目录
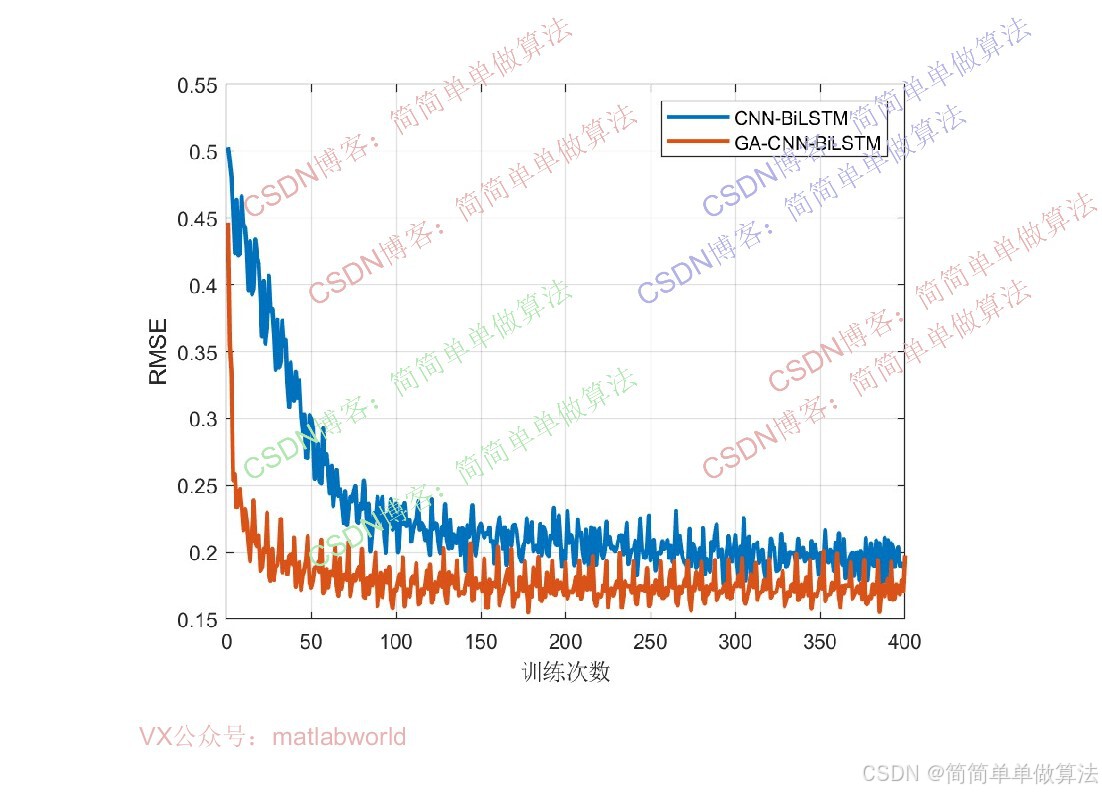
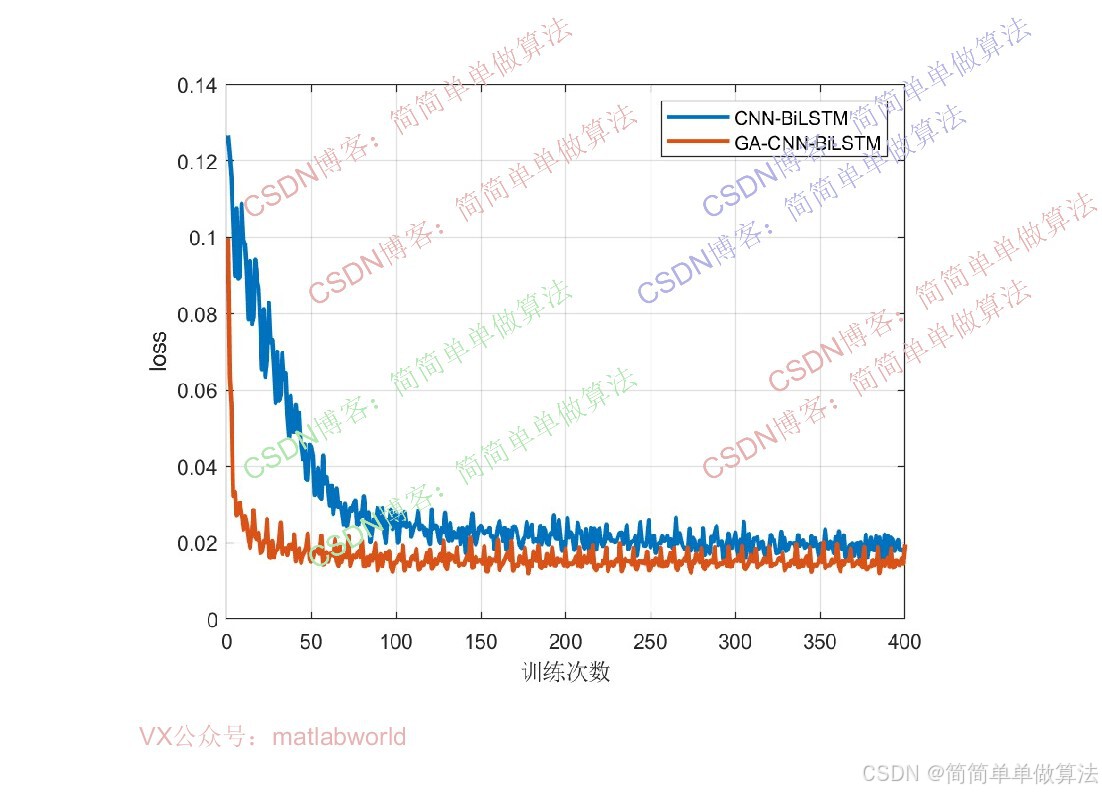
本文提出一种基于遗传算法(GA)优化的CNN-BiLSTM混合神经网络模型,用于多输入单输出回归预测任务。该方法通过GA优化BiLSTM的隐含层节点数和学习率,以模型训练误差作为适应度函数,经过遗传操作筛选最优超参数组合。