Linux发行版有很多这里作者使用ubuntu来搭建。
以下是Hadoop 完全分布式搭建VMware17 适配的Ubuntu、Hadoop、JDK的版本推荐:
1. Ubuntu 20.04 LTS 镜像
- 清华大学镜像(优先):https://mirrors.tuna.tsinghua.edu.cn/ubuntu-releases/20.04/ubuntu-20.04.6-desktop-amd64.iso
- 阿里云镜像(备选):
- https://mirrors.aliyun.com/ubuntu-releases/20.04/ubuntu-20.04.6-desktop-amd64.iso
- 说明:选择「desktop-amd64.iso」(桌面版),适合新手操作,服务器版无图形界面难度较高。
2. JDK 1.8.0_391 镜像
- 华为云镜像(无需注册):
- https://repo.huaweicloud.com/java/jdk/8u181-b13/jdk-8u181-linux-x64.tar.gz
- 说明:Hadoop 仅支持 Oracle JDK 或 OpenJDK,此处选 Oracle JDK 8,兼容性最好。
3. Hadoop 3.3.6 镜像
4**.Xftp8:**
前置知识:
-
网卡 :是设备(如虚拟机)连接网络的硬件 / 虚拟接口(比如你用的
ens33),负责收发网络数据; -
子网 :是一个小网络的地址范围(图中是
192.168.1.0/24),同一子网内的设备能直接通信; -
IP :是子网内设备的唯一地址(比如
192.168.1.102),用于标识设备并传输数据; -
网关 :是子网内设备访问外部网络的 "出口"(图中是
192.168.1.2),所有跨子网的通信都要经过网关
在Linux系统操作中:
Ctrl+C可以退出进程
输入:"i"对配置文件进行编辑
输入:wq!可以保存并推出配置文件
一、vmware安装完之后创建第一个虚拟机主机
推荐配置:磁盘大小50G、内存大小4G、网络适配器选择NAT模式,最后再设置OCD/DVD (IDE)为Ubuntu。
这里讲一下NAT和桥接模式的区别;NAT是虚拟机共享实际主机的IP,而桥接模式则是虚拟机另外用一个IP。桥接模式比较好,但是部署难度大,这里我们采用NAT模式。
二、在虚拟机里配置安装Ubuntu
Ubuntu的安装这里作者就不多赘述,平台上有很多教程,我只提供一些问题的解决方法
1.使用vmware安装ubuntu的时候,由于分辨率的问题我们可能看不到安装的"下一步",此时我们可调整分辨率解决问题。
①ctrl+alt+t打开终端
②输入xrandr并回车,查看支持的分辨率
③选择其中一个较大的分辨率,如:
xrandr -s 1024x768_60.00
2.安装时最好选择比较全的配置
3.安装完之后点击一下vmware顶端的查看调整窗口大小,再调节合适的分辨率即可令系统界面观感合适
三、网络配置
①点击编辑>虚拟网络编辑器>点击VMnet8>子网和子网掩码配置>NAT设置,配置按照我的来就可以
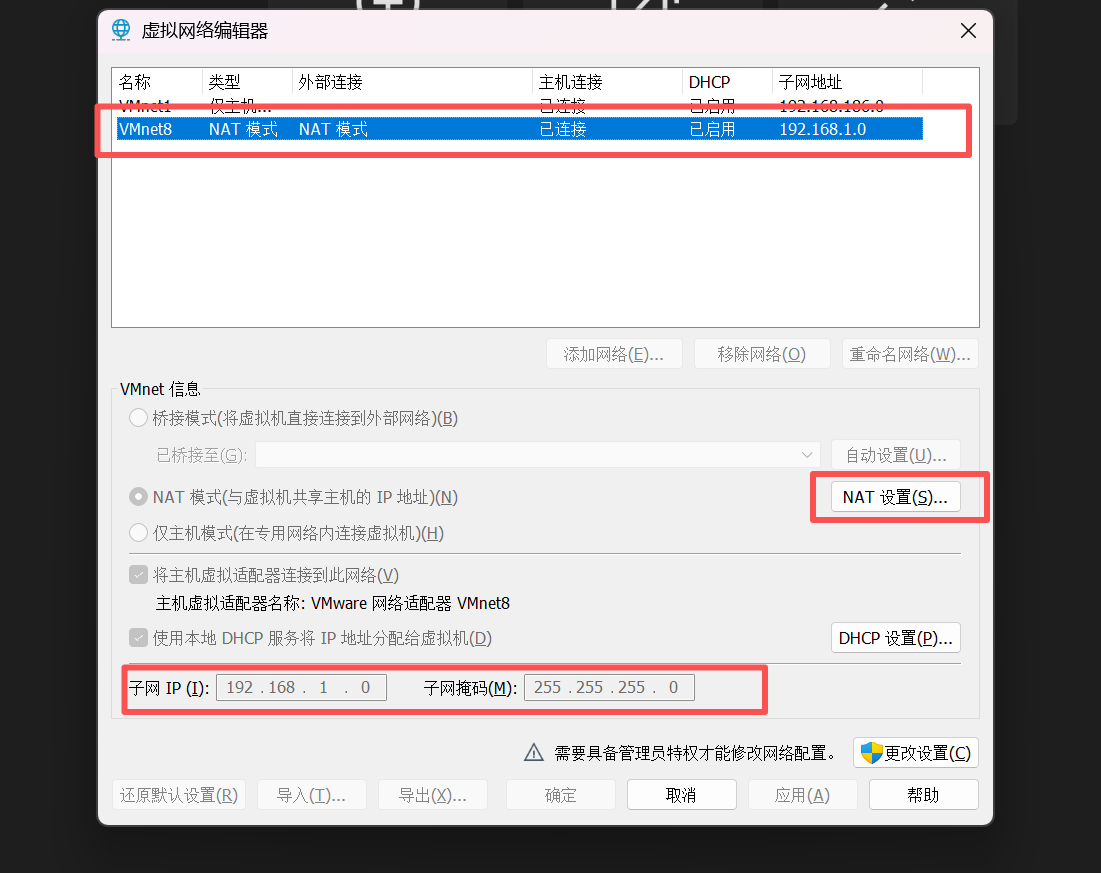
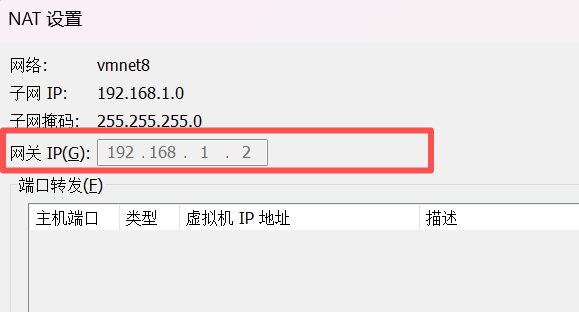
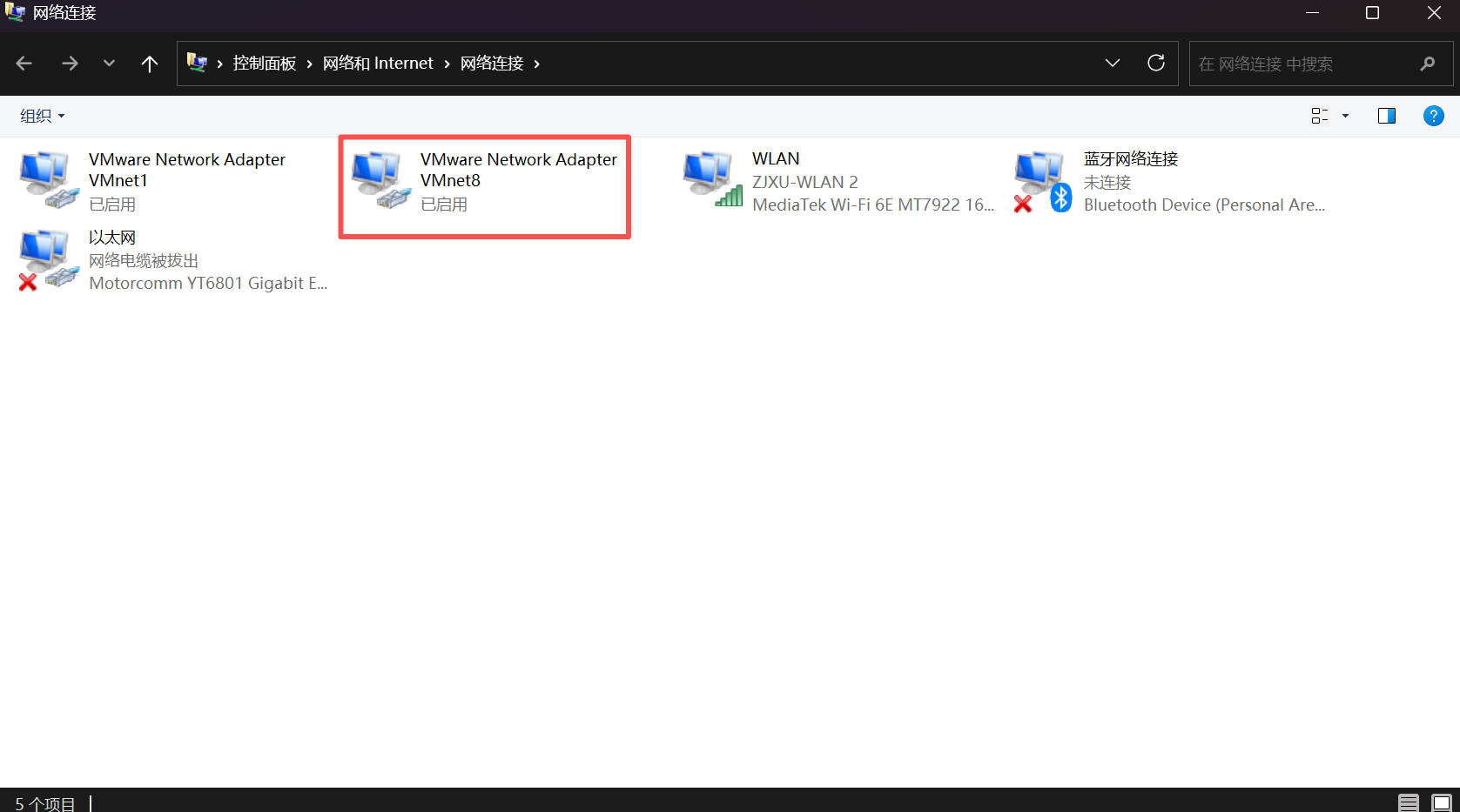
