👨🎓博主简介
💊交流社区: 运维交流社区 欢迎大家的加入!
🐋 希望大家多多支持,我们一起进步!😄
🎉如果文章对你有帮助的话,欢迎 点赞 👍🏻 评论 💬 收藏 ⭐️ 加关注+💗
文章目录
-
- 引言
- 一、时序数据的特点与挑战
-
- [1.1 时序数据的典型特征](#1.1 时序数据的典型特征)
- [1.2 面临的技术挑战](#1.2 面临的技术挑战)
- 二、时序数据库选型维度
- [三、Apache IoTDB 简介](#三、Apache IoTDB 简介)
-
- [3.1 核心特性](#3.1 核心特性)
- [四、IoTDB 技术优势详解](#四、IoTDB 技术优势详解)
-
- [4.1 高性能写入机制](#4.1 高性能写入机制)
-
- [示例代码:Java 写入数据](#示例代码:Java 写入数据)
- [4.2 自研 TsFile 存储格式](#4.2 自研 TsFile 存储格式)
-
- [TsFile 文件结构图(建议插图)](#TsFile 文件结构图(建议插图))
- [4.3 强大的查询能力](#4.3 强大的查询能力)
-
- [示例 SQL 查询](#示例 SQL 查询)
- 聚合查询示例
- [4.4 与大数据生态集成](#4.4 与大数据生态集成)
-
- [示例:Spark 读取 TsFile](#示例:Spark 读取 TsFile)
- 五、与国外产品对比分析
- [六、IoTDB 应用案例](#六、IoTDB 应用案例)
-
- [6.1 国家电网:智能电表数据管理](#6.1 国家电网:智能电表数据管理)
- [6.2 某大型制造企业:设备监控系统](#6.2 某大型制造企业:设备监控系统)
- 七、选型建议与总结
- 附录:资源链接
引言
随着物联网(IoT)、工业4.0、智能制造、车联网等场景的快速发展,时序数据(Time Series Data)成为大数据领域中最重要的一类数据形式。时序数据具有高频写入、顺序存储、时间维度强关联等特点,传统的关系型数据库在应对这类数据时往往力不从心。因此,时序数据库(Time Series Database, TSDB)应运而生,成为大数据架构中的关键组件。
本文将从大数据架构的角度出发,系统性地介绍时序数据库的选型要点,并结合 Apache IoTDB 的设计理念和实际应用案例,分析其在面对海量时序数据时的技术优势,帮助企业在复杂的技术选型中做出明智决策。

下载 IoTDB:https://iotdb.apache.org/zh/Download/
企业版官网:https://timecho.com
一、时序数据的特点与挑战
1.1 时序数据的典型特征
- 高频写入:传感器、设备、日志系统等每秒可产生数万至数百万条数据。
- 数据量大:长期积累下,数据量可达PB级别。
- 时间维度强关联:数据按时间顺序产生,查询通常基于时间范围。
- 写多读少:大部分场景下,数据写入频率远高于读取频率。
- 数据生命周期管理:旧数据需归档、压缩或删除。
1.2 面临的技术挑战
| 挑战 | 描述 |
|---|---|
| 写入性能 | 高频写入对数据库的写入吞吐量提出极高要求 |
| 存储效率 | 时序数据冗余度高,需高效压缩与存储机制 |
| 查询性能 | 时间范围查询、聚合查询需优化索引与存储结构 |
| 水平扩展 | 数据量大,需支持分布式架构 |
| 数据一致性 | 多副本机制下需保证数据一致性与可用性 |
二、时序数据库选型维度
在面对众多时序数据库产品时,企业应从以下几个维度进行系统性评估:
