思维导图
本文的思维导图如下:
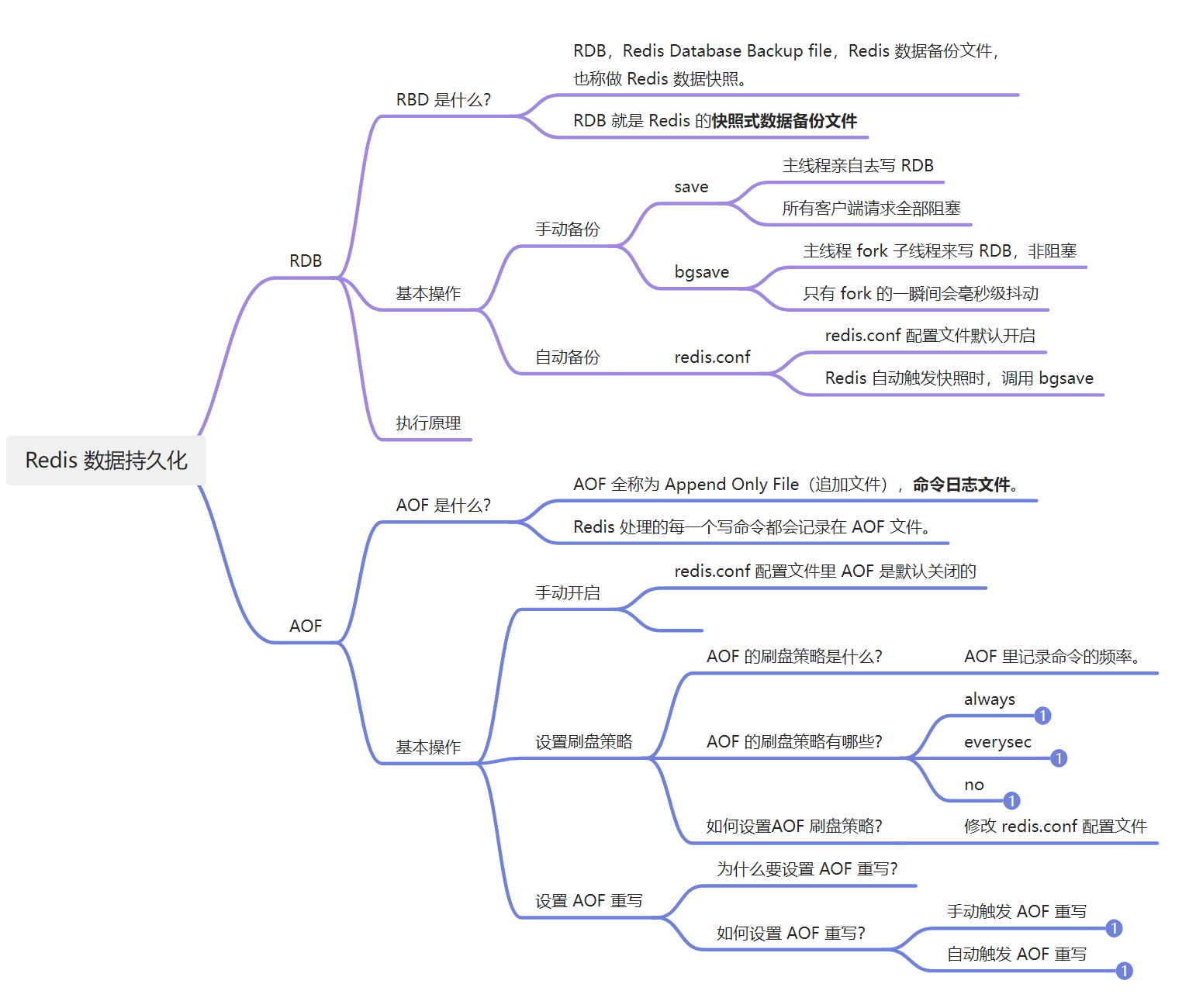
Redis 持久化相关面试题的思维导图如下:
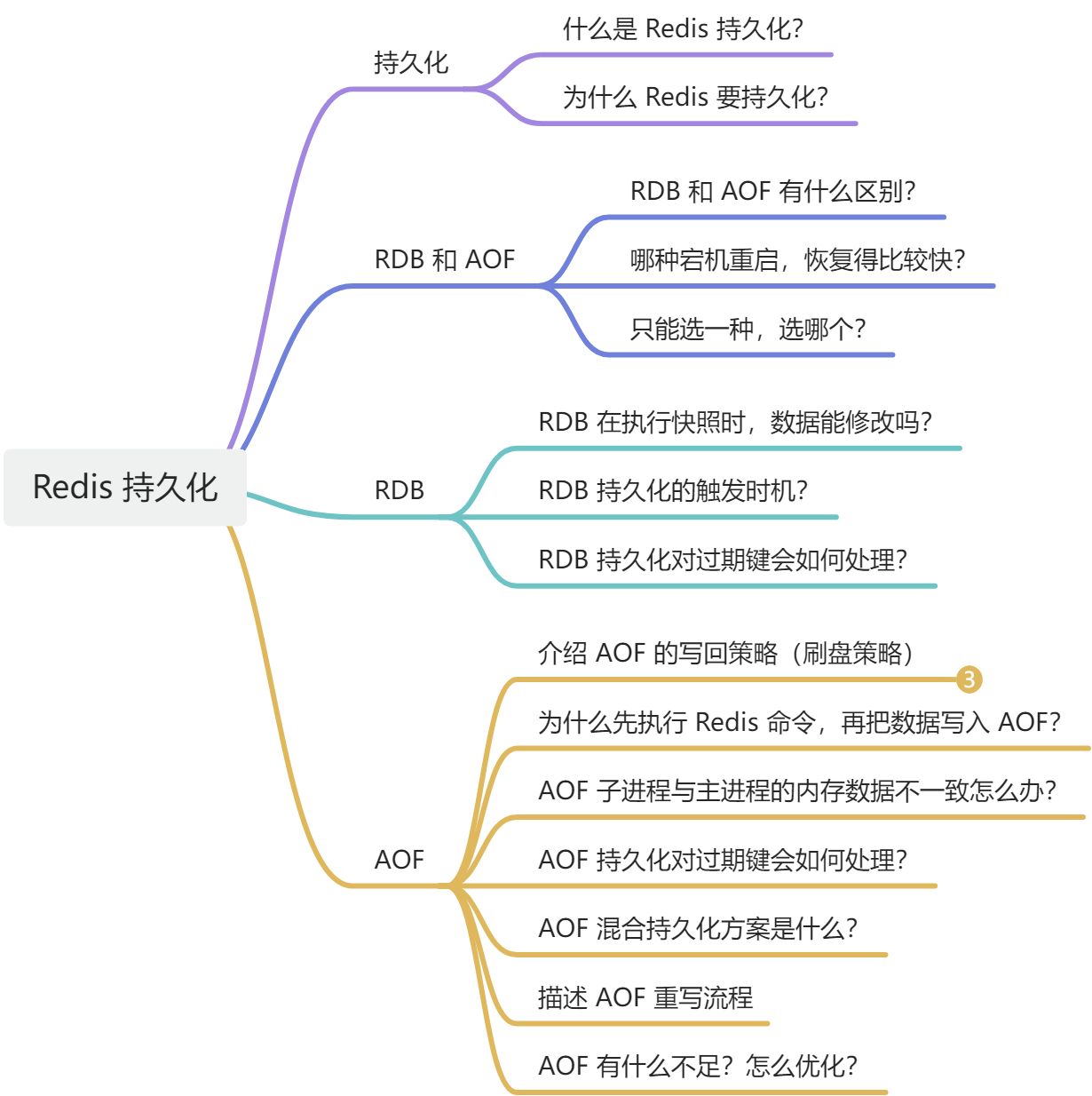
一、Redis 持久化
Redis 作为缓存,其数据的持久化是怎么做的?
Redis 提供了两种数据持久化的方式:
- RDB
- AOF
(一)RDB
1. 什么是 RDB?
