Keye-VL-671B-A37B 正式发布!作为快手新一代旗舰多模态大语言模型,在保持基础模型强大通用能力的前提下,对视觉感知、跨模态对齐与复杂推理链路进行了系统升级,实现了多模态理解和复杂推理的全方位性能跃升:更会"看"、更会"想"、也更会"答"。无论是日常场景还是高难任务,都能给出更准确、更稳健的回应。下面用两个直观例子,带你快速感受它的能力。
**图像语义理解更可靠。**下面的图中有几张电影票?大多数人看完第一眼都会说:"三张。"

但仔细一看,其实只有两张电影票,最上面那一张是爆米花小吃券,我们人很容易被这样的"视觉"错觉所蒙蔽。而 Keye-VL 却能很好地克服这个问题,它不仅能识别画面中每一张票的文字、标识和版式差异,还会进一步推理:左边和中间的票符合电影票特征,而右侧的一张票只是叠放的食品券,无座位或影片场次信息,属于小吃兑换券,非电影票。于是,它给出的结论是:"这里实际上只有两张电影票。"

这就是模型的优势:它不仅"看得清",还能"想得明白"。在复杂、嘈杂的真实场景中,它能够综合视觉细节和上下文信息,甚至能做出比人类更严谨、更可靠的判断。
**视频细节把握更精准。**除了图像理解能力以外,最新的 Keye-VL 同样拥有强大的视频理解和感知能力。下面我们来看看 Keye-VL 对于复杂视频信息的表现。
问题:"视频的镜头是怎样变化的?"
Keye-VL 在思考后,首先分析视频中的元素:"蓝色双层电车"、"周边建筑:Louis Vuitton、Tiffany & Co."等,随后给出了镜头变化信息:"视频镜头从高角度固定位置出发,缓慢向右侧旋转,保持视角高度不变,逐步展示更广阔的中环夜景街道,持续捕捉车辆流动、周边建筑与行人动态,突出城市夜景的繁忙活力。"

这说明 Keye-VL 对视频里的物体和时序信息把握非常准,即使视频过程复杂、信息密集,模型也能抓住所有关键点,不仅能识别出车辆信息,甚至还能发现"Louis Vuitton"等建筑,最终得出"缓慢向右侧旋转"的结论。
