Ollama 让我们可以用简单透明的方式和大语言模型(LLM)交互。不过软件开发往往需要的不只是跑跑基础测试或者入门了解 LLM 的工作原理,通常还需要更多高级和个性化的选项。
在这篇文章中,我们会探索 Ollama 提供的这些高级功能 ,学习如何定制自己的模型 ,以及怎么用它的 API 来充分发挥潜力并构建 AI 应用程序。
1、前置概念
上一篇文章里,我们讨论了一些用 Ollama 本地运行 LLM 相关的理论知识。随着用例变得更复杂,也需要了解一些新概念。
需要注意的是,这些理论概念是适用于所有 LLM 的通用概念,不管用的是什么工具。有时候,工具本身可能没法直接实现某个概念(比如:Ollama 不能从零开始训练模型,但可以用 LoRA/QLoRA 适配器来微调)。
以下是这些概念:
1.1 微调
微调 就是调整预训练模型来适应特定任务的过程。通过使用跟该任务相关的数据集来完成,可以部分或完全更新神经网络的权重。这样通用模型就能适应特定任务,而不用从头重新训练------省下大量时间和资源。
前面说过,LLM 是通过预测上下文中的下一个词来工作的。如果没有精心设计的提示(提示工程),没微调过的 LLM 可能会生成连贯但跟用户意图不符的答案。
比如,如果问:"怎么做简历? ",LLM 可能会回答"用 Microsoft Word"。这个答案没错,但可能不是用户想要的------即使 LLM 对写简历有很多知识储备。
微调特别适合定制 LLM 的风格(比如聊天机器人)或者添加领域专业知识(比如法律、金融或医疗领域的专业术语),这些知识基础模型里是没有的。
一些微调类型包括:
- 全量微调:更新神经网络的所有权重------类似原始训练,但从预训练模型开始。
- 部分微调:只更新一部分权重------通常是跟预期任务最相关的部分。
- 加法方法 :不修改现有权重,而是添加新的权重或层。这类方法里比较流行的是 LoRA。
微调方法还可以按是否人工监督(SFT --- Supervised Fine-Tuning)、半监督或无监督来分类。
1.2 文件格式:Safetensors 和 GGUF
