1. 什么是LangChain
🍋LangChain是一个基于大语言模型的开发框架,旨在帮助开发者构建端到端的语言模型应用。它提供丰富的工具套件和接口,支持实现文本生成图像、智能问答、聊天机器人等多种复杂任务。类似于 Java 中的 Spring ,Python 中的 Django
官网地址 :https://python.langchain.com/docs/introduction/
中文地址:https://www.langchain.com.cn/docs/introduction/
源码地址: https://github.com/langchain-ai/langchain
LangChain介绍:
python
🎉LangChain is a framework for developing applications powered by large language models (LLMs).
LangChain simplifies every stage of the LLM application lifecycle:
- Development: Build your applications using LangChain's open-source building blocks, components, and third-party integrations. Use LangGraph to build stateful agents with first-class streaming and human-in-the-loop support.
- Productionization: Use LangSmith to inspect, monitor and evaluate your chains, so that you can continuously optimize and deploy with confidence.
- Deployment: Turn your LangGraph applications into production-ready APIs and Assistants with LangGraph Cloud.
LangChain简化了LLM应用程序生命周期的各个阶段:
- 开发阶段 :使用
LangChain的开源构建块和组件构建应用程序,利用第三方集成和模板快速启动。- 生产化阶段 :使用
LangSmith检查、监控和评估您的链,从而可以自信地持续优化和部署。- 部署阶段 :使用
LangServe将任务链转化为API。
2. 大模型框架的重要性
2.1 多步骤串联(包含多轮思考与逻辑判断)
你想让
