TL;DR
- 场景:想在自研业务里借鉴 Netflix 的 EVCache 体系,但只知道 "基于 Memcached 的分布式缓存"。
- 结论:从 EVCache/Rend/Memcached/Mnemonic 四层拆开,看清缓存层职责边界、性能天花板和多可用区复制模型。
- 产出:一套可落地的架构理解框架 + 典型部署路径 + 常见错误速查卡,可直接对照你现有缓存架构做差距评估

版本矩阵
| 模块 / 主题 | 验证状态 | 说明 |
|---|---|---|
| EVCache 架构与命名含义 | 部分验证 | 基于 Netflix 官方/社区文档与公开演讲整理,文中未给出具体版本号。 |
| EVCache 性能数据与规模案例 | 未完全验证 | QPS、请求总量、延迟、命中率等指标参考官方/社区公开数据,建议标注数据来源与时间。 |
| Rend 高性能代理特性 | 基于资料验证 | Go 实现、高并发、连接池、协议支持等描述与官方设计方向一致,未结合自家压测数据。 |
| Memcached 特性与性能指标 | 未完全验证 | 内存存储、LRU、数据类型描述准确;"单节点 QPS 可达 50 万"依赖硬件与配置,建议注明条件。 |
| Mnemonic(RocksDB + SSD 引擎) | 基于资料验证 | LSM-tree、WAL、Direct I/O 等特性来自官方/社区说明,本文未给出本地实测指标。 |
| 单可用区部署流程(注册/哈希/连接池) | 部分验证 | 与典型 EVCache 实践一致,但具体实现细节可能随内部版本调整。 |
| 多可用区复制流程(Kafka + Propagator) | 基于资料建模 | 复制链路和最终一致性描述合理,属于工程级推演总结,非逐项实验报告。 |
EVCache
EVCache 是一个由Netflix网飞公司开发的开源、高性能分布式缓存系统。它基于Memcached的内存存储架构,并采用Spymemcached客户端实现,专为大规模分布式环境设计。
EVCache名称的每个字母都有其特定含义:
- E:Ephemeral(短暂的) - 表示数据存储具有时效性,系统会为每个数据项设置存活时间(TTL),超过期限后自动失效。例如,在Netflix的内容推荐系统中,用户偏好数据可能设置15分钟的存活时间。
- V:Volatile(易失的) - 强调数据的非持久性特征,数据可能因节点故障、内存回收或系统重启等原因随时丢失。这种特性使得EVCache不适合存储关键业务数据。
- Cache:内存级键值对存储 - 采用类似Memcached的内存哈希表结构,支持高速的键值存取操作,典型访问延迟在毫秒级别。
