在数据工程中,"数据同步"一直是最让人心累的工作之一:表多、脚本复杂、流程繁琐、不透明、不稳定......
本次 qData 数据中台商业版的大更新,正是为了解决这些长期困扰一线工程师的痛点。
通过 整库同步、自动建表、调度执行、链路可视化、全面监控、可配置容错 等能力,qData 将传统的脚本化同步流程升级为可视化、可管理、可追踪的稳定链路,使数据同步真正做到------更快、更稳、更省心。

一、行业真实痛点:为什么数据同步总是如此折磨人?
在大量用户反馈和实地调研中,我们发现大家普遍面临着这些问题:
-
1. 表数量庞大,一个个配置耗时耗力
几十、上百张表手动同步?工作量指数级增长。
-
2. 全靠写脚本,复杂且容易出错
写一次像做一份大作业,脚本风格不统一,维护困难。
-
3. 表结构变化频繁,脚本需要不断修改
稍有疏忽,同步失败,链路中断。
-
4. 目标库没有表,还要手动建表
字段多得像"下雨",新建过程非常费时。
-
5. 同步过程不可见,定位问题困难
进度靠猜、日志靠翻,出了问题不知卡在哪一步。
-
6. 定时同步靠手动管理
忘记一次,就可能造成严重数据滞后。
-
7. 脏数据导致任务直接中断
整个任务失败,又得从头来过。
这些痛点并非个案,而是数据同步领域普遍存在的"顽疾"。
二、构建标准化、可视化、自动化的数据同步能力
基于以上痛点,本次更新的核心目标是------
让数据同步从"写脚本"升级为"点选式、流程化、可视化"的专业链路。
qData 商业版在本次更新中带来了 9 大关键能力,让整库同步变得前所未有的简单:
1. 整库同步:一键同步上百张表