RDB 全称 Redis Database Backup file(Redis 数据备份文件 ),也被叫做 Redis 数据快照。
简单来说 RDB 就是 Redis 的一种数据备份文件 ,++它把内存中的所有数据都记录到磁盘中++。
更专业一点来说 RDB 就是 Redis 的快照式数据备份文件。
它会在某个时间点,把内存里的所有数据打包成一个 .rdb 文件保存到磁盘上。
当 Redis 实例故障重启后,可以直接读取这个 RDB 文件,快速恢复数据。
2. RDB 的基本操作
1)主动备份
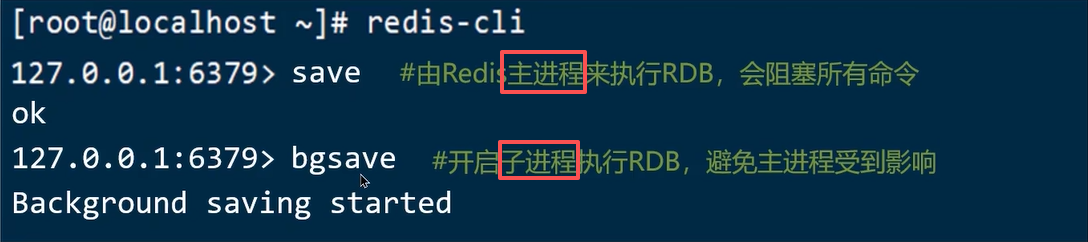
解释:
-
save:主进程自己亲自干活
save的流程是:主进程直接把内存写成 RDB 文件,在这期间会阻塞所有客户端命令。
-
bgsave:主进程 fork 一个子进程,由子进程专门干活(写 RBD)
bgsave的流程是:- 主进程接到
bgsave命令; - 主进程
fork()一个子进程; - 主进程继续处理客户端请求(只有在 fork 那一瞬间会有毫秒级抖动);
- 子进程负责把当前内存快照写成 RDB 文件。
- 主进程接到
2)自动备份
Redis 默认是开启 RDB 自动备份的, 它会按照 redis.conf 里配置的 save 规则,在满足条件时自动生成 .rdb 快照文件。
redis.conf 里配置的 save 规则格式如下:

解释:
plsql
save 900 1 # 15分钟内 ≥1 次修改 → 触发 RDB
save 300 10 # 5分钟内 ≥10 次修改 → 触发 RDB
save 60 10000 # 1分钟内 ≥10000 次修改 → 触发 RDB它本质是一个"或(OR)关系":只要任意一条满足条件 ,就会触发 bgsave。
这是 Redis 的一种 "多级自动快照保险机制":
- 写得少 → 用 15 分钟兜底
- 写得多 → 5 分钟甚至 1 分钟就备份一次
这些 save 规则是执行 save 还是 bgsave?
Redis 在"自动触发快照"这种场景下,选择的是 bgsave,而不是 save。
3. RDB 的执行原理
bgsave 中 RDB 是如何被子进程写到磁盘里的呢?
bgsave 在开始时会 fork 主进程得到子进程,子进程会 共享 主进程的内存数据。
完成 fork 后,子线程读取内存数据并写入 RDB 文件。
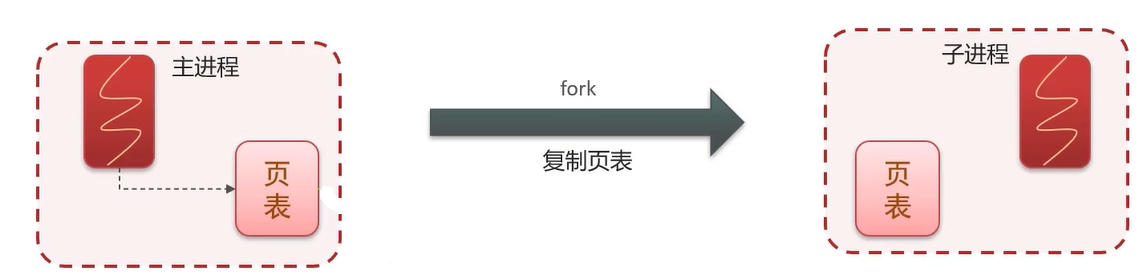
子进程如何共享内存呢?
Redis 的主进程通过复制一份自己的页表给子线程。
为什么要通过复制页表呢?什么是页表呢?
这个问题得回到 ++Redis 的进程都是如何访问物理内存++上来。
因为 Redis 的进程没办法直接操作 操作系统的物理内存,只能操作 操作系统提供给它们的虚拟内存,具体来说就是通过页表来操作。
页表:记录虚拟地址和物理地址的映射关系。
这样,Redis 就能通过页表来关联到物理内存,从而实现在内存读写数据。
两个进程异步读写共享内存,如何避免脏读呢?
问题描述: 子进程在写 RDB 的时候,需要读取共享内存,这个过程中主进程也在继续处理客户端请求,可能会修改共享内存的数据,这样 RDB 就会出现脏数据,那如何避免"RDB 脏写"问题呢?
解决方案: 操作系统的 fork 机制中有一种叫做 读写复制(Copy-On-Write,COW)。
什么是读写复制?
