Transformer实战(30)------Transformer注意力机制可视化
0. 前言
随着大语言模型 (Large Language Model, LLM)的广泛应用,模型输出的准确性与可解释性之间的权衡问题变得尤为重要。可解释人工智能 (explainable artificial intelligence, XAI) 研究中的最大挑战是处理深度神经网络模型中大量的网络层和参数,本节将从 Transformer 模型的角度来探讨可解释人工智能。我们将研究自注意力机制,这是 Transformer 架构中与可解释性最相关的部分。自注意力机制能够帮助我们理解 Transformer 模型如何处理输入。为此,我们将使用多种注意力可视化工具,这些工具提供了重要的功能来增强模型的可解释性和可理解性。我们将讨论如何可视化注意力内部结构,并解释学习到的表示,这有助于我们理解自注意力头在 Transformer 中编码的信息,注意力最有趣的特征是某些注意力头对应于语法或语义的某些方面。
1. 解释注意力头
与大多数深度学习 (Deep Learning, DL) 架构一样,Transformer 模型的成功及其学习过程尚未完全被理解,但我们知道,Transformer 模型能够学习语言的许多语言学特征。大量的语言学知识分布在预训练模型的隐藏状态和自注意力头中。研究人员已经开发了许多工具来理解和更好地解释这些现象。
得益于自然语言处理 (Natural Language Processing, NLP) 的一些工具,我们可以解释 Transformer 模型中自注意力头所学习的信息。由于词元之间的权重,这些注意力头可以自然地进行解释。我们将在本节中我们将看到,某些注意力头对应于句法或语义的特定方面,还可以观察到表面模式和许多其他语言学特征。
接下来,我们将观察注意力头中的这些模式和特征。近期的研究已经揭示了自注意力的许多特征。例如,大多数注意力头关注分隔符词元,如分隔符 (SEP) 和分类词元 (CLS),因为这些词元未被掩码,且承载着段落级的信息;此外,大多数注意力头对当前词元关注较少,某些注意力头专门关注下一个或前一个词元,特别是在较早的网络层中。
以下是研究中发现的其他模式:
- 同一层中的注意力头表现出相似的行为
- 特定的注意力头对应于句法或语义关系的特定方面
- 某些注意力头编码使得直接宾语倾向于关注其动词,例如
<lesson, take>或<car, drive> - 在某些注意力头中,名词修饰语会关注其名词(例如,"
