继前分享的锂电池数据
精品数据分享 | 锂电池数据集(一)新能源汽车大规模锂离子电池数据集
精品数据分享 | 锂电池数据集(二)Nature子刊论文公开锂离子电池数据
精品数据分享 | 锂电池数据集(三)西安交通大学(XJTU)电池数据集
精品数据分享 | 锂电池数据集(四)PINN+锂离子电池退化稳定性建模和预测
精品数据分享 | 锂电池数据集(五)麻省理工-斯坦福-丰田研究中心电池数据集
精品数据分享 | 锂电池数据集(六)基于深度迁移学习的锂离子电池实时个性化健康状态预测
本期继续分享一篇Nature communicationTop论文公开锂离子电池数据,划重点-数据集开源, 代码开源!!!
论文题目:《Data-driven capacity estimation of commercial lithium-ion batteries from voltage relaxation》
论文链接:
https://www.nature.com/articles/s41467-022-29837-w
数据集链接:
https://zenodo.org/records/6405084
论文代码:
https://github.com/Yixiu-Wang/data-driven-capacity-estimation-from-voltage-relaxation
如果您使用此数据集,请引用作者论文:
Jiangong Zhu, Yixiu Wang, Yuan Huang, R. Bhushan Gopaluni, Yankai Cao, Michael Heere, Martin J. Mühlbauer, Liuda Mereacre, Haifeng Dai, Xinhua Liu, Anatoliy Senyshyn, Xuezhe Wei, Michael Knapp, & Helmut Ehrenberg. (2022). Data-driven capacity estimation of commercial lithium-ion batteries from voltage relaxation Data set. Zenodo. https://doi.org/10.5281/zenodo.6405084
注意:如果下载不了,后台回复"锂电池7",可获取我们已经打包好的论文、数据集和代码!
1 摘要
准确的容量估算是锂离子电池可靠、安全运行的关键。特别是,利用松弛电压曲线功能可以在没有额外循环信息的情况下进行电池容量估计。在这里,我们报告了130个商用锂离子电池在不同条件下循环的三个数据集的研究,以评估容量估计方法。收集了一个数据集,用于从LiNi0.86Co0.11Al0.03O2基正极的电池中建立模型。用于验证的另外两个数据集来自LiNi0.83Co0.11Mn0.07O2正极电池和Li(NiCoMn)O2-Li(Nicoal)O2正极混合物电池。使用机器学习方法的基本模型被用来使用从松弛电压分布得到的特征来估计电池容量。对于用于模型构建的数据集,最好的模型实现了1.1%的均方根误差。然后,通过在基本模型中添加特征线性变换来建立迁移学习模型。该扩展模型在用于模型验证的数据集上的均方根误差小于1.7%,表明利用单元电压松弛的容量估计方法是成功的。