目前,Keye-VL-671B-A37B 已经正式开源,欢迎下载体验:
Github: github.com/Kwai-Keye/K...
HuggingFace: huggingface.co/Kwai-Keye/K...
技术更新
模型结构
Keye-VL-671B-A37B 采用 DeepSeek-V3-Terminus 作为大语言模型基座初始化,具备更强的文本推理能力,视觉模型采 KeyeViT 初始化,来自 KeyeVL1.5,二者通过 MLP 层进行桥接。
预训练
Keye-VL-671B-A37B 的预训练涵盖三个阶段,系统化构建模型的多模态理解与推理能力。我们复用 Keye-VL-1.5 的视觉编码器,该编码器已经通过 8B 大小的模型在 1T token 的多模态预训练数据上对齐,具备强大的基础感知能力。结合严格筛选的约 300B 高质量数据预训练数据,以有限计算资源高效构建模型的核心感知基础,确保视觉理解能力扎实且计算成本可控。
在第一阶段,冻结 ViT 和 LLM,只训练随机初始化的 Projector,保证视觉、语言特征能初步做对齐。在第二阶段,我们打开全部参数进行预训练。第三阶段会在更高质量的数据上做退火训练,提升模型的细粒度感知能力。Keye 多模态的预训练数据构建,通过自动化数据管道实施严格的过滤、重采样与 VQA 数据增强,覆盖 OCR、图表及表格等多种格式,端到端提升模型的感知质量与泛化能力;在退火阶段,使用 DeepSeek-V3-Terminus 合成思维链数据,使模型在深化感知训练的同时保持 LLM 原有的强大推理能力。
后训练
Keye-VL-671B-A37B 的后训练由监督微调,冷启动和强化学习三个步骤组成,训练任务涵盖视觉问答、图表理解、富文本 OCR、数学、代码、逻辑推理等。在 SFT 阶段,采用更多多模态和纯文本的长思维链数据,对模型的纯文本能力进行回火并增强多模态能力。在冷启动阶段,采用推理数据增强模型的推理能力,在强化学习阶段,采用复杂推理数据提升模型的 think 和 no_think 能力,并加入视频数据,增强模型的视频理解能力。
监督微调
在监督微调阶段,技术团队对数据集中指令(Instruct)数据和长思维链(Long-CoT)数据的配比进行反复实验,突破了此前监督微调范式片面依赖指令数据的局限性,验证了混合模式( Instruct + Long-CoT)相对于单一模式(Instruct)的优越性,即在 SFT 数据集中加入更多长思维链推理数据有利于提升模型整体性能,以及改善后续训练稳定性:
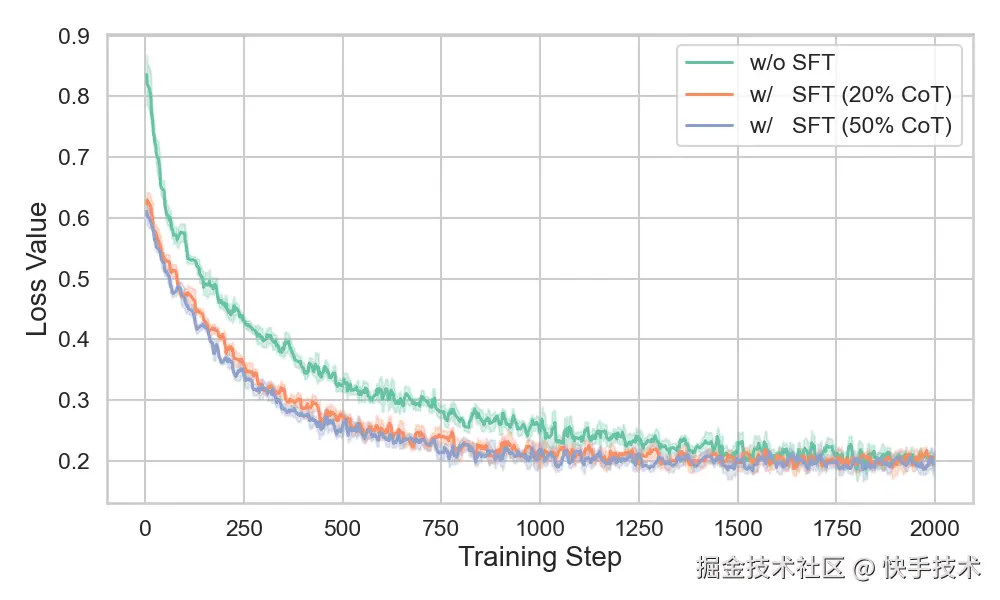
loss 曲线显示,在 SFT 阶段加入更多的 CoT 数据可以显著降低冷启动阶段的训练 loss,在多个 benchmark 上的性能对比也表明,混合 CoT 数据训练的模型相比于指令微调的模型取得了明显的性能提升。
冷启动
在冷启动阶段,CoT 数据的质量对于提升模型的推理能力至关重要,而纯文本模型的推理过程往往冗长而且存在大量重复,为了缓解过度思考的问题,技术团队开发了严格的数据筛选流程,过滤掉存在冗余反思行为的思维链。

在 Keye-VL-1.5-8B 上的实验结果显示,过滤冗余数据对于模型的推理能力和感知能力均有增益。
强化学习
**底层强化学习算法。**传统的 GRPO 强化学习算法是 token-level 的建模,在训练 MoE 模型时存在不稳定性。在 Keye-VL-671B 的训练中,我们采用 GSPO(Group Sequence Policy Optimization)作为底层强化学习算法,进行 sequence-level 的建模,提升可验证奖励强化学习(RLVR)训练的稳定性。
**验证器奖励信号增强。**著名的验证者定律指出:训练 AI 解决一个任务的难易程度,与该任务的可验证性成正比。对于强化学习而言,奖励信号的质量至关重要。