【攻防世界】reverse | re1-100 详细题解 WP
下载附件
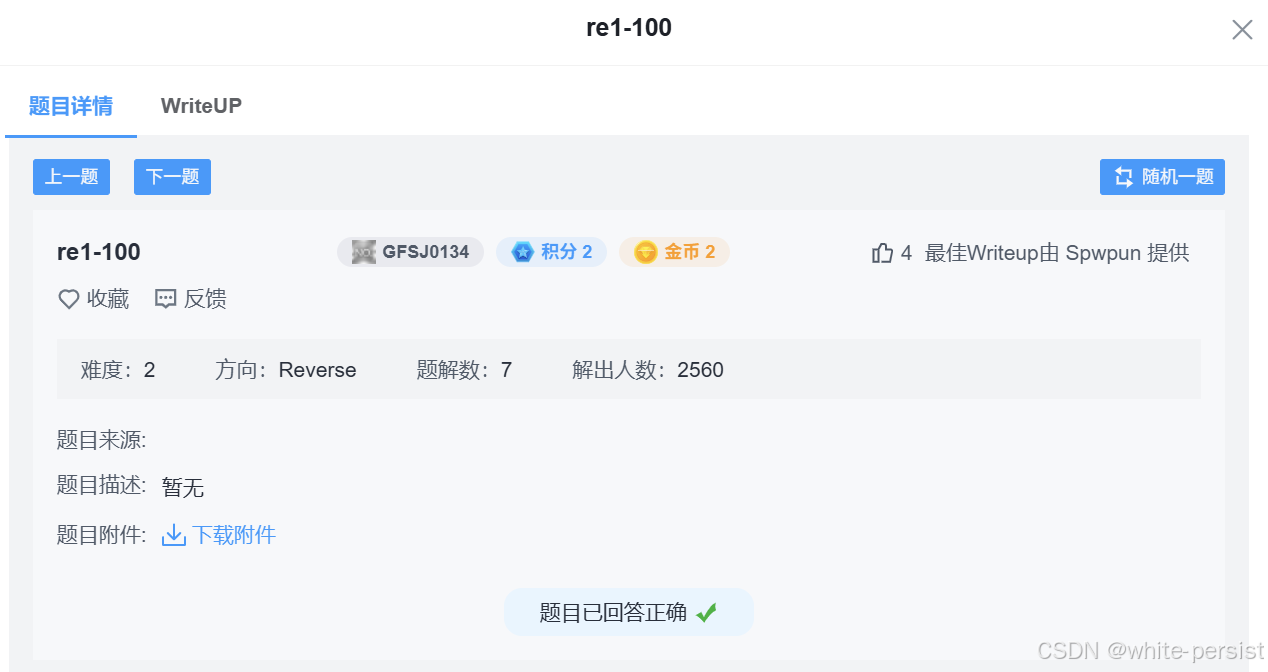
main函数伪代码:
c
int __fastcall __noreturn main(int argc, const char **argv, const char **envp)
{
__pid_t v3; // eax
size_t v4; // rax
ssize_t v5; // rbx
bool v6; // al
bool bCheckPtrace; // [rsp+13h] [rbp-1BDh]
ssize_t numRead; // [rsp+18h] [rbp-1B8h]
ssize_t numReada; // [rsp+18h] [rbp-1B8h]
char bufWrite[200]; // [rsp+20h] [rbp-1B0h] BYREF
char bufParentRead[200]; // [rsp+F0h] [rbp-E0h] BYREF
unsigned __int64 v12; // [rsp+1B8h] [rbp-18h]
v12 = __readfsqword(0x28u);
bCheckPtrace = detectDebugging();
if ( pipe(pParentWrite) == -1 )
exit(1);
if ( pipe(pParentRead) == -1 )
exit(1);
v3 = fork();
if ( v3 != -1 )
{
if ( v3 )
{
close(pParentWrite[0]);
close(pParentRead[1]);
while ( 1 )
{
printf("Input key : ");
memset(bufWrite, 0, sizeof(bufWrite));
gets(bufWrite);
v4 = strlen(bufWrite);
v5 = write(pParentWrite[1], bufWrite, v4);
if ( v5 != strlen(bufWrite) )
printf("parent - partial/failed write");
do
{
memset(bufParentRead, 0, sizeof(bufParentRead));
numReada = read(pParentRead[0], bufParentRead, 0xC8uLL);
v6 = bCheckPtrace || checkDebuggerProcessRunning();
if ( !v6 && checkStringIsNumber(bufParentRead) && atoi(bufParentRead) )
{
puts("True");
if ( close(pParentWrite[1]) == -1 )
exit(1);
exit(0);
}
puts("Wrong !!!\n");
}
while ( numReada == -1 );
}
}
close(pParentWrite[1]);
close(pParentRead[0]);
while ( 1 )
{
