目录
[1.2 推荐系统原理](#1.2 推荐系统原理)
[1.2.1 机器学习视角下的推荐系统](#1.2.1 机器学习视角下的推荐系统)
[1.2.1.1 推荐问题的数学形式化](#1.2.1.1 推荐问题的数学形式化)
[1.2.1.2 特征工程在推荐系统中的作用](#1.2.1.2 特征工程在推荐系统中的作用)
[1.2.1.3 传统机器学习模型在推荐系统中的应用](#1.2.1.3 传统机器学习模型在推荐系统中的应用)
[1. 矩阵分解模型](#1. 矩阵分解模型)
[2. 因子分解机(Factorization Machine, FM)](#2. 因子分解机(Factorization Machine, FM))
[3. 梯度提升决策树(GBDT)](#3. 梯度提升决策树(GBDT))
[1.2.1.4 推荐系统的评估指标](#1.2.1.4 推荐系统的评估指标)
[1. 评分预测指标](#1. 评分预测指标)
[2. 分类指标](#2. 分类指标)
[3. 排序指标](#3. 排序指标)
[4. 业务指标](#4. 业务指标)
[1.2.1.5 推荐系统的冷启动问题](#1.2.1.5 推荐系统的冷启动问题)
[1. 用户冷启动](#1. 用户冷启动)
[2. 物品冷启动](#2. 物品冷启动)
[3. 系统冷启动](#3. 系统冷启动)
[1.2.1.6 推荐系统的偏差与公平性](#1.2.1.6 推荐系统的偏差与公平性)
[1. 选择偏差(Selection Bias)](#1. 选择偏差(Selection Bias))
[2. 流行度偏差(Popularity Bias)](#2. 流行度偏差(Popularity Bias))
[3. 位置偏差(Position Bias)](#3. 位置偏差(Position Bias))
[1.2.1.7 传统推荐系统的局限性](#1.2.1.7 传统推荐系统的局限性)
[1.2.1.8 传统机器学习推荐系统的总结](#1.2.1.8 传统机器学习推荐系统的总结)
1.2 推荐系统原理
推荐系统作为连接用户与信息的重要桥梁,其核心原理涉及多个学科领域,包括机器学习、信息检索、人机交互等。本节将从机器学习视角、深度学习范式以及系统架构三个维度,全面剖析推荐系统的工作原理。
1.2.1 机器学习视角下的推荐系统
从机器学习的角度看,推荐系统本质上是一个信息过滤系统,它通过学习用户的历史行为模式来预测用户对新物品的偏好。这一过程可以形式化为以下几个核心组件:
1.2.1.1 推荐问题的数学形式化
推荐系统的核心问题可以形式化为以下数学框架:
设用户集合为 U={u1,u2,...,um}U={u1,u2,...,um},物品集合为 I={i1,i2,...,in}I={i1,i2,...,in},用户 uu 对物品 ii 的评分(或偏好)为 rui∈Rrui∈R。推荐系统的目标是学习一个函数 f:U×I→Rf:U×I→R,使得对于给定的用户 uu 和物品 ii,函数 f(u,i)f(u,i) 能够预测用户 uu 对物品 ii 的偏好程度。
评分矩阵的构建
用户-物品评分矩阵是推荐系统的基本数据结构:
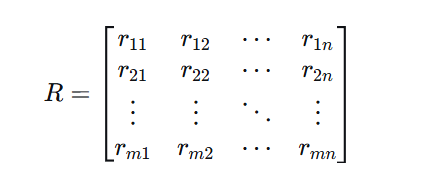
其中 ruirui 表示用户 uu 对物品 ii 的评分,未评分的元素通常用0或缺失值表示。在实际应用中,这个矩阵通常非常稀疏,只有少量元素有观测值。
推荐问题的分类
根据不同的任务目标,推荐问题可以分为以下几类:
-
评分预测:预测用户对物品的具体评分值,是回归问题
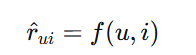
-
点击率预测:预测用户点击物品的概率,是二分类问题
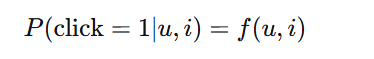
-
排序学习:学习一个排序函数,将用户可能感兴趣的物品排在前面
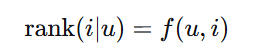
-
序列推荐:基于用户的历史行为序列预测下一个可能感兴趣的物品
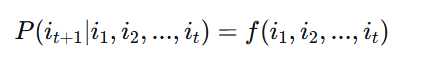
1.2.1.2 特征工程在推荐系统中的作用
特征工程是传统机器学习推荐系统的核心环节,它包括用户特征、物品特征和上下文特征的提取与构造。
用户特征
-
人口统计学特征:年龄、性别、地域、职业等
-