②接下来要配置本地网络,点击控制面板,进入网络适配器界面,选择 vm8,点击属性,修改ipv4,需要和虚拟机中设置的网络信息保持一致。
意义:VMnet8 是虚拟机与主机通信的 "桥梁",只有让它的 IPv4 地址和虚拟机的网络配置(静态 IP、网关、子网掩码)保持同网段且参数一致,主机才能识别并连接到 Hadoop 集群的各个节点,避免出现 "ping 不通虚拟机""无法上传文件""Web 端打不开集群页面" 等问题。
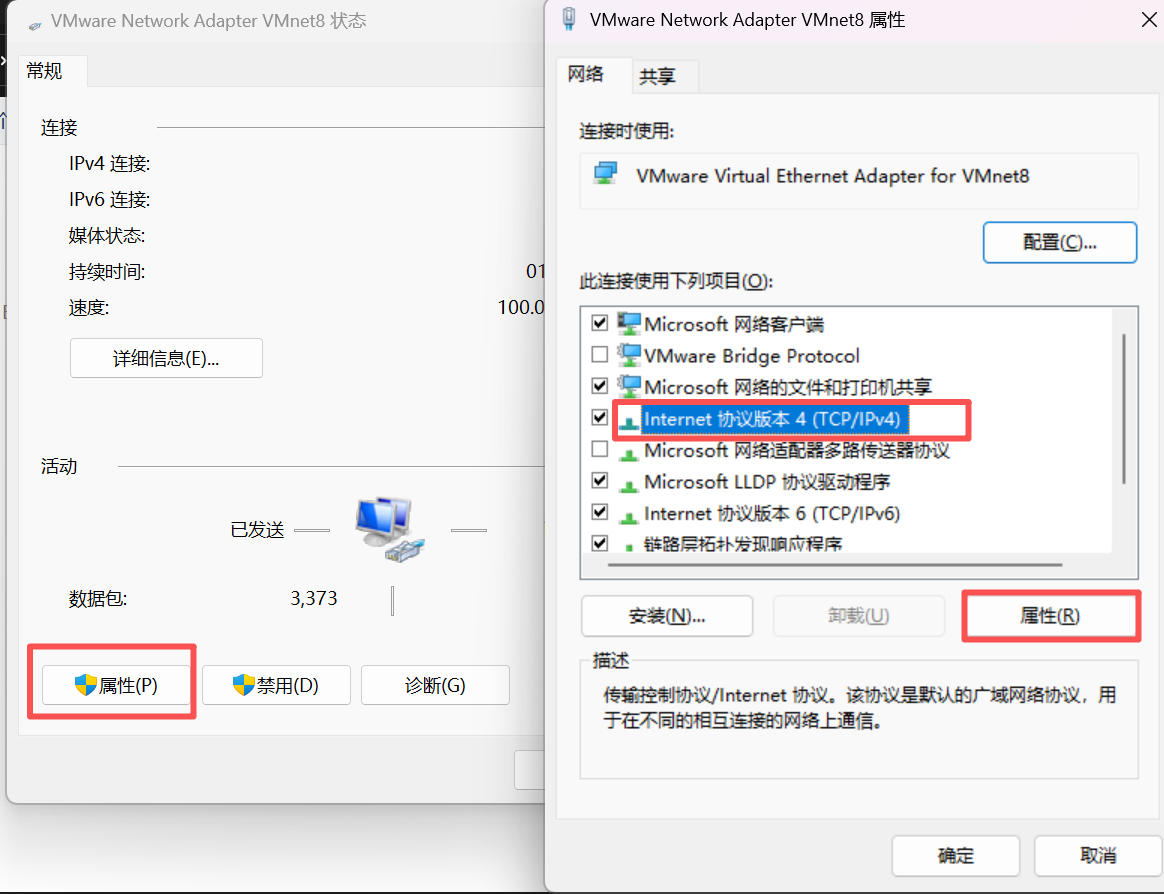
③在 Linux 终端中修改网络配置文件,手动设置静态 IP、网关和 DNS(域名解析服务器)。必须确保这里的 IP、网关,和 VMware 虚拟网络编辑器(VMnet8)、Windows 的 VM8 适配器配置在同一网段(比如文档中统一用 192.168.1.x 网段),否则会无法连通。
目的:将网卡从 "DHCP 自动获取 IP" 改为 "静态固定 IP",编辑前网卡 IP 随机变化,编辑后网卡固定使用你指定的 IP(适配 Hadoop 集群稳定通信)。
先输入:ip addr #查看网卡名称,如 :ens33
然后输入:ls /etc/netplan/*.yaml 查看自己机器下面的配置文件,如:
il@IL:~$ ls /etc/netplan/*.yaml
/etc/netplan/01-network-manager-all.yaml
之后编辑网络配置文件:il@IL:~$ sudo nano /etc/netplan/01-network-manager-all.yaml
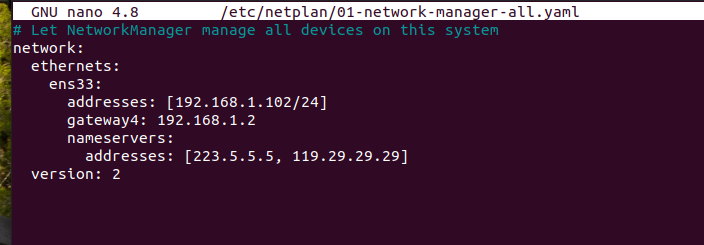
一定要注意打开的文件是否是你的配置文件!有可能系统会直接创建并打开编辑文件,但这不是你的配置文件!
最后可以使用ifconfig 命令查看和配置网络接口信息,这个也需要安装。
sudo apt update -y # 更新软件源列表
sudo apt install -y net-tools # 安装net-tools
④复制黏贴功能:为了后续步骤能高效部署,我们先解决虚拟机和实际主机之间无法复制粘贴的问题;
步骤 1:安装增强工具
-
CentOS/RHEL 系统 :
sudo yum update -y sudo yum install open-vm-tools open-vm-tools-desktop -y # 后者是剪贴板/拖放关键 sudo systemctl restart vmtoolsd # 重启服务 -
Ubuntu/Debian 系统 :
sudo apt update -y sudo apt install open-vm-tools open-vm-tools-desktop -y sudo systemctl restart vmtoolsd
步骤 2:启用剪贴板共享
- 关闭虚拟机,右键选择「设置」→「选项」→「客户机隔离」。
- 勾选「启用复制粘贴」和「启用拖放」,保存后启动虚拟机
最后重启虚拟机再验证是否能正常使用复制粘贴功能。
四、Hadoop完全分布式搭建
①后面Ubuntu部署完全分布式还需要按照这几个工具
| 工具 | 核心作用(集群搭建关键用途) | Ubuntu 安装命令 |
|---|---|---|
ifconfig |
查看 / 配置网络接口信息(验证静态 IP、网卡状态,确保集群节点网段一致) | sudo apt update -y && sudo apt install -y net-tools |
