DALLE系列论文概述
DALLE系列是OpenAI推出的基于生成对抗网络(GAN)和Transformer架构的多模态模型,专注于文本到图像的生成任务。核心论文包括DALL·E(2021)、DALL·E 2(2022)和后续改进版本。
DALL-E 并不是基于扩散模型的方法,但是因为它的后续工作 DALL-E 2 和 DALL-E 3 都是基于扩散模型的,所以这个方法也放到扩散模型系列里。
DALL·E(2021)
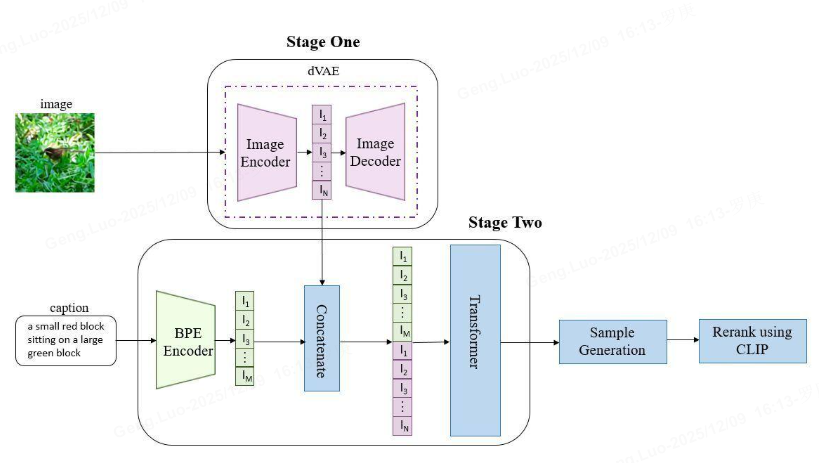
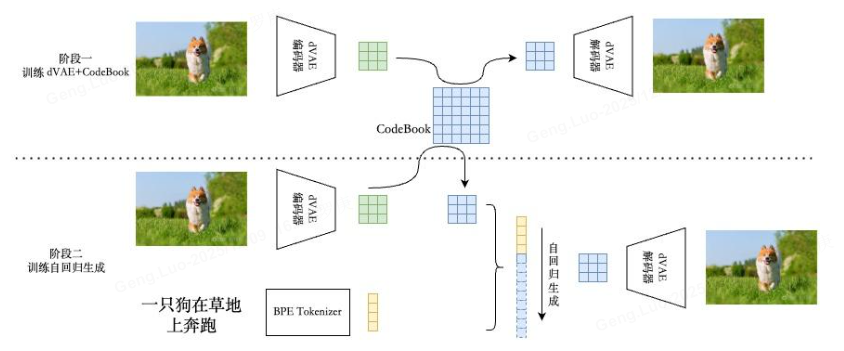
第一个阶段 ,先训练一个dVAE把每张 256x256 的 RGB 图片压缩成 32x32 的图片token,每个位置有 8192 种可能的取值(也就是说dVAE的encoder输出是维度为32x32x8192的logits,然后通过logits索引codebook的特征进行组合,codebook的embedding是可学习的)
第二阶段 ,用BPE Encoder对文本进行编码,得到最多 256 个文本token,token 数不满256的话 padding 到256,然后将256个文本token与1024个图像token进行拼接,得到长度为1280的数据,最后将拼接的数据输入 Transformer 中进行自回归训练,典型的 teacher forcing 的方式,滑窗式样生成
第三训练阶段 ,先训练dVAE模型,然后固定dVAE模型再来训练自回归的 Transformer
**第四推理阶段:**给定文本,将其 BPE 编码为 256 个文本 token,在后面预测图片 token 即可。在图片的自回归生成中,codebook 就相当于自然语言中的词表。所谓生成,就是预测下一个 token 的索引。预测出每一个 token 之后,将其 reshape 为特征图,送入 dVAE decoder 中生成出真实像素图片。这就完成了一次推理生图。
核心思想
结合离散VAE(dVAE)和Transformer架构,将图像生成任务转化为序列建模问题。文本和图像通过共享的隐空间对齐,实现文本到图像的生成。
技术要点
- dVAE编码器:将图像压缩为离散token序列(类似VQ-VAE)。
- 自回归Transformer:基于文本和图像token的联合分布进行序列预测。
- 两阶段训练 :
- 训练dVAE编码图像为token。
- 训练Transformer建模文本和图像token的联合概率。
公式表示
图像生成概率建模为条件自回归过程:
P(ximage∣xtext)=∏iP(xi∣x<i,xtext) P(x_{\text{image}} | x_{\text{text}}) = \prod_{i} P(x_i | x_{<i}, x_{\text{text}}) P(ximage∣xtext)=i∏P(xi∣x<i,xtext)
其中ximagex_{\text{image}}ximage为图像token序列,xtextx_{\text{text}}xtext为文本token序列。
DALL·E 2(2022)
2020 年从 DDPM 开始,扩散模型在图像生成领域大放异彩。DALL-E 2 就使用了扩散模型,方法与 OpenAI 之前另一篇扩散模型的工作 GLIDE 非常相似。在此基础上,为了实现更好的文本引导,OpenAI 还结合了自家提出的 CLIP 模型。
改进方向
引入层级式生成和CLIP引导,提升生成质量和多样性。
CLIP 可以实现 zeroshot 的图文检索,比如由图片检索文本。而 DALL-E 2 刚好是倒过来,由文本生成图片,所以原文中将 DALL-E 2 称为 unCLIP。
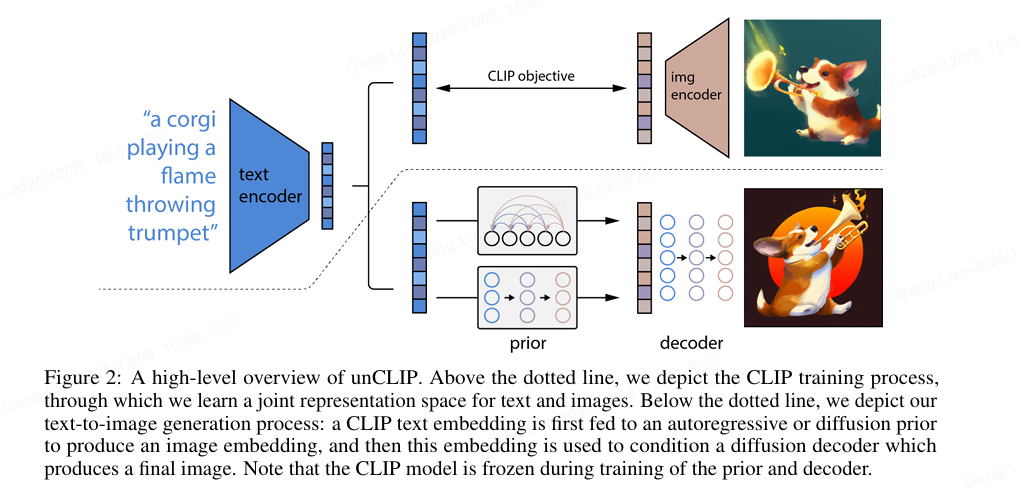
DALL-E 2(unCLIP)共有三部分组成,分别是预训练的 CLIP 模型,prior 模型和 decoder 模型 。从上图 unCLIP 的采样过程可以看出他们各自的作用,CLIP 的文本编码器负责提取文本特征,prior 模型将文本特征转换为图片特征,解码器 decoder 则根据图片特征生成图片。
CLIP 模型不仅在 DALL-E 2 的推理生图过程中负责理解文本条件,在训练过程中它也非常重要。训练时,其参数固定,为 decoder 和 prior 的训练提供输入和监督信号。需要训练的 decoder 和 prior 分别是以 CLIP 的图像和文本特征作为输入,其中 prior 的训练还需要 CLIP 的图像特征作为监督信号,decoder 的训练则是以输入原图作为监督信号。
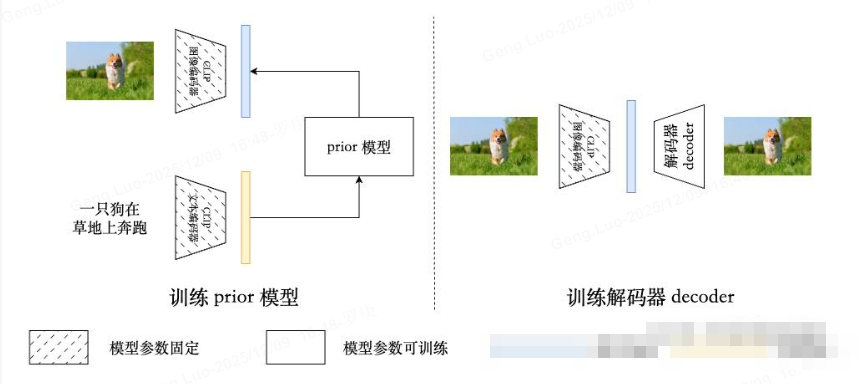
prior 模型 负责的是将 CLIP 文本特征转换为 CLIP 图像特征。既然 CLIP 图片文本特征是对齐的,为什么不直接拿文本特征去生图,而是还要一步转换为图像特征呢?虽然经过 CLIP 对比学习的训练,图像特征和文本特征得到了一定的对齐,但是毕竟还是不同模态的特征来自两个不同的模型,还是有 modality gap 的存在。熟悉 CLIP 的读者也会知道,CLIP 的图文特征相似度的绝对值很小,即使是正样本,其相似度一般也在 0.5 以下,与孪生网络类的同模态特征相似度正样本特征接近 1 相比,modality gap 非常明显。