行为特征:点击率、购买频率、停留时长、活跃时间段等
-
偏好特征:喜欢的类别、品牌、价格区间等
-
社交特征:好友关系、社交影响力等
物品特征
-
内容特征:标题、描述、类别、标签、价格等
-
统计特征:销量、评分、点击量、收藏量等
-
时空特征:发布时间、地理位置等
上下文特征
-
时间特征:季节、节假日、时间段等
-
位置特征:用户所在位置、设备位置等
-
设备特征:设备类型、操作系统、网络环境等
交互特征
交互特征是用户特征和物品特征的组合,能够捕捉用户与物品之间的复杂关系:
-
交叉特征:用户年龄×物品类别、用户性别×品牌等
-
统计特征:用户对该类别物品的历史点击率等
1.2.1.3 传统机器学习模型在推荐系统中的应用
1. 矩阵分解模型
矩阵分解是协同过滤的核心技术,它将评分矩阵分解为用户和物品的隐因子矩阵:
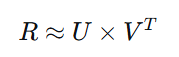
其中 U∈Rm×kU∈Rm×k 是用户隐因子矩阵,V∈Rn×kV∈Rn×k 是物品隐因子矩阵,kk 是隐因子维度。
奇异值分解(SVD):
import numpy as np
from scipy.sparse.linalg import svds
def svd_recommendation(R, k=50):
"""
使用SVD进行矩阵分解
参数:
R: 用户-物品评分矩阵 (m x n)
k: 保留的奇异值数量
返回:
重构的评分矩阵
"""
# 均值中心化
user_mean = np.mean(R, axis=1, keepdims=True)
R_centered = R - user_mean
# 执行SVD
U, sigma, Vt = svds(R_centered, k=k)
# 重构矩阵
sigma = np.diag(sigma)
R_pred = user_mean + U @ sigma @ Vt
return R_pred2. 因子分解机(Factorization Machine, FM)
因子分解机是一种通用的监督学习模型,特别适合处理高维稀疏特征:
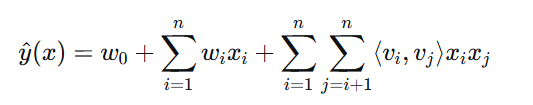
其中:
-
w0w0 是全局偏置
-
wiwi 是特征 i 的权重
-
⟨vi,vj⟩⟨vi,vj⟩ 是特征 i 和 j 的隐向量内积
3. 梯度提升决策树(GBDT)
GBDT通过集成多个决策树来提高预测精度,在推荐系统中常用于特征转换和组合:
from sklearn.ensemble import GradientBoostingClassifier
class GBDTRecommender:
"""
基于GBDT的推荐系统
"""
def __init__(self, n_estimators=100, learning_rate=0.1, max_depth=3):
self.gbdt = GradientBoostingClassifier(
n_estimators=n_estimators,
learning_rate=learning_rate,
max_depth=max_depth,
random_state=42
)
def train(self, X_train, y_train):
"""训练GBDT模型"""
self.gbdt.fit(X_train, y_train)
# 提取叶子节点索引作为新特征
self.leaf_indices = self.gbdt.apply(X_train)[:, :, 0]
def predict(self, X):
"""预测用户偏好"""
return self.gbdt.predict_proba(X)[:, 1]1.2.1.4 推荐系统的评估指标
评估推荐系统的性能需要从多个角度考虑,主要包括以下三类指标:
1. 评分预测指标
用于评估评分预测的准确性:
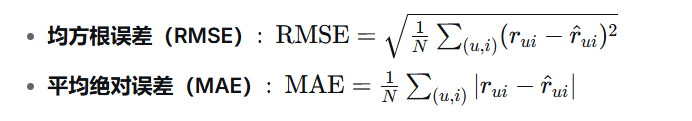
2. 分类指标
用于评估点击率预测等二分类任务:

3. 排序指标
用于评估推荐列表的质量:
-
Precision@K:前K个推荐物品中相关物品的比例
-
Recall@K:前K个推荐物品中相关物品占所有相关物品的比例
-
NDCG@K:归一化折损累积增益,考虑相关性和位置
-
MAP:平均精确率均值
-
MRR:平均倒数排名
4. 业务指标
-
