多场景头盔佩戴检测系统
本文档旨在全面、深入地介绍安全帽佩戴检测系统的技术细节、架构设计及功能实现。系统集成了深度学习目标检测算法、Web全栈开发技术与数据库管理技术,形成了一套完整的闭环解决方案。
1. 系统架构设计 (System Architecture)
本系统采用经典的前后端分离 B/S (Browser/Server) 架构,确保了系统的高可扩展性与维护性。
1.1 技术栈概览
- 前端 (Frontend) :
- 框架: Vue.js 3.0 (Composition API)
- UI组件库: Element Plus (响应式设计)
- 数据可视化: ECharts 5.0 (动态图表)
- 网络请求: Axios (拦截器封装)
- 路由管理: Vue Router 4.0
- 后端 (Backend) :
- 框架: Django 5.x + Django REST Framework (DRF)
- 语言: Python 3.9+
- 身份认证: JWT (JSON Web Token)
- 任务队列: 异步多线程处理 (Python Threading/AsyncIO)
- 算法核心 (AI Core) :
- 框架: PyTorch / Ultralytics
- 模型: YOLOv8 / YOLOv5 (自适应加载)
- 图像处理: OpenCV, PIL (Pillow)
- 数据库 (Database) :
- 开发/测试: SQLite
- 生产: MySQL 8.0
- ORM: Django ORM
1.2 数据流向
- 用户请求: 前端通过 Axios 发送 HTTP 请求(GET/POST/PUT/DELETE)。
- API 网关: Django URL路由分发请求至对应的 ViewSet。
