引言
在计算机科学的世界里,最精妙的魔法往往隐藏在最基础的机制之中。当我们编写一个简单的printf("Hello World")时,背后正上演着一场关于内存管理的交响乐。进程地址空间、页表、缺页中断------这些看似深奥的概念,实则是现代操作系统的智慧结晶,它们共同构筑了一个让每个进程都"自以为"独占整个计算机内存的完美幻境。理解这套机制,不仅是掌握操作系统原理的关键,更是窥见计算机系统设计美学的窗口。

目录
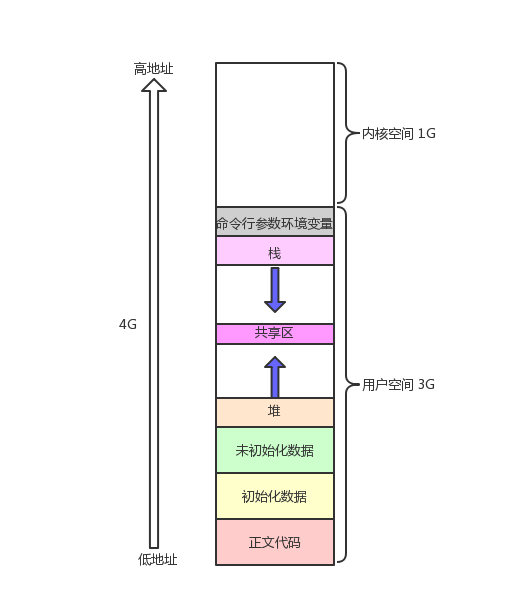
一、程序地址空间
1.1 核心概念
- 一个N位 的系统,其指针地址的位宽即为N比特,理论可寻址空间为 ( 2^N ) 字节。
- 在内存布局图中,地址通常用十六进制 表示。每1个十六进制数对应4个二进制位(比特)。
因为一个字节(8比特位)可以用2个十六进制位数完整表示
-
32位环境
- 地址位宽为 32比特。
- 一个完整的地址需要用 ( 32 / 4 = 8 ) 个十六进制数表示。
- 因此,最低地址通常表示为
0x00000000(共8位十六进制数),最高地址为0xFFFFFFFF。
-
64位环境
- 地址位宽为 64比特。
- 一个完整的地址需要用 ( 64 / 4 = 16 ) 个十六进制数表示。
- 因此,最低地址通常表示为
0x0000000000000000(共16位十六进制数),最高地址为0xFFFFFFFFFFFFFFFF。
空间布局演进
- 从32位到64位,不仅是地址范围的指数级扩张(从4GB到 ( 2^{64} ) 字节),其内部布局也更为科学。64位架构通常在用户空间与内核空间之间留有巨大"空洞",使得堆、栈等区域拥有近乎无限的独立增长空间,极大地提升了系统的稳健性与能力上限。

1.2 实例讲解
我们先来看看程序地址空间的实例图:
- 程序空间地址排布验证:
cpp
1 #include <stdio.h>
2 #include <stdlib.h>
3
4 int g_val_1 = 0; // 已初始化全局变量
5 int g_val_2; // 未初始化全局变量
6
7 int main()
8 {
9 printf("代码段地址: %p\n", main); // 代码段地址
10 const char* str = "wobushidaitou";
11 printf("只读字符常量地址: %p\n", str); // 只读字符串常量地址
12 printf("已经初始化全局变量地址: %p\n", &g_val_1); // 已初始化全局变量地址