点击率(CTR):CTR=点击次数曝光次数CTR=曝光次数点击次数
-
转化率(CVR):CVR=转化次数点击次数CVR=点击次数转化次数
-
用户留存率:Retention=次日活跃用户当日新增用户Retention=当日新增用户次日活跃用户
-
用户生命周期价值(LTV):用户在整个使用周期内产生的总价值
1.2.1.5 推荐系统的冷启动问题
冷启动是推荐系统面临的重要挑战,主要包括以下三种情况:
1. 用户冷启动
新用户没有历史行为数据,难以建立准确的用户画像。
解决方案:
-
利用注册信息:使用用户注册时提供的人口统计学信息
-
热门推荐:推荐当前热门物品
-
探索-利用策略:使用多臂老虎机等算法平衡探索和利用
-
跨域推荐:利用其他领域的行为数据
2. 物品冷启动
新物品没有用户交互数据,难以被推荐系统发现。
解决方案:
-
基于内容的推荐:利用物品的内容特征
-
物品属性相似性:推荐与用户历史喜欢物品相似的物品
-
主动学习:选择有代表性的用户对新物品进行标注
-
社交传播:通过社交关系传播新物品
3. 系统冷启动
全新的推荐系统没有用户行为数据。
解决方案:
-
内容推荐:初期主要依赖基于内容的推荐
-
外部数据导入:导入相似平台的用户行为数据
-
混合推荐:结合多种推荐策略
-
快速迭代:通过A/B测试快速优化算法
1.2.1.6 推荐系统的偏差与公平性
推荐系统中存在多种偏差,影响推荐的公平性和多样性:
1. 选择偏差(Selection Bias)
用户更倾向于点击或评分他们感兴趣的物品,导致观测数据存在偏差。
解决方法:
-
逆概率加权:为每个观测样本赋予权重
-
数据增强:使用合成数据平衡样本分布
-
解耦学习:分离用户偏好和物品曝光的影响
2. 流行度偏差(Popularity Bias)
热门物品获得更多曝光,进一步加剧其流行度。
解决方法:
-
去偏置处理:降低热门物品的权重
-
长尾推荐:专门优化长尾物品的推荐
-
公平性约束:在目标函数中加入公平性约束
3. 位置偏差(Position Bias)
用户更倾向于点击位置靠前的物品,与物品质量无关。
解决方法:
-
点击模型:建模位置对点击概率的影响
-
随机化实验:随机排列推荐结果
-
对抗学习:学习位置不变的特征表示
1.2.1.7 传统推荐系统的局限性
尽管传统机器学习方法在推荐系统中取得了显著成果,但仍存在一些局限性:
-
特征工程依赖:需要大量人工特征工程,成本高且难以迁移
-
交互建模有限:难以建模高阶特征交互和非线性关系
-
序列建模困难:传统方法难以有效建模用户行为序列
-
多模态融合挑战:难以有效融合文本、图像、视频等多模态信息
-
可扩展性问题:随着数据规模增长,传统方法面临计算复杂度挑战
下面是一个完整的基于传统机器学习的推荐系统实现示例,展示了从特征工程到模型训练的全过程:
"""
传统机器学习推荐系统完整实现
包含特征工程、多种模型实现和综合评估
"""
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
import lightgbm as lgb
import xgboost as xgb
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm import tqdm
import warnings
warnings.filterwarnings('ignore')
class TraditionalMLRecommender:
"""
传统机器学习推荐系统
实现完整的特征工程和多种机器学习模型
"""
def __init__(self):
self.user_encoder = LabelEncoder()
self.item_encoder = LabelEncoder()
self.scaler = StandardScaler()
self.models = {}
self.feature_importance = {}
def generate_synthetic_data(self, n_users=1000, n_items=2000, n_interactions=50000):
"""
生成模拟推荐系统数据
参数:
n_users: 用户数量
n_items: 物品数量
n_interactions: 交互数量
返回:
包含用户、物品和交互特征的数据框
"""
print("生成模拟数据...")