- 业务逻辑: ViewSet 处理业务逻辑,如权限校验、参数清洗。
- AI 推理 : 对于检测任务,后端调用
utils.py中的推理引擎,加载.pt模型进行计算。 - 数据持久化: 结果存入数据库(SQLite/MySQL),文件存入文件系统。
- 响应返回: 处理结果封装为 JSON 格式返回前端渲染。
2. 数据集与预处理 (Dataset & Preprocessing)
高质量的数据集是模型性能的基石。本项目针对工地复杂环境进行了专门的数据收集与清洗。
2.1 数据集构成
-
样本数量: 包含数千张精选的工地现场图片。
-
类别定义 :
helmet: 佩戴安全帽 (正样本)head/no-helmet: 未佩戴安全帽 (负样本) - 重点检测对象person: 辅助类别,用于定位人员主体 (可选)
-
标注格式 : 采用 YOLO 标准格式 (
.txt)。text<class_id> <x_center> <y_center> <width> <height> 0 0.453 0.672 0.120 0.345 1 0.123 0.456 0.098 0.210所有坐标均经过归一化处理 (0~1),便于模型训练时适应不同分辨率的输入。
2.2 数据增强 (Data Augmentation)
为了提高模型的泛化能力,防止过拟合,在训练阶段采用了多种增强策略:
- Mosaic 增强: 将4张图片随机缩放、裁剪、拼接成一张新图,丰富了背景并增加了小目标的数量,极大地提升了模型对复杂背景的鲁棒性。
- Mixup: 将两张图片按透明度叠加,迫使模型学习更鲁棒的特征。
- 随机几何变换: 旋转、缩放、平移、水平翻转。
- HSV 色彩空间变换: 随机调整色调 (Hue)、饱和度 (Saturation)、亮度 (Value),模拟不同光照环境(如阴天、强光、夜间)。
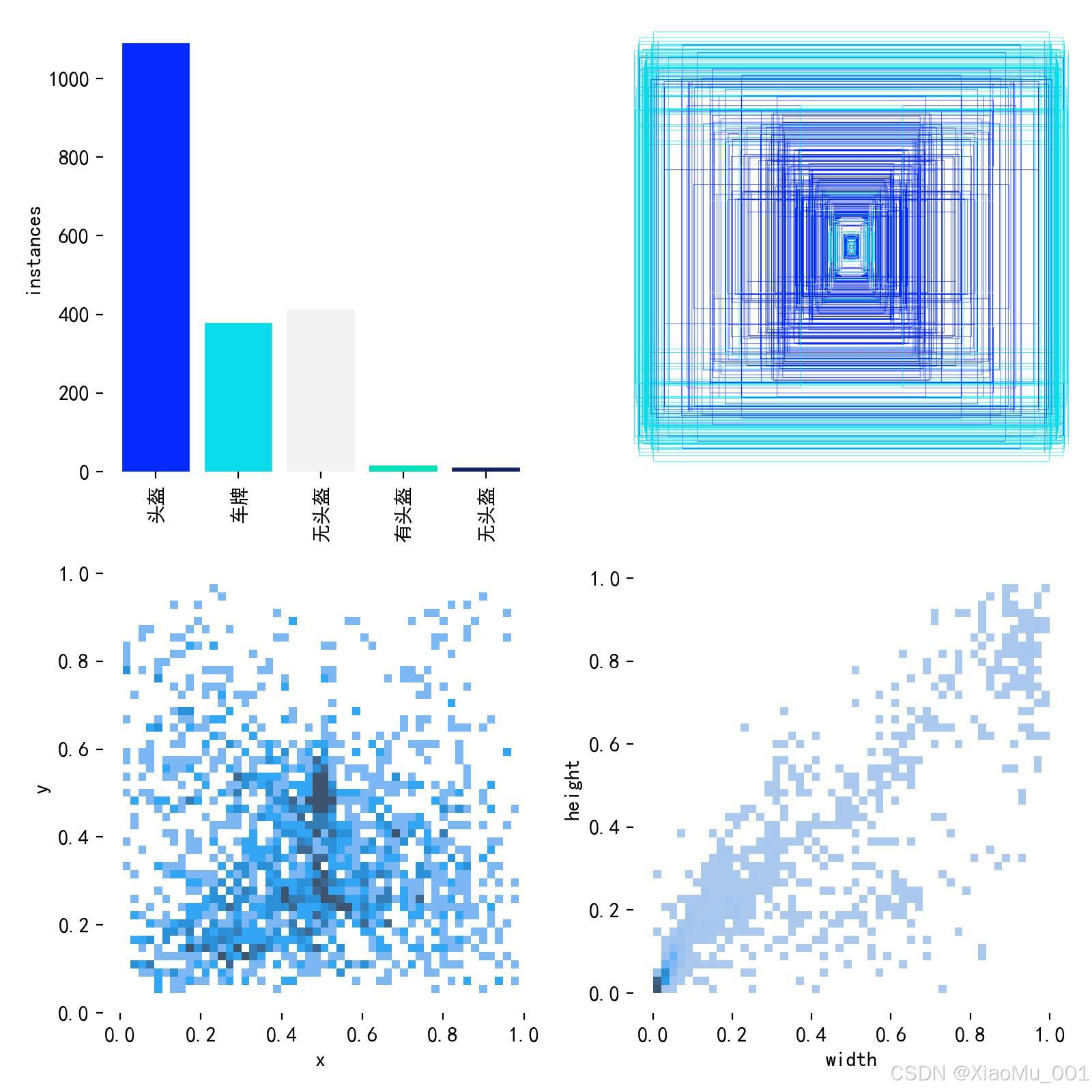
上图展示了数据集中各类别标签的空间分布及数量分布。
3. 核心算法原理 (Core Algorithm)
本项目兼容 YOLOv8 和 YOLOv5 两种主流单阶段目标检测模型,通过 ultralytics 库或 torch.hub 动态加载。
3.1 网络结构详解
A. Backbone (主干特征提取网络)
- CSPDarknet: 采用跨阶段局部网络 (Cross Stage Partial Network) 结构。
- 核心组件 :
C2f(YOLOv8) 或C3(YOLOv5) 模块。 - 作用: 通过残差连接和分流合并,在加深网络深度的同时,有效缓解了梯度消失问题,减少了参数量和计算量。
B. Neck (特征融合网络)
- 结构: PANet (Path Aggregation Network) + FPN (Feature Pyramid Network)。
- 原理 :
- 自顶向下: 将高层语义特征(强语义)传递给底层。
- 自底向上: 将底层定位特征(强位置信息)传递给高层。
- 作用 : 实现了多尺度特征的深度融合,显著提升了对小目标 (如远处的工人)和大目标(如近处的特写)的检测能力。
C. Head (检测头)
- Decoupled Head (解耦头) : 将分类任务 (Classification) 和回归任务 (Regression) 分开处理。
- Cls 分支: 预测目标的类别概率。
- Reg 分支: 预测目标框的坐标偏移量。
- Anchor-free (YOLOv8): 抛弃了传统的 Anchor Box 设计,直接预测目标的中心点和宽高,减少了超参数的调优工作,加快了收敛速度。
