安装环境
⚫ 虚拟机系统:CentOS7
⚫ Hadoop 安装模式:伪分布式(单节点)
⚫ Hive 安装模式:嵌入模式
⚫ 安装包:
Hive(3.1.3)
安装步骤
(1) 安装
解压 Hive 安装包
tar -zxvf apache-hive-3.1.3-bin.tar.gz
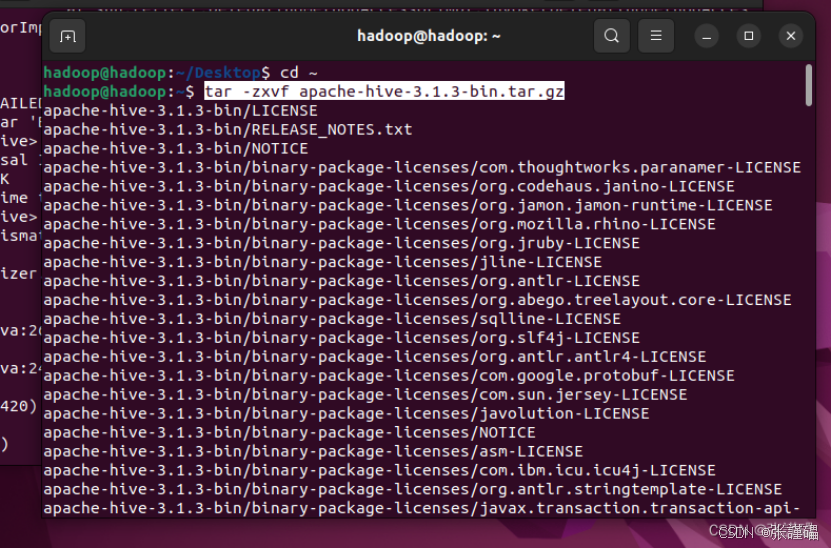
打开文件重命名
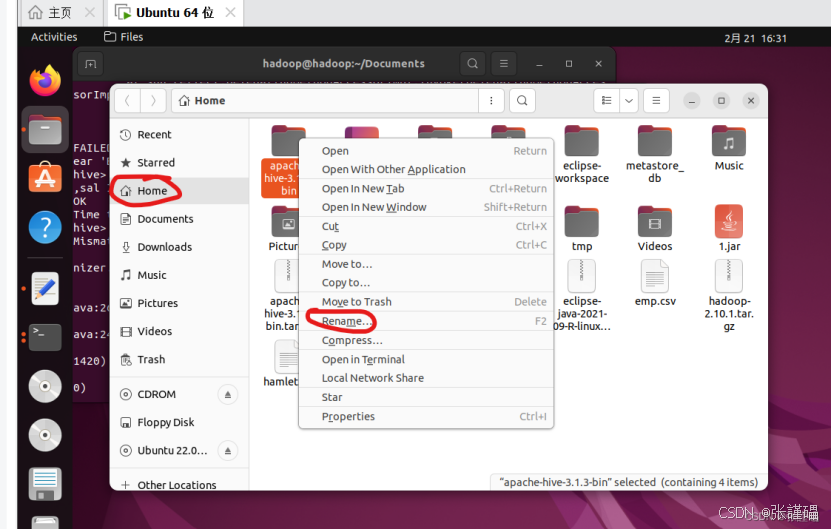
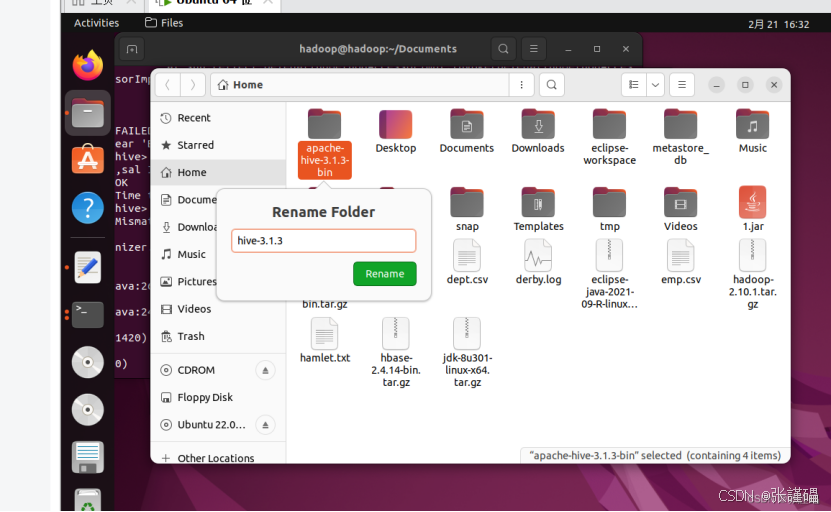
移动到/usr/local 路径下并命名
sudo mv hive-3.1.3 /usr/local/
(2) 配置环境变量
在**/etc/profile.d 路径** 下新建 hive.sh 脚本文件在文件中添加 HIVE_HOME 变量并将其添加到 PATH 变量中,后 export 这
两个变量。
sudo vim /etc/profile
在最下面添加
HIVE_HOME=/usr/local/hive-3.1.3
PATH=HIVE_HOME/bin:PATH
export HIVE_HOME PATH
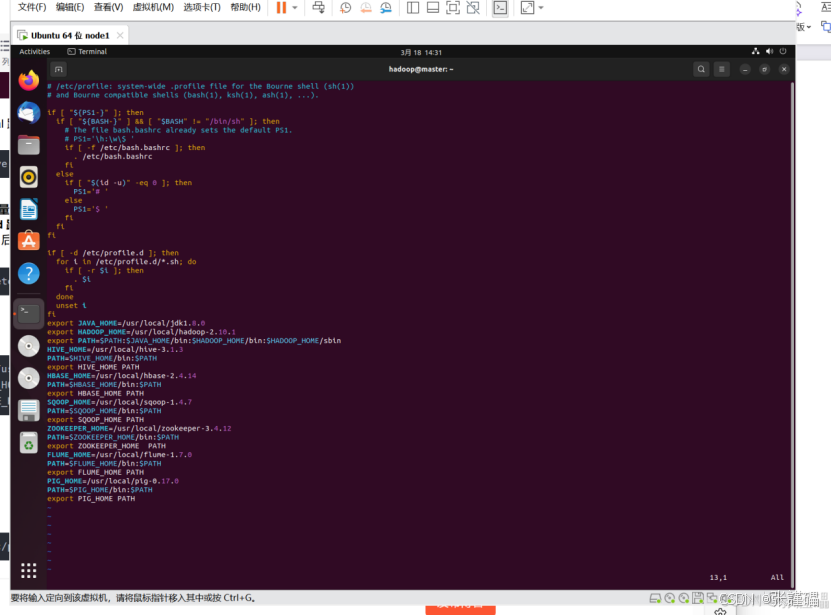
更新环境变量
source /etc/profile
测试是否配置成功**(需要提前启动 hdfs)**
hive
(3) Hive 配置文件
进入**/usr/local/hive-3.1.3 /conf/** 路径下
将 hive-env.sh.template 复制一份并命名为 hive-env.sh
cp hive-env.sh.template hive-env.sh
编辑 hive-env.sh 进行配置
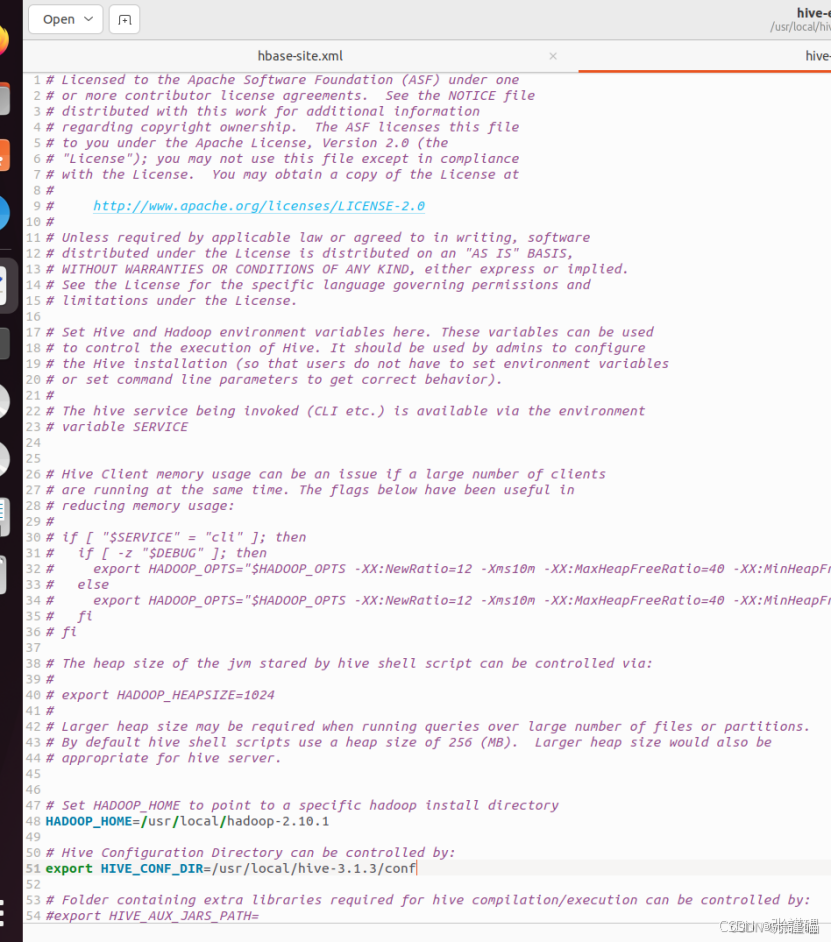
Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/usr/local/hadoop-2.10.1
Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/usr/local/hive-3.1.3/conf
找到"# HADOOP_HOME="开头的一行,去掉行首的"#",后配置为
Hadoop 的安装路径
找到"# HIVE_CONF_DIR="开头的一行,去掉行首的"#",后配置为
Hive 按照文件下的 conf 路径(/usr/local/hive-3.1.3 /conf/ )
在**/usr/local/hive-3.1.3/conf/** 路径下新建 hive-site.xml 并编辑
根据自己的实际hostname进行 编辑
vim hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby:;databaseName=metastore_db;create=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.apache.derby.jdbc.EmbeddedDriver</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
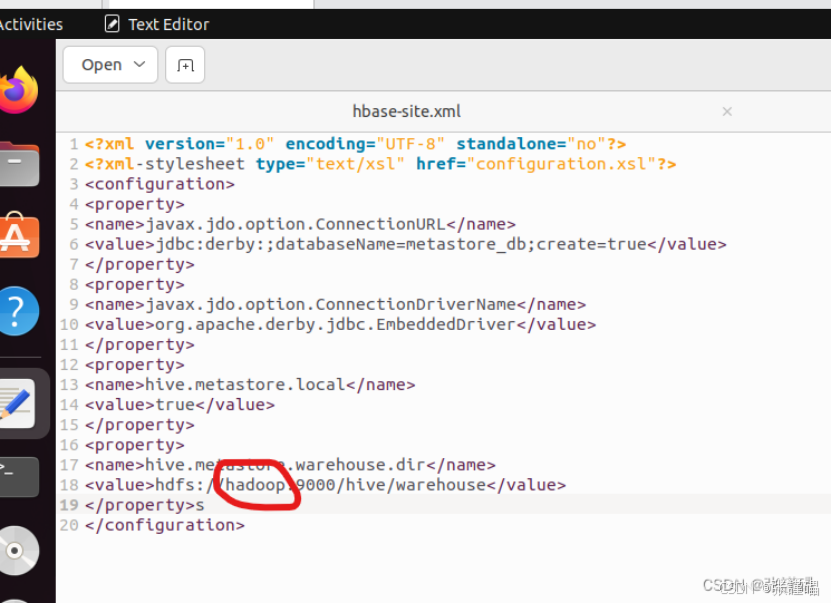
<property>
<name>hive.metastore.warehouse.dir</name>
<value>hdfs://192.168.254.7:9000/hive/warehouse</value>
</property>
</configuration>
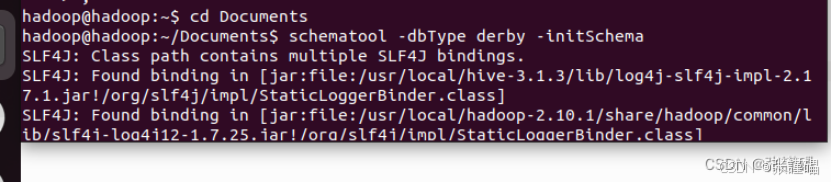