np.random.seed(42)
# 1. 生成用户数据
user_data = []
for i in range(n_users):
user_data.append({
'user_id': i,
'age': np.random.randint(18, 60),
'gender': np.random.choice([0, 1]), # 0:女, 1:男
'location': np.random.choice(['北京', '上海', '广州', '深圳', '其他']),
'registration_days': np.random.randint(1, 3650), # 注册天数
'activity_level': np.random.uniform(0, 1) # 活跃度
})
users_df = pd.DataFrame(user_data)
# 2. 生成物品数据
item_data = []
categories = ['科技', '娱乐', '体育', '财经', '教育', '健康', '旅游', '美食']
for i in range(n_items):
category = np.random.choice(categories)
price = np.random.uniform(10, 1000)
item_data.append({
'item_id': i,
'category': category,
'price': price,
'quality_score': np.random.uniform(0.5, 1.0), # 质量评分
'popularity': np.random.poisson(lam=50) # 流行度
})
items_df = pd.DataFrame(item_data)
# 3. 生成交互数据
interactions = []
for _ in range(n_interactions):
user_id = np.random.randint(0, n_users)
item_id = np.random.randint(0, n_items)
# 获取用户和物品特征
user = users_df.iloc[user_id]
item = items_df.iloc[item_id]
# 模拟点击概率(基于特征组合)
base_prob = 0.3
age_effect = 0.001 * user['age']
gender_effect = 0.1 if user['gender'] == 1 else 0
price_effect = -0.0005 * item['price']
quality_effect = 0.5 * item['quality_score']
# 类别偏好(模拟不同性别对类别的偏好)
category_preference = {
'科技': 0.2 if user['gender'] == 1 else 0.1,
'娱乐': 0.3 if user['gender'] == 0 else 0.2,
'体育': 0.4 if user['gender'] == 1 else 0.1,
'财经': 0.2,
'教育': 0.1,
'健康': 0.3 if user['gender'] == 0 else 0.2,
'旅游': 0.25,
'美食': 0.35 if user['gender'] == 0 else 0.2
}
category_effect = category_preference.get(item['category'], 0.1)
# 计算点击概率
click_prob = base_prob + age_effect + gender_effect + price_effect + quality_effect + category_effect
click_prob = np.clip(click_prob, 0, 1)
# 生成点击标签
clicked = 1 if np.random.random() < click_prob else 0
# 模拟评分(如果点击)
if clicked:
rating = np.random.randint(1, 6)
dwell_time = np.random.exponential(30) # 停留时间(秒)
else:
rating = 0
dwell_time = 0
# 上下文特征
hour = np.random.randint(0, 24)
weekend = 1 if np.random.random() > 0.7 else 0 # 30%的概率是周末
interactions.append({
'user_id': user_id,
'item_id': item_id,
'clicked': clicked,
'rating': rating,
'dwell_time': dwell_time,
'hour': hour,
'weekend': weekend,
'timestamp': np.random.randint(0, 1000000)
})
interactions_df = pd.DataFrame(interactions)
print(f"数据生成完成:")
print(f" 用户数: {n_users}")
print(f" 物品数: {n_items}")
print(f" 交互数: {n_interactions}")
print(f" 点击率: {interactions_df['clicked'].mean():.2%}")
return users_df, items_df, interactions_df
def create_features(self, users_df, items_df, interactions_df):
"""
创建机器学习特征
参数:
users_df: 用户数据框
items_df: 物品数据框
interactions_df: 交互数据框
返回:
特征矩阵和标签
"""
print("创建特征...")
# 1. 基本特征
features_df = interactions_df.copy()
# 2. 合并用户特征
features_df = features_df.merge(users_df, on='user_id', how='left')
# 3. 合并物品特征
features_df = features_df.merge(items_df, on='item_id', how='left')
# 4. 编码分类特征
categorical_cols = ['location', 'category']
for col in categorical_cols:
if col in features_df.columns:
le = LabelEncoder()
features_df[f'{col}_encoded'] = le.fit_transform(features_df[col].astype(str))
# 5. 创建交叉特征
# 用户年龄与物品价格交叉
features_df['age_price_interaction'] = features_df['age'] * features_df['price']
# 用户性别与物品类别交叉
features_df['gender_category_interaction'] = features_df['gender'] * features_df['category_encoded']
# 6. 创建统计特征
# 用户历史点击率
user_click_stats = interactions_df.groupby('user_id')['clicked'].agg(['mean', 'sum']).reset_index()
user_click_stats.columns = ['user_id', 'user_click_rate', 'user_total_clicks']
features_df = features_df.merge(user_click_stats, on='user_id', how='left')
# 物品历史点击率
item_click_stats = interactions_df.groupby('item_id')['clicked'].agg(['mean', 'sum']).reset_index()
item_click_stats.columns = ['item_id', 'item_click_rate', 'item_total_clicks']
features_df = features_df.merge(item_click_stats, on='item_id', how='left')
# 7. 时间特征
# 时间段特征
features_df['hour_sin'] = np.sin(2 * np.pi * features_df['hour'] / 24)
features_df['hour_cos'] = np.cos(2 * np.pi * features_df['hour'] / 24)
# 8. 选择最终特征
feature_cols = [
# 用户特征
'age', 'gender', 'registration_days', 'activity_level',
'user_click_rate', 'user_total_clicks',
# 物品特征
'price', 'quality_score', 'popularity',
'item_click_rate', 'item_total_clicks',
# 上下文特征
'hour_sin', 'hour_cos', 'weekend',
# 交叉特征
'age_price_interaction', 'gender_category_interaction',
# 编码特征
'location_encoded', 'category_encoded'
]
# 确保所有特征都存在
available_features = [col for col in feature_cols if col in features_df.columns]
X = features_df[available_features].fillna(0)
y = features_df['clicked'].values
print(f"特征创建完成,特征维度: {X.shape[1]}")
print(f"正负样本比例: {y.mean():.2%}")
return X, y, available_features
def train_models(self, X_train, y_train, X_test, y_test):
"""
训练多种传统机器学习模型
参数:
X_train: 训练特征
y_train: 训练标签
X_test: 测试特征
y_test: 测试标签
返回:
模型性能比较
"""
print("训练多种机器学习模型...")