3.2 损失函数 (Loss Function)
模型训练的目标是最小化总损失 LtotalL_{total}Ltotal:
Ltotal=λboxLbox+λclsLcls+λdflLdfl L_{total} = \lambda_{box} L_{box} + \lambda_{cls} L_{cls} + \lambda_{dfl} L_{dfl} Ltotal=λboxLbox+λclsLcls+λdflLdfl
- 边界框回归损失 (LboxL_{box}Lbox) : 采用 CIoU Loss (Complete IoU) 或 DIoU Loss。不仅考虑了重叠面积,还考虑了中心点距离和长宽比,使得回归更精准。
- 分类损失 (LclsL_{cls}Lcls) : 采用 BCEWithLogitsLoss (二元交叉熵损失),用于衡量类别预测的准确性。
- 分布焦点损失 (LdflL_{dfl}Ldfl): (YOLOv8特有) 用于优化边界框的分布,解决边界模糊问题。
3.3 推理与后处理
- 预处理: 图像 Resize 到 640x640,归一化至 0~1,通道转换 (BGR -> RGB)。
- 前向传播: 输入网络,输出预测张量。
- NMS (非极大值抑制) :
- 过滤掉置信度低于阈值 (Conf Threshold) 的框。
- 对于重叠度 (IoU) 高于阈值的冗余框,只保留得分最高的一个,消除重复检测。
4. 模型训练与评估 (Training & Evaluation)
4.1 评估指标
- Precision (精确率) : 预测为正样本中实际为正的比例。 P=TPTP+FPP = \frac{TP}{TP+FP}P=TP+FPTP