2 前言
锂离子电池已经成为便携式电子设备、电动汽车(EVS)和许多其他应用的主要储能设备。但是,电池退化是锂离子电池使用中的一个重要问题,因为随着时间的推移,锂离子电池的性能会因不可逆转的物理和化学变化而降低。健康状态(SOH)一直被用作电池状态的指标,通常用相对剩余容量与初始容量的比率来表示。准确的电池容量估计对锂离子电池的可靠使用具有挑战性,但也是关键,即准确的容量估计可以准确地预测行驶里程和准确计算车辆的最大储能能力。通常,电池容量是在充满电后通过完全放电过程获得的。在实际使用场景中,电池充满电通常是在电动汽车并网停放时实现的,然而,电池放电取决于用户行为,环境和操作条件具有不确定性,因此很少有完整的放电曲线用于车载电池健康监测。电池的充放电电压是一个容易获得的参数,它与电池的热力学和动力学特性有关。因此,这些利用充放电过程的方法被提出用于实际应用中的容量估计,其中输入变量是从测量的电压曲线中提取的,而使用统计和机器学习技术的数据驱动方法由于其强大的数据处理和非线性拟合能力而在最近的电池研究中非常流行数据驱动方法不需要深入了解电池的电化学原理,但需要大量的数据来确保模型的可靠性。Severson等人报道了一种很有前途的方法,使用机器学习来构建模型,使用充放电电压数据准确预测石墨||LiFePO4(LFP)商业电池的寿命。Zhang等人使用高斯过程机器学习模型从阻抗谱中识别电池退化模式。丁等人介绍了一种提高膜电极组件设计和实验效率的机器学习方法。这种数据驱动的方法关注输入和输出特征之间的关系,而数据驱动的电池状态估计的一个关键部分是退化特征的提取,这在很大程度上决定了估计性能。
表1
在实际的电动交通应用中,与受驾驶行为和道路环境影响的随机放电过程相比,电池充电是必不可少的,并且经常发生。因此,从充电过程中提取电压特征引起了人们的广泛关注。考虑到现有文献,可以定义三类基于电压的提取方法:(I)基于CC(恒流)充电电压,(Ii)基于CC-CV(恒流-恒压)充电电压,和(Iii)基于补充表1中列出的剩余电压。用于特征提取的特定电压范围中的部分充电过程通常用于容量估计,基于内部实验和不同的公开数据集,最新技术水平的估计精度从0.39%的均方根误差(RMSE)到4.26%的RMSE。部分电压曲线的变换,即差分电压分析和增量容量分析,被用于电池老化机理识别和容量衰减评估。通常,使用部分增量容量曲线来应用SVR(支持向量回归)、GPPF(高斯过程粒子滤波)、BPNN(反向传播神经网络)和线性模型来估计电池容量。与基于充电电压的特征提取方法相比,从剩余电压中提取特征的研究较少。
巴格达迪等人提出了一种利用休眠过程的典型电池容量估计方法。他们提出了一个线性模型,利用电池充满电后休息30分钟后的电压来估计电池容量,对于三种不同的商业电池,容量估计百分比误差在0.7%到3.3%之间。Schindler等人和L等人把电压松弛用于电池容量衰减过程中的锂电镀检测。钱等人使用等效电路模型(ECM)来描述电压松弛,并发现提取的参数提供了对电池SOH和老化机制的评估。Attideou等人使用从电阻-电容器(RC)网络模型得出的动态时间常数,模拟了100%SoC下休息期的电池容量衰减。然而,随着rc链路的数量增加,ecm的复杂性将相应地增加,这使得其难以在车载应用中使用。此外,由于电池类型和工作条件的差异,容量估计的准确性和稳健性很难评估。