models = {
'Logistic Regression': LogisticRegression(
max_iter=1000,
random_state=42,
class_weight='balanced'
),
'Random Forest': RandomForestClassifier(
n_estimators=100,
max_depth=10,
random_state=42,
class_weight='balanced',
n_jobs=-1
),
'Gradient Boosting': GradientBoostingClassifier(
n_estimators=100,
learning_rate=0.1,
max_depth=5,
random_state=42
),
'XGBoost': xgb.XGBClassifier(
n_estimators=100,
max_depth=6,
learning_rate=0.1,
random_state=42,
use_label_encoder=False,
eval_metric='logloss'
),
'LightGBM': lgb.LGBMClassifier(
n_estimators=100,
max_depth=6,
learning_rate=0.1,
random_state=42,
class_weight='balanced'
)
}
results = {}
for name, model in tqdm(models.items(), desc="训练模型"):
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
y_pred_proba = model.predict_proba(X_test)[:, 1]
# 计算指标
metrics = {
'accuracy': accuracy_score(y_test, y_pred),
'precision': precision_score(y_test, y_pred, zero_division=0),
'recall': recall_score(y_test, y_pred, zero_division=0),
'f1': f1_score(y_test, y_pred, zero_division=0),
'auc': roc_auc_score(y_test, y_pred_proba)
}
results[name] = metrics
# 保存模型
self.models[name] = model
# 计算特征重要性
if hasattr(model, 'feature_importances_'):
self.feature_importance[name] = model.feature_importances_
elif hasattr(model, 'coef_'):
self.feature_importance[name] = np.abs(model.coef_[0])
return results
def evaluate_models(self, results):
"""
评估模型性能
参数:
results: 模型性能结果
返回:
性能比较数据框
"""
# 转换为数据框
metrics_df = pd.DataFrame(results).T
print("\n模型性能比较:")
print("=" * 60)
print(metrics_df.round(4))
# 可视化比较
self._visualize_model_comparison(metrics_df)
return metrics_df
def _visualize_model_comparison(self, metrics_df):
"""
可视化模型比较结果
"""
fig, axes = plt.subplots(2, 3, figsize=(15, 10))
metrics = ['accuracy', 'precision', 'recall', 'f1', 'auc']
titles = ['准确率', '精确率', '召回率', 'F1分数', 'AUC']
for idx, (metric, title) in enumerate(zip(metrics, titles)):
ax = axes[idx // 3, idx % 3]
values = metrics_df[metric]
bars = ax.bar(range(len(values)), values, alpha=0.7)
ax.set_xlabel('模型')
ax.set_ylabel(title)
ax.set_title(f'{title}比较')
ax.set_xticks(range(len(values)))
ax.set_xticklabels(values.index, rotation=45, ha='right')
ax.grid(True, alpha=0.3)
# 在柱子上添加数值
for bar, value in zip(bars, values):
height = bar.get_height()
ax.text(bar.get_x() + bar.get_width()/2., height,
f'{value:.4f}', ha='center', va='bottom')
# 移除多余的子图
if len(metrics) < 6:
axes[-1, -1].axis('off')
plt.suptitle('传统机器学习模型性能比较', fontsize=14)
plt.tight_layout()
plt.show()
def visualize_feature_importance(self, feature_names, top_n=20):
"""
可视化特征重要性
参数:
feature_names: 特征名称列表
top_n: 显示前N个重要特征
"""
if not self.feature_importance:
print("没有特征重要性数据")
return
# 选择第一个有特征重要性的模型
model_name = list(self.feature_importance.keys())[0]
importance = self.feature_importance[model_name]
# 创建特征重要性数据框
importance_df = pd.DataFrame({
'feature': feature_names[:len(importance)],
'importance': importance
})
# 按重要性排序
importance_df = importance_df.sort_values('importance', ascending=False).head(top_n)
# 可视化
plt.figure(figsize=(10, 8))
bars = plt.barh(range(len(importance_df)), importance_df['importance'].values[::-1])
plt.yticks(range(len(importance_df)), importance_df['feature'].values[::-1])
plt.xlabel('特征重要性')
plt.title(f'{model_name}模型特征重要性 (Top {top_n})')
plt.grid(True, alpha=0.3, axis='x')