- Recall (召回率) : 实际正样本中被正确预测的比例。 R=TPTP+FNR = \frac{TP}{TP+FN}R=TP+FNTP
- mAP@0.5: IoU阈值为0.5时的平均精度均值,反映模型的基本检测能力。
- mAP@0.5:0.95: IoU阈值从0.5到0.95步长0.05计算的平均值,反映模型的高精度定位能力。
4.2 训练过程分析
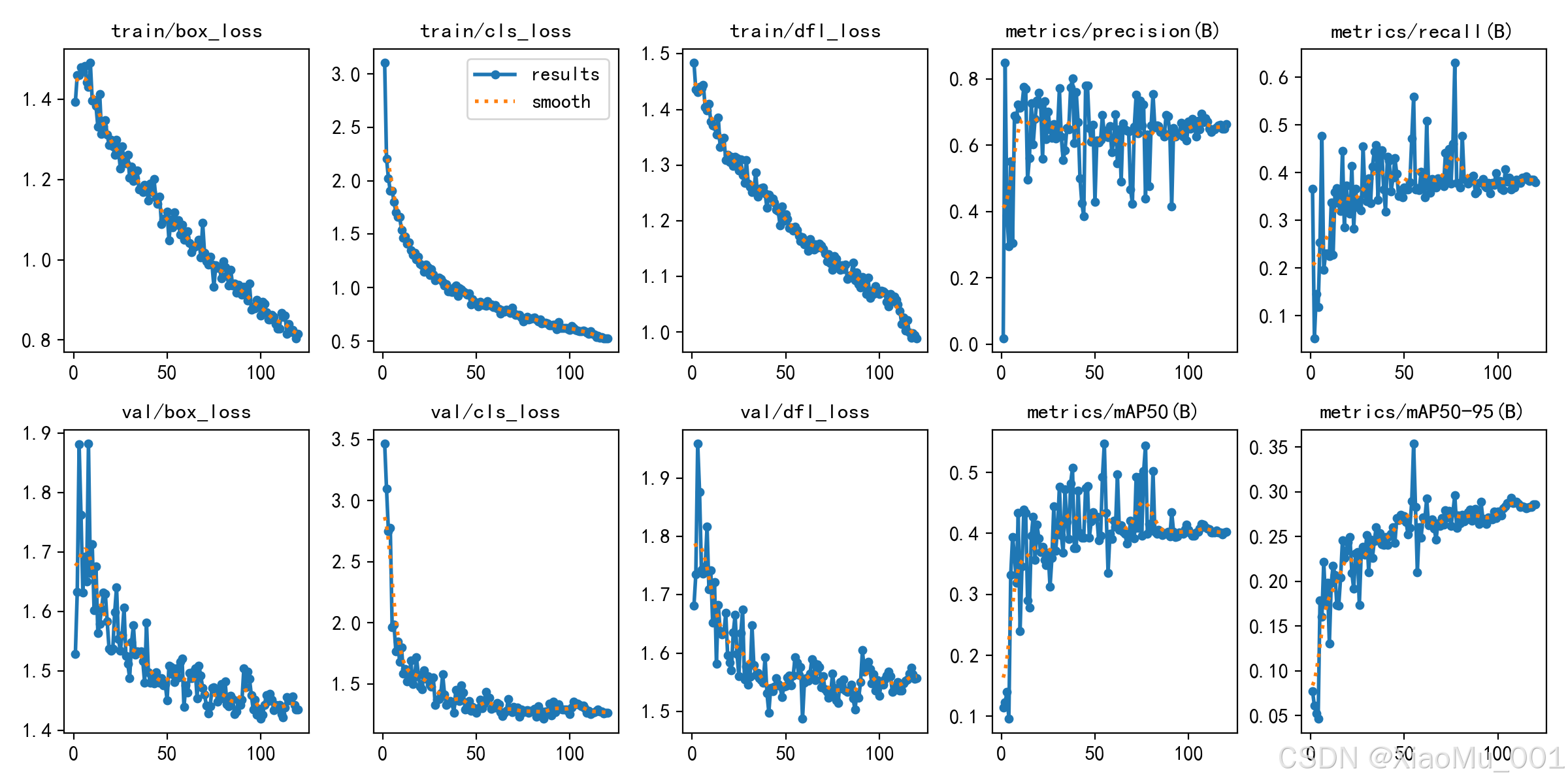
- Loss曲线 :
box_loss,cls_loss,dfl_loss均呈下降趋势,表明模型正在有效学习。 - Metric曲线 :
mAP_0.5和mAP_0.5:0.95快速上升并在后期趋于平稳,说明模型性能达到瓶颈,训练完成。
4.3 性能可视化
- 混淆矩阵 :
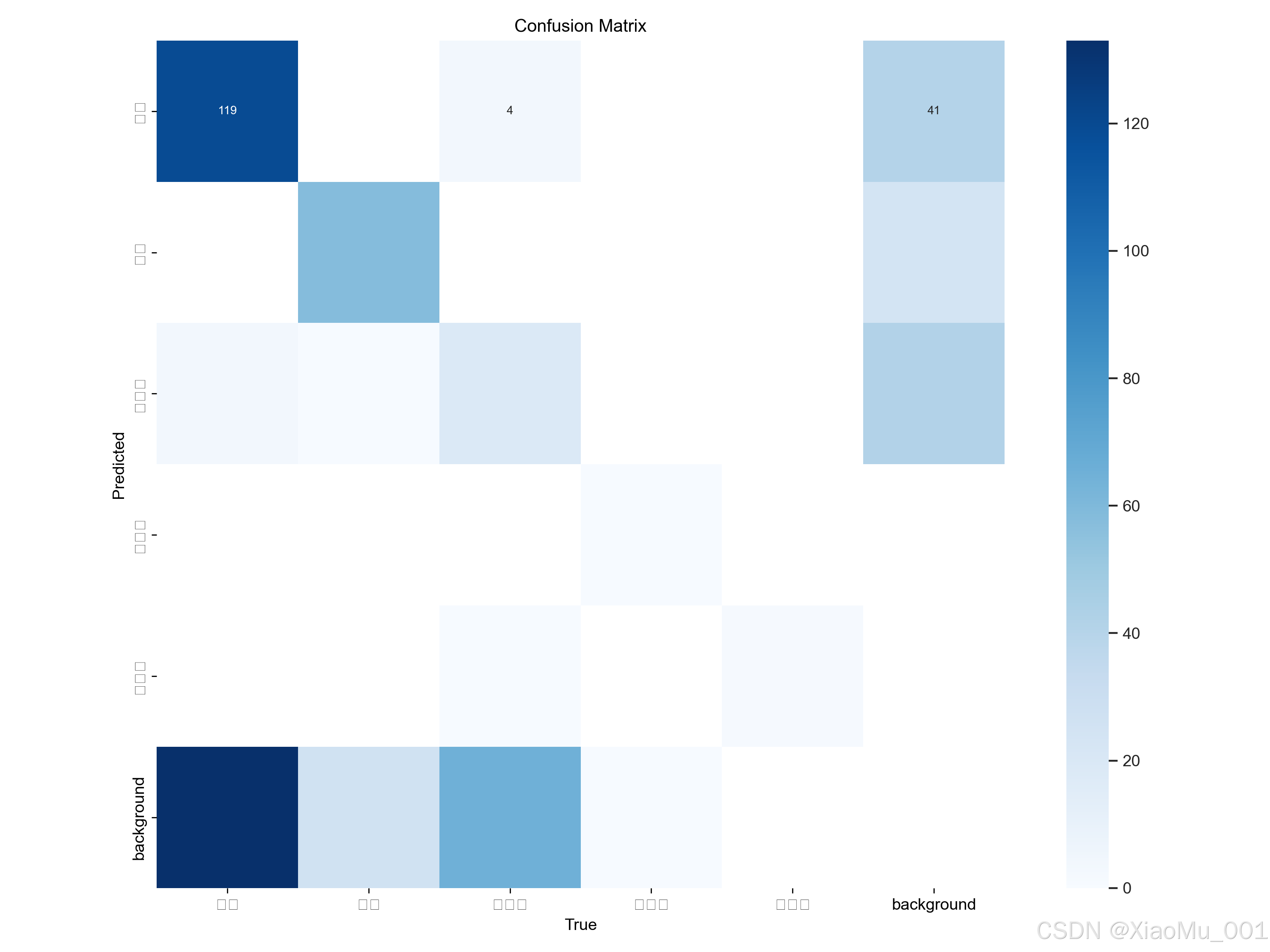
显示了类别间的误判情况。理想情况下,主对角线数值应接近1.0。 - PR曲线 :
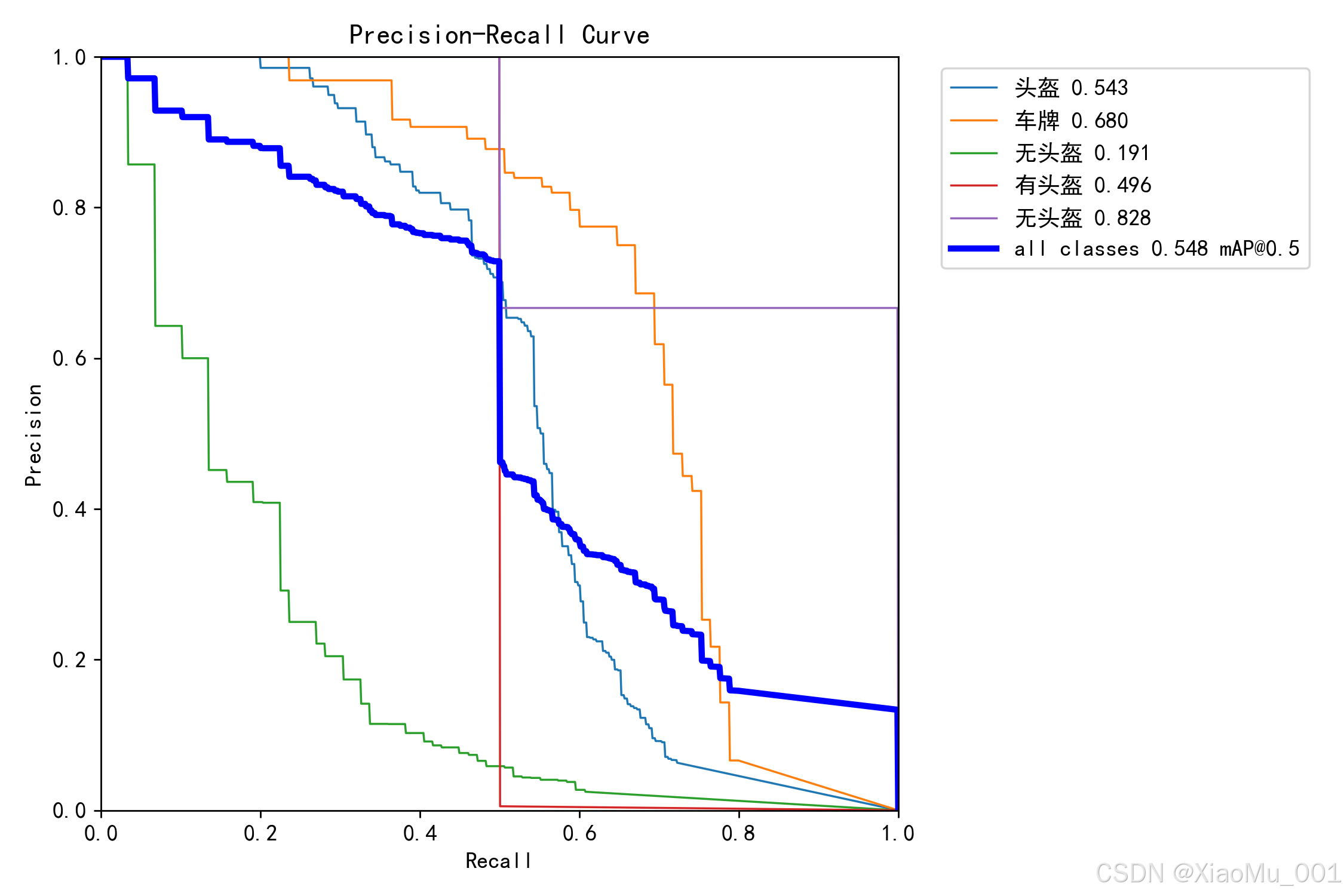
曲线下面积越大越好。 - F1曲线 :
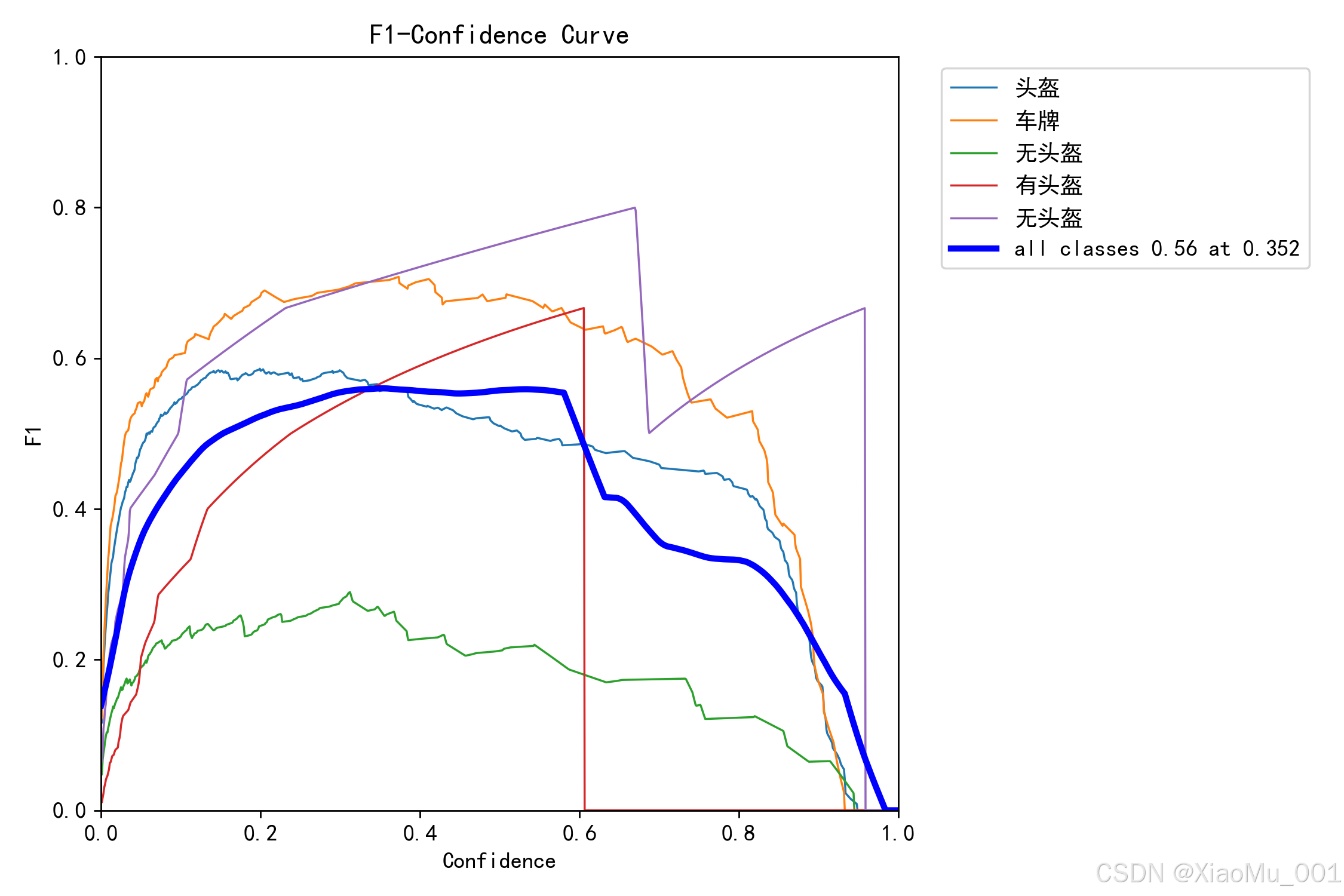
寻找最佳置信度阈值,平衡精确率和召回率。
5. 数据库详细设计 (Database Schema)
后端采用关系型数据库存储核心业务数据。以下是详细的数据字典。
5.1 用户表 (auth_user)
Django 原生用户表,支撑系统的权限管理体系。
| 字段名 | 类型 | 长度 | 约束 | 说明 |
|---|---|---|---|---|
id |
Integer | - | PK, AI | 用户ID |
username |
Varchar | 150 | Unique | 登录账号 |