LLM:先调用知识库;再判断答案是否不完整;如果不完整,再调用另一个模型补足。 你怎么办?原始代码写死逻辑就麻烦了。框架可以让你用链(Chain)或Agent来封装这类流程,非常容易扩展。
python
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": "请推荐三本书"}]
)2.2 多模型、多任务融合
你希望系统: 用户提问 →
Claude回答; 遇到结构草图 → 用GPT-4; 编程代码 → 用kimi k2; 语义分析 → 用本地模型; 你要怎么切换?怎么统一接口?怎么路由调用逻辑?框架可以一键适配OpenAI、Anthropic、本地模型、HuggingFace等,统一抽象出Model类调用接口。 而且还能一点点扩展,而且避免你代码中充满下面代码
python
if model == 'gpt-3.5':
pass
elif model == 'claude-3':
passLangchain的核心组件
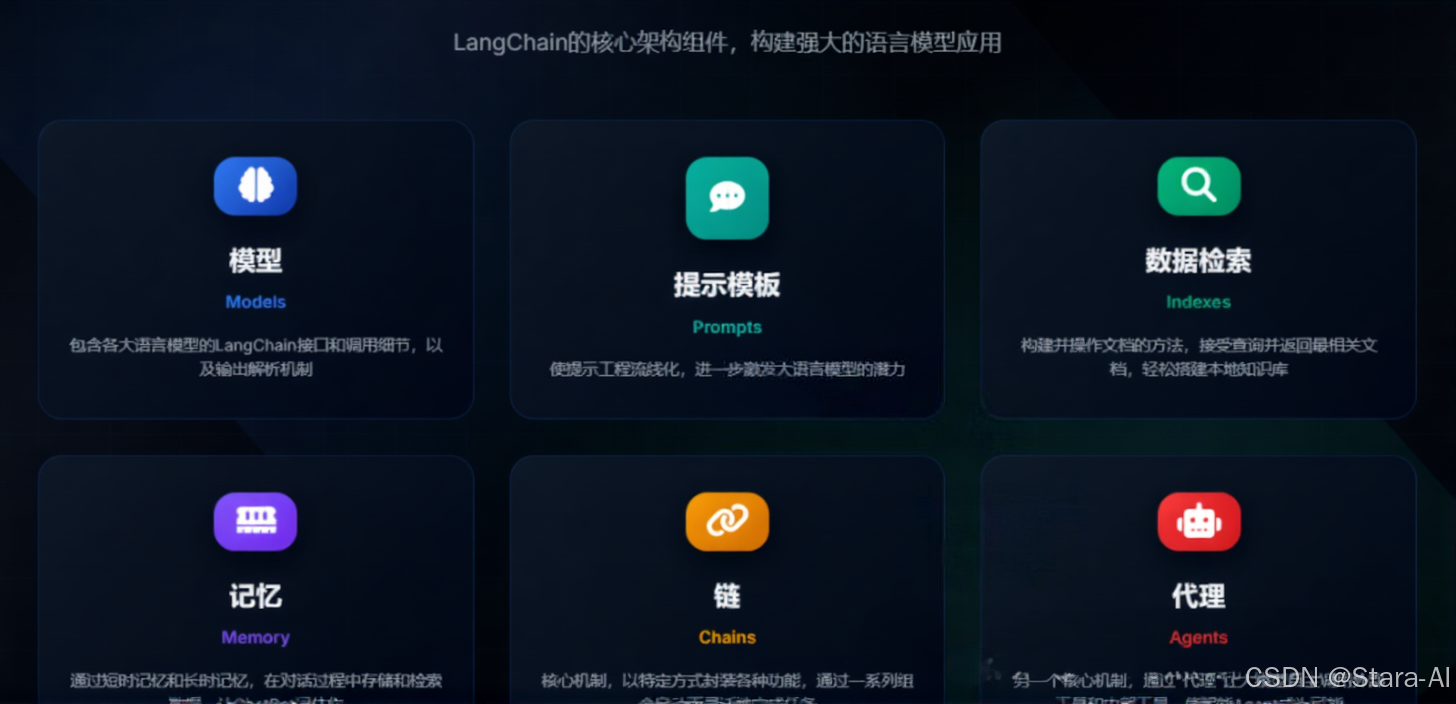
- 模型(
Models) :包含各大语言模型的LangChain接口和调用细节,以及输出解析机制。 - 提示模板(
Prompts):使提示工程流线化,进一步激发大语言模型的潜力。 - 数据检索(
Indexes):构建并操作文档的方法,接受用户的查询并返回最相关的文档,轻松搭建本地知识库。 - 记忆(
Memory) :通过短时记忆和长时记忆,在对话过程中存储和检索数据,让ChatBot记住你。 - 链(
Chains) :LangChain中的核心机制,以特定方式封装各种功能,并通过一系列的组合,自动而灵活地完成任务。 - 代理(
Agents) :另一个LangChain中的核心机制,通过"代理"让大模型自主调用外部工具和内部工具,使智能Agent成为可能。
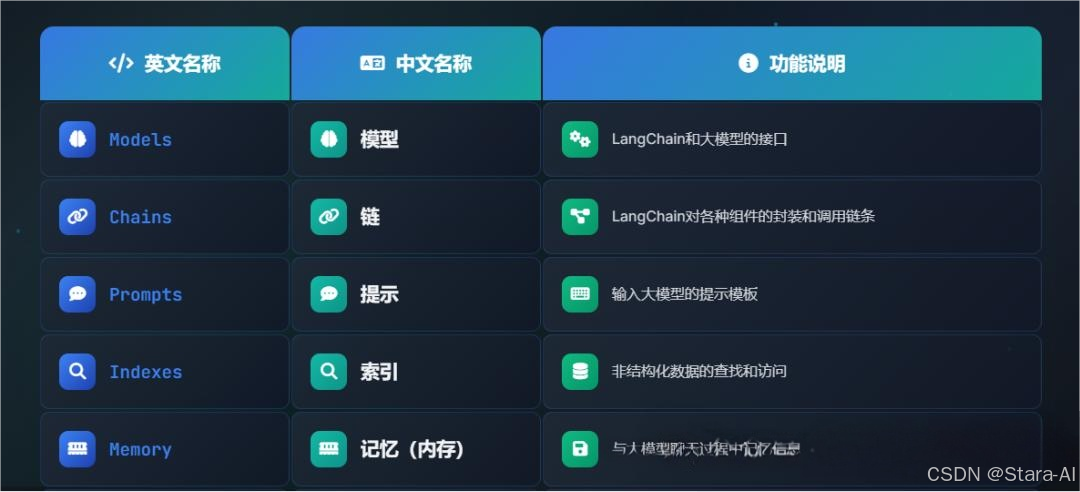
封装了多个功能模块
模型 I/O 封装,包括:
LLMs:大语言模型ChatModels:一般基于 LLMs,但按对话结构重新封装Prompt:提示词模板OutputParser:解析输出
Retrieval 数据连接与向量检索封装,包括:
Retriever: 向量的检索Document Loader:各种格式文件的加载器Embedding Model:文本向量化表示,用于检索等操作Verctor Store: 向量的存储Text Splitting:对文档的常用操作
Agents 根据用户输入,自动规划执行步骤,自动选择每步需要的工具,最终完成用户指定的功能,包括:
Tools:调用外部功能的函数,例如:调 google 搜索、文件 I/O、Linux Shell ...Toolkits:操作某软件的一组工具集,例如:操作 DB 、操作 Gmail ...