# 添加数值标签
for i, (bar, value) in enumerate(zip(bars, importance_df['importance'].values[::-1])):
plt.text(value + 0.001, i, f'{value:.4f}', va='center')
plt.tight_layout()
plt.show()
# 打印特征重要性
print(f"\n{model_name}模型特征重要性 (Top {top_n}):")
for i, row in importance_df.head(10).iterrows():
print(f" {row['feature']}: {row['importance']:.4f}")
def analyze_model_decisions(self, X_sample, feature_names, model_name='LightGBM'):
"""
分析模型决策过程
参数:
X_sample: 样本特征
feature_names: 特征名称
model_name: 模型名称
"""
if model_name not in self.models:
print(f"模型 {model_name} 不存在")
return
model = self.models[model_name]
if hasattr(model, 'predict_proba'):
# 获取预测概率
proba = model.predict_proba(X_sample)[:, 1]
# 对于树模型,可以分析决策路径
if hasattr(model, 'decision_path'):
# 获取决策路径
decision_paths = model.decision_path(X_sample)
# 分析决策路径
print(f"\n模型 {model_name} 决策分析:")
for i in range(min(3, len(X_sample))):
print(f"\n样本 {i+1} 分析:")
print(f" 预测点击概率: {proba[i]:.4f}")
# 获取特征重要性
if hasattr(model, 'feature_importances_'):
# 获取对该样本影响最大的特征
feature_contributions = model.feature_importances_ * X_sample.iloc[i]
top_features_idx = np.argsort(np.abs(feature_contributions))[::-1][:5]
print(f" 最重要的特征贡献:")
for idx in top_features_idx:
feature_name = feature_names[idx] if idx < len(feature_names) else f'特征{idx}'
print(f" {feature_name}: {feature_contributions[idx]:.4f}")
def create_ensemble_model(self, X_train, y_train, X_test, y_test, weights=None):
"""
创建集成模型
参数:
X_train: 训练特征
y_train: 训练标签
X_test: 测试特征
y_test: 测试标签
weights: 各模型权重
返回:
集成模型性能
"""
print("\n创建集成模型...")
if not self.models:
print("请先训练基础模型")
return
# 收集所有模型的预测概率
predictions = []
model_names = []
for name, model in self.models.items():
if hasattr(model, 'predict_proba'):
y_pred_proba = model.predict_proba(X_test)[:, 1]
predictions.append(y_pred_proba)
model_names.append(name)
if not predictions:
print("没有可用的预测概率")
return
predictions = np.array(predictions)
# 设置权重(如果没有提供,则使用平均权重)
if weights is None:
weights = np.ones(len(predictions)) / len(predictions)
else:
weights = np.array(weights)
weights = weights / weights.sum() # 归一化
# 加权平均
ensemble_pred = np.average(predictions, axis=0, weights=weights)
# 转换为类别预测
ensemble_pred_class = (ensemble_pred >= 0.5).astype(int)
# 计算指标
metrics = {
'accuracy': accuracy_score(y_test, ensemble_pred_class),
'precision': precision_score(y_test, ensemble_pred_class, zero_division=0),
'recall': recall_score(y_test, ensemble_pred_class, zero_division=0),
'f1': f1_score(y_test, ensemble_pred_class, zero_division=0),
'auc': roc_auc_score(y_test, ensemble_pred)
}
print("\n集成模型性能:")
print("=" * 60)
for metric, value in metrics.items():
print(f" {metric}: {value:.4f}")
# 可视化各模型权重
self._visualize_ensemble_weights(model_names, weights)
return metrics
def _visualize_ensemble_weights(self, model_names, weights):
"""
可视化集成模型权重
"""
plt.figure(figsize=(8, 6))
bars = plt.bar(model_names, weights, alpha=0.7)
plt.xlabel('模型')
plt.ylabel('权重')
plt.title('集成模型权重分配')
plt.grid(True, alpha=0.3, axis='y')
# 添加数值标签
for bar, weight in zip(bars, weights):
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2., height,
f'{weight:.3f}', ha='center', va='bottom')
plt.tight_layout()
plt.show()
def analyze_bias_fairness(self, X_test, y_test, sensitive_feature):
"""
分析模型的偏差和公平性
参数:
X_test: 测试特征
y_test: 测试标签
sensitive_feature: 敏感特征名称或索引
"""
print("\n分析模型偏差和公平性...")