| 维度 | 说明 |
|---|---|
| 性能 | 写入吞吐量、查询延迟、并发能力 |
| 存储 | 压缩率、存储结构、冷热数据分离 |
| 扩展性 | 是否支持分布式部署、横向扩展能力 |
| 兼容性 | 是否支持 SQL、是否兼容现有大数据生态 |
| 易用性 | 部署难度、运维成本、文档与社区支持 |
| 开源/商业 | 是否开源、是否有企业版支持 |
| 安全性 | 权限控制、数据加密、审计能力 |
三、Apache IoTDB 简介
Apache IoTDB 是一款专为物联网场景设计的开源时序数据库,由清华大学发起,现为 Apache 顶级项目。其核心设计目标是高写入性能、低存储成本、强查询能力,特别适合工业传感器、设备监控、能源管理等场景。
3.1 核心特性
- 列式存储 + 时间索引:优化时序数据写入与查询性能
- TsFile 文件格式:自研的列式存储格式,支持高效压缩与快速查询
- 支持 SQL 查询:兼容标准 SQL,降低学习成本
- 边缘-云协同:支持边缘部署与云端同步
- 与大数据生态无缝集成:支持 Hadoop、Spark、Flink、Grafana 等
- 分布式架构:支持多节点部署,自动分片与负载均衡
四、IoTDB 技术优势详解
4.1 高性能写入机制
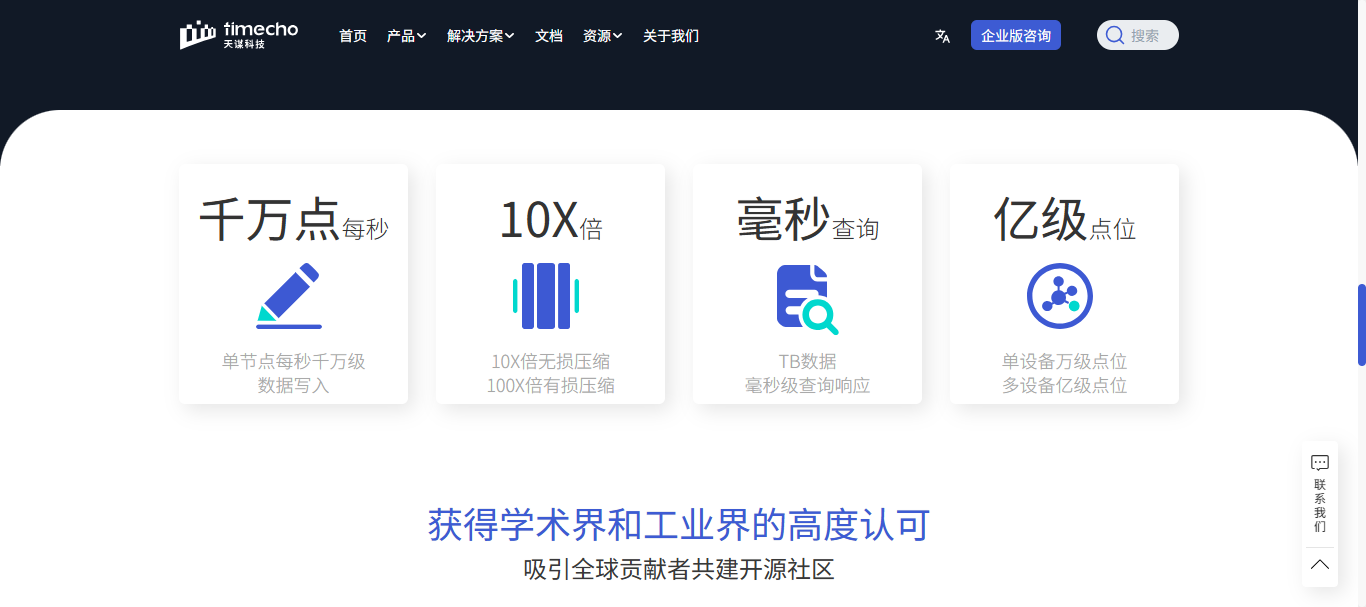
IoTDB 采用列式存储 + 时间索引 结构,支持批量写入与异步刷盘机制,写入性能可达每秒千万级数据点。
示例代码:Java 写入数据
java
Session session = new Session("127.0.0.1", 6667, "root", "root");
session.open();
String deviceId = "root.sg1.d1";
List<String> measurements = Arrays.asList("temperature", "humidity");
List<String> values = Arrays.asList("23.5", "60.0");
long timestamp = System.currentTimeMillis();
session.insertRecord(deviceId, timestamp, measurements, values);
session.close();4.2 自研 TsFile 存储格式
TsFile 是 IoTDB 的核心存储格式,具备以下优势:
- 高压缩比:相比 CSV 格式压缩率提升 10 倍以上
- 快速查询:内置时间索引与统计信息,支持快速范围查询
- 跨平台支持:支持 Java、C++、Python 等多语言读取
TsFile 文件结构图(建议插图)
ts
+------------------+
| TsFile Header |
+------------------+
| Chunk Group 1 |
| - Chunk 1.1 |
| - Chunk 1.2 |
+------------------+
| Chunk Group 2 |
| - Chunk 2.1 |
+------------------+
| Index Metadata |
+------------------+4.3 强大的查询能力
IoTDB 支持标准 SQL 查询,并提供丰富的时间序列函数,如 FIRST, LAST, AVG, COUNT, TIME_WINDOW 等。
示例 SQL 查询
sql
