
文章摘要
本文介绍了SciDaSynth,一个创新的交互式系统,利用大语言模型自动从科学文献中提取结构化数据。系统能够整合文本、表格和图片等多模态信息,生成标准化数据表,并通过可视化摘要和语义分组功能帮助研究人员高效验证和优化数据,显著提升科研效率。
原文pdf:https://t.zsxq.com/wxoxx
一、研究背景:科学文献爆炸式增长带来的挑战
1.1 数据提取的紧迫性
科学研究的快速发展导致各学科研究文献呈现前所未有的增长态势。从这片浩瀚的信息海洋中提取和综合结构化知识,已成为推进科学理解和支持循证决策的关键环节。在这一过程中,数据提取------即从科学文献中识别和结构化相关信息------是效率和精度至关重要的关键阶段,尤其在时间敏感的领域。
一个典型案例是新冠疫情早期,研究人员急需确定感染COVID-19的女性进行母乳喂养的安全性。这要求从快速扩增的文献体系中,迅速而准确地提取关于实验条件(如人口统计学特征、研究环境)和健康结果的数据。
1.2 结构化数据的重要价值
数据提取过程产生的结构化数据通常以表格形式组织,对于跨研究的系统性比较、定量荟萃分析以及从多元证据来源得出综合结论都至关重要。这类数据对世界卫生组织(WHO)等机构制定和传播及时的循证指南具有关键作用。
1.3 当前面临的挑战
尽管数据提取极为重要,但它仍然是一项认知要求高且耗时的任务。研究人员常需要手动从多篇论文中提炼相关信息,在不同文档和数据录入工具之间频繁切换。这一过程不仅效率低下,还容易出现不一致和错误。
主要挑战包括:
-
文献中的多模态信息:科学论文包含文本、表格、图表等多种形式的信息,需要综合处理。
-
数据的多样性和不一致性:不同研究采用不同的术语、测量标准和报告格式,导致跨文档数据整合困难。
-
验证和质量控制:确保提取数据的准确性需要大量的人工审核工作。
二、SciDaSynth系统:创新的解决方案
2.1 系统核心架构
为应对上述挑战,研究团队开发了SciDaSynth------一个交互式系统,旨在帮助研究人员高效、可靠地从科学文献中提取和结构化数据。该系统利用大语言模型(LLMs)在检索增强生成框架(RAG)内工作,能够解释用户查询,从科学文档的多种模态中提取相关信息,并生成结构化的表格输出。
RAG框架的优势:
与仅依赖模型预训练知识的标准提示方法不同,RAG能够动态检索和整合最新的、特定领域的信息到提示中。通过将检索到的信息注入生成过程,RAG减少了幻觉现象并提高了事实准确性。
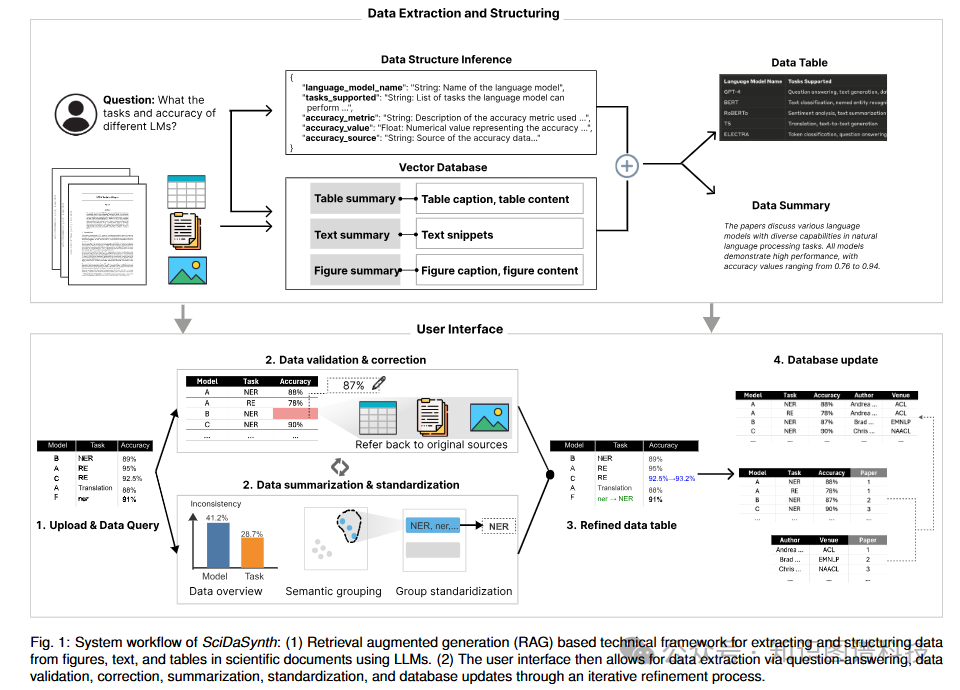
2.2 核心功能特性
2.2.1 灵活的数据查询与提取
用户上传研究文献的PDF文件后,可以通过自然语言问题(如"不同语言模型的任务和准确率是多少?")或自定义数据提取表单与SciDaSynth进行交互。系统随后处理这些问题,向用户呈现文本摘要和结构化数据表。
系统生成的数据表包含与用户问题相关的特定维度,如"模型"、"任务"和"准确率",以及从文献中提取的相应值。为引导用户关注需要验证的区域,系统会突出显示缺失值("空"单元格)和相关性得分低的记录。
2.2.2 多层次数据验证机制