开源库组成
langchain-core:基础抽象和 LangChain 表达式语言langchain-community:第三方集成。合作伙伴包(如langchain-openai、langchain-anthropic 等),一些集成已经进一步拆分为自己的轻量级包,只依赖于langchain-corelangchain:构成应用程序认知架构的链、代理和检索策略langgraph:通过将步骤建模为图中的边和节点,使用 LLMs构建健壮且有状态的多参与者应用程序langserve:将 LangChain 链部署为 RESTAPILangSmith:一个开发者平台,可让您调试、测试、评估和监控LLM应用程序,并与LangChain无缝集成
3. LangChain 核心用法
安装指定版本的
LangChain
python
pip install langchain==0.3.7 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install langchain-openai==0.2.3 -i https://pypi.tuna.tsinghua.edu.cn/simple通过
LangChain的接口来调用OpenAI对话
python
# 从dotenv模块导入load_dotenv函数,用于加载.env文件中的环境变量
from dotenv import load_dotenv
# 加载.env文件中的环境变量到当前环境中
load_dotenv()
# 导入Python标准库的os模块,用于读取系统环境变量
import os
# 从langchain_openai包导入ChatOpenAI类,这是LangChain封装的OpenAI兼容聊天模型接口
from langchain_openai import ChatOpenAI
# ==============================================
# 模型初始化配置部分
# ==============================================
# 注释掉的代码:默认初始化(会使用OPENAI_API_KEY环境变量和官方OpenAI端点)
# llm = ChatOpenAI()
# 初始化通义千问(Qwen)模型客户端
# 参数说明:
# api_key: 从环境变量DASHSCOPE_API_KEY获取API密钥(阿里云DashScope平台)
# base_url: 指定API端点地址(DashScope的兼容模式接口)
# model: 指定使用的模型为"qwen-plus"
qwllm = ChatOpenAI(api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model="qwen-plus")
# 初始化DeepSeek模型客户端
# 参数说明:
# api_key: 从环境变量DEEPSEEK_API_KEY获取API密钥
# base_url: DeepSeek官方API端点
# model: 指定使用的模型为"deepseek-chat"
dpllm = ChatOpenAI(api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com",
model="deepseek-chat")
# ==============================================
# 模型调用示例
# ==============================================
# 使用通义千问模型进行对话调用
# invoke()方法:LangChain统一的方法调用接口
response = qwllm.invoke("什么是大模型?") # 传入用户问题
# 打印完整的响应对象(包含元数据、content等)
print(response)
print("=" * 50) # 分隔线
# 打印响应中的具体内容(AI的实际回复)
print(response.content)多轮对话的封装
python
from langchain_openai import ChatOpenAI
# 默认是gpt-3.5-turbo
# llm = ChatOpenAI()
llm = ChatOpenAI(api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model="qwen-plus")
from langchain.schema import (
AIMessage, #等价于OpenAI接口中的assistant role
HumanMessage, #等价于OpenAI接口中的user role
SystemMessage #等价于OpenAI接口中的system role
)
messages = [
SystemMessage(content="你是于老师的个人助理。你叫小沐"),
HumanMessage(content="我叫同学小张"),
HumanMessage(content="你是谁?")