rsync |
远程文件同步工具(集群分发脚本xsync核心依赖,快速同步 JDK、Hadoop 配置到所有节点) |
sudo apt update -y && sudo apt install -y rsync |
vim |
文本编辑器(编辑 NetPlan 网络配置、Hadoop 核心配置文件core-site.xml等,语法高亮 + 便捷编辑) |
sudo apt update -y && sudo apt install -y vim |
②克隆机器
右击创建好的虚拟机,选择管理 ------克隆 ------点击下一页,**完整克隆,**克隆两台虚拟机master2和master3。克隆完一台之后要修改一台克隆机器的ip地址,否则会导致集群中节点冲突(如 IP 冲突、主机名重复)
克隆的机器也要同样做网络配置中第三步的设置静态IP的步骤:
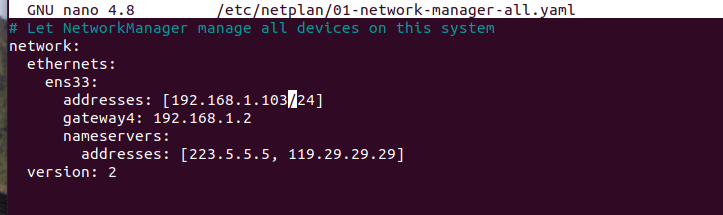
但这里我们把addresses改为192.168.1.103即可,其余的不变。接下来的master3,addresses改为104。
③修改克隆机的主机名,否则会出现主机名重复
首先,编辑主机名配置文件:sudo nano /etc/hostname,删除原内容,填入新主机名;
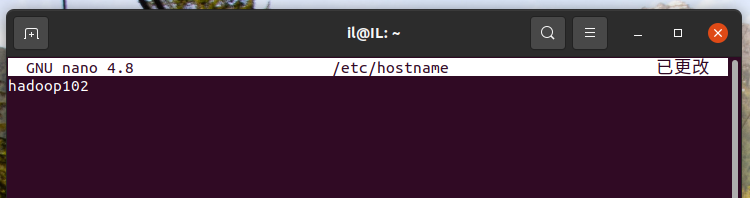
把原主机名改成新主机名,如:IL改为hadoop102
然后输入:sudo nano /etc/hosts,修改映射如:
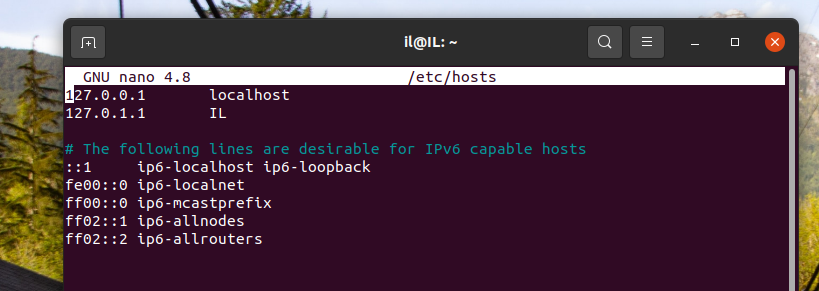
删掉127.0.1.1 IL(你的用户名)并添加:
Hadoop集群主机名映射
192.168.1.102 hadoop102
192.168.1.103 hadoop103
192.168.1.104 hadoop104
修改完之后重启机器,输入hostname验证

还要修改windows端的文件
④免登录设置
前置准备:
克隆机修改完静态 IP 后需要配置 SSH 免密登录,Hadoop 集群节点间需频繁通信(如分发文件、启动服务),免密登录可避免重复输入密码,保证集群操作自动化。
首先要安装SSH服务
sudo apt-get update
sudo apt-get install -y openssh-server
# 启动SSH服务并设置开机自启
sudo systemctl start ssh sudo systemctl enable ssh
# 验证SSH服务状态,出现active(running)即为正常
sudo systemctl status ssh验证结果如下:
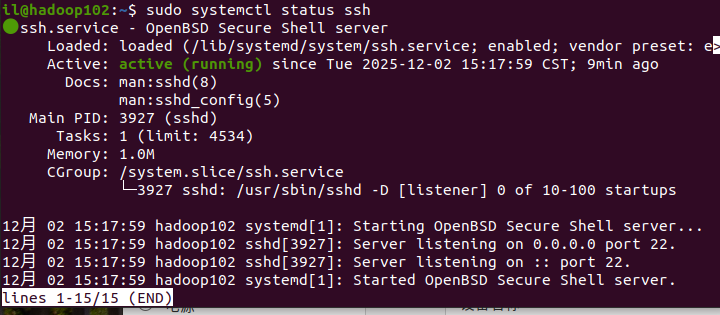
注:有时候SHH服务的安装会失败,有可能是因为当前系统正在更新,占用了进程
执行以下命令,检查自动更新进程是否仍在运行:
# 查看是否有 unattended-upgr 进程在运行
ps aux | grep unattended-upgr如果有更新进程则温和禁止更新,
sudo systemctl stop unattended-upgrades解决完之后:
步骤1 3 台机器都要 创建名为 "atguigu" 的用户 作为 Hadoop 集群的专用用户。3 台机器的atguigu用户虽然是分别创建的,但操作集群时用的是同一用户名,Linux 会默认判定为 "同一身份",这样就方便后续的统一配置操作。
# 1. 创建 atguigu 用户(-m 表示自动创建用户的家目录 /home/atguigu)
sudo useradd -m atguigu
# 2. 为 atguigu 用户设置密码(执行后会提示输入密码,输入时密码不显示,输入完成回车即可)
sudo passwd atguigu步骤 2:给 "atguigu" 用户配置 sudo 权限
记住!!!!下面的操作都得由atguigu用户执行
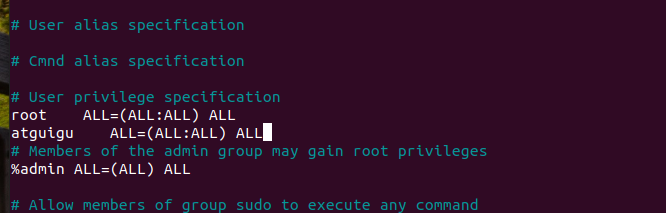
1.编辑 sudo 配置文件:
执行该命令后,会打开/etc/sudoers文件的编辑
sudo visudo2.root ALL=(ALL:ALL) ALL"):在这一行的下方添加一行atguigu ALL=(ALL:ALL) ALL,给 atguigu 用户配置 sudo 权限:
3.指定新的默认Shell为 /bin/bash,后面跟目标用户名 atguigu
sudo chsh -s /bin/bash atguigu
查看当前默认Shell的命令
echo $SHELL
步骤 3:验证 "atguigu" 用户是否创建成功
执行以下命令切换到 "atguigu" 用户,验证是否能正常登录:
# 切换到 atguigu 用户(su - 表示切换用户时同时加载该用户的环境变量)
su - atguigu这个时候你要看你命令行的用户名变成了什么,如果是$则说明你的Shell还是默认的。输入"exit"退出atauigu用户。
步骤 4 :在hadoop102生成密钥对执行密钥生成命令,按 3 次回车(所有选项默认,无需输入内容):
ssh-keygen -t rsa一路回车即可
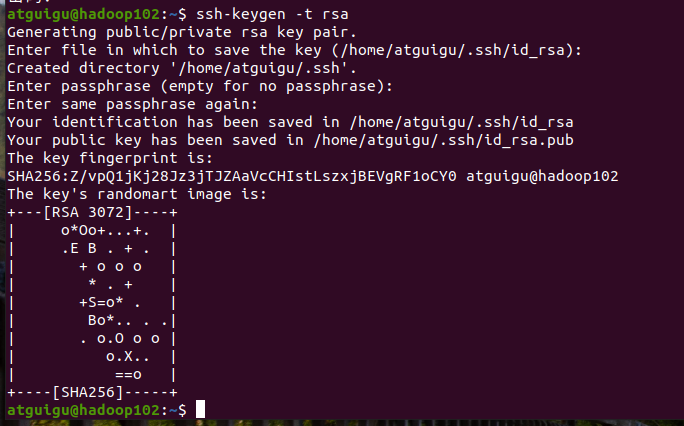
执行成功后,会在atguigu的家目录下生成 .ssh 隐藏文件夹,内含 2 个核心文件:
~/.ssh/id_rsa:私钥(本地保存,切勿删除或复制给他人);~/.ssh/id_rsa.pub:公钥(需分发到hadoop102、hadoop103、hadoop104)
步骤5 :将hadoop102的公钥分发到 3 台机器(包括自己)
ssh-copy-id atguigu@hadoop102
ssh-copy-id atguigu@hadoop103
ssh-copy-id atguigu@hadoop104
验证:然后通过ssh atguigu@hadoop103,然后是102,104看看登录是否需要密码。
⑥Hadoop和JDK下载和部署
我下载的是 hadoop-3.3.6 版本,JDK是根据自身需求来。在atguigu的主节点 master 中的 /opt 目录下新建两个文件夹 module(存放数据) 和 sofeware (存放安装包):
这两个的下载链接我上面有,然后就需要你创建这两个文件,每台机器多要执行。
sudo mkdir -p /opt/software && sudo chown atguigu:atguigu /opt/software
然后下载一个XFTP:
下载之后新建一个会话,主机IP填虚拟机的,密码写自己atguigu账号的,其他的和我一样,最后要点链接而不是确定!
