设计实现概述
a)实现包括子流程:
1)逻辑优化(Opt Design):对逻辑设计进行优化,使其更易于适配目标器件;
2)功耗优化(Power Opt Design,可选):对设计元素进行优化,以降低目标器件的功耗需求;
3)布局设计(Place Design):将设计布局到目标器件上,并执行扇出复制以改善时序性能;
4)布局后功耗优化(Post-Place Power Opt Design,可选):在完成布局后进行额外优化,以进一步降低功耗;
5)布局后物理优化(Post-Place Phys Opt Design,可选):基于布局信息得到的预估时序,对逻辑和布局进行优化,包括高扇出驱动单元的复制;
6)布线设计(Route Design):将设计布线到目标器件上;
7)布线后物理优化(Post-Route Phys Opt Design,可选):利用实际的布线延迟,对逻辑、布局和布线进行优化;
8)生成比特流(Write Bitstream):生成用于器件配置的比特流。通常,比特流生成步骤会在实现流程之后执行。
b)在多处理器系统上,Vivado会利用多线程加速特定流程,包括设计规则检查DRC报告、静态时序分析、布局布线。同时运行的最大线程数会根据处理器数量和任务类型有所不同。各任务对应的最大线程数如下:设计规则检查DRC报告8个、静态时序分析8个、布局8个、布线8个、物理优化8个。最大同时运行线程数的默认值由操作系统决定:对于Windows系统,默认限制为2;对于Linux系统,默认限制为8。Vivado通过提供launch_runs -jobs选项支持并行启动设计运行,该选项可指定同时运行的任务数量。每个并行运行的任务都是独立进程,需要占用独立的CPU和内存资源。分配充足的资源以满足整体峰值计算需求至关重要。例如,假设某设计任务在general.maxThreads设为8时,典型峰值内存占用为20GB。若并行启动4个类似任务,将需要32个处理器核心和大约80GB内存,以避免4个进程因竞争计算资源而导致性能下降。
c)Vivado支持网表驱动式设计,可导入来自AMD工具或第三方工具的已综合网表。支持的网表输入格式包括:结构化Verilog(Structural Verilog)、结构化SystemVerilog(Structural SystemVerilog)、EDIF格式、AMD NGC格式、综合后设计检查点(Synthesized Design Checkpoint,.dcp)。在项目模式或非项目模式下使用IP时,务必使用XCI文件而非DCP文件。这能确保IP输出产物在设计流程的所有阶段都被一致使用。若IP已通过上下文外综合(out-of-context synthesis)生成关联的DCP文件,则会自动使用该DCP文件,且不会重新对IP进行综合。
1)XCI文件(Xilinx Core Instance文件)是IP实例的配置描述文件(文本/XML 格式),是Vivado中IP调用的源头文件。包含IP的完整配置信息,例如IP型号(如AXI寄存器切片、时钟管理MMCM)、参数设置(如数据宽度、时钟频率、接口协议)、引脚映射规则、关联的约束模板等。
2)DCP文件(Design Checkpoint文件)是设计的快照文件(二进制格式),是Vivado实现流程中某一阶段的结果文件。包含当前阶段的设计数据,例如已综合的网表、设计约束、布局/布线信息、IP 实例的物理位置(若已布局)等。
3)若直接用DCP作为IP入口,DCP中的IP网表是固定快照,可能与顶层设计的综合策略(如时序约束、优化目标)、器件型号、其他IP的接口协议不兼容,导致实现阶段出现DRC错误或时序违规。只有当IP已通过上下文外综合(即单独对IP进行综合,且参数/上下文不再变化)生成DCP时,Vivado才会自动复用该DCP(避免重复综合以节省时间)
d)设计约束分为:物理约束、时序约束、功率约束。
1)物理约束:物理约束用于定义逻辑设计对象与器件资源之间的关联关系,例如:封装引脚布局、单元的绝对或相对布局、将单元分配到器件通用区域的布局规划约束、器件配置设置;
2)时序约束:时序约束用于定义设计的频率需求,采用赛灵思设计约束(XDC)格式编写,该格式基于行业标准的Synopsys设计约束(SDC)。若没有时序约束,Vivado设计套件将仅针对线长和布线拥堵优化设计,不会尝试评估或提升设计性能;
3)功率约束:功率约束用于定义准确功率分析所需的设置,这些设置包括:工作条件(Operating conditions)如电压设置、功率与电流预算、工作环境详情;开关活动率(Switching activity rates)适用于设计对象、设计对象类型、全局置位和复位信号。
4)Vivado功率分析会利用时序约束确定开关速率,并采用无向量传播法(vectorless propagation) 确定整个设计的翻转率(toggle rates)。若没有功率约束,将使用默认的12.5%翻转率;但为确保功率计算的准确性,必须设置准确的开关活动率以覆盖默认值。