]
response = llm.invoke(messages)
print(response.content)使用提示模板
python
# 我们也可以创建prompt template, 并引入一些变量到prompt template中,这样在应用的时候更加灵活
# 导入ChatPromptTemplate类,用于创建聊天格式的提示词模板
from langchain_core.prompts import ChatPromptTemplate
# ==============================================
# 创建提示词模板
# ==============================================
# ChatPromptTemplate.from_messages()方法:通过消息列表创建模板
# 参数说明:
# - 列表中的每个元组代表一条消息:(角色, 内容)
# - 角色:通常是"system"、"user"、"assistant"
# - 内容:可以是固定文本,也可以包含变量占位符 {variable_name}
prompt = ChatPromptTemplate.from_messages([
# system角色:设置AI的"人设"或任务背景
# 这条消息会告诉AI:"你是一个世界级的技术文档编写者"
("system", "您是世界级的技术文档编写者"),
# user角色:用户输入,使用变量占位符 {input}
# {input} 是一个变量,在实际调用时会被具体的用户问题替换
("user", "{input}")
])
# 打印模板对象,查看其结构和配置
print(prompt)
# ==============================================
# 使用模板(传统方式)
# ==============================================
# 方式1:手动格式化模板
# prompt.format(input="具体问题") 将 {input} 替换为实际值
formatted_prompt = prompt.format(input="大模型中的LangChain是什么")
# 调用语言模型,传入格式化后的提示词
result = llm.invoke(formatted_prompt)
# 打印结果
print(result)
# ==============================================
# 使用链式调用(LangChain推荐方式)
# ==============================================
# 注释掉的代码展示了更优雅的链式调用方式
# chain = prompt | llm # 创建处理链:prompt模板 -> 语言模型
#
# 说明:
# "|" 运算符:类似于Linux管道,将前一个组件的输出作为后一个组件的输入
# 相当于:input → prompt模板格式化 → LLM处理 → 输出
#
# 调用链:
# result = chain.invoke({"input": "大模型中的LangChain是什么?"})
#
# 优势:
# 1. 代码更简洁
# 2. 支持异步、流式处理
# 3. 易于扩展和调试输出解析器的应用
python
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser, JsonOutputParser
# 初始化模型
llm = ChatOpenAI()
# 创建提示模板
prompt = ChatPromptTemplate.from_messages([
("system", "您是世界级的技术文档编写者。"),
("user", "{input}")
])
# 使用输出解析器
output_parser = StrOutputParser()
# output_parser = JsonOutputParser()
# 将其添加到上一个链中
chain = prompt | llm | output_parser
# chain = prompt | llm
# 调用它并提出同样的问题。答案是一个字符串,而不是ChatMessage
chain.invoke({"input": "LangChain是什么?"})
# chain.invoke({"input": "LangChain是什么? 问题用question 回答用answer 用JSON格式回复"})向量存储
python
# 使用一个简单的本地向量存储 FAISS
pip install faiss-cpu
pip install langchain_community==0.3.7
python
# 导入WebBaseLoader类,用于从网页加载文档内容
from langchain_community.document_loaders import WebBaseLoader
# 加载环境变量(用于后续的API密钥管理)
from dotenv import load_dotenv
load_dotenv()
# 导入所需库
import bs4 # BeautifulSoup4,用于HTML解析
import os # 操作系统接口,用于环境变量和文件操作
# ==============================================
# 设置网络代理(针对国内网络环境)
# ==============================================
# 设置HTTP代理,解决网络访问问题
os.environ["http_proxy"] = "http://127.0.0.1:7897"
os.environ["https_proxy"] = "http://127.0.0.1:7897"
# ==============================================
# 加载网页文档
# ==============================================
# 创建WebBaseLoader实例,指定要加载的网页
loader = WebBaseLoader(
# web_path: 要抓取的网页URL
web_path="https://www.gov.cn/yaowen/liebiao/202512/content_7050601.htm",
# bs_kwargs: 传递给BeautifulSoup的解析参数
# parse_only: 只解析特定的HTML元素,提高效率
# bs4.SoupStrainer(id="UCAP-CONTENT"): 只提取id为"UCAP-CONTENT"的div元素
# (这是中国政府网文章内容的特定容器)
bs_kwargs=dict(parse_only=bs4.SoupStrainer(id="UCAP-CONTENT"))