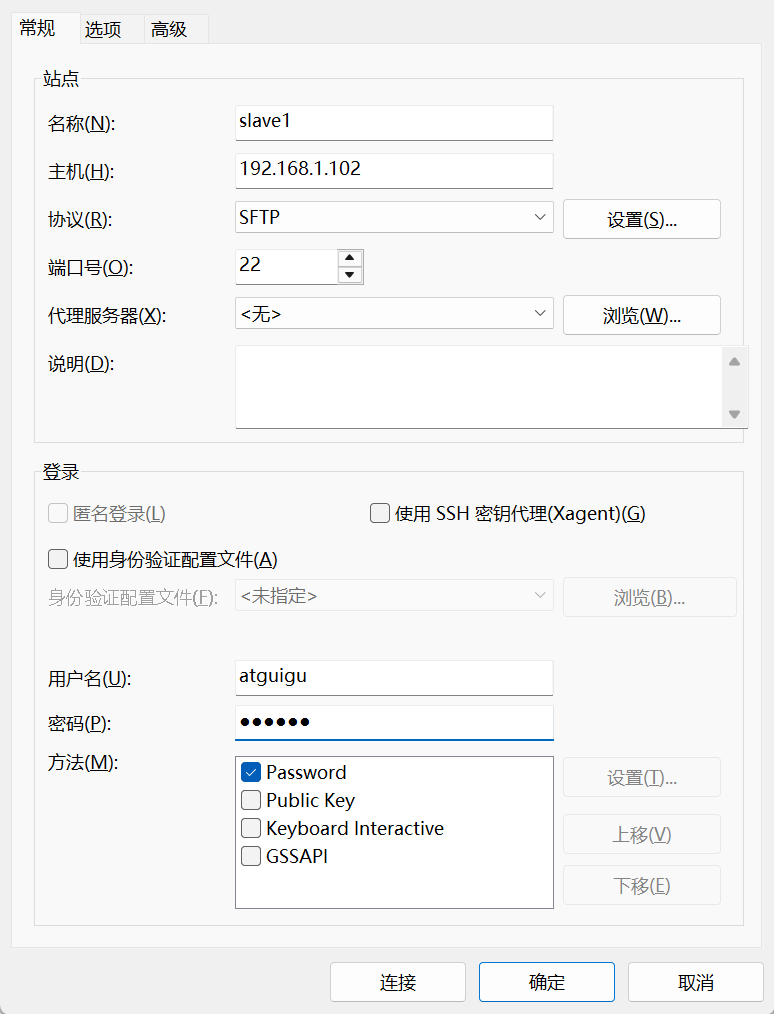
如果连接失败:
输入命令sudo vim /etc/ssh/sshd_config
修改里面的配置PasswordAuthentication yes(允许密码登录,默认应为yes,若为no则改为yes) ChallengeResponseAuthentication no(关闭挑战响应认证,避免干扰密码登录)
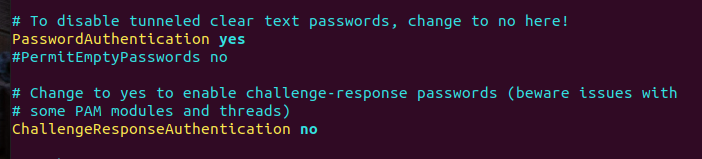
连接之后是这样:
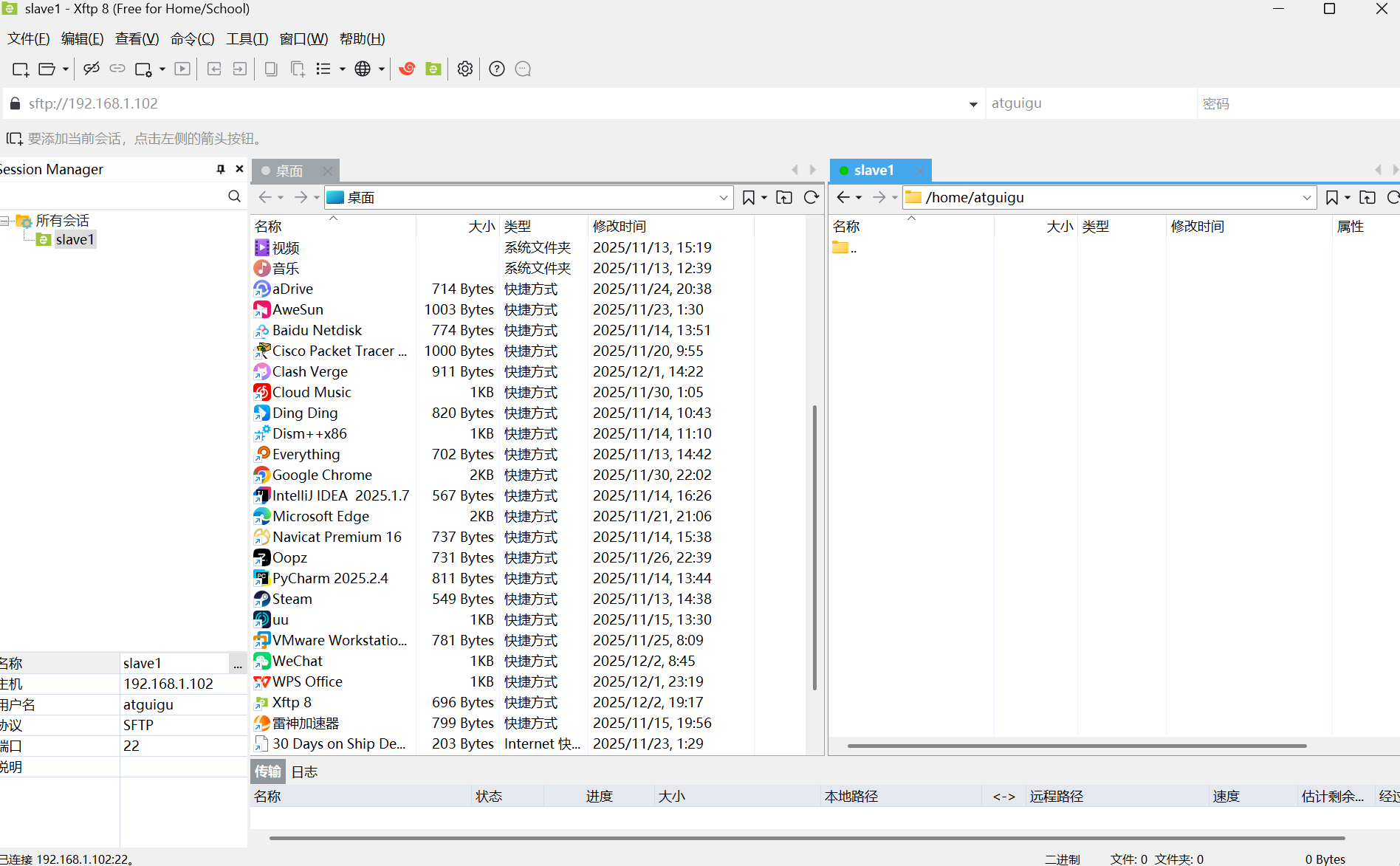
然后把Hadoop和JDK的压缩包传输到/opt/software目录下:
可输入ls /opt/software查看目录内容

同步到 hadoop103,104(下图以103为例)
# 同步JDK到hadoop103
scp /opt/software/jdk-8u181-linux-x64.tar.gz atguigu@hadoop103:/opt/software/
# 同步Hadoop到hadoop103
scp /opt/software/hadoop-3.3.6.tar.gz atguigu@hadoop103:/opt/software/把两个安装包解压到 /opt/module:
/opt/module 是我们约定的 "软件安装目录"(区别于存放安装包的/opt/software),必须给atguigu用户权限,否则无法解压文件到其中,每一个机器都要执行:
# 1. 用sudo创建/opt/module目录(需管理员权限,输入atguigu的密码)
sudo mkdir -p /opt/module
# 2. 将目录所有权转移给atguigu(确保后续能正常读写)
sudo chown -R atguigu:atguigu /opt/module
# 1. 解压JDK到/opt/module(-C 指定解压目标目录)
tar -zxvf /opt/software/jdk-8u181-linux-x64.tar.gz -C /opt/module/
# 2. 解压Hadoop到/opt/module
tar -zxvf /opt/software/hadoop-3.3.6.tar.gz -C /opt/module/执行命令:
ls /opt/module查看目录文件是否出现hadoop-3.3.6 jdk1.8.0_181
⑦配置 JDK 和 Hadoop 的环境变量
在atguigu用户下执行命令,打开/etc/profile文件(该文件对所有用户生效,适合集群统一配置):
sudo vim /etc/profile在/etc/profile文件的末尾 ,粘贴以下内容(注意替换JAVA_HOME和HADOOP_HOME路径为你实际的解压目录)
JDK Environment Variables
export JAVA_HOME=/opt/module/jdk1.8.0_181
export PATH=PATH:JAVA_HOME/bin
Hadoop Environment Variables
export HADOOP_HOME=/opt/module/hadoop-3.3.6
export PATH=PATH:HADOOP_HOME/bin
export PATH=PATH:HADOOP_HOME/sbin
然后执行命令:source /etc/profile 使配置生效。再执行以下命令查看版本信息是否对
hadoop version
java -version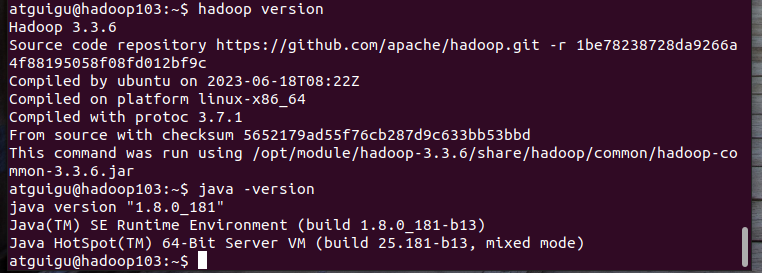
下一步配置 Hadoop 核心文件并启动集群:
在 Hadoop 配置中指定 JAVA_HOME
修改 Hadoop 的hadoop-env.sh文件(该文件专门配置 Hadoop 运行的环境变量),3 台机器均需修改。
步骤1在 hadoop102 上编辑hadoop-env.sh
进入 Hadoop 配置目录(hadoop102 的atguigu用户下):
