《📚 全面解析RAG技术:从原理到实战------基于Streamlit的智能文档问答系统》
【注:代码附于文章末尾,代码简单容易入手】
- [《📚 全面解析RAG技术:从原理到实战------基于Streamlit的智能文档问答系统》](#《📚 全面解析RAG技术:从原理到实战——基于Streamlit的智能文档问答系统》)
-
- 一、什么是RAG(检索增强生成)?
- 二、RAG与语义搜索的区别
- 三、RAG系统关键模块详解
-
- [1. 文档加载器(Document Loaders)](#1. 文档加载器(Document Loaders))
- [2. 文本分割器(Text Splitters)](#2. 文本分割器(Text Splitters))
- [3. 向量嵌入与存储(Embedding & Vector Store)](#3. 向量嵌入与存储(Embedding & Vector Store))
- [4. 检索器(Retriever)](#4. 检索器(Retriever))
- [5. 对话记忆(Memory)](#5. 对话记忆(Memory))
- [6. 智能代理(Agent)](#6. 智能代理(Agent))
- 四、项目实战:基于Streamlit的RAG问答系统
- 五、项目效果演示
- 六、总结与展望
一、什么是RAG(检索增强生成)?
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合了检索系统 与生成模型的混合型AI技术。其核心思想是:在大型语言模型(LLM)生成答案之前,先从外部知识库中检索相关文档片段,将这些信息作为上下文与用户查询一起输入给模型,从而生成更准确、更可信的答案。
RAG的核心优势:
- ✅ 经济高效:无需重新训练大模型,只需构建外部知识库。
- ✅ 信息实时性:可动态更新知识库,让模型回答基于最新信息。
- ✅ 增强可信度:答案可附带来源引用,提升用户信任。
- ✅ 可控性强:开发人员可以控制知识来源,避免模型"胡言乱语"。
二、RAG与语义搜索的区别
很多人容易混淆RAG和语义搜索,其实二者是互补关系:
- 语义搜索:侧重于从大规模文档中准确检索出相关段落,常用于问答系统、知识库搜索。
- RAG:在检索的基础上,利用LLM对检索结果进行整合、推理、生成自然语言回答。
可以说,语义搜索是RAG的"检索引擎"部分,而RAG在此基础上增加了"智能生成"能力。
三、RAG系统关键模块详解
一个完整的RAG系统通常包含以下几个核心模块:
1. 文档加载器(Document Loaders)
用于从不同格式的文件中加载文本内容,如:
- CSV、HTML、PDF、TXT、Markdown等
- 支持从Slack、Notion、Google Drive等平台导入
示例代码(加载CSV):
python