为确保数据准确性,系统建立并维护提取数据与原始文献来源之间的连接,使用户能够迭代验证、纠正和优化数据。用户可以查看LLM使用的相关上下文,重要文本片段会被突出显示,还可以访问原始PDF文档。
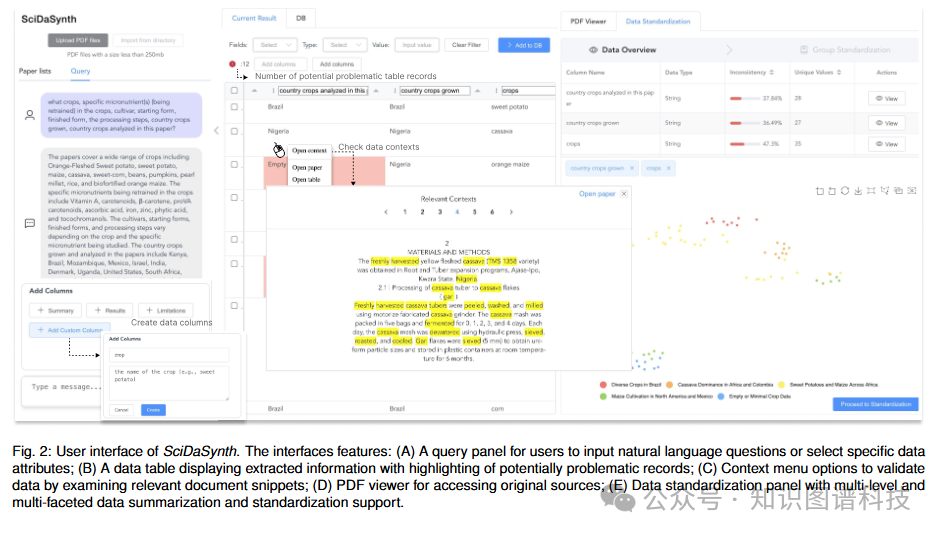
2.2.3 多维度可视化摘要
SciDaSynth提供数据维度和子集的多方面可视化摘要,突出显示定性和定量数据的变化和不一致性。系统支持基于语义和定量值的灵活数据分组,使用户能够通过操作这些组来标准化数据,并在组级别执行数据编码或编辑。
用户可以获得数据属性及其一致性信息的概览。选择特定属性后,系统对属性值进行语义分组,帮助用户识别潜在不一致性的上下文模式和分布(如全称与缩写)。
2.2.4 智能数据标准化
基于分组的属性值及其可视化摘要,用户可以创建、修改、重命名或合并组,有效地对数据进行分类。对分组结果满意后,用户可以应用标准化结果立即更新主数据表。此外,后续查询指令可应用于特定数据组以进一步优化。
三、技术创新:站在巨人的肩膀上
3.1 大语言模型在信息提取中的应用
科学论文的指数级增长为LLMs的构建和信息提取任务应用提供了大规模数据资源,如命名实体识别和科学领域的关系提取。这些模型分为两大类:仅编码器(非生成式)LLMs和生成式模型(自回归LLMs)。
编码器模型的特点:
- 如SciBERT通过在数百万科学摘要和全文论文上进行预训练,擅长分类、实体识别和检索任务,但不擅长生成新文本。
生成式模型的优势:
- GPT-4等生成式大语言模型可以预测序列中的下一个词,使其能够创建流畅的文本甚至直接从用户提示生成结构化输出。这种训练范式允许零样本或少样本提示:用户可以用自然语言描述提取任务,无需任何额外微调即可获得结构化结果------JSON、CSV等。
3.2 问答系统与可靠性保障
研究人员通常使用自然语言问题来表达他们对文档的信息需求和兴趣。许多研究者一直致力于为科学文档构建问答模型和基准。
然而,LLMs可能产生不可靠的答案,导致幻觉现象。因此,将生成结果归因于知识来源(或上下文)非常重要。SciDaSynth利用检索增强生成技术,通过将LLM输出建立在源文档的相关支持证据上来提高可靠性。然后,系统使用上下文相关性等定量指标来评估答案质量,并优先引导用户关注检查和修复低质量答案。
四、用户需求调研:倾听研究者的声音
4.1 调研方法
为了更好地理解当前实践及研究人员在数据提取过程中面临的挑战,研究团队开展了形成性访谈研究。调研重点关注研究人员完成论文搜索和筛选后,准备进行数据提取的阶段。
4.2 用户期望
自动化需求:
-
参与者期望AI系统能够根据他们的请求自动从文献中提取相关数据(7/12)
-
将数据组织成表格(9/12)
-
快速数据摘要和标准化以促进综合(6/12)
-
支持基于用户定义标准的论文分类(4/12)
-
支持批量高效审查和编辑(4/12)
易用性要求:
参与者期望计算机支持应易于学习并灵活适应他们的数据需求。许多参与者表示,现有工具如Covidence和Revman有些复杂,特别是新用户可能难以理解其功能和界面交互。
4.3 关注的问题