EVCache的主要特点包括:
- 线性扩展能力:通过一致性哈希算法实现节点动态增减
- 多区域部署:支持跨数据中心的数据复制
- 监控集成:提供完善的指标收集和报警功能
- 客户端智能路由:能自动处理节点故障和网络分区
典型应用场景包括:
- 内容推荐系统的临时数据缓存
- 用户会话状态存储
- 热点数据加速访问
- 分布式锁服务
在Netflix的生产环境中,EVCache集群规模可达数千个节点,每日处理数万亿次请求,是支撑其全球流媒体服务的关键基础设施之一。
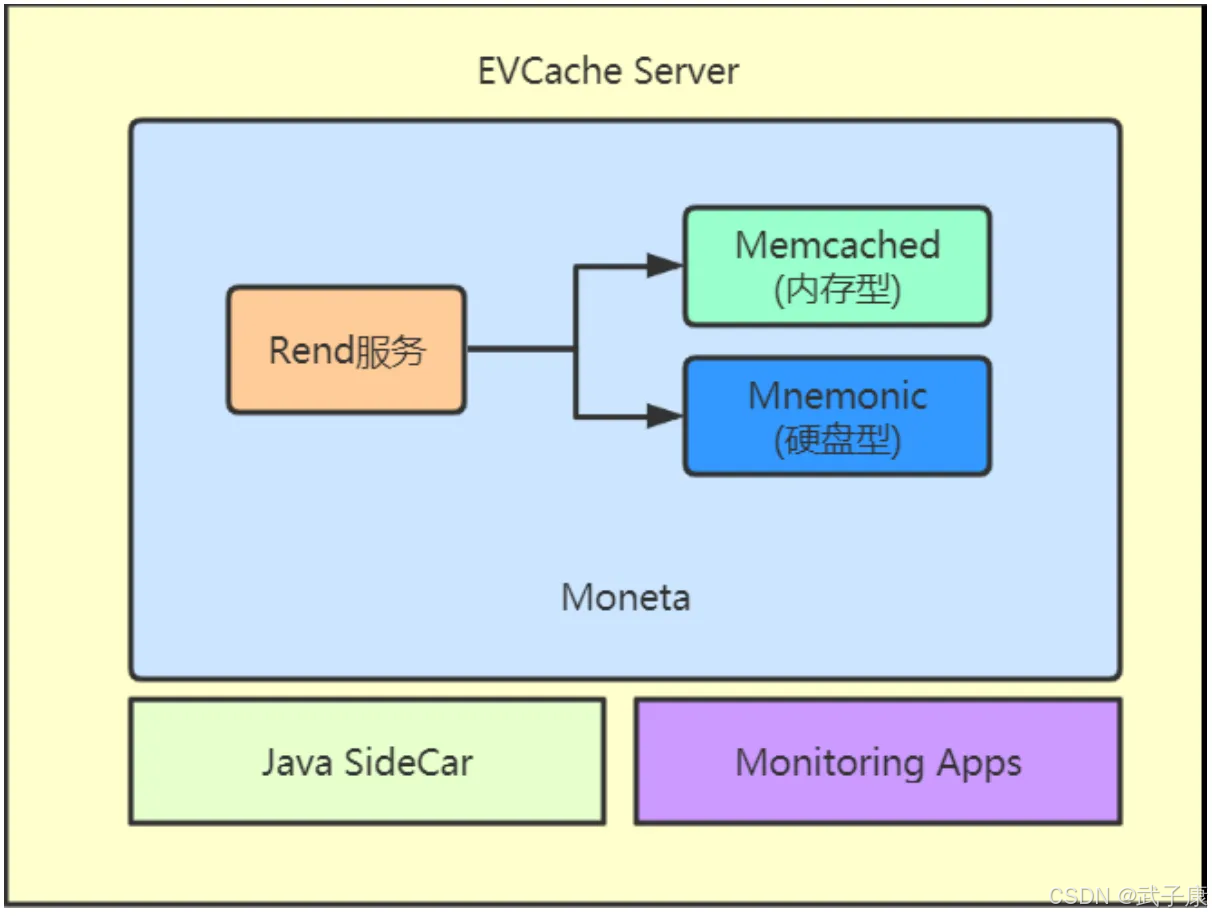
Rend服务
Rend是一个高性能的代理服务,采用Go语言编写,专为处理高并发场景优化。其核心特性包括:
- 高性能架构:利用Go语言的goroutine和channel机制实现轻量级并发处理
- 连接池管理:内置智能连接复用机制,显著降低TCP握手开销
- 协议支持:兼容Memcached二进制协议和文本协议
- 负载均衡:支持一致性哈希算法实现后端节点动态分配
典型应用场景:
- 作为缓存中间层部署在Web应用与Memcached集群之间
- 在微服务架构中充当分布式缓存访问的统一入口
Memcached
基于内存的分布式键值存储系统,主要特点:
- 内存存储:所有数据存储在RAM中,提供微秒级响应
- LRU淘汰机制:当内存不足时自动淘汰最近最少使用的数据
- 集群架构:支持多节点部署,通过客户端哈希算法实现数据分片
- 数据类型:仅支持字符串类型值,最大1MB的单条数据
性能基准:
- 单节点QPS可达50万次/秒
- 典型部署包含8-32个节点组成的集群
Mnemonic
基于SSD的嵌入式键值存储引擎,技术实现:
- 存储引擎:深度封装RocksDB(Facebook开源的LSM-tree存储引擎)
- 硬件优化 :
- 针对SSD特性优化写放大问题
- 使用Direct I/O绕过系统缓存
- 持久化特性 :
- 支持WAL(Write-Ahead Logging)确保数据安全
- 提供快照备份功能
- 性能表现 :
- 随机读取延迟<1ms
- 顺序写入吞吐量可达200MB/s
部署模式对比:
| 特性 | Memcached | Mnemonic |
|---|---|---|
| 存储介质 | 内存 | SSD |
| 持久化 | 不支持 | 支持 |
| 单条大小限制 | 1MB | 无限制 |
| 适用场景 | 热点缓存 | 持久存储 |
性能相关
