介绍
- 用java语言编写
- 对跨机器集群的数据进行分布式计算
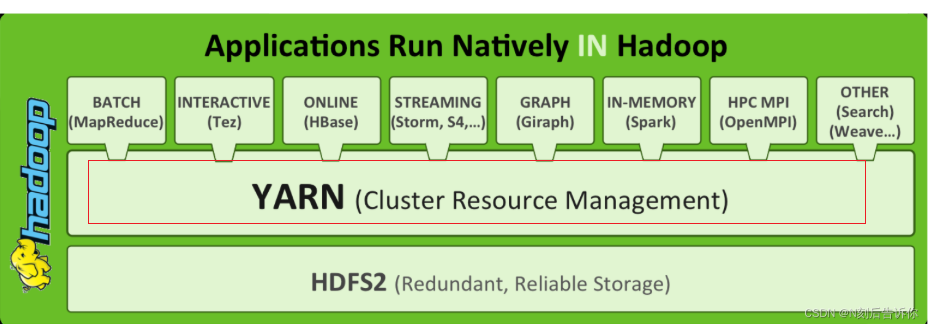
- Hadoop 由三大核心模块组成:HDFS 负责存储,YARN 负责资源调度,MapReduce 负责分布式计算。
核心组件:
- Hadoop HDFS(分布式文件存储系统Hadoop Distributed File System):解决海量数据存储
- Hadoop YARN(集群资源管理,任务调度框架Yet Another Resource Negotiator):解决资源任务调度
- Hadoop MapReduce(分布式计算框架):对海量数据进行计算。第一代分布式计算引擎,一般不直接使用
HDFS
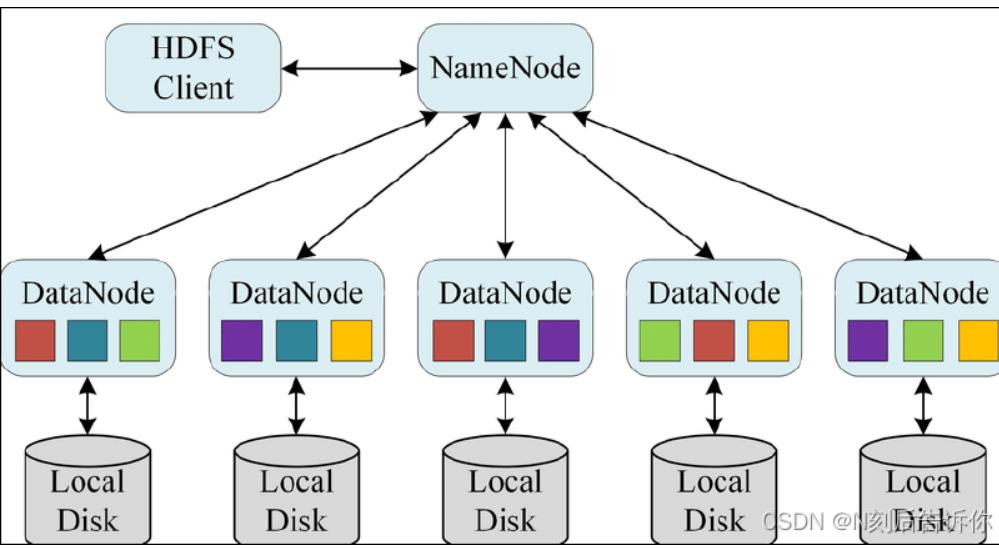
Hadoop分布式文件存储系统(Hadoop Distributed File System)
- namespace:命名空间(目录树)。(NameNode的name就是namespace)
HDFS 为什么适合存大文件,不适合存小文件?
分块存储(默认 128MB/256MB Block),每个block维持3个副本
不适合小文件,因为:
- 每个小文件至少会占用一个block(即使他的空间比block小),造成资源浪费。
- NameNode存储了元数据,并且每个block都要对应一条元数据,小文件的情况下就会造成元数据压力大
HDFS 的读写流程是什么?