张量 是一个数学对象(本质上是个多维数组),用来表示数据。Safetensor 是 Hugging Face 开发的一种文件格式,专门用来安全存储这类张量 。跟其他格式不同,Safetensor 是只读的 ,防止意外执行代码,而且设计上追求效率和可移植性。
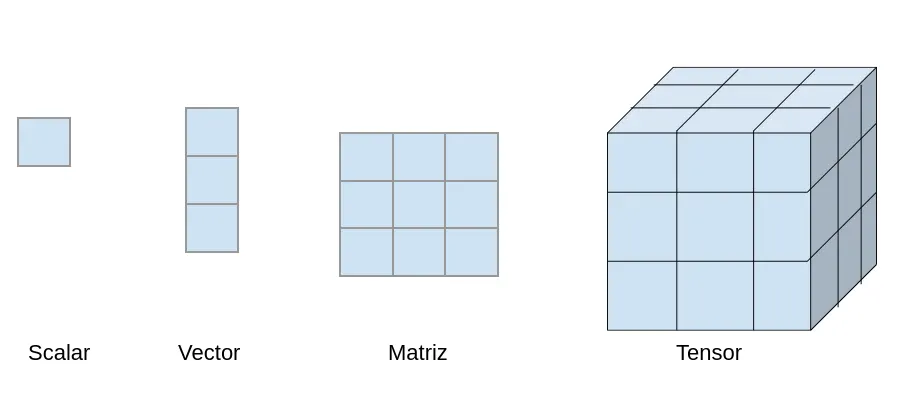
举个实际例子来说明张量代表什么:
- 标量(0 维张量):比如灰度图像中一个像素的强度值。
- 向量(1 维张量):灰度图像中的一行像素。
- 矩阵(2 维张量):一张完整的灰度图像。
- 3 维张量:彩色图像------每个像素有三个值(RGB),可以看作三个堆叠的矩阵(每个颜色通道一个)。
另一种文件格式是 GGUF (GPT-Generated Unified Format),支持 LLM 的优化管理。GGUF 可以存储张量加上元数据,并支持不同类型的量化和微调。
GGUF 设计得很灵活和通用,允许添加新信息而不破坏跟旧模型的兼容性,支持未来扩展。
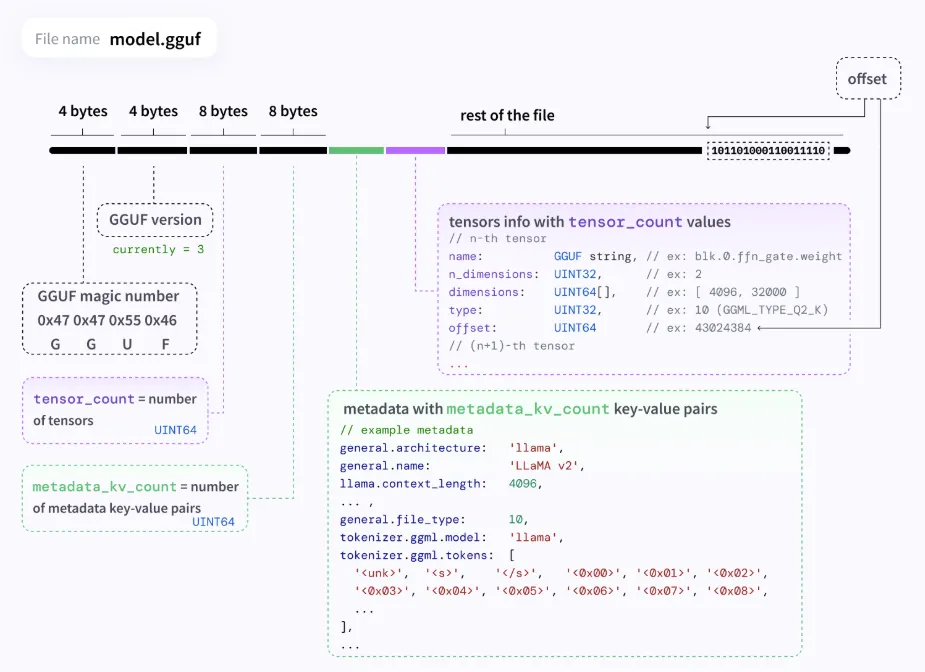
GGUF 模型
2、模型参数
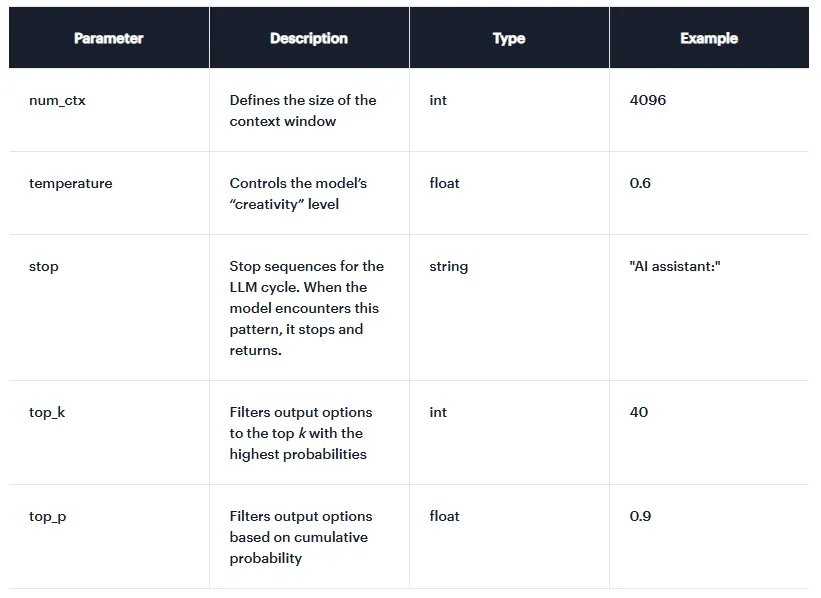
就像应用程序有可配置的参数(多货币、多语言等),模型也有可配置的参数 。除了模型特定的参数外,还有一些对优化很重要的常见参数:
- temperature:调整模型输出的概率分布------也就是控制"创造力"。值越低输出越确定;值越高回答越随机或越有创意。典型值范围从 0 到 1,通常默认是 0.7 或 0.8。
- top_p :让模型从概率累加至少为 p 的最小可能集合中选择输出标记。值在 0 到 1 之间。
- top_k :选择 k 个最可能的标记(按概率排序)作为可能的输出。
- num_predict:模型一次响应中生成的最大标记数。值为"-1"时,会一直生成标记直到遇到明确的停止条件。
- stop:一组字符串------如果模型生成其中任何一个,生成就会停止。有助于强制模型在想要的地方结束。
- num_ctx:定义上下文窗口(context-window)的大小------模型一次可以处理的标记总数。这是最重要的参数之一(见下文)。
这些是最重要的参数,但还有很多其他参数。根据跟 Ollama 的交互方式(CLI、API、modelfile),不是所有参数都能配置。
3、上下文长度
上下文长度定义了模型一次可以处理的最大标记数。包括:
- 用户输入标记(提示)。
- 记忆或历史标记(之前的对话状态、存储的对话等)。
- 输出标记(响应)。
- 系统提示标记(对 LLM 行为的指示)。
上下文长度很关键,因为它直接影响模型输出的质量。在长对话或提供大量信息(比如文档)时,超过上下文限制可能导致响应不稳定或重复,或者记不住早期的信息。
虽然可以调整,LLM 在预训练时都有最大上下文长度 (比如 2048、4096、8192......高达 128K;一些先进模型如 Gemini 1.5 Pro 声称支持200 万个标记)。超过模型限制增加上下文长度可能导致回答不连贯以及大量资源占用(RAM、CPU),可能引起性能问题。
可以通过以下方式修改这个参数:
- CLI :比如,对于用 ollama run 的交互式会话,可以通过:/set parameter num_ctx < value > 设置。

-
API:在请求体中用 options 指定参数。
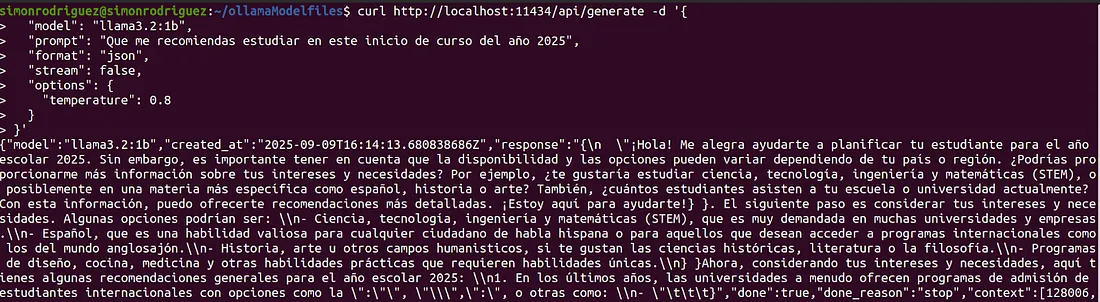
curl http://localhost:11434/api/generate -d '{
"model": "llama3.2:1b",
"prompt": "地球旋转有多快?",
"options": {
"num_ctx": 1024
}
}'

- Modelfile :稍后会介绍这种方法,只需在 Modelfile 中加入指令:PARAMETER num_ctx < value > 就行。
4、API
除了交互命令外,Ollama 提供了一个 API ,让我们可以通过编程方式跟 LLM 交互。这个 API 在跟其他应用集成时特别有用 (比如,跟 Spring AI 集成),因为只需要调用相应的 REST 端点就行。
默认情况下,API 在端口 11434 上公开(http://localhost:11434 或 http://127.0.0.1:11434),不过可以配置。API 公开了以下端点:
- /api/generate : POST 方法。用单个提示从 LLM 获取响应的端点,没有对话问答序列。适合文本生成或翻译等任务。
- /api/chat : POST 方法。用于对话问答交互的端点。

- /api/embeddings : POST 方法。为输入生成嵌入(数值向量表示)。

- /api/tags : GET 方法。相当于交互命令 ollama list,显示系统中所有可用的模型。

- /api/show : POST 方法。相当于 ollama show,提供特定模型的详细信息,比如参数、模板、许可证等。

- /api/delete : DELETE 方法。相当于 ollama rm 命令,用于从本地系统删除一个模型。
- /api/pull : POST 方法。相当于 ollama pull,用于从远程仓库下载一个模型到本地系统。
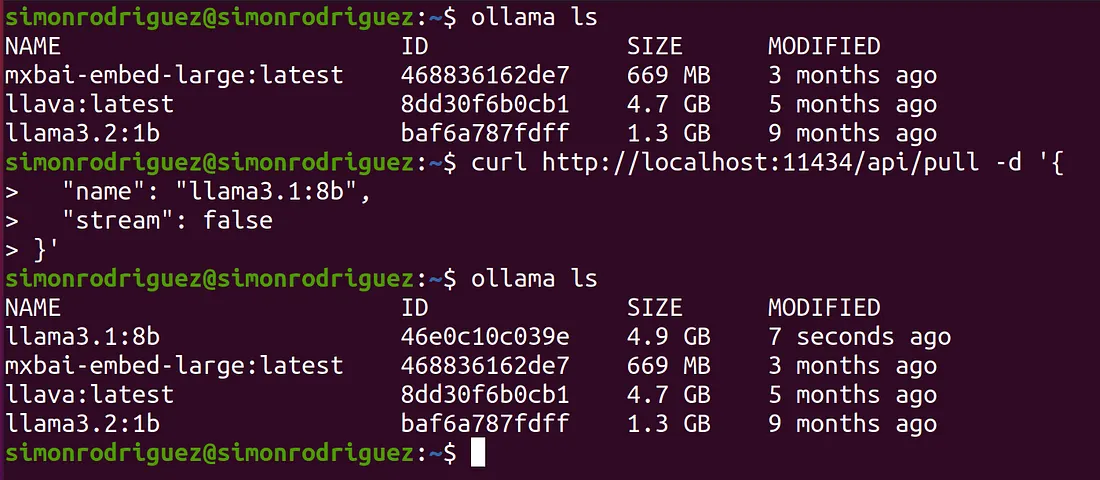
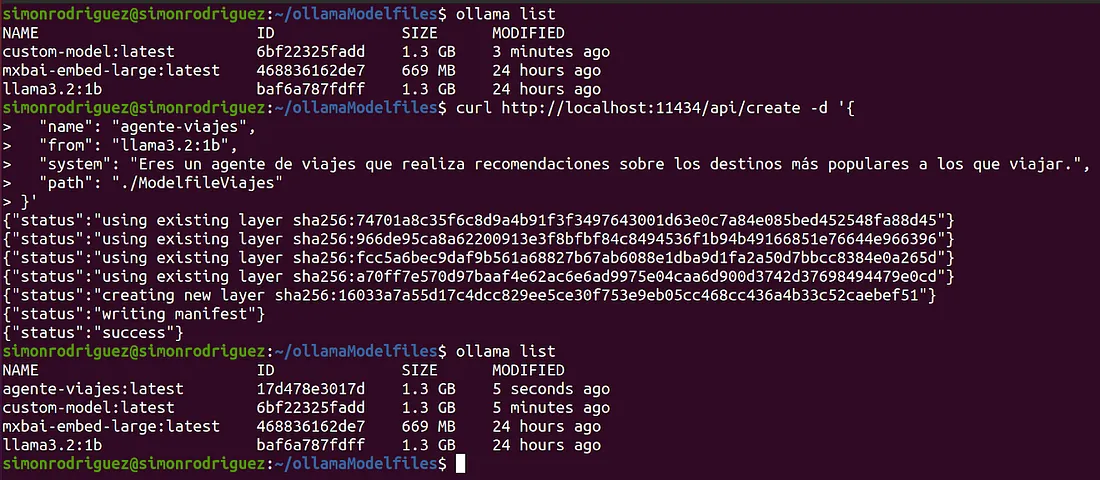
- /api/create : POST 方法。相当于 ollama create,可以从 Modelfile 创建一个自定义模型。
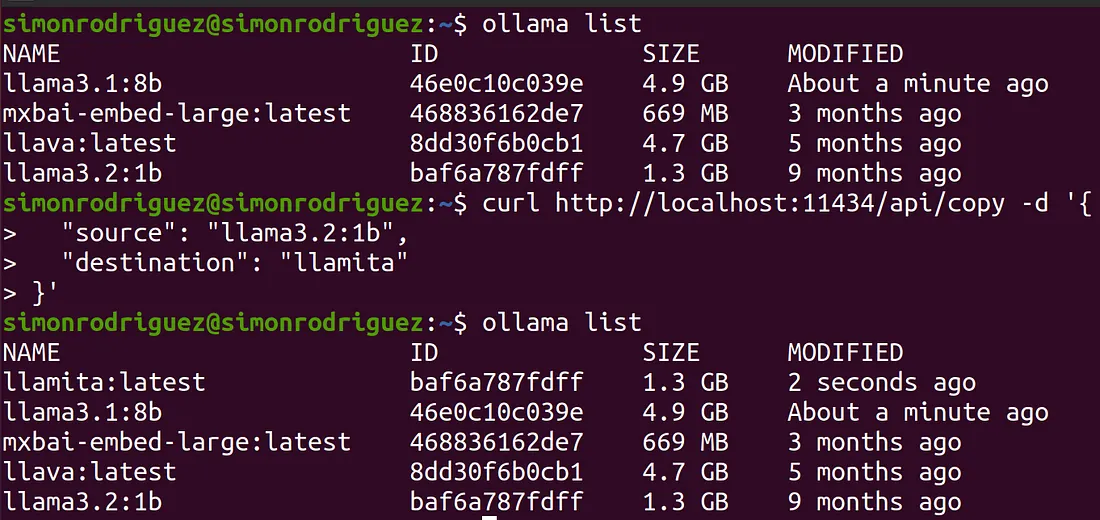
- /api/copy : POST 方法。相当于 ollama cp,用于在本地复制一个现有模型。
- /api/push : POST 方法。用于将模型上传到远程仓库的端点。
4.1 OpenAI API 兼容性
众所周知,OpenAI 是当前基于 LLM 的 AI 浪潮的主要推动者 ,所以很多应用都依赖它的 API。为了保持集成的简单性,Ollama 提供了一个兼容层,匹配 OpenAI API 格式。
这意味着,除了上面的端点外,Ollama 还通过 /v1/ 路径(http://localhost:11434/v1/)公开其他端点,遵循 OpenAI API 结构。目前支持的一些兼容端点包括:
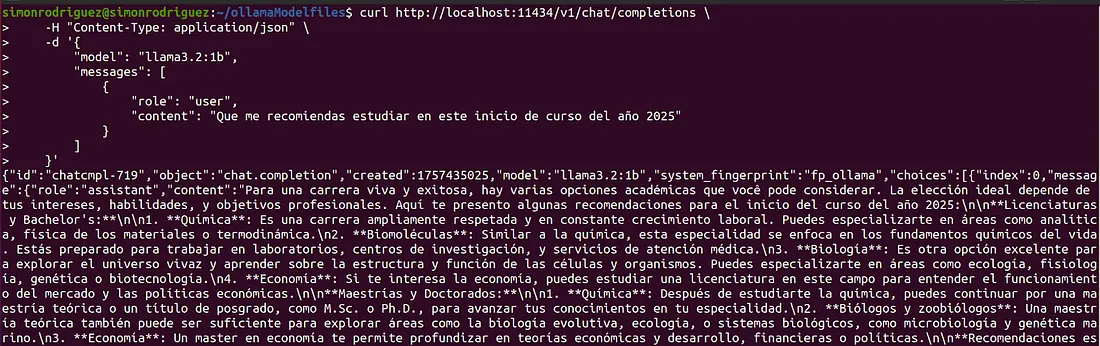