算法在Matlab2024b环境下实现,包含完整的训练流程和预测功能,通过对比预测数据与真实数据的误差评估模型性能。理论部分详细阐述了GA的编码机制、适应度函数设计以及遗传操作原理。研究结果为深度学习模型超参数优化提供了一种有效解决方案,相关代码可通过指定方式获取。
1.前言
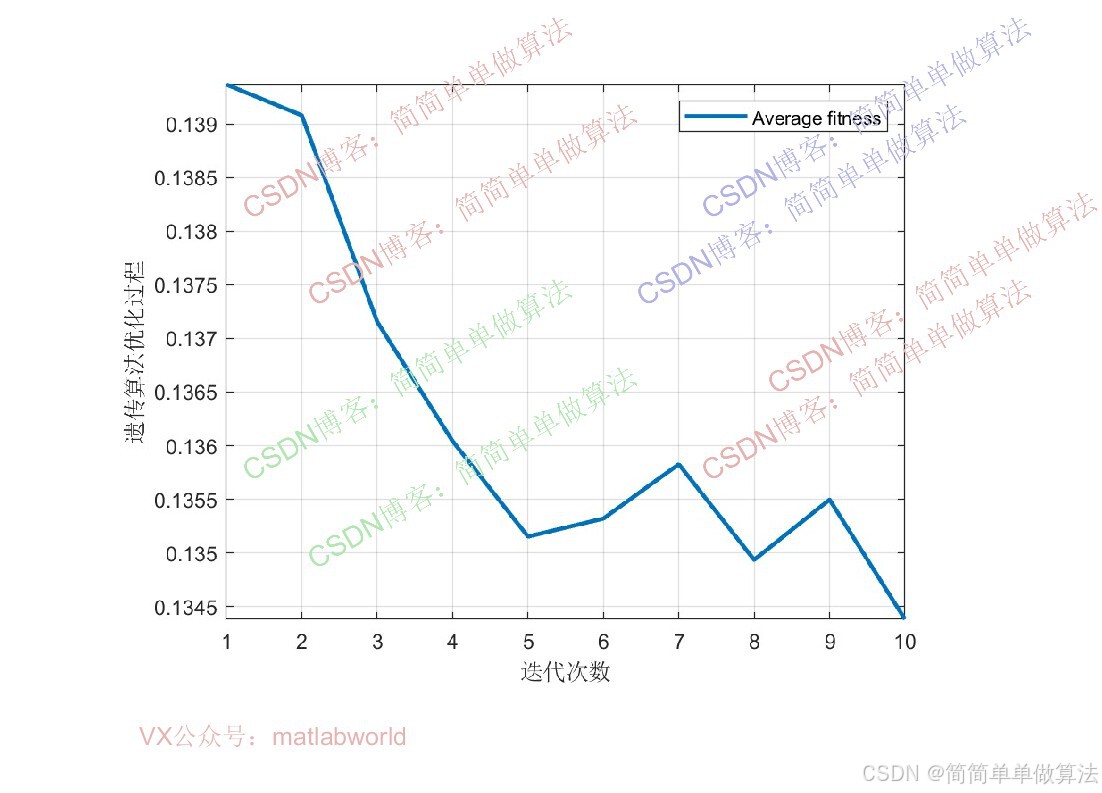
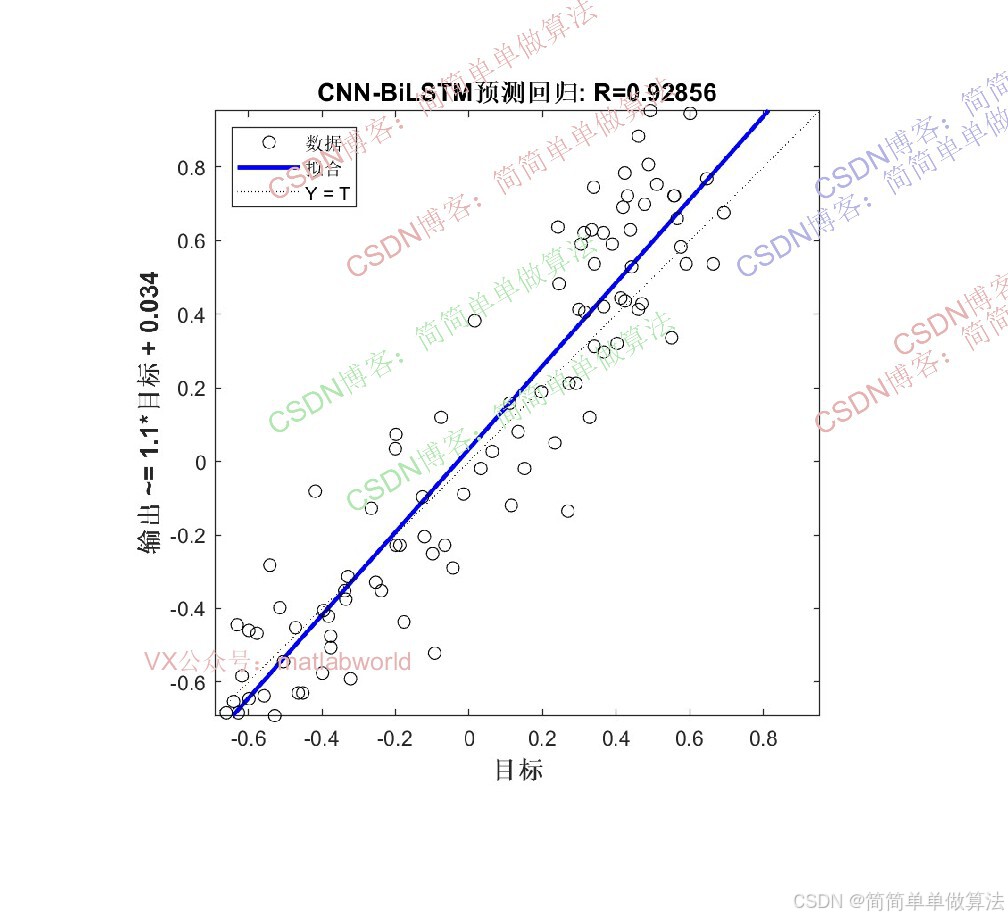