读文件的流程
- Client 请求 NameNode 获取文件 Block 的 DataNode 列表
- 根据就近原则选择一个 DataNode
- 与 DataNode 建立流式读取
流式读取(streaming read):DataNode 通过网络持续、分段地向客户端发送 Block 数据,而不是一次性读完整个block再返回。
写文件的流程
- Client 向 NameNode 请求写文件
- NameNode 返回 DataNode 列表(副本位置)
- Client 以 Pipeline 方式向第一个 DataNode 写数据
- 第一个写给第二个,第二个写给第三个(复制链)
- 所有 DataNode 写完返回 ACK,NameNode 更新元数据、写入完成
Pipeline写文件时,Client 写 Block 的第 1 个副本,然后由这个副本节点用链式方式继续把同一个 Block 复制到其他副本节点的过程。
NameNode 宕机怎么办?它如何保证高可用?(HDFS HA)
HA:High Availability(高可用)
HDFS HA 是通过双 NameNode( Active/Standby )来实现的。他们通过共享 EditLog(写操作日志)来保证数据一致,并且DataNode会同时向两个NameNode汇报最新信息,来及时更新block情况,当Active挂了后,Standby会变成新的Active来保证高可用
YARN
可以把Hadoop YARN理解为相当于一个分布式的操作系统平台,而MapReduce等计算程序则相当于运行于操作系统之上的应用程序,YARN为这些程序提供运算所需的资源(内存、CPU等)。
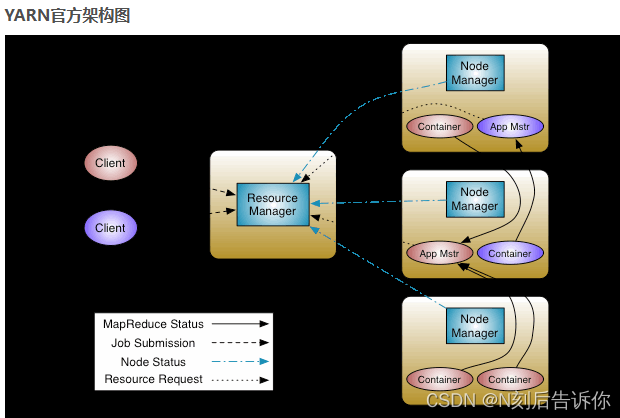
请描述YARN的基本架构和核心组件的工作流程。
- ResourceManager - 全局资源管理器
- NodeManager - 单节点资源管理器:定期向ResourceManager汇报本节点的资源使用状况
- ApplicationMaster - 单个应用的管理者
工作流程:
- 客户端 将应用程序(如MapReduce Job)提交给 ResourceManager
- RM选择一台NM创建一个Container,并且在这里面启动AM(AM是在第一个NM里的)
- AM启动之后,会将程序拆分成Task,并且RM申请容器,将Task发送到NM的容器中运行
- 容器中运行的任务会向 ApplicationMaster 发送心跳,汇报自身情况。当程序运行完成后, ApplicationMaster 再向 ResourceManager 注销并释放容器资源。
container指的是资源的抽象比如说内存和CPU
YARN的调度器(Scheduler)有哪些?它们之间有什么区别和优缺点?
| 调度器 | 核心策略 | 银行比喻 (例子) | 主要优点 (好处) | 主要缺点 (挑战) | 适用场景 |
|---|---|---|---|---|---|
| FIFO | 先进先出 (排队顺序) | 单一排队,先来先服务。 | 配置最简单。 | 不公平,大作业会阻塞所有小作业。 | 已淘汰,仅用于极小规模测试。 |
| Capacity (容量) | 容量保证 + 弹性借用 | 专属窗口,保证核心业务服务,闲时可借用。 | ✅ 隔离性好 :确保核心业务的资源(硬性保证)。 ✅ 利用率高:空闲资源允许借用。 | ❌ 配置复杂:需要事先划分队列容量。 | 工业界主流:多部门、多租户、对 SLA 有要求。 |
| Fair (公平) | 公平共享 + 权重分配 | 轮流服务,确保所有人都能在短时间内被处理。 | ✅ 响应快 :所有作业都能及时启动运行。 ✅ 动态灵活:资源分配可根据权重动态调整。 | ❌ 隔离性弱:资源保证不如 Capacity 严格。 | 共享池场景:资源需要平等分配给所有用户,强调响应时间。 |
Capacity:当一个队列的资源空闲时,他可以给其他借用,但是如果当前队列有任务的话,立刻收回资源
Fair:保证所有任务的资源都是平均的,不管大小任务
当遇到一个YARN作业运行非常慢或者失败时,你的排查思路是什么?