DALL-E 2 最终选择了扩散模型来作为 prior。
关键技术
- 层级生成 :
- 先验模型:基于CLIP文本嵌入生成图像嵌入(扩散模型或自回归模型)。
- 解码器:将图像嵌入解码为高分辨率图像(扩散模型)。
- CLIP引导:利用预训练的CLIP模型对齐文本和图像语义,增强生成内容的相关性。
扩散模型公式
图像生成通过逐步去噪实现:
pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t)) p_\theta(x_{t-1}|x_t) = \mathcal{N}(x_{t-1}; \mu_\theta(x_t,t), \Sigma_\theta(x_t,t)) pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))
其中(x_t)为第(t)步噪声图像,(\mu_\theta)和(\Sigma_\theta)为模型预测的均值和方差。


后续演进
DALL·E 3没有开源,通过在高度描述性的生成图像标题上进行训练,可以显著提高文本到图像模型的提示遵循能力。现有的文本到图像模型在遵循详细图像描述方面存在困难,往往忽略某些词语或混淆提示的含义。假设这一问题源于训练数据集中图像标题的噪声和不准确性。为了解决这个问题,作者训练了一个定制的图像标题生成器,并使用它为训练数据集重新生成标题。然后,我们训练了几个文本到图像模型,发现使用这些合成标题进行训练能够可靠地提升模型的提示遵循能力。最后,作者利用这些发现构建了DALL-E 3:一个新的文本到图像生成系统,并在一个旨在衡量提示遵循性、一致性和美学的评测中对其性能进行基准测试,结果显示其表现优于竞争对手。作者还发布了用于这些评测的样例和代码,以便未来的研究能够继续优化文本到图像系统这一重要方面。
- DALL·E 3(2023)进一步优化文本理解能力,采用更精细的文本编码和更大的模型规模,支持复杂指令生成。
- 与其他模型对比 :DALL·E系列强调文本-图像对齐,而Stable Diffusion等开源模型侧重计算效率。

应用与挑战
- 应用场景:艺术创作、广告设计、教育素材生成。
- 局限性:细节控制不足,可能生成不符合物理规律的图像。
代码示例(PyTorch风格伪代码):
python
# DALL·E 2扩散模型训练步骤
for x_real in dataset:
x_noisy = add_noise(x_real, t) # 加噪声
pred_noise = model(x_noisy, t, text_embedding) # 预测噪声
loss = MSE(pred_noise, true_noise)
optimizer.step(loss)