

🔥@晨非辰Tong: 个人主页
👀专栏:《数据结构与算法入门指南》、《C++学习之旅》
💪学习阶段:C语言、数据结构与算法初学者
⏳"人理解迭代,神理解递归。"
文章目录
- 引言
- 一、梦的出发点:C++输入&&输出
-
- [1.1 一览:入门C++要知道的](#1.1 一览:入门C++要知道的)
- [1.2 关于C++要注意的](#1.2 关于C++要注意的)
- 二、缺省参数
-
- [2.1 一览:关键要点全知道](#2.1 一览:关键要点全知道)
- [三、 函数重载](#三、 函数重载)
-
- [3.1 一览:重载情况分类](#3.1 一览:重载情况分类)
- 四、引用
-
- [4.1 一览:引用的方方面面](#4.1 一览:引用的方方面面)
- [4.2 重难点:引用的使用](#4.2 重难点:引用的使用)
- [4.3 存疑的地方](#4.3 存疑的地方)
- 总结
引言
从C语言步入C++,我们正从结构化的世界迈向一个更注重抽象与效率的编程新阶段。C++在继承C语言高性能的同时,通过引入I/O流、缺省参数、函数重载和引用等核心特性,显著提升了代码的简洁性、安全性与表达能力。本节将深入解析这些构建现代C++程序的基石,为您后续探索面向对象与泛型编程打下坚实基础
一、梦的出发点:C++输入&&输出
1.1 一览:入门C++要知道的
- 核心组件
< iostream >标准库(一个头文件) ,是Input Out Stream的缩写,它是标准的输入、输出流库,定义标准的输入、输出对象,构成了C++标准I/O流库的基础框架。
- 标准流对象解析
- 输入流机制:
std::cin是istream类的对象,主要面向窄字符(char类型)的标准输入操作,建立了从部设备(键盘)到程序内部的数据通道。 - 输出流机制:
std::cout是ostream类的对象,主要面向窄字符的标准输出流,负责向标准输出设备(显示器)传输窄字符。
- 部分基础元素
- 换行 / 缓冲区控制:
std::endl,是一个函数,流插入输出时,相当于插入一个换行符+刷新缓冲区。 - 运算符多重角色扮演:
<<是流输入运算符,>>是流提取运算符。(在C语言中分别扮演了位运算左移、位运算右移的角色)。
提示: I / O流 涉及类和对象、运算符重载、继承等很多面向对象的知识 ,由于是刚刚开始接触
C++的学习,就先简单认识了I/O流的用法,后面会专门学习。
1.2 关于C++要注意的
-
使用C++的输入输出更方便,不需要像C语言的
printf/scanf输入输出时要自己设定格式。C++的输入输出能够自动识别变量的类型 (本质为函数重载)。最重要的是C++的流更好的支持自定义类型对象的输入输出。 -
cout / cin / endl等都属于C++的标准库 ,标准库放在std的命名空间中,要通过命名空间的使用方式去调用。
cpp
#include <iostream>
using namespace std;//日常联系可以
int main()
{
int a = 0;
double b = 0.1;
//输入
// 任何变量,都转换成字符串,插入到流中
cin >> a >> b;//自动识别类型
//输出
cout << a << '\n';//换行除endl也可以是'\n',"\n"
cout << a << b << endl;
return 0;
}
注意: 推荐换行使用
'\n',这样有助于提升效率,而在最后一次的输出语句是使用endl。
- 没有包含
<stdio.h>头文件,但是也可以用printf / scanf,因为被间接包含在了<iostream>中。(在VS编译器中是这样的,使用别的编译器可能报错!)
通过简单的程序观察是否不用包含<stdio.h>:
cpp
#include <iostream>
int main()
{
int a = 0;
printf("请输入:");
scanf("%d", &a);
printf("a = %d\n", a);
return 0;
}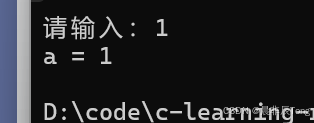
显然是它是对的!!
cpp
#include<iostream>
using namespace std;
int main()
{
//在io需求比较高的地方,如部分大量输入的竞赛题中,加上以下3行代码
//提高C++IO效率
//取消了同步流
ios_base::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
return 0;
}二、缺省参数
缺省参数又称默认参数,是声明/定义函数时将函数的参数设定为默认值 。调用函数如果没有指定实参 ,就是用默认值,反之使用实参。缺省参数分为全缺省、半缺省参数。
2.1 一览:关键要点全知道
- 全缺省参数:函数参数全部不指定实参,形参使用缺省值;半缺省参数:函数指定部分实参,其余使用缺省参数。
- C++规定,半缺省参数必须从右往左依次连续缺省,不能间隔给缺省值。
- C++:调用带缺省参数的函数,必须从左往右依次给实参,不能间隔指定。
- 函数的声明、定义分离时,规定缺省参数只能在函数声明给出。
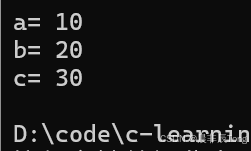
- 演示全缺省:
cpp
//全缺省
#include <iostream>
using namespace std;
void func1(int a = 10, int b = 20, int c = 30)
{
cout << "a= " << a << '\n';
cout << "b= " << b << '\n';
cout << "c= " << c << endl;
}
int main()
{
func1();
return 0;
}
- 演示半缺省:
(缺省参数必须从右往左连续缺省,传参必须从左往右连续传参,不能跳跃!)
- 正确使用
cpp
//半缺省
#include <iostream>
using namespace std;
void func1(int a = 10, int b = 20, int c = 30)
{
cout << "a= " << a << '\n';
cout << "b= " << b << '\n';
cout << "c= " << c << endl;
}
int main()
{
func1(1, 2);
return 0;
}- 错误使用
cpp
#include <iostream>
using namespace std
//缺省参数设置正确
void func1(int a = 100, int b = 210, int c = 310)
{
cout << "a= " << a << '\n';
cout << "b= " << b << '\n';
cout << "c= " << c << endl;
}
int main()
{
//传实参错误:跳跃
//func1(1, ,2);
return 0;
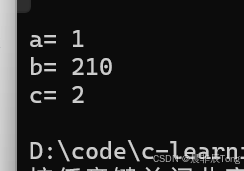
}在传参时,如果想让第二个参数 b 为缺省参数,因为不能跳跃传参,那么可以调换缺省参数的顺序:
cpp
#include <iostream>
using namespace std
void func1(int a = 100, int c = 310, int b = 210)
{
cout << "a= " << a << '\n';
cout << "b= " << b << '\n';
cout << "c= " << c << endl;
}
int main()
{
func1(1, 2);
return 0;
}
当然,缺省参数的使用在前面学习的数据结构中同样有作用
三、 函数重载
函数重载:C++允许在同一个作用域中定义同名函数,但是要求参数不同(个数不同/类型不同)。
3.1 一览:重载情况分类
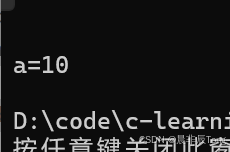
- 参数个数不同:
cpp
#include <iostream>
using namespace std;
void func()
{
cout <<' ' << endl;
}
void func(int a)
{
cout << "a=" << a << endl;
}
int main()
{
func();
func(10);
return 0;
}
这里要注意:对于个数不同的,最好不要使用缺省参数!! 会导致调用歧义,编译器不知道调用哪个函数。
cpp
#include <iostream>
using namespace std;
void func1()
{
cout <<' ' << endl;
}
void func1(int a = 10)
{
cout << "a=" << a << endl;
}
int main()
{
//func();
/?func(10);
return 0;
}
- 参数类型不同:
cpp
#include <iostream>
using namespace std;
int Add(int a, int b)
{
return a + b;
}
double Add(double a, double b)
{
return a + b;
}
int main()
{
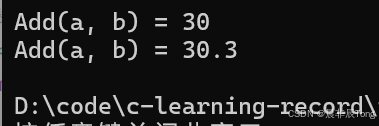
cout << "Add(a, b) = " << Add(10, 20) << '\n';
cout << "Add(a, b) = " << Add(10.1, 20.2) << endl;
return 0;
}
- 参数顺序不同:
cpp
#include <iostream>
using namespace std;
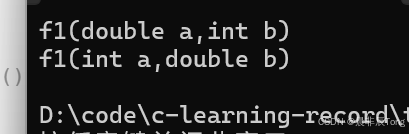
void func1(double a, int b)
{
cout << "f1(double a,int b)" << '\n';
}
void func1(int a, double b)
{
cout << "f1(int a,double b)" << '\n';
}
int main()
{
//编译器会根据传参的顺序来调用对应函数
func1(2.3, 1);
func1(1, 2.3);
return 0;
}
- 返回条件不同不能构成函数重载,调用歧义
cpp
#include<iostream>
using namespace std;
void func2()
{
}
int func2()
{
return 1;
}
int main()
{
//调用时无法确定调用那个
func2();
int x = func2();
return 0;
}
四、引用
4.1 一览:引用的方方面面
- 概念及定义:
引用不是重新定义变量 ,而是给已经定义的变量起一个别名(编译器不会为引用变量开辟内存空间,共用同一块)。
形式:类型& 引用别名 = 引用对象;
C++中为了避免引入太多的运算符,会复用C语言的⼀些符号,比如
<<,>>,引用也和取地址使用了同⼀个符号&,注意使用方法角度来区分。
- 引用的特性:
- 引用在定义时必须初始化。
- ⼀个变量可以有多个引用。
- 引用一旦引用一个实体,再不能引用其他实体。
cpp
#include<iostream>
using namespace std;
int main()
{
int i = 10;
//引用:j是i的别名
int& j = i;
//多个引用
int& k = i;
//给别名取别名
int& a = j;
//看地址
cout << &i << '\n';
cout << &j << '\n';
cout << &k << '\n';
cout << &a << endl;
return 0;
}
(观察地址都是一个变量!)