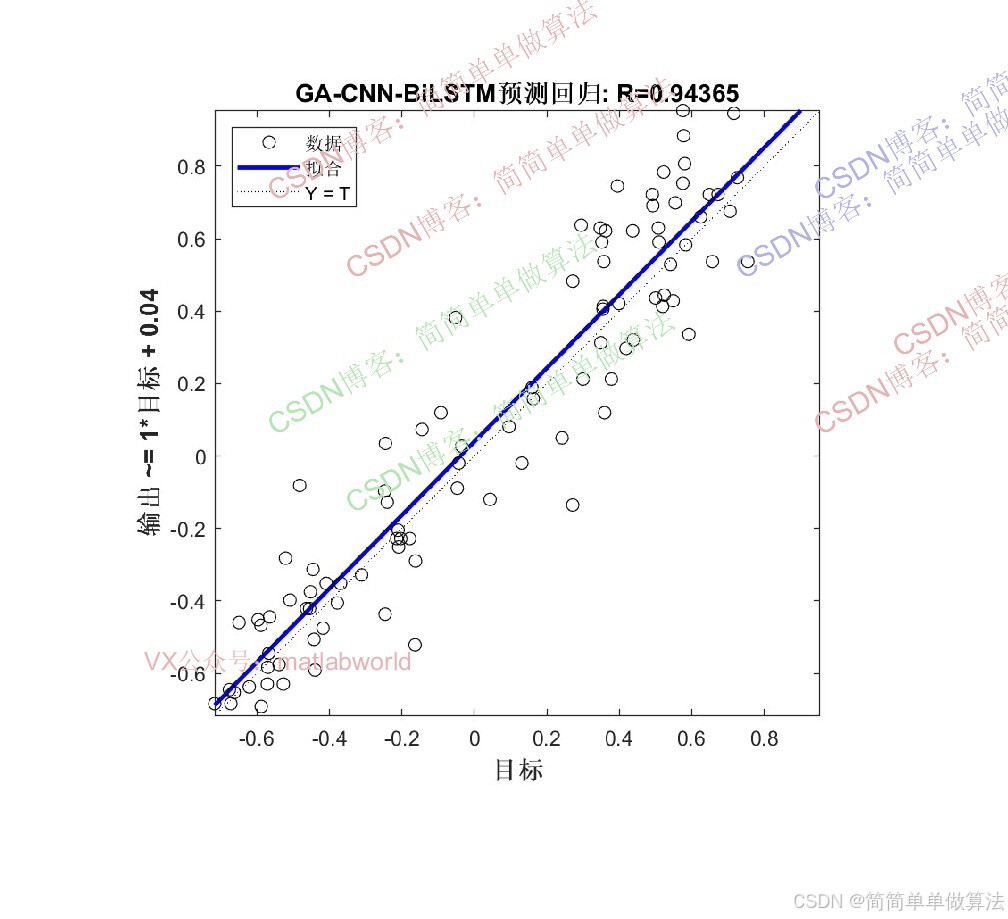
算法通过GA优化将BiLSTM的隐含层个数和学习率作为GA的优化变量,以CNN-BiLSTM模型在训练集上的回归预测误差作为GA的适应度函数,通过选择、交叉、变异等遗传操作迭代筛选最优超参数组合,再将最优超参数代入CNN-BiLSTM模型完成最终的多输入单输出回归预测。
2.算法运行效果图预览
(完整程序运行后无水印)
3.算法运行软件版本
Matlab2024b(推荐)或者matlab2022a
4.部分核心程序
(完整版代码包含中文注释和操作步骤视频)
....................................................
options = trainingOptions( 'adam', ...
'MaxEpochs',Miters, ...
'GradientThreshold',1, ...
'InitialLearnRate',LR, ...