e)约束集结构:一个约束集中包含多个约束文件,包含独立物理约束文件和时序约束文件的约束集。一个主约束文件+一个可接收约束变更的新约束文件。一个项目可包含多个约束集,通过多个约束集,可使用不同的实现运行来测试不同方案。例如,可创建一个用于综合的约束集,再创建一个用于实现的约束集。两个约束集可让你在综合、仿真、实现阶段应用不同约束进行试验。若要验证时序约束,需在综合后设计上运行report_timing_summary(时序摘要报告)和report_methodology(方法学报告)命令。实现前修复存在问题的约束。
f)可在硬件描述语言HDL源文件中以属性语句式添加约束。Verilog和VHDL源文件均支持添加此类属性,并将其传递到Vivado综合或Vivado实现流程中。在某些情况下,约束仅能以HDL属性形式存在,无法通过XDC实现。此时,必须在HDL源文件中以属性形式指定该约束。
g)Vivado使用物理设计数据库存储布局和布线信息。设计检查点文件(.dcp格式)允许在设计流程的关键节点保存和恢复该物理数据库。检查点是设计在流程中特定节点的快照,包含:当前网表(包括在实现过程中进行的所有优化)、设计约束、实现结果。通过Tcl命令,可将检查点设计代入设计流程的剩余环节,但无法通过新的设计源对其进行修改。 在项目模式下,随着设计推进,Vivado会自动保存和恢复检查点;在非项目模式下,必须在设计流程的适当阶段手动保存检查点,否则设计进度会丢失。write_checkpoint写入检查文件,open_checkpoint读取检查文件。
h)Vivado的编译时间受多种因素影响,包括设计网表的复杂度、器件利用率、物理约束与时序约束,以及实现命令所采用的策略。此外,中间报告的数量、Vivado所使用的线程数、Vivado工具的机器配置,以及负载共享工具LSF的作业请求设置,也均起到重要作用。
1)编译时间分析:若要在多个设计的多个阶段之间对比Vivado各命令的编译时间,可使用VivadoRuntime脚本从vivado.log文件中提取调试信息,包括编译时间、内存占用、校验和、时序、拥堵情况及命令行内容。若要在Vivado Tcl shell中,通过执行目标操作来调试特定设计的编译时间问题,可使用profiler.tcl分析文件。
2)设计与约束对编译时间的影响:编译时间受网表复杂度和利用率、时序约束和优化的影响。可以使用Vivado的多线程、并行生成报告、快速指令缩短最快编译时间。
i)非工程模式下的实际实现
c
source run.tcl
# 步骤1:读取综合工具生成的顶层EDIF网表
read_edif c:/top.edf
# 读取底层IP核网表
read_edif c:/core1.edf
read_edif c:/core2.edf
# 步骤2:指定目标器件并链接网表
# 将底层核与顶层设计合并为单一设计
link_design -part xc7k325tfbg900-1 -top top
# 步骤3:读取XDC约束以指定时序需求
read_xdc c:/top_timing.xdc
# 读取用于指定物理约束(如引脚位置)的XDC约束
read_xdc c:/top_physical.xdc
# 步骤4:使用默认设置对设计进行优化
opt_design
# 步骤5:使用默认指令进行布局,并保存检查点
# 建议在某些中间步骤保存进度
# 已布局的检查点可通过不同选项用于多次布线运行
place_design -directive Default
write_checkpoint post_place.dcp
# 步骤6:使用AdvancedSkewModeling指令进行布线
# 如需了解布线器指令的更多信息,可在Vivado Tcl控制台中输入"route_design -help"
route_design -directive AdvancedSkewModeling
# 步骤7:运行时序摘要报告以查看时序结果
report_timing_summary -file post_route_timing.rpt
# 运行利用率报告以查看器件资源使用情况
report_utilization -file post_route_utilization.rpt
# 步骤8:写入检查点以保存设计数据库
# 该检查点可用于Vivado IDE或Tcl API中的设计分析
write_checkpoint post_route.dcpj)在实现流程的每个步骤前后插入自定义Tcl脚本(称为钩子脚本,hook script),对应脚本分别为tcl.pre和tcl.post。插入钩子脚本后,可在每个实现步骤前后执行特定任务(例如,在布局设计步骤前后生成时序报告,以对比时序结果)。
k)
逻辑优化
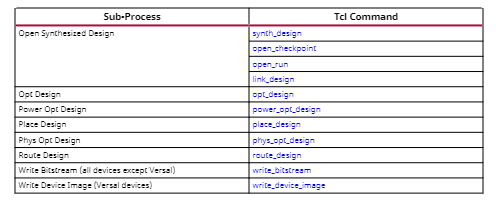