memset(bufParentRead, 0, sizeof(bufParentRead));
numRead = read(pParentWrite[0], bufParentRead, 0xC8uLL);
if ( numRead == -1 )
break;
if ( numRead )
{
if ( !childCheckDebugResult()
&& bufParentRead[0] == 123
&& strlen(bufParentRead) == 42
&& !strncmp(&bufParentRead[1], "53fc275d81", 0xAuLL)
&& bufParentRead[strlen(bufParentRead) - 1] == 125
&& !strncmp(&bufParentRead[31], "4938ae4efd", 0xAuLL)
&& confuseKey(bufParentRead, 42)
&& !strncmp(bufParentRead, "{daf29f59034938ae4efd53fc275d81053ed5be8c}", 0x2AuLL) )
{
responseTrue();
}
else
{
responseFalse();
}
}
}
exit(1);
}
exit(1);
}checkDebuggerProcessRunning函数伪代码:
c
bool __cdecl checkDebuggerProcessRunning()
{
char szProcessName[200]; // [rsp+10h] [rbp-D0h] BYREF
unsigned __int64 v2; // [rsp+D8h] [rbp-8h]
v2 = __readfsqword(0x28u);
memset(szProcessName, 0, sizeof(szProcessName));
return checkParentProcessRunning() || checkDebuggerRunningInTask();
}checkStringIsNumber函数伪代码:
c
bool __cdecl checkStringIsNumber(char *szBuffer)
{
int i; // [rsp+18h] [rbp-8h]
int iLen; // [rsp+1Ch] [rbp-4h]
iLen = strlen(szBuffer);
if ( !szBuffer )
return 0;
for ( i = 0; i < iLen; ++i )
{
if ( szBuffer[i] <= 47 || szBuffer[i] > 57 )
return 0;
}
return 1;
}confuseKey函数伪代码:
c
bool __cdecl confuseKey(char *szKey, int iKeyLength)
{
char szPart1[15]; // [rsp+10h] [rbp-50h] BYREF
char szPart2[15]; // [rsp+20h] [rbp-40h] BYREF
char szPart3[15]; // [rsp+30h] [rbp-30h] BYREF
