哈喽,我是我不是小upper~
做深度学习的同学肯定都有过这困扰:处理时序数据、文本序列或是传感器序列时,CNN 和 LSTM 到底该 pick 谁?
其实不用死磕二选一!
对于大多数需要兼顾 "抓局部细节模式" 和 "连长程关联" 的任务来说,CNN+BiLSTM 就是对超有默契的黄金搭档,强强联合才是最优解呀~
为什么是 CNN+BiLSTM?
在深度学习处理时序数据、文本序列或传感器序列的场景中,很多从业者都会纠结模型选型,但CNN与BiLSTM的组合绝非二选一的取舍,而是针对序列建模核心痛点的 "精准破局方案"。
一、序列建模的核心痛点与单模型局限
我们在做序列建模时,始终面临两个绕不开的核心需求,同时也是单模型难以兼顾的痛点:
- 局部模式的精准捕捉:序列中往往存在关键局部结构,比如文本里情感词的固定搭配、传感器数据中突发事件对应的数值尖峰,这类特征需要依赖局部感受野来锁定;
- 长程依赖的全局关联:序列的完整语义或趋势由上下文的长距离关系决定,比如文本中否定词对后续情感倾向的扭转、患者生理指标在跨时段的关联影响,这类关联需要具备记忆和双向上下文感知的能力。
若仅用 CNN,虽能高效抓取局部特征,却会因感受野有限而忽略跨长时段的关联;若仅用 LSTM,虽能建模长程依赖,但存在参数冗余、训练效率低的问题,且对局部微小模式的感知效率远不及卷积。
而 CNN+BiLSTM 的组合恰好实现优势互补:CNN 为模型搭建稳定的局部特征金字塔并赋予局部不变性,BiLSTM 则通过门控机制实现双向信息整合与长程记忆,既保障了梯度传播的稳健性,又能兼顾局部与全局特征。因此在多数序列分类任务中,该组合能显著提升模型性能与泛化能力。
二、底层原理
(一)一维卷积:序列局部特征的高效提取
当处理序列数据时,一维卷积会沿时间轴滑动卷积核,完成局部特征的提取与层级化构建。
1. 输入与卷积输出定义
设输入为长度为T的序列,每个时间步的特征维度为,则输入可表示为矩阵
。若卷积核大小为k(时间维度的窗口长度)、输入通道数为
(即din)、输出通道数为
,则在时间步t处,卷积输出第c个通道的特征可表示为:
其中,为卷积核权重,
为偏置项,σ为 ReLU、Sigmoid 等非线性激活函数,且需满足
(超出序列长度的位置可通过 padding 补齐)。
2. 层级化感受野的递推
通过堆叠多层卷积,可逐步扩大模型的感受野,实现从细粒度到粗粒度的特征提取。若不使用空洞卷积,设第l层卷积的感受野为,卷积核大小为
,则感受野的递推公式为:
其中,(首层感受野等于卷积核大小),
为第m层卷积的步幅(若步幅
=1,则公式简化为
)。
3. 一维卷积的核心优势
- 可在局部窗口内形成专属 "模式检测器",对序列中的尖峰、固定词组等局部特征具备平移不变性;
- 基于参数共享机制,计算效率高且对局部噪声鲁棒性强;
- 可搭配池化层或步幅卷积,构建多尺度特征金字塔。
(二)双向 LSTM(BiLSTM):长程双向上下文的精准建模
LSTM 通过独特的门控机制缓解了传统 RNN 的梯度消失问题,可稳定记忆远距离信息;而 BiLSTM 则同时沿正向 (从序列开头到结尾)和反向(从序列结尾到开头)处理数据,实现双向上下文的深度融合。
1. 单向 LSTM 的门控机制
设单向 LSTM 的输入为时间步t的特征,上一时刻记忆单元为
、隐状态为
,各权重矩阵分别为W(输入权重)、U(隐状态权重),偏置为b,则各核心模块的计算公式为:
- 输入门 :控制新信息的输入权重
- 遗忘门 :控制历史记忆的保留比例
- 输出门 :控制记忆单元向隐状态的输出比例
- 候选记忆 :生成当前时刻的候选记忆内容
- 记忆单元更新 :融合历史记忆与当前候选记忆
- 隐状态输出 :生成当前时刻的隐状态
其中,⊙为哈达玛积(逐元素相乘),σ为 Sigmoid 激活函数,tanh为双曲正切激活函数。
2. BiLSTM 的双向信息融合
设正向 LSTM 在时间步t的隐状态为,反向 LSTM 的隐状态为
,单向隐状态维度为
,则 BiLSTM 的最终隐状态为双向隐状态的拼接:
其中,";" 表示维度拼接操作。
3. BiLSTM 的核心优势
- 实现双向上下文的整合,可精准理解序列的完整语义(如文本中前后文的逻辑关联);
- 门控机制保障了长程依赖建模的稳定性,避免了传统 RNN 的梯度消失问题;
- 分类任务中可灵活选择最后时刻隐状态、全局平均池化或注意力池化完成特征汇聚。
三、CNN+BiLSTM 的融合结构与信息流
1. 经典融合架构
CNN+BiLSTM 的标准流程为 **"CNN 局部特征提取→BiLSTM 长程依赖建模→全连接层分类"**:先通过一维 CNN 将原始序列转化为结构化的高层局部特征,再将卷积输出的通道特征作为 BiLSTM 的输入,最后通过特征聚合与全连接层输出类别概率分布。