password |
Varchar | 128 | - | PBKDF2加密哈希 |
is_staff |
Boolean | - | - | 是否管理员 (拥有后台权限) |
is_active |
Boolean | - | - | 软删除标记 |
date_joined |
DateTime | - | - | 注册时间 |
5.2 检测任务表 (detection_detectiontask)
系统的核心业务表,记录每一次检测的生命周期。
| 字段名 | 类型 | 长度 | 约束 | 说明 |
|---|---|---|---|---|
id |
Integer | - | PK, AI | 任务ID |
task_type |
Varchar | 20 | Choice | 任务类型: image (图片), video (视频), realtime (实时流) |
input_file |
FilePath | - | Null | 原始上传文件路径 (uploads/...) |
output_file |
FilePath | - | Null | 处理后带标注的文件路径 (results/...) |
status |
Varchar | 20 | Choice | 状态机: pending -> processing -> completed / failed |
result_json |
JSON | - | Null | 结构化结果: {"counts": {"helmet": 5}, "boxes": [...]} |
location |
Varchar | 100 | Null | 检测发生的场景/地点 (如"主入口监控") |
created_at |
DateTime | - | Index | 创建时间,用于按时间倒序查询 |
5.3 训练模型表 (detection_trainedmodel)
支持多模型版本管理与热切换。
| 字段名 | 类型 | 长度 | 约束 | 说明 |
|---|---|---|---|---|
id |
Integer | - | PK, AI | 模型ID |
name |
Varchar | 100 | - | 模型名称 (如 "YOLOv8n-Helmet") |
version |
Varchar | 50 | - | 版本号 (v1.0, v2.0) |
path |
Varchar | 255 | - | .pt 权重文件的物理路径 |
map |
Float | - | Null | 模型的 mAP@0.5 评分 |
is_active |
Boolean | - | - | 激活标记 (全局只能有一个为True) |
6. 系统功能模块与界面详解 (System Modules & Interfaces)
本系统提供了直观、友好的 Web 操作界面,涵盖了从用户管理到核心检测的全流程功能。
6.1 用户认证模块
- 功能: 提供用户登录和注册功能。
- 安全机制 :
- 前端对密码进行长度校验。
- 后端使用 Django 的
authenticate进行验证,通过后签发 JWT Token。 - 未登录用户访问系统会自动重定向至此页面。
6.2 综合监控仪表盘 (Dashboard)
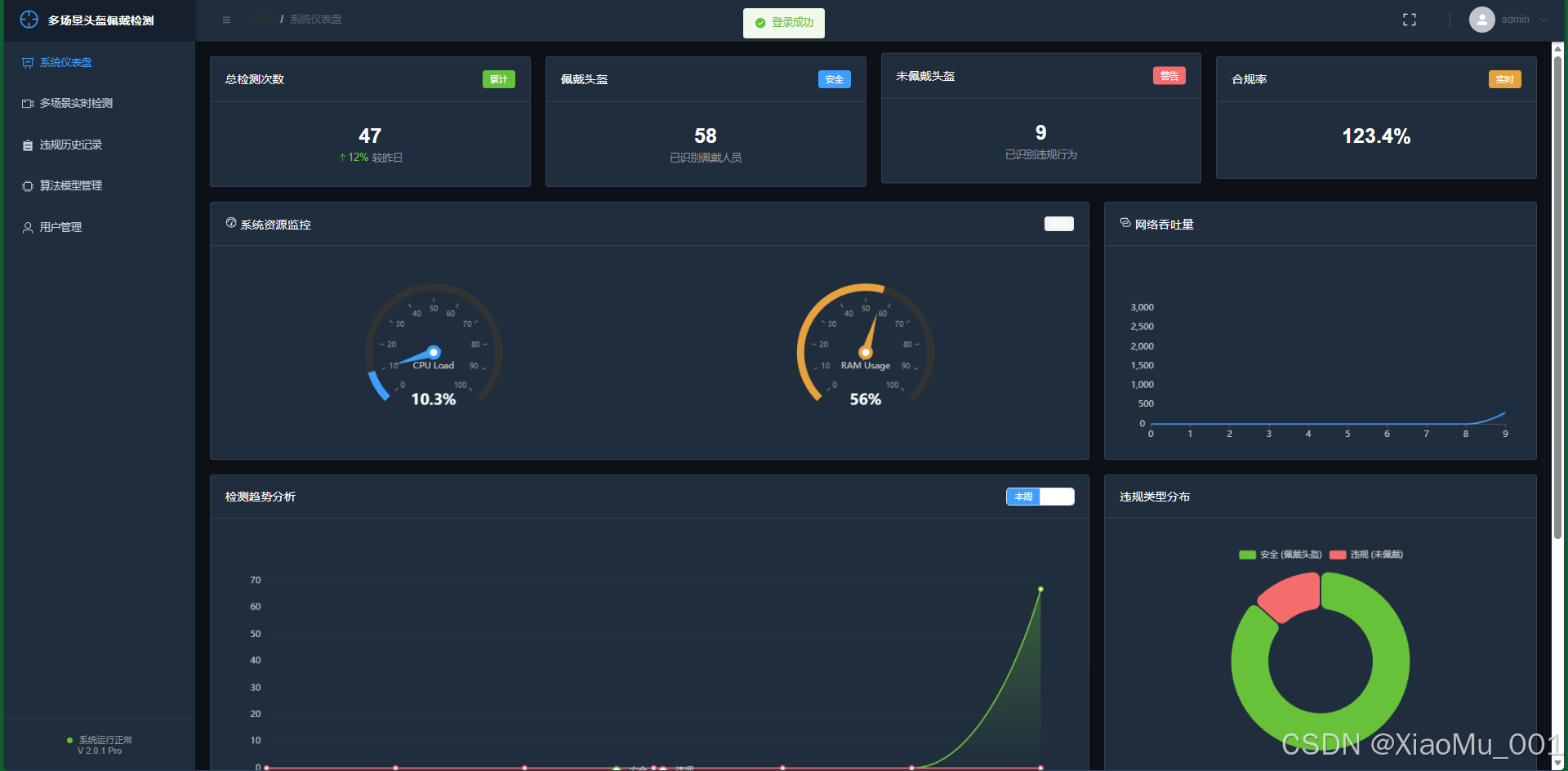
- 功能: 系统的"驾驶舱",展示全局统计数据。
- 展示内容 :
- 关键指标卡片: 实时显示今日检测数、违规数、在线设备等核心指标。
- 趋势图表: 使用 ECharts 绘制折线图,展示近7天的违规趋势,帮助管理者掌握安全状况变化。
