文章目录
- 一、布隆过滤器的两个核心参数是什么?
- 二、计算公式
-
- [1、位数组大小 m:](#1、位数组大小 m:)
- [2、哈希函数数量 k:](#2、哈希函数数量 k:)
- [三、实战计算:n = 100000,误判率 = 1%](#三、实战计算:n = 100000,误判率 = 1%)
-
- [1、计算 m(位数组大小)](#1、计算 m(位数组大小))
- [2、计算 k(hash 函数数量)](#2、计算 k(hash 函数数量))
- 四、直观对比:不同误判率下,所需内存差多少?
- [五、Redisson 的参数与布隆过滤器公式的对应关系](#五、Redisson 的参数与布隆过滤器公式的对应关系)
- 六、总结
在实际开发中,布隆过滤器(Bloom Filter)经常被用来 防止缓存穿透、过滤无效 ID、减少数据库压力 。
在 医院信息系统(HIS/EMR/LIS) 中,"按患者ID查询"、"按报告单号查询" 等接口非常多,一旦有大量非法 ID 请求穿透缓存,数据库就会被大量"空查"拖垮。
布隆过滤器通过"空间换时间"的方式,让我们能:
- 迅速判断一个 key 是否一定不存在
- 用极少内存存大量数据
- 允许极小概率的误报(false positive)
一、布隆过滤器的两个核心参数是什么?
无论你在什么业务里使用布隆过滤器,你都必须确定这两个参数:
- n :预计要插入的元素数量
例如:医院系统预计存 30 万个患者ID - p :可接受的误判率(false positive probability)
常见取值:10%(0.1)、1%(0.01)、0.1%(0.001)
确定了 n 和 p 之后,布隆过滤器的其余两个参数就可以通过公式求得:
- m:位数组长度(bit 数量)
- k:哈希函数数量(几个 hash 函数)
这两个决定了你的布隆过滤器的性能和准确性。
二、计算公式
布隆过滤器有一套经典数学推导
1、位数组大小 m:
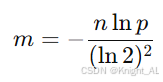
2、哈希函数数量 k:
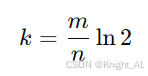
它们由 n 和 p 唯一确定。
这就是为什么 Guava 的 BloomFilter 只让你输入:
java
expectedInsertions, fpp剩下的它自动算。
三、实战计算:n = 100000,误判率 = 1%
假设你有一个医院系统,每天会产生很多 "按患者ID查询" 的请求。
你预估布隆过滤器里会放 10 万条患者ID。
java
long expectedInsertions = 100_000; // n
double fpp = 0.01; // p = 1%把它们代入公式:
1、计算 m(位数组大小)
最终结果:
m ≈ 958,506 bit
换算成内存:
| 单位 | 数值 |
|---|---|
| 字节(byte) | 958,506 / 8 ≈ 119,813 B |
| KB | ≈ 117 KB |
👉 也就是说:
10 万数据 + 1% 误判率,一个布隆过滤器只需要约 117 KB 内存。
太省了!
2、计算 k(hash 函数数量)
计算结果:
k ≈ 6.64
实际取整数:
一般选择 6 或 7 个 hash 函数
四、直观对比:不同误判率下,所需内存差多少?
假设固定 n = 100000
| fpp(误判率) | m(bit) | 约内存 | k(hash 数量) | 说明 |
|---|---|---|---|---|
| 0.1 (10%) | ≈ 479,253 | ≈ 60KB | ≈ 3 | 误报较多,最省内存 |
| 0.01 (1%) | ≈ 958,506 | ≈ 117KB | ≈ 7 | 常用折中方案 |
| 0.001 (0.1%) | ≈ 1,437,759 | ≈ 180KB | ≈ 10 | 误报极低,更费内存 |
你会发现:
- 误判率每降低 10 倍(10% → 1% → 0.1%)
→ 内存大约多一半
→ hash 函数数量也逐渐变多
这就是你在选择 fpp 时要"权衡"的地方。
五、Redisson 的参数与布隆过滤器公式的对应关系
与 Guava 一样,Redisson 的布隆过滤器使用也非常简单 。
你仍然只需要告诉它两件事:
- 预计存多少条数据?(n)
- 可接受的误判率?(p)
剩下的复杂计算(m、k)全部由 Redisson 自动完成。
Redisson 布隆过滤器的使用方式如下:
java
RBloomFilter<Object> bloomFilter = redissonClient.getBloomFilter("sky:bloom:filter");
// n = expectedInsertions(预计元素数量)
// p = falseProbability(期望误判率)
bloomFilter.tryInit( expectedInsertions, falseProbability );参数说明对应布隆过滤器公式:
| Redisson 参数名 | 数学公式名 | 说明 |
|---|---|---|
expectedInsertions |
n | 预计存入的元素数量 |
falseProbability |
p | 可接受误判率 |
| Redisson 自动计算 | m | 二进制数组长度 |
| Redisson 自动计算 | k | 哈希函数个数 |
你只管告诉 Redisson:我要多少容量?误判率多少?
示例:
java
RBloomFilter<Object> bloomFilter = redissonClient.getBloomFilter("sky:bloom:filter");
bloomFilter.tryInit(100000, 0.01); // n=10 万,p=1%Redisson 自动:
- 根据 n 和 p 计算最优 bit 数组长度 m
- 根据公式计算最优 哈希函数个数 k
- 自动构建布隆过滤器,无需你手动计算任何公式
结论
无论是 Guava 还是 Redisson,布隆过滤器的核心数学公式完全相同。
不同的是:
| 框架 | 存储位置 | 适用场景 |
|---|---|---|
| Guava | 本地 JVM 内存 | 单机项目、小工具 |
| Redisson | Redis 集群 | 分布式系统、微服务、缓存穿透防护 |
你的项目是微服务,所以必须用 Redisson 才能让多个服务共享同一个 BloomFilter。
六、总结
布隆过滤器虽然简单,但非常适合医院系统、金融系统、订单系统等需要"快速存在校验"的场景。
你只需要记住这几句话:
- 只要确定
n和p,就能唯一算出m和k - 高精度(低误判率)意味着更大内存、更多 hash
- 已经帮你封装好所有数学细节
- 在医院系统里能有效防止缓存穿透,保护数据库
布隆过滤器的本质是:
用极少的内存,换取极高的性能保障。