(14 条消息) 大家觉得做一个大模型检索增强生成(RAG)系统,最难搞定的是那部分工作? - 知乎
一、RAG基本概念
定义:
**一种将检索与生成相结合的人工智能模型架构,**是目前大语言模型(LLM)落地应用中最主流的技术架构。
解决问题:
-
幻觉问题 (Hallucinations): 模型会一本正经地胡说八道。
-
知识时效性 (Outdated Knowledge): 模型的知识截止于训练结束的那一天(例如训练数据只到2023年)。
-
回答无法追根溯源:无法知道模型生成回答的依据。
-
RAG 的作用: 通过外挂一个知识库,让模型基于检索到的事实来生成答案,从而"更诚实、更实时、更懂你的业务"。
二、RAG 的核心工作流程 (The Workflow)
RAG 的运作可以分为两个阶段:数据准备(Indexing) 和 检索生成(Inference)。
(一)数据准备阶段 (离线)
为了让机器读懂知识库文档:
-
加载 (Load): 读取 PDF, Word, Markdown, HTML 等格式的结构化知识库。
-
切分 (Chunk): 将长文本切分成小的段落(Chunk),因为 LLM 有上下文窗口限制,且小段落语义更集中。
-
嵌入 (Embed): 使用 Embedding 模型将文本转化为向量 (Vectors)(一串数字,代表语义)。
-
**构建索引 (Build Index):**将上述向量输入 FAISS,FAISS 内部进行训练和添加,生成索引结构如倒排链表、HNSW 图等。
-
存储 (Store/Persist):将构建好的 Index 保存为文件或存入内存。
注释:
-
Chunk:用来做 embedding 和检索的小知识片段,是 RAG 的核心单位。
-
FAISS(Facebook AI Similarity Search): 由 Meta (原 Facebook) AI Research 团队开源的一个库,它是目前世界上最流行、最强悍的向量搜索引擎 。
FAISS vs. 向量数据库 (Vector DB):
-
**FAISS 是库 :**是一个底层工具包,需要写 Python/C++ 代码来调用它,数据存在内存或本地文件中,它不管数据的增删改查(CRUD)管理,只管算得快。
-
向量数据库 (如 Milvus, Chroma, Weaviate) 是一个完整的系统 : 它们很多底层其实就是封装了 FAISS或者类似的算法,但外层提供了服务器、API、数据持久化、权限管理等功能,让你像用 MySQL 一样用它。
-
总结关系: 如果你想自己造车,就用 FAISS; 如果你想直接开车,就用向量数据库。 但在做 RAG 实验或轻量级应用时,直接用 FAISS或 LangChain 里的 FAISS 包装器是最简单的。
-
(二) 检索生成阶段 (在线)
当用户提问时发生的动作:
-
提问编码(embedding): 将用户的问题也转化为向量。
-
语义检索 (Retrieve): 在向量库中寻找与"问题向量"距离最近的几个"文档片段向量"。
-
提示构建 (Augment): 将 <用户问题> + <检索到的相关片段> 拼装成一个新的 Prompt。
Prompt 示例: "你是一个助手。 请仅根据以下背景信息回答用户的问题:检索片段 1, 2, 3...。 用户问题:..."
-
生成回答 (Generate): LLM 阅读 Prompt,根据提供的背景信息生成最终答案。
三、RAG vs. Fine-tuning
这是开发者最常纠结的选择。 可以用"考试"来打比方:
-
RAG = 开卷考试(带着教科书进考场,随时查阅)。
-
Fine-tuning = 长期补习(把知识通过大量练习内化到脑子里,但这很难改变,且容易遗忘旧知识)。
| 维度 | RAG (检索增强) | Fine-tuning (微调) |
|---|---|---|
| 知识更新速度 | 极快 (直接更新数据库即可) | 慢 (需要重新训练模型) |
| 准确性/幻觉 | 较低 (基于事实检索) | 依然可能产生幻觉 |
| 数据隐私 | 数据在本地/私有库,不需要发给模型训练 | 数据需用于训练模型 (若是闭源模型有风险) |
| 成本 | 较低 (主要是检索和推理成本) | 高 (算力成本 + 数据清洗成本) |
| 适用场景 | 问答系统、客服、企业知识库 | 模仿特定说话风格、特定领域的复杂指令遵循 |
四、进阶 RAG (Advanced RAG)
基础 RAG 容易遇到检索不准的问题,目前业界正在向进阶架构演进:
-
混合检索 (Hybrid Search): 结合关键词检索 (BM25) 和 向量检索(Embedding),兼顾精确匹配和语义理解。
-
重排序 (Rerank): 在检索出前 50 个片段后,用一个高精度的 Rerank 模型(如 BGE-Reranker)对它们进行精细打分,只把最相关的 Top 5 给大模型。
-
GraphRAG: 利用知识图谱(Knowledge Graph)捕捉实体间的复杂关系,适合回答由于碎片化导致难以总结的全局性问题。
-
Self-RAG / Agentic RAG: 让模型自己判断"检索到的内容够不够回答问题",如果不够,自动重写查询词再次检索,甚至调用搜索引擎。
五、RAG应用开发最头疼两个问题:数据清洗和权限区分(企业)
"主流的数据清洗方式很难通吃多样的半结构化数据,很大情况下还是需要人工审核每一个文档,把一次性处理做不好的挑出来重新处理。"(14 条消息) 大家觉得做一个大模型检索增强生成(RAG)系统,最难搞定的是那部分工作? - 知乎
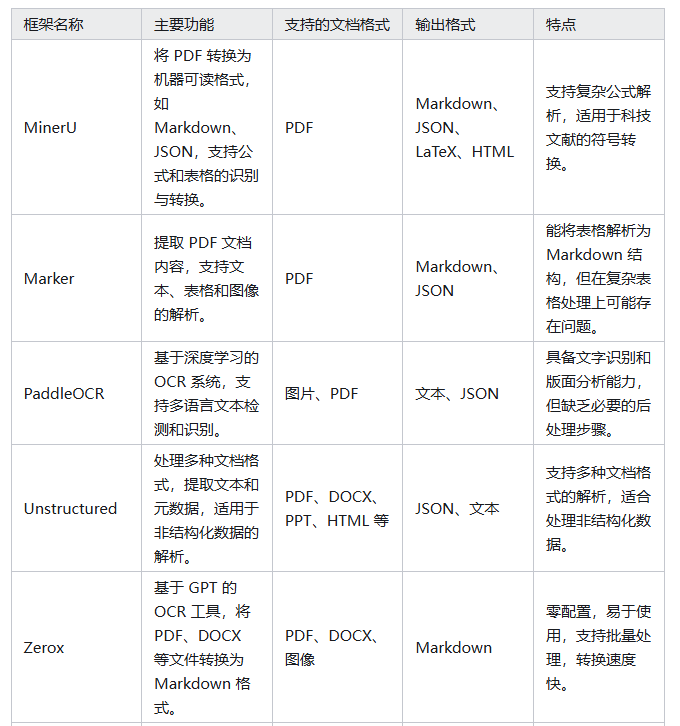
主流的文档预处理框架: