重要信息
时间:2026年1月9-11日
地点:马来西亚-吉隆坡


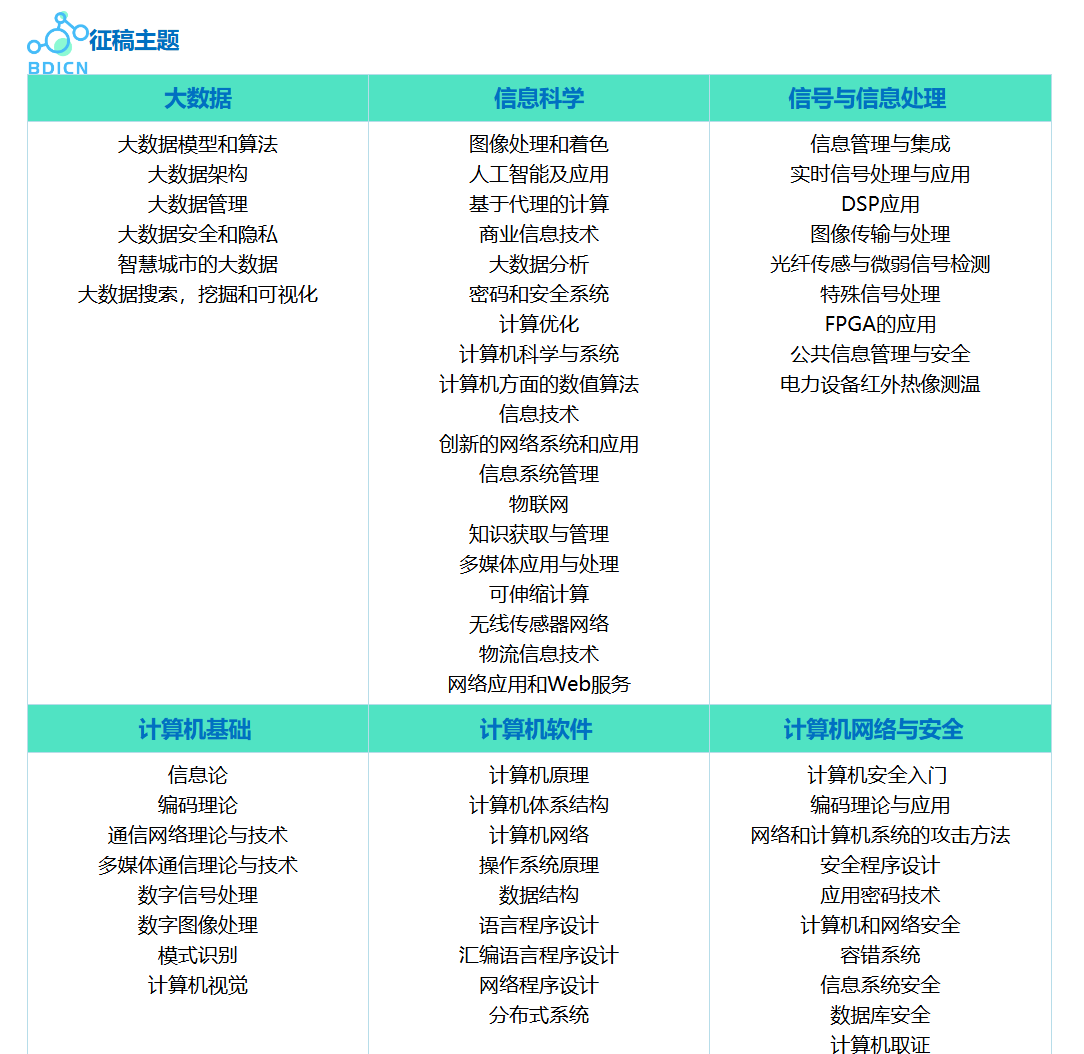
征稿主题
一、大数据、信息与计算机网络的技术体系架构
大数据、信息处理与计算机网络三者深度融合,构成 "数据采集网络层 - 数据传输网络层 - 数据存储与处理层 - 信息服务应用层" 的完整技术体系,覆盖物联网数据传输、分布式大数据处理、网络安全防护等核心场景,具体如下:
| 技术层级 | 核心技术方向 | 典型应用场景 | 技术核心目标 |
|---|---|---|---|
| 数据采集网络层 | 物联网传感网络、边缘采集节点、5G/6G 接入、数据采集协议(MQTT/CoAP) | 工业物联网数据采集、智慧城市感知网络 | 实现多源异构数据的泛在化、低功耗采集 |
| 数据传输网络层 | SDN(软件定义网络)、NFV(网络功能虚拟化)、量子通信、网络切片 | 大数据高速传输、低延迟网络通信 | 保障数据传输的高带宽、低延迟、高可靠 |
| 数据存储与处理层 | 分布式存储(HDFS/Ceph)、并行计算(Spark/Flink)、数据清洗与融合 | 海量日志数据处理、实时流数据分析 | 高效存储与处理 PB 级以上大数据 |
| 信息服务应用层 | 网络信息检索、智能推荐、网络安全分析、可视化展示 | 网络舆情分析、智能网络运维、数据服务 API | 挖掘数据价值,提供智能化信息服务 |
二、数据采集网络层:基于 MQTT 的异构网络数据采集
物联网传感网络是大数据采集的核心载体,MQTT 协议凭借轻量级、低功耗特性,成为异构网络(有线 + 无线)数据采集的主流协议,适用于跨网络、多设备的大数据采集场景。
2.1 技术环境与依赖
- 核心工具:
paho-mqtt(MQTT 客户端)、pyserial(串口通信,适配有线传感设备)、pandas(数据预处理) - 适用场景:工业传感器、智能家居设备、环境监测节点的跨网络数据采集
bash
运行
# 安装依赖
pip install paho-mqtt pyserial pandas numpy2.2 Python 实现异构网络数据采集与整合
python
运行
import paho.mqtt.client as mqtt
import serial
import pandas as pd
import numpy as np
import time
from threading import Thread
# 全局数据缓存
data_buffer = []
BUFFER_SIZE = 100 # 缓存大小
MQTT_BROKER = "broker.emqx.io" # 公共MQTT服务器
MQTT_PORT = 1883
MQTT_TOPIC = "bdicn2026/sensor/data"
SERIAL_PORT = "COM3" # 串口(根据实际设备调整)
SERIAL_BAUDRATE = 9600
# 1. MQTT无线传感节点数据采集
def mqtt_data_collector():
"""订阅MQTT主题,采集无线传感节点数据"""
def on_connect(client, userdata, flags, rc):
print(f"MQTT连接状态:{rc}")
client.subscribe(MQTT_TOPIC)
def on_message(client, userdata, msg):
"""接收MQTT消息并解析"""
try:
payload = msg.payload.decode("utf-8")
# 解析JSON格式数据(模拟:{"device_id":"wifi_001","temp":25.5,"hum":60.2,"time":"2026-01-01 10:00:00"})
import json
data = json.loads(payload)
data["network_type"] = "wireless_mqtt"
data_buffer.append(data)
# 缓存满时写入临时文件
if len(data_buffer) >= BUFFER_SIZE:
save_buffer_to_file()
print(f"MQTT采集数据:{data}")