EVCache 作为 Netflix 大规模分布式缓存系统的核心组件,其性能表现和扩展能力在业界处于领先水平。在标准配置下,单个 EVCache 节点集群的峰值处理能力可达每秒200KB请求量。然而在实际生产环境中,Netflix 通过智能化的集群部署策略,将 EVCache 的性能发挥到了极致:
-
超大规模部署:
- 全球范围内部署超过数千台 memcached 服务器节点
- 采用多区域(Multi-Region)架构设计,实现地理分布式缓存
- 通过一致性哈希算法实现数据分片和负载均衡
-
惊人的处理能力:
- 日常请求处理峰值超过每秒3000万个操作(包括 get/set/delete)
- 存储对象数量级达到数十亿级别(约50-100亿个缓存对象)
- 日均请求总量接近2万亿次,相当于每分钟处理约13.9亿次请求
-
卓越的性能指标:
- 响应延迟:在正常负载下保持1-5毫秒的极低延迟
- 峰值延迟:即使在流量洪峰时,99%的请求也能在20毫秒内完成
- 命中率:通过智能缓存淘汰算法(LRU)和预热策略,维持99%的超高命中率
- 示例场景:用户浏览电影详情页时,所有推荐数据、评分信息都能在10ms内从缓存获取
-
高可用保障:
- 采用多副本机制,单节点故障不会影响服务可用性
- 通过实时监控和自动故障转移确保服务连续性
- 支持滚动升级,维护期间仍能保持99.99%的可用性
这种性能表现使得 EVCache 能够完美支撑 Netflix 的全球视频流媒体服务,特别是在应对热门剧集上线时的瞬时流量爆发场景中展现出卓越的弹性扩展能力。EVCache 作为 Netflix 大规模分布式缓存系统的核心组件,其性能表现和扩展能力在业界处于领先水平。在标准配置下,单个 EVCache 节点集群的峰值处理能力可达每秒200KB请求量。然而在实际生产环境中,Netflix 通过智能化的集群部署策略,将 EVCache 的性能发挥到了极致:
-
超大规模部署:
- 全球范围内部署超过数千台 memcached 服务器节点
- 采用多区域(Multi-Region)架构设计,实现地理分布式缓存
- 通过一致性哈希算法实现数据分片和负载均衡
-
惊人的处理能力:
- 日常请求处理峰值超过每秒3000万个操作(包括 get/set/delete)
- 存储对象数量级达到数十亿级别(约50-100亿个缓存对象)
- 日均请求总量接近2万亿次,相当于每分钟处理约13.9亿次请求
-
卓越的性能指标:
- 响应延迟:在正常负载下保持1-5毫秒的极低延迟
- 峰值延迟:即使在流量洪峰时,99%的请求也能在20毫秒内完成
- 命中率:通过智能缓存淘汰算法(LRU)和预热策略,维持99%的超高命中率
- 示例场景:用户浏览电影详情页时,所有推荐数据、评分信息都能在10ms内从缓存获取