the hot water"; "the next layer"),或者所有格代词会关注名词(例如,"her car") - 某些注意力头编码使得被动助动词会关注相关的动词,例如 "
Been damaged" 和 "was taken" - 在某些注意力头中,共指提及会关注自己,例如 "
talks-negotiation","she-her" - 较低层通常包含关于词位置的信息
- 句法特征通常在
Transformer的早期层中被观察到,而高层次的语义信息则出现在上层 - 最后一层通常是特定于任务的,因此在下游任务中非常有效
为了观察这些模式,我们可以使用两个重要的工具------exBERT 和 BertViz,首先从 exBERT 开始。
2. 使用 exBERT 可视化注意力头
exBERT 是一个用于查看 Transformer 内部结构的可视化工具。我们将使用它来可视化 BERT-base-cased 模型的注意力头。BERT-base-cased 模型包含 12 层,每层有 12 个自注意力头,总共有 144 个自注意力头。接下来,我们将学习如何使用 exBERT。
(1) 访问Hugging Face上托管的 exBERT
(2) 输入句子 "The dog is very happy." 并查看输出结果,如下所示:
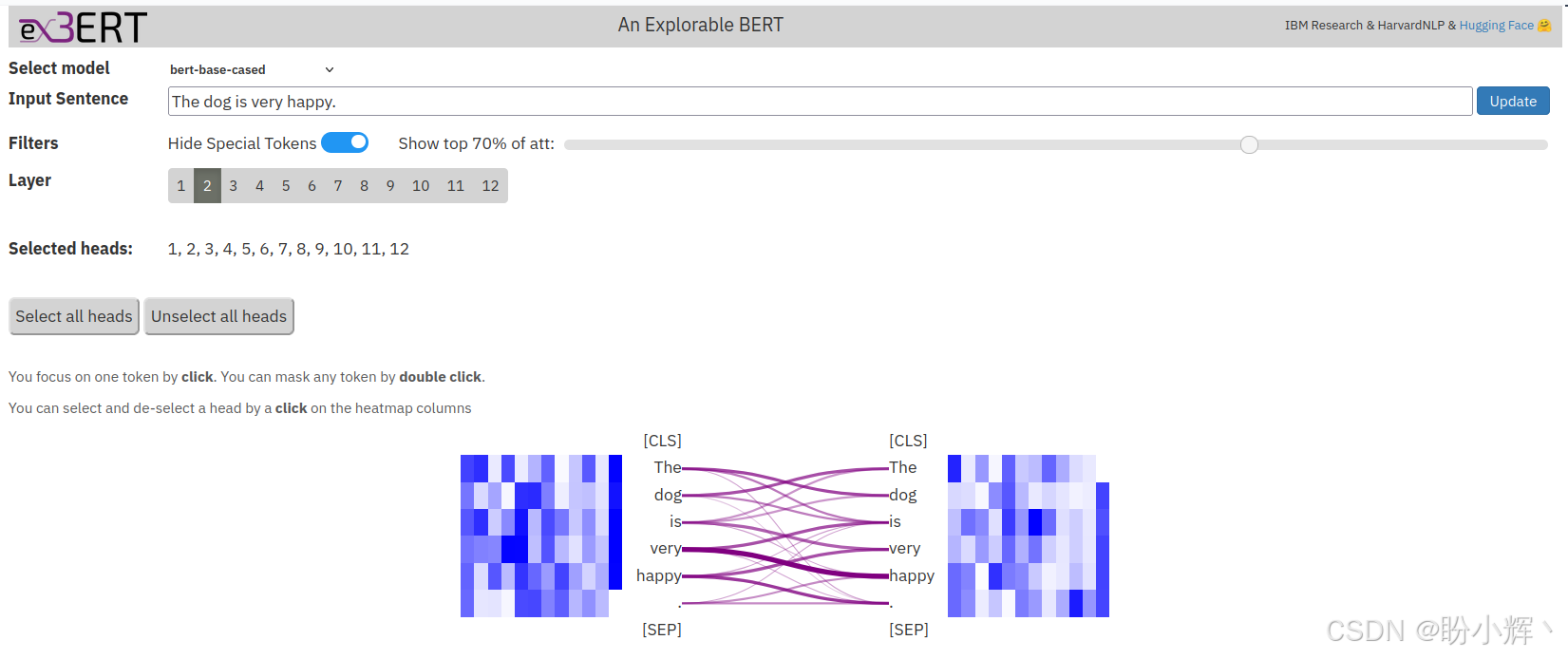
在以上截图中,左侧的词元关注右侧的词元,线条的粗细表示权重值。由于 CLS 和 SEP 词元有非常频繁和密集的连接,为了简化显示,使用 "Hide Special Tokens" 按钮切断了与它们相关的连接。上图表示第 2 层的注意力映射,其中线条对应的是所有注意力头权重的总和。多头注意力机制中,12 个注意力头并行工作,使我们能够捕捉比单头注意力机制更广泛的关系,这就是我们在图中看到广泛关注模式的原因。我们还可以通过点击 "Head" 列观察任意特定的注意力头。
如果将鼠标悬停在左侧的词元上,将看到该词元连接到右侧词元的具体权重。
(3) 接下来,我们将观察模型中是否存在本节介绍的其它模式。例如,验证在早期层中是否存在专门关注下一个或前一个词元的注意力头。
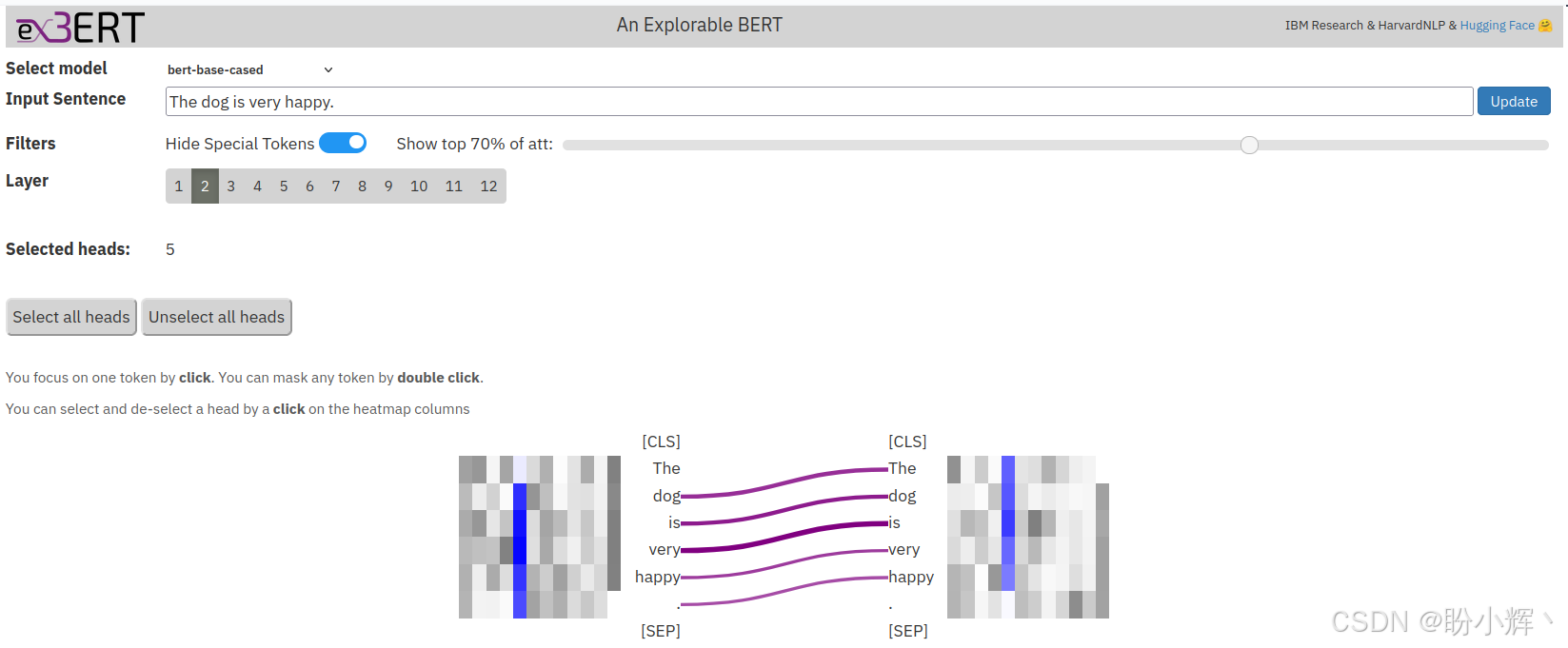
(4) 接下来,我们将使用 <Layer-No, Head-No> 表示法来表示特定的自注意力头,其中 exBERT 的索引从 1 开始,而 BertViz 的索引从 0 开始------例如,<3,7> 表示 exBERT 中第 3 层的第 7 个注意力头。选择 <2,5> (或 <4,12> 或 <6,2> )注意力头时,将得到以下输出,在该输出中,每个词元仅关注前一个词元:
(5) 对于 <2,12> 和 <3,4> 注意力头,每个词元仅关注下一个词元:
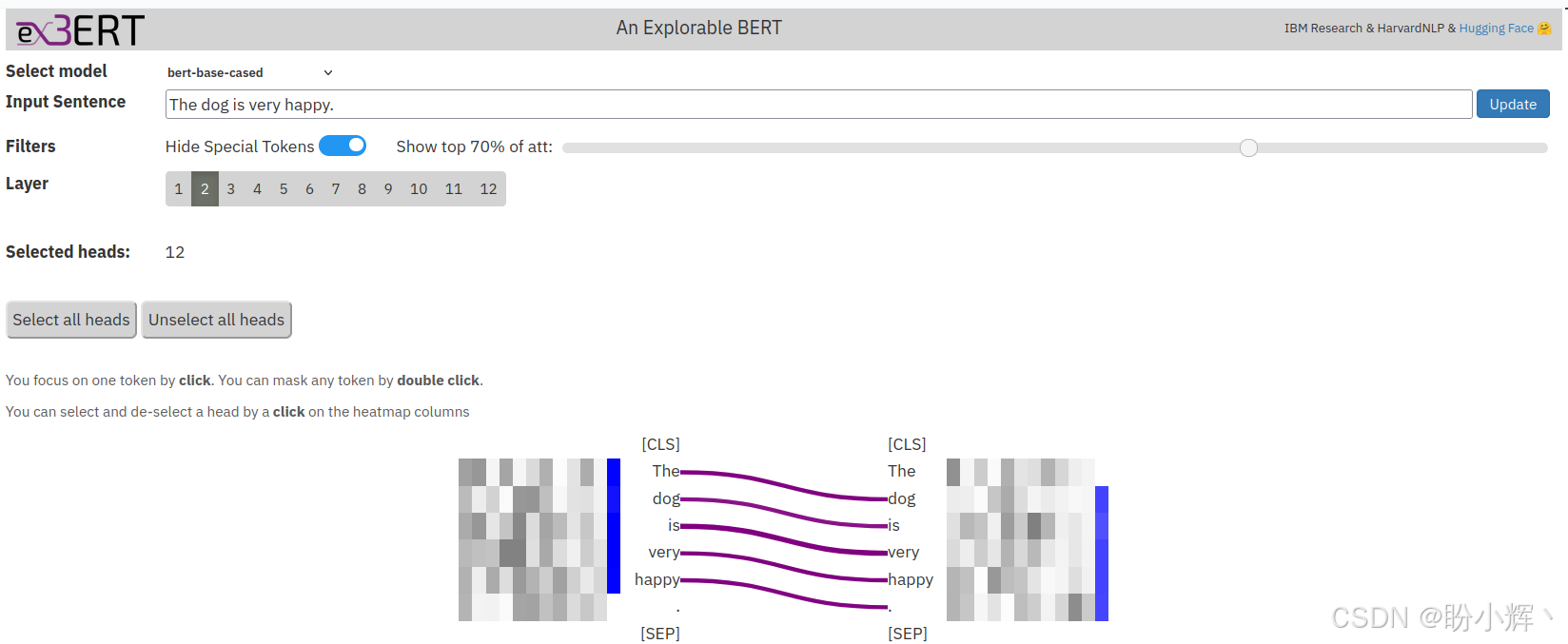
这些注意力头对其他输入句子具有相同的功能------即它们独立于输入工作。你可以自己尝试不同的句子。
我们可以使用注意力头来进行更高级的语义任务,例如通过探测分类器进行代词解析。首先,我们将定性检查内部表示是否具有这种代词解析(或共指消解)能力。代词解析是一个具有挑战性的语义关系任务,因为代词与其先行词之间的距离通常非常长。
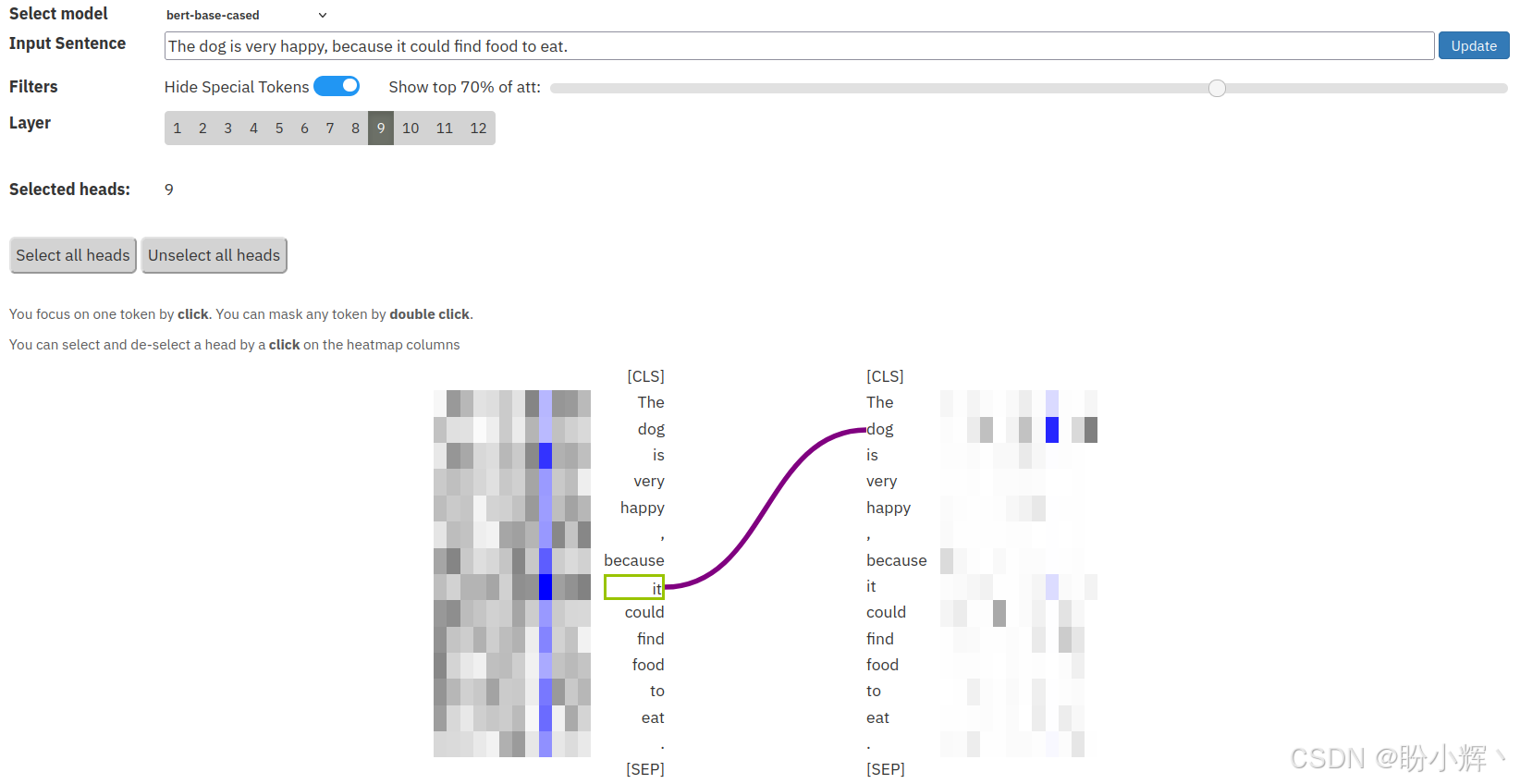
(6) 现在,采用句子:"The cat is very sad, because it could not find food to eat." 当检查每个注意力头时,会注意到 <9,9> 和 <9,12> 头编码了代词关系。当鼠标在 <9,9> 头上悬停时,得到以下输出:
<9,12> 头也适用于代词关系,当鼠标悬停在该注意力头时,得到以下输出:
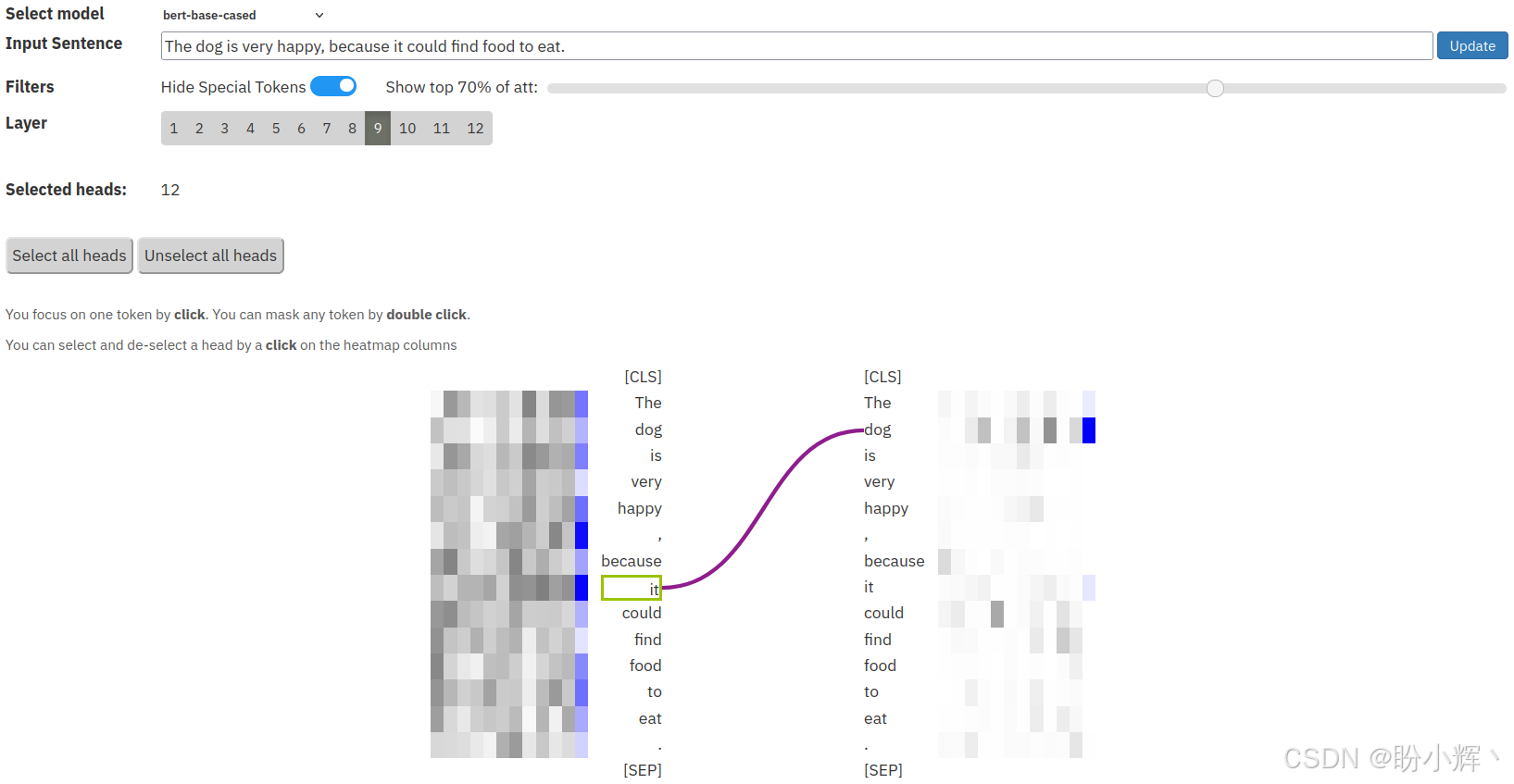
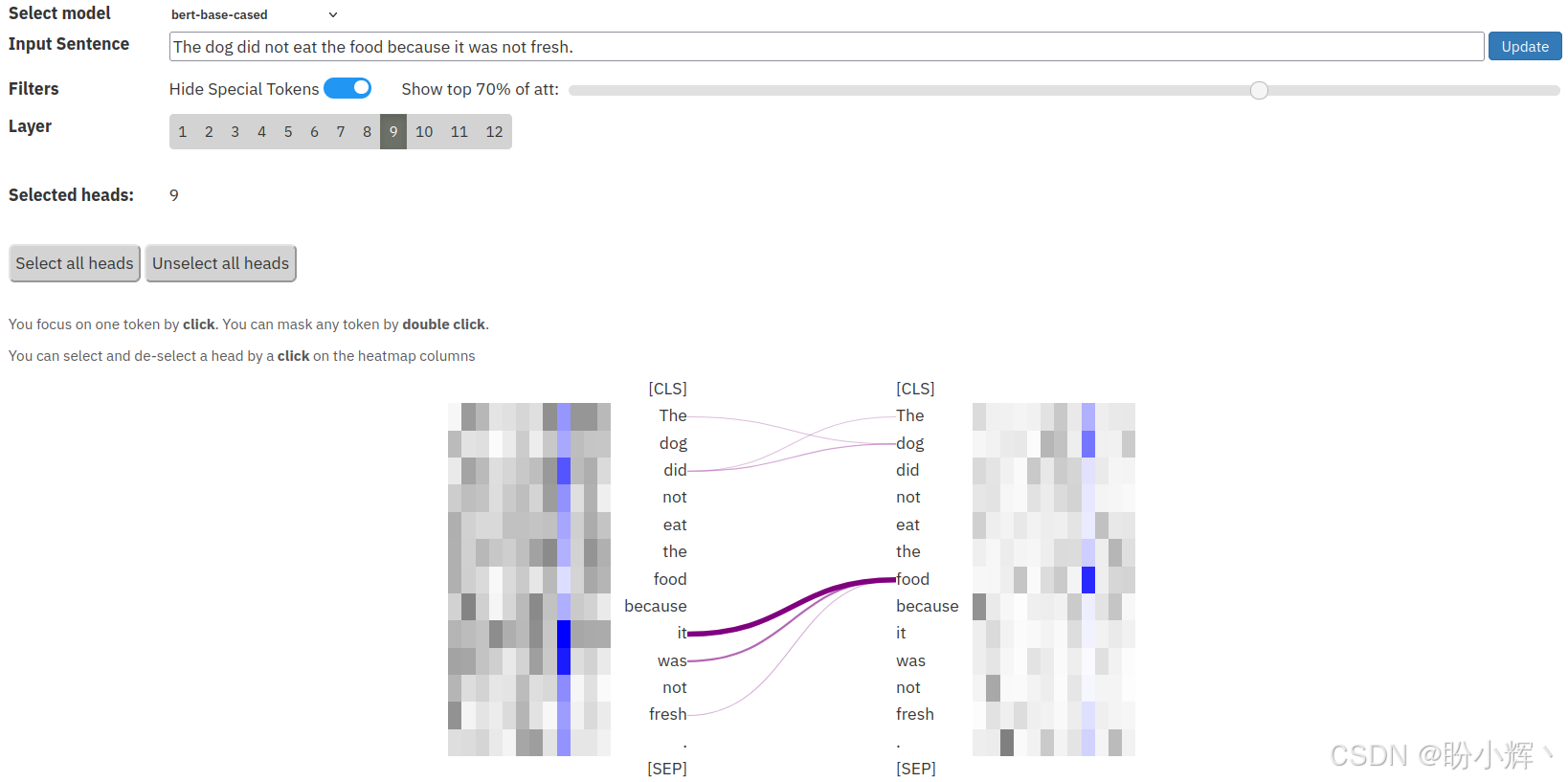
从以上截图中,可以看到,代词 "it" 强烈关注它的先行词 "dog"。稍微修改句子,使得 "it" 代词现在指代的是 "food" 词元,而不是 "dog" 词元,如,"The dog did not eat the food because it was not fresh." 如下图所示,涉及到 <9,9> 头,它正确地关注其先行词 "food":
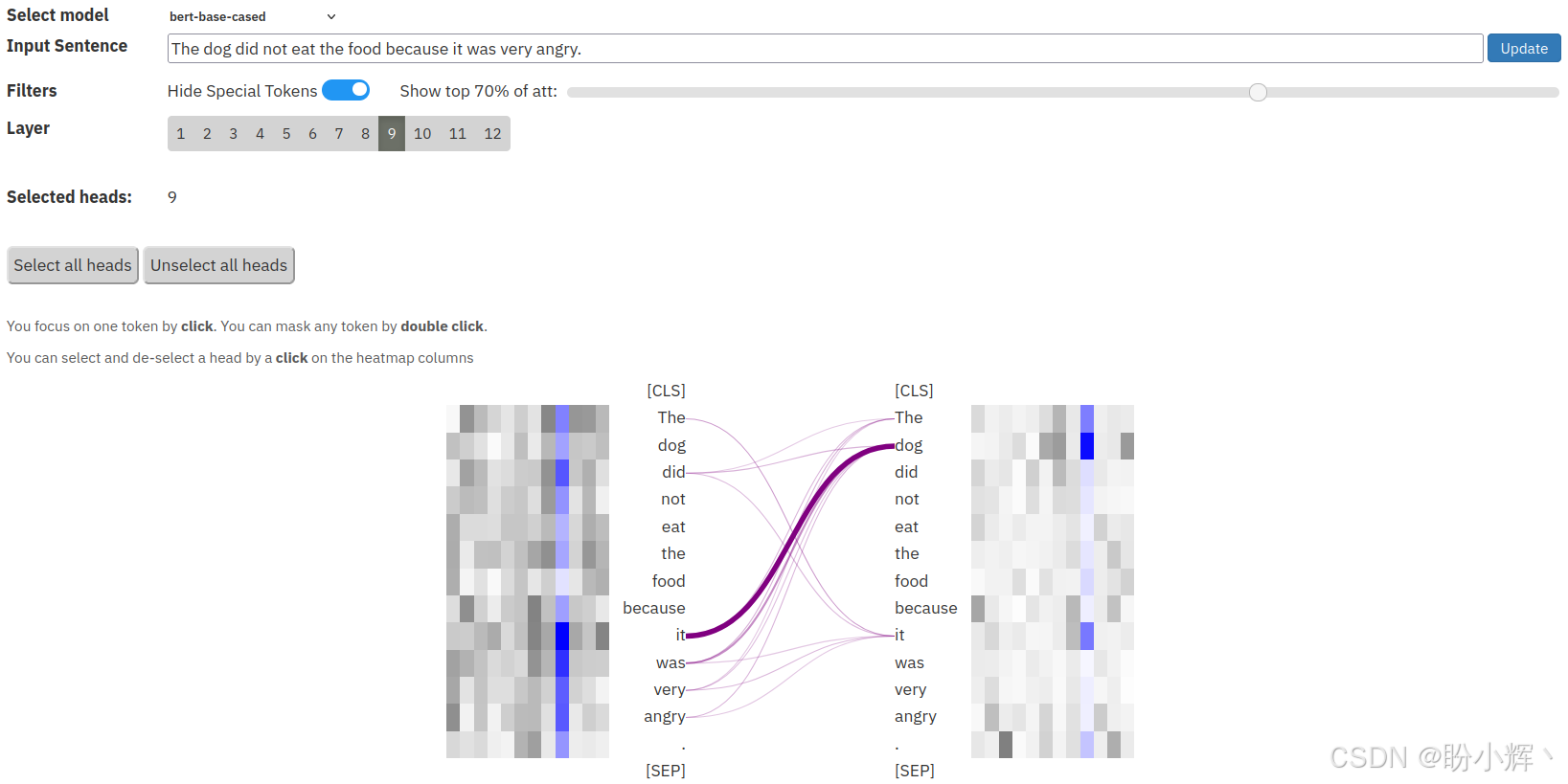
(7) 使用另一个例子,其中代词指代 "dog" 词元,如句子:"The dog did not eat the food because it was very angry." 在<9,9>头中,"it" 代词主要关注 "cat" 词元,如下图所示:
(8) 接下来,我们将以不同的方式使用exBERT模型来评估模型的能力。重新启动 exBERT 界面,选择最后一层(第 12 层),并保留所有注意力头。然后,输入句子:"The dog did not eat the food." 并将 "food" 词元掩码掉。双击可以将 "food" 词元掩码:
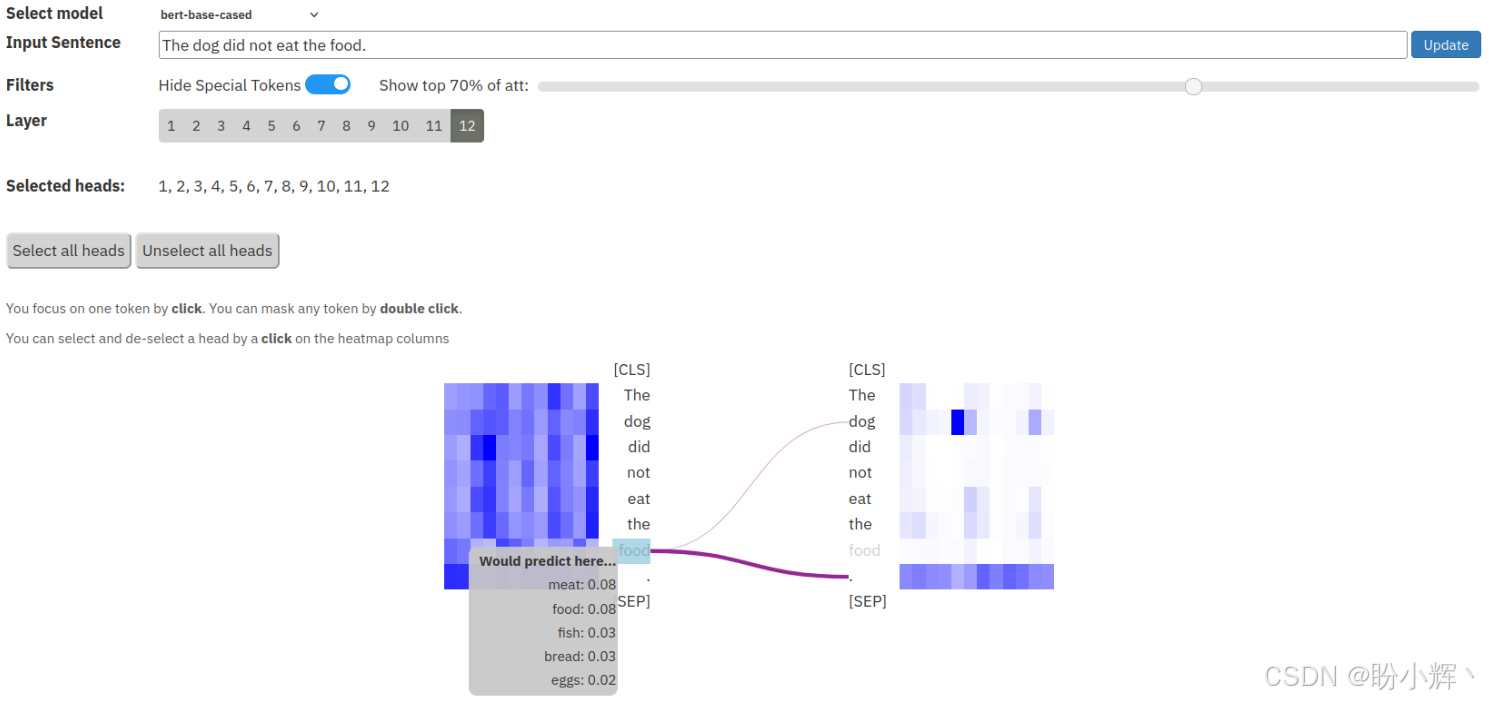
当鼠标悬停在掩码词元上时,可以看到 BERT-base cased 模型的预测分布,如上图所示,前 2 个预测是 "meat" 和 "food"。我们可以利用 BERT 模型的这些特性进行数据增强。例如,可以将 "food" 替换为预测 "meat",得到一个类似于原始句子的新的样本。
下一节,我们将使用 BertViz 并编写 Python 代码来可视化注意力头。
3. 使用 BertViz 实现注意力头的多尺度可视化
接下来,我们将编写代码,使用 BertViz 来可视化 Transformer 注意力头,BertViz 是一个用于可视化 Transformer 模型中注意力的工具,类似于 exBERT。它是 Tensor2Tensor 可视化工具工作的扩展。我们可以通过多尺度定性分析监控模型的内部结构。BertViz 的优势在于,它支持与大多数 Hugging-Face 托管的模型(如 BERT、GPT 和 XLM )进行交互,并且可以通过 Python API 进行操作。因此,我们也可以使用非英语模型或任何预训练模型。
像 exBERT 一样,BertViz 也可以在一个界面中可视化注意力头。此外,它还支持鸟瞰视图和低级神经元视图,在这些视图中,我们可以观察单个神经元如何相互作用以建立注意力权重。
(1) 首先,我们需要使用 pip 命令安装所需库:
shell
$ pip install bertviz ipywidgets transformers(2) 然后,导入所需模块:
python
from bertviz import head_view
from transformers import BertTokenizer, BertModelBertViz 支持三种视图:注意力头视图 (attention head view)、模型视图 (model view) 和神经元视图 (neuron view)。首先需要指出的是,在 exBERT 中从 1 开始索引层和注意力头,而在 BertViz 中,从 0 开始进行索引。因此,在 exBERT 中 <9,9> 注意力头在 BertViz 中对应的是 <8,8>。
3.1 注意力头视图
注意力头视图 (attention head view) 是 BertViz 中相当于在上一小节中用 exBERT 所看到的内容。注意力头视图可视化基于选定层中一个或多个注意力头的注意力模式。
(1) 首先,定义 get_bert_attentions() 函数,用于检索给定模型和一对句子的注意力和词元:
python
def get_bert_attentions(model_path,sentence_a,sentence_b):
model = BertModel.from_pretrained(model_path, output_attentions=True)
tokenizer = BertTokenizer.from_pretrained(model_path)
inputs = tokenizer.encode_plus(sentence_a,
sentence_b,
return_tensors='pt',
add_special_tokens=True)
token_type_ids = inputs['token_type_ids']
input_ids = inputs['input_ids']
attention = model(input_ids, token_type_ids=token_type_ids)[-1]
input_id_list = input_ids[0].tolist()
tokens = tokenizer.convert_ids_to_tokens(input_id_list)
return attention, tokens(2) 加载 bert-base-cased 模型,并检索给定两个句子的词元和相应的注意力。然后,调用 head_view() 函数来可视化注意力:
python
model_path = 'bert-base-cased'
sentence_a = "The cat is very sad."
sentence_b = "Because it could not find food to eat."
attention, tokens=get_bert_attentions(model_path, sentence_a, sentence_b)
head_view(attention, tokens)输出如下所示:

再上图左侧部分中,将鼠标悬停在左侧的任何词元上时,会显示从该词元出发的注意力。顶部的彩色方块对应于注意力头,双击任意一个方块会进行选择并丢弃其他方块,较粗的注意力线表示更高的注意力权重。
需要注意的是,在 exBERT 示例中,我们观察到 <9,9> 注意力头(在 BertViz 中等效于 <8,8>,因为索引从 0 开始) 承载了代词-先行词关系。在上图中,我们观察到了相同的模式,选择第 8 层和第 8 注意力头。然后,当我们将鼠标悬停在 it 上时,会看到上图右侧部分,发现 it 强烈关注 the、cat 和 it 词元。虽然其他模型中的注意力不完全相同,但某些注意力头确实可以编码这些语义特征。同时研究表明,语义特征主要编码在较高层中。
(3) 接下来,在土耳其语模型中寻找共指模式。加载一个土耳其语 bert-base-cased 模型,并使用一个句子对。可以观察到,在土耳其语中,<8,8> 头也具有与英语语言模型相同的语义特征,如下所示:
python
model_path = 'dbmdz/bert-base-turkish-cased'
sentence_a = "Kedi çok üzgün."
sentence_b= "Çünkü o her zamanki gibi çok fazla yemek yedi."
attention, tokens= get_bert_attentions(model_path, sentence_a, sentence_b)
head_view(attention, tokens)在以上代码中,sentence_a 和 sentence_b 分别表示"猫很伤心"和"因为它吃了太多食物"。当我们将鼠标悬停在 o (它)上时,可以看到其关注 Kedi (猫):
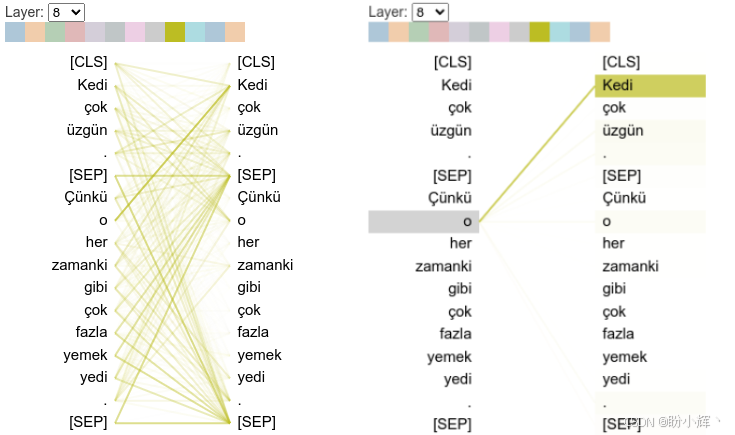
除了 o (它)之外,其他词元大多会关注 SEP 分隔符词元,这是 BERT 架构中所有注意力头的主导行为模式。
(4) 作为注意力头视图的最后一个示例,我们将解释另一个语言模型,选择 bert-base-german-cased 德语语言模型,并将其可视化,输入与土耳其语相同的句子对的德语同义句。
(5) 加载一个德语模型,处理一对句子,并将其可视化:
python
model_path = 'bert-base-german-cased'
sentence_a = "Die Katze ist sehr traurig."
sentence_b = "Weil sie zu viel gegessen hat"
attention, tokens= get_bert_attentions(model_path, sentence_a, sentence_b)
head_view(attention, tokens)检查注意力头,可以再次看到第 8 层的共指模式,但这次是在第 11 注意力头。要选择 <8,11> 注意力头,从下拉菜单中选择第 8 层,并双击最后一个注意力头:
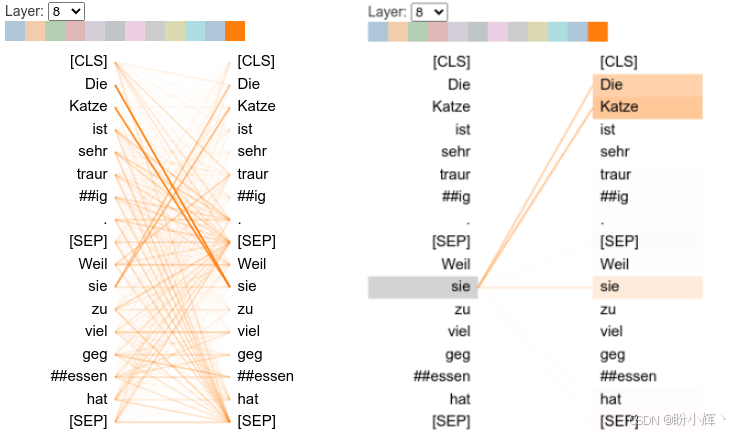
当将鼠标悬停在 "sie" 上时,会看到其关注 "Die Katze" (猫)。虽然这个 <8,11> 头是最强的共指关系注意力头,但这种关系可能扩展到许多其他注意力头。为了观察这一点,我们需要逐一检查所有注意力头。而 BertViz 的模型视图功能提供了一种基本的鸟瞰视图,可以一次性查看所有注意力头。
3.2 模型视图
模型视图 (model view) 允许我们从全局视角查看所有注意力头和层的注意力。自注意力头以表格形式展示,行和列分别对应层和头。每个头以可点击的缩略图形式呈现,其中包含了注意力模式的整体形状。
模型视图可以帮助我们理解 BERT 的工作原理,并使其更容易解释。研究发现了有关层的行为的线索,并得出了一些结论,我们已经在"解释注意力头"部分中列出了一些结论,可以使用 BertViz 的模型视图测试这些结论。接下来,继续使用德语语言模型。
(1) 首先,导入所需模块:
python
from bertviz import model_view
from transformers import BertTokenizer, BertModel(2) 使用 show_model_view() 包装函数:
python
from bertviz import model_view
def show_model_view(model, tokenizer, sentence_a, sentence_b=None, hide_delimiter_attn=False, display_mode="dark"):
inputs = tokenizer.encode_plus(sentence_a, sentence_b, return_tensors='pt')
input_ids = inputs['input_ids']
token_type_ids = inputs['token_type_ids'] # token type id is 0 for Sentence A and 1 for Sentence B
attention = model(input_ids, token_type_ids=token_type_ids)[-1]
sentence_b_start = token_type_ids[0].tolist().index(1) # Sentence B starts at first index of token type id 1
token_ids = input_ids[0].tolist() # Batch index 0
tokens = tokenizer.convert_ids_to_tokens(token_ids)
model_view(attention, tokens, sentence_b_start, display_mode)(3) 加载德语模型:
python
model_path='bert-base-german-cased'
sentence_a = "Die Katze ist sehr traurig."
sentence_b = "Weil sie zu viel gegessen hat"
model = BertModel.from_pretrained(model_path, output_attentions=True)
tokenizer = BertTokenizer.from_pretrained(model_path)
show_model_view(model, tokenizer, sentence_a,
sentence_b,
hide_delimiter_attn=False)输出结果如下所示:

这种视图帮助我们轻松地观察到许多模式,例如下一个词元(或上一个词元)注意力模式。正如我们在"解释注意力头"部分中提到的,词元通常倾向于关注分隔符,具体而言,在较低层关注 CLS 分隔符,在较高层关注 SEP 分隔符。因为这些词元未被掩码,它们可以促进信息的流动。在最后几层,我们只观察到以 SEP 分隔符为中心的注意力模式。可以推测,SEP 用于收集段落级信息,这些信息可以用于句子间任务,例如下一句预测或编码句子级的含义。
另一方面,我们观察到共指关系模式主要编码在 <8,1>、<8,11>、<10,1> 和 <10,7> 这几个头中。同样可以明确地说,<8,11> 头是德语模型中最强的编码共指关系的注意力头。点击该缩略图时,会看到相同的输出:
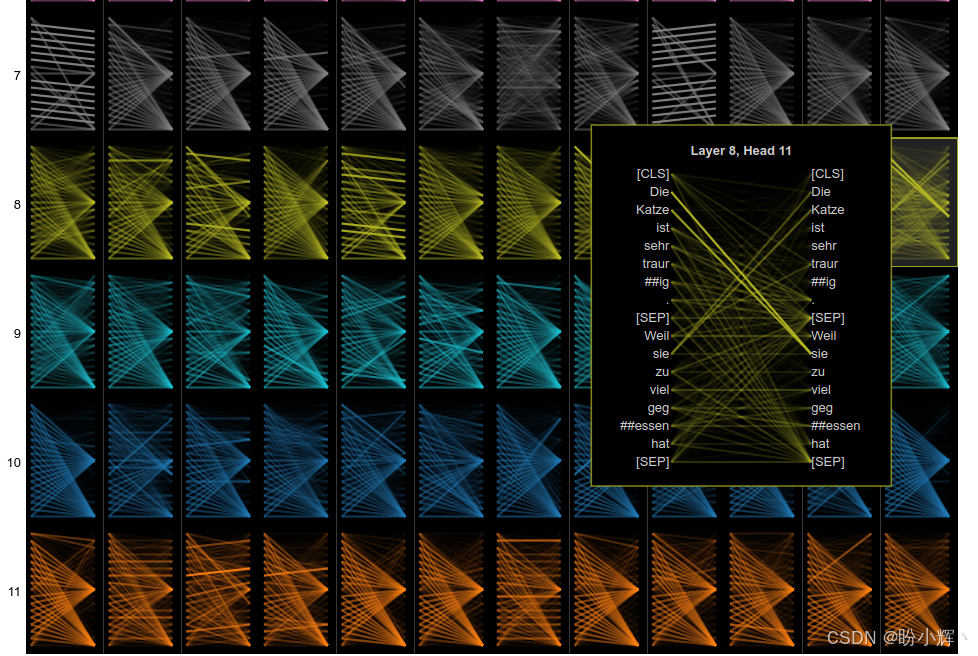
同样,可以将鼠标悬停在词元上,查看它们之间的映射。接下来,通过神经元视图进一步解构模型,并尝试理解注意力如何计算权重。
3.3 神经元视图
我们已经可视化了给定输入的计算权重。神经元视图 (neuron view) 可视化了查询中的神经元和键向量,以及如何基于交互计算词元之间的权重。我们可以追踪任意两个词元之间的计算过程。
(1) 接下来,加载模型,并可视化在上一小节使用的相同句子对:
python
from bertviz.transformers_neuron_view import BertModel, BertTokenizer
from bertviz.neuron_view import show
model_type = 'bert'
model_version = 'bert-base-uncased'
do_lower_case = True
model = BertModel.from_pretrained(model_version)
tokenizer = BertTokenizer.from_pretrained(model_version, do_lower_case=do_lower_case)
sentence_a = "The cat is very sad."