在 Keye-VL-671B 的 RL 系统中,我们首先训练了专门的验证器(Verifier)用于验证模型输出思考过程的逻辑性,以及最终答案与标准答案的一致性,Verifier 模型采用 Keye-VL-1.5 8B 作为基座,训练过程包括 SFT 和 RL 两个阶段,在 SFT 阶段,既有简单的二分类任务,即直接判断生成的答案是否与参考答案一致,也有更复杂的分析任务,需要模型采用 think-answer 的格式分析模型生成的回复的逻辑性和正确性。在 RL 阶段,首先在大规模偏好数据上训练,然后利用人工标注的高质量数据集进行退火,提高 Verifier 模型的精度。
为了验证 Verifier 模型对于生成结果的检测精度,我们抽取了 10,000 条训练数据以及模型生成的答案,对比 Verifier 模型和 Qwen-2.5-VL 72B Instruct 模型的检测精度,在人工抽样的 150 条 Keye Verifier 与 Qwen 判别结果不一致的数据中,Keye 正确的数目达到了 128 条,而 Qwen 仅占 22 条。基于 Keye-VL-preview 的预实验显示,Keye-Verifier 提供的奖励信号相对于基于规则匹配的奖励信号使 Keye-VL-preview 在多个通用多模态评测基准上的平均准确率提升了 1.45%,在三个多模态数学数据集上的平均准确率提升了 1.33%。
为了筛选高难度样本,我们利用 Keye-VL-1.5-8B 作为过滤器,在候选数据集上采样并用 Verifier 模型计算准确率,仅保留正确率在 25%~75%之间的数据用于训练。在 RL 数据集中,我们加入了更多视频数据以提升模型的视频理解能力。
模型评估
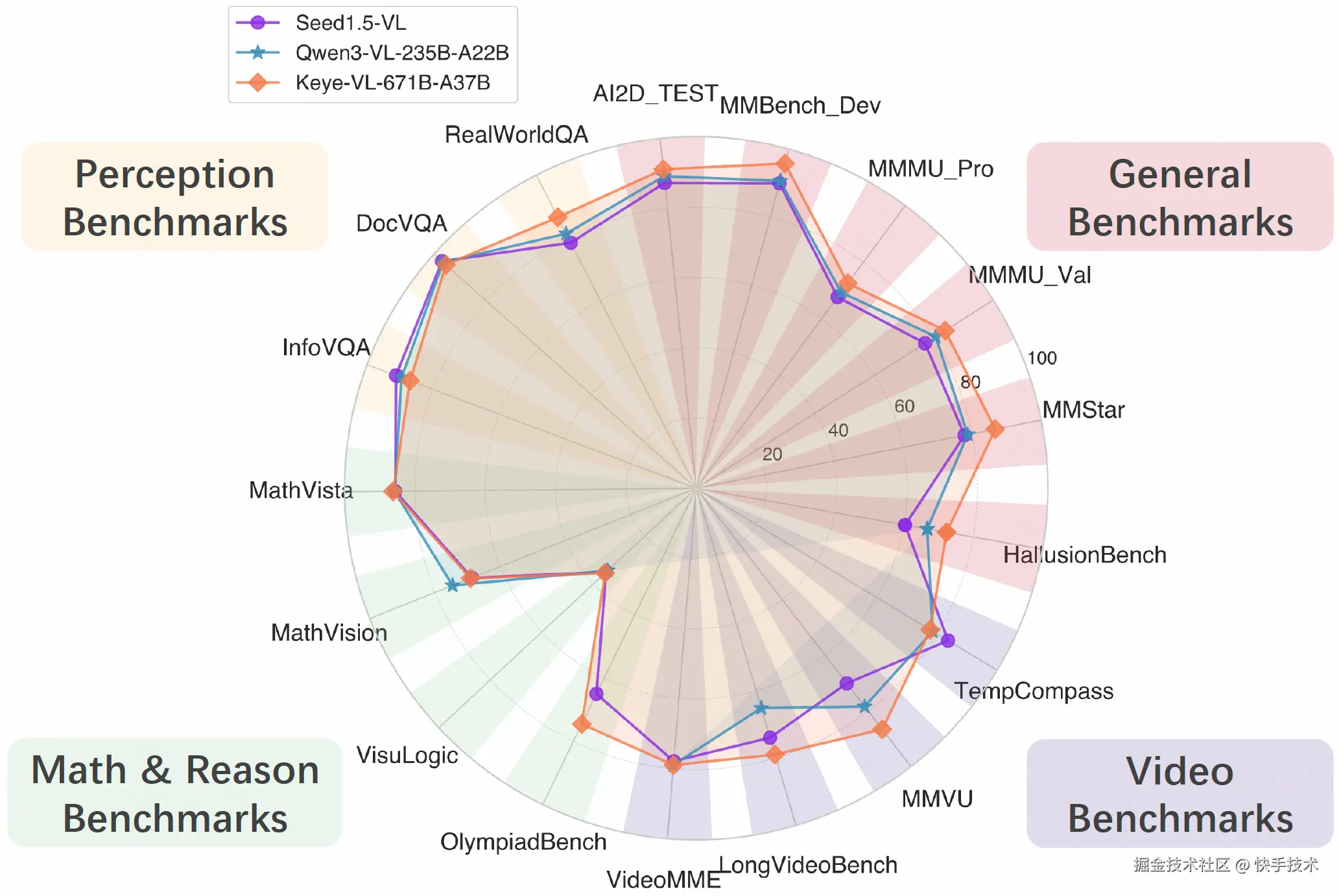