)
# 执行加载操作,将网页内容转换为Document对象
docs = loader.load()
# print(docs) # 可以打印查看加载的文档结构
# ==============================================
# 初始化嵌入模型(文本向量化)
# ==============================================
# 注释掉的部分:使用OpenAI的嵌入模型
# from langchain_openai import OpenAIEmbeddings
# embeddings = OpenAIEmbeddings() # 需要OPENAI_API_KEY环境变量
# 使用阿里云DashScope(通义千问)的嵌入模型
from langchain_community.embeddings.dashscope import DashScopeEmbeddings
# 创建DashScope嵌入模型实例
embeddings = DashScopeEmbeddings(
model="text-embedding-v3", # 指定嵌入模型版本
dashscope_api_key=os.getenv("DASHSCOPE_API_KEY") # 从环境变量获取API密钥
)
# ==============================================
# 文本分割与向量存储
# ==============================================
# 导入向量存储和文本分割器
from langchain_community.vectorstores import FAISS # Facebook AI Similarity Search
from langchain_text_splitters import RecursiveCharacterTextSplitter # 递归文本分割器
# 创建文本分割器实例
# chunk_size=500: 每个文本块的最大字符数
# chunk_overlap=50: 相邻文本块之间的重叠字符数(保持上下文连贯性)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50
)
# 对加载的文档进行分割
# 将长文档分割成适合模型处理的小块
documents = text_splitter.split_documents(docs)
# 打印分割后的文档块数量
print(len(documents))
# ==============================================
# 创建向量数据库
# ==============================================
# 使用FAISS创建向量存储
# FAISS.from_documents()方法:
# 1. 使用嵌入模型将每个文档块转换为向量
# 2. 将所有向量存储在FAISS索引中
# 3. 建立快速相似度搜索的能力
vector = FAISS.from_documents(
documents=documents, # 分割后的文档列表
embedding=embeddings # 使用的嵌入模型
)
RAG+Langchain,基于外部知识,增强大模型回复
python
# 导入文档组合链创建函数,用于将检索到的文档与用户问题组合
from langchain.chains.combine_documents import create_stuff_documents_chain
# 导入聊天提示词模板类
from langchain_core.prompts import ChatPromptTemplate
# ==============================================
# 创建提示词模板(RAG专用)
# ==============================================
# 创建一个专门用于检索增强生成(RAG)的提示词模板
prompt = ChatPromptTemplate.from_template("""仅根据提供的上下文回答以下问题:
<context>
{context}
</context>
问题: {input}""")
# 模板解析:
# 1. {context}: 占位符,将被替换为检索到的相关文档内容
# 2. {input}: 占位符,将被替换为用户的实际问题
# 3. "仅根据提供的上下文": 重要指令,强制模型只基于提供的文档回答,避免幻觉
# ==============================================
# 初始化语言模型
# ==============================================
from langchain_openai import ChatOpenAI
# 创建语言模型实例(默认使用gpt-3.5-turbo)
llm = ChatOpenAI()
# ==============================================
# 创建文档组合链
# ==============================================
# 创建文档组合链:将文档内容和用户问题组合成完整提示
# 工作流程:接收文档列表 + 用户问题 → 格式化提示词 → 传递给LLM
document_chain = create_stuff_documents_chain(llm, prompt)
# ==============================================
# 创建检索增强生成(RAG)链
# ==============================================
from langchain.chains import create_retrieval_chain
# 从向量数据库中创建检索器(假设vector是已存在的FAISS向量库)
retriever = vector.as_retriever()
# 配置检索参数:限制最多返回3个最相关的文档
retriever.search_kwargs = {"k": 3}
# 创建检索链:结合检索器和文档组合链
# 工作流程:用户问题 → 检索器查找相关文档 → 文档组合链生成答案
retrieval_chain = create_retrieval_chain(retriever, document_chain)