'LearnRateSchedule','piecewise', ...
'LearnRateDropPeriod',20, ...
'LearnRateDropFactor',0.8, ...
'L2Regularization',1e-3,...
'Verbose',false, ...
'ExecutionEnvironment',mydevice,...
'Plots','training-progress');
%训练
[net,INFO] = trainNetwork(Xtrains,Ytrains,layers,options);
%预测
YPred = predict(net,XTests,"ExecutionEnvironment",mydevice);
YPred = double(YPred');
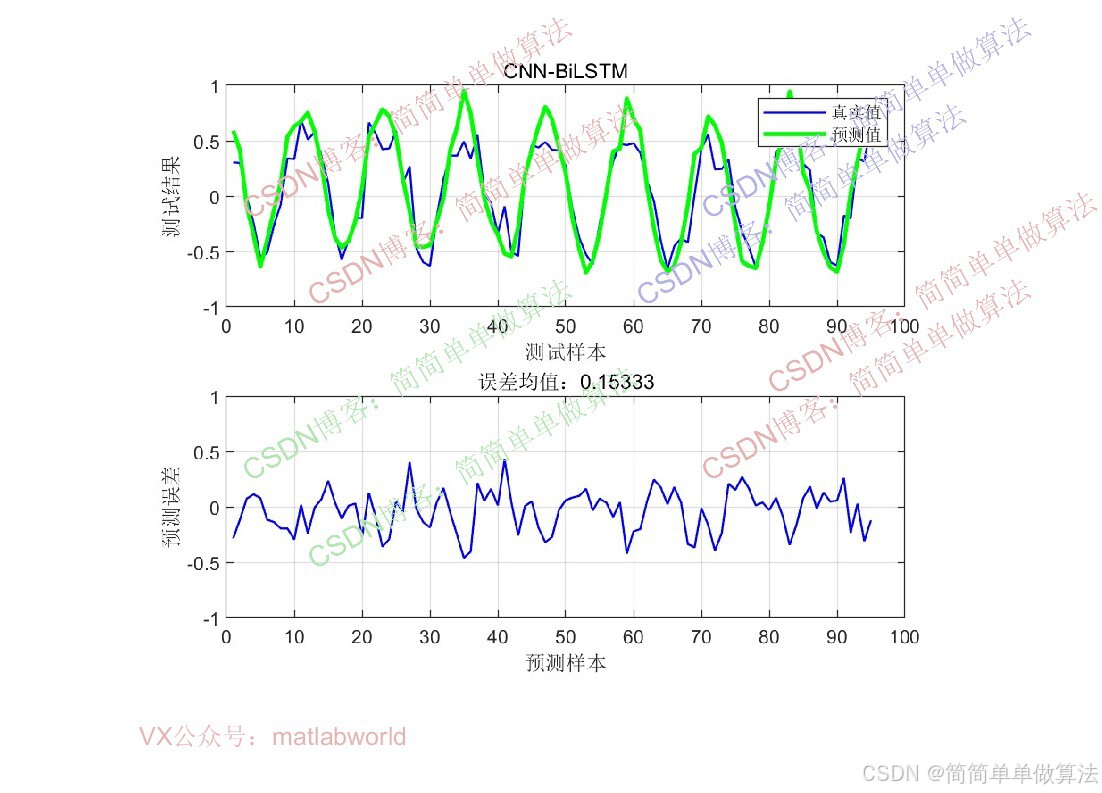
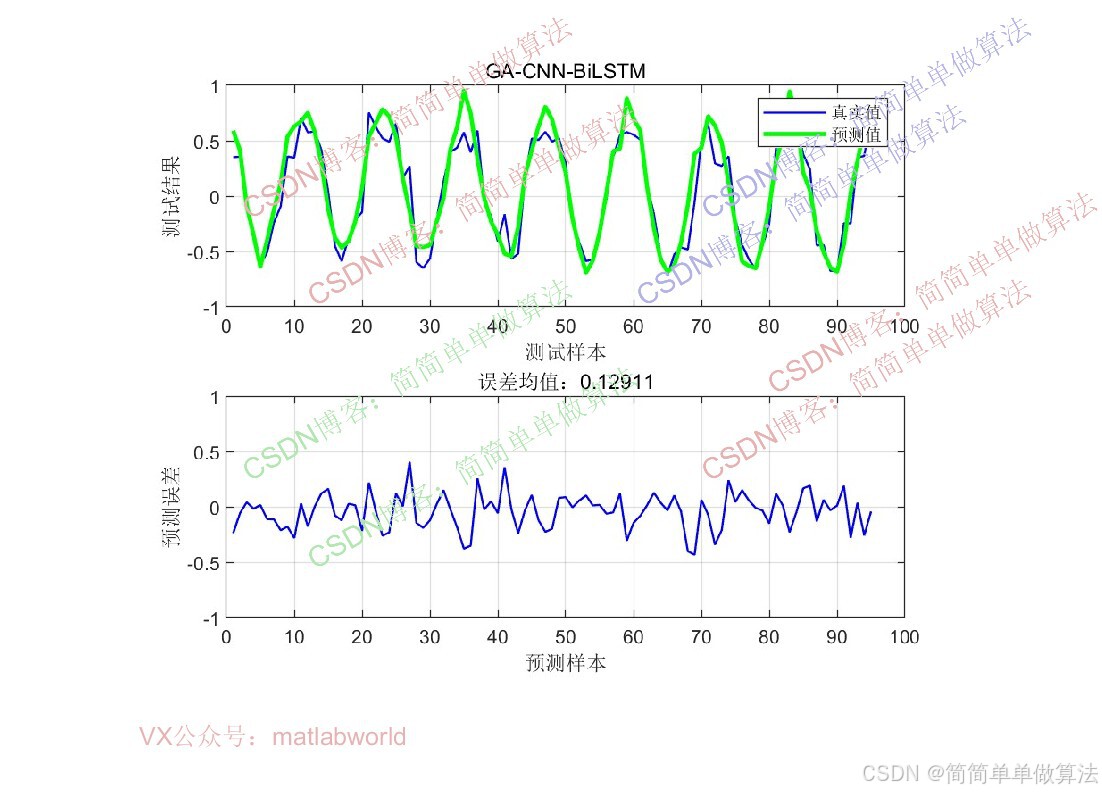
err1=mean(abs(YPred-Ytest));
figure;
subplot(211)
plot(YPred);
hold on
plot(Ytest);
legend('预测数据','真实数据');
subplot(212)
plot(YPred-Ytest);
ylim([-1,1]);
title(['预测误差:',num2str(err1)]);
save R2.mat err1 YPred Ytest net INFO Error2