**通用视觉理解与推理。**评测结果显示,Keye-VL-671B-A37B 在多项核心 benchmark 中全面领跑:在通用视觉理解(如 MMBench、MMMU、MMStar、RealWorldQA 等)表现突出,覆盖日常场景理解、跨模态常识与复杂指令跟随;同时在数学与推理能力上优势明显(MathVista、VisuLogic、OlympiadBench 等),无论是图文数学题、空间关系推断还是多步逻辑链条,都展现出更强的稳健性与上限。对比同级别主流多模态模型,KeyeVL 兼具"看得懂、想得深、算得准"的综合实力,为通用视觉智能与高难度推理任务提供了更可靠的基座选择。
**视频理解。**在多种视频理解 benchmark 上,Keye-VL-671B-A37B 同样展现出稳定的优势:在 MMVU、LongVideoBench、VideoMME 等主流视频评测中保持领先,体现出更强的时序建模与跨帧推理能力。无论是长视频的关键事件捕捉、人物与物体的持续跟踪,还是对剧情脉络、因果关系与多步问题的综合理解,Keye-VL 都能给出更准确的答案。
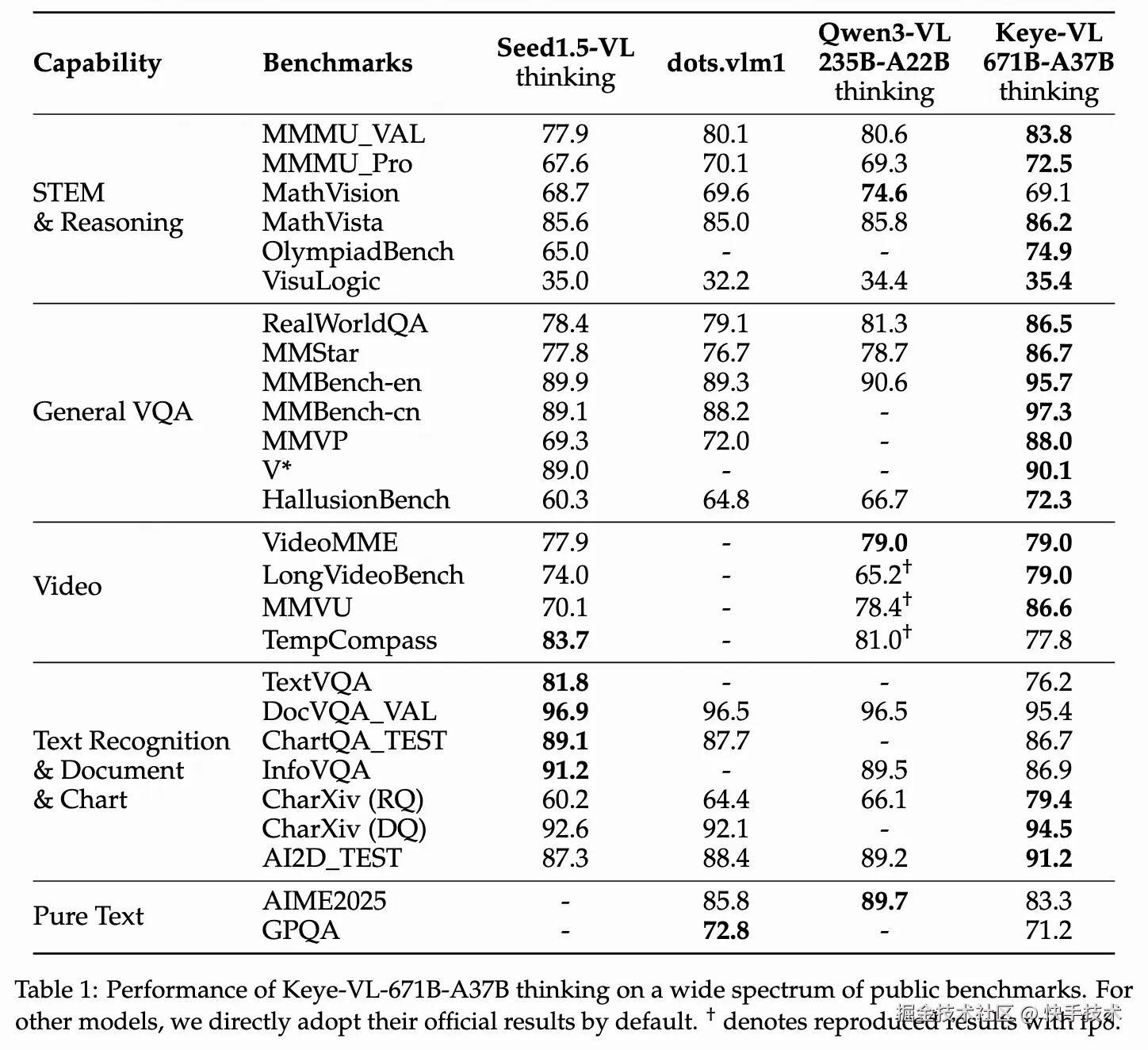
**全面的性能对比。**为了更客观、清晰地展示模型效果,我们也提供了多种主流开源 benchmark 上的对比结果,涵盖 STEM、推理、通用问答、视频理解、OCR 和纯文本能力等。在绝大多数评测中,Keye-VL 都展现出明显的优势。
未来展望
面向未来,Keye-VL 将在持续夯实基础模型能力的同时,进一步融合多模态 Agent 能力,走向更"会用工具、能解复杂问题"的智能形态。我们将强化模型的多轮工具调用能力,让它能够在真实任务中自主调用外部工具,完成搜索、推理、整合;同时推进"think with image"、"think with video"等关键方向,使模型不仅能看懂图像与视频,还能围绕它们进行深度思考与链式推理,在复杂的视觉信号中发掘关键信息。通过基础能力+Agent 能力的双轮驱动,Keye-VL 目标是不断拓展多模态智能的上限,向更通用、更可靠、更强推理的下一代多模态系统迈进。