13 printf("未初始化全局变量地址: %p\n", &g_val_2); // 未初始化全局变量地址
14
15 char* heap = (char*)malloc(100);
16 printf("堆地址: %p\n", heap); // 堆地址
17 printf("栈地址: %p\n", &str); // 栈地址
18
19 free(heap); // 记得释放内存
20 return 0;
21 } 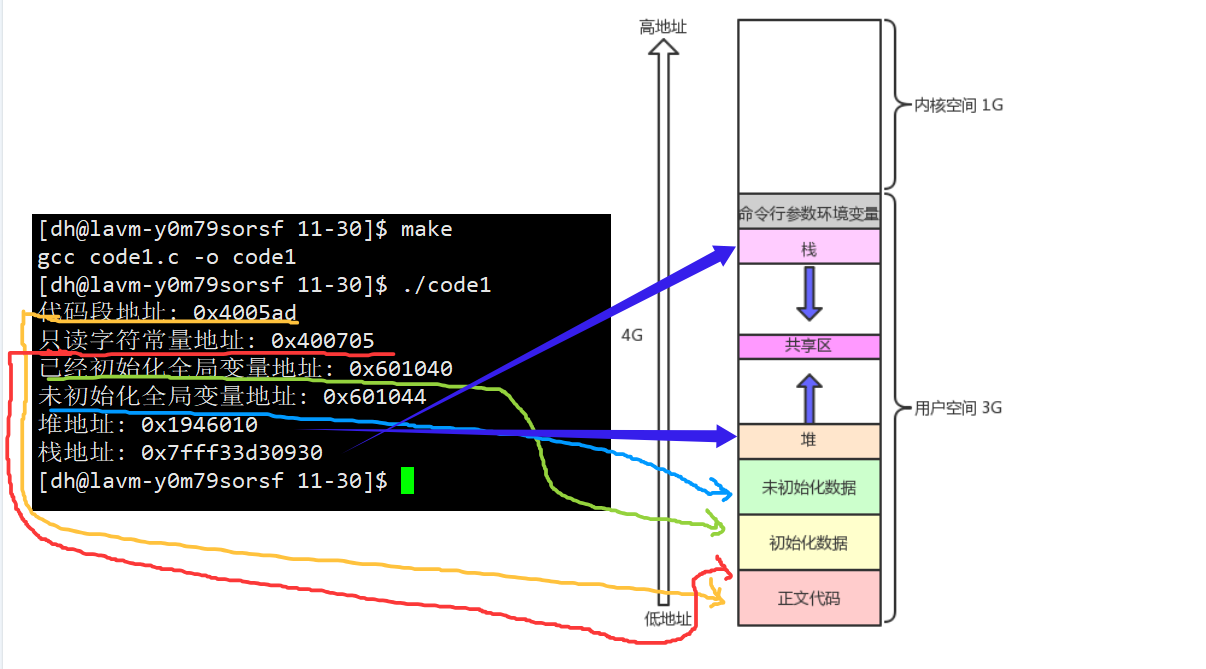
- 我们从对应的地址可以看出,栈区和堆区的地址中间存在很大的镂空,存在很大的地址空间,其实是因为堆区是向上增长,栈区是向下增长。
- 注意:
static修饰的局部变量是具有全局变量的属性的,只不过是受到局部作用域的限制,即static修饰的局部变量其被编译的时候是被编译全局数据区的。
二、虚拟地址
2.1 概念引入
cpp
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <unistd.h>
4
5 int g_val = 0;
6 int main()
7 {
8 pid_t id = fork();
9 if(id < 0)
10 {
11 perror("fork");
12 return 0;
13 }
14 else if(id == 0)//子进程
15 {
16 printf("child[%d]: %d: %p\n",getpid(),g_val,&g_val);
17 }
18 else
19 {
20 printf("parent[%d]: %d: %p\n",getpid(),g_val,&g_val);
21 }
22 sleep(2);
23
24 return 0;
25 }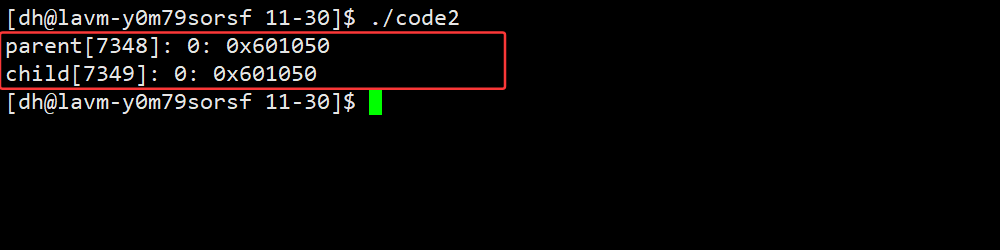
我们能观察到输出的变量值和地址都是一模一样的。
- 因为子进程是以父进程为基准,他们共用代码和数据,且都没有对变量进行任何的修改,所以输出的一模一样。
再看以下进行修改的代码:
cpp
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <unistd.h>
4
5 int g_val = 0;
6 int main()
7 {
8 pid_t id = fork();
9 if(id < 0)