# 选择最佳模型
best_model_name = list(self.models.keys())[0]
model = self.models[best_model_name]
# 获取预测
y_pred = model.predict(X_test)
# 提取敏感特征
if isinstance(sensitive_feature, str):
# 假设敏感特征是X_test的列
sensitive_values = X_test[sensitive_feature]
else:
# 假设敏感特征是索引
sensitive_values = X_test.iloc[:, sensitive_feature]
# 计算不同组的指标
groups = np.unique(sensitive_values)
fairness_results = {}
for group in groups:
mask = sensitive_values == group
if mask.sum() == 0:
continue
group_y_true = y_test[mask]
group_y_pred = y_pred[mask]
# 计算组内指标
metrics = {
'group_size': mask.sum(),
'accuracy': accuracy_score(group_y_true, group_y_pred),
'precision': precision_score(group_y_true, group_y_pred, zero_division=0),
'recall': recall_score(group_y_true, group_y_pred, zero_division=0),
'f1': f1_score(group_y_true, group_y_pred, zero_division=0),
'positive_rate': group_y_pred.mean()
}
fairness_results[group] = metrics
# 打印公平性分析结果
print(f"\n{best_model_name}模型公平性分析:")
print("=" * 60)
fairness_df = pd.DataFrame(fairness_results).T
print(fairness_df.round(4))
# 计算公平性差异
if len(fairness_results) >= 2:
groups = list(fairness_results.keys())
base_group = groups[0]
print(f"\n公平性差异 (相对于组 {base_group}):")
for metric in ['accuracy', 'precision', 'recall', 'f1', 'positive_rate']:
base_value = fairness_results[base_group][metric]
diffs = []
for group in groups[1:]:
group_value = fairness_results[group][metric]
diff = abs(group_value - base_value) / base_value if base_value != 0 else float('inf')
diffs.append(diff)
avg_diff = np.mean(diffs) if diffs else 0
print(f" {metric}平均相对差异: {avg_diff:.2%}")
return fairness_df
def optimize_hyperparameters(self, X_train, y_train, model_name='LightGBM'):
"""
优化模型超参数
参数:
X_train: 训练特征
y_train: 训练标签
model_name: 模型名称
返回:
最优参数和性能
"""
print(f"\n优化 {model_name} 模型超参数...")
if model_name == 'LightGBM':
# LightGBM超参数搜索
param_grid = {
'num_leaves': [31, 50, 100],
'learning_rate': [0.01, 0.05, 0.1],
'n_estimators': [50, 100, 200],
'max_depth': [5, 10, 15],
'min_child_samples': [20, 50, 100]
}
# 使用简单的网格搜索
best_score = 0
best_params = None
# 简化搜索(实际应用中应使用GridSearchCV或RandomizedSearchCV)
for n_estimators in param_grid['n_estimators'][:2]: # 只测试前两个
for learning_rate in param_grid['learning_rate'][:2]:
for max_depth in param_grid['max_depth'][:2]:
model = lgb.LGBMClassifier(
n_estimators=n_estimators,
learning_rate=learning_rate,
max_depth=max_depth,
random_state=42,
class_weight='balanced',
n_jobs=-1
)
# 交叉验证(简化版)
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model, X_train, y_train,
cv=3, scoring='roc_auc', n_jobs=-1)
mean_score = scores.mean()
if mean_score > best_score:
best_score = mean_score
best_params = {
'n_estimators': n_estimators,
'learning_rate': learning_rate,
'max_depth': max_depth
}
print(f"最优参数: {best_params}")
print(f"最优AUC: {best_score:.4f}")
# 使用最优参数重新训练
optimized_model = lgb.LGBMClassifier(**best_params, random_state=42)
optimized_model.fit(X_train, y_train)
# 保存优化后的模型
self.models[f'{model_name}_optimized'] = optimized_model
return best_params, best_score
else:
print(f"暂不支持 {model_name} 的超参数优化")
return None, None
# 主程序示例
def main():
"""
传统机器学习推荐系统主程序示例
"""
print("传统机器学习推荐系统演示")
print("=" * 60)
# 1. 初始化推荐系统
recommender = TraditionalMLRecommender()
# 2. 生成模拟数据
users_df, items_df, interactions_df = recommender.generate_synthetic_data(
n_users=1000,
n_items=2000,
n_interactions=50000
)
# 3. 创建特征
X, y, feature_names = recommender.create_features(users_df, items_df, interactions_df)
# 4. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
print(f"\n数据划分:")
print(f" 训练集大小: {X_train.shape[0]}")
print(f" 测试集大小: {X_test.shape[0]}")
print(f" 特征数量: {X_train.shape[1]}")
# 5. 训练多种模型
results = recommender.train_models(X_train, y_train, X_test, y_test)
# 6. 评估模型
metrics_df = recommender.evaluate_models(results)
# 7. 可视化特征重要性
recommender.visualize_feature_importance(feature_names, top_n=15)
# 8. 创建集成模型
ensemble_results = recommender.create_ensemble_model(
X_train, y_train, X_test, y_test,
weights=[0.1, 0.15, 0.2, 0.25, 0.3] # 给更复杂的模型更高权重
)
# 9. 分析模型偏差和公平性
# 假设'gender'是敏感特征
if 'gender' in X_test.columns:
fairness_df = recommender.analyze_bias_fairness(
X_test, y_test, sensitive_feature='gender'
)
# 10. 优化超参数
best_params, best_score = recommender.optimize_hyperparameters(
X_train, y_train, model_name='LightGBM'
)
# 11. 分析模型决策过程
print("\n分析模型决策过程...")