2. 完整信息流公式
设原始输入序列为,经L层一维 CNN 后得到高层局部特征
(T′为卷积后序列长度,由 padding 和步幅决定);将
输入 BiLSTM,得到各时间步的双向隐状态
。
最后可通过以下 3 种方式完成特征聚合,再送入全连接层FC得到类别分布:
- 最后时刻聚合 :直接取序列末尾的双向隐状态作为全局特征
- 全局平均池化 :对所有时间步的隐状态做均值聚合,兼顾全序列信息
- 注意力池化 :为不同时间步隐状态分配权重,聚焦关键特征先计算注意力权重
再加权求和得到全局特征:
其中,、
为注意力权重参数,ba∈Rda为偏置项,da为注意力隐层维度。
3. 融合架构的核心优势
- 降噪减负:CNN 先将原始输入中的噪声转化为结构化通道特征,大幅降低 BiLSTM 的特征处理负担;
- 加速收敛:卷积的局部特征先验让模型无需在原始噪声数据中盲目学习,提升训练效率;
- 优势协同:BiLSTM 在卷积特征基础上建模,可精准挖掘局部模式的长程序列关联;
- 参数优化:将局部特征学习任务交给轻量高效的 CNN,避免了用超大 LSTM 隐层实现端到端记忆的参数冗余问题。
四、何时 CNN+BiLSTM 更优?
CNN 与 BiLSTM 的组合并非万能解,但在中等长度、同时具备显著局部模式与长程上下文逻辑的序列建模任务中,是兼顾性能与效率的高性价比方案。不同领域的任务适配逻辑、特征流转机制及选型边界可具体拆解如下:
1. 典型适配场景的核心逻辑与特征公式
1.1 文本分类任务:兼顾局部搭配与全局语义
文本分类的核心需求是同时识别词 / 短语级的局部情感 / 语义搭配 (如 "不 + 好用" 这类否定情感组合)和整句的全局上下文逻辑(如前文铺垫对后文观点的影响)。
- CNN 的作用:以词嵌入为输入,通过一维卷积捕捉局部词组搭配的特征模式,过滤无意义的词汇噪声;
- BiLSTM 的作用:在卷积提取的局部特征基础上,整合双向上下文语义,完成情感或类别判定。
对应场景的特征流转公式
设文本序列的词嵌入矩阵为(T为文本长度,
为词嵌入维度),经一维 CNN 处理后得到局部词组特征
,再输入 BiLSTM 得到双向隐状态
,最终通过注意力池化聚合特征并分类:
其中为全连接层权重,
为文本分类类别数。
1.2 生理信号 / 工业传感器时序任务:捕捉局部异常与跨时段演变
生理信号(如心电、脑电)和工业传感器数据的核心需求是识别局部异常波形 (如心电的早搏峰值、传感器的故障尖峰)和跨时段的状态演变(如患者症状的渐进性变化、设备参数的缓慢漂移)。
- CNN 的作用:对原始时序信号做局部卷积,精准定位波形中的异常段和特征峰值,生成结构化的局部状态特征;
- BiLSTM 的作用:整合这些局部状态的时序关联,挖掘先兆模式与故障 / 病症的长程依赖。
对应场景的特征流转公式
设传感器 / 生理信号的原始时序为(
为信号维度,如多导联心电的导联数),经多层一维 CNN 和池化操作后得到局部波形特征
,输入 BiLSTM 后采用全局平均池化聚合全时段状态特征(避免单时刻特征的偶然性):
若需聚焦异常时段,可替换为最大池化 :,强化异常特征的权重。
1.3 金融时间序列任务:整合短期形态与长程策略逻辑
金融时序(如股票 K 线、期货价格)的核心需求是识别短期价格形态 (如阳包阴 K 线组合、MACD 金叉的局部走势)和长程趋势逻辑(如政策周期对价格的持续影响、多周期指标的联动)。
- CNN 的作用:对 K 线的价格、成交量等维度做局部卷积,提取短期技术形态特征;
- BiLSTM 的作用:整合这些短期形态的时序关联,挖掘长程的风险累积或趋势延续逻辑。
对应场景的特征流转公式
设金融时序的多维度指标(价格、成交量、均线等)为,经 CNN 得到短期形态特征
,输入 BiLSTM 后结合最后时刻聚合(聚焦最新趋势)完成趋势 / 涨跌分类:
1.4 多模态序列任务:实现局部模态聚合与跨模态时序对齐
多模态序列(如视频的帧图像 + 音频时序、医疗的影像切片 + 检验指标时序)的核心需求是聚合单模态的局部特征 (如影像的病灶区域、音频的特征频段)和实现跨模态的时序对齐(如影像病灶变化与检验指标的时序关联)。
- CNN 的作用:对各模态的局部信息分别做卷积(如 2D CNN 处理影像切片、1D CNN 处理音频 / 检验指标),完成单模态局部特征的提取与聚合;
- BiLSTM 的作用:对多模态卷积特征做时序对齐,整合跨模态的长程上下文关联。
对应场景的特征流转公式
设模态 1(如影像切片时序)为,经 2D CNN 得到局部特征
;模态 2(如检验指标)为
,经 1D CNN 得到特征
;将多模态特征拼接为
,再输入 BiLSTM 完成跨模态时序建模:
2. 方案选型边界:何时不用 CNN+BiLSTM?