(4) 初始化 Derby 数据库
schematool -dbType derby -initSchema

测试hive安装是否成功:
Hive Shell入门基础命令
创建database test_db
CREATE DATABASE test_db;
使用database testDB
USE test_db;
创建emp表
CREATE TABLE emp(empno INT,ename STRING,job STRING,mgr INT,hiredate STRING,sal INT,comm INT,deptno INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY',';
1.将emp.csv中的数据导入到emp表中emp.csv表如下(要提前上传到hdfs上)
|------|--------|-----------|------|------------|------|------|----|
| 7369 | SMITH | CLERK | 7902 | 1980/12/17 | 800 | | 20 |
| 7499 | ALLEN | SALESMAN | 7698 | 1981/2/20 | 1600 | 300 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981/2/22 | 1250 | 500 | 30 |
| 7566 | JONES | MANAGER | 7839 | 1981/4/2 | 2975 | | 20 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981/9/28 | 1250 | 1400 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981/5/1 | 2850 | | 30 |
| 7782 | CLARK | MANAGER | 7839 | 1981/6/9 | 2450 | | 10 |
| 7788 | SCOTT | ANALYST | 7566 | 1987/4/19 | 3000 | | 20 |
| 7839 | KING | PRESIDENT | | 1981/11/17 | 5000 | | 10 |
| 7844 | TURNER | SALESMAN | 7698 | 1981/9/8 | 1500 | 0 | 30 |
| 7876 | ADAMS | CLERK | 7788 | 1987/5/23 | 1100 | | 20 |
| 7900 | JAMES | CLERK | 7698 | 1981/12/3 | 950 | | 30 |
| 7902 | FORD | ANALYST | 7566 | 1981/12/3 | 3000 | | 20 |
| 7934 | MILLER | CLERK | 7782 | 1982/1/23 | 1300 | | 10 |LOAD DATA INPATH '/ussr/local/input/emp.csv' INTO TABLE emp;
常用查询语句的使用
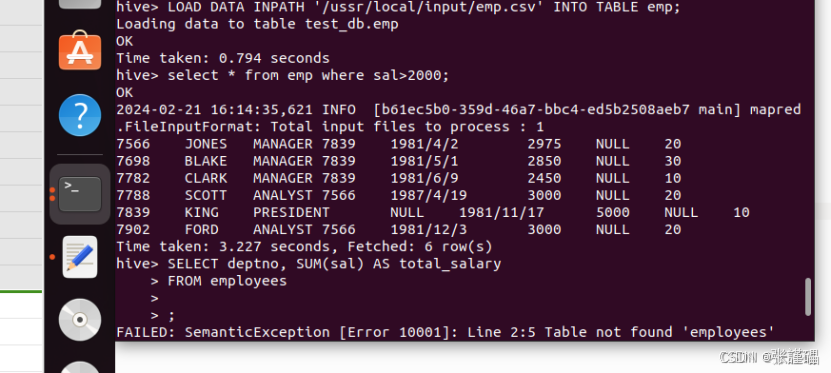
- 查询工资大于2000的员工信息。
select * from emp where sal>2000;
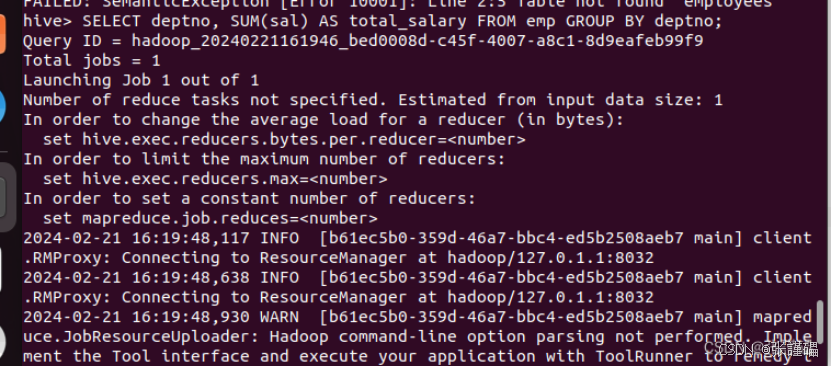
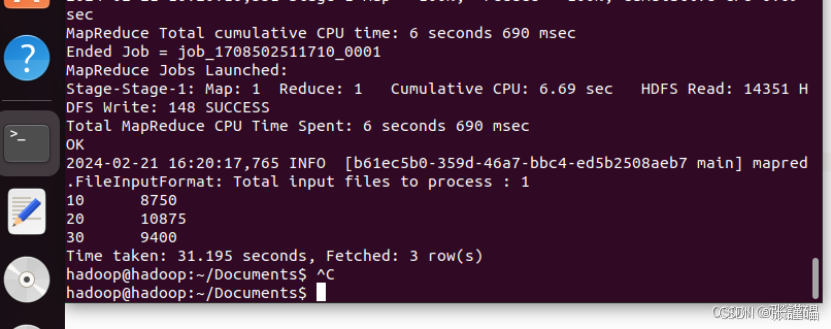
2.以部门号(deptno)来分组对员工工资(sal)进行求和。SELECT deptno, SUM(sal) AS total_salary FROM emp GROUP BY deptno;