事实证明,松弛过程包括特定时刻的松弛电压值和特定时间段的电压曲线,与SOH电池有一定的关系。从对电池充电研究的回顾、EVS的实时数据以及对真实世界电动汽车充电的调查(补充说明1、补充表2和3以及补充图1和2)来看,除了CC充电策略之外,使用SoC相关充电电流的多级电流充电算法是一种很有前途的最大化充电效率的方法。电动汽车的开始充电通常分布在中间SoC周围,正如统计数据所预期的那样。在电压基法中,由于多段电流充电策略的多样性和充电点起始点的不确定性,使得在恒流条件下获得特定的电压范围变得困难。充满电后的松弛相对不受充电过程的影响,也很容易获得,因为在实际电动汽车使用中,电池充满的可能性很高,也不需要额外的设备,因为电压数据可以直接从电池管理系统获得。然而,据我们所知,目前还没有用机器学习方法对不同类型电池的大规模数据进行系统地研究电池的松弛电压曲线。为此,提出了一种基于电池松弛电压特征提取的短期电池容量估计方法,该方法在没有任何先验循环信息的情况下进行车载实现。
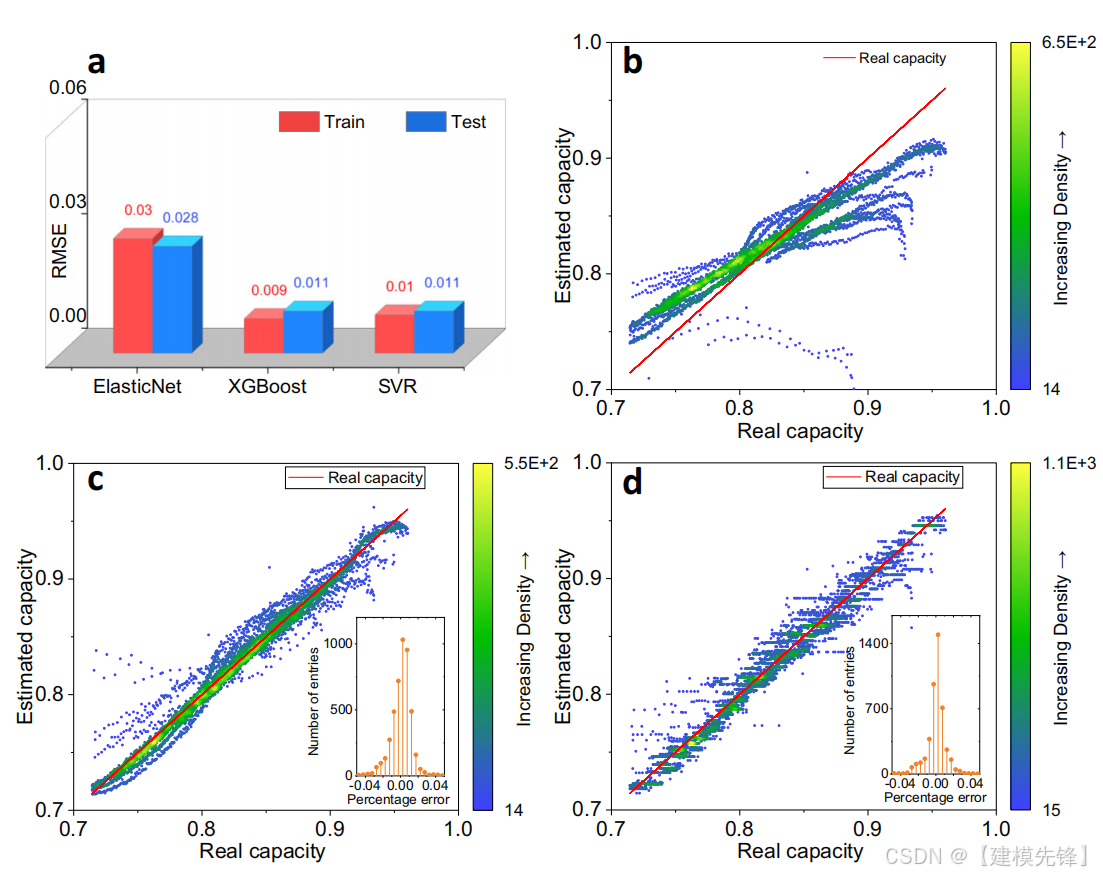
在这项研究中,使用了基于机器学习方法的基本模型,即线性模型(ElasticNet)和非线性模型(XGBoost和支持向量回归(SVR)),使用了来自三种商业锂离子电池的大数据集。模型的输入是从电压松弛曲线中提取的统计特征。使用LiNi0.86Co0.11Al0.03O2正极电池(NCA电池)在不同温度和电流速率下循环进行基础建模,RMSE为1.0%,表现出最佳的测试性能。将迁移学习方法应用于正极材料为LiNi0.83Co0.11Mn0.07O2的电池(NCM电池)和正极材料为42(3)wt.%Li(NiCoMn)O2和58(3)wt.%Li(Nicoal)O2的电池(NCM+NCA电池),分别获得1.7%和1.6%的RMSE,使该方法具有较好的通用性。
图1
在这项工作中,我们设计了一个可转移的深度网络来实现个性化和实时的锂离子电池健康状态预测,使用最近30个循环在任何感兴趣的周期的部分循环数据(图1)。为此,我们构建了一个包含77个锂离子电池的实验平台,电池的循环寿命从1100到2700次不等。电池经历不同的多级放电方案以近似使用可变性,从而总共获得146122个充放电循环。在所有充放电循环中,容量估计和RUL预测的平均测试误差分别为0.176%和8.72%。此外,我们还执行了另外两项任务,通过从另外两个数据集中转移退化知识来预测数据集中测试电池的健康状态,这两个数据集中分别具有不同的充放电条件和不同的电池化学成分。在接下来的两个任务中,容量估计和RUL预测的平均测试误差分别为0.328%(0.193%)和9.80%(9.9%)。这些结果说明了深度迁移学习框架根据个性化使用模式进行健康状态预测的有效性和泛化能力。
3 结果
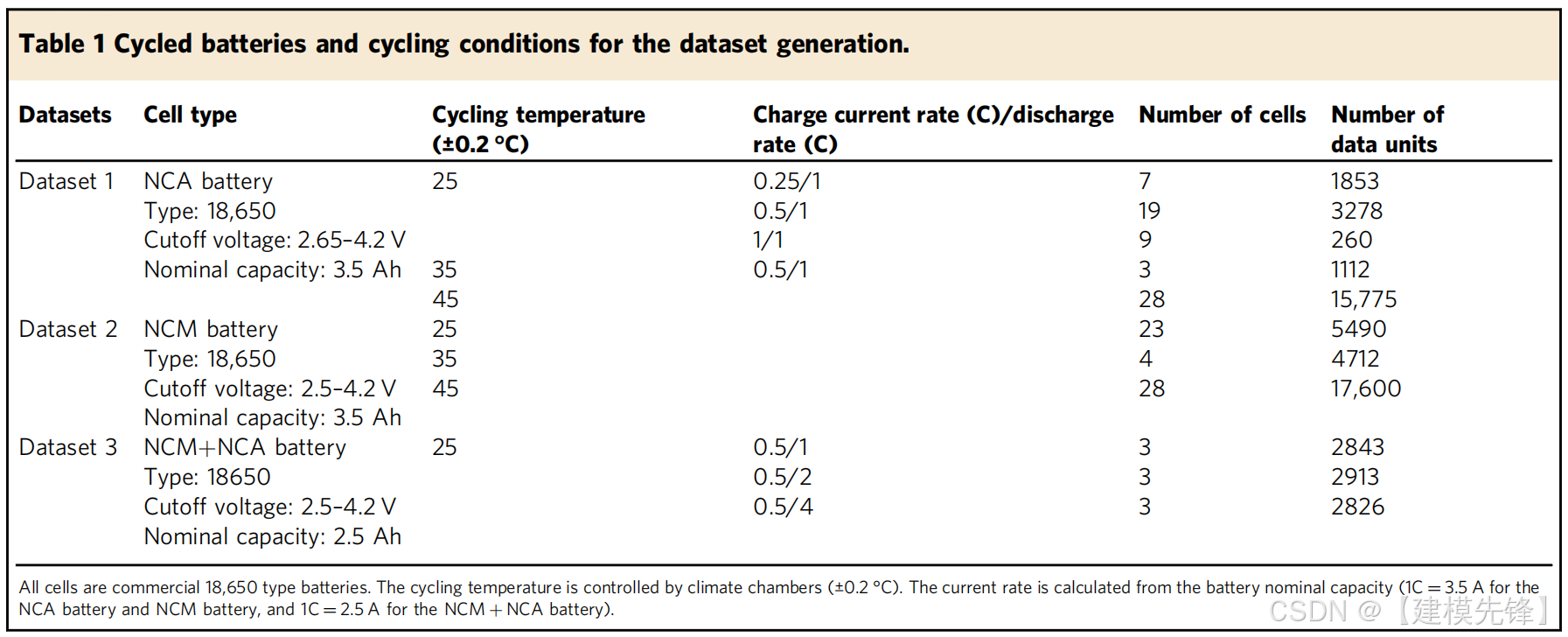
3.1 数据生成
本研究建立了关于NCA电池、NCM电池和NCM+NCA电池的大型循环数据集。电池在温度控制室中循环,并带有不同的充电电流费率。补充表4列出了电池规格。所有电池都进行了长期循环,循环条件总结见表1。选择的温度为25、35和45°C。使用的电流速率范围为0.25C(0.875 A)到4 C(10 A)。电流率是根据电池的额定容量计算的,即对于NCA电池和NCM电池,1C等于3.5A,对于NCM+NCA电池,1C等于2.5A。根据细胞的循环条件,将这些细胞命名为Cyx-Y/Z。X表示温度,Y/Z表示充放电电流速率。表1中分配给每个循环条件的单元格数量旨在获得涵盖单元格之间可能变化的数据集。一个数据单元包括具有以下放电容量的充满电后的松弛电压曲线。每条弛豫电压曲线被变换为六个统计特征,即方差(Var)、偏度(Ske)、最大值(Max)、最小值(Min)、平均值(Mean)和超额峰度(Kur)。这六个特征的数学描述见补充表5。本研究中从NCA、NCM和NCM+NCA小区收集的数据集分别命名为数据集1、数据集2和数据集3。数据集1用于基本模型训练和测试。使用数据集2和数据集3通过迁移学习来评估和改进该方法的泛化能力。
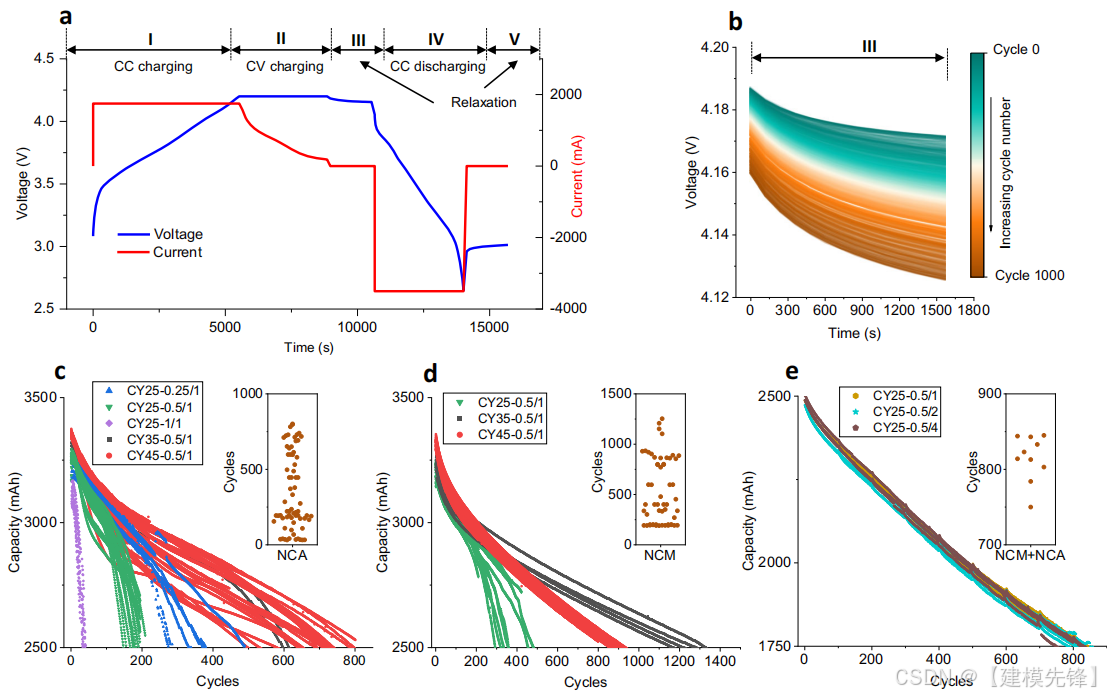
图1
电压和电流是这些实验中记录的基本数据,包括充电、放电和松弛过程。电池循环是通过恒流(CC)充电到4.2V,电流速率从0.25C(0.875 A)到1C(3.5A),然后是4.2V的恒压(CV)充电步骤,直到达到0.05C的电流。然后使用恒流分别将NCA电池和NCM+NCA电池分别放电到2.65V和2.5V。使用0.5C充电率的NCA电池的一条完整的循环曲线如图1A所示,它包括五个过程,即(I)CC充电,(II)CV充电,(III)充电后的松弛,(IV)CC放电,和(V)放电后的松弛。CC放电容量视为电池在循环过程中的剩余容量。当实际采样时间为120时,NCA电池和NCM电池的循环充电到CC放电的松弛时间为30min,而当采样时间为30 S时,NCM+NCA电池的松弛时间为60min。电池松弛期间的起止电压随循环次数的增加而呈下降趋势,如图1B所示。
生成容量低至标称容量的71%的三个数据集。NCA电池的电池容量与循环次数的函数如图1C所示。周期数在100%-71%的容量窗口中从50%到800。显然,充电电流和温度对容量衰减都有很大的影响,电池容量表现出显著的差异,如图1C所示,表明了循环电池的退化分布。最糟糕的情况是电池在25°C(CY25-1/1)下以1C充电循环,在电池达到额定容量的71%之前只能循环50次。总体而言,对于充电为0.5C的电池,分别在25℃和35℃下循环125次和600次后,容量达到71%(CY25-0.5/1和CY35-0.5/1)。总体而言,在25°C和0.25 C充电电流下循环250次后容量达到71%(Cy25-0.25/1),在45°C和0.5C充电电流下在500-800次循环范围内(Cy45-0.5/1)容量达到71%。NCM电池的循环数据如图1D所示。