2.1 单 CNN 即可胜任的场景
当序列长度极短 (如短句分类、单周期传感器数据)或长程依赖不显著(如独立的文本短语情感判定、单批次工业质检信号)时,无需 BiLSTM 的长程建模能力,单 CNN 即可通过多层卷积扩大感受野,以更低的计算成本完成任务。
2.2 注意力 / 纯 Transformer 更优的场景
当序列的局部模式不明显、核心逻辑高度依赖全局关联时(如长文档的语义摘要、多轮对话的意图理解),CNN 的局部感受野会限制全局信息捕捉;此时基于自注意力的 Transformer 或纯注意力模型,可通过全局注意力机制直接建模任意位置的关联,效果优于 CNN+BiLSTM。
2.3 核心结论
只有在序列为中等长度、同时具备 "可识别的局部模式" 和 "强关联性的长程上下文" 时,CNN+BiLSTM 才能最大化其 "局部特征提取 + 长程依赖整合" 的协同优势,成为兼顾性能与效率的最优解。
完整案例
为了方便说明问题,我们构造一个虚拟序列分类任务,共 4 类。
整个数据特性:
每条序列长度 T=50,每步特征维度d=8 。
每个类别由不同的局部模式和长程规则定义:
-
类 0:序列前段出现上升局部模式且后段平稳。
-
类 1:在中段出现两个相距一定的尖峰对。
-
类 2:序列末段出现下降局部模式。
-
类 3:全局和局部混合规则,比如起伏中但均值偏高 并伴随一个微小尖峰。
CNN 负责检测局部模式(如尖峰、上升/下降片段),BiLSTM 负责根据模式的出现位置与组合关系进行判别。
python
import os
import random
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import TensorDataset, DataLoader
from sklearn.metrics import confusion_matrix, roc_curve, auc, accuracy_score
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
import seaborn as sns
from torch.optim.lr_scheduler import ReduceLROnPlateau
import sklearn # 查看版本
print(f"sklearn版本: {sklearn.__version__}")
def set_seed(seed=42):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True # 增加确定性
set_seed(42)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 优先用GPU
print(f"使用设备: {device}")
# 合成序列数据生成(增加轻微噪声增强,提升泛化性)
def generate_sequence(num_samples=2000, seq_len=50, feat_dim=8, num_classes=4):
"""
生成带有类别特有局部模式与长程关系的序列数据,增加随机噪声增强泛化性。
"""
X = np.random.randn(num_samples, seq_len, feat_dim) * 0.4 # 基础噪声
y = np.zeros(num_samples, dtype=np.int64)
for i in range(num_samples):
cls = np.random.randint(0, num_classes)
y[i] = cls
# 基础趋势(不同类别的上升或下降趋势)
trend = np.linspace(0, 1, seq_len) if cls in [0, 3] else np.linspace(1, 0, seq_len)
X[i, :, 0] += trend * (0.8 if cls==0 else 0.5)
X[i, :, 1] += trend[::-1] * (0.3 if cls==2 else 0.2)
# 类 1:局部尖峰对
if cls == 1:
pos1 = np.random.randint(seq_len//3, seq_len//2)
pos2 = pos1 + np.random.randint(5, 12)
X[i, pos1, 2] += 3.0
X[i, pos2, 2] += 2.5
# 尖峰附近做平滑增强
for p in [pos1, pos2]:
for w in range(-2, 3):
idx = np.clip(p + w, 0, seq_len-1)
X[i, idx, 2] += (2.0 - abs(w)) * 0.3
# 类 0:序列开头的上升模式
if cls == 0:
start = np.random.randint(0, 6)
window = range(start, min(start+8, seq_len))
for t in window:
X[i, t, 3] += 0.2 * (t - start)
X[i, seq_len//2:, 3] += 0.0 # 后半段保持平稳
# 类 2:结尾区域下降模式
if cls == 2:
end = np.random.randint(seq_len-10, seq_len-3)
window = range(max(0, end-8), end)