sample_indices = np.random.choice(len(X_test), 5, replace=False)
X_sample = X_test.iloc[sample_indices]
recommender.analyze_model_decisions(
X_sample, feature_names, model_name='LightGBM'
)
# 12. 特征相关性分析
print("\n特征相关性分析...")
# 选择部分特征进行相关性分析
if len(feature_names) > 10:
selected_features = feature_names[:10]
X_selected = X[selected_features]
# 计算相关系数矩阵
corr_matrix = X_selected.corr()
# 可视化相关系数矩阵
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True, fmt='.2f', cmap='coolwarm',
center=0, square=True, linewidths=0.5)
plt.title('特征相关系数矩阵 (Top 10 Features)')
plt.tight_layout()
plt.show()
# 找出高度相关的特征对
high_corr_pairs = []
for i in range(len(selected_features)):
for j in range(i+1, len(selected_features)):
corr = abs(corr_matrix.iloc[i, j])
if corr > 0.7: # 相关系数阈值
high_corr_pairs.append((
selected_features[i],
selected_features[j],
corr
))
if high_corr_pairs:
print("\n高度相关的特征对:")
for feat1, feat2, corr in high_corr_pairs:
print(f" {feat1} 和 {feat2}: {corr:.3f}")
# 13. 模型校准分析
print("\n模型校准分析...")
# 使用最佳模型进行概率校准分析
best_model_name = 'LightGBM_optimized' if 'LightGBM_optimized' in recommender.models else 'LightGBM'
if best_model_name in recommender.models:
model = recommender.models[best_model_name]
y_pred_proba = model.predict_proba(X_test)[:, 1]
# 计算校准曲线
from sklearn.calibration import calibration_curve
prob_true, prob_pred = calibration_curve(y_test, y_pred_proba, n_bins=10)
# 绘制校准曲线
plt.figure(figsize=(8, 6))
plt.plot(prob_pred, prob_true, 's-', label=best_model_name)
plt.plot([0, 1], [0, 1], 'k--', label='完美校准')
plt.xlabel('预测概率')
plt.ylabel('实际概率')
plt.title('模型校准曲线')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
# 计算Brier分数
from sklearn.metrics import brier_score_loss
brier_score = brier_score_loss(y_test, y_pred_proba)
print(f" Brier分数: {brier_score:.4f}")
print(" Brier分数越小表示概率预测越准确")
print("\n传统机器学习推荐系统演示完成!")
if __name__ == "__main__":
main()1.2.1.8 传统机器学习推荐系统的总结
传统机器学习方法在推荐系统中有着广泛的应用,其核心优势包括:
-
可解释性强:决策树、线性模型等传统方法具有较好的可解释性
-
计算效率高:相对于深度学习模型,传统方法通常计算成本更低
-
数据需求少:在数据量较小的情况下,传统方法往往表现更稳定
-
理论基础坚实:有成熟的数学理论和优化方法支持
-
易于部署和维护:模型结构相对简单,易于在生产环境中部署和维护
然而,传统机器学习方法也存在一些局限性:
-
特征工程依赖:需要大量人工特征工程,且特征质量直接影响模型性能
-
交互建模有限:难以有效捕捉高阶特征交互和非线性关系
-
序列建模困难:传统方法难以有效建模用户行为序列中的长期依赖
-
多模态融合挑战:难以有效融合文本、图像等多种模态的信息
-
泛化能力有限:面对新领域或新场景时,传统方法的泛化能力相对较弱
随着深度学习技术的发展,推荐系统正逐渐从传统机器学习方法向深度学习方法过渡。深度学习能够自动学习特征表示,捕捉复杂的非线性关系,有效建模序列依赖,为推荐系统带来了新的突破。
在下一小节中,我们将深入探讨深度学习推荐系统的新范式,了解深度学习如何解决传统方法的局限性,并推动推荐系统向更智能、更个性化的方向发展。