10 {
11 perror("fork");
12 return 0;
13 }
14 else if(id == 0)//子进程
15 {
16 g_val = 100;
17 printf("child[%d]: %d: %p\n",getpid(),g_val,&g_val);
18 }
19 else
20 {
21 sleep(3);
22 printf("parent[%d]: %d: %p\n",getpid(),g_val,&g_val);
23 }
24 sleep(2);
25
26 return 0;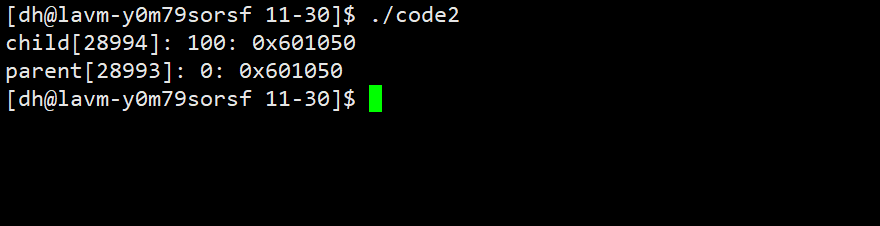
我们观察输出发现:
- 变量值不同:这很好理解。因为进程具有独立性,一个进程的数据改变不应影响另一个。
- 变量地址相同:这就令人费解了。如果它们访问的是同一个物理内存位置,那么值理应相同,但是这里子进程已经修改了变量的值。
这个矛盾引出了一个关键结论:我们在C/C++程序中通过 & 取地址运算符获得的地址,绝非物理内存的直接地址。
2.2 写时拷贝
-
虚拟地址空间
-
每个进程都被操作系统赋予了一个独立的、私有的虚拟地址空间。这是一个从0到最大地址的连续、统一的"内存视图",与实际的物理内存布局无关。
-
我们程序中看到的所有地址(包括代码、全局变量、栈、堆的地址)都是这个空间内的虚拟地址。
-
因此,上述中的父子进程中的
0x601050,是它们各自虚拟地址空间中的地址。虽然数值相同,但它们是两个不同"世界"里的坐标。
-
-
写时拷贝
-
创建子进程时,操作系统为了效率,并不会立即复制父进程的全部数据。而是让子进程与父进程共享相同的物理内存页。
-
只有当任一进程(父或子)试图修改共享的数据时(如子进程将 g_val 从0改为100),操作系统才会在此时介入:
-
- 为要修改的数据(这里是 g_val)分配新的物理内存页。
- 将原始数据拷贝到新分配的物理页中。
- 更新修改进程(子进程)的页表,使其虚拟地址 0x60104c 重新映射到这块新的物理内存上。
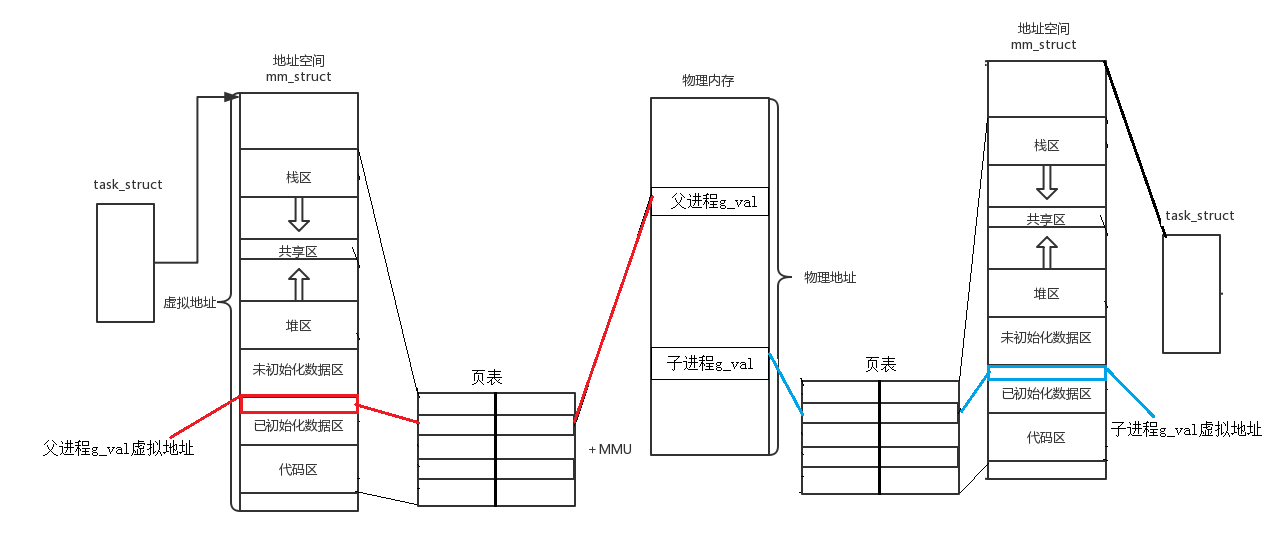
总结: 同一个变量,地址相同说明他们的虚拟地址相同;内容不同,说明虚拟地址映射到了不同的物理地址中。
2.3 大富翁画饼
上述我们已经引出了虚拟地址的概念,有了一个初步的认识,接下来我们通过一个例子来更深刻的理解虚拟地址空间!
- 笨富翁