base = X[i, :, 4].copy()
for j, t in enumerate(window):
X[i, t, 4] += -0.25 * j
X[i, end:, 4] += -0.25 * len(list(window))
# 类 3:全局均值更高 + 中间小峰值 + 正弦波动
if cls == 3:
X[i, :, 5] += 0.8
mid = np.random.randint(seq_len//2-4, seq_len//2+4)
X[i, mid, 5] += 1.5
osc = 0.3 * np.sin(np.linspace(0, 6*np.pi, seq_len))
X[i, :, 6] += osc
# 对通道做随机置换增加难度
perm = np.arange(feat_dim)
np.random.shuffle(perm)
X = X[:, :, perm]
# 增加轻微随机噪声(提升泛化性)
X += np.random.randn(*X.shape) * 0.05
return X.astype(np.float32), y
# 数据增强:序列时间轴轻微偏移
def augment_sequence(x):
"""对序列做随机时间轴偏移(-2~+2步),增强鲁棒性"""
shift = np.random.randint(-2, 3)
if shift == 0:
return x
elif shift > 0:
return np.pad(x[shift:], ((0, shift), (0, 0)), mode='edge')
else:
return np.pad(x[:shift], ((-shift, 0), (0, 0)), mode='edge')
# 生成训练/验证/测试集
num_classes = 4
train_X, train_y = generate_sequence(num_samples=2400, seq_len=50, feat_dim=8, num_classes=num_classes)
val_X, val_y = generate_sequence(num_samples=600, seq_len=50, feat_dim=8, num_classes=num_classes)
test_X, test_y = generate_sequence(num_samples=600, seq_len=50, feat_dim=8, num_classes=num_classes)
# 转换为Tensor并创建DataLoader
train_ds = TensorDataset(torch.tensor(train_X), torch.tensor(train_y))
val_ds = TensorDataset(torch.tensor(val_X), torch.tensor(val_y))
test_ds = TensorDataset(torch.tensor(test_X), torch.tensor(test_y))
train_loader = DataLoader(train_ds, batch_size=64, shuffle=True, drop_last=True)
val_loader = DataLoader(val_ds, batch_size=128, shuffle=False)
test_loader = DataLoader(test_ds, batch_size=128, shuffle=False)
class CNNBiLSTM(nn.Module):
def __init__(self, input_dim=8, cnn_channels=[64, 128], kernel_size=5, lstm_hidden=64,
num_classes=4, dropout=0.3, lstm_dropout=0.2):
super().__init__()
# 定义LSTM层数(修复NameError的核心)
lstm_num_layers = 1
# Conv1d 输入维度:(N, C_in, L)
self.conv_block = nn.Sequential(
nn.Conv1d(in_channels=input_dim, out_channels=cnn_channels[0],
kernel_size=kernel_size, padding=kernel_size//2),
nn.BatchNorm1d(cnn_channels[0]),
nn.ReLU(),
nn.Dropout(dropout),
nn.MaxPool1d(kernel_size=2, stride=1), # 增加池化,降低序列长度
nn.Conv1d(in_channels=cnn_channels[0], out_channels=cnn_channels[1],
kernel_size=kernel_size, padding=kernel_size//2),
nn.BatchNorm1d(cnn_channels[1]),
nn.ReLU(),
nn.Dropout(dropout)
)
# BiLSTM 输入维度=最后一层 CNN 的通道数(修复dropout判断的变量)
self.lstm = nn.LSTM(
input_size=cnn_channels[-1],
hidden_size=lstm_hidden,
