继续跟进《文档智能》,最近多模态的文档解析模型一个接一个开源《文档智能解析方案总结进展更新(含ocr-pipline、layout+VLM+纯多模态端到端解析)》。下面继续看看腾讯开源的HunyuanOCR。HunyuanOCR的OCR任务(文本检测与识别、文档解析、信息提取与视觉问答、文本图像翻译)。
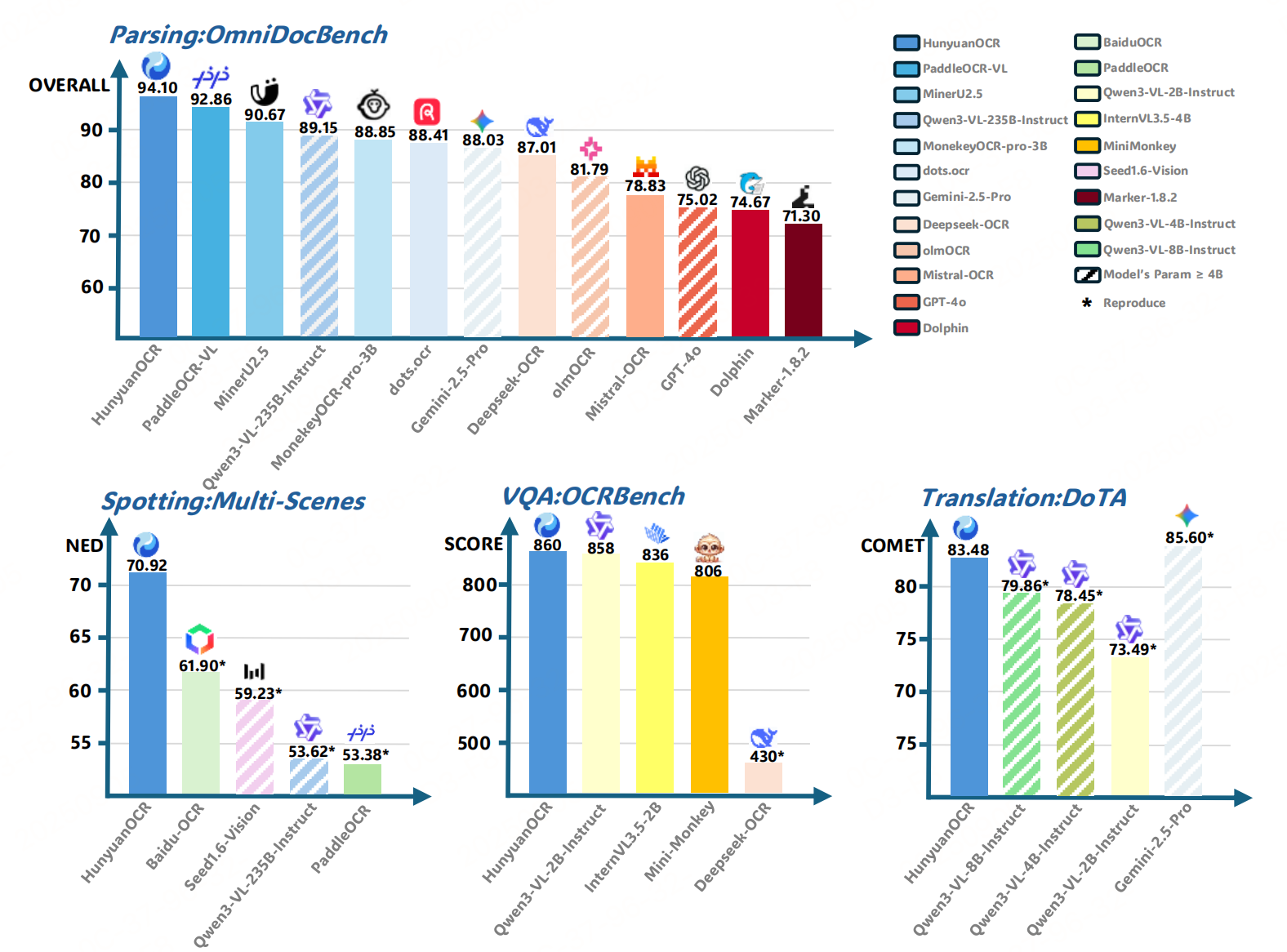
模型架构

视觉编码器(SigLIP-v2-400M)+MLP+LLM(Hunyuan-0.5B)=0.9B
训练方法
HunyuanOCR的训练方案包含四阶段预训练 和针对性强化学习 两大环节,通过数据质量把控、任务自适应优化,训练1B参数模型。
1、预训练:四阶段递进式优化