# ==============================================
# 调用RAG链并获取回答
# ==============================================
# 调用检索增强生成链
response = retrieval_chain.invoke({"input": "建设用地使用权是什么?"})
# 打印生成的答案
# response是一个字典,包含:
# - "answer": AI生成的答案
# - "context": 使用的参考文档
# - "question": 原始问题等
print(response["answer"])代理的使用
在 LangChain 框架中,Agents是一种利用大型语言模型(Large Language Models,简称LLMs)来执行任务和做出决策的系统。
在 LangChain 的世界里,Agent 是一个智能代理,它的任务是听取你的需求(用户输入)和分析当前的情境(应用场景),然后从它的工具箱(一系列可用工具)中选择最合适的工具来执行操作
- 使用工具(
Tool):LangChain中的Agents可以使用一系列的工具(Tools)实现,这些工具可以是API调用、数据库查询、文件处理等,Agents通过这些工具来执行特定的功能。 - 推理引擎(
Reasoning Engine):Agents使用语言模型作为推理引擎,以确定在给定情境下应该采取哪些行动,以及这些行动的执行顺序。 - 可追溯性(
Traceability):LangChain的Agents操作是可追溯的,这意味着可以记录和审查Agents执行的所有步骤,这对于调试和理解代理的行为非常有用。 - 自定义(
Customizability):开发者可以根据需要自定义Agents的行为,包括创建新的工具、定义新的Agents类型或修改现有的Agents。 - 交互式(
Interactivity):Agents可以与用户进行交互,响应用户的查询,并根据用户的输入采取行动。 - 记忆能力(
Memory):LangChain的Agents可以被赋予记忆能力,这意味着它们可以记住先前的交互和状态,从而在后续的决策中使用这些信息。 - 执行器(
Agent Executor):LangChain提供了Agent Executor,这是一个用来运行代理并执行其决策的工具,负责协调代理的决策和实际的工具执行。
python
# 导入检索器工具创建函数,将检索器包装成Agent可调用的工具
from langchain.tools.retriever import create_retriever_tool
# ==============================================
# 创建检索器工具
# ==============================================
# 将之前的retriever(向量检索器)包装成工具
retriever_tool = create_retriever_tool(
retriever, # 之前创建的向量检索器实例
"CivilCodeRetriever", # 工具名称(Agent内部识别用)
"搜索有关中华人民共和国民法典的信息。关于中华人民共和国民法典的任何问题,您必须使用此工具!", # 工具描述(Agent决策用)
)
# 工具列表(可以包含多个工具)
tools = [retriever_tool]
# ==============================================
# 初始化智能代理(Agent)
# ==============================================
# 导入相关模块
from langchain_openai import ChatOpenAI
from langchain import hub # LangChain的提示词模板库
from langchain.agents import create_openai_functions_agent # 创建基于OpenAI函数调用的Agent
from langchain.agents import AgentExecutor # Agent执行器
# ==============================================
# 获取预定义的Agent提示词模板
# ==============================================
# 从LangChain Hub拉取预定义的Agent提示词模板
# hwchase17/openai-functions-agent 是一个标准的OpenAI函数调用Agent模板
# 访问 https://smith.langchain.com/hub 查看所有可用模板
prompt = hub.pull("hwchase17/openai-functions-agent")
# ==============================================
# 创建Agent
# ==============================================
# 初始化语言模型(使用GPT-4,temperature=0确保确定性回答)
llm = ChatOpenAI(model="gpt-4", temperature=0)
# 创建OpenAI函数调用Agent
# 参数:语言模型、可用工具列表、提示词模板
agent = create_openai_functions_agent(llm, tools, prompt)
# 创建Agent执行器(实际执行Agent决策的组件)
# verbose=True 会打印详细的执行过程
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# ==============================================
# 运行Agent
# ==============================================
# 调用Agent执行器处理用户输入
response = agent_executor.invoke({"input": "建设用地使用权是什么"})
# response包含Agent的完整响应4. 结语
在本文中,我们系统梳理了
LangChain框架的核心架构、关键组件与实践应用。作为大语言模型应用开发的重要工具,LangChain通过模块化设计、标准化接口与链式编排,显著降低了构建复杂AI应用的门槛。无论是实现检索增强生成(RAG)、构建智能代理系统,还是整合多源模型与外部工具,LangChain都为开发者提供了一条清晰、可扩展的技术路径。随着大模型技术的持续演进,掌握LangChain这样的框架工具,将助力我们在 AI时代更高效地将技术潜力转化为实际价值,推动智能化应用在各行各业的落地与创新。