a)逻辑优化可在尝试布局前,确保得到最高效的逻辑设计。它会执行网表连通性检查,以预警潜在的设计问题(例如存在多驱动端的网络和未接驱动的输入端)。逻辑优化还会进行block RAM功耗优化。通常,设计的连通性错误会在逻辑优化阶段暴露,导致流程中断。因此,在执行实现流程前,通过设计规则检查DRC报告确保连通性有效至关重要。执行逻辑优化的Tcl命令为opt_design。
b)对于DONT_TOUCH属性设为TRUE的单元和网络,逻辑优化会跳过对其的优化。此外,对于直接施加了时序约束与约束例外的设计对象,以及带有LOC、Bel、RLOC、LUTNM、HLUTNM、ASYNC_REG、LOCK_PINS等物理约束的设计对象,逻辑优化同样会跳过优化。在每个优化阶段结束时,会输出一条信息,汇总因约束而被阻止的优化操作数量。若要生成哪些约束阻止了哪些优化的具体信息,可使用-debug_log开关。
c)导致逻辑优化失败的一个常见错误是使用未接驱动的查找表输入, 即该输入被LUT的逻辑方程所使用,但未连接驱动信号。这种情况会触发如下错误提示:ERROR Opt 31-67 Problem: A LUT6 cell in the design is missing a connection on input pin I0, which is used by the LUT equation。
d)可用的逻辑优化类型: 可通过选择对应的命令选项,将逻辑优化限制为特定类型。此时,工具仅会运行指定的优化操作,所有其他优化(即使是默认执行的类型)都会被禁用。
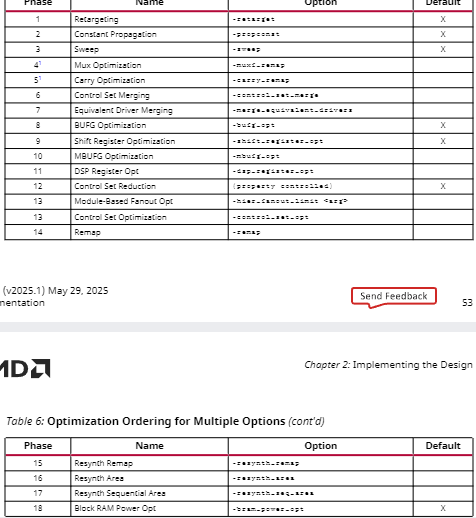
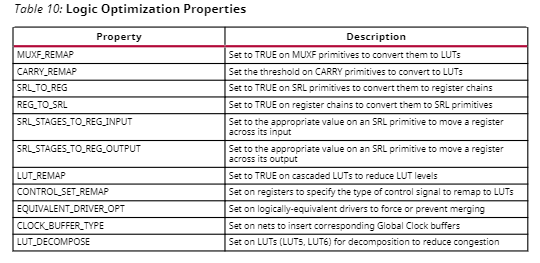
1)Retargeting (Default):当将设计从一个器件系列重定向到另一个器件系列时,会将一种类型的模块重定向为另一种类型。例如,将实例化的MUXCY或XORCY组件重定向到CARRY4模块;或将DCM重定向到MMCM。此外,反相器等简单单元会被吸收到下游逻辑中。若下游逻辑无法吸收反相器,则会将反相操作推移到驱动端前方,从而消除驱动端与其负载之间额外的逻辑层级。转换后,驱动端的INIT(初始)值会被取反,且置位 / 复位逻辑会相应转换,以确保功能等效。
2)Constant Propagation (Default):常量传播可以产生逻辑消除、逻辑简化、冗余逻辑处理。
3)Sweep (Default):清除优化会移除无负载单元和未连接的网络,并执行其他优化操作,具体包括:对宏引脚、触发器D引脚进行端接;
复制驱动多个输出缓冲器的触发器;基于反馈环路,根据MMCM补偿属性的变更进行更新;若仅使用双端口RAM的一个输出,则将其重定向为单端口RAM;在可能的情况下,针对面积优化SRLC32E、SRLC16E、ODDR、IDDR、CARRY4单元;移除未使用的IDELAYCTRL,并对输入输出进行分组,使其由最优数量的IDELAYCTRL控制;插入输入缓冲器和输出缓冲器,以确保特定单元的连接合法性。
4)Mux Optimization:将MUXF7、MUXF8和MUXF9原语重映射为LUT3,以提升布线可行性。可通过MUXF_REMAP单元属性(而非 - muxf_remap选项)限制多路复用器重映射的范围:只需在单个MUXF原语上将MUXF_REMAP属性设为TRUE即可。
5)Carry Optimization:将进位链中的CARRY4和CARRY8原语重映射为LUT,以提升布线可行性。使用-carry_remap选项时,仅单级进位链会被转换为LUT。你可通过CARRY_REMAP单元属性控制任意长度的单个进位链的转换:该属性为整数类型,用于指定可被重映射为LUT的最大进位链长度。CARRY_REMAP属性适用于CARRY4和CARRY8原语,且同一进位链中的每个CARRY原语必须设置相同的属性值,才能被转换为LUT。该属性支持的最小值为1。
6)Control Set Merging:将逻辑等效的控制信号的驱动端缩减为单个驱动端。这一过程类似反向扇出复制,最终得到的网络更适合基于模块的复制操作。
7)Equivalent Driver Merging:将所有逻辑等效信号的驱动端缩减为单个驱动端。此操作与控制集合并类似,但适用于所有信号,而非仅针对控制信号。可通过EQUIVALENT_DRIVER_OPT单元属性限制等效驱动端合并与控制集合并的范围:若在原始驱动端及其副本上,将 EQUIVALENT_DRIVER_OPT属性设为MERGE,则在执行opt_design命令时会触发等效驱动端合并阶段,进而合并带有该属性的驱动端;
若在原始驱动端及其副本上,将EQUIVALENT_DRIVER_OPT属性设为KEEP,则在等效驱动端合并与控制集合并阶段,会阻止带有该属性的驱动端被合并。
8)BUFG Optimization (Default):逻辑优化会在时钟网络及高扇出非时钟网络(如器件级复位信号网络)上保守地插入全局时钟缓冲器。在Versal系列器件中,高扇出非时钟网络会插入BUFG_FABRIC时钟缓冲器。对于7系列器件,只要全局时钟缓冲器总数不超过12个,就会插入时钟缓冲器;对于UltraScale、UltraScale+及Versal系列器件,只要全局时钟缓冲器总数(不含BUFG_GT缓冲器)不超过24个,就会插入时钟缓冲器。非时钟网络插入缓冲器的条件:扇出必须超过25000;该网络所驱动逻辑的时钟周期,需低于对应器件/速度等级的特定限值。片上结构驱动的时钟网络插入缓冲器的条件:扇出必须大于等于30。
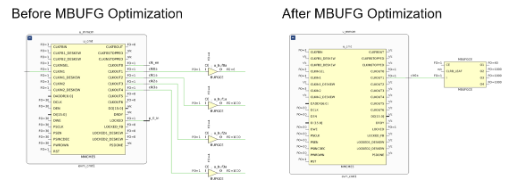
9)MBUFG Optimization:在Versal系列器件中,新型多时钟缓冲器MBUFG可通过其O1、O2、O3、O4输出端,提供对输入时钟的1分频、2分频、4分频、8分频时钟信号。MBUFG输出的时钟均通过同一全局时钟布线资源传输,仅在到达BUFDIV_LEAF直连基本单元后才进行分频处理。MBUFG驱动的时钟消耗的布线资源更少;且对于由同一MBUFG驱动的时钟之间的同步跨时钟域CDC路径,由于公共节点更靠近信号源与目的地,时钟偏移可被最小化。当并行时钟缓冲器由公共驱动端或时钟修改模块(CMB,如MMCM、DPLL或XPLL)驱动,且并行时钟的分频系数为某一公共时钟的1分频、2分频、4分频或8分频时,MBUFG优化会将这些并行时钟缓冲器转换为MBUFG。对于由CMB驱动的时钟,需满足相移为0、占空比为50%的条件才能进行转换;若由BUFG驱动的时钟网络存在冲突约束(如CLOCK_DELAY_GROUP或USER_CLOCK_ROOT约束),则会阻止该转换操作。仅当转换操作安全且不会破坏时序约束时,才会执行转换。
10)Shift Register Optimization (Default):移位寄存器(SRL,基于查找表的移位寄存器)优化包含多种转换操作:
①SRL扇出优化:若某一SRL原语(基于查找表的移位寄存器原语)的驱动扇出达到100或以上,会从该SRL链的末端提取一个寄存器级,并将其转换为寄存器原语。若该网络成为时序关键网络,这种操作可使下游复制更灵活。通常而言,高扇出寄存器驱动端比高扇出SRL驱动端更易于复制。
②SRL与寄存器原语之间的转换:若将SRL原语的SRL_TO_REG属性设为true,可将该SRL原语转换为逻辑等效的寄存器原语链。这种转换通常用于增加可用的流水线寄存器级数,使信号能在器件内部传输更长距离。增加寄存器级数可提高时钟频率,但会以增加延迟为代价。若将寄存器原语链的REG_TO_SRL属性设为true,可将该寄存器原语链转换为逻辑等效的SRL原语。这种转换通常用于减少信号在器件内部长距离传输时所用的流水线寄存器级数,过多的寄存器级数可能导致布线拥堵或其他布局问题。
③SRL与寄存器链之间流水线级的选择性迁移:当流水线寄存器链由SRL和寄存器原语组成时,可采用此类转换操作。寄存器级可从SRL的输入端或输出端提取出来,也可插入到SRL的输入端或输出端。通过这种操作,可更好地控制流水线寄存器结构,以应对欠流水线和过流水线问题。欠流水线:若要从SRL的输入端提取一个寄存器,需将SRL的SRL_STAGES_TO_REG_INPUT属性设为1;若要从SRL的输出端提取一个寄存器级,需将SRL_STAGES_TO_REG_OUTPUT属性设为1。过流水线:若要向SRL的输入端插入一个寄存器,需将SRL的SRL_STAGES_TO_REG_INPUT属性设为-1;若要向SRL的输出端插入一个寄存器级,需将SRL_STAGES_TO_REG_OUTPUT属性设为-1。
11)Shift Register Remap:将移位寄存器在分立寄存器链与SRL(基于LUTRAM的移位寄存器原语)之间进行转换。这些优化通过设定全局阈值,来控制移位寄存器在两种形式之间的转换,目的是平衡寄存器与基于LUTRAM的SRL的利用率。高SRL利用率可能导致布线拥堵,此时将小型SRL转换为寄存器,不仅可缓解拥堵,还能通过提供分立寄存器来覆盖关键路径的更长传输距离,从而提升性能。但当寄存器利用率过高时,又可能再次出现拥堵,此时将极长的寄存器链转换为SRL,可吸收寄存器级及其布线资源,进而减少拥堵。
12)DSP Register Opt:此选项用于对DSP切片的流水线寄存器、输入寄存器、输出寄存器执行各类优化,以改善DSP切片内部以及与DSP切片之间(输入到切片、从切片输出)的时序性能。
13)Control Set Reduction:包含多个唯一控制集的设计,其布局可选方案会更少,进而导致功耗更高、性能更低。而包含较少唯一控制集的设计,在布局方面拥有更多可选方案与灵活性,通常能实现更优的设计结果。通过为存在控制信号驱动同步置位/复位引脚或时钟使能引脚的寄存器施加CONTROL_SET_REMAP属性,可缩减唯一控制集的数量。这一操作会触发可选的控制集缩减阶段,并将置位/复位逻辑和/或时钟使能逻辑映射到寄存器的D输入引脚。若条件允许,该逻辑会与驱动D输入引脚的现有查找表合并,从而避免增加额外的逻辑层级。CONTROL_SET_REMAP属性支持以下取值:ENABLE:将使能EN输入映射到D输入;RESET将同步置位或复位输入映射到D输入;
ALL功能等同于同时设置ENABLE和RESET;NONE或未设置不执行优化(默认值)。若在任意寄存器上检测到CONTROL_SET_REMAP属性,此优化会自动触发。
14)Control Set Optimization:此优化对设计的优化方式与控制集缩减(Control Set Reduction)类似,不同之处在于,优化候选对象由工具自动选择。
15)Module-Based Fanout Optimization:扇出量超过指定限值(该限值通过此选项作为参数传入)的网络驱动端,会根据逻辑层级进行复制。对于由该高扇出网络驱动的每个层级实例,若该层级内的扇出量超过指定限值,则该层级内的网络将由高扇出网络驱动端的副本进行驱动。每次执行逻辑优化,影响的都是内存中的设计,而非最初打开的综合后设计。
16)Remap:重映射将多个查找表合并为单个查找表,以减少逻辑深度。通过为一组查找表施加LUT_REMAP属性,可触发选择性重映射:LUT_REMAP值设为TRUE的查找表链,会在条件允许时合并为更少的逻辑层级。重映射优化可将属于不同逻辑层级的查找表合并为单个查找表,从而减少逻辑层级。重映射后的逻辑会合并到逻辑锥(logic cone)中最下游的查找表中。此优化还会在转换前,对扇出量大于1且带有LUT_REMAP属性的查找表进行复制。
17)Resynth Area:面积重新综合在面积模式下执行重新综合,以减少查找表的数量。
18)Resynth Sequential Area:时序逻辑面积重新综合通过执行重新综合,同时减少组合逻辑和时序逻辑的数量。其优化范围是面积重新综合的超集。
19)Block RAM Power Optimization (Default):功耗优化对Block RAM单元启用功耗优化,具体包括:将true dual-port RAM中未被读取的端口的WRITE_MODE(写入模式)改为NO_CHANGE(保持不变);对输出端应用智能时钟门控。
e)当对某一原语单元执行优化操作时,该单元的OPT_MODIFIED属性会随之更新,以反映对该单元执行的优化操作。若对同一原语单元执行多项优化操作,OPT_MODIFIED属性的值会包含一份优化操作列表,且列表中的优化操作按其执行顺序排列。

f)Using Directives
1)Explore(探索):执行多遍次优化。
2)ExploreArea(面积探索):执行多遍次优化,重点关注减少组合逻辑。
3)ExploreSequentialArea(时序逻辑面积探索):执行多遍次优化,重点关注减少寄存器及相关组合逻辑。
4)RuntimeOptimized(运行时优化):执行最少遍次优化,以牺牲设计性能为代价换取更快的编译时间。
5)ExploreWithRemap(带重映射的探索):与Explore指令功能相同,但包含重映射优化。
6)Default(默认):使用默认设置运行opt_design命令。
g)使用-debug_log和-verbose
1)使用-debug_log选项可获取优化分析的详细信息,该日志包含两类关键内容:被常量值简化的逻辑和待移除的无负载逻辑。同时,日志还会记录因约束限制而未能实施的优化详情。如需查看opt_design执行的全部优化细节,可通过-verbose选项启用完整日志输出。考虑到可能产生大量信息,该选项默认关闭,建议仅在需要时启用。为提升大型设计的工具运行速度,推荐仅在Shell模式或批处理模式下使用-verbose选项,不要在GUI模式下使用。
h)逻辑优化约束
1)Vivado在逻辑优化时会保留DONT_TOUCH属性,确保带有该属性的网表或单元不会被优化移除。为提升网表选择效率,系统会预先过滤带有DONT_TOUCH属性的网表,使其不参与物理优化流程。
2)建议将DONT_TOUCH属性主要用于叶子单元(leaf cells)以防止优化。当应用于层次化单元(hierarchical cell)时,仅能保留单元边界结构,内部仍允许优化且支持常量跨边界传播。如需完整保留层次化网表,需通过get_nets命令的-segments选项为所有网表段添加DONT_TOUCH属性。
3)系统会自动为带有MARK_DEBUG属性(设为TRUE)的网表添加DONT_TOUCH属性(TRUE值),确保设计各阶段的可探测性。这是MARK_DEBUG的标准用法。但在某些特殊场景下,DONT_TOUCH可能过度限制优化(如阻碍常量传播、线网清理或重映射),影响时序收敛。此时可单独关闭DONT_TOUCH(设为FALSE)而保留MARK_DEBUG。推荐通过config_flows的-mark_debug选项管理优化行为,无需修改源代码或约束条件。该选项提供三种模式:enable(默认模式,禁止优化带有MARK_DEBUG的网表)、disable(允许在综合和实现阶段完全优化)、synthesis_only(仅禁止在综合阶段优化,实现阶段可自由优化)。
4)一些属性
功耗优化
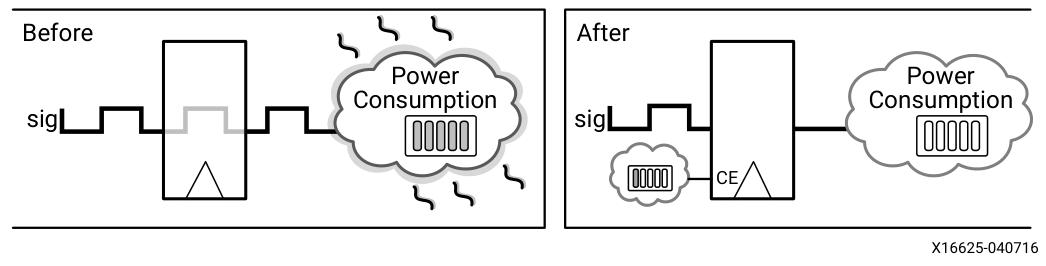
a)功耗优化作为可选步骤,提供时钟门控功能以降低动态功耗。该功能支持项目模式和非项目模式,可在逻辑优化或布局阶段灵活启用,有效减少设计功耗需求。AMD时钟门控解决方案可在保持设计功能不变的前提下,显著降低动态功耗。
b)Vivado功耗优化工具会对设计进行全面分析,包括传统IP和第三方IP模块。其智能识别可优化场景:对非周期读取但仍持续切换的信号实施时钟门控,从而减少信号切换活动,降低动态功耗。
1)工具充分利用设计中的时钟使能资源,构建门控逻辑驱动寄存器时钟使能端。该机制确保寄存器仅在数据捕获周期工作,避免无效时钟周期消耗。需要注意的是,在实际芯片中,CE通过切断非必要时钟信号实现门控功能,而非在触发器D/Q端进行选择。这种实现方式既提升了CE输入性能,又有效降低了时钟相关功耗。
c)智能时钟门控
1)
2)时钟门控还能降低BRAM的功耗,支持简单双端口和真双端口两种模式,这类BRAM包含多个使能信号,分别为:阵列使能、写使能、输出寄存器时钟使能。大部分功耗节省来自阵列使能的使用。Vivad 功耗优化器实现了特定功能:当无数据写入且输出未被使用时,自动降低BRAM的功耗。
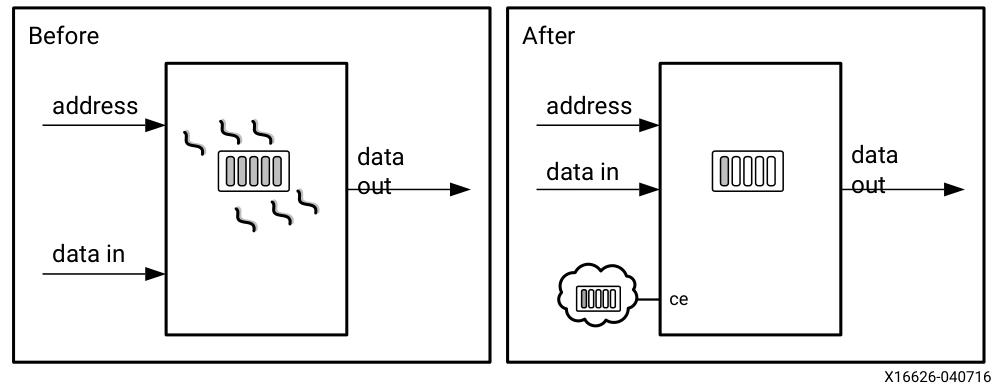
d)power_opt_design
1)power_opt_design命令用于分析和优化设计功耗。该命令默认对整个设计进行操作,通过智能时钟门控技术在不改变设计功能的前提下降低动态功耗。如需针对特定模块进行优化,可使用set_power_opt命令配置优化范围,包括:指定包含或排除的单元类型、限定优化的层次结构、设置opt_design中需要优化的特定BRAM单元。
2)set_power_opt -include_cells -exclude_cells -clocks -cell_types -quiet -verbose
3)注意事项: 当opt_design已执行BRAM功耗优化时,power_opt_design将自动跳过相应的优化步骤。
布局
a)Vivado布局器同步优化三个关键指标:时序裕量(优先为时序关键路径上的单元选取能改善负时序的位置)、线长(以最小化总线长为目标,降低信号延迟和功耗)、拥塞(实时监测引脚密度,通过合理分布单元来预防布线拥塞)。
b)布局开始前,Vivado自动执行双重设计规则检查:用户自定义DRC(基于report_drc命令选择的检查项)和系统内置DRC(检测非法布局情形,如未定位的内存IP单元或I/O bank中的电平标准冲突)。
c)设计规则检查完成后,布局器首先处理时钟单元和I/O单元,这些元件受器件物理布局规则的严格约束。针对UltraScale系列和Versal器件,还会分配时钟轨道并完成时钟预布线。同时会处理带IOB属性的寄存器:将标记为TRUE的寄存器映射到I/O逻辑位点,若无法实现则会触发严重告警。优先布局的核心资源包括:I/O端口及关联逻辑、全局时钟缓冲器(BUFG)、时钟管理模块和GT单元。
d)未固定布局逻辑时,布局器将严格遵循物理约束(包括LOC属性及Pblock分配),并校验现有LOC约束与网表连接性、器件位点的兼容性。特定IP(如内存IP、GT模块)在生成时会自带器件级布局约束,布局器将自动遵守此类约束。受器件I/O架构限制,LOC约束常会级联影响非直接关联单元。例如,对输入端口设置LOC约束时,将同时固定其关联的I/O缓冲器、IDELAY和ILOGIC单元的物理位置;且不允许对输入路径中的单个单元设置冲突的LOC约束。输出端口及GT相关单元遵循类似约束规则。
e)时钟与I/O布局失败的典型原因:
1)时钟树异常:由约束冲突(如时钟域重叠)或结构过于复杂导致布局器解析失败;
2)存储/DSP块冲突:RAM、DSP模块布局与Pblock等约束产生冲突;
3)资源超额使用:目标器件的特定资源(如I/O位点、时钟缓冲器)使用率超过上限;
4)I/O bank规则不符:违反I/O bank的电压、IOSTANDARD等电气约束。
部分情况下,布局器会采用试探性布局策略:先将关键单元临时放置在候选位点,再尝试布局其他单元。这种临时布局结果往往能有效定位故障根源,手动调整其中失败的单元可能促进布局收敛。建议先执行place_ports命令单独处理时钟与I/O布局,再运行place_design完成整体布局。若端口布局失败,相关结果仍会保留在内存中以便分析(可通过place_ports -help查看详细参数说明)。
f)布局阶段
1)全局布局(Global Placement):
i)平面规划:将设计划分为逻辑集群,基于I/O和时钟资源位置确定初始布局(Pblock视为硬约束)。针对SSI器件,会执行SLR分区以降低跨区延迟。
ii)物理合成:基于平面规划后的初始布局,因已知单元的初始位置,可针对性优化以减少拥塞、提升时序,核心优化内容包括:
①控制集优化:仅Explore指令触发,结合布局位置信息,更精准地合并逻辑等效的控制信号,如复位、时钟使能,减少控制集数量;
②LUT组合优化:将两个输入重叠的LUT原语映射到同一物理LUT位点,减少LUT资源占用。非时序关键路径优先组合,时序关键路径保留独立LUT以优化延迟;
③自动流水线插入:对用户标记的网表,插入流水线寄存器以缓解时序压力,随后调整寄存器位置以提升时钟频率;
④属性驱动重定时:基于属性的重定时通过在寄存器或查找表上设置属性,实现用户可控的重定时操作。该优化非常适合时序起点或终点存在足够余量的关键路径。通过调整寄存器在路径中的位置,平衡延迟分布以改善关键路径时序。在布局器物理合成阶段中,重定时由两个属性控制:PSIP_RETIMING_BACKWARD设为TRUE时执行反向重定时(将寄存器向信号传播反方向移动);PSIP_RETIMING_FORWARD设为TRUE时执行正向重定时(将寄存器向信号传播正方向移动)。当PSIP_RETIMING_FORWARD设为TRUE并应用于寄存器时,PSIP会对该寄存器Q端驱动的所有LUT负载执行正向重定时(即把寄存器向LUT方向移动,缩短信号从寄存器到LUT的延迟)。当 PSIP_RETIMING_FORWARD设为TRUE并应用于LUT原语时,仅对与该LUT相关的路径执行正向重定时(不影响其他路径,精准控制优化范围)。当PSIP_RETIMING_BACKWARD设为TRUE并应用于寄存器时,PSIP会对驱动该寄存器D端的LUT执行反向重定时(即把寄存器向LUT方向移动,缩短信号从LUT到寄存器的延迟),需注意对寄存器设置反向重定时属性时,不会触发控制集引脚驱动LUT的反向重定时。当PSIP_RETIMING_BACKWARD设为TRUE并应用于LUT原语时,由该LUT驱动的寄存器会被移动到LUT的输入端(进一步缩短LUT 到寄存器的延迟)。若需对多级逻辑路径执行重定时,需将上述属性应用于路径上的所有LUT原语,所有经过重定时的单元,其PHYS_OPT_MODIFIED属性会被设为RETIMING,便于跟踪优化记录。
⑤高扇出优化:该优化会复制驱动极高扇出网表的寄存器,适用场景为网表扇出>1000且时序裕量<2.0ns。
⑥关键单元优化:该优化通过复制时序关键路径中的关键单元来改善时序。当检测到某个驱动单元的负载分布较分散时,工具会自动复制该单元,并将新复制的驱动单元放置在更靠近负载集群的位置。此优化特别适用于驱动BRAM、UltraRAM或大量DSP的网表,因为这些宏单元在器件上的物理分布范围较广。触发条件仅需时序裕量小于0.5ns,无需满足高扇出要求。
⑦扇出优化:当网表的实际扇出值超过其MAX_FANOUT属性设定值时,即触发扇出优化。通过添加FORCE_MAX_FANOUT属性,可强制复制驱动寄存器或查找表。该属性值定义了优化后每个驱动单元允许的最大物理扇出数。需要注意的是,物理扇出计算的是实际器件位点的引脚负载,而非逻辑负载。例如,若复制的驱动单元在同一SLICE内驱动多个LUTRAM,这些负载仅计为1个物理扇出。该优化在物理合成阶段强制执行,不受信号时序裕量影响。
⑧DSP寄存器优化:若能改善关键路径的延迟,该优化可将寄存器从DSP单元移出到逻辑阵列,或从逻辑阵列移入到DSP单元。
⑨移位寄存器转流水线优化:通过将固定长度的移位寄存器转换为可动态调整的流水线结构,并优化流水线布局来提升时序性能。本优化仅在移位寄存器查找表的PHYS_SRL2PIPELINE属性设置为TRUE时生效。注意:寄存器提取/插入操作仅作用于SRL的Q端,且该优化不支持动态长度的SRL结构。
⑩BRAM寄存器优化:若能改善关键路径的延迟,该优化可将寄存器从BRAM单元移出到逻辑阵列,或从逻辑阵列移入到BRAM单元。
2)详细布局(Detailed Placement)
i)详细布局将设计从初始全局布局转变为完全布局完成的设计,通常从最大的结构(这些结构作为良好的锚点)开始,逐步处理至最小的结构。详细布局流程首先布局大型宏单元,如多列UltraRAM、BRAM和DSP块阵列,随后布局LUTRAM阵列宏单元,以及小型宏单元(如用户定义的XDC宏单元)。逻辑布局会反复进行,以优化线长、时序和拥塞。LUT-FF对被打包到CLB中,同时存在额外约束:CLB内的寄存器必须共享相同的控制集。
3)布局后优化
i)关键路径布局优化:调整时序关键路径上单元的位置,减少路径延迟;
ii)BUFG复制:针对非Versal器件,若BUFG驱动的网表跨越多个SLR,则为每个SLR分配独立的BUFG驱动。该优化会在以下场景中跳过:存在布局 / 布线冲突、有阻止复制的约束、或优化会导致时序退化;
iii)可选的BUFG插入:布局器将高扇出网表路由到全局布线轨道,以释放普通布线资源。不同架构触发条件如下:UltraScale/UltraScale+器件:网表扇出>1000,且驱动的控制信号时序裕量>1.0ns;Versal器件:网表扇出>10000,且驱动的控制信号时序裕量>1.0ns。优化时会将负载分为关键负载和高正裕量负载,高正裕量负载通过BUFGCE驱动,关键负载则保持与原驱动的连接。仅当优化不会导致时序退化时才会执行;若优化所需的网表编辑失败,该优化也会跳过。BUFG插入默认启用,可通过-no_bufg_opt选项禁用。