except Exception as e:
print(f"MQTT数据解析异常:{str(e)}")
client = mqtt.Client()
client.on_connect = on_connect
client.on_message = on_message
client.connect(MQTT_BROKER, MQTT_PORT, 60)
client.loop_forever()
# 2. 串口有线传感节点数据采集
def serial_data_collector():
"""读取串口数据,采集有线传感节点数据"""
try:
ser = serial.Serial(SERIAL_PORT, SERIAL_BAUDRATE, timeout=1)
time.sleep(2) # 串口初始化
print("串口连接成功,开始采集数据...")
while True:
if ser.in_waiting > 0:
# 读取串口数据(模拟格式:device_id,pressure,flow,time)
line = ser.readline().decode("utf-8").strip()
if line:
parts = line.split(",")
if len(parts) == 4:
data = {
"device_id": parts[0],
"pressure": float(parts[1]),
"flow": float(parts[2]),
"time": parts[3],
"network_type": "wired_serial"
}
data_buffer.append(data)
# 缓存满时写入临时文件
if len(data_buffer) >= BUFFER_SIZE:
save_buffer_to_file()
print(f"串口采集数据:{data}")
time.sleep(1)
except Exception as e:
print(f"串口采集异常:{str(e)}")
# 3. 缓存数据持久化
def save_buffer_to_file():
"""将缓存数据写入CSV文件,实现数据整合"""
global data_buffer
if not data_buffer:
return
df = pd.DataFrame(data_buffer)
# 补充缺失字段(异构数据对齐)
if "temp" not in df.columns:
df["temp"] = np.nan
if "pressure" not in df.columns:
df["pressure"] = np.nan
# 时间格式标准化
df["time"] = pd.to_datetime(df["time"], errors="coerce")
# 写入文件
df.to_csv("sensor_data_merged.csv", mode="a", header=False, index=False)
# 清空缓存
data_buffer = []
print("缓存数据已写入文件,数据整合完成")
# 主程序
if __name__ == "__main__":
# 初始化CSV文件头
header = ["device_id", "temp", "hum", "pressure", "flow", "time", "network_type"]
pd.DataFrame(columns=header).to_csv("sensor_data_merged.csv", mode="w", header=True, index=False)
# 启动多线程采集(MQTT+串口)
t1 = Thread(target=mqtt_data_collector, daemon=True)
t2 = Thread(target=serial_data_collector, daemon=True)
t1.start()
t2.start()
# 主线程保持运行
try:
while True:
time.sleep(3600) # 持续运行
except KeyboardInterrupt:
print("采集程序终止,保存剩余数据...")
save_buffer_to_file()2.3 代码说明
- 多网络采集:通过多线程实现 MQTT 无线传感节点和串口有线传感节点的并行数据采集,适配异构网络场景;
- 数据整合:通过缓存机制对齐异构数据字段(补充缺失值、标准化时间格式),实现跨网络数据的统一存储;
- 持久化存储:缓存满时自动写入 CSV 文件,避免数据丢失,为后续大数据处理提供统一数据源。
三、数据传输网络层:SDN 网络流量调度实现
软件定义网络(SDN)打破传统网络的 "控制与转发耦合" 架构,可动态调度大数据传输流量,提升网络资源利用率。以下实现基于 mininet 仿真的 SDN 流量调度核心逻辑。
3.1 技术原理与场景
- SDN 核心原理:分离控制平面(Controller)与数据平面(Switch),通过控制器编程实现流量动态调度;
- 适用场景:大数据中心跨节点数据传输、高优先级业务流量保障。
3.2 Python 实现 SDN 流量调度(核心逻辑)
python
运行
from ryu.base import app_manager
from ryu.controller import ofp_event
from ryu.controller.handler import MAIN_DISPATCHER, DEAD_DISPATCHER
from ryu.controller.handler import set_ev_cls
from ryu.ofproto import ofproto_v1_3
from ryu.lib.packet import packet, ethernet, ipv4, tcp
from ryu.lib import hub
import csv
class SDNTrafficScheduler(app_manager.RyuApp):
OFP_VERSIONS = [ofproto_v1_3.OFP_VERSION]
def __init__(self, *args, **kwargs):
super(SDNTrafficScheduler, self).__init__(*args, **kwargs)
self.datapaths = {} # 存储交换机连接
self.traffic_stats = {} # 存储流量统计
self.scheduler_thread = hub.spawn(self.traffic_scheduler) # 调度线程
# 1. 交换机连接处理
@set_ev_cls(ofp_event.EventOFPStateChange,
[MAIN_DISPATCHER, DEAD_DISPATCHER])
def _state_change_handler(self, ev):
datapath = ev.datapath
if ev.state == MAIN_DISPATCHER:
if datapath.id not in self.datapaths:
self.logger.info(f"交换机 {datapath.id} 上线")
self.datapaths[datapath.id] = datapath
elif ev.state == DEAD_DISPATCHER:
if datapath.id in self.datapaths:
self.logger.info(f"交换机 {datapath.id} 下线")
del self.datapaths[datapath.id]
# 2. 流量统计收集
def _request_stats(self, datapath):
"""向交换机请求流量统计"""
self.logger.debug(f"请求交换机 {datapath.id} 流量统计")
ofproto = datapath.ofproto
parser = datapath.ofproto_parser
# 请求端口统计
req = parser.OFPPortStatsRequest(datapath, 0, ofproto.OFPP_ANY)
datapath.send_msg(req)
# 3. 流量统计处理
@set_ev_cls(ofp_event.EventOFPPortStatsReply, MAIN_DISPATCHER)
def _port_stats_reply_handler(self, ev):
"""处理交换机端口统计回复"""
body = ev.msg.body
datapath_id = ev.msg.datapath.id
self.traffic_stats[datapath_id] = {}
for stat in body:
self.traffic_stats[datapath_id][stat.port_no] = {
"rx_bytes": stat.rx_bytes,
"tx_bytes": stat.tx_bytes,
"rx_packets": stat.rx_packets,
"tx_packets": stat.tx_packets
}
# 记录统计数据
self._save_traffic_stats()
# 4. 流量调度核心逻辑
def traffic_scheduler(self):
"""周期性调度流量,优先保障大数据传输"""
while True:
# 遍历所有交换机,请求统计
for dp in self.datapaths.values():
self._request_stats(dp)
# 调度逻辑:识别高优先级流量(大数据传输,目的端口9000)
self._schedule_high_priority_traffic()
hub.sleep(10) # 每10秒调度一次
def _schedule_high_priority_traffic(self):
"""为大数据传输流量分配最优路径"""
for dp_id, dp in self.datapaths.items():
ofproto = dp.ofproto
parser = dp.ofproto_parser
# 匹配TCP目的端口9000(大数据传输端口)
match = parser.OFPMatch(
eth_type=0x0800, # IPv4
ip_proto=6, # TCP
tcp_dst=9000
)
# 选择负载最低的端口(简化版调度策略)
min_load_port = self._get_min_load_port(dp_id)
if min_load_port:
# 下发流表:将高优先级流量转发到低负载端口
actions = [parser.OFPActionOutput(min_load_port)]
inst = [parser.OFPInstructionActions(ofproto.OFPIT_APPLY_ACTIONS, actions)]
mod = parser.OFPFlowMod(
datapath=dp, match=match, cookie=0,
command=ofproto.OFPFC_ADD, idle_timeout=0, hard_timeout=0,
priority=65535, instructions=inst
)
dp.send_msg(mod)
self.logger.info(f"交换机 {dp_id}:高优先级流量转发到端口 {min_load_port}")
def _get_min_load_port(self, dp_id):
"""获取交换机负载最低的端口"""
if dp_id not in self.traffic_stats:
return None
port_stats = self.traffic_stats[dp_id]
# 排除本地端口(OFPP_LOCAL)
valid_ports = {p: s for p, s in port_stats.items() if p != ofproto_v1_3.OFPP_LOCAL}
if not valid_ports:
return None
# 按接收字节数排序,选择负载最低的端口
min_port = min(valid_ports.items(), key=lambda x: x[1]["rx_bytes"] + x[1]["tx_bytes"])[0]
return min_port
# 5. 统计数据持久化
def _save_traffic_stats(self):
"""保存流量统计数据,用于后续分析"""
with open("sdn_traffic_stats.csv", "a", newline="") as f:
writer = csv.writer(f)
timestamp = hub.time.time()
for dp_id, port_stats in self.traffic_stats.items():
for port, stats in port_stats.items():
writer.writerow([
timestamp, dp_id, port,
stats["rx_bytes"], stats["tx_bytes"],
stats["rx_packets"], stats["tx_packets"]
])
# 运行说明:
# 1. 安装ryu:pip install ryu
# 2. 启动控制器:ryu-manager --observe-links sdn_traffic_scheduler.py
# 3. Mininet仿真:sudo mn --topo single,3 --mac --controller remote,ip=127.0.0.1 --switch ovsk,protocols=OpenFlow133.3 代码说明
- 核心架构:基于 RYU 控制器实现 SDN 控制平面,分离流量统计收集与调度逻辑;
- 流量统计:周期性向交换机请求端口流量统计,记录接收 / 发送字节数、数据包数;
- 调度策略:识别大数据传输的高优先级流量(TCP 9000 端口),将其转发到负载最低的端口,提升传输效率;
- 数据持久化:保存流量统计数据,为网络性能分析、调度策略优化提供依据。
四、数据存储与处理层:Spark 分布式大数据处理
Apache Spark 是大数据处理的核心框架,支持批处理、流处理等多种计算模式,可高效处理 PB 级的网络日志、传感数据等海量数据。
4.1 技术原理与环境
- 核心原理:基于 RDD(弹性分布式数据集)实现分布式并行计算,支持内存计算,提升处理效率;
- 环境依赖:
pyspark(Spark Python API)、pandas(本地数据处理)
bash
运行
# 安装依赖
pip install pyspark pandas numpy4.2 Python 实现 Spark 分布式数据处理(网络日志分析)
python
运行
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, count, sum, avg, udf
from pyspark.sql.types import StringType, FloatType
import pandas as pd
import re
# 1. 初始化Spark会话
def init_spark_session():
spark = SparkSession.builder \
.appName("BDICN2026_NetworkLogAnalysis") \
.master("local[*]") # 本地模式,*表示使用所有CPU核心
.config("spark.executor.memory", "4g") \
.config("spark.driver.memory", "2g") \
.getOrCreate()
return spark
# 2. 自定义UDF:解析IP地址归属地(模拟)
def parse_ip_location(ip):
"""模拟IP地址归属地解析"""
ip_prefix = ip.split(".")[0]
location_map = {
"192": "内网",
"10": "内网",
"172": "内网",
"202": "北京",
"114": "上海",
"183": "广东"
}
return location_map.get(ip_prefix, "其他")
# 3. 分布式网络日志分析
def analyze_network_logs(spark, log_path):
"""基于Spark分析海量网络日志"""
# 读取日志文件(支持本地/分布式文件系统)
df = spark.read.text(log_path)
# 解析日志行(模拟格式:time,ip,url,status_code,response_size,network_delay)
log_pattern = r"(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}),(\d+\.\d+\.\d+\.\d+),(.*?),(\d+),(\d+),(\d+\.\d+)"
def parse_log_line(line):
match = re.match(log_pattern, line)
if match:
return (
match.group(1), match.group(2), match.group(3),
int(match.group(4)), int(match.group(5)), float(match.group(6))
)
else:
return ("", "", "", 0, 0, 0.0)
# 注册UDF
parse_log_udf = udf(parse_log_line, StringType())
parse_location_udf = udf(parse_ip_location, StringType())
# 数据解析与结构化
parsed_df = df.select(
parse_log_udf(col("value")).alias("parsed")
).filter(col("parsed") != "")
# 拆分字段
structured_df = parsed_df.select(
col("parsed").getItem(0).alias("time"),
col("parsed").getItem(1).alias("ip"),
col("parsed").getItem(2).alias("url"),
col("parsed").getItem(3).cast("int").alias("status_code"),
col("parsed").getItem(4).cast("int").alias("response_size"),
col("parsed").getItem(5).cast("float").alias("network_delay")
)
# 添加IP归属地字段
structured_df = structured_df.withColumn("location", parse_location_udf(col("ip")))
# 1. 基础统计分析
print("=== 网络日志基础统计 ===")
total_requests = structured_df.count()
error_requests = structured_df.filter(col("status_code") >= 400).count()
error_rate = error_requests / total_requests * 100
avg_delay = structured_df.select(avg(col("network_delay"))).first()[0]
total_traffic = structured_df.select(sum(col("response_size"))).first()[0] / (1024*1024) # 转换为MB
print(f"总请求数:{total_requests}")
print(f"错误请求数:{error_requests},错误率:{error_rate:.2f}%")
print(f"平均网络延迟:{avg_delay:.2f}ms")
print(f"总流量:{total_traffic:.2f}MB")
# 2. 按地域统计请求分布
print("\n=== 按地域请求分布 ===")
location_stats = structured_df.groupBy("location") \
.agg(count("ip").alias("request_count")) \
.orderBy(col("request_count").desc())
location_stats.show()
# 3. 按响应状态码统计
print("\n=== 按响应状态码分布 ===")
status_stats = structured_df.groupBy("status_code") \
.agg(count("status_code").alias("count")) \
.orderBy(col("status_code"))
status_stats.show()
# 4. 结果保存(分布式存储)
structured_df.write.mode("overwrite").parquet("network_log_analysis_result.parquet")
print("\n分析结果已保存为Parquet格式(分布式存储)")
return structured_df
# 主程序
if __name__ == "__main__":
# 生成模拟网络日志数据
def generate_sample_logs():
"""生成模拟网络日志文件"""
log_data = []
ips = ["192.168.1.1", "202.106.0.20", "114.114.114.114", "183.60.83.19", "172.16.0.5"]
urls = ["/api/data", "/index.html", "/static/js/app.js", "/api/login", "/api/query"]
status_codes = [200, 404, 500, 200, 403, 200]
for i in range(10000):
time = f"2026-01-01 10:{i//60:02d}:{i%60:02d}"
ip = ips[i%len(ips)]
url = urls[i%len(urls)]
status = status_codes[i%len(status_codes)]
size = int(np.random.normal(1024, 512))
delay = round(np.random.normal(50, 10), 2)
log_line = f"{time},{ip},{url},{status},{size},{delay}"
log_data.append(log_line)
with open("network_logs.txt", "w") as f:
f.write("\n".join(log_data))
# 生成模拟日志
generate_sample_logs()
# 初始化Spark
spark = init_spark_session()
# 分析日志
analyze_network_logs(spark, "network_logs.txt")
# 停止Spark
spark.stop()4.3 代码说明
- Spark 初始化:配置本地分布式计算环境,适配大数据处理的并行计算需求;
- 日志解析:通过自定义 UDF 解析非结构化网络日志,转换为结构化 DataFrame;
- 分布式分析:实现基础统计(请求数、错误率、延迟)、地域分布、状态码分布等核心分析;
- 结果存储:将分析结果保存为 Parquet 格式(列式存储,适配大数据场景),便于后续复用。
五、国际交流与合作机会
作为国际学术会议,将吸引全球范围内的专家学者参与。无论是发表研究成果、聆听特邀报告,还是在圆桌论坛中与行业大咖交流,都能拓宽国际视野,甚至找到潜在的合作伙伴。对于高校师生来说,这也是展示研究、积累学术人脉的好机会。