这位富翁拥有一个庞大的公开家庭,他的孩子们都生活在同一座庄园里。他知道自己总共有10亿美元,孩子们也都知道彼此的存在。
- 孩子A首先请求:"父亲,我需要100美元。"富翁觉得这微不足道,便答应了。
- 正当钱要递出时,孩子B冲过来一把抢走,喊道:"我先看到的!"
- 孩子C见状不服:"他拿了100,那我就要200!"
- 孩子A感到不公,也改口:"那我也至少要200!"
富翁的困境:
孩子们开始竞争和攀比。他们不仅争夺当前的小额钞票,更因为知道"家底"总共就10亿,都想着"我现在拿得少,以后分家产时就亏了"。这让富翁头疼不已,因为他必须实时调解每一笔钱的归属,确保不会超支,还要维持公平------一个孩子的挥霍,会直接影响到其他孩子。

- 精明富翁
另一位富翁同样拥有10亿美元和很多孩子,但他的孩子们都是"私生子",彼此不知道对方的存在。富翁为每个孩子都建造了一座一模一样的、独立的豪华庄园。
- 他来到A孩子的庄园,对辛勤工作的A说:"好好干,我所有的10亿美元未来都是你的。" A备受鼓舞。
- 他来到B孩子的庄园,对努力训练的B说:"好好打球,我的10亿美元未来都是你的。" B充满希望。
- 他同样对学跳舞的C孩子,以及其他所有孩子,许下了同样的承诺。
富翁的精明:
每个孩子都活在一个专属的世界里,坚信自己是唯一的继承人,拥有对"全部10亿美元"的未来所有权。当他们需要钱时(比如申请内存),富翁就从总财富中划出一部分给他们,但在每个孩子的"个人账本"(他们的认知世界里),他们看到的都是自己的需求被满足,并且自己仍然拥有那完整的"10亿"远景。孩子们之间无法也无意识去争夺,因为他们根本不知道对方的存在。

三、进程地址空间
3.1 概念引入
- 进程地址空间概念引入
进程地址空间是操作系统为每个运行中的进程分配的独立虚拟内存视图。它就像给每个进程一个"私人定制"的内存世界,让进程以为自己独占整个计算机的内存资源。
这个精妙的设计解决了多个关键问题:它实现了进程间的安全隔离,防止一个进程的错误影响其他进程;它简化了程序员的编程模型,无需关心物理内存的实际布局;它允许操作系统更高效地管理有限的物理内存资源。通过虚拟内存机制,进程可以使用比实际物理内存更大的地址空间,部分数据可以暂时存储在磁盘上,需要时再调入内存。
-
32位地址空间的特点与局限
在32位系统中,进程地址空间的理论上限是4GB(2的32次方字节),这4GB空间被划分为用户空间和内核空间两大部分。典型的32位Linux系统采用3:1划分,用户进程可使用3GB的地址范围,内核占用1GB。
-
64位地址空间的突破与优势