- /v1/chat/completions: 等同于 /api/chat 端点。
- /v1/embeddings: 等同于 /api/embeddings 端点。

- /v1/models: 等同于 /api/tags 端点。

有了这个兼容层,很多跟 OpenAI API 集成的库只需要最小的配置改动就能跟 Ollama 一起用。一些关键设置包括:
- base_url : 设置为 Ollama 的 v1 端点 →
<http://localhost:11434/v1/> - api_key : 任何非空值都行;Ollama 不验证这个参数。
5、Modelfiles
从早期开始,Ollama 就设计得模块化和可扩展 (创始人中有之前在 Docker 工作的人)。这就是 Modelfiles 存在的原因:配置文件,作为定义 LLM 的分层配方,类似于 Dockerfile 描述容器镜像的方式。
一个 Modelfile 组合了模型的 GGUF 权重、模板、系统提示和其他指令。
信息分为特定的 Modelfile 指令,精神上类似于 Dockerfile。一些最重要的包括:
FROM:必需的指令。指定模型构建的基础。允许几种形式:
- 现有模型:引用本地或 Ollama 仓库中已有的模型。
- 示例:
FROM llama3.2:1b - Safetensors 权重:safetensors 文件和必要配置的相对或绝对路径。目前支持的架构包括 llama、mistral、gemma 或 phi3。
- 示例:FROM ./models/llama_safetensors/
- GGUF 模型:GGUF 文件的相对或绝对路径。
- 示例:FROM ./models/llama-3--2.gguf
PARAMETER:设置执行参数的默认值。
- 示例:PARAMETER temperature 0.3 ; PARAMETER num_ctx 8192
- 一些最重要的参数包括:
- TEMPLATE :用于定义 LLM 输入提示格式结构的指令。这对聊天或基于指令的模型非常重要,因为模板指定了系统消息、用户回合、助手回合等是怎么分隔的,确保问答循环正确运行。模板用 Go 模板语法编写。关键变量是:

一个模板指令的例子可能是:
TEMPLATE """{{ if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ if .Prompt }}<|im_start|>user
{{ .Prompt }}<|im_end|>
{{ end }}<|im_start|>assistant
"""-
SYSTEM:配置默认的系统提示。可以定义 LLM 应该怎么表现(旅行代理、财务代理、数学老师等)。比如:
SYSTEM """ 你是一个提供有用信息的旅行代理,比如法律、价格、重要的旅游景点、用餐地点、住宿和其他重要的旅游信息。 """
-
ADAPTER :用文件路径,这个指令可以指定一个 LoRa 或 QLoRa 适配器,应用到 FROM 指令中指示的基础模型上。需要注意的是,FROM 指令中的基础模型必须是适配器最初训练时用的模型,否则模型可能会有不可预测的行为。
路径可以指向:
-
一个 GGUF 格式的单文件:modelo-lora.gguf。
-
一个包含 Safetensor 格式权重的文件夹:
-
adaptador-modelo.safetensors, adaptador-config.json.
ADAPTER ./llama3.2-lora.gguf
-
LICENCE:指定模型分发的许可证。比如:
LICENSE """ MIT License """
MESSAGE:包含示例对话回合的指令,帮助 LLM 遵循特定的风格或格式。可能的角色包括:
- System:定义系统提示的另一种方式。
- User:用户问题的示例。
- Assistant:模型应该怎么回应的示例。
消息指令的一个例子可能是:
MESSAGE user 马德里在西班牙吗?
MESSAGE assistant 是的
MESSAGE user 巴黎在西班牙吗?
MESSAGE assistant 不是
MESSAGE user 巴塞罗那在西班牙吗?
MESSAGE assistant 是的需要注意的是,Modelfile 不区分大小写 ------指令用大写字母写只是为了清晰。另外,指令不需要遵循严格的顺序 (不过建议把 FROM 指令放最前面提高可读性)。