batch_first=True,
bidirectional=True,
num_layers=lstm_num_layers, # 使用提前定义的变量
dropout=lstm_dropout if lstm_num_layers>1 else 0 # 修复:用定义好的lstm_num_layers
)
# 分类层:改用全局平均池化(更鲁棒,避免仅依赖最后时间步)
self.fc = nn.Sequential(
nn.Linear(2*lstm_hidden, 128),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(128, num_classes)
)
def forward(self, x):
# 输入 x: (N, T, D) → 转成 (N, D, T) 适配Conv1d
x = x.transpose(1, 2)
z = self.conv_block(x) # (N, C, T)
# 转回 (N, T, C) 适配LSTM
z = z.transpose(1, 2)
out, (hn, cn) = self.lstm(z) # out: (N, T, 2h)
# 全局平均池化(替代仅取最后时间步,提升泛化性)
agg = torch.mean(out, dim=1) # (N, 2h)
logits = self.fc(agg)
return logits, agg # 返回特征用于 t-SNE 可视化
# 初始化模型(现在无变量未定义错误)
model = CNNBiLSTM(
input_dim=8,
cnn_channels=[64, 128],
kernel_size=5,
lstm_hidden=64,
num_classes=num_classes,
dropout=0.3 # 增加dropout率
).to(device)
# 评估函数
def evaluate(model, loader):
model.eval()
all_logits = []
all_labels = []
with torch.no_grad():
for xb, yb in loader:
xb, yb = xb.to(device), yb.to(device)
logits, _ = model(xb)
all_logits.append(logits.cpu().numpy())
all_labels.append(yb.cpu().numpy())
logits = np.concatenate(all_logits, axis=0)
labels = np.concatenate(all_labels, axis=0)
preds = logits.argmax(axis=1)
acc = accuracy_score(labels, preds)
loss = nn.CrossEntropyLoss()(torch.tensor(logits), torch.tensor(labels)).item()
return loss, acc, logits, labels
# 优化器与学习率调度器(核心:增加学习率衰减)
optimizer = optim.Adam(model.parameters(), lr=1e-3, weight_decay=5e-4) # 增加权重衰减
criterion = nn.CrossEntropyLoss()
scheduler = ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=3, verbose=True)
history = {"train_loss": [], "val_loss": [], "train_acc": [], "val_acc": []}
best_val_acc = 0.0
patience = 5 # 早停耐心值
patience_counter = 0
# 模型训练(增加数据增强+梯度裁剪+早停)
epochs = 25
for epoch in range(1, epochs+1):
model.train()
total_loss = 0.0
total_correct = 0
total_count = 0
for xb, yb in train_loader:
xb, yb = xb.to(device), yb.to(device)
# 训练时数据增强:随机时间轴偏移
if np.random.rand() > 0.2: # 80%概率增强
xb = torch.stack([torch.tensor(augment_sequence(x.cpu().numpy())) for x in xb]).to(device)
optimizer.zero_grad()
logits, _ = model(xb)
loss = criterion(logits, yb)
loss.backward()
# 梯度裁剪(防止梯度爆炸)
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
total_loss += loss.item() * xb.size(0)
preds = logits.argmax(dim=1)
total_correct += (preds == yb).sum().item()
total_count += xb.size(0)