g)自动指令(Auto Directives):针对时序难收敛的设计,可通过Auto_1/Auto_2/Auto_3指令让工具基于机器学习预测最优策略(无需手动尝试所有指令),建议运行3个Auto指令并选择最优结果。工具会在日志中报告预测的指令(如INFO: Place 30-1947 Predicted directive using ML models is: EarlyBlockPlacement)。
h)使用开关
1)-no_bufg_opt:禁用布局后优化中的BUFG插入功能(默认启用),避免全局轨道资源占用冲突;
2)-no_psip:禁用布局器PSIP阶段,仅执行基础布局(适用于无需物理优化的场景);
3)-no_timing_driven:禁用时序驱动布局,仅基于线长优化(编译快但忽略时序约束,仅用于资源评估);
4)-post_place_opt:启用额外的布局后优化迭代,针对时序紧张的设计进一步修复关键路径(增加编译时间);
5)-sll_align_opt:SSI 器件专属,尝试对齐驱动超级长线SLL的寄存器,减少跨SLR延迟(单芯片器件忽略);
6)-timing_summary:布局后输出基于静态时序引擎的时序摘要(更精准,需额外编译时间),默认输出布局器内部估算值;
7)-ultrathreads:仅UltraScale+ SSI与vu440器件支持,通过多线程均匀分配SLR布局任务,加速编译(结果略有差异);
8)-unplace:取消所有无固定位置(IS_LOC_FIXED=FALSE)的单元与端口布局,保留固定位置对象;
9)-verbose:输出布局过程的详细日志(如单元布局位点、优化决策),默认关闭(避免日志冗余)。
物理优化
a)物理优化针对设计中的负时序裕量路径执行时序驱动优化,包含两种运行模式:布局后模式(post-place)与布线后模式(post-route)。
1)在布局后模式下,优化基于单元布局的时序估算值展开:物理优化会自动整合逻辑优化导致的网表变更,并根据需要调整单元布局。
2)在布线后模式下,优化基于实际布线延迟展开:除自动更新网表(逻辑变更时)和调整单元布局外,物理优化还会根据需要自动更新布线。
3)布线后物理优化仅在失败路径较少的设计中效果最佳。若设计的最差负时序裕量(WNS)<-0.200ns,或失败端点超过200个,使用布线后物理优化会导致编译时间显著延长,而QoR提升有限。
4)布局后模式的物理优化更激进,该阶段存在更多逻辑优化空间;而布线后模式更保守,目的是避免破坏已时序收敛的布线。在运行物理优化前,工具会先检查设计的布线状态,自动判断应使用布局后模式还是布线后模式。
5)若设计存在负时序裕量,当执行包含时序优化选项的物理优化时,命令将立即终止且不进行任何优化操作。为兼顾编译效率与设计性能,物理优化仅会针对前百分之几的最关键失效路径进行处理,不会自动优化所有失效路径。建议多次连续运行物理优化命令以逐步消除设计中的时序违例路径。
b)Vivado可通过选择对应的命令选项,将物理优化限制为特定类型,即仅运行指定的优化,其他优化(即使默认启用的优化)均会被禁用。当对原语单元执行优化后,该单元的PHYS_OPT_MODIFIED属性会被更新,以反映其经历的优化操作。若同一单元经历多次优化,PHYS_OPT_MODIFIED的值会以列表形式按优化发生的顺序记录所有操作。
c)优化内容
1)扇出优化:筛选扇出值高且负时序裕量处于最差负时序裕量(WNS)一定百分比范围内的网表,将其纳入驱动复制的优化范围。根据负载的位置邻近性进行聚类,为每个负载集群复制驱动单元,并将新驱动布局在靠近集群的位置。优化后会重新分析时序,仅当时序得到改善时,才提交这些逻辑变更。
2)布局优化:通过重新布线关键路径上的网表与引脚,选择延迟更短的布线资源,优化关键路径时序。
3)重构优化:通过交换LUT上的连接关系,减少关键信号的逻辑层级(例如将3级LUT逻辑简化为2级),同时修改LUT的逻辑方程以确保设计功能不变,最终优化关键路径延迟。
4)关键单元优化:对时序失败路径中的单元进行复制优化,若某一单元的负载在器件上分布过于分散(导致单驱动无法覆盖所有负载,局部延迟超标),则复制该单元,并将新生成的驱动布局在更靠近各负载集群的位置。
5)时钟优化:默认情况下,物理优化中的时钟优化采用基于路径的模式,聚焦设计中的特定路径(尤其是关键路径)进行优化,有助于改善关键路径的时序,且每次优化后可增量更新时序,评估对设计性能的影响。通过-clock_opt开关可启用基于阶段的时钟优化,将优化过程划分为多个独立阶段,每个阶段针对设计的特定模块(如UltraRAM、BRAM、DSP),利用useful clock skew,即通过调整时钟到达不同端点的时间差,补偿数据路径延迟,尤其通过IRI_QUAD(互连资源象限)中的CLK_MOD(时钟调制器)改善负建立时间裕量。需注意:部分设计中,可能因输出裕量不足,导致无法有效借用时钟skew进行优化。
(未完待续)