在250至500次循环(25°C)、1250次至1500次(35°C)以及在45°C循环温度下约1000次循环之间,可发现疲劳最低至剩余容量的71%。容量衰减结果表明,将温度提高到35℃和45°C有利于容量保持,充电电流处于电池可以处理的极限。对于NCA和NCM电池,观察到在相同条件下循环的电池的容量扩散,这被推测归因于固有的制造变化,因为这种扩散在循环开始时已经看到。NCM+NCA电池的循环数据如图1E所示,无论循环放电率如何,呈现线性退化趋势,71%的剩余容量出现在750至850次循环的范围内,表明电池循环条件的影响。
3.2 特征提取
总结统计数据可以有效地用数值表示电压曲线5、9的形状和位置的变化。如上所述,由于充分充电后的松弛过程与电池劣化有很强的相关性,并且在电池实际使用中容易获得,因此采用了松弛过程进行特征提取。每条电压松弛曲线被转换为六个统计特征,即Var、Ske、Max、Min、Mean和Kur,如图2所示。
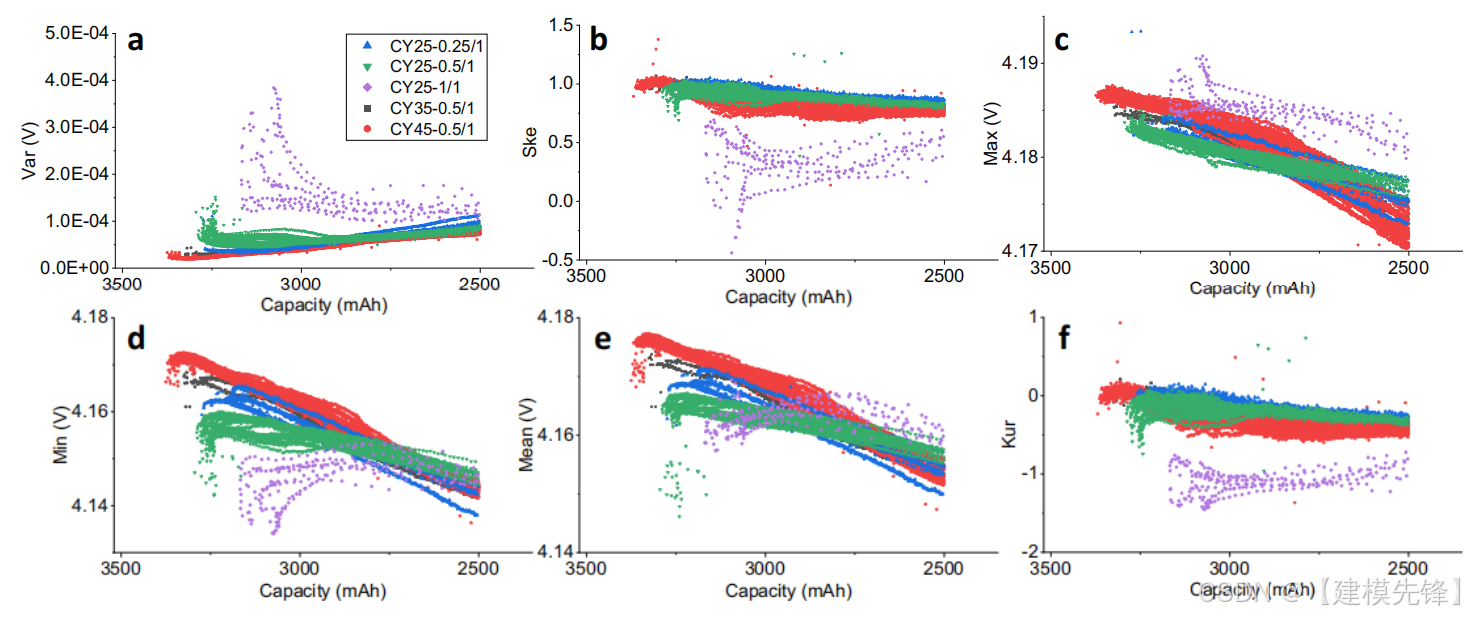
图2
电池容量和相应特性之间的关系取决于图2所示的循环条件。由此可见,仅用线性函数来描述这种关系是困难的。图2a中的Var代表了一个驰豫过程中电压点的分布,Var随容量衰减的减小意味着驰豫电压随容量的增加而呈现出更尖锐的分布循环编号,反之亦然。Ske和Kur都使用Var进行归一化,它们被用来描述相应的电压曲线的形状。图2B中的Ske在几乎所有循环条件下都是正的,表明超过一半的采样电压数据低于平均电压(平均值),平均电压对应于松弛电压曲线的形状,即相对于松弛时间,电压最初快速下降,然后逐渐减慢。图2C中的最大值显示了所有循环条件下最大电压与容量降之间的单调下降。如图2D所示,与容量减少相比,最小值和平均值分别先增加后减少。图2F中所示的Kur为超额用原始数据的峰度减去正态分布的峰度得到的峰度。在所有循环条件下,过量峰度都是负的,这意味着弛豫电压的分布比正态分布更温和。
3.3 容量估算
基于充电后松弛电压曲线提取的特征,采用数据驱动的方法对电池容量进行估计。由于特征的大小顺序不同,对数据集1执行电池特征的标准归一化。通过应用与数据集1相同的归一化尺度来归一化数据集2和数据集3的特征。考虑电池额定容量的差异来统一容量。选择XGBoost40作为主要的机器学习方法。采用ElasticNet39作为多元线性模型进行比较,SVR41作为转移学习方法验证的支撑。对于基本模型的训练和测试,不同的数据拆分策略与补充说明2和补充表6-9中的数据集1进行了比较。温度依赖拆分方法的最佳测试结果显示RMSE为1.5%。用时间序列数据分割方法得到的检验均方根误差为2.3%。数据随机分裂和单元分层抽样方法获得了较好的估计精度,RMSE为1.1%,这表明工况变化导致不同的退化模式是提高模型泛化能力的关键。本研究介绍了细胞分层抽样法的结果,即来自同一细胞的数据要么在训练集,要么在测试集中(补充说明2中的战略D)。训练和测试单元的比例约为4:1(补充表9)。在模型训练过程中,使用K=5的K-折交叉验证来确定模型的超参数。通过使用不同的特征组合来执行特征约简,以减少输入的数量并简化模型的复杂性。图3比较了XGBoost方法在不同特征组合下的交叉验证RMSE。i和j用于表示不同的特征组合,参见补充表10。