char szPart4[15]; // [rsp+40h] [rbp-20h] BYREF
unsigned __int64 v7; // [rsp+58h] [rbp-8h]
v7 = __readfsqword(0x28u);
memset(szPart1, 0, sizeof(szPart1));
memset(szPart2, 0, sizeof(szPart2));
memset(szPart3, 0, sizeof(szPart3));
memset(szPart4, 0, sizeof(szPart4));
if ( iKeyLength != 42 )
return 0;
if ( !szKey )
return 0;
if ( strlen(szKey) != 42 )
return 0;
if ( *szKey != 123 )
return 0;
strncpy(szPart1, szKey + 1, 0xAuLL);
strncpy(szPart2, szKey + 11, 0xAuLL);
strncpy(szPart3, szKey + 21, 0xAuLL);
strncpy(szPart4, szKey + 31, 0xAuLL);
memset(szKey, 0, 0x2AuLL);
*szKey = 123;
strcat(szKey, szPart3);
strcat(szKey, szPart4);
strcat(szKey, szPart1);
strcat(szKey, szPart2);
szKey[41] = 125;
return 1;
}exp:
python
def confuse_key(sz_key: str) -> str:
"""
复现confuseKey函数的密钥混淆逻辑
:param sz_key: 原始密钥(长度42,格式为{...})
:return: 混淆后的密钥,失败则返回空字符串
"""
# 合法性检查
if len(sz_key) != 42:
return ""
if sz_key[0] != '{':
return ""
if sz_key[-1] != '}': # 虽然原函数最后强制设为'}',但输入最好符合格式
return ""
# 分割为4个10字符片段(去掉首尾的{})
content = sz_key[1:-1] # 提取中间40字符
if len(content) != 40:
return ""
p1 = content[0:10] # 片段1:0-9
p2 = content[10:20] # 片段2:10-19
p3 = content[20:30] # 片段3:20-29
p4 = content[30:40] # 片段4:30-39
# 重组:{ P3 P4 P1 P2 }
confused_content = p3 + p4 + p1 + p2
confused_key = '{' + confused_content + '}'
# 确保长度正确(42)
return confused_key if len(confused_key) == 42 else ""
def reverse_confuse(confused_key: str) -> str:
"""