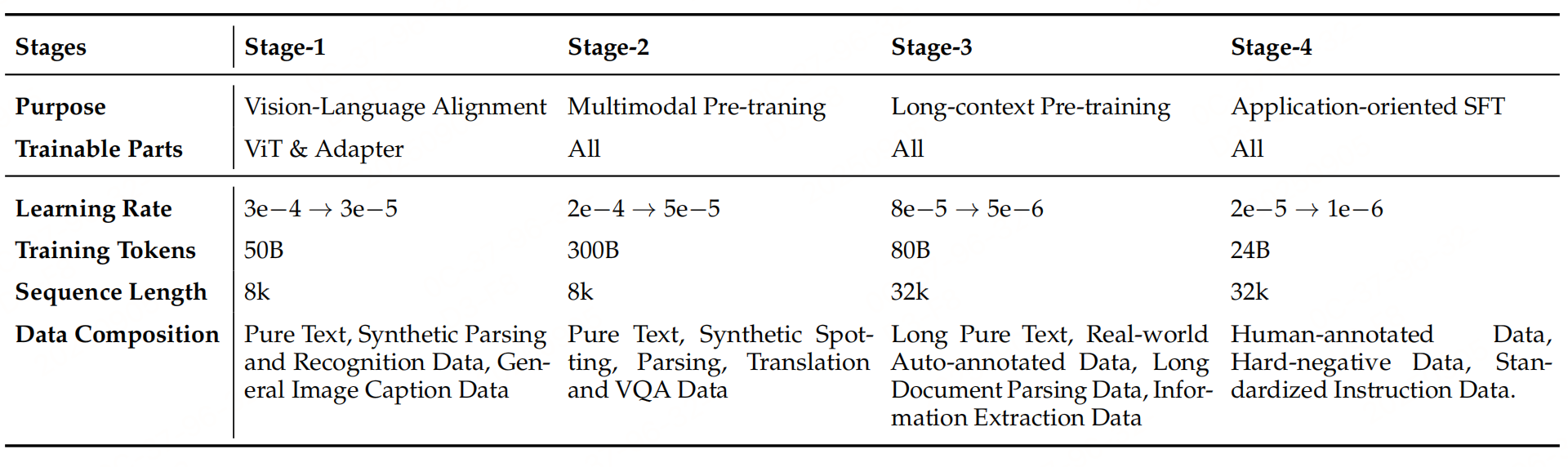
预训练采用四阶段逐步解锁。
-
阶段1:视觉-语言对齐:仅训练视觉编码器(ViT)和MLP适配器,冻结语言模型。用50B tokens训练,学习率从3e-4衰减至3e-5,聚焦文本解析与识别基础能力。
-
阶段2:多模态预训练:解锁所有参数,进行端到端联合学习。用300B tokens训练,学习率从2e-4衰减至5e-5,强化文档、表格等结构化内容的理解与推理。
-
阶段3:长上下文预训练:扩展上下文窗口至32K tokens,支持长文档处理。用80B tokens训练,学习率从8e-5衰减至5e-6,纳入长文本和真实场景自动标注数据。
-