64位系统将地址空间扩展到惊人的16EB(2的64次方字节),这几乎是无限的地址资源。如此巨大的空间使得操作系统可以采用更加灵活的布局策略,在用户空间和内核空间之间留下巨大的"空洞",为堆和栈的增长提供了近乎无限的空间。
linux中的进程是十分多的,每一个进程都要有自己独立的进程地址空间,进程一旦十分多,那么就容易混乱,那么我们应该先描述再组织,使用结构体描述进程地址空间,在linux中是mm_struct描述进程地址空间
3.2 区域划分
- 我们用"同桌三八线"这个每个人学生时代都可能经历过的事情,来透彻地理解计算机中的"区域划分"。
- 假设小明和小红是同桌,他们共用一张长方形的课桌。
一开始,桌子是"公共的",没有界限。结果:
- 小明的胳膊肘总是撞到小红。
- 小红的文具和书本常常"入侵"到小明那边。
- 两人为此经常争吵,谁都觉得自己吃亏了。
- 为了解决这个问题,他们谈判后,用粉笔在桌子中间划了一条线,郑重约定:
- 规则一:线以左归小明,线以右归小红。
- 规则二:未经允许,不得越界放置物品或伸展肢体。
这条线,就是他们桌子的"区域划分"。
- 划线之后,效果立竿见影:
- 秩序建立:争吵立刻减少了。因为权责清晰,任何越界行为都"有理可循,有据可依"。
- 独立发展 :小明可以在自己的区域内随意摆放书本、涂鸦,只要不越线,小红无权干涉。小红亦然。这就是在各自区域内 "自主治理"。
- 效率提升:他们不再需要把精力花在争吵上,可以更专注于自己的事情(学习和玩耍)。
- 现在,我们把这张课桌想象成计算机的物理内存 ,小明和小红就是两个需要共用内存的进程。
| 课桌故事 | 对应计算机概念 | 核心思想 |
|---|---|---|
| 一整张课桌 | 一整块物理内存 | 初始状态是共享的、混沌的资源池。 |
| 小明和小红 | 进程A 和 进程B | 多个实体需要共享同一资源。 |
| 胳膊碰撞、物品入侵 | 内存访问冲突、数据被篡改 | 没有隔离会导致混乱和不安全。 |
| 谈判划线的行为 | 操作系统的内存管理 | 引入一个管理者来制定规则。 |
| "三八线"本身 | 进程的地址空间边界 | 一条逻辑上的、强制性的边界。 |
| "线左归明,线右归红"的规则 | 虚拟地址空间映射 | 操作系统通过页表,让进程A的地址空间映射到物理内存的A区,进程B的映射到B区。它们看到的都是"整张桌子",但实际用的只是各自那一半。 |
| 小明在自己的区域随意摆放 | 进程在自己的地址空间内自由操作 | 进程无需关心其他进程在干什么,它认为自己独享整个内存空间。这简化了编程。 |