考虑到上面这些,一个简单的 Modelfile 示例可能是:
FROM llama3.2:1b
PARAMETER temperature 0.3
PARAMETER num_ctx 8192
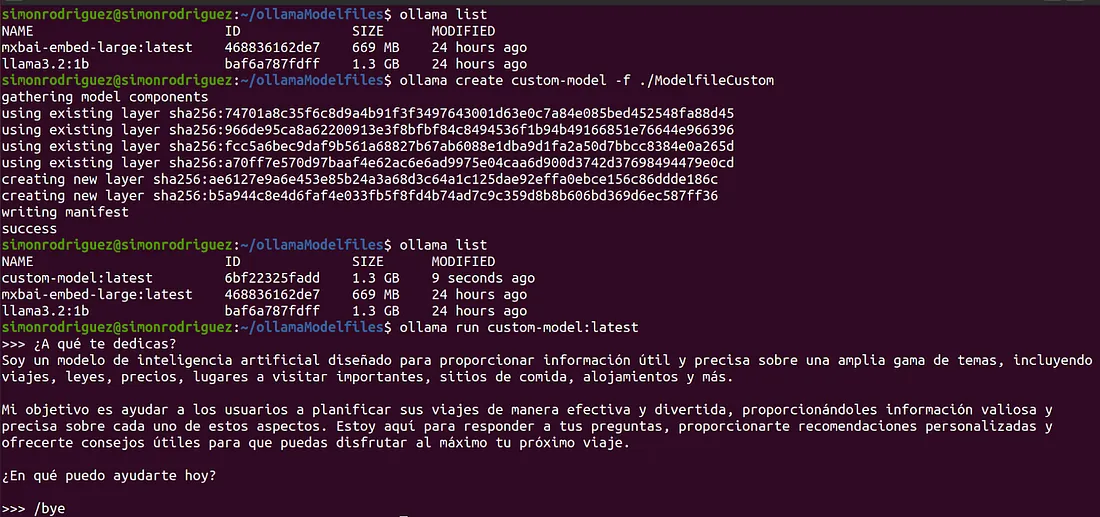
SYSTEM 你是一个提供有用信息的旅行代理,比如法律、价格、重要的旅游景点、用餐地点、住宿和其他重要的旅游信息。保存这个文件后,执行以下命令来创建它:
ollama create custom-model -f ./ModelfileCustom创建完成后,可以确认它现在跟其他模型一起列出,就可以开始跟它交互了:
6、导入外部模型
Ollama 支持执行自己仓库以外的模型 ,只要它们以标准格式分发,比如 GGUF 或 Safetensors,或者带有微调适配器。以下是一些示例:
6.1 GGUF
a) 下载 .gguf 格式的文件 。可以在这个链接找到一个示例。
b) 生成引用下载文件的 Modelfile。
FROM ./external-models/gguf/llama-3.2-1b-instruct-q4_k_m.gguf
PARAMETER num_ctx 4096
SYSTEM "你是一个只讲笑话的聊天机器人。"c) 创建模型以便以后执行:
ollama create custom-gguf-model -f ./Modelfile_gguf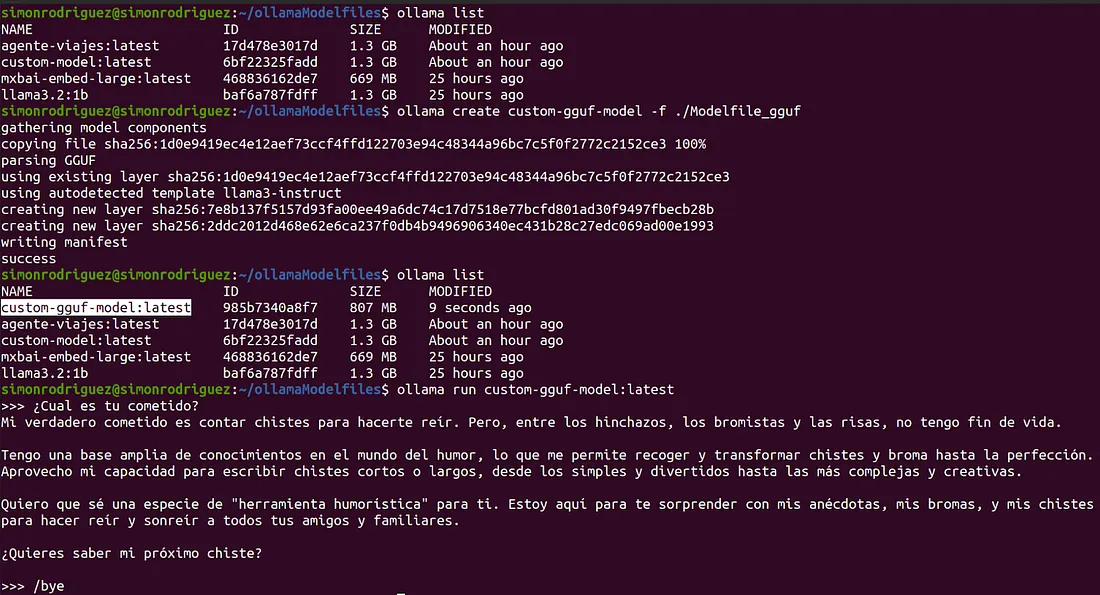
6.2 Safetensors
a) 将所需的文件下载到同一文件夹中 。可以在这个链接找到一个示例。
b) 生成引用文件所在路径的 Modelfile。
FROM ./external-models/safetensors/llama3_2_instruct_st/
PARAMETER num_ctx 4096
PARAMETER temperature 0.7c) 创建模型以便以后执行:
ollama create custom-st-model -f ./modelfile6.3 适配器