train_loss = total_loss / total_count
train_acc = total_correct / total_count
# 验证集评估
val_loss, val_acc, _, _ = evaluate(model, val_loader)
# 学习率调度
scheduler.step(val_loss)
# 早停逻辑
if val_acc > best_val_acc:
best_val_acc = val_acc
patience_counter = 0
torch.save(model.state_dict(), "best_cnn_bilstm.pth") # 保存最优模型
else:
patience_counter += 1
if patience_counter >= patience:
print(f"早停触发!Epoch: {epoch}, 最佳验证准确率: {best_val_acc:.4f}")
break
history["train_loss"].append(train_loss)
history["train_acc"].append(train_acc)
history["val_loss"].append(val_loss)
history["val_acc"].append(val_acc)
print(f"Epoch {epoch:02d}: train_loss={train_loss:.4f} train_acc={train_acc:.4f} "
f"val_loss={val_loss:.4f} val_acc={val_acc:.4f}")
# 加载最优模型评估测试集
model.load_state_dict(torch.load("best_cnn_bilstm.pth"))
test_loss, test_acc, test_logits, test_labels = evaluate(model, test_loader)
print(f"\n[Test] loss={test_loss:.4f} acc={test_acc:.4f}")
# 提取测试特征用于 t-SNE
model.eval()
test_features = []
test_preds = []
with torch.no_grad():
for xb, yb in test_loader:
logits, feats = model(xb.to(device))
test_features.append(feats.cpu().numpy())
test_preds.append(logits.argmax(dim=1).cpu().numpy())
test_features = np.concatenate(test_features, axis=0)
test_preds = np.concatenate(test_preds, axis=0)
# 多分类 ROC(One-vs-Rest)
y_true_onehot = np.eye(num_classes)[test_labels]
y_score = test_logits
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(num_classes):
fpr[i], tpr[i], _ = roc_curve(y_true_onehot[:, i], y_score[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# 混淆矩阵
cm = confusion_matrix(test_labels, test_logits.argmax(axis=1))
# t-SNE 降维(sklearn 1.7.1兼容:用max_iter)
tsne = TSNE(
n_components=2,
random_state=42,
perplexity=30,
max_iter=800 # sklearn 1.7.1支持的参数
)
X_tsne = tsne.fit_transform(test_features)
# 可视化分析
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文显示
plt.rcParams['axes.unicode_minus'] = False
# 1) 训练 & 验证曲线(双坐标轴)
plt.figure(figsize=(10, 6))
plt.title("训练/验证曲线", fontsize=16)
epochs_range = np.arange(1, len(history["train_loss"])+1)
color_loss_train = '#ff00ff'
color_loss_val = '#ff7f0e'
color_acc_train = '#17becf'
color_acc_val = '#2ca02c'
ax1 = plt.gca()
lns1 = ax1.plot(epochs_range, history["train_loss"], color=color_loss_train, linewidth=2.5, label='训练损失')
lns2 = ax1.plot(epochs_range, history["val_loss"], color=color_loss_val, linewidth=2.5, linestyle='--', label='验证损失')