cd $HADOOP_HOME/etc/hadoop
vim hadoop-env.sh
步骤 2:在文件中添加 JAVA_HOME 配置
在hadoop-env.sh文件的任意空白处 (建议开头或末尾),添加以下内容(路径需与你实际的 JDK 解压目录一致,你的 JDK 目录是/opt/module/jdk1.8.0_181):
# 手动指定JAVA_HOME,让Hadoop启动脚本能识别
export JAVA_HOME=/opt/module/jdk1.8.0_181步骤 3:同步hadoop-env.sh到 hadoop103 和 hadoop104
由于 3 台机器的 JDK 路径一致,直接同步修改后的文件到其他机器,避免重复操作:
# 同步到hadoop103
scp $HADOOP_HOME/etc/hadoop/hadoop-env.sh atguigu@hadoop103:$HADOOP_HOME/etc/hadoop/
# 同步到hadoop104
scp $HADOOP_HOME/etc/hadoop/hadoop-env.sh atguigu@hadoop104:$HADOOP_HOME/etc/hadoop/步骤4:配置 Hadoop 核心配置文件(仅 hadoop102 需先配置,再同步到其他机器)
各节点进程分发安排:
|------|-------------------|-----------------------------|----------------------------|
| | hadoop102 | hadoop103 | hadoop104 |
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
执行:cd $HADOOP_HOME/etc/hadoop 进入文件目录,在这个目录下操作
该目录下有core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml等核心配置文件。
(1)修改core-site.xml(指定 NameNode 地址)
vim core-site.xml在<configuration>标签内添加:
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<property>
<name>hadoop.data.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<property>
<name>hadoop.proxyuser.atguigu.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.atguigu.groups</name>
<value>*</value>
</property>(2)修改hdfs-site.xml(指定 DataNode 副本数、NameNode/DataNode 数据存储路径)
vim hdfs-site.xml在<configuration>标签内添加:
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.data.dir}/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.data.dir}/data</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file://${hadoop.data.dir}/namesecondary</value>
</property>
<property>
<name>dfs.client.datanode-restart.timeout</name>
<value>30</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>(3)修改yarn-site.xml
vim yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>(4)修改mapred-site.xml(指定 MapReduce 框架为 YARN)
