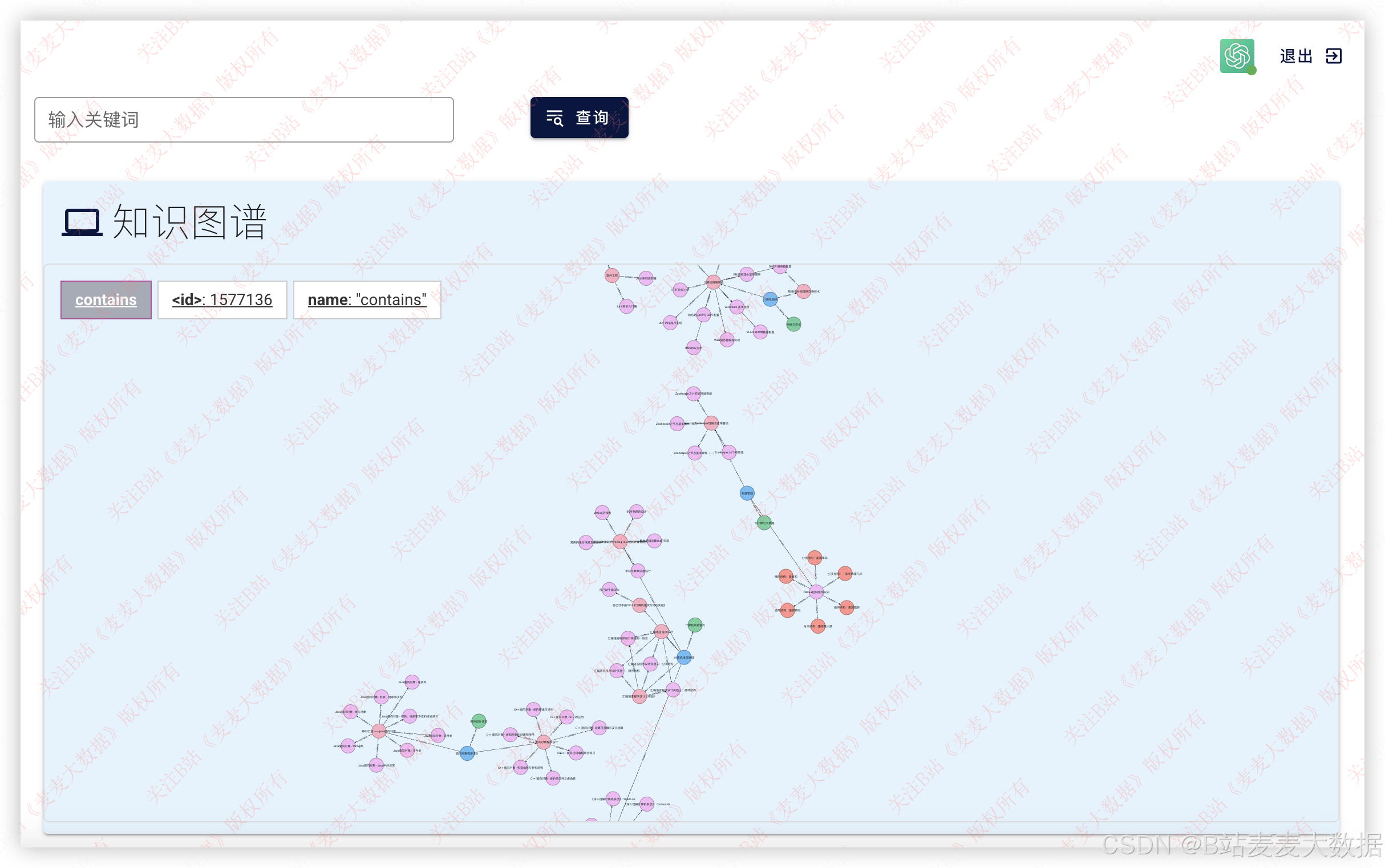
利用d3.js进行知识图谱的可视化,以下是展示效果
可以输入课程进行搜索,比如搜索Java
3.8 我的课程
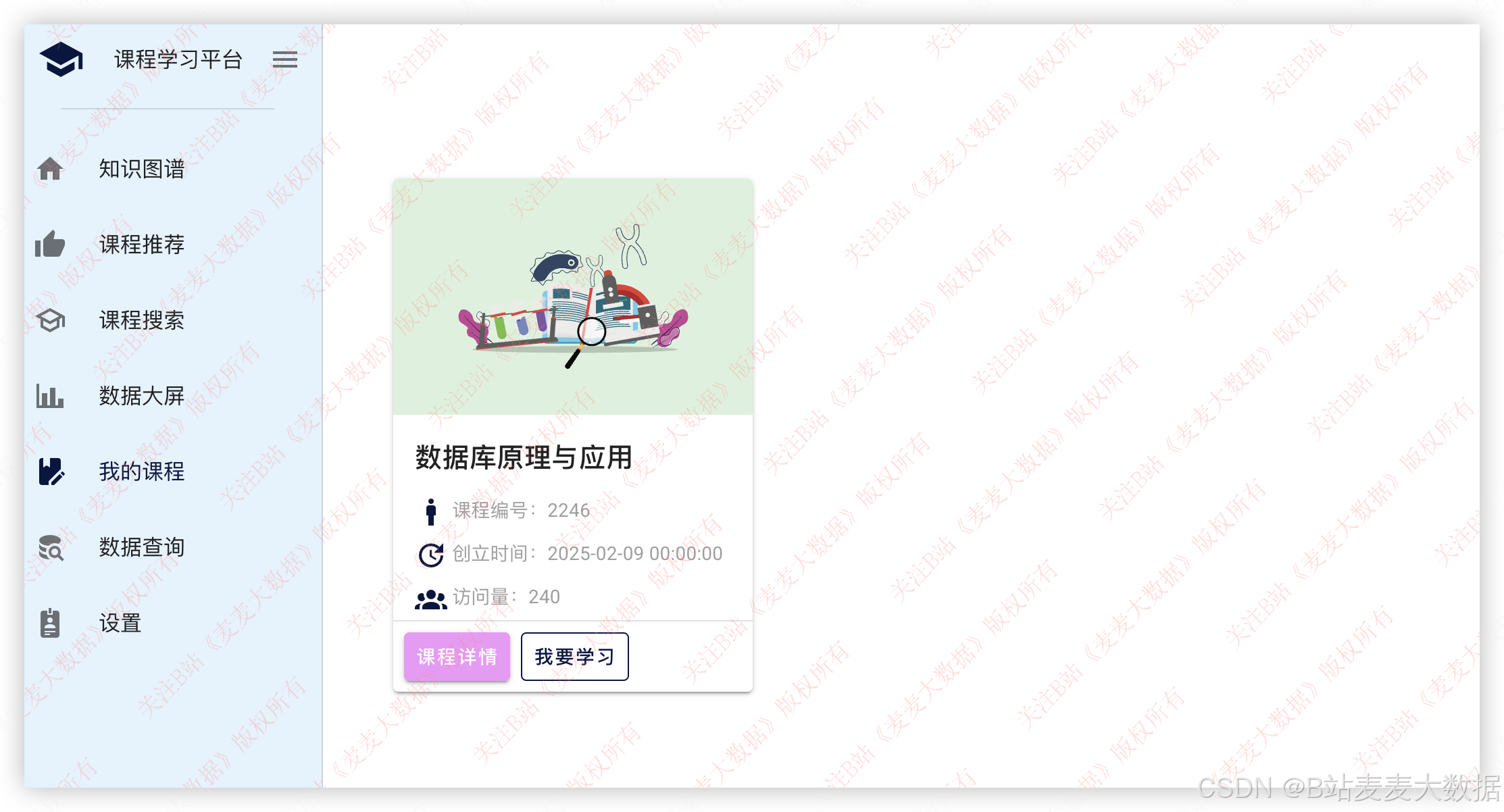
3.9 数据分析

3.10 课程表格搜索

3.11 个人设置
个人设置方面包含了用户信息修改、密码修改功能。
用户信息修改中可以上传头像,完成用户的头像个性化设置,也可以修改用户其他信息。
修改密码需要输入用户旧密码和新密码,验证旧密码成功后,就可以完成密码修改。
3.11 用户管理(管理员功能)
管理员登录后可以使用用户管理功能,可以修改用户信息,和修改用户的权限。

4程序代码
4.1 代码说明
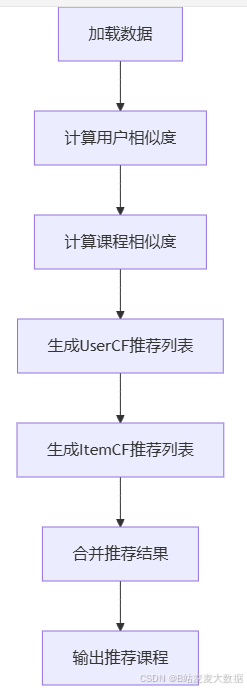
代码介绍:该推荐算法主要分为以下步骤:
加载数据:从CSV文件中加载用户-课程评分数据。
计算用户相似度:使用Jaccard相似度计算用户之间的相似度。
计算课程相似度:同样使用Jaccard相似度计算课程之间的相似度。
生成推荐列表:分别基于UserCF和ItemCF生成推荐列表,并进行加权合并。
输出推荐课程:根据最终推荐分数,输出给定数量的推荐课程。
该算法通过结合两种协同过滤方法,能够有效提升推荐的准确性和多样性。
4.2 流程图
4.3 代码实例
python
import pandas as pd
import numpy as np
def load_data():
# 加载用户-课程评分数据
data = pd.read_csv('ratings.csv')
return data
def calculate_user_sim(data, user_id):
# 计算用户与user_id的相似度
user_scores = data[data['user_id'] == user_id]['course_id']
sim_scores = []
for other_user in data['user_id'].unique():
if other_user == user_id:
continue