ax1.set_xlabel('Epoch')
ax1.set_ylabel('Loss')
ax1.grid(True, alpha=0.3)
ax1b = ax1.twinx()
lns3 = ax1b.plot(epochs_range, history["train_acc"], color=color_acc_train, linewidth=2.5, label='训练准确率')
lns4 = ax1b.plot(epochs_range, history["val_acc"], color=color_acc_val, linewidth=2.5, linestyle='--', label='验证准确率')
ax1b.set_ylabel('Accuracy')
lns = lns1 + lns2 + lns3 + lns4
labels = [l.get_label() for l in lns]
ax1.legend(lns, labels, loc='lower right', fontsize=10)
plt.tight_layout()
plt.show()
# 2) 混淆矩阵
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='magma', cbar=True, square=True)
plt.xlabel('预测类别')
plt.ylabel('真实类别')
plt.title(f'混淆矩阵 (测试准确率={test_acc:.2f})')
plt.tight_layout()
plt.show()
# 3) 多分类 ROC 曲线
plt.figure(figsize=(10, 7))
colors = ['#e41a1c', '#377eb8', '#4daf4a', '#984ea3']
for i in range(num_classes):
plt.plot(fpr[i], tpr[i], color=colors[i], linewidth=2.5, label=f'类别 {i} (AUC={roc_auc[i]:.2f})')
plt.plot([0, 1], [0, 1], color='#7f7f7f', linestyle='--', linewidth=1.5, label='随机水平')
plt.xlabel('假阳性率 (FPR)')
plt.ylabel('真阳性率 (TPR)')
plt.title('多分类 ROC 曲线')
plt.grid(True, alpha=0.3)
plt.legend(loc='lower right', fontsize=10)
plt.tight_layout()
plt.show()
# 4) t-SNE 特征可视化
plt.figure(figsize=(10, 7))
markers = ['o', '^', 's', '*']
palette = ['#fb9a99', '#1f78b4', '#33a02c', '#fdbf6f']
for cls in range(num_classes):
idx = np.where(test_labels == cls)[0]
plt.scatter(X_tsne[idx, 0], X_tsne[idx, 1], s=35, marker=markers[cls], c=palette[cls],
edgecolor='k', linewidth=0.5, alpha=0.85, label=f'类别 {cls}')
plt.title('CNN+BiLSTM 全局平均池化特征的 t-SNE')
plt.xlabel('维度 1')
plt.ylabel('维度 2')
plt.grid(True, alpha=0.3)
plt.legend(loc='best', fontsize=10)
plt.tight_layout()
plt.show()训练/验证损失与准确率:
模型的收敛趋势与是否过拟合。左 Y 轴是损失,右 Y 轴是准确率。实线为训练、虚线为验证。
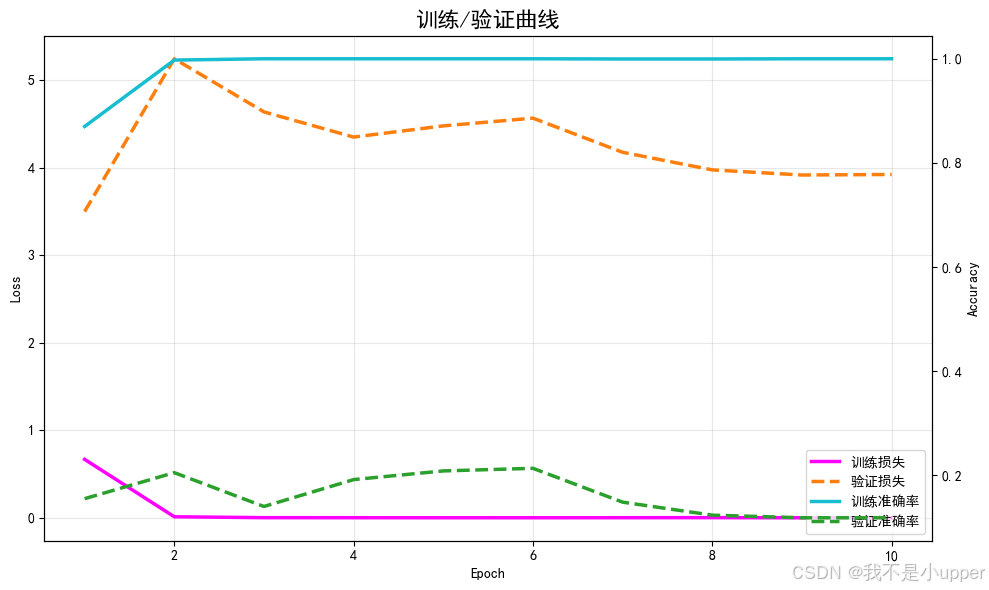
从图中,咱们可以判断,模型是否在稳定收敛?若训练损失持续下降,验证损失也下降,说明学习有效。
是否出现过拟合?若训练准确率持续上升,但验证准确率不升反降,说明过拟合,需加大正则化或减少复杂度。
是否需要调节学习率?若震荡明显或收敛缓慢,可能需要调参。该图能直观指导后续的超参数选择。
混淆矩阵:
不同类别之间的预测混淆情况及类间易混淆对。鲜艳的 magma colormap 让高值区域突显。
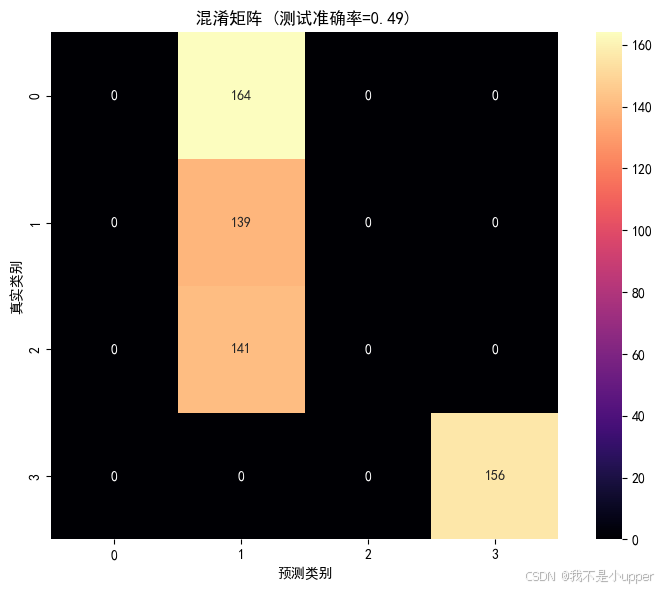
从图中,咱们可以判断,哪些类别被误判最多?有无特定类别(如类 1 或类 3)的混淆容易发生?
混淆是否体现我们设计的局部模式或长程规则相似性?例如类 0 的上升局部模式 与类 2 的下降模式是否在边缘段容易混淆?
是否需要针对某类数据增强或改进特征抽取?
多类别 ROC 曲线:
从阈值无关的角度衡量分类器质量,展示各类别的一对多 ROC 曲线和 AUC。
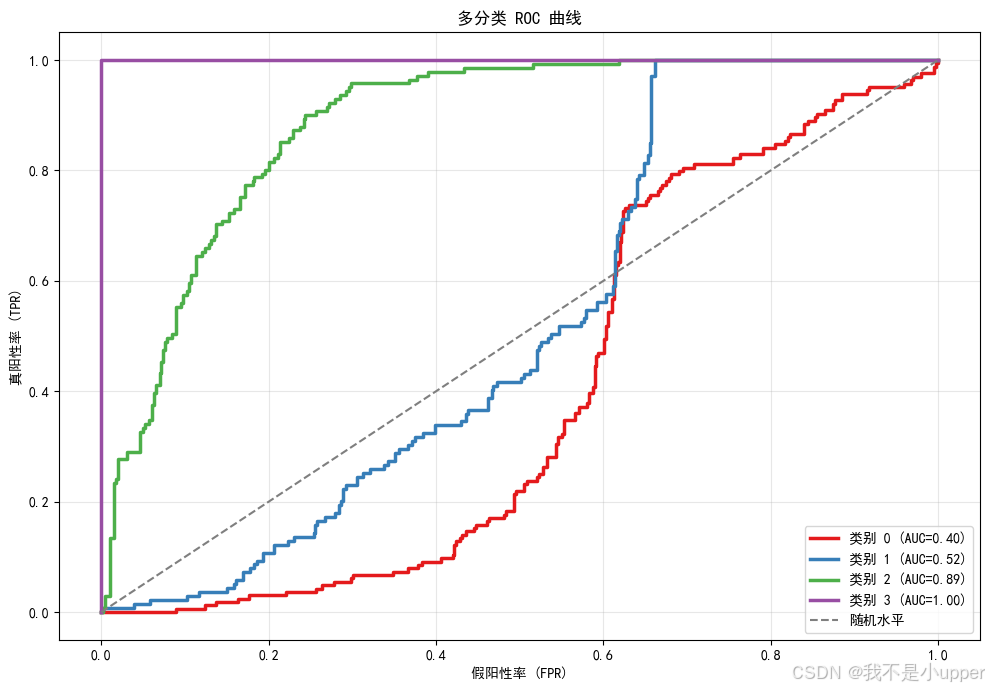
从图中,咱们可以判断,哪个类别最容易被正确区分(AUC 高)?哪个类别较难(AUC 低)?