from langchain_community.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path="data.csv")
data = loader.load()2. 文本分割器(Text Splitters)
由于大模型有输入长度限制,需将长文档切分为小块。常用方法:
- 递归分割:按段落→句子→单词的优先级切割
- 语义分割:根据句子之间的语义相似度进行分组
示例(递归分割):
python
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(documents)3. 向量嵌入与存储(Embedding & Vector Store)
将文本转换为向量,并存入向量数据库以便快速检索:
- 常用嵌入模型:OpenAI Embeddings、Sentence-BERT等
- 常用向量库:Chroma、FAISS、Pinecone
python
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(chunks, embeddings)4. 检索器(Retriever)
根据用户查询,从向量库中检索最相关的文档片段:
python
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
docs = retriever.invoke("什么是执剑人?")5. 对话记忆(Memory)
为了让AI记住对话历史,需引入记忆机制:
python
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(return_messages=True, memory_key="chat_history")6. 智能代理(Agent)
结合工具调用与推理能力,实现自主决策的问答代理:
python
from langchain.agents import create_react_agent, AgentExecutor
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, memory=memory)四、项目实战:基于Streamlit的RAG问答系统
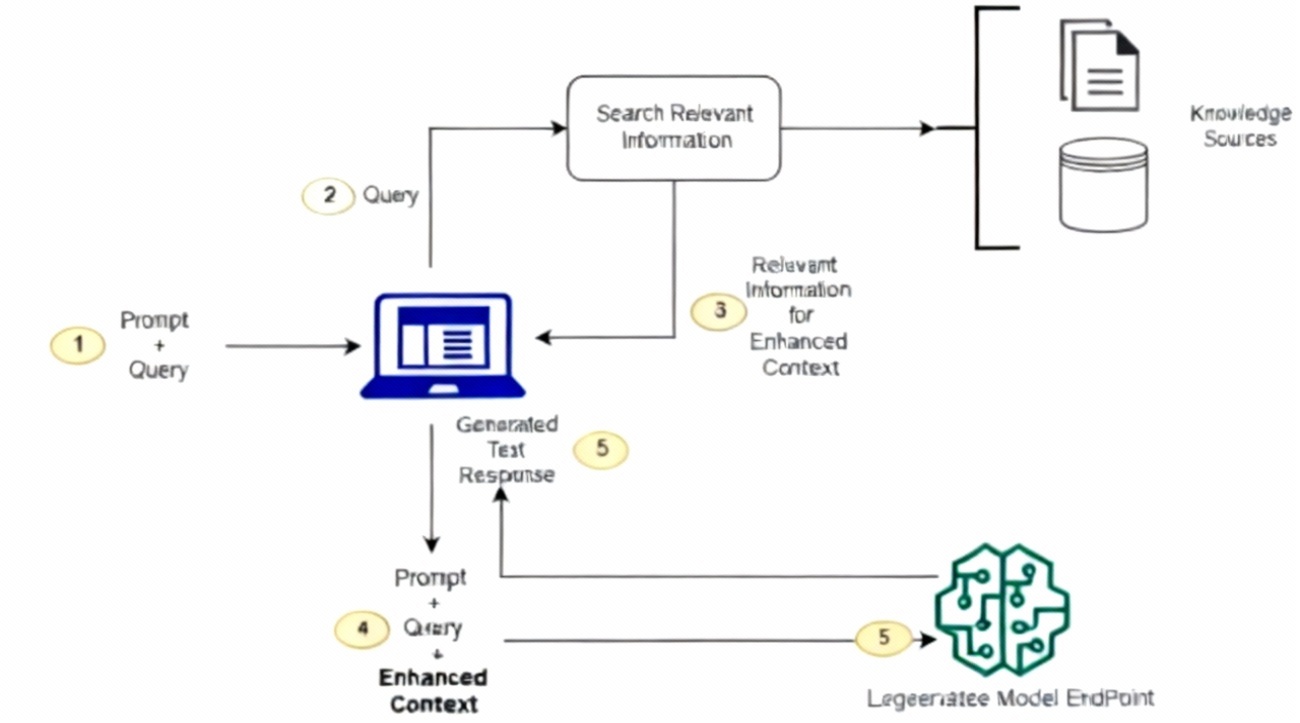
系统架构图
用户上传TXT → 文档加载 → 文本分割 → 向量化存储 → 检索器构建 → 用户提问 → 检索+生成 → 返回答案步骤一:环境搭建
bash
pip install streamlit langchain langchain-openai langchain-chroma langchain-community步骤二:实现文件上传与处理
python
import streamlit as st