- 支持整库同步(如 Oracle → Doris、SQLServer → Doris)
- 支持多表手动选择
极大降低重复操作成本。
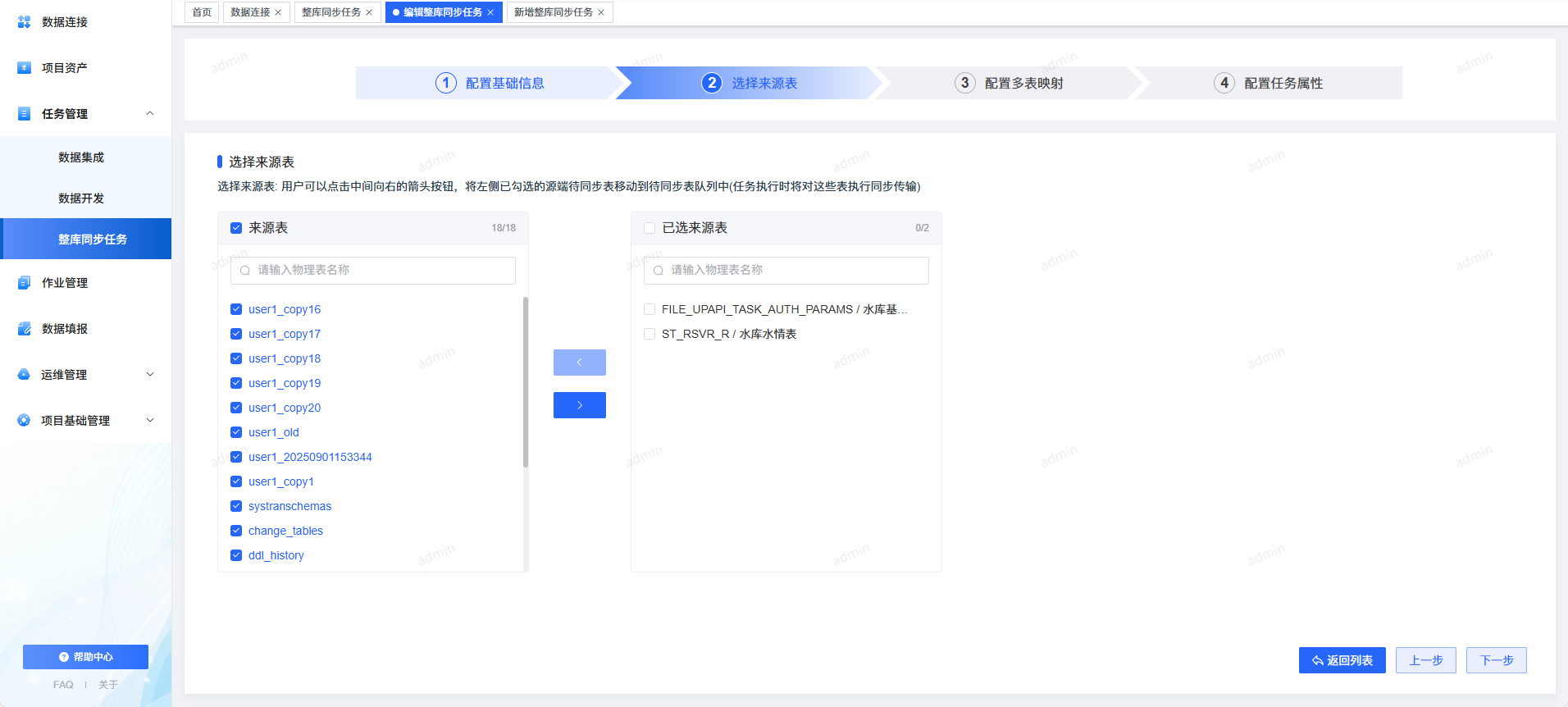
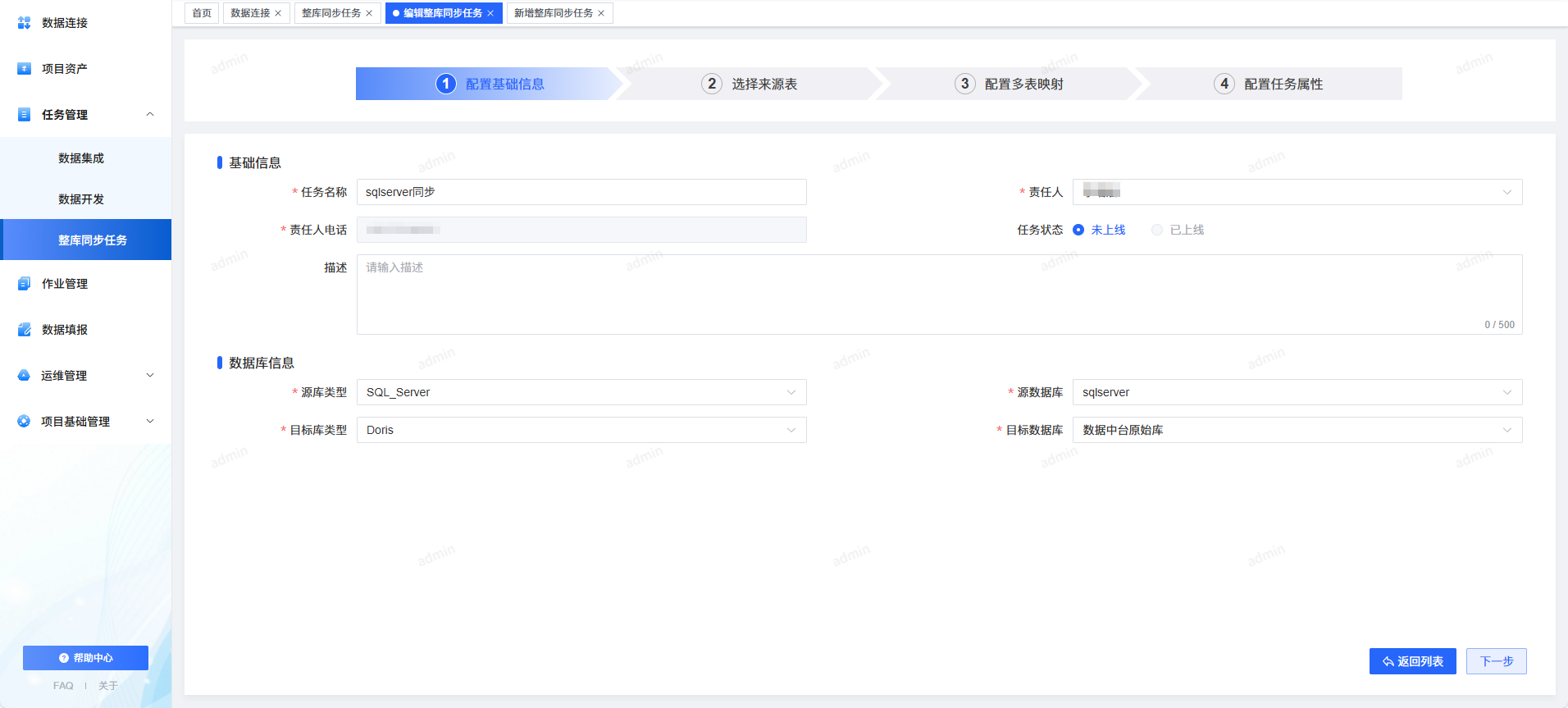
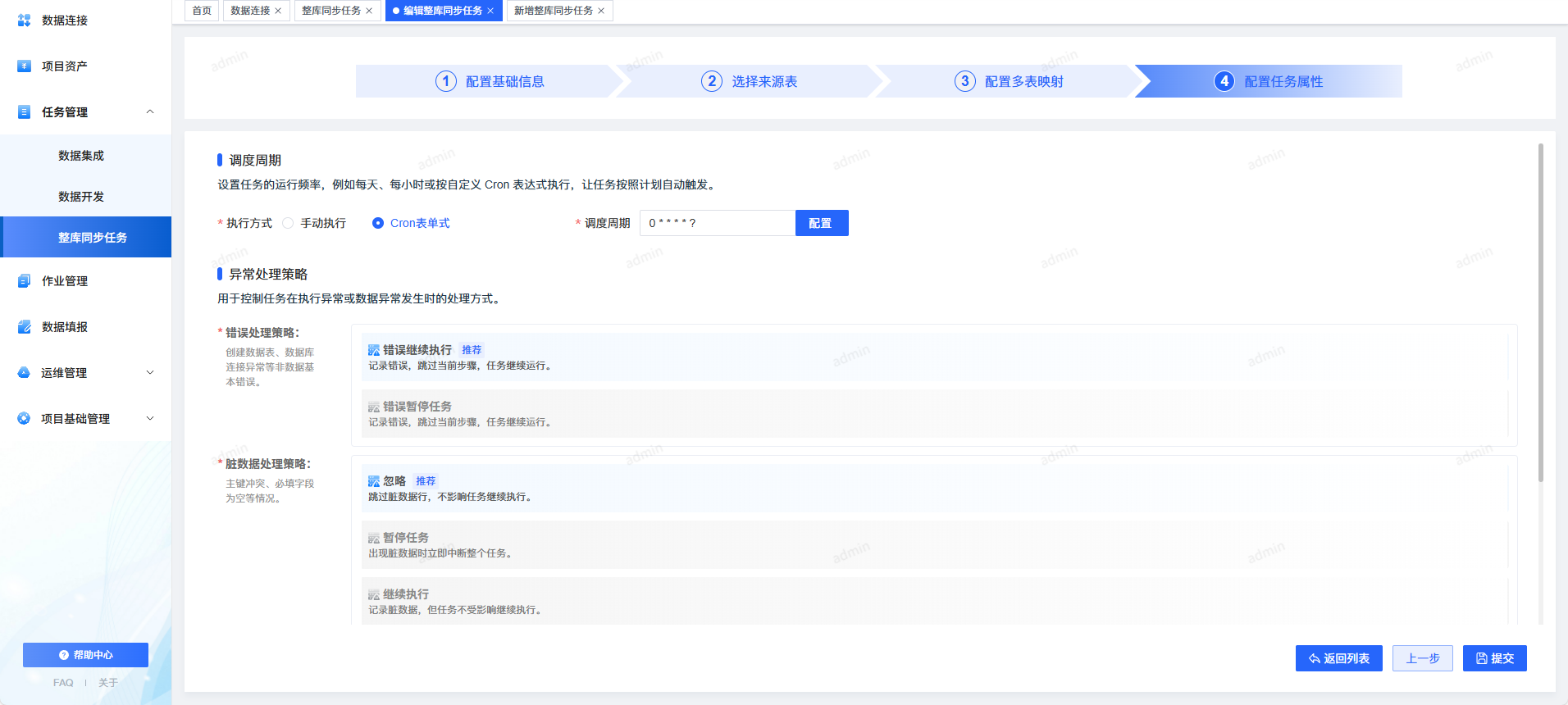
2. 标准化四步流程,团队协作更规范
同步任务配置统一分为 4 步:
- 基本信息
- 输入配置
- 输出配置
- 调度配置
新手也能在一分钟内学会。
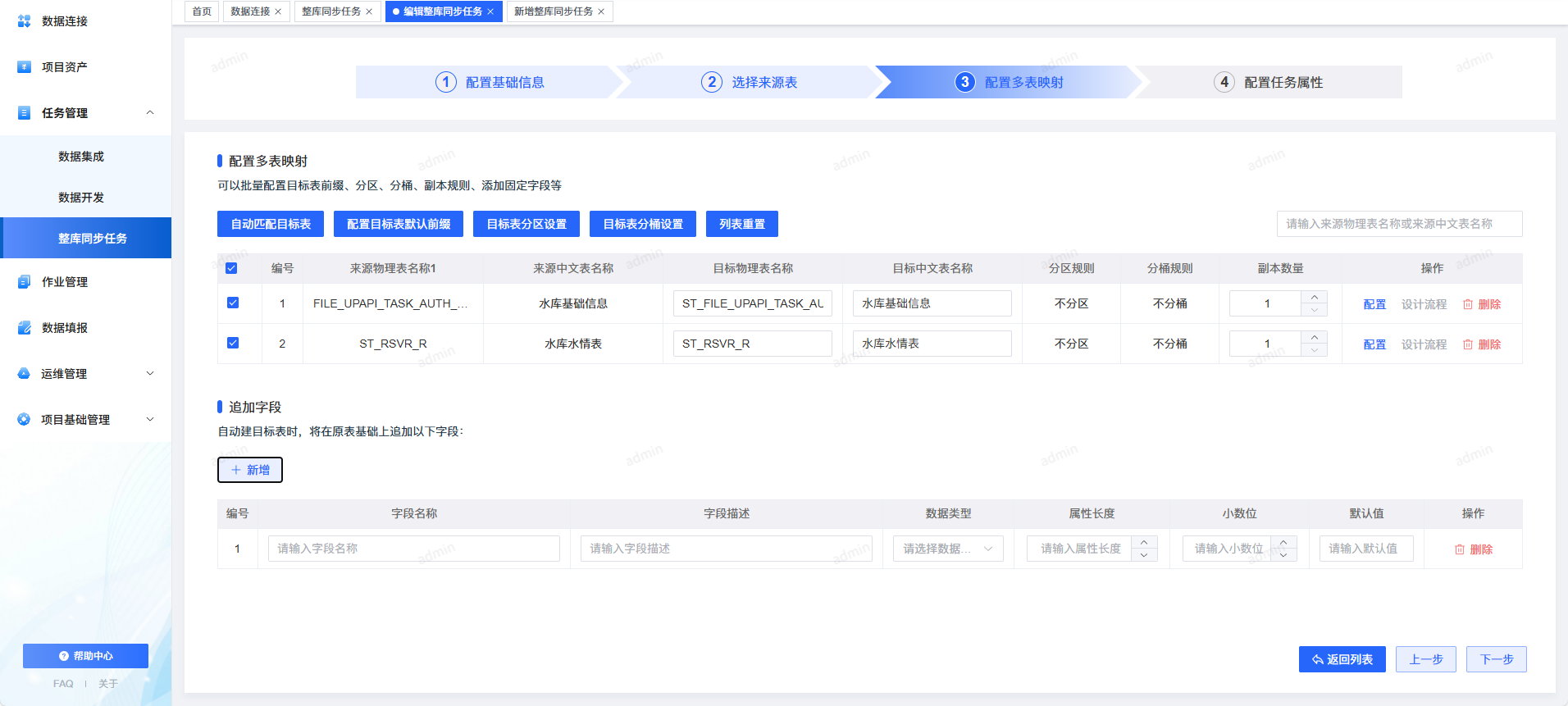
3. 自动建表:再多字段也不怕了
目标库没有表?不用自己建。
系统可自动创建:
- 分区策略
- 副本策略