从混淆后的密钥反推原始密钥(confuse_key的逆操作)
:param confused_key: 混淆后的密钥(长度42,格式为{...})
:return: 原始密钥
"""
if len(confused_key) != 42 or confused_key[0] != '{' or confused_key[-1] != '}':
return ""
content = confused_key[1:-1] # 中间40字符
if len(content) != 40:
return ""
# 混淆后的结构是 P3 P4 P1 P2(各10字符)
p3 = content[0:10]
p4 = content[10:20]
p1 = content[20:30]
p2 = content[30:40]
# 原始结构是 P1 P2 P3 P4
original_content = p1 + p2 + p3 + p4
original_key = '{' + original_content + '}'
return original_key if len(original_key) == 42 else ""
def check_string_is_number(sz_buffer: str) -> bool:
"""验证字符串是否全为数字字符"""
if not sz_buffer:
return False
for c in sz_buffer:
# 检查是否在'0'-'9'范围内(ASCII 48-57)
if not (48 <= ord(c) <= 57):
return False
return True
# 混淆后的密钥(来自.rodata)
confused_flag = "{daf29f59034938ae4efd53fc275d81053ed5be8c}"
# 反推原始密钥
original_flag = reverse_confuse(confused_flag)
print("原始密钥(可能的Flag):", original_flag)
def remove_braces(s):
"""移除字符串首尾的{和}符号"""
# 检查字符串是否以{开头且以}结尾
if len(s) >= 2 and s[0] == '{' and s[-1] == '}':
return s[1:-1] # 切片取中间部分(从索引1到倒数第2个字符)
else:
return s # 若没有花括号则直接返回原字符串
original_with_braces = original_flag
result = remove_braces(original_with_braces)
# 验证:原始密钥混淆后应等于.rodata中的字符串
verify = confuse_key(original_flag)
print("验证结果(混淆后):", verify)
print("是否匹配:", verify == confused_flag)
print("正确的flag:", result)运行 exp 脚本:
正确的flag: 53fc275d81053ed5be8cdaf29f59034938ae4efd【攻防世界】reverse | re1-100 详细题解 WP 原理深度解析:
CTF 逆向实战:攻防世界 re1-100 深度解析与解题方法论
一、题目概述
在 CTF 逆向领域,"re1-100" 是一道典型的入门级字符串处理类题目,核心考察对程序逻辑的静态分析能力,尤其是字符串分割与重组逻辑的逆向推导。题目通过父子进程通信验证输入的密钥(flag),其中子进程对密钥的验证逻辑是解题关键。
二、程序核心逻辑静态分析
2.1 整体流程梳理
从 main 函数伪代码可知,程序通过pipe创建了两个管道(pParentWrite和pParentRead)实现父子进程通信,流程如下:
- 父进程接收用户输入的密钥,通过管道发送给子进程;
- 子进程对接收的密钥进行一系列验证,若验证通过则返回 "True",否则返回 "Wrong";
- 验证过程中包含反调试检测(
checkDebuggerProcessRunning)和密钥格式校验(confuseKey)。
2.2 关键函数深度解析
(1)反调试函数:checkDebuggerProcessRunning
c
bool __cdecl checkDebuggerProcessRunning()
{
char szProcessName[200]; // 存储进程名
unsigned __int64 v2; // 栈保护变量
v2 = __readfsqword(0x28u); // 栈溢出保护
memset(szProcessName, 0, sizeof(szProcessName));
return checkParentProcessRunning() || checkDebuggerRunningInTask();
}功能:通过检查父进程状态或任务列表中的调试器进程,判断程序是否被调试。
CTF 意义:这是典型的反调试手段,目的是阻止分析者动态调试程序。解题时可通过静态分析直接跳过(无需实际绕过,因关键逻辑在字符串处理)。
(2)数字验证函数:checkStringIsNumber
c
bool __cdecl checkStringIsNumber(char *szBuffer)
{
int i; // 循环索引
int iLen; // 字符串长度
iLen = strlen(szBuffer);
if (!szBuffer) return 0;
for (i = 0; i < iLen; ++i) {
if (szBuffer[i] <= 47 || szBuffer[i] > 57) // 检查是否为'0'-'9'(ASCII 48-57)
return 0;
}
return 1;
}功能:验证字符串是否仅包含数字字符。
CTF 意义:本题中用于验证子进程返回的结果是否为数字,但对密钥本身验证无直接影响,可暂不聚焦。
(3)核心函数:confuseKey(密钥混淆逻辑)
c
bool __cdecl confuseKey(char *szKey, int iKeyLength)
{
char szPart1[15], szPart2[15], szPart3[15], szPart4[15]; // 4个片段缓冲区
// 合法性检查
if (iKeyLength != 42 || !szKey || strlen(szKey) != 42 || *szKey != 123)