操作系统在实现
fork()时"原生自带"的一种内存优化机制:多个进程"先共享同一份数据",只有在"真的要修改时",才复制一份出来。
1)fork 时:
- 父进程和子进程 先共享同一块物理内存
- 内存页在页表中被标记为 只读(read-only)
2)读操作:
- 父子进程都直接读这块共享内存
3)写操作:
- 只要某个进程要修改:
- CPU 发现这是只读页
- 触发异常
- 操作系统 复制一份新的内存页
- 然后再让这个进程修改自己的副本
Redis 的主进程在调用 fork 的时候,操作系统就会在页表上把共享内存标记为 read-only。
- 当主进程执行读操作时,可以读取共享内存;
- 当主进程执行写操作时,需要拷贝一份数据,才能执行写操作。
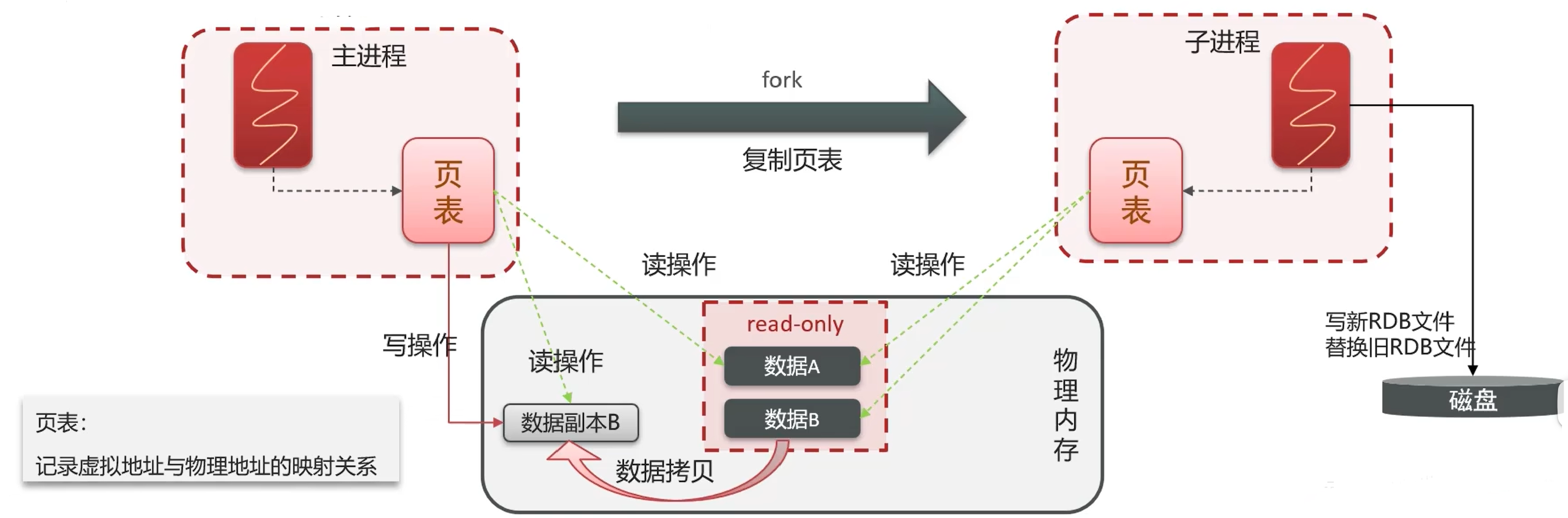
Redis 里一次完整的bgsave流程如下:
plsql
客户端发送 BGSAVE
↓
Redis 主进程调用 fork()
↓
操作系统创建子进程(共享内存页:主线程把页表拷贝给子进程)
↓
子进程:遍历内存 → 写 dump.rdb 文件,把 RDB 写入 磁盘中
↓
主进程:继续处理客户端请求
↓
子进程写完 → 发送信号给父进程
↓
父进程替换旧 RDB 文件(二)AOF
1. 什么是 AOF?