-
高可用保障:
- 采用多副本机制,单节点故障不会影响服务可用性
- 通过实时监控和自动故障转移确保服务连续性
- 支持滚动升级,维护期间仍能保持99.99%的可用性
这种性能表现使得 EVCache 能够完美支撑 Netflix 的全球视频流媒体服务,特别是在应对热门剧集上线时的瞬时流量爆发场景中展现出卓越的弹性扩展能力。
典型用例
Netflix 用来构建超大容量、高性能、低延时、跨区域的全球可用的缓存数据层,EVCache 典型适合对强一致性没有必须要求的场合。
典型用例:Netflix 向用户推荐用户感兴趣的电影
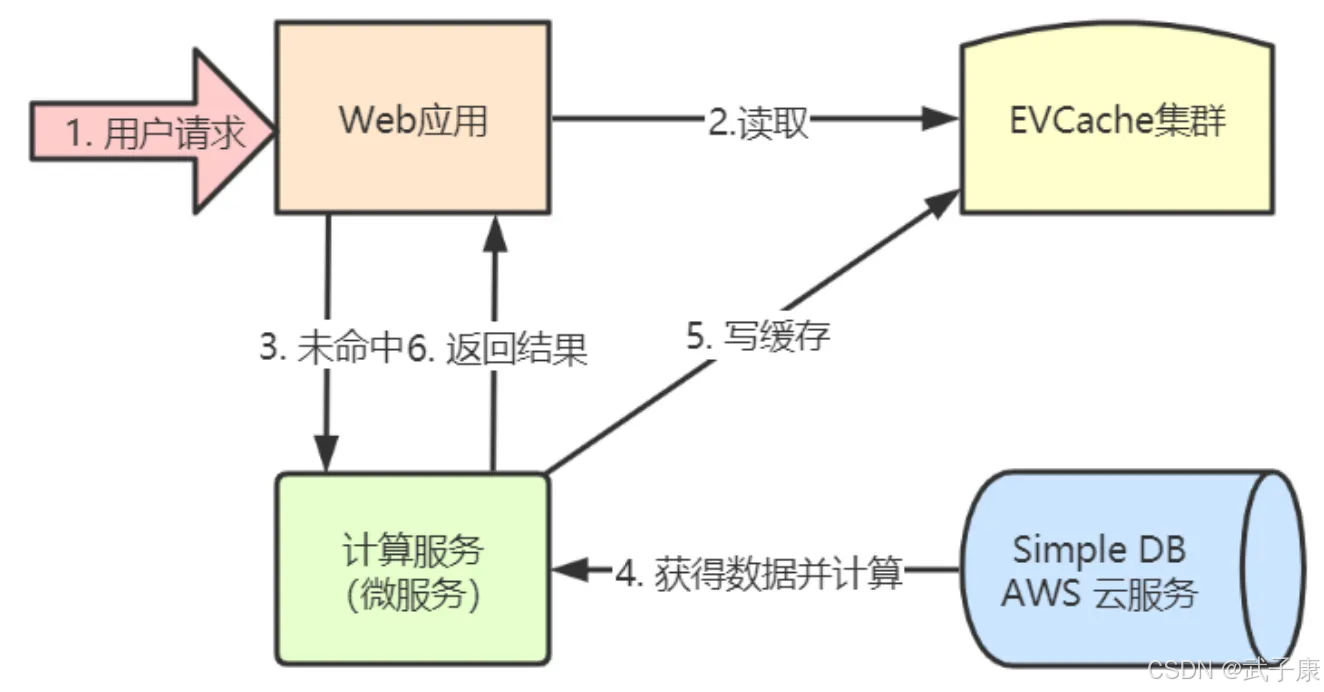
典型部署
EVCache 是线性扩展的,可以在一分钟之内完成扩容,在几分钟之内完成负载均衡和缓存预热。
单节点部署
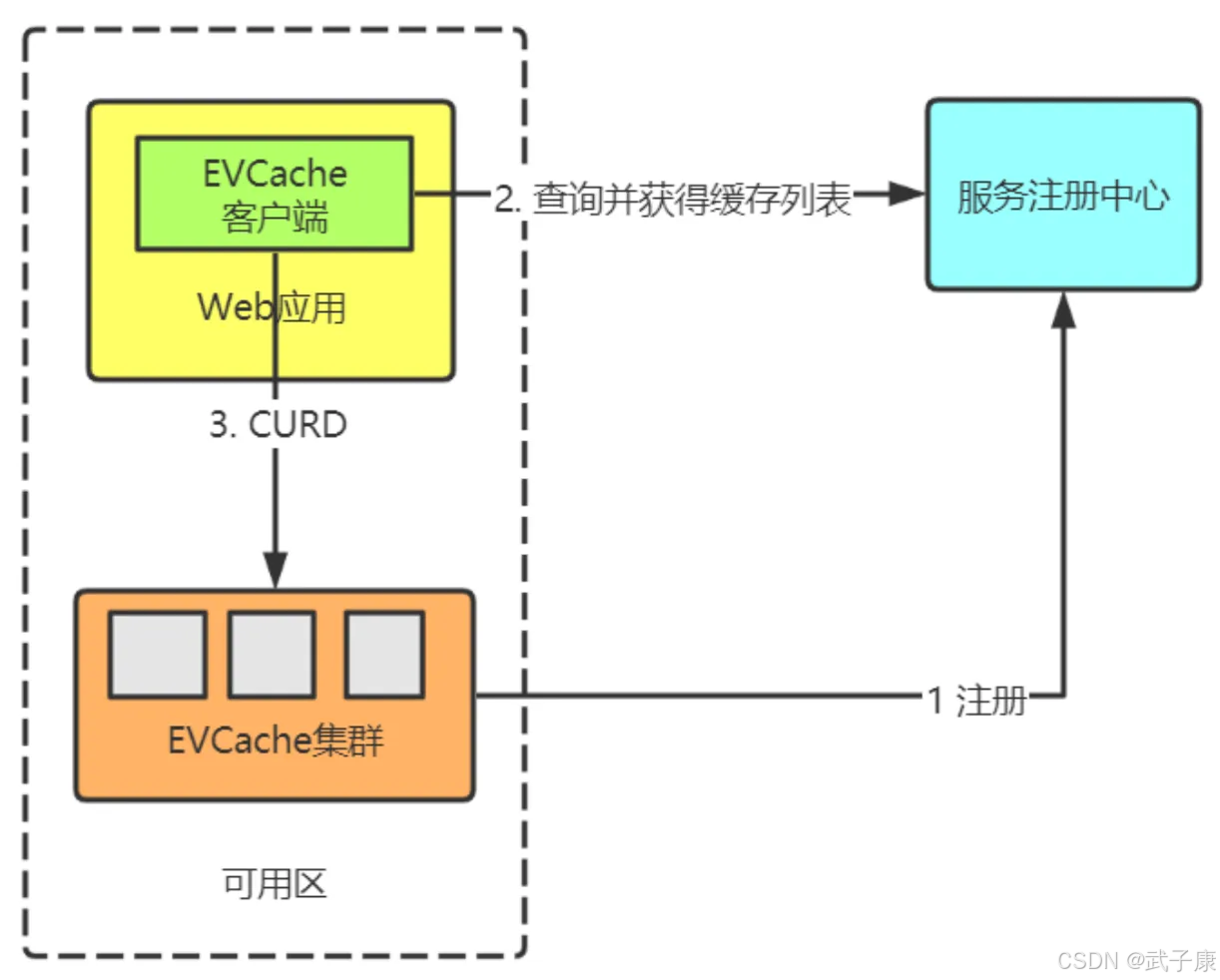
-
集群启动阶段:
- EVCache服务器实例启动时,会自动向服务注册中心(如ZooKeeper或Eureka)发送注册请求。每个实例会携带元数据信息,包括:
- 服务器IP地址和端口
- 可用内存容量
- 当前负载状态
- 所属的集群名称(如"EVCache-Production")
- 注册中心会将这些信息组织成树状结构(ZooKeeper)或服务列表(Eureka),供客户端查询
- 注册成功后,EVCache实例会定期发送心跳包(通常30秒一次)维持注册状态
- EVCache服务器实例启动时,会自动向服务注册中心(如ZooKeeper或Eureka)发送注册请求。每个实例会携带元数据信息,包括:
-
客户端初始化阶段:
- Web应用启动时,EVCache客户端组件会:
- 从配置文件中读取命名服务地址(如ZooKeeper集群地址)
- 连接命名服务,查询"/evcache/servers"路径下的服务器列表
- 获取所有可用EVCache服务器的IP、端口和状态信息
- 建立TCP长连接池(默认每个服务器10-20个连接)
- 初始化一致性哈希环,根据服务器节点信息计算虚拟节点分布
- 客户端会订阅命名服务的变更通知,当服务器列表变化时自动更新连接池
- Web应用启动时,EVCache客户端组件会:
-
数据操作阶段:
- 应用通过EVCacheClient接口(如get/set/delete)操作数据时:
- 客户端对Key进行MD5哈希处理,得到128位哈希值
- 使用一致性哈希算法定位目标服务器:
- 哈希环上顺时针查找第一个大于Key哈希值的虚拟节点
- 每个物理服务器对应160个虚拟节点(可配置)
- 例如Key"user_123"的哈希落在ServerB的虚拟节点范围内
- 根据配置的副本数(通常为2-3),继续查找后续N-1个节点作为备份节点
- 通过预先建立的连接池向主节点发送操作命令
- 如果是写操作,客户端会并行向所有副本节点发送更新请求
- 客户端内置故障转移机制,当主节点不可达时会自动尝试备份节点- 集群启动阶段:
- EVCache服务器实例启动时,会自动向服务注册中心(如ZooKeeper或Eureka)发送注册请求。每个实例会携带元数据信息,包括:
- 服务器IP地址和端口
- 可用内存容量
- 当前负载状态
- 所属的集群名称(如"EVCache-Production")
- 注册中心会将这些信息组织成树状结构(ZooKeeper)或服务列表(Eureka),供客户端查询
- 注册成功后,EVCache实例会定期发送心跳包(通常30秒一次)维持注册状态
- 应用通过EVCacheClient接口(如get/set/delete)操作数据时:
-
客户端初始化阶段:
- Web应用启动时,EVCache客户端组件会:
- 从配置文件中读取命名服务地址(如ZooKeeper集群地址)
- 连接命名服务,查询"/evcache/servers"路径下的服务器列表
- 获取所有可用EVCache服务器的IP、端口和状态信息
- 建立TCP长连接池(默认每个服务器10-20个连接)
- 初始化一致性哈希环,根据服务器节点信息计算虚拟节点分布
- 客户端会订阅命名服务的变更通知,当服务器列表变化时自动更新连接池
- Web应用启动时,EVCache客户端组件会:
-
数据操作阶段:
- 应用通过EVCacheClient接口(如get/set/delete)操作数据时:
- 客户端对Key进行MD5哈希处理,得到128位哈希值
- 使用一致性哈希算法定位目标服务器:
- 哈希环上顺时针查找第一个大于Key哈希值的虚拟节点
- 每个物理服务器对应160个虚拟节点(可配置)
- 例如Key"user_123"的哈希落在ServerB的虚拟节点范围内
- 根据配置的副本数(通常为2-3),继续查找后续N-1个节点作为备份节点
- 通过预先建立的连接池向主节点发送操作命令
- 如果是写操作,客户端会并行向所有副本节点发送更新请求
- 客户端内置故障转移机制,当主节点不可达时会自动尝试备份节点
- 应用通过EVCacheClient接口(如get/set/delete)操作数据时:
多可用区部署
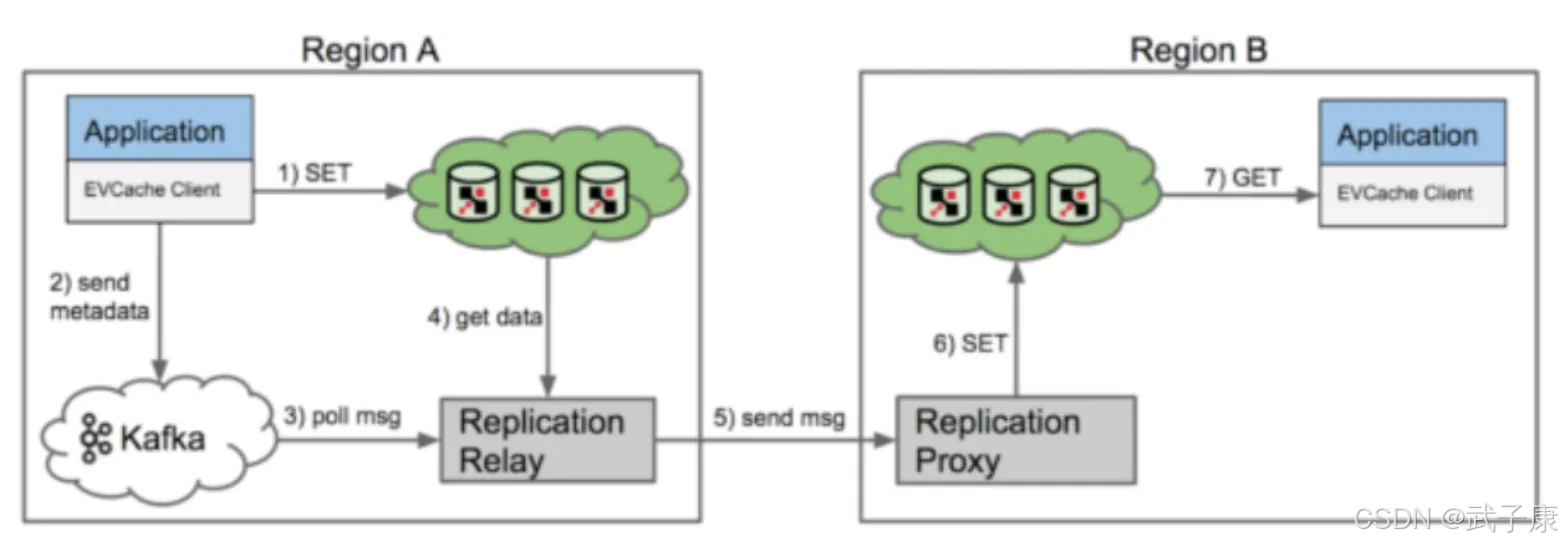
EVCache 的跨可用区复制详细流程:
- 初始写入阶段
- 应用程序通过EVCache客户端发起SET操作时,客户端包会首先将数据写入本地可用区(Zone A)的一个缓存节点实例
- 典型写入示例:客户端执行
evcache.set("user:1001", profileData),数据会立即存储在Zone A的缓存集群中
- 元数据复制准备
- 在写入本地缓存的同时,EVCache客户端库会生成一条复制元数据消息,包含:
- 操作的Key(如"user:1001")
- 操作类型(SET/DELETE)
- 时间戳
- 源可用区标识
- 该元数据会被发送到专用的跨区复制Kafka消息队列(不包含实际数据以节省带宽)
- 本地复制传播服务处理
- Zone A部署的"复制传播服务"(Replication Propagator)会持续监听Kafka队列
- 当检测到新消息时,传播服务会:
a. 解析消息获取Key信息
b. 从本地缓存中查询该Key对应的完整数据
c. 准备跨区复制请求包
- 跨可用区数据传输
- 传播服务通过内部网络将SET请求发送到目标可用区(Zone B)的"复制代理服务"(Replication Agent)
- 传输过程采用压缩和加密措施确保效率和安全
- 典型场景:当Zone A是us-west-1,需要复制到Zone B的us-east-1时
- 目标区域数据更新
- Zone B的复制代理服务收到请求后:
a. 验证请求合法性
b. 在本地缓存集群执行相同的SET操作
c. 返回操作结果给源区域
- 数据一致性保证
- 最终一致性模型:目标区域应用可能在短时间内(通常<1s)读取到旧数据
- 读取路径优化:当Zone B的应用执行GET("user:1001")时,请求会被自动路由到本地缓存节点,无需跨区访问
补充说明:
- 故障处理机制:如果跨区复制失败,系统会进行指数退避重试
- 网络隔离场景:当区域间网络中断时,复制队列会积压消息,待网络恢复后继续处理
- 数据冲突解决:基于时间戳的"最后写入获胜"策略解决可能的写冲突EVCache 的跨可用区复制详细流程:
- 初始写入阶段
- 应用程序通过EVCache客户端发起SET操作时,客户端包会首先将数据写入本地可用区(Zone A)的一个缓存节点实例
- 典型写入示例:客户端执行
evcache.set("user:1001", profileData),数据会立即存储在Zone A的缓存集群中
- 元数据复制准备
- 在写入本地缓存的同时,EVCache客户端库会生成一条复制元数据消息,包含:
- 操作的Key(如"user:1001")
- 操作类型(SET/DELETE)
- 时间戳
- 源可用区标识