阶段4:SFT:用标注数据+高质量合成数据退火训练,保持32K上下文。用24B tokens训练,学习率从2e-5衰减至1e-6,统一任务指令和输出格式,为RL铺垫。
2、强化学习:任务自适应优化
围绕"数据-奖励-算法"。
2.1 数据构建
- 筛选高质量开源+合成数据,剔除易作弊样本(如多选题)。
- 覆盖 spotting、解析、IE、翻译等全场景,平衡任务难度,避免 trivial 或无解样本。
2.2 奖励设计:任务自适应
- spotting:结合IoU(定位)和编辑距离(识别)计算奖励,平衡定位与识别精度。
- 文档解析:基于输出与真值的归一化编辑距离评分。
- VQA:二元奖励(1/0),仅关注内容完整性和事实正确性。
- 翻译:LLM打分(0-5分)后归一化,中间区间(2-4分)扩大粒度,捕捉细微质量差异。
2.3 训练策略:GRPO算法+格式约束
GRPO算法强化格式约束:超长度或不符合结构化要求的输出直接判0分,确保模型输出有效性。
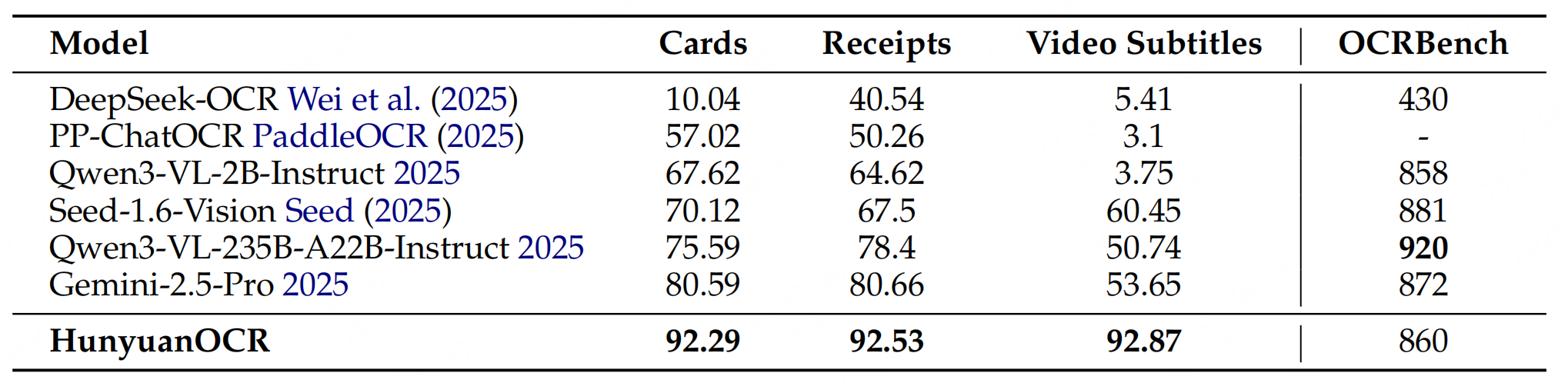
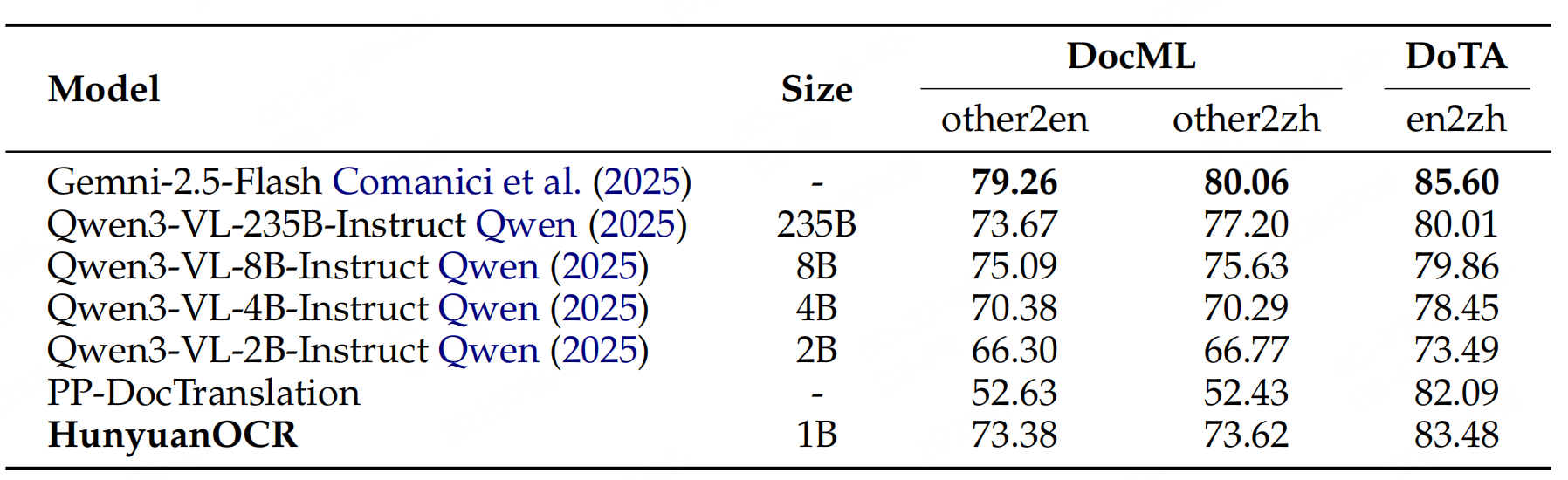
实验性能

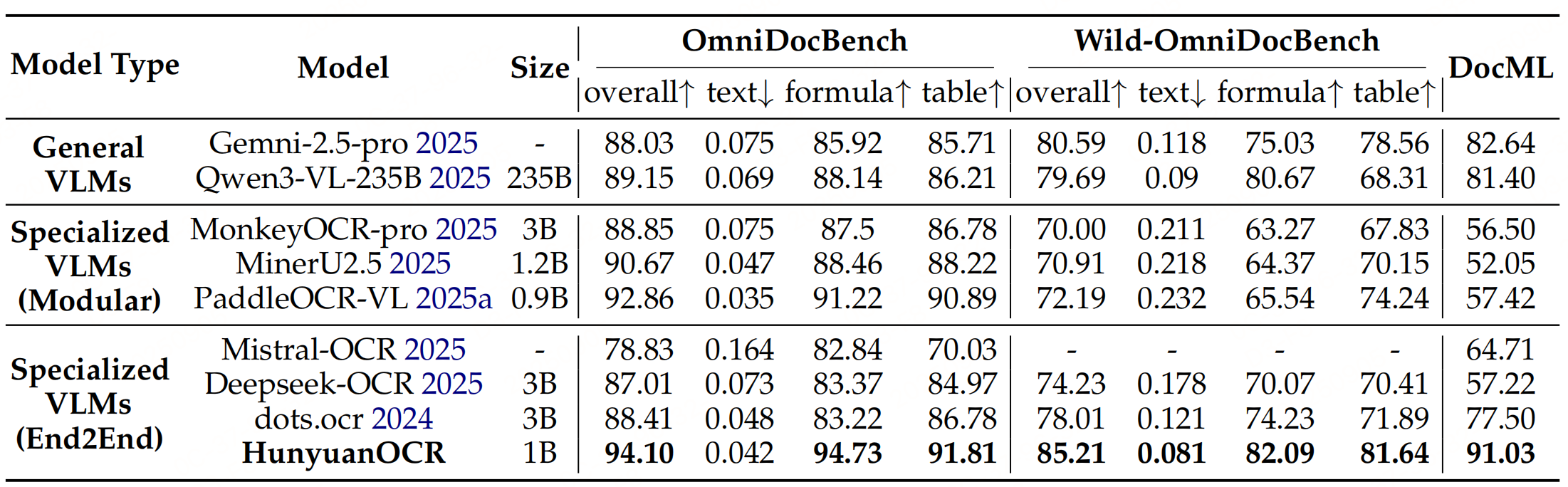
参考文献:HunyuanOCR Technical Report,https://github.com/Tencent-Hunyuan/HunyuanOCR/blob/main/HunyuanOCR_Technical_Report.pdf