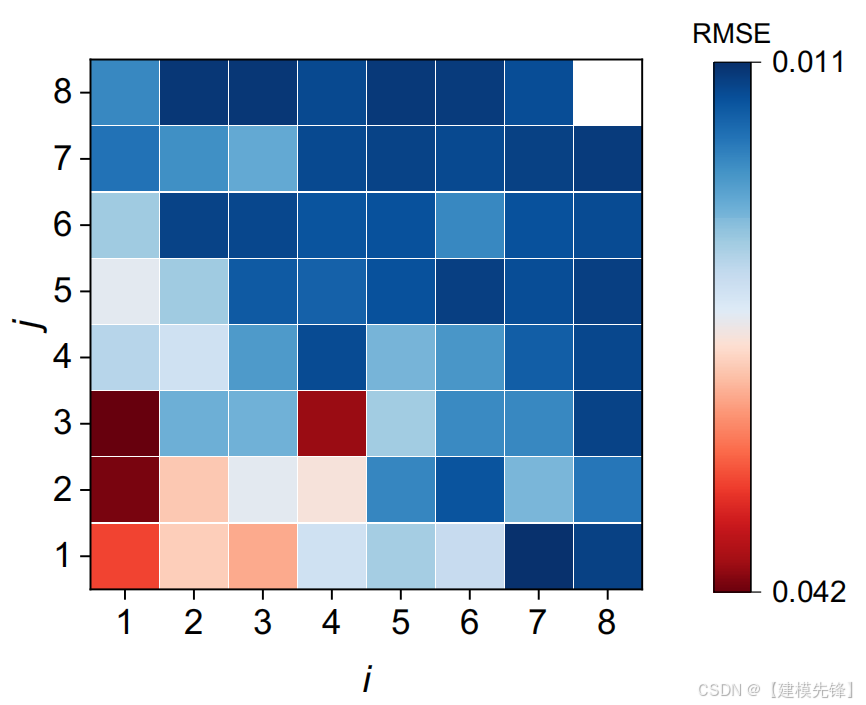
图3
结果表明,均方根误差随着特征个数的增加而逐渐减小,在使用图3中的三个特征后,精度提高不再明显。输入Var,Ske,Max三个特征组合的估计结果最佳。松弛时间对容量估计的影响如补充图3所示,在XGBoost方法中,训练和测试的均方根随着松弛时间的增加而减小,表明较长的松弛时间提高了模型的精度。因此,提取30分钟后的电压松弛的Var、Ske和Max作为基本模型的输入。补充表11提供了每种算法的超参数。图4A总结了不同估计方法在数据集1上的均方根误差。结果表明,XGBoost和SVR的测试均方根误差均达到1.1%,表现出比线性模型更好的性能,而训练和测试的均方根误差接近,说明了数据拆分的有效性。为了直观起见,图4B-D中说明了估计容量与实际容量之间的关系。
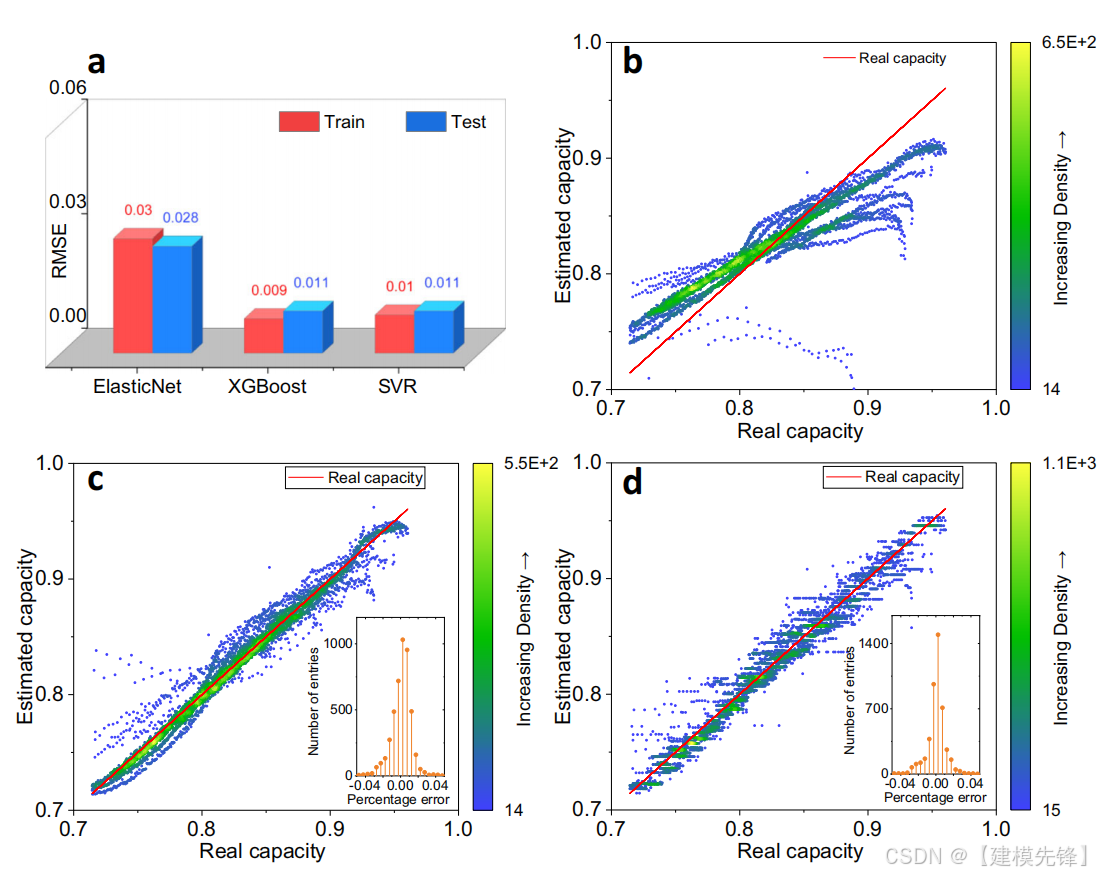
图4
3.4 对所提出的方法进行了性能测试
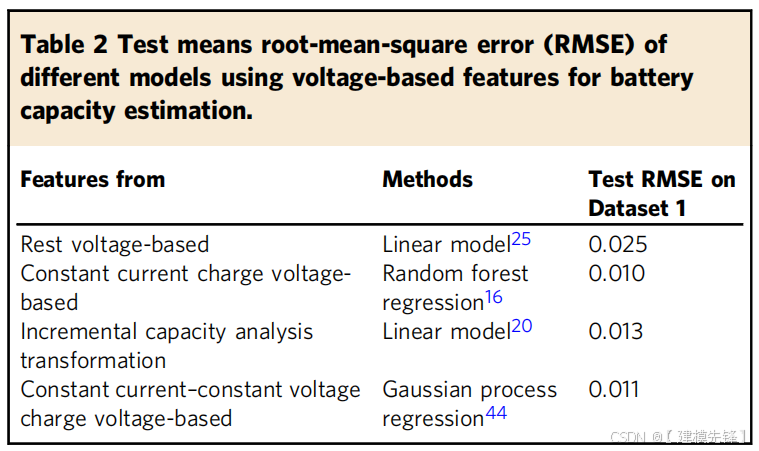
如表2所示,使用用于电池容量估计的电压曲线的最新模型对所提出的方法的性能进行了基准测试。从所提出的容量估计方法的每一类中选择一种具有代表性的方法(补充表1)。由于文献中使用的数据集在电池材料和测试程序上与我们的不同,解决这种差异的策略是将他们的算法应用到我们的数据集。补充说明3和补充图4-7详细描述了每种方法的数据处理和估计结果。巴格达迪等人25中基于静止电压估计电池容量的线性模型的性能显示了2.5%的RMSE,这可以用我们的数据集中的大量数据和各种工作条件来解释,1突出了仅使用线性模型估计容量的难度。在基于CC充电电压的方法中,使用3.6V到3.8V的电压范围的随机森林回归(RFR)方法16在数据集1上获得了1.0%的RMSE,比我们基于电压松弛的RMSE低0.1%。Peri等人提出了一种基于剩余电荷的方法,该方法具有根据增量电容值的阈值。在数据集1上应用相同的增量容量转换方法,RMSE为1.3%,表明我们提出的方法具有更好的精度。使用全CC-CV充电电压曲线的高斯过程回归(GPR)方法44在数据集1上获得了良好的估计结果,测试RMSE为1.1%。与目前的研究现状相比,尤其是在大数据集的情况下,本文提出的基于静止电压的估计方法可以达到较好的估计精度。正如导言部分所提到的,在获取特定的充电电压曲线方面存在一些挑战,因为电池充电的开始通常取决于驾驶员的行为,而且在电动汽车的实际应用中,充电模式与充电站有很大不同。在不需要特定的工作条件和电压范围的情况下,很容易得到电池充满电的松弛过程,这为电池容量的估计提供了一个新的视角。
表2
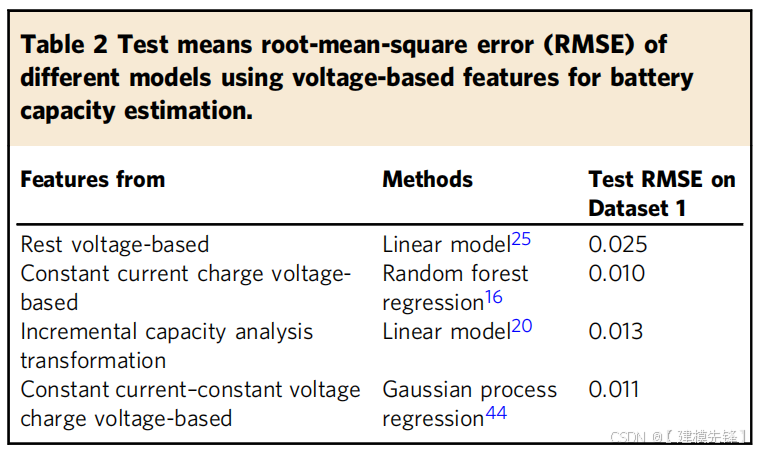
3.5 物理解释