- 该元数据会被发送到专用的跨区复制Kafka消息队列(不包含实际数据以节省带宽)
- 本地复制传播服务处理
- Zone A部署的"复制传播服务"(Replication Propagator)会持续监听Kafka队列
- 当检测到新消息时,传播服务会:
a. 解析消息获取Key信息
b. 从本地缓存中查询该Key对应的完整数据
c. 准备跨区复制请求包
- 跨可用区数据传输
- 传播服务通过内部网络将SET请求发送到目标可用区(Zone B)的"复制代理服务"(Replication Agent)
- 传输过程采用压缩和加密措施确保效率和安全
- 典型场景:当Zone A是us-west-1,需要复制到Zone B的us-east-1时
- 目标区域数据更新
- Zone B的复制代理服务收到请求后:
a. 验证请求合法性
b. 在本地缓存集群执行相同的SET操作
c. 返回操作结果给源区域
- 数据一致性保证
- 最终一致性模型:目标区域应用可能在短时间内(通常<1s)读取到旧数据
- 读取路径优化:当Zone B的应用执行GET("user:1001")时,请求会被自动路由到本地缓存节点,无需跨区访问
补充说明:
- 故障处理机制:如果跨区复制失败,系统会进行指数退避重试
- 网络隔离场景:当区域间网络中断时,复制队列会积压消息,待网络恢复后继续处理
- 数据冲突解决:基于时间戳的"最后写入获胜"策略解决可能的写冲突
错误速查
| 症状 | 根因 | 定位思路 | 修复 / 规避方案 |
|---|---|---|---|
| 业务把 EVCache 当"强一致持久存储",偶发读到旧数据或数据丢失 | EVCache/E = Ephemeral、V = Volatile,本质是 TTL + 易失内存缓存,跨区复制是最终一致而非强一致 | 观察跨区写入-读取延迟,检查下游是否只有缓存没有 DB;确认多副本、复制链路和 TTL 配置 | 把数据库作为真源(Source of Truth),缓存只做加速;对强一致场景单独设计(如 DB + 本地缓存 + 乐观锁) |
| 缓存命中率远低于预期,高并发场景下后端 DB 被打爆 | Key 设计无热点复用、TTL/容量过小导致频繁淘汰;业务误用"随机 key" 或强行塞超大对象 | 对比命中率、对象大小分布、淘汰原因(LRU/过期),查看业务日志中 key 模式 | 优化 key 设计(按用户/资源维度稳定命名),限制单对象大小,合理设置 TTL 和容量,必要时拆层缓存 |