| "越界=犯规"的共识 | 内存保护机制 | 如果进程A试图访问进程B的内存区域,硬件和操作系统会立刻拦截,并触发一个段错误/访问违规,强制该进程崩溃,从而保护了整个系统的安全。 |
3.3 虚拟内存管理
如上我们已经知道了其地址上的区域划分,其实描述linux下进程的地址空间的所有的信息的结构体是 mm_struct(内存描述符)。
每个进程只有⼀个
mm_struct结构,在每个进程的task_struct结构中,有⼀个指向该进程的结构。
cpp
struct task_struct
{
struct mm_struct *mm;
//对于普通的⽤⼾进程来说该字段指向他的虚拟地址空间的⽤⼾空间部分,对于内核线程来说这部分为NULL。
struct mm_struct *active_mm;
// 该字段是内核线程使⽤的。当该进程是内核线程时,它的mm字段为NULL,表⽰没有内存地址空间,可也并不是真正的没有,这是因为所有进程关于内核的映射都是⼀样的,内核线程可以使⽤任意进程的地址空间。
}mm_struct结构是对整个用户空间的描述。每⼀个进程都会有自己独立的mm_struct。- 这样每⼀个进程都会有自己独立的地址空间才能互不⼲扰。先来看看由
task_struct到mm_struct,进程的地址空间的分布情况:
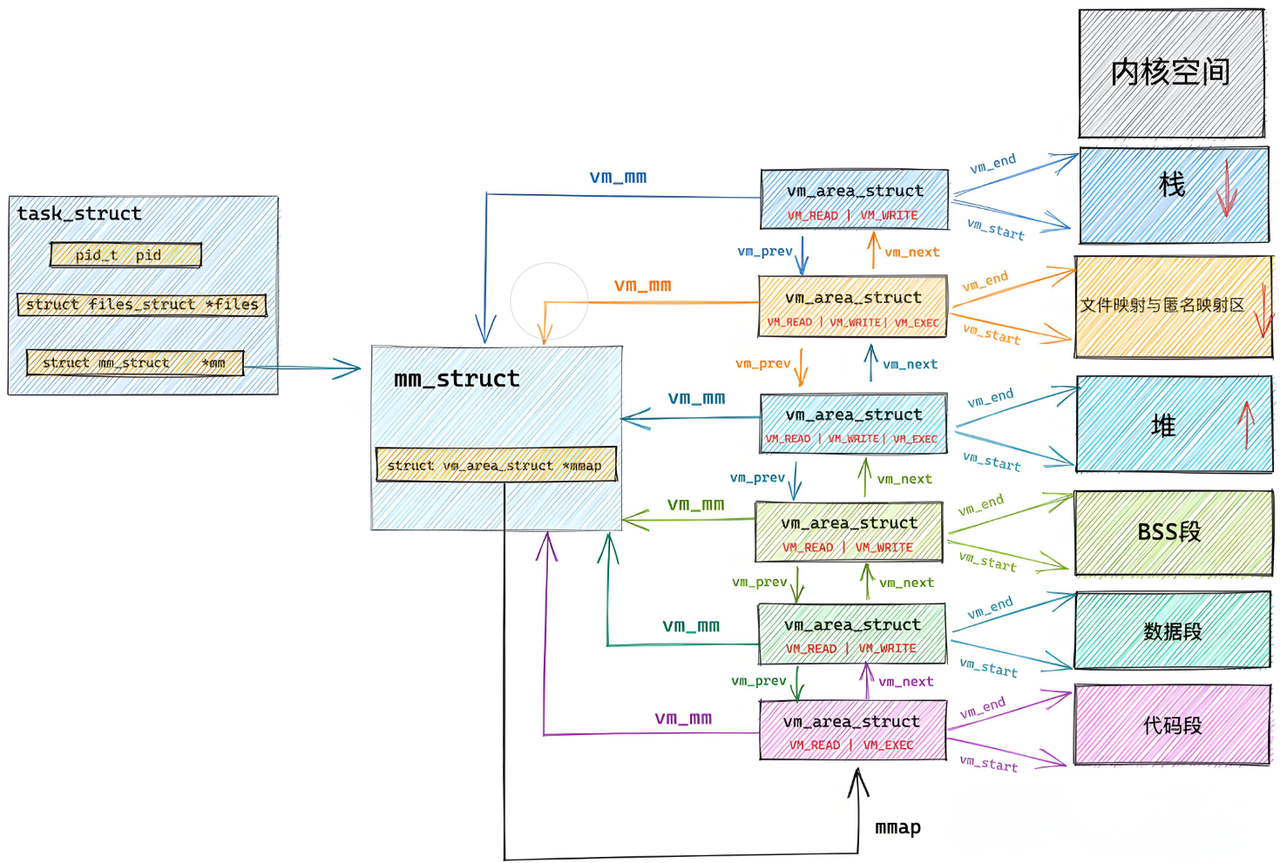
进程 == 内核数据结构 + 代码和数据内核数据结构 == task_struct && mm_struct && 页表
四、 页表
4.1 核心概念
当CPU从一个进程切换到另一个进程时,它实际上是在切换一整套"执行上下文"。这个上下文的核心是"三件套":
- 进程控制块(PCB):这是进程的唯一身份证,操作系统通过PCB来管理和调度进程。
- 进程地址空间(mm_struct):这是进程看待内存的"视角地图",它定义了代码、数据、堆、栈等区域在虚拟内存中的布局。
- 页表:这是虚拟地址到物理地址的"翻译官",存储着地址映射关系。
关键机制 :CPU中有一个名为CR3 的寄存器,它专门用来存放当前正在运行的进程的页表物理地址。当发生进程切换时,操作系统会将新进程的页表地址加载到CR3寄存器中。这一操作是硬件级地址空间隔离的基石------它确保了即使两个进程使用相同的虚拟地址,也会因为CR3指向不同的页表,最终访问到不同的物理内存区域,从而实现完全隔离。
4.2 页表的双重角色
- 角色一:内存权限管家