- 在RM UI上看应用的总体状态:是ACCEPTED, RUNNING, 还是FAILED?
- 如果是失败的话,就要详细的查看下Spark日志了
- 然后可以看看队列的资源情况,如果没有资源了
- 一般我们的做法就是让用户换一个不可抢占队列就可以了
- 查看AM UI,检查是否有少数MapTask或ReduceTask运行时间远超其他任务。这是导致速度慢的常见原因。但是这种情况我没有处理过
架构图
MapReduce
请详细描述一下 MapReduce 的完整工作流程。
MapReduce 的工作流程主要分为 5 个阶段:输入、Map、Shuffle & Sort、Reduce、输出。
- 输入分片 (Input Splitting) & RecordReader:
- HDFS 上的文件会被切分成逻辑上的输入分片 (Input Split)。
RecordReader负责读取每个 Split 的数据,将其解析成一个个<Key, Value>对,传递给 Map 函数。
- Map 阶段 (Mapping):
- 用户自定义的
Mapper函数接收<Key, Value>对。 - Mapper 对数据进行处理,并输出一组新的中间
<Key, Value>对。
- 用户自定义的
- Shuffle & Sort 阶段 (核心):
- 分区 (Partitioner): 根据 Key 的哈希值确定该数据应该发送给哪个
Reducer。
- 分区 (Partitioner): 根据 Key 的哈希值确定该数据应该发送给哪个
- Reduce 阶段 (Reducing):
- 用户自定义的
Reducer函数接收<Key, List<Value>>。 - Reducer 对值列表进行聚合、计算或汇总,并输出最终结果。
- 用户自定义的
- 输出 (Output):
- 由
OutputFormat将最终的<Key, Value>对写入 HDFS 或其他存储系统
- 由
MapReduce 中的 Shuffle 阶段具体做了什么?为什么说它是性能优化的关键?
Shuffle是连接Map和Reduce的关键
先将Mapper端的机器进行Partition(分区,规则: Hash(城市名) % Reducer数量)
在将Mapper端的机器进行merge,Mapper 自己算出:<北京, 1000万元>(将 100万条数据浓缩成 1 条)
再就是Reduce端了,Reduce会去Mapper端根据标签拉数据
之后将每一个Mapper端拉取的数据进行归并排序
最后这里不属于shuffle,是reduce只要顺序执行就可以了
请说明 Partitioner 和 Combiner 的作用和区别。
| 特性 | Partitioner (分区器) | Combiner (合并器) |
|---|---|---|
| 作用 | 决定 Map 输出的 Key-Value 对应该发送给哪个 Reducer。 | 在 Map 端对数据进行本地预聚合。 |
| 执行位置 | Map 端(Shuffle 开始之前)。 | Map 端(溢写到磁盘之前)。 |
| 职能 | 负责数据的分配和路由(逻辑)。 | 负责数据的局部计算(优化)。 |
| 可选性 | 必需 (默认为 HashPartitioner)。 |
可选(仅用于优化,不是所有算法都适用)。 |
| 关键区别 | Partitioner 决定数据去哪里 ;Combiner 决定数据变多小。 | |
| 优化意义 | 确保数据在 Reducer 之间均匀分配,避免数据倾斜。 | 减少溢写到磁盘和网络传输的数据量,大幅提升性能。 |
Combiner的流程是在merge中,主要目的是减少内存写入磁盘的IO以及之后reduce拉取数据的网络传输
补充
👉 早期 Hadoop 自带的 MapReduce 既负责调度又负责计算,后来为了让其他计算框架(不仅仅是 MR)也能用 Hadoop 集群的资源,就把调度 拆出来形成 YARN (Yet Another Resource Negotiator)。
据的网络传输
补充
👉 早期 Hadoop 自带的 MapReduce 既负责调度又负责计算,后来为了让其他计算框架(不仅仅是 MR)也能用 Hadoop 集群的资源,就把调度 拆出来形成 YARN(Yet Another Resource Negotiator)。