- 分布统计: 展示不同类型的违规占比。
6.3 智能检测中心 (Detection Center)
检测中心是系统的核心功能区,支持多种检测模式。
A. 实时视频流检测
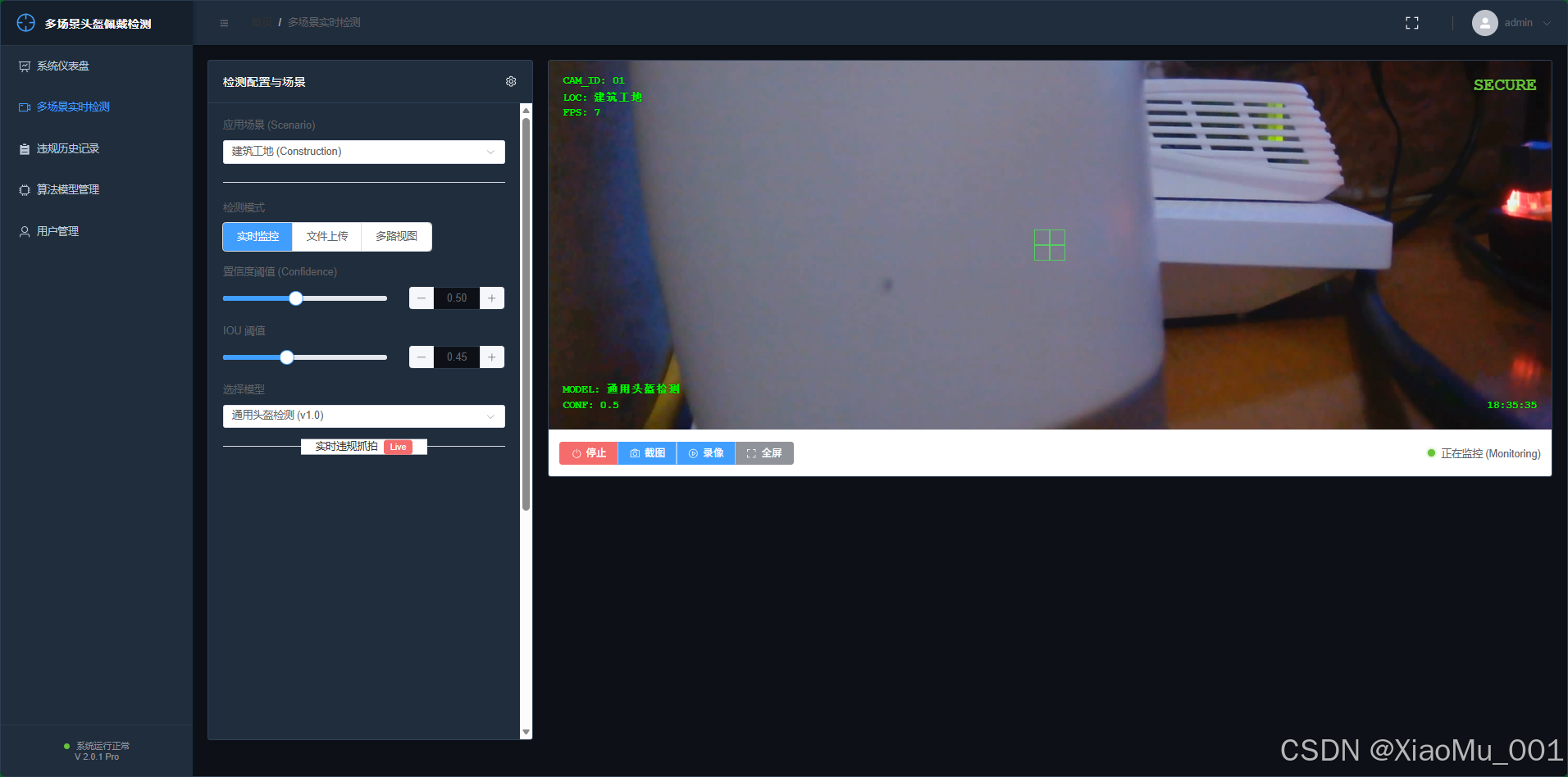
- 功能: 调用本地或网络摄像头进行实时监控。
- 特性 :
- 实时推理: 每一帧画面实时传输至后端或在前端预处理,延迟低。
- 声光报警: 当检测到"未佩戴头盔"时,界面会出现红色警示框,并伴有提示音。
- 自动抓拍: 系统会自动截取违规画面并保存至历史记录,作为证据留存。
B. 图片上传检测
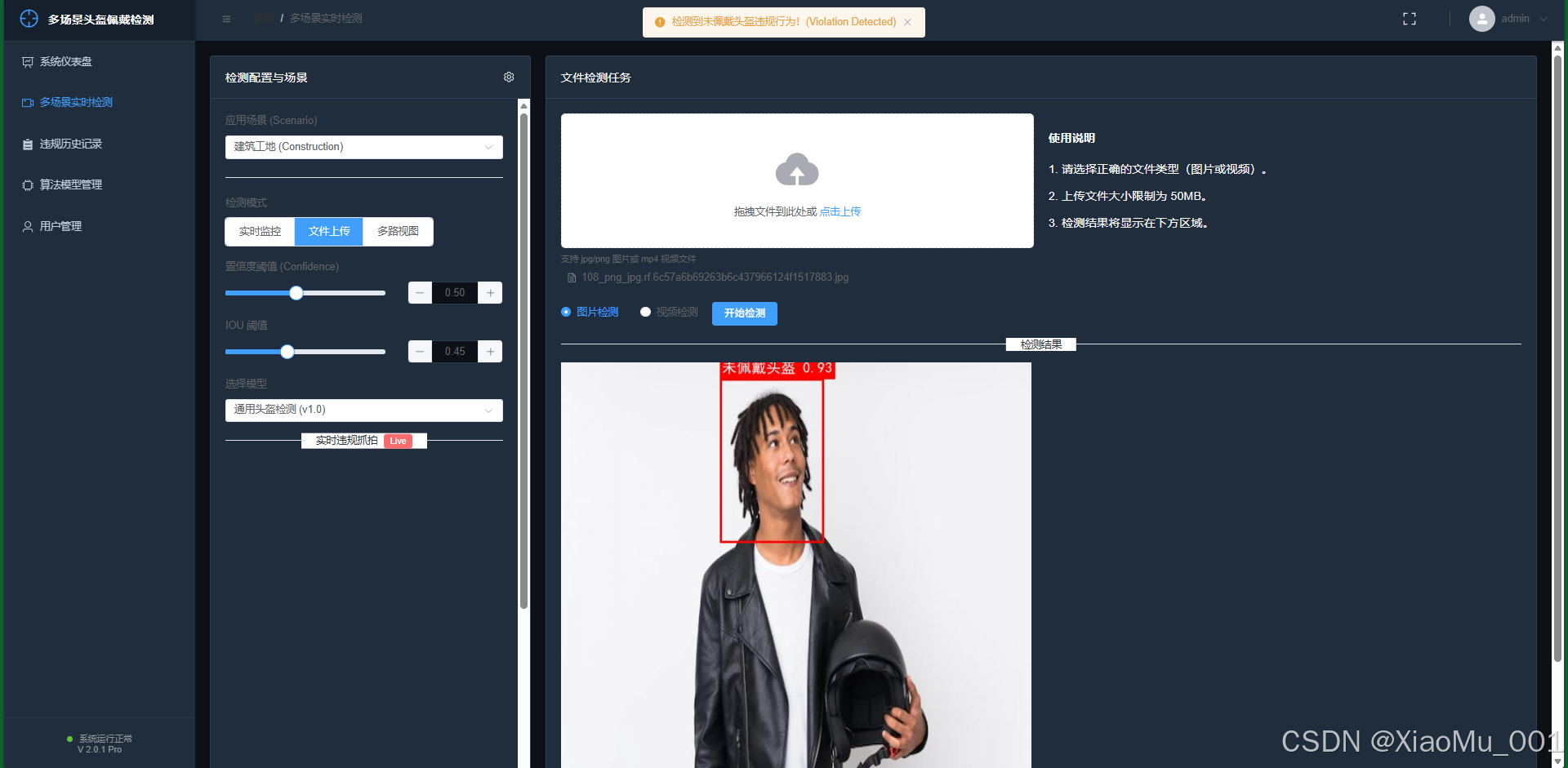
- 功能: 支持用户上传单张或多张静态图片进行检测。
- 流程: 用户拖拽上传 -> 后端分析 -> 返回带标注框的图片 -> 展示检测类别统计(如:佩戴:5人,未佩戴:2人)。
C. 多路/视频检测
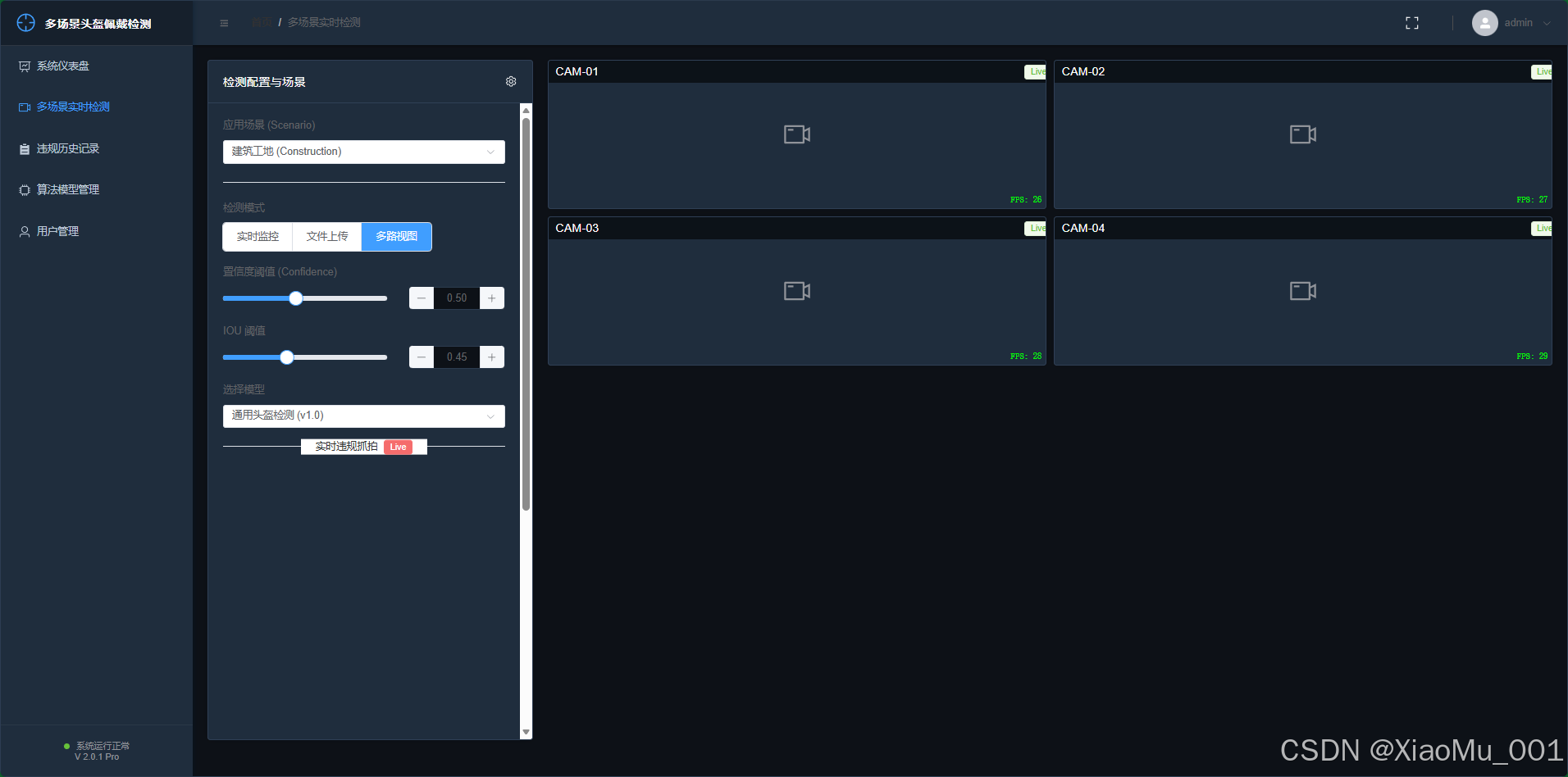
- 功能: 支持视频文件的上传分析,或扩展支持多路摄像头同时监控。
- 特性: 对上传的视频进行逐帧分析,处理完成后生成带标注的视频文件供下载播放。
6.4 历史记录与追溯 (History)
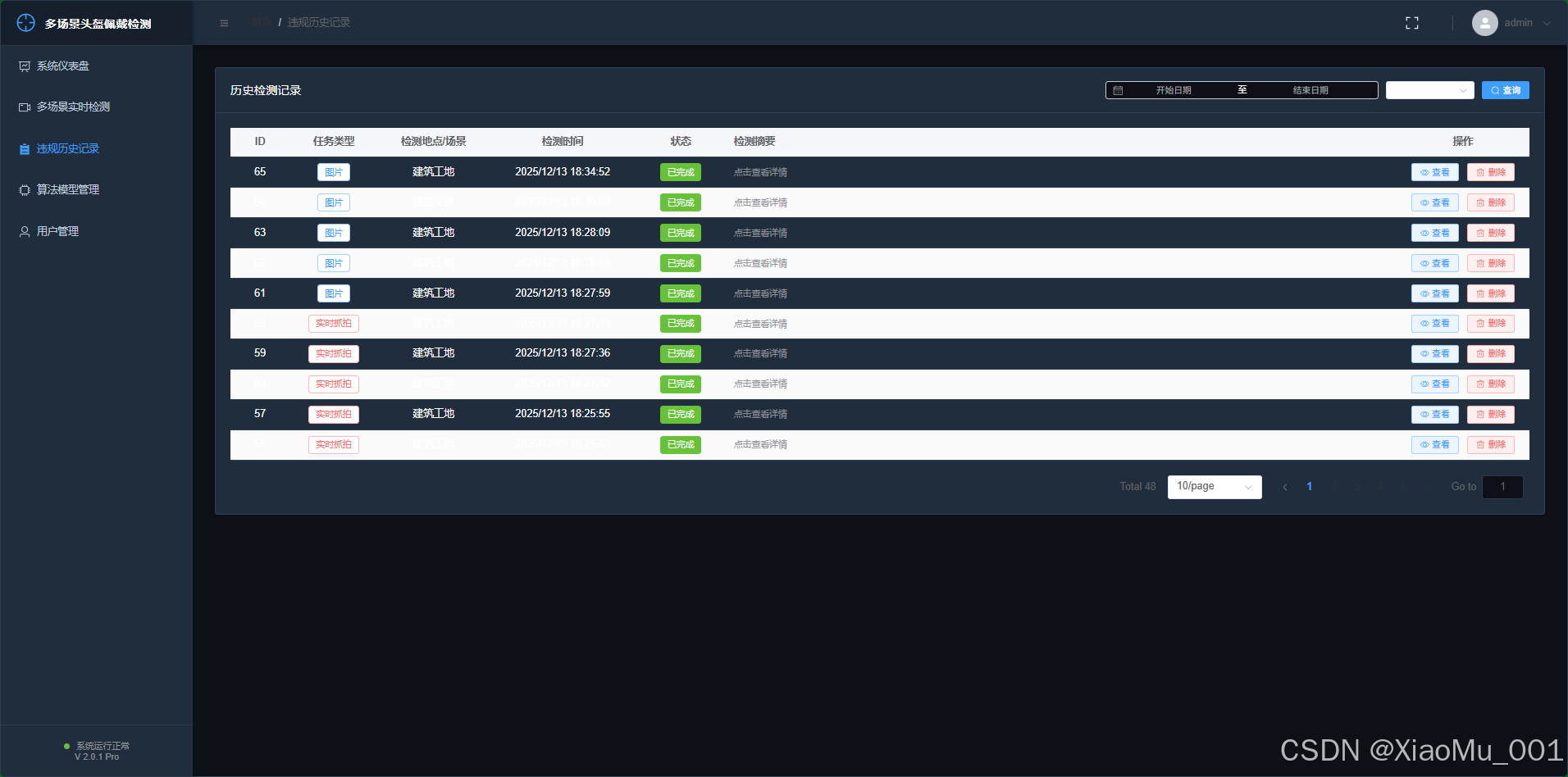
- 功能: 记录所有的检测事件,特别是违规事件。
- 操作 :
- 查询: 支持按时间范围、地点、是否有违规进行筛选。
- 查看: 点击列表项可查看大图及详细的检测数据。
- 删除: 管理员可清理过期的历史记录。
6.5 模型生命周期管理
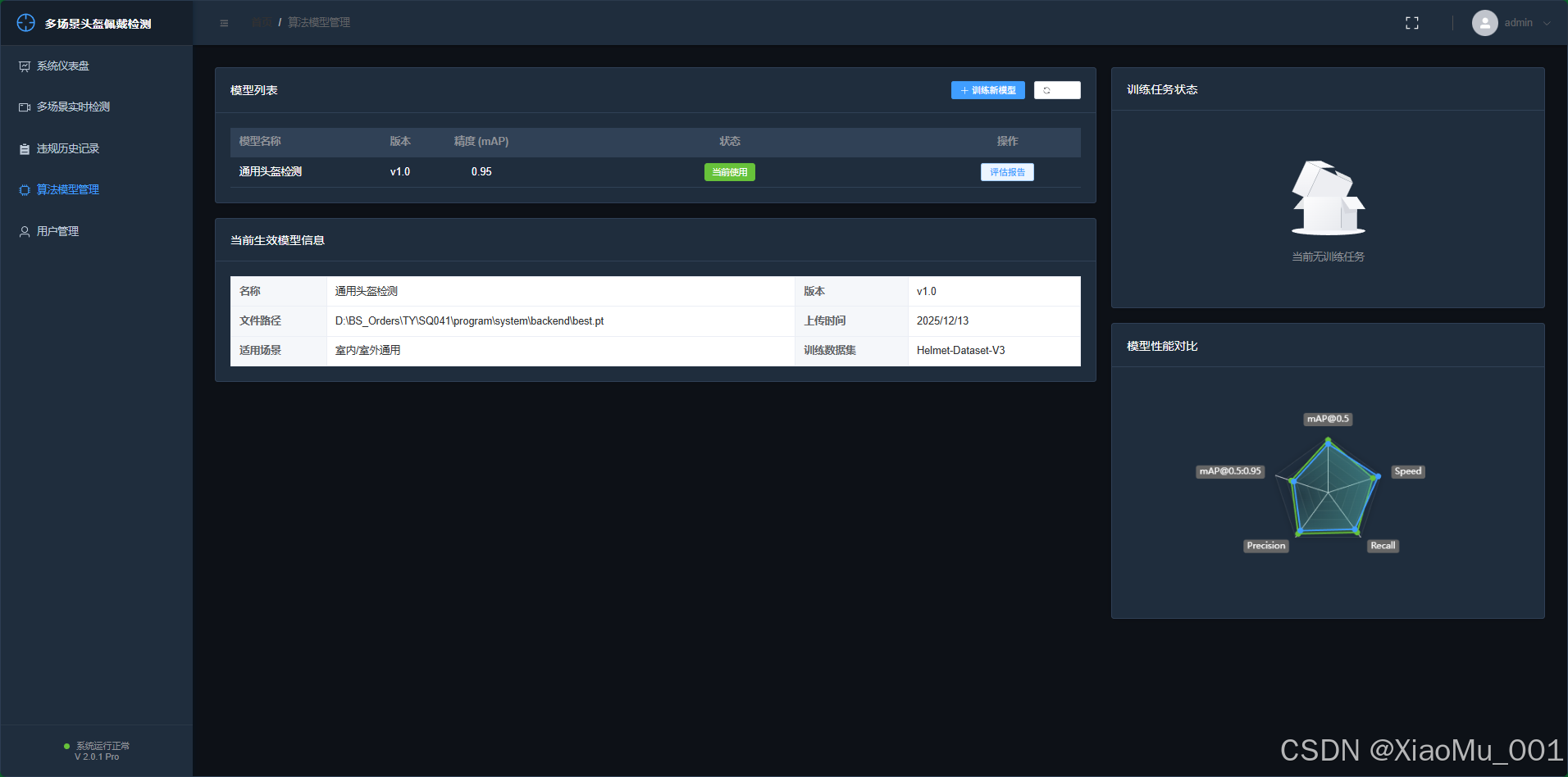
- 功能: 