是否需要使用类别不平衡策略或阈值调优?可根据曲线形状选择更合适的决策阈值或损失加权。
对于实际生产,如果某类误检成本高,可通过 ROC 分析进行阈值移动,使召回与精度的权衡更合理。
t-SNE 特征嵌入:
可视化 BiLSTM 汇聚后的高维特征(最后时刻),观察类间分布是否分离。不同颜色+形状的点代表不同类别,便于区分。
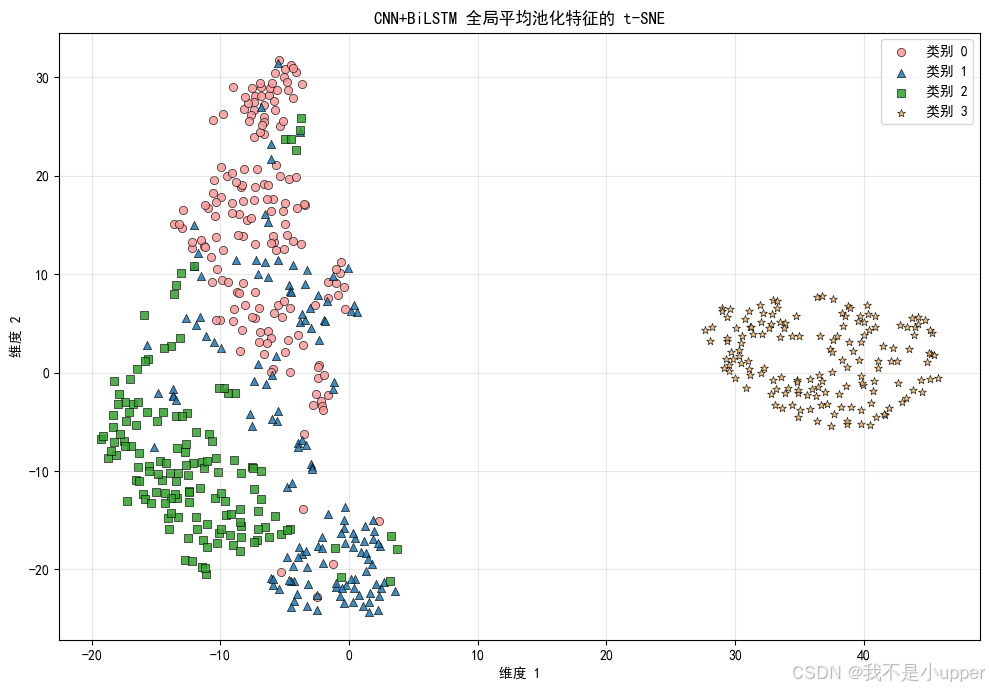
从图中,咱们可以判断,CNN+BiLSTM 是否学到可分离的特征空间?若类簇明显分离,说明表示学习有效。
哪些类别簇有重叠?这可提示需要加入注意力机制或改进卷积核设计以加强区分。
是否存在异常点(离群点)?可能是样本噪声或模型未学到该类的关键特征。
总体结论:CNN+BiLSTM 的组合通过卷积先验 + 序列记忆的方式,在需要同时识别局部模式与长程依赖的多数序列任务上具有优势,体现为更好地学习到稳健的可分特征、更高的泛化性能以及更实用的诊断信号。
大家,如果在实际的情形下,进一步的优化方向包括:
-
引入注意力池化或自注意力模块增强长程交互;
-
使用空洞卷积扩展感受野、提高多尺度建模能力;
-
对于类不平衡任务引入 Focal Loss 或类权重;
大家如果有问题,评论区留言~
如果对大家有所帮助,记得点赞或者转发~