由于科学研究的复杂性,参与者对AI生成结果的准确性和可靠性表示担忧。他们担心AI缺乏足够的领域知识,可能基于错误的表格/文本/图表生成结果。参与者要求AI系统应突出显示不确定和缺失的信息,并希望对AI结果进行验证。
五、设计理念:以用户为中心
基于形成性研究识别的当前实践和挑战,以及从事数据提取的研究人员的具体需求,研究团队提炼出以下设计目标:
DG1. 支持灵活和全面的数据提取与结构化
系统应使用户能够为不同数据维度和测量定制数据提取查询。为减少手动工作,应自动从文本、表格和图表等各种模态中提取定性和定量数据。提取的数据应组织成结构化表格,为进一步优化和分析提供坚实基础。
DG2. 提供高效的数据验证和优化工具
系统应建立提取数据与源文献之间的可追溯连接,支持用户验证和纠正AI生成的结果。
DG3. 处理跨文档数据不一致性
系统应提供可视化工具和智能分组功能,帮助用户识别和解决不同文献间的数据差异和不一致。
六、实证研究:验证系统有效性
6.1 研究设计
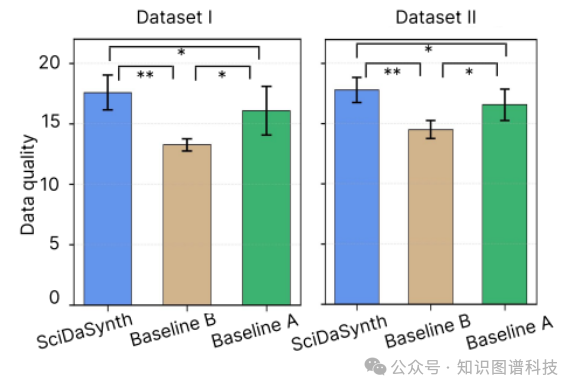
研究团队进行了一项受试者内研究,邀请来自营养学和自然语言处理(NLP)领域的研究人员评估SciDaSynth在研究文献数据提取方面的效率和准确性。
6.2 主要发现
效率提升:
定量分析表明,使用SciDaSynth,参与者能够在比基线方法短得多的时间内产生高质量数据。
用户反馈:
研究还讨论了用户感知的优势和局限性,为系统的进一步改进提供了宝贵见解。
七、主要贡献与未来展望
7.1 核心贡献
-
创新系统架构:SciDaSynth集成LLMs协助研究人员从广泛文献中提取和结构化多模态科学数据。系统将灵活的数据查询、多方面可视化摘要和语义分组整合在一个连贯的工作流程中,实现高效的跨文档数据验证、不一致性解决和优化。
-
实证验证:用户研究的定量和定性结果揭示了SciDaSynth在科学文献数据提取方面的有效性和可用性。
-
设计启示:为未来人机交互系统在数据提取和结构化方面的设计提供了重要启示。
7.2 未来方向
随着科学文献持续快速增长,像SciDaSynth这样的智能辅助系统将在加速知识发现和支持循证决策方面发挥越来越重要的作用。未来的研究可以关注:
-
进一步提升多模态信息融合能力
-
增强跨领域的泛化性能
-
优化人机协作的交互模式
-
扩展对更多科学领域的支持
八、结语
SciDaSynth代表了科学文献数据提取领域的重要进步。通过将大语言模型的强大能力与用户友好的交互设计相结合,系统不仅显著提升了数据提取的效率和准确性,还为研究人员提供了一个强大的工具来应对日益增长的文献量。这项工作为构建下一代科研辅助系统奠定了坚实基础,有望在加速科学发现和促进知识传播方面发挥重要作用。
相关标签
#LLM #大语言模型 #科学文献挖掘 #数据提取 #RetrievalAugmentedGeneration #知识图谱
欢迎加入「知识图谱增强大模型产学研」知识星球,获取最新产学研相关"知识图谱+大模型"相关论文、政府企业落地案例、避坑指南、电子书、文章等,行业重点是医疗护理、医药大健康、工业能源制造领域,也会跟踪AI4S科学研究相关内容,以及Palantir、OpenAI、微软、Writer、Glean、OpenEvidence等相关公司进展。