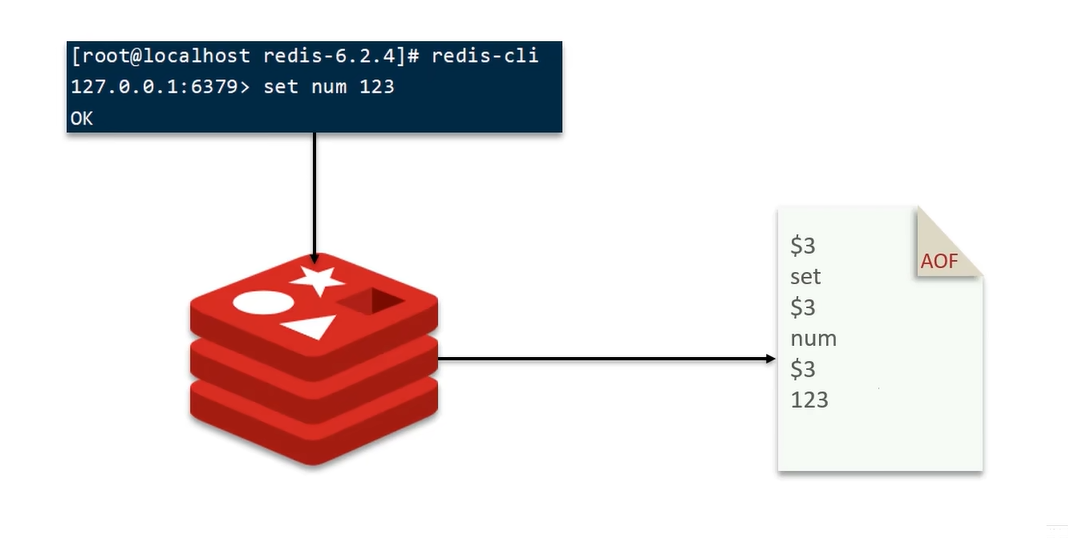
AOF 全称为 Append Only File(追加文件)。
Redis 处理的每一个写命令都会记录在 AOF 文件,可以看做是命令日志文件。
2. AOF 的基本操作
1)手动开启 AOF
在 redis.conf 配置文件中,AOF 默认是关闭的,需要将appendonly no 修改为 appendonly yes来开启 AOF:

2)设置刷盘策略
什么是 AOF 的刷盘策略?
AOF 刷盘策略是控制 AOF 缓冲区里的数据多久同步到磁盘一次。
每次执行写命令,比如
set num 123,Redis 会做以下三步:① 执行命令,修改内存数据
② 把这条命令追加写入 AOF 缓冲区
③ 什么时候真正写进磁盘?→ 由 appendfsync 决定
也就是说:
- 记录命令:几乎每次都会发生
- 刷盘落盘:由策略控制
AOF 是"先记日志,再按策略刷盘",刷盘策略管的是"落盘频率"。
AOF 的刷盘策略也可以通过修改 redis.conf 配置文件来设置:

AOF 有三种刷盘策略:

我们一般选择 everysec,性能适中,风险适中。
3)设置 AOF 重写
AOF 的缺点
- 因为是 AOF 记录的是命令, RDB 记录的是数据 → 所以 AOF 文件会比 RDB 文件大的多。
- 而且 AOF 会记录对同一个 key 的多次写操作,但只有最后一次写操作才是有意义的。
解决方案 ------ bgrewriteaof命令
- 手动触发 AOF 重写
我们可以在 redis-cli 里手动执行bgrewriteaof命令,立即 fork 子进程,在后台重写 AOF 文件,以此用最少的命令达到相同效果。
示例: 左边是原始 AOF(命令"流水账")→ 右边是重写后的 AOF(只保留"最终状态")

| 命令 | 含义 |
|---|---|
set num 123 |
把 key = num 的值设为 123 |
set name jack |
把 key = name 的值设为 jack |
set num 666 |
再次覆盖 key = num 的值,变成 666 |
num被 set 了两次123这个值 已经变成"历史垃圾数据"
- 自动触发 AOF 重写
我们也可以在 redis.conf 配置文件里配置 AOF 重写的策略(触发阈值)。
这样 Redis 就可以在触发某个阈值的时候,自动去重写 AOF 文件。

AOF 只有在"体积增长够多 + 文件本身够大"这两个条件同时满足时,才会自动触发重写。
(三)RDB 和 AOF 对比
RDB 和 AOF 是 Redis 提供的两套不同的数据持久化方案。
| 名称 | 本质身份 |
|---|---|
| RDB | 一种持久化方式(快照持久化) |
| AOF | 一种持久化方式(日志持久化) |
它们解决的是同一个问题:如何保证内存数据在 Redis 实例宕机后还能恢复?
它们最终会都会各自产生对应的磁盘文件。
| 持久化方式 | 生成的文件 |
|---|---|
| RDB | dump.rdb(二进制快照文件) |
| AOF | appendonly.aof(命令日志文件) |
RDB 和 AOF 各有优缺点,如果对数据安全性要求较高,在实际开发中往往会结合两者来使用。
二、相关面试题
什么是 Redis 的持久化?
Redis 的持久化机制,是指 Redis 通过 RDB 快照 或 AOF 日志 的方式,把内存中的数据同步保存到磁盘文件中,当 Redis 重启时,可以通过这些文件把数据恢复回来,从而保证数据不因宕机而丢失。
为什么 Redis 一定要做持久化?
因为:Redis 默认是 内存数据库
如果:服务器断电、进程崩溃
- 不做持久化 → 数据全部清空 ❌
- 做了持久化 → 可以从磁盘恢复 ✅
Redis 作缓存,数据的持久化是怎么做的?
Redis 中提供了两种数据持久化方式:一是 RDB ,二是 AOF 。
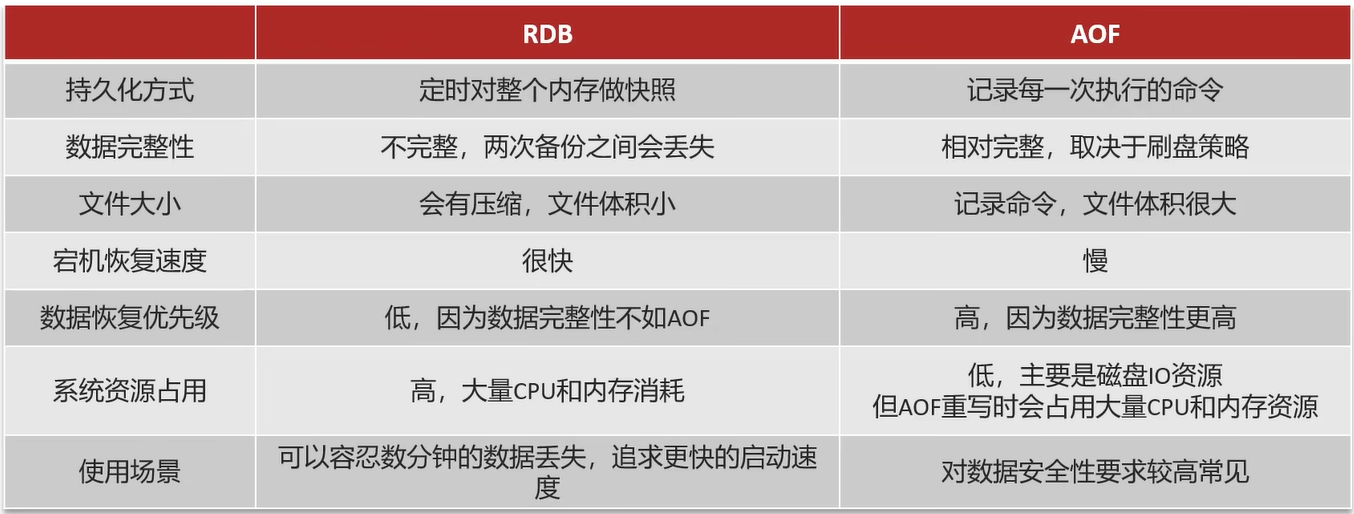
RDB 和 AOF 有什么区别?
RDB
定义: RDB 是通过生成内存数据快照来做持久化的,它会把某一时刻 Redis 内存中的所有数据一次性写入磁盘。优点: RDB 文件体积小、恢复快。
缺点: 但缺点是如果 Redis 异常宕机,可能会丢失最近一次快照之后的数据。
AOF
定义: AOF 是通过追加写命令日志来做持久化的。优点: 每一条写命令都会被记录下来,因此数据安全性更高。
缺点: 但缺点是 AOF 文件体积更大、恢复时需要重放命令,所以恢复速度相对更慢。
当 Redis 宕机重启时,会从 AOF 日志中再次执行一遍命令来恢复数据。
实际生产
我们在实际生产中通常会同时开启 RDB 和 AOF。
用 RDB 做冷备和快速恢复,用 AOF 保证数据安全。
这两种方式,哪种恢复得比较快?
RBD 快。
因为 RDB 是二进制文件,它在保存的时候体积也是比较小的,所以它恢复的比较快。
但是它有可能会丢数据,所以我们通常在项目中也会使用 AOF 来恢复数据。
虽然 AOF 恢复的速度慢一些,但是它丢数据的风险要小很多。
而且在 AOF 文件中可以设置刷盘策略,我们可以设置每秒批量写入一次命令。