a) 将所需的文件下载到同一文件夹中 。可以在这个链接找到一个示例。
b) 生成引用文件所在路径的 Modelfile。
FROM llama-3.2-3b-instruct-bnb-4bit
ADAPTER ./adapters/llama3_2_lora/llama3.2_LoRA_Spanish.gguf
PARAMETER temperature 0.5
SYSTEM "你现在以LoRA教授的风格进行回答。"c) 创建模型以便以后执行:
ollama create custom-lora-model -f ./modelfile7、使用 Ollama 进行量化
Ollama 还提供了在创建模型时对模型进行量化(也就是降低权重的数值精度)的选项。通过在 create 命令中指定 -q (或 --quantize)参数来完成,像这样:
ollama create llama-quantized -f ./Modelfile -q q4_K_M根据下面的 Modelfile,可以看到量化结果(可以看到结果模型的大小更小了):
FROM llama3.2:1b-instruct-fp16
PARAMETER temperature 0.9
SYSTEM """ 你是一个叫Mr Travel的旅行代理。"""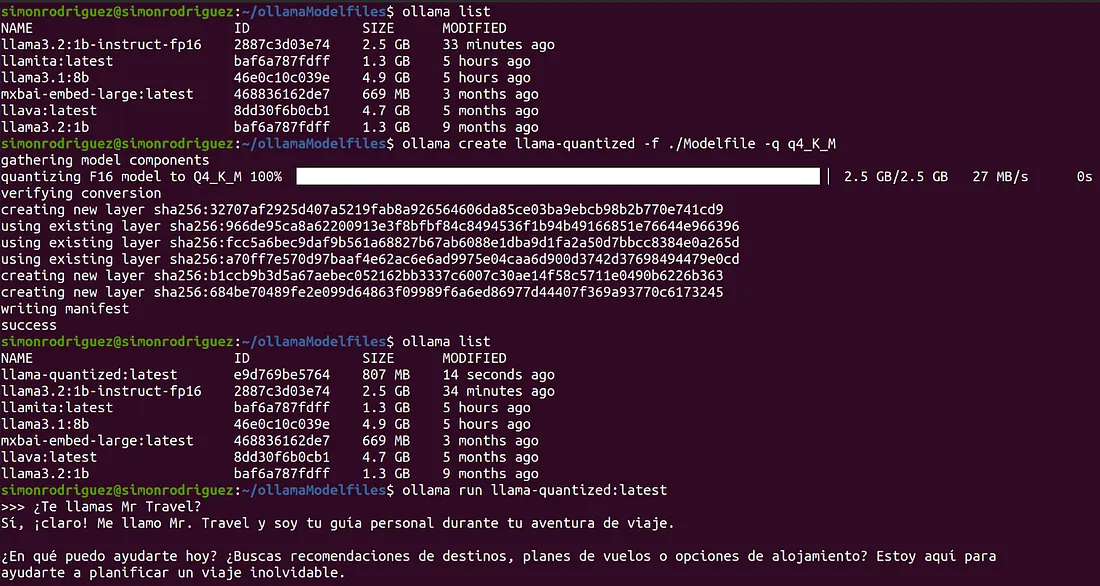
内部使用的是来自 llama.cpp 库的量化指令 来执行这个过程,并用适当的名称保存模型。一些可能的量化选项 包括:q4_0、q5_0、q6_K、q8_0、q4_K_S、q4_K_M 等。
8、总结
本文探索了 Ollama 的更高级交互选项 。我们测试了 Ollama API 的工作方式,以及重要的参数和配置,确保模型的最佳性能。
我们还测试了 Ollama 最强大的功能之一:定制模型,让它更好地适应特定用例,在 AI 驱动的应用程序中提供更好的用户体验。
原文链接:Running LLMs Locally: Advanced Ollama
https://paradigma-digital.medium.com/running-llms-locally-advanced-ollama-29fa92a65bac