交流(AC)电化学阻抗在频域中提供有关电池退化机制的信息,如参考文献中所证明的那样。通过用ECM拟合阻抗谱提取的电化学阻抗参数的变化,可以确定退化机理。在补充图8中补充了循环过程中的电化学阻抗谱示意图和相应的ECM。基本上,R0的增加可能是由于接触损失和电解液中离子电导率的降低。R1代表与阳极固体电解质界面(SEI)有关的电阻,高频时用半圆形表示。R2是描述电化学反应速度的电荷转移电阻,它与电极材料通过颗粒破裂而损失有关,。在我们以前的工作中,用原位中子粉末衍射法研究了数据集1和数据集2中循环电池的容量损失,结果表明,正负电极中锂含量的下降与观测到的放电容量有很好的相关性。在循环过程中,正负电极都不会分解成其他晶相,但通过检测电极晶格的变化,可以追踪到电极中导致锂物质损失的锂损失。锂物质的损失和SEI的形成被怀疑是导致锂损失的原因。
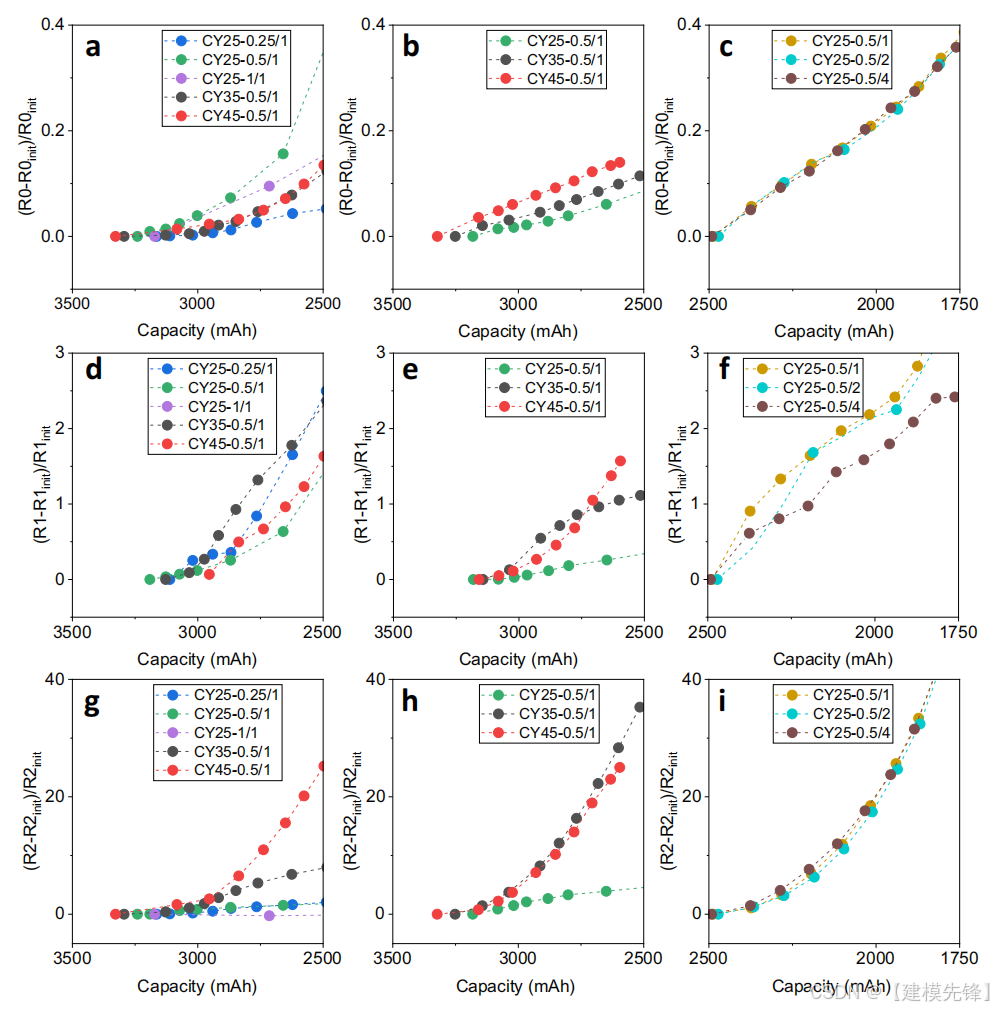
图5
在此,通过拟合的电化学阻抗参数讨论了每个循环组的主要老化因素,如图5所示。原始数据和拟合数据之间的每个测量阻抗谱的决定系数(R2)汇总在补充表12中。所有R2值都大于0.999,表明拟合精度可靠。所有原始和拟合的阻抗数据都可以从数据可用性中找到。通过比较所有三种类型电池的初始值(Rinit)的电阻增量,R0的增量最小(图5a-c),其次是R1(图5d-f)。如图5G-I所示,R2在电池容量衰减过程中表现出最大的增长。在不同的工作条件下,主要的退化因素是不同的。对于NCA细胞,如图5A所示,Cy25-0.25/1显示R0稳定而相对较小的增加,但在图5D中其R1显示加速上升,表明SEI层厚度增加。图5G中的CY250.25/1的R2与其R0呈现类似的增加趋势。图5A中的Cy25-0.5/1和Cy25-1/1的R0始终是最大的电阻贡献,但它们的R1和R2相对较低,这表明锂电镀47,49可能导致更严重的电池退化,如电解液干涸或接触损失。对于图5B,e,h中的NCM电池的结果,Cy25-0.5/1的所有电阻都缓慢增加,而在35℃和45℃循环的电池的电阻表现出较大的增加率。对于NCA+NCM电池,通过比较图5C,f,I中的结果,放电速率的影响主要由R1表示。图5F中的CY25-0.5/4 SEI电阻的增加明显慢于其他循环条件。温度对降解机理的影响可以在图5G,h中看到,其中R2的增加主要与环境温度的升高有关。在45℃和35℃下循环的电池主要导致R2的增加,这可能与正极活性物质的损失有关,例如颗粒破裂和粉碎50,51。电池内部退化机制的多样性导致了各种退化路径,这可以解释将简单的线性模型应用于电池容量估计。此外,不同类型的电池似乎在某种程度上遵循相似的退化规律,例如R2的指数上升,这启发了后面部分的迁移学习的使用。
3.6 通过迁移学习进行方法验证
为了适应数据集2和数据集3中使用不同电池和循环条件时存在的电压特征的变化,提出了一种利用相对较少的新收集的数据来重建机器学习模型以提高学习能力的转移学习方法。通过数据集1对模型权重进行预训练,得到基本模型。然后,将数据集2和数据集3中的一些新数据单元设置为输入变量,以重新训练TL模型。补充说明4和补充表13讨论了不同的数据选择方法,说明了为了提高模型估计的准确性,有必要改变工作条件。从数据集2和数据集3的每个循环条件中随机选择一个单元,然后以100个周期的间隔选择每个单元中的数据单元作为TL模型重新训练的输入变量(补充说明4中的策略D)。