我们从学习C语言开始就知道,不能修改代码区和字符串常量区。这个限制正是由页表强制执行的。页表中的每一项都包含权限位,例如:
- 代码区 的权限通常是 只读+可执行 (r-x)。任何试图写入的操作都会被CPU拦截,并立即触发段错误(Segmentation Fault)。
- 已初始化全局变量区 的权限是 可读可写 (rw-),允许正常读写。
- 字符串常量区 的权限是 只读 (r--),禁止修改。
重要认知 :物理内存本身是没有权限概念的,只要知道物理地址,就可以进行读写。是页表这层"抽象壳" 在地址翻译的过程中附加了权限检查,从而实现了软件层面的内存保护。
- 角色二:页面状态记录员
页表中有一个至关重要的 "在位(Present)"标志位。
- 当该位为 1,表示这个页面目前就在物理内存中,可以直接访问。
- 当该位为 0,表示这个页面当前不在物理内存中(可能被换出到磁盘上)。
这个标志位是操作系统知晓页面是否在内存中的根本依据。在Linux中,虽然没有一个直接的"挂起"状态,但一个进程的很多页面如果Present位为0,它在效果上就是被"挂起"了,因为它的部分代码和数据不在物理内存中。
4.3 惰性加载与缺页中断
问题: 一个10GB的游戏,如何在只有4GB物理内存的电脑上流畅运行?如果一次性全部加载,内存必然崩溃。
- 低效的解决方案:分批加载
设想操作系统预先加载500MB。但由于程序在短时间内通常只执行一小部分代码(例如5MB),这会导致提前加载的495MB内存被闲置,其他进程也无法使用,造成巨大的资源浪费。- 高效的解决方案:惰性加载 + 缺页中断
现代操作系统采用了一种更聪明的方法:惰性加载。其核心思想是"不到万不得已,绝不分配资源"。
工作流程如下:
- 创建空壳:当进程启动时,操作系统仅为其创建PCB、地址空间和页表结构。在页表中,它为所有虚拟地址建立映射,但将这些映射的"在位(Present)位"均标记为0,且不立即申请物理内存加载任何代码数据。
- 触发需求:当程序开始执行,访问第一条指令(一个虚拟地址)时,CPU通过CR3找到页表进行查询。
- 中断触发 :CPU发现该地址对应的页面"不在位(Present=0)",便会触发一个缺页中断(Page Fault),将控制权交给操作系统。
- 加载数据:操作系统处理这个中断,它识别出需要哪个页面,然后从磁盘上的可执行文件中找到对应的代码或数据,在物理内存中申请一个空闲页框,将其加载进去。
- 更新映射:操作系统将这块物理内存的地址填回页表项,并将"在位(Present)位"设置为1。