vim mapred-site.xml在<configuration>标签内添加:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>同步配置文件到 hadoop103 和 hadoop104
hadoop102 配置完成后,用scp命令将整个hadoop配置目录同步到其他机器,避免重复修改:
# 同步到hadoop103
scp -r $HADOOP_HOME/etc/hadoop atguigu@hadoop103:$HADOOP_HOME/etc/
# 同步到hadoop104
scp -r $HADOOP_HOME/etc/hadoop atguigu@hadoop104:$HADOOP_HOME/etc/格式化NameNode:
hdfs namenode -format⑧验证集群
# 启动 HDFS(hadoop102 执行)
start-dfs.sh
# 启动 YARN(hadoop102 执行)
start-yarn.sh各点启动进程如下:
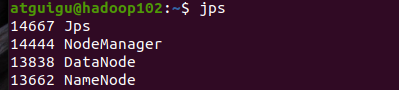
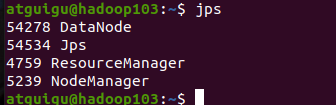
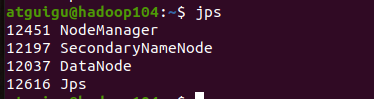
最后一步:确认 workers文件配置正确
vim $HADOOP_HOME/etc/hadoop/workers确保文件内容包含所有从节点
hadoop102
hadoop103
hadoop104再同步到其他节点
scp $HADOOP_HOME/etc/hadoop/workers hadoop103:$HADOOP_HOME/etc/hadoop/
scp $HADOOP_HOME/etc/hadoop/workers hadoop104:$HADOOP_HOME/etc/hadoop/测试HDFS 读写功能
# 创建HDFS目录
hdfs dfs -mkdir /test
# 上传本地文件到HDFS
hdfs dfs -put $HADOOP_HOME/README.txt /test
# 查看HDFS文件
hdfs dfs -ls /test测试 YARN 运行任务
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar pi 2 5运行成功:
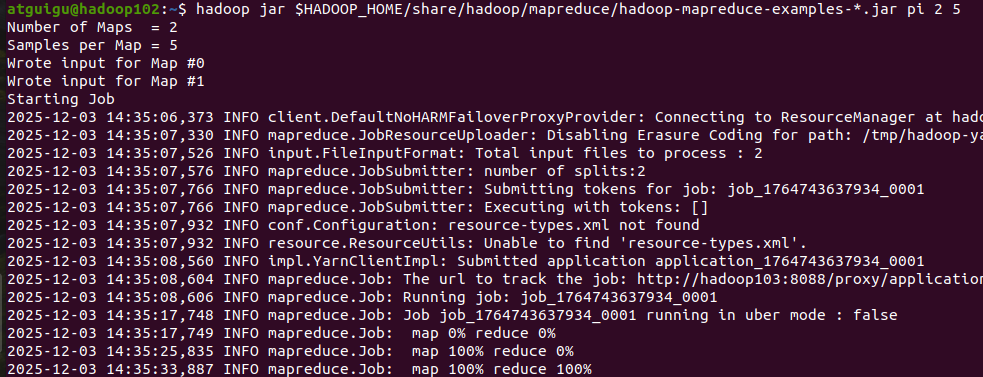
各个组件进程的端口网址:
HDFS 组件
| 进程 | 默认端口 | 用途 | Web 访问网址 |
|---|---|---|---|
| NameNode | 9870(HTTP) | NameNode Web UI | http://hadoop102:9870 |
| DataNode | 9864 | DataNode Web UI | http://<DataNode节点IP>:9864(如http://hadoop102:9864) |
| SecondaryNameNode | 9868(HTTP) | SecondaryNameNode Web UI | http://hadoop104:9868 |
YARN 组件
| 进程 | 默认端口 | 用途 | Web 访问网址 |
|---|---|---|---|
| ResourceManager | 8088(HTTP) | YARN 集群管理 Web UI | http://hadoop103:8088 |
| NodeManager | 8042(HTTP) | NodeManager Web UI | http://<NodeManager节点IP>:8042(如http://hadoop102:8042) |
MapReduce 组件(MRv2/YARN)
| 进程 | 默认端口 | 用途 | Web 访问网址 |
|---|---|---|---|