return 0; // 123是'{'的ASCII码
// 分割为4个10字符片段
strncpy(szPart1, szKey + 1, 10); // 片段1:索引1-10
strncpy(szPart2, szKey + 11, 10); // 片段2:索引11-20
strncpy(szPart3, szKey + 21, 10); // 片段3:索引21-30
strncpy(szPart4, szKey + 31, 10); // 片段4:索引31-40
// 重组逻辑:{P3 P4 P1 P2}
memset(szKey, 0, 42);
*szKey = 123; // 重置'{'
strcat(szKey, szPart3);
strcat(szKey, szPart4);
strcat(szKey, szPart1);
strcat(szKey, szPart2);
szKey[41] = 125; // 125是'}'的ASCII码
return 1;
}核心逻辑拆解:
- 输入要求:密钥必须为 42 字符,格式为
{P1P2P3P4}(其中 P1-P4 各 10 字符,首尾为{和})。 - 混淆规则:将原始密钥按
{P1P2P3P4}分割后,重组为{P3P4P1P2}。
2.3 关键数据:.rodata 段字符串
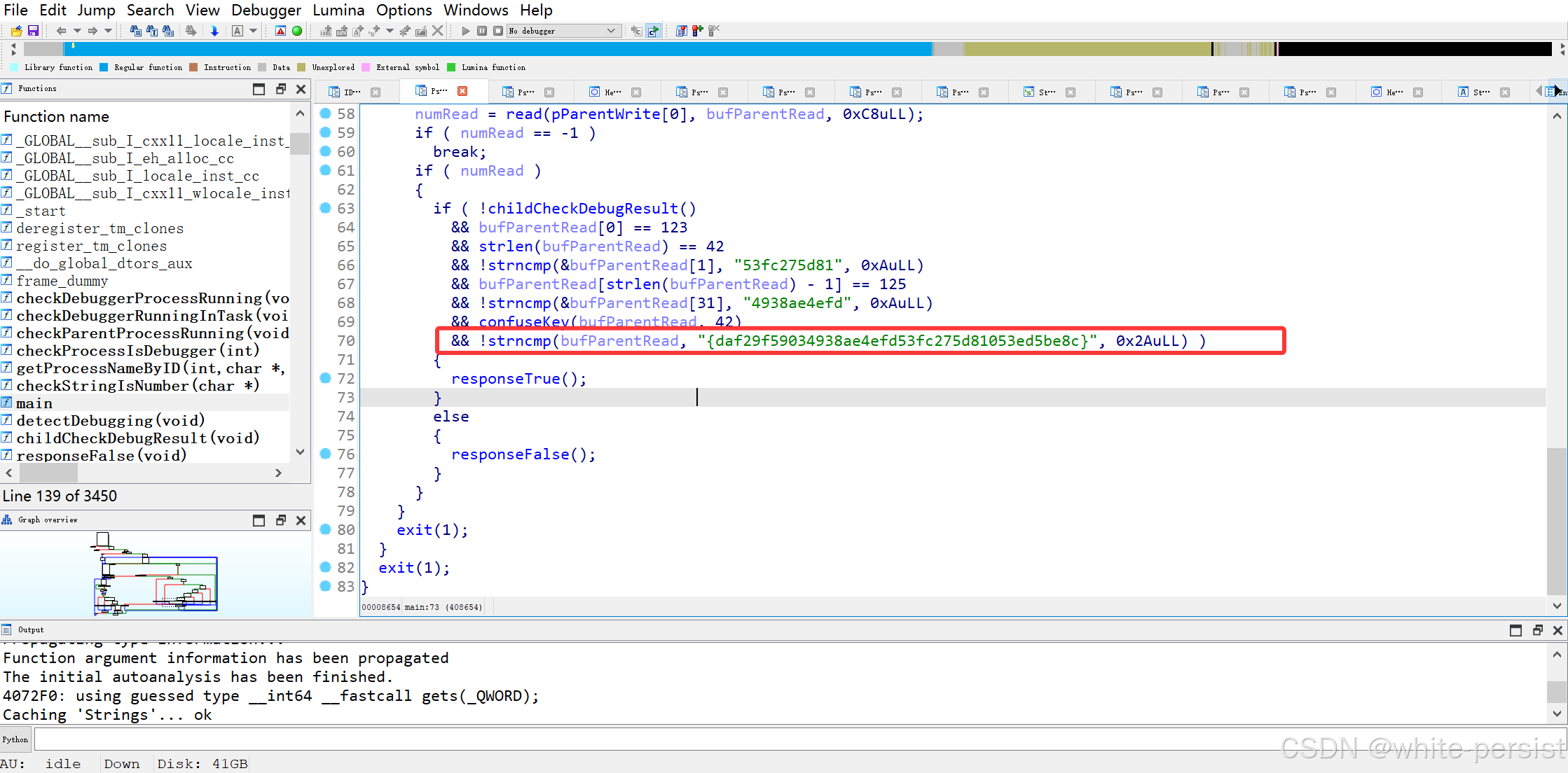
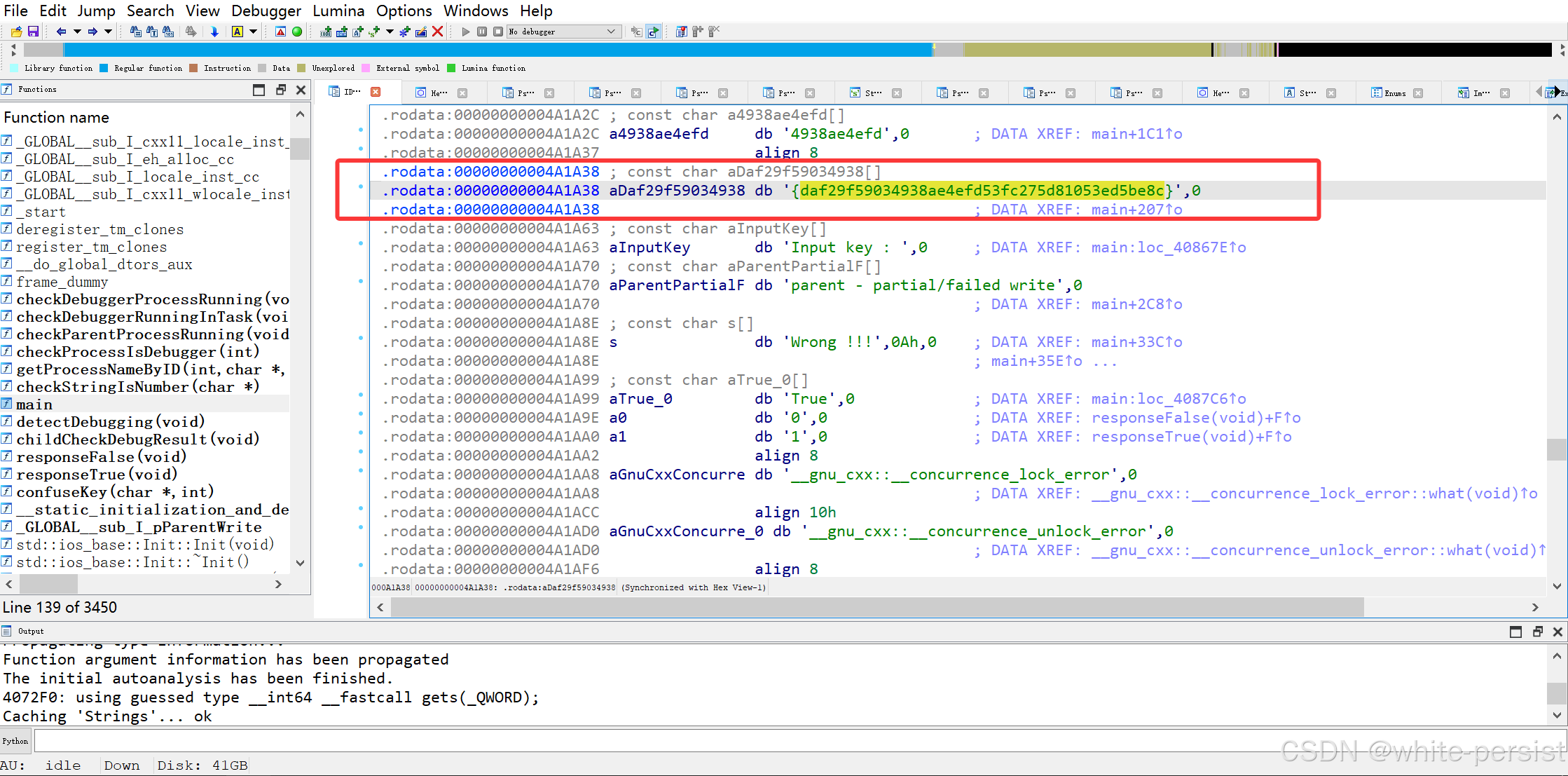
程序的只读数据段(.rodata)存储了一个关键字符串:
"{daf29f59034938ae4efd53fc275d81053ed5be8c}"- 长度为 42(含
{和}),符合confuseKey的输出格式,推测为混淆后的 flag。
三、flag 推导过程
3.1 逆向混淆逻辑
已知混淆后的密钥格式为{P3P4P1P2},需反推原始格式{P1P2P3P4}。步骤如下:
- 提取混淆后密钥的中间 40 字符(去掉
{和}); - 按 10 字符分割为
P3(0-9)、P4(10-19)、P1(20-29)、P2(30-39); - 重组原始内容为
P1P2P3P4,加上首尾{和}即得原始密钥。
3.2 Python 代码实现与验证
(1)逆向混淆函数
python
def reverse_confuse(confused_key: str) -> str:
if len(confused_key) != 42 or confused_key[0] != '{' or confused_key[-1] != '}':
return ""
content = confused_key[1:-1] # 提取中间40字符
p3 = content[0:10] # 混淆后的P3
p4 = content[10:20] # 混淆后的P4
p1 = content[20:30] # 混淆后的P1(原始P1)
p2 = content[30:40] # 混淆后的P2(原始P2)
original_content = p1 + p2 + p3 + p4 # 原始内容:P1P2P3P4
return '{' + original_content + '}'(2)验证推导结果