cpp
#include<iostream>
using namespace std;
int main()
{
//未初始化引用
int& j;
cout << j << endl;
return 0;
}
cpp
#include<iostream>
using namespace std;
int main()
{
int a = 10;
int& b = a;
//再次引用其他变量相当于赋值
int c = 20;
b = c;
cout << "b=" << b << endl;
return 0;
}
4.2 重难点:引用的使用
- 引用的主要实践用途是通过引用传参和引用返回来减少数据拷贝提高效率 ,以及在修改引用对象时同步改变被引用的原对象。(引用返回值相对复杂,先简单了解。)
- 引用传参跟指针传参功能是类似的,引用传参相对更方便⼀些。
- 引用和指针相辅相成,并不能完全替代。
- 引用传参------>代替指针(大部分情况引用可以代替指针)
cpp
void Swap(int* a, int* b)
{
if (*a > *b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
}
void Swap(int& rx, int& ry)
{
if (rx > ry)
{
int tmp = rx;
rx = ry;
ry = tmp;
}
}
int main()
{
int x = 2;
int y = 1;
Swap(&x, &y);
cout << x << ' ' << y << '\n';
Swap(x, y);
cout << x << ' ' << y << '\n';
return 0;
}
在逻辑上,
rx,ry是x,y的别名,本质上就是x,y,所以交换rx,ry就是交换x,y。对于函数传参时,引用的初始化:因为只有调用函数才会定义引用,传参就相当于赋值
int& rx = x, int& ry = y。
- 一级指针的引用:
cpp
#include<iostream>
using namespace std;
void swap(int** x, int** y)
{
int* tmp = *x;
*x = *y;
*y = tmp;
}
void swap(int*& x, int*& y)
{
int* tmp = x;
x = y;
y = tmp;
}
int main()
{
//swap函数交换指针
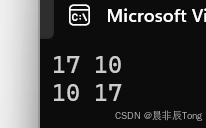
int a = 10; int b = 17;
int* pa = &a; int* pb = &b;
swap(&pa, &pb);//用指针
cout << *pa << " " << *pb << '\n';
swap(pa, pb);//用引用
cout << *pa << " " << *pb << '\n';
return 0;
}
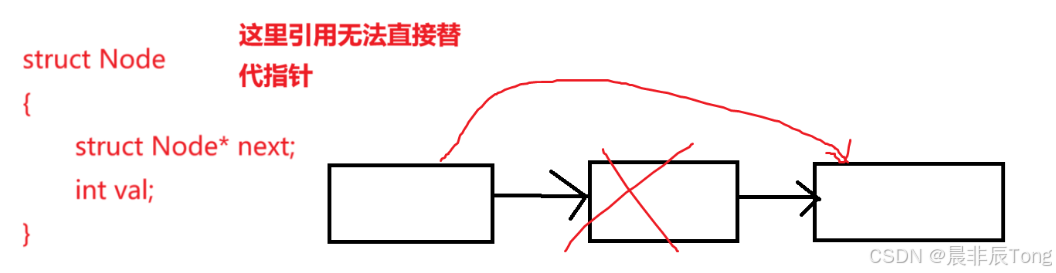
对于链表、树等,节点定义位置,只能使用指针。因为C++的引用无法改变指针指向,但是节点一定存在改变指向的情况。
- 引用返回值:
- 先看传值返回
cpp
#include<iostream>
using namespace std;
//传值返回
int func()
{
int ret = 0;
//...
return ret;
}
int main()
{
int x = func();
//func() += 1;
return 0;
}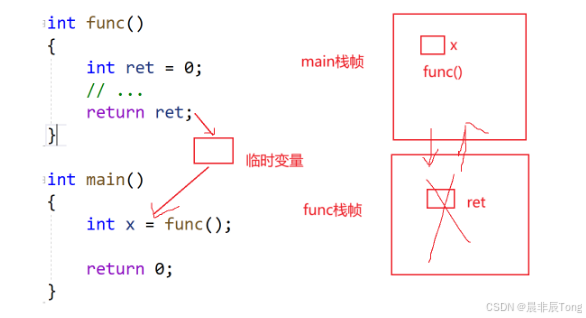
看传值返回,func函数返回的其实ret的一个拷贝(相当于临时变量),调用结束,函数销毁,看下面的func() += 1;就会报错。
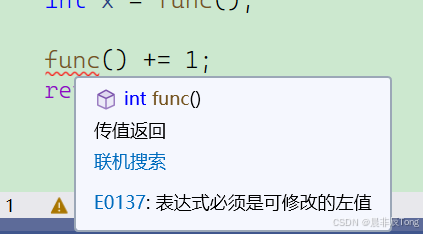
- 对比看传引用返回
cpp
#include<iostream>
using namespace std;
//传引用返回
int& func()
{
int ret = 0;
//...