sentence_b = "Because it could not find food to eat."
show(model, model_type, tokenizer, sentence_a, sentence_b, display_mode='light', layer=8, head=10)输出结果如下所示:
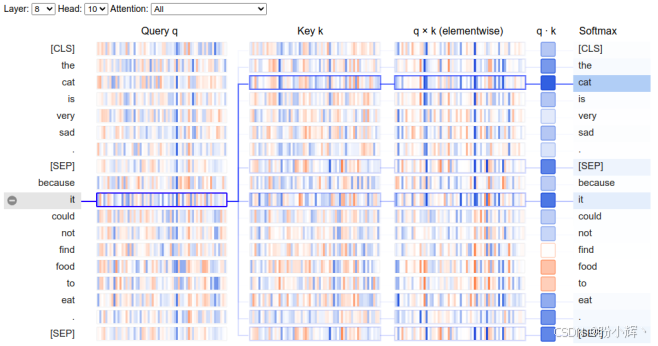
该视图帮助我们追踪从左侧选择的 "it" 词元到右侧其他词元的注意力计算过程。正值显示为蓝色,负值显示为橙色,颜色强度表示数值的大小。"it" 的查询与 "Die" 的键向量非常相似。如果仔细观察这些模式,会发现向量的相似性。因此,它们的点积比其他比较更高,从而在这些词元之间建立了强烈的注意力。我们还可以追踪点积和 softmax 函数的输出。点击左侧的其他词元时,也可以追踪其他计算过程。
(2) 接下来,选择一个带有下一个词元注意力模式的头,并追踪它。为此,我们选择 <1,1> 头。在这种模式中,几乎所有的注意力都集中在下一个词元上。再次点击it词元,结果如下所示:
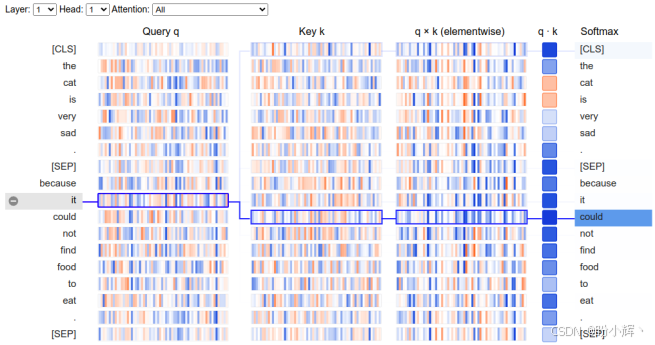
可以看到,sie 词元的注意力集中在下一个词元上,而不是它自己所指代的先行词 (Die Katze)。当我们查看查询和候选键时,与 "sie" 查询最相似的键是下一个词元 "zu"。同样,我们观察到点积和 Softmax 函数如何按顺序应用。
接下来,我们将介绍如何使用探测分类器 (probing classifier) 来解释 Transformer 模型。
4. 使用探测分类器理解 BERT 的内部结构
深度学习 (Deep Learning, DL) 模型学习内容的不透明性引发了许多关于如何解释此类模型的研究。在本节中,我们将尝试回答 Transformer 模型的哪些部分负责某些语言特征,或者输入的哪些部分导致模型做出特定决策。为了实现这一点,除了可视化内部表示外,我们还可以通过训练分类器来预测一些外部的形态、句法或语义属性。据此,我们可以确定是否可以将内部表示与外部属性关联起来。成功训练模型的结果将成为这种关联的量化证据,也就是说,语言模型已经学习到了与外部属性相关的信息。这种方法称为探测分类器 (probing classifier) 方法,它是 NLP 和其他 DL 研究中的一种重要分析技术。基于注意力的探测分类器将注意力图作为输入,并预测诸如共指关系或主语-修饰关系等外部属性。
我们可以使用 get_bert_attention() 函数获得给定输入的自注意力权重。与其可视化这些权重,不如直接将它们传递到分类管道中。通过监督学习,我们可以确定哪个注意力头适合特定的语义特征------例如,我们可以通过标注数据找出哪些注意力头适合进行共指分析。
但探测分类器的方法框架远比表面看上去的复杂。定义原始数据集和模型,以及探测数据集和分类器非常关键。根据具体目标,可能需要评估从探测器中提取信息的复杂性和难易程度。
小结
在本节中,我们讨论了人工智能面临的最重要问题之一:可解释人工智能 (explainable artificial intelligence, XAI)。随着语言模型的不断发展,可解释性成为一个严峻的问题。本节中,我们从 Transformer 的角度出发,研究了 Transformer 架构中的自注意力机制,尝试通过各种可视化工具理解这些机制的内部过程。
系列链接
Transformer实战(1)------词嵌入技术详解
Transformer实战(2)------循环神经网络详解
Transformer实战(3)------从词袋模型到Transformer:NLP技术演进
Transformer实战(4)------从零开始构建Transformer
Transformer实战(5)------Hugging Face环境配置与应用详解
Transformer实战(6)------Transformer模型性能评估
Transformer实战(7)------datasets库核心功能解析
Transformer实战(8)------BERT模型详解与实现
Transformer实战(9)------Transformer分词算法详解
Transformer实战(10)------生成式语言模型 (Generative Language Model, GLM)
Transformer实战(11)------从零开始构建GPT模型
Transformer实战(12)------基于Transformer的文本到文本模型
Transformer实战(13)------从零开始训练GPT-2语言模型
Transformer实战(14)------微调Transformer语言模型用于文本分类
Transformer实战(15)------使用PyTorch微调Transformer语言模型
Transformer实战(16)------微调Transformer语言模型用于多类别文本分类
Transformer实战(17)------微调Transformer语言模型进行多标签文本分类
Transformer实战(18)------微调Transformer语言模型进行回归分析
Transformer实战(19)------微调Transformer语言模型进行词元分类
Transformer实战(20)------微调Transformer语言模型进行问答任务
Transformer实战(21)------文本表示(Text Representation)
Transformer实战(22)------使用FLAIR进行语义相似性评估
Transformer实战(23)------使用SBERT进行文本聚类与语义搜索
Transformer实战(24)------通过数据增强提升Transformer模型性能
Transformer实战(25)------自动超参数优化提升Transformer模型性能
Transformer实战(26)------通过领域适应提升Transformer模型性能
Transformer实战(27)------参数高效微调(Parameter Efficient Fine-Tuning,PEFT)
Transformer实战(28)------使用 LoRA 高效微调 FLAN-T5
Transformer实战(29)------大语言模型(Large Language Model,LLM)