uploaded_files = st.sidebar.file_uploader("上传TXT文件", type=["txt"], accept_multiple_files=True)步骤三:构建检索器(带缓存)
python
@st.cache_resource(ttl="1h")
def configure_retriever(uploaded_files):
# 读取文档
docs = []
for file in uploaded_files:
loader = TextLoader(file, encoding="utf-8")
docs.extend(loader.load())
# 分割文本
splitter = RecursiveCharacterTextSplitter(chunk_size=300, chunk_overlap=50)
splits = splitter.split_documents(docs)
# 向量化存储
embeddings = OpenAIEmbeddings()
vectordb = Chroma.from_documents(splits, embeddings)
return vectordb.as_retriever()步骤四:创建对话代理
python
from langchain.tools.retriever import create_retriever_tool
tool = create_retriever_tool(retriever, "文档检索", "用于检索用户问题相关的文档内容")
tools = [tool]
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, memory=memory)步骤五:交互界面实现
python
user_query = st.chat_input("请输入您的问题:")
if user_query:
response = agent_executor.invoke({"input": user_query})
st.chat_message("assistant").write(response["output"])步骤六:运行应用
bash
streamlit run my_rag_app.py五、项目效果演示
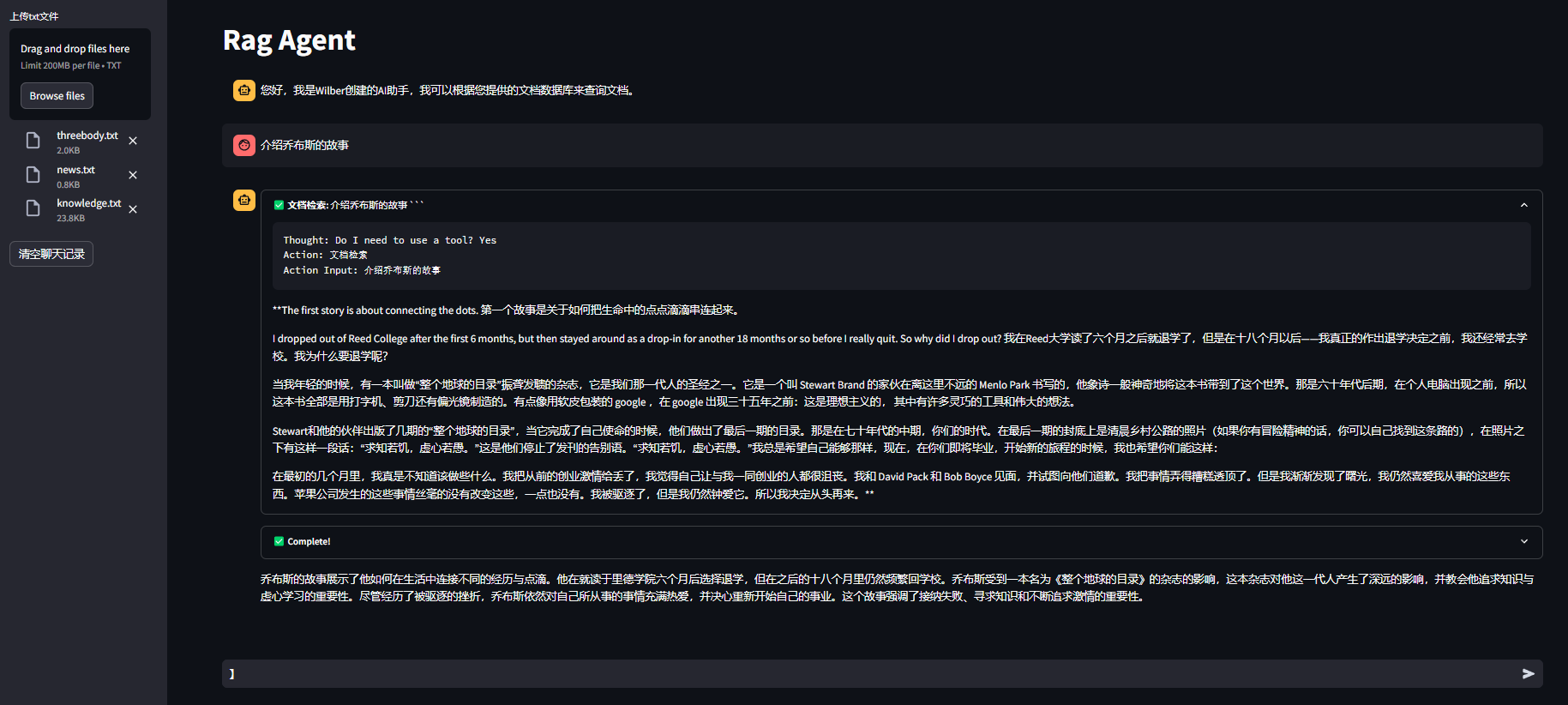
我们以《三体》相关内容为例:
上传文档内容:
执剑人是掌握地球与三体文明之间威慑平衡的关键人物...
罗辑通过与三体文明的对话和博弈,利用智慧与黑暗森林法则威胁三体文明...问答示例:
用户:执剑人是什么角色?
AI:在《三体》系列中,执剑人是掌握地球与三体文明之间威慑平衡的关键人物...
用户:罗辑通过什么方法威胁三体文明?AI:罗辑通过与三体文明的对话和博弈,利用黑暗森林法则...