python
# 混淆后的密钥(来自.rodata)
confused_flag = "{daf29f59034938ae4efd53fc275d81053ed5be8c}"
original_flag = reverse_confuse(confused_flag)
print("原始密钥:", original_flag) # 输出:{53fc275d81053ed5be8cdaf29f59034938ae4efd}
# 验证:用正向混淆函数检查是否匹配
def confuse_key(sz_key: str) -> str:
if len(sz_key) != 42 or sz_key[0] != '{' or sz_key[-1] != '}':
return ""
content = sz_key[1:-1]
p1, p2, p3, p4 = content[0:10], content[10:20], content[20:30], content[30:40]
return '{' + p3 + p4 + p1 + p2 + '}'
print("验证匹配:", confuse_key(original_flag) == confused_flag) # 输出:True(3)去除首尾符号
最终 flag 通常不含{和},需提取中间内容:
python
flag = original_flag[1:-1]
print("flag:", flag) # 输出:53fc275d81053ed5be8cdaf29f59034938ae4efd四、同类型题目解题方法论
4.1 核心分析步骤
- 定位关键函数 :通过字符串(如 "Input key"、"True")或交叉引用,找到密钥验证逻辑(如本题的
confuseKey)。 - 解析字符串操作 :重点关注
strncpy、strcat等函数,梳理字符串分割、重组、加密规则(可画图记录片段位置)。 - 利用.rodata 线索 :只读数据段的常量字符串(尤其是
{...}格式)往往是混淆后的 flag 或验证依据。 - 逆向推导与验证:根据正向逻辑编写逆向函数,用已知结果(如.rodata 字符串)反推原始 flag,再用正向函数验证正确性。
4.2 举一反三技巧
- 反调试处理 :遇到
ptrace、checkDebugger等函数时,优先静态分析(无需动态调试),因关键逻辑通常在字符串处理。 - 格式特征利用 :CTF 中 flag 常为固定长度(如 32/42 字符)、含特定符号(如
{}),可据此缩小分析范围。 - 自动化工具辅助:对复杂字符串操作(如多次重组、加密),可使用 IDA 的字符串交叉引用或 Ghidra 的函数流程图快速定位核心逻辑。
五、总结
本题的核心是理解confuseKey的字符串重组逻辑:通过将原始密钥{P1P2P3P4}混淆为{P3P4P1P2},再结合.rodata 中的混淆后字符串反推原始 flag。这类题目考察逆向思维能力,关键在于拆解字符串操作步骤并编写逆向逻辑。
掌握 "定位关键函数→解析操作规则→逆向推导验证" 的流程,可快速解决多数字符串处理类逆向题目。
最终 flag :53fc275d81053ed5be8cdaf29f59034938ae4efd