- 重试执行:一切就绪后,操作系统让CPU重新执行那条触发中断的指令。这次,页表查询成功,程序得以继续运行。
通过这个机制,10GB的游戏在运行时,实际上只有当前真正被使用到的部分(可能是几十MB)才会被加载到物理内存中,这就完美地解决了大程序在有限内存中运行的难题。
4.4 架构设计的精髓
惰性加载和缺页中断机制带来了一个至关重要的架构优势:实现了进程管理模块与内存管理模块的解耦合。
- 进程管理模块:它的职责是"需要什么",即进程需要访问某个虚拟地址。它完全不用关心这个地址背后是否有物理内存、内存是否充足等细节。
- 内存管理模块:它的职责是"提供什么",即当缺页中断发生时,负责分配物理页面、从磁盘加载数据、更新页表。它不用关心是哪个进程发出的请求。
页表和缺页中断机制充当了二者之间的"协调中间件"。这种设计使得两个核心模块可以独立发展和优化,大大提升了操作系统的稳定性、灵活性和资源利用效率。
4.4 关键问题解答
问:进程在被创建的时候,是先创建内核数据结构,还是先加载可执行程序对应的代码和数据?
答:先创建内核数据结构。
得益于页表和缺页中断机制,操作系统的流程是:
- 快速搭建框架:立即创建PCB、进程地址空间(mm_struct)和初始页表。此时页表内的映射大部分是"空"的(Present=0)。
- 按需精细填充:并不立即加载任何代码和数据到物理内存。进程开始执行后,当它的指令指针真正触碰到那些尚未加载的虚拟地址时,再通过缺页中断这个"按需配送"机制,逐页地将所需的代码和数据加载进物理内存,并完善页表映射。
五、总结
注意:命令行参数和环境变量的地址是在栈的地址之上
从32位到64位的地址空间演进,从简单的内存划分到精巧的虚拟内存管理,我们看到的不仅是技术的进步,更是设计哲学的升华。进程地址空间为每个进程提供了独立的沙盒环境,页表机制实现了地址翻译、权限控制和状态监控的三重使命,而缺页中断与惰性加载的完美配合,则展现了"按需分配"这一效率至上的设计智慧。这套环环相扣的机制,如同一个精密的生态系统,在保证安全隔离的前提下,最大化地提升了资源利用率。正如一位智者所言,最好的系统设计是让复杂对用户不可见------当我们能够流畅运行远比物理内存庞大的程序时,正是这些底层机制在默默发挥着它们的魔力。
✨ 坚持用 清晰易懂的图解 + 代码语言, 让每个知识点都 简单直观 !
🚀 个人主页 :不呆头 · CSDN
🌱 代码仓库 :不呆头 · Gitee
📌 专栏系列 :
💬 座右铭 : "不患无位,患所以立。"