other_scores = data[data['user_id'] == other_user]['course_id']
# 计算Jaccard相似度
intersection = len(set(user_scores) & set(other_scores))
union = len(set(user_scores).union(set(other_scores)))
sim = intersection / union if union != 0 else 0
sim_scores.append((other_user, sim))
return sim_scores
def calculate_item_sim(data, course_id):
# 计算course_id与其他课程的相似度
course_users = data[data['course_id'] == course_id]['user_id']
sim_scores = []
for other_course in data['course_id'].unique():
if other_course == course_id:
continue
other_users = data[data['course_id'] == other_course]['user_id']
intersection = len(set(course_users) & set(other_users))
union = len(set(course_users).union(set(other_users)))
sim = intersection / union if union != 0 else 0
sim_scores.append((other_course, sim))
return sim_scores
def recommend_courses(user_id, num_recommendations=5):
data = load_data()
# 基于UserCF的推荐
user_sims = calculate_user_sim(data, user_id)
user_based_courses = []
for sim_user, sim in user_sims:
courses = data[data['user_id'] == sim_user]['course_id']
user_based_courses.extend([(course, sim) for course in courses])
# 基于ItemCF的推荐
watched_courses = data[data['user_id'] == user_id]['course_id']
item_based_courses = []
for course in watched_courses:
course_sims = calculate_item_sim(data, course)
item_based_courses.extend([(sim_course, sim) for sim_course, sim in course_sims])
# 合并推荐,权重分配:UserCF占50%,ItemCF占50%
combined = {}
for course, sim in user_based_courses:
combined[course] = combined.get(course, 0) + sim * 0.5
for course, sim in item_based_courses:
combined[course] = combined.get(course, 0) + sim * 0.5
# 生成推荐列表,排除已观看的课程
recommendations = sorted(combined.items(), key=lambda x: x[1], reverse=True)
recommendations = [course for course, _ in recommendations if course not in watched_courses]
return recommendations[:num_recommendations]
# 使用示例
recommended_courses = recommend_courses(1)
print("推荐课程:", recommended_courses)