六、总结与展望
本文从RAG的基本原理出发,详细讲解了其核心模块,并实现了一个完整的基于Streamlit的RAG智能问答系统。该系统支持:
- 📁 多文件上传
- 🧠 对话记忆
- 🔍 语义检索
- 🤖 智能生成
未来可扩展方向:
- 支持更多文件格式(PDF、Word、PPT)
- 集成多源知识库
- 加入联网搜索能力
- 实现多轮对话优化
相关技术栈:
- LangChain
- Streamlit
- OpenAI API
- Chroma DB
如果你对RAG技术或LangChain开发感兴趣,欢迎在评论区留言讨论,别忘了点赞收藏哦!🌟
【代码附录】
python
import streamlit as st
import tempfile
import os
from langchain_classic.memory import ConversationBufferMemory
from langchain_community.chat_message_histories import StreamlitChatMessageHistory
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
from langchain_core.prompts import PromptTemplate
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_classic.agents import create_react_agent, AgentExecutor
from langchain_community.callbacks.streamlit import StreamlitCallbackHandler
from langchain_openai import ChatOpenAI
from langchain_core.tools.retriever import create_retriever_tool
# 设置st应用地页面标题与布局
st.set_page_config(page_title="Rag Agent", layout="wide")
st.title("Rag Agent")
# 上传文件,可多个
uploaded_files = st.sidebar.file_uploader(
label="上传txt文件", type=["txt"], accept_multiple_files=True
)
# 若没有上传文件则提醒用户上传并停止运行
if not uploaded_files:
st.info("请先上传按TXT文档。")
st.stop()
# 实现检索器,返回一个检索对象
@st.cache_resource(ttl="1h")
def configure_retriever(uploaded_files):
# 读取上传文档并创建临时目录存取
docs = []
temp_dir = tempfile.TemporaryDirectory(dir=r"D:\\")
for file in uploaded_files:
temp_filepath = os.path.join(temp_dir.name, file.name)
with open(temp_filepath, "wb") as f:
f.write(file.getvalue())
# 用TextLoader加载文件
loader = TextLoader(temp_filepath, encoding="UTF-8")
docs.extend(loader.load())
# 进行文档分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=300, chunk_overlap=50)
splits = text_splitter.split_documents(docs)
# 调用OpenAI的向量模型生成文档的向量表示
embeddings = OpenAIEmbeddings()
vectordb = Chroma.from_documents(splits, embeddings)
# 创建文档检索器
retriever = vectordb.as_retriever()
return retriever
# 配置检索器
retriever = configure_retriever(uploaded_files)
# 如果session_state中没有消息记录或用户点击了清空聊天记录按钮,则初始化消息记录
if "messages" not in st.session_state or st.sidebar.button("清空聊天记录"):
st.session_state["messages"] = [{"role": "assistant", "content": "您好,我是Wilber创建的AI助手,我可以根据您提供的文档数据库来查询文档。"}]
# 加载历史聊天记录
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg["content"])
# 创建检索工具
tool = create_retriever_tool(
retriever,
"文档检索",
"用于检索用户提出的问题,并基于检索到的文档内容进行回复.",
)
tools = [tool]
# 创建聊天消息历史记录
msgs = StreamlitChatMessageHistory()
# 创建对话缓冲区内存
memory = ConversationBufferMemory(
chat_memory=msgs, return_messages=True, memory_key="chat_history", output_key="output"
)
# 指令模板
instructions = """
您是一个设计用于查询文档来回答问题的代理。
您可以使用文档检索工具,并基于检索内容来回答问题
您可能不查询文档就知道答案,但是您仍然应该查询文档来获得答案。
如果您从文档中找不到任何信息用于回答问题,则只需返回"抱歉,这个问题我还不知道。"作为答案。
"""
base_prompt_template = """
{instructions}
TOOLS:
------
You have access to the following tools:
{tools}
To use a tool, please use the following format:
```
Thought: Do I need to use a tool? Yes
Action: the action to take, should be one of [{tool_names}]
Action Input: {input}
Observation: the result of the action
```
When you have a response to say to the Human, or if you do not need to use a tool, you MUST use the format:
```
Thought: Do I need to use a tool? No
Final Answer: [your response here]
```
Begin!
Previous conversation history:
{chat_history}
New input: {input}
{agent_scratchpad}"""
# 创建基础模板
base_prompt = PromptTemplate.from_template(base_prompt_template)
# 创建部分填充的提示模板
prompt = base_prompt.partial(instructions=instructions)
# 创建llm
llm= ChatOpenAI()
# 创建react Agent
agent = create_react_agent(llm, tools, prompt)
# 创建Agent执行器
agent_executor = AgentExecutor(agent=agent,tools=tools, memory=memory, verbose=True, handle_parsing_errors=True)
# 创建聊天输入框
user_query = st.chat_input(placeholder="请输入您的问题:")
# 若有用户输出的查询
if user_query:
# 将用户消息添加到session_state
st.session_state.messages.append({"role":"user", "content": user_query})
# 显示用户消息
st.chat_message("user").write(user_query)
with st.chat_message("assistant"):
# 创建Streamlit回调处理器
st_cb = StreamlitCallbackHandler(st.container())
# agent执行过程日志回调显示在Streamlit Container (如思考、选择工具、执行查询、观察结果等)
config = {"callbacks": [st_cb]}
# 执行Agent并获取响应
response = agent_executor.invoke({"input": user_query}, config=config)
# 添加助手消息到session_state
st.session_state.messages.append({"role": "assistant", "content": response["output"]})
# 显示助手响应
st.write(response["output"])