- 分桶策略
并可统一追加字段,如:
_qdata_sync_time_qdata_sync_batch_id
保证所有表的结构一致、字段齐全、扩展方便。
4. 引擎可选:Spark / Flink 灵活匹配场景
不同任务规模、实时性需求不同:
- Spark:适合大批量批处理
- Flink:适合流式或高实时场景
你可根据资源情况自由选择。
5. 全面的容错与脏数据策略
支持同步任务错误策略:
- 错误继续
- 错误暂停
支持脏数据策略(MVP 已上线配置界面):
- 忽略
- 暂停
- 继续
- 写入脏数据表(完善中)
让同步不再"一条脏数据全任务崩溃"。
6. 支持立即执行与定时执行
告别手动跑脚本:
- Cron 调度
- 周期任务
- 立即执行
让同步从"记得执行"变成"自动准时执行"。
7. 可视化执行监控:进度、耗时、行数一目了然
你可以实时查看:
- 任务整体进度
- 已同步行数
- 各阶段耗时
- 执行状态变化
- 错误节点信息
不用再翻一大堆日志。
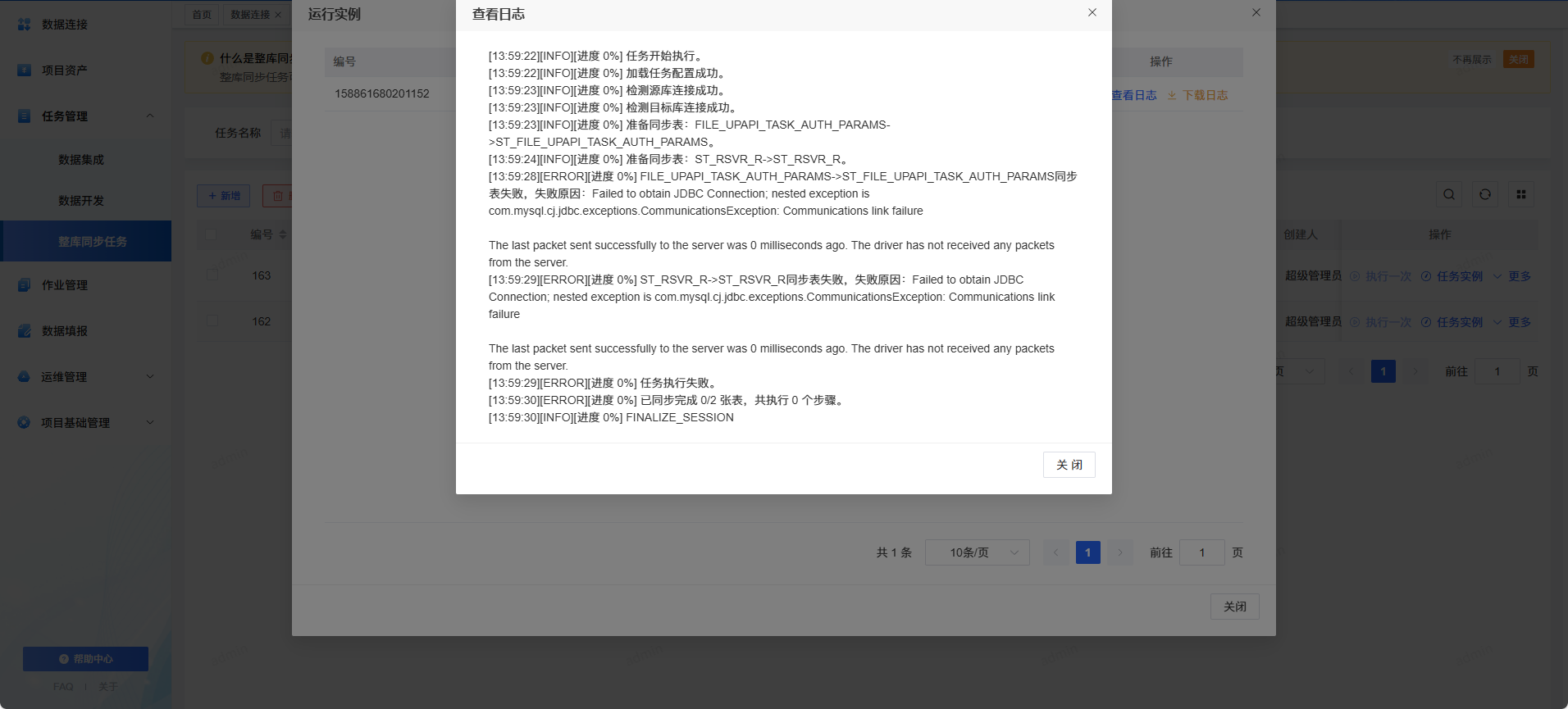
8. 同步链路可视化:快速定位问题
系统自动绘制链路拓扑:
源 → 映射 → Doris 写入 → 指标 & 日志
卡在哪一步,一眼就看到,排查问题效率大幅提升。
9. 极致简单的操作体验:人人都能用
没有复杂的脚本、没有难懂的参数、没有大量重复劳动。
四步流程 + 可视化界面
使同步任务更轻松、更可控。
四、核心价值:qData 帮你把同步从"工作量"变成"管理量"
-
1. 降低人力成本,减少重复劳动
批量同步几百张表只需几分钟。
-
2. 降低错误率,提高稳定性
自动建表、可视化链路、监控面板,让错误更少、定位更快。
-
3. 消除脚本不统一带来的风险
不同人做同步,结果都是一致的。
-
4. 透明化的执行过程,方便审计与管理
执行、日志、链路全部可见,团队协同更高效。
-
5. 让同步管理从"靠人"变成"靠平台"
不再依赖某个熟悉脚本的人,任何人都能执行标准化同步。
五、结语:同步不再难,qData 让数据流动变得更简单
随着数字化项目规模越来越大,数据同步任务的复杂度也在提升。
qData 数据中台商业版本次整库同步能力的升级,是为了帮助企业从传统的脚本式操作中走出来,实现真正的自动化、可视化和平台化的数据同步。
从此,数据同步不再是工程师的负担,而是系统的能力。
如果你正在经历类似的同步痛点,这次更新一定值得你尝试。