| 任意一个可用区故障后,其他区读写延迟飙升,甚至出现大面积超时 | 多可用区拓扑设计不当,读流量依赖跨区访问;复制链路被误当成"读路径"使用 | 故障演练时抓取各 Zone 的 GET 路径,查看是否有跨 Region 访问;检查客户端路由配置 | 所有读请求尽量就近访问本 Region,跨区链路只做复制;对关键数据做多 Region 冗余,而非跨区强依赖 |
| 新增或缩减节点后,缓存命中率瞬间腰斩,预热时间很长,业务抖动明显 | 一致性哈希虚拟节点/扩缩容策略设置不当,导致大量 key 重映射,缓存几乎重建 | 排查扩容时间点前后的命中率曲线;对比一致性哈希环变更;查看是否做了批量下线/上线操作 | 调整虚拟节点数量,采用滚动扩缩容 + 预热策略;有条件时在扩容期间降低 TTL 或引入只读模式减缓冲击 |
| 跨可用区复制出现长时间"数据不一致",故障恢复后大量复制请求挤占带宽 | Kafka 复制队列长时间堆积;网络中断期间持续产生写请求,恢复后瞬时重放数据 | 监控复制队列长度、复制延迟;查看各 Zone 的写入峰值与网络流量;排查是否有持续网络抖动 | 为复制链路单独规划带宽,设置队列长度告警;必要时对低价值 key 降级(不复制或延迟复制) |
| 代理层 Rend/Memcached 连接耗尽,出现间歇性请求超时或连接失败 | 连接池配置过小或泄漏,客户端并发远超设计;健康检查/负载均衡策略不合理 | 查看连接数、拒绝连接、超时指标;抓取代理日志,分析连接生命周期和错误码 | 调整连接池大小与超时配置,做好连接复用;优化负载均衡策略(健康检查、慢节点摘除),避免单点热点 |
| 将 Mnemonic/SSD 引擎当成"和内存一样快"的缓存层使用,写入延迟明显升高 | SSD + RocksDB 受写放大和 I/O 限制,延迟特性与内存缓存完全不同 | 对比内存缓存与 SSD 层的 P95/P99 写延迟,检查 RocksDB 统计(写放大、Compaction 次数) | 将 Mnemonic 明确定位为"持久化 KV 层",只缓存冷数据或大对象;前置内存缓存,控制写入模式 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南!
AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-180 Java 接入 FastDFS:自编译客户端与 Maven/Spring Boot 实战
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS正在更新... 深入浅出助你打牢基础!
🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
🔗 大数据模块直达链接