return ret;
}
int main()
{
int x = func();
cout << x << endl;
return 0;
}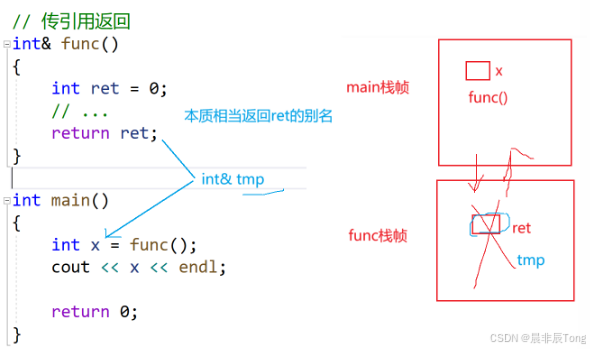
看传引用返回,实际上函数返回的是ret的别名(比如tmp)。与传值返回不同的是,函数销毁后,将空间返回操作系统(但仍然指向这块空间),如果别人对空间进行操作,就会改变,这是就相当于野指针的访问!很危险!!

- 验证上面说法:
一个很奇怪的结果:
cpp
#include<iostream>
using namespace std;
int& func1()
{
int ret = 0;
//...
return ret;
}
int& func2()
{
int y = 123;
//...
return y;
}
int main()
{
int& x = func1();
cout << x << endl;
func2();
cout << x << endl;
return 0;
}
可以看到,我们并没有修改x的值,为什么再次输出x确是y的数值?
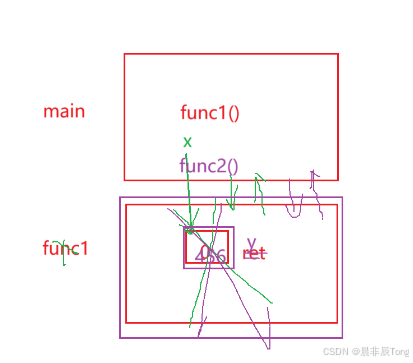
已经知道,函数销毁后,将空间返回给操作系统(但是别名x仍然指向这块空间),意味着这块空间可以分配给其他操作 。那么新创建的函数就会在这块空间上,又因为故意的将两个函数结构写的类似,代表二者的栈帧一样大 。
既然栈帧一样大,x就会接收func2返回的别名,也就是y的值。
4.3 存疑的地方
- 传引用返回相当于野指针访问,为什么不报错?
要知道,越界不一定报错! 数组的越界存在 越界抽查。越界抽查:在临近数组结束的位置进行检查。
- 越界读:没事
cpp
int main()
{
int a[10];
//越界读:没事
a[10];
return 0;
}
- 越界写:有事
cpp
int main()
{
int a[10];
//越界写:有事
a[11] = 1;
a[15] = 1;
return 0;
}
总结
html
🍓 我是晨非辰Tong!若这篇技术干货帮你打通了学习中的卡点:
👀 【关注】跟我一起深耕技术领域,从基础到进阶,见证每一次成长
❤️ 【点赞】让优质内容被更多人看见,让知识传递更有力量
⭐ 【收藏】把核心知识点、实战技巧存好,需要时直接查、随时用
💬 【评论】分享你的经验或疑问(比如曾踩过的技术坑?),一起交流避坑
🗳️ 【投票】用你的选择助力社区内容方向,告诉大家哪个技术点最该重点拆解
技术之路难免有困惑,但同行的人会让前进更有方向~愿我们都能在自己专注的领域里,一步步靠近心中的技术目标!结语:
C++的基础特性为我们打开了现代化编程的大门:I/O流以更自然的方式处理输入输出,缺省参数让函数调用更加灵活,函数重载通过参数差异实现接口统一,而引用机制则在安全性与效率间找到平衡。掌握这些核心概念,不仅是理解C++设计哲学的关键,更是后续探索面向对象、模板元编程等高级特性的坚实基础。从C到C++的升级,正是从"如何实现"到"如何优雅高效地实现"的思维跃迁。
源码参考: 【https://gitee.com/tian-aochen/c-learning-record/tree/master/test_11.21_C++入门/Basics】
