每一类数据在训练中对模型参数产生"方向稳定且可区分"的梯度贡献模式;客户端上传的模型更新,其实就是"各类梯度的加权和",权重正是各类样本占比。
Decaf 的思想是通过数学分解这一"加权和",从而反推每类权重(= 类别占比)。
一、为什么「梯度 → 类别占比」是可推断的?(关键直觉)
深度学习模型在同⼀标签的样本上,会产生类似的梯度方向。
1. 交叉熵 + softmax 的梯度具有"类别特征指纹"
- 对于分类器,softmax + cross-entropy 的梯度形式是:
表示模型输出与真实标签 one-hot 的差。
-
不同 label 的 one-hot 不同 → 梯度方向不同
-
随着训练迭代,同类样本的梯度变化趋势具有一致性(称为 gradient signature)
因此,类别梯度具有可区分性(class separability)。
2. 客户端本地训练 = "类梯度的加权和"
对某个客户端 kkk,其本地训练执行:
其中:
-
:客户端 c 类样本占比(Decaf 最想恢复的量)
-
-
这是最关键的公式!就是 Decaf 能推断的本质原因。
3. 不同客户端之间的数据分布差异 → 更新差异可被观察和分解
-
有的客户端"偏某些类",更新中对应类梯度成分强;
-
有的客户端缺失某些类(null class),对应梯度成分几乎为 0;
-
服务器跨多轮收集更新后可以得到大量线索,足够解出每个客户端的 "加权系数"。
Decaf 就是建立在这个梯度分解框架之上的。
二、 Decaf 的实现流程(高层逻辑,不可滥用版)
下面是 Decaf 核心步骤,用论文格式说明即可。
Step 1:服务器收集梯度变化(Gradient Changes)
服务器是 honest-but-curious,所以它正常参与 FL,同时记录:
即第 t 轮客户端 k 的更新。

跨多轮收集,就有一堆:
这就是被 Decaf 用来反推分布的关键观察数据。
Step 2:识别每个客户端的 null classes(缺失类)
论文证明了:
如果客户端完全没有某类数据,则其梯度中对这一类的投影长期为 0 或非常小。
Decaf 用统计方法(类似 hypothesis testing)判断:
在客户端 k 的成分是否显著 > 0
若长期为 0 → 该客户端缺失该类。
(这一步非常重要,因为减少类别维度后,分解难度大幅下降。)
Step 3:构建"类别梯度基"(Gradient Basis)
Decaf 不需要知道真实数据,只需要找到每个类梯度的"公共方向"。
方法大意是:
-
利用全局模型对所有客户端更新进行 PCA / 子空间分解;
-
利用多客户端间梯度差异 + 缺失类信息,把每类梯度在参数空间里的方向估计出来;
-
得到一组基向量:
这些基向量代表每个类别的典型梯度贡献方向(不需要真实样本)。
可以理解为:
服务器找到了"class signature"的数学表示。
Step 4:把客户端上传更新分解到这些基上(Solve coefficients)
服务器对于某个客户端 k:
通过最小二乘 / 投影求:
最后归一化:

这就是 Decaf 恢复的"类别占比"。
三、本质总结
Decaf 能恢复客户端标签占比的根本原因是:
-
每个标签对模型参数产生可区分、稳定的梯度贡献;
-
客户端本地更新是"各类梯度的加权和",权重就是该类的样本比例;
-
因此只要服务器能观察到这些更新,就能通过分解恢复权重,也就是类别占比。
在标准的联邦学习中,交叉熵损失导致不同类别样本在模型参数空间中呈现出方向可分的梯度特征(gradient signatures)。客户端上传的局部模型更新实际上是这些类别特征梯度的加权组合,其权重即客户端上各类别的相对样本占比。Decaf 正是利用这种梯度的可分性和线性可加性,通过对跨轮梯度变化的统计分解,反向解出各类别梯度成分的强度,从而推断客户端的标签分布。
四、用医学图像分类(以 DR 分类)举例说明 Decaf 的工作流程
假设任务是 5 类糖尿病视网膜病变(0--4级)分类。
客户端数据:
| 客户端 | 标签比例(未知) |
|---|---|
| 医院A | 80% 类别0(正常),20% 类别1 |
| 医院B | 60% 类别3+4(重度 DR) |
| 医院C | 比较均匀分布 |
服务端不知道这些分布,但 Decaf 想告诉你这些标签占比。
下面按流程说明。
五、Decaf 攻击的完整流程(结合医学图像)
步骤1:预训练一个"标签识别模型(calibration model)"
攻击者(服务端)准备一套公开医图数据,比如:
-
Kaggle DR dataset(公开)
-
Messidor dataset(公开)
然后 单独训练一个分类器 C(x)
用于学会区分 5 类医学图像的判别特征。
这个模型不参与联邦学习,只用于"理解梯度和标签的关系"。
它能回答:
"如果梯度方向是这样的,那它更像是由某类样本训练出来的?"
步骤2:在本地对每个标签计算"类别特征梯度 fingerprint"
服务端使用 C(x),对公开数据每一类生成一组基准梯度:
例如对于类别 0:
类别1:
最终服务端得到五个类别的"梯度指纹":
| 类别 | 梯度方向 fingerprint |
|---|---|
| 0 | |
| 1 | |
| 2 | |
| 3 | |
| 4 |
这些 fingerprint 就像"五种梯度味道的模板"。
步骤3:联邦学习开始时,客户端上传模型更新 Δw
假设医院 A 上传:
Decaf 的任务是分析:
步骤4:Decaf 计算 Δw_A 与每个类别梯度 fingerprint 的相似度
例如:
你会看到:
-
-
与类别2、3、4 的几乎不相关
所以 Decaf 推断:
医院 A 的数据主要来自类别 0 和 1
步骤5:利用非负最小二乘回归(NNLS)估计"标签占比"
Decaf 将问题表示成一个线性组合:
并加约束:
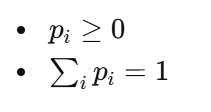
求解得:
| 类别 | 估计比例 |
|---|---|
| 0 | 0.79 |
| 1 | 0.18 |
| 2 | 0.01 |
| 3 | 0.01 |
| 4 | 0.01 |
→ 和真实(80%类0, 20%类1)基本一致!
📌 四、用病理图像客户端示例总结
如果医院B上传的模型更新 更像:
-
类别3
-
类别4
Decaf 就能判断:
医院 B 的数据主要是重症 DR (3/4类)
如果医院C上传的模型更新和所有类别都差不多:
Decaf 推断该客户端的数据分布更加均衡。
🔥 五、总结:Decaf 为什么能检测到客户端标签占比?
因为:
-
不同类别的样本训练出的梯度方向不同(深度模型具有类别特征)
-
服务端提前训练好基准"类别梯度模板 fingerprint"
-
客户端上传的更新 Δw 带有它自己数据分布的"特征"
-
Decaf 把 Δw 分解为各类梯度模板的线性组合
-
得到每个类别对应的比例 → 即客户端的标签分布!