2385.算法理论概述
遗传算法是模拟达尔文生物进化论的自然选择和遗传学机理的随机搜索算法,通过模拟"适者生存、优胜劣汰" 的进化过程,在解空间中全局搜索最优解。
**编码与解码:**将优化变量(BiLSTM隐含层个数n 、学习率η)映射为染色体(二进制/实数编码),是 GA与CNN-BiLSTM衔接的关键。
BiLSTM隐含层个数n:离散变量,取值范围通常为2,64(需根据数据规模调整),记为n∈N,nmin ≤n≤n max ;
学习率η:连续变量,取值范围通常为10−5,10−2 ,记为η∈R,ηmin≤η≤ηmax 。
优化变量组合记为 θ=(n,η) 。
**适应度函数:**衡量染色体(超参数组合)优劣的指标,直接关联CNN-BiLSTM的预测性能。
以CNN-BiLSTM模型在验证集上的均方误差mse最小化为目标。
**遗传操作:**选择、交叉、变异,实现种群的迭代进化。
6.参考文献
1 Ang L , Baoyu Z , Liyan Z ,et al.The Application of the CNN-BiLSTM-TPA Model Based on Deep Learning in Porosity PredictionJ.Journal of Geophysics and Engineering, 2025.DOI:10.1093/jge/gxaf141.
7.算法完整程序工程
OOOOO
OOO
O
关注后输入自动回复码: 0016