输入变量的大小汇总于补充表14(分别占数据集2的0.06%和数据集3的0.35%)。在不改变基本模型的任何权重的情况下对数据集2和数据集3进行验证被用作零射击学习(ZSL)参考。使用来自数据集2和数据集3的相同输入变量重新训练完整的基本模型,作为无TL比较。两种具有微调策略的TL方法(TL1和TL2)被激活来调整新添加的层的权重,而其他层的权重保持不变。TL1意味着在输出容量之前添加一个线性变换层。TL2表示构建基本模型之前的线性变换层,以适应输入特性如补充图9所示。表3比较了测试RMSE。
表3
ZSL策略直接使用基本模型在所有数据集上获得3.4%以上的测试均方根误差。如补充图10所示,估计容量和实际容量之间的误差相当大,这意味着电池类型和材料的差异不能被忽视。当以No TL策略重新训练基本模型时,XGBoost在数据集2上达到2.9%的测试RMSE,在数据集3上达到2.0%的测试RMSE,而SVR在准确性方面没有明显的改进(补充图11和补充表15)。当在数据集2和数据集3上应用TL1时,SVR方法的测试RMSE分别下降到2.6%和3.5%,但在补充图12中仍然出现大量异常值。图6给出了TL2估计容量相对于实际容量的结果。XGBoost使用数据集2上的TL2将测试RMSE降低到2.4%,注意到在数据集3上使用No TL的XGBoost的性能好于TL,这可以归因于数据集3中容量衰落的窄分布。使用TL2的支持向量机在数据集2和数据集3上都达到了最好的精度,测试RMSE分别为1.7%和1.6%。可以得出结论,TL2的使用提高了估计精度,而精度提高背后的原因是输入特征的线性变换有助于模型适应电池类型的差异但相似退化模式。有趣的是,我们发现SVR比XGBoost更可靠,更适合迁移学习,而且新收集的数据量很少。可能的原因是XGBoost是一个离散的梯度增强框架,即使在基础模型之前增加一个新的层,模型的输出也受到基础模型的限制,而SVR是一个基于核的框架,在设计的TL2下,连续计算达到了更好的预测效果。综上所述,利用松弛电压曲线估计电池容量是一种有效的方法,而转移学习提高了容量估计的精度,只需要很少的调整就可以适应电池的差异。
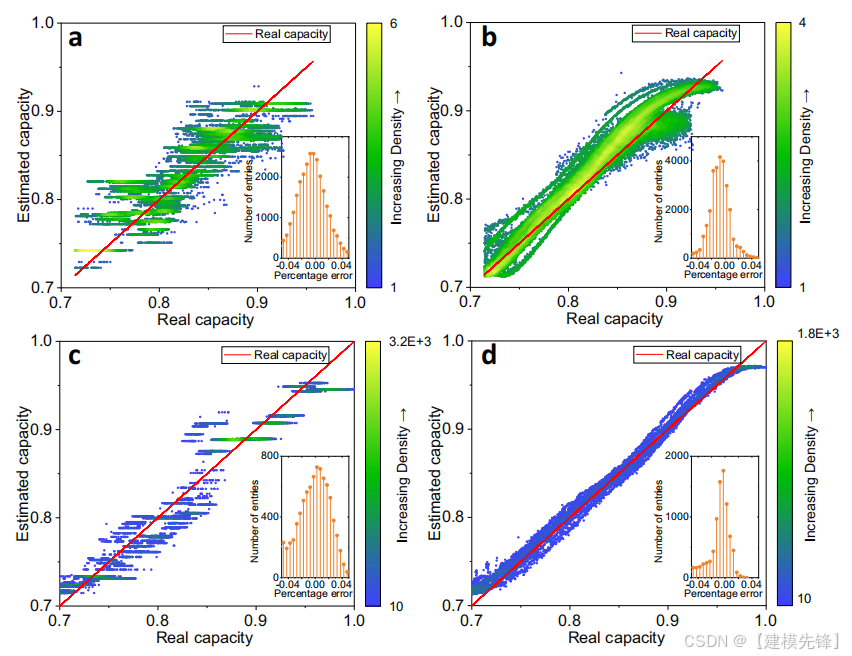
图6
4 讨论
锂离子电池容量的准确识别有助于准确估计行驶里程,这是电动汽车的主要关注点。提出了一种不需要前一次循环信息来估计电池容量的方法。该方法使用从电压松弛曲线中提取的三个统计特征(Var,Ske,Max)作为输入来预测下一周期的容量。将传递学习嵌入机器学习方法应用于130个单元,建立了合适的模型,并对方法进行了验证。最优基本模型的均方根误差为1.1%。在基础模型前增加一个线性变换层的转移学习对不同电池的预测能力在RMSE为1.7%以内。在保证输入数据变化的情况下,转移学习的再训练只需要少量的数据单元,从而提高了方法的适用性。在不需要特定的工作条件和电压范围的情况下,很容易得到电池充满电后的松弛过程,为在电动汽车应用的系统实现中使用数据驱动方法估计电池容量提供了新的可能性。
5 代码、数据整理如下:
后台回复"锂电池7",可获取我们已经打包好的论文、数据集和代码!