| JobHistoryServer | 19888(HTTP) | 历史任务查看 Web UI | http://<JobHistory节点IP>:19888(如:http://192.168.1.102:19888/jobhistory) |
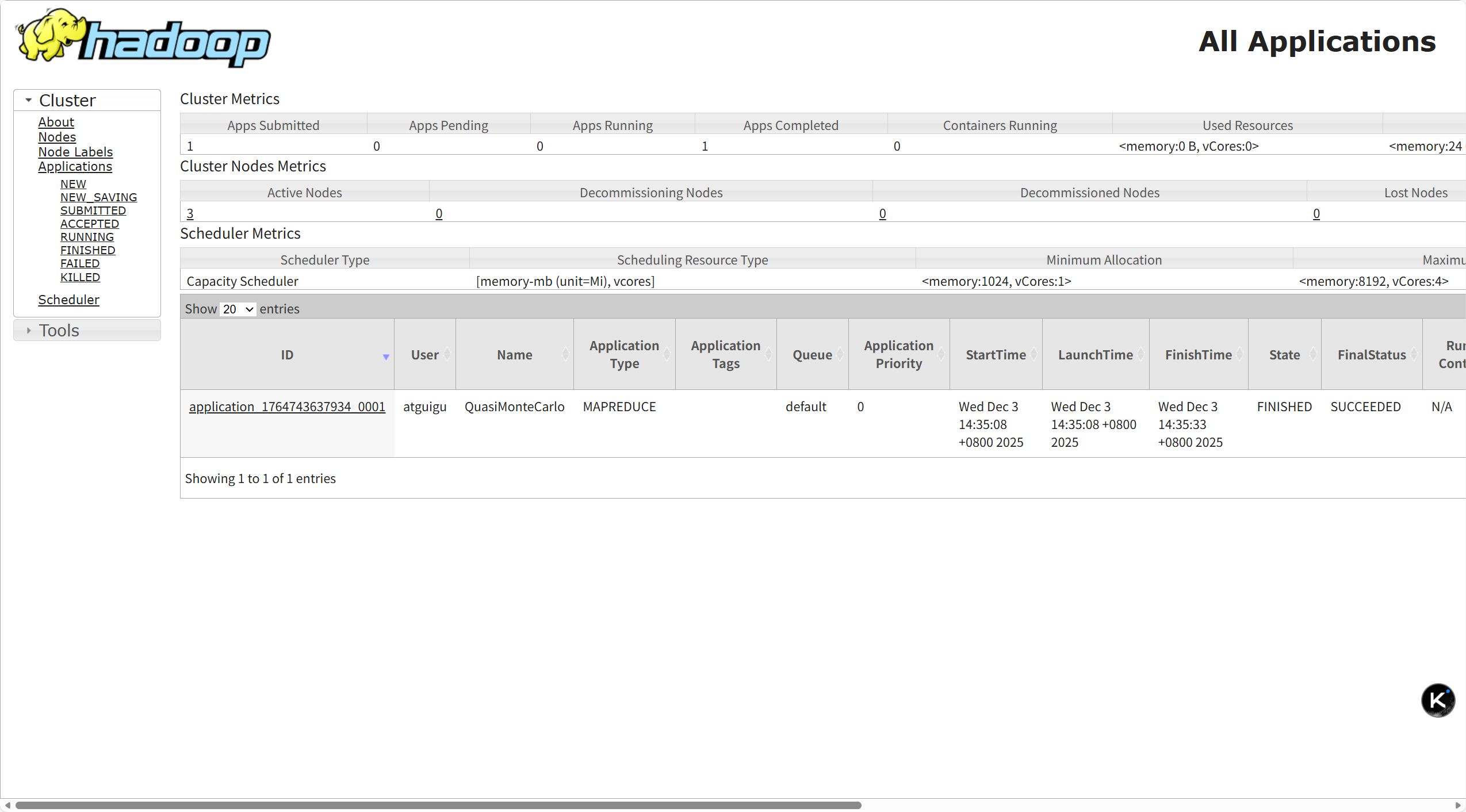
各web界面如下:
|----------------------------------------------------------------------------|----------------------------------------------------------------------------|
|  |
|  |
|
|  |
|  |
|
|  |
|  |
|
配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager。
开启日志聚集功能具体步骤如下:
- 配置yarn-site.xml
vim yarn-site.xml
在该文件里面增加如下配置。
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>分发配置
scp mapred-site.xml hadoop103:$HADOOP_HOME/etc/hadoop/关闭NodeManager 、ResourceManager和HistoryServer
在103上执行: stop-yarn.sh
在102上执行: mapred --daemon stop historyserver
启动NodeManager 、ResourceManager和HistoryServer
在103上执行:start-yarn.sh
在102上执行:mapred --daemon start historyserver
删除HDFS上已经存在的输出文件
hdfs dfs -rm -R /user/atguigu/output
在 HDFS 上创建输入目录
# 创建 /user/atguigu/input 目录(-p 确保父目录不存在时也能创建)
hdfs dfs -mkdir -p /user/atguigu/input- 准备本地文件(作为 WordCount 输入数据)
随便创建一个文本文件(比如 words.txt),里面写一些单词(用空格 / 换行分隔):
# 在本地家目录创建文件
vim ~/words.txt写入内容(示例):
hadoop spark hive
hadoop mapreduce yarn
spark hive hadoop
hello world hadoop-
将本地文件上传到 HDFS 输入目录
上传本地的 words.txt 到 HDFS 的 /user/atguigu/input 目录
hdfs dfs -put ~/words.txt /user/atguigu/input/
-
验证文件是否上传成功
查看 HDFS 输入目录下的文件
hdfs dfs -ls /user/atguigu/input
-
再次执行 WordCount 任务
确保输出目录不存在(避免报错)
hdfs dfs -rm -r /user/atguigu/output
执行 WordCount
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar wordcount /user/atguigu/input /user/atguigu/output
查看任务结果
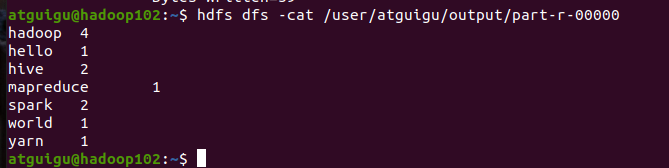
任务执行成功后,输出结果会保存在 /user/atguigu/output/part-r-00000(MapReduce 输出的默认结果文件),查看命令:
hdfs dfs -cat /user/atguigu/output/part-r-00000输出结果:
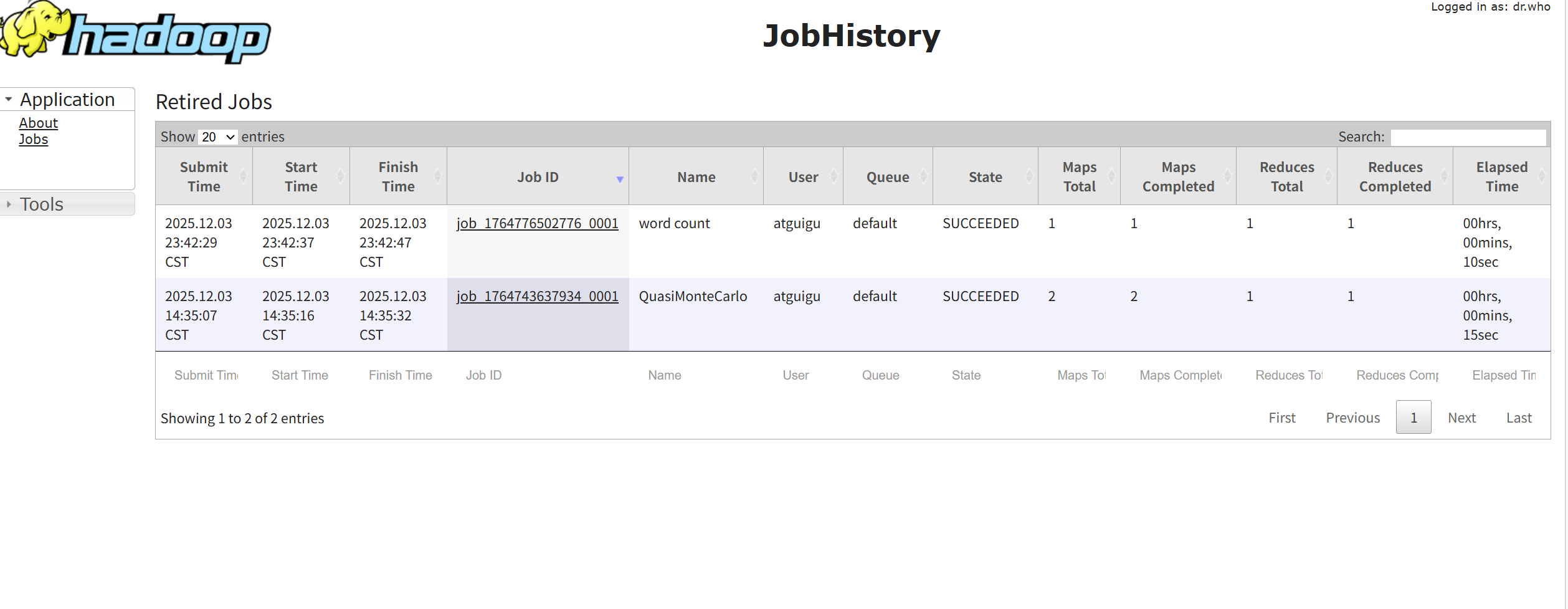
日志记录:
OK,全部流程结束,恭喜你完成了hadoop的完全分布式搭建!!