SELECT temperature, humidity
FROM root.sg1.d1
WHERE time > 2025-12-01T00:00:00
AND time < 2025-12-02T00:00:00聚合查询示例
sql
SELECT AVG(temperature)
FROM root.sg1.d1
GROUP BY ([2025-12-01T00:00:00, 2025-12-02T00:00:00), 1h)4.4 与大数据生态集成
IoTDB 提供与 Spark、Flink、Hadoop、Grafana 等系统的连接器,支持:
- Spark SQL 查询 TsFile
- Flink 实时写入 IoTDB
- Grafana 可视化展示
- Hadoop MapReduce 分析
示例:Spark 读取 TsFile
scala
val df = spark.read
.format("org.apache.iotdb.spark.tsfile")
.load("hdfs://localhost:9000/data/test.tsfile")
df.show()五、与国外产品对比分析
| 特性 | IoTDB | InfluxDB | TimescaleDB | OpenTSDB |
|---|---|---|---|---|
| 写入性能 | ★★★★★ | ★★★☆☆ | ★★★☆☆ | ★★☆☆☆ |
| 存储压缩 | ★★★★★ | ★★★☆☆ | ★★☆☆☆ | ★★☆☆☆ |
| SQL 支持 | ✅ 标准 SQL | ✅ Flux 语法 | ✅ PostgreSQL | ❌ |
| 分布式支持 | ✅ | 企业版支持 | ✅ | ✅ |
| 边缘计算 | ✅ | ❌ | ❌ | ❌ |
| 开源协议 | Apache 2.0 | MIT(部分闭源) | Apache 2.0 | Apache 2.0 |
六、IoTDB 应用案例
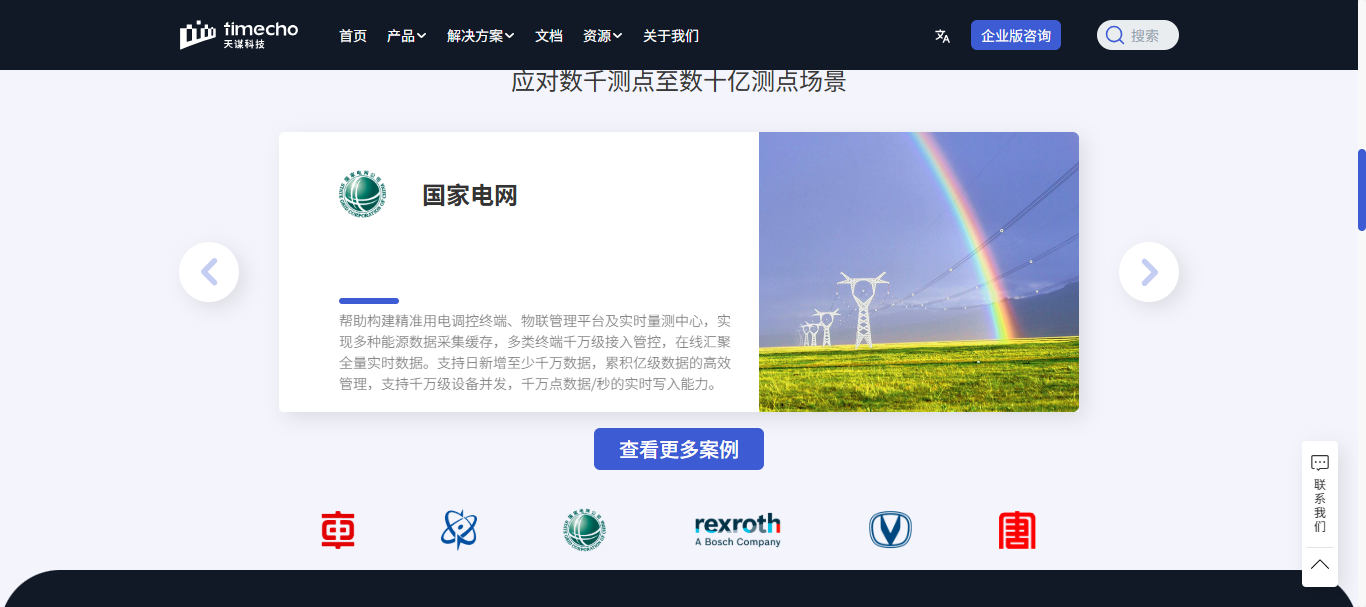
6.1 国家电网:智能电表数据管理
- 数据规模:接入 1 亿+ 电表设备
- 写入频率:每秒 5000 万数据点
- 存储周期:5 年以上
- 成果:存储成本降低 70%,查询响应时间提升 5 倍
6.2 某大型制造企业:设备监控系统
- 场景:机床传感器数据实时监控
- 部署方式:边缘节点 + 云端同步
- 成效:实现毫秒级告警,设备故障率下降 30%

七、选型建议与总结
在面对海量时序数据时,企业应根据自身业务特点,综合考虑性能、扩展性、生态兼容性等因素。Apache IoTDB 凭借其高写入性能、优异压缩率、强大查询能力 和与大数据生态的深度集成,已成为工业物联网、能源、制造等领域的优选方案。
对于希望快速部署、低成本运维、并具备未来扩展潜力的企业,IoTDB 是一个值得优先考虑的开源时序数据库解决方案。
附录:资源链接
- 下载地址(含 Linux/Windows/ARM 与源码) :https://iotdb.apache.org/zh/Download/
- 企业级功能与白皮书 :https://timecho.com
- Docker 快速入门 :https://iotdb.apache.org/zh/UserGuide/latest/Deployment-and-Maintenance/Docker-Deployment_apache.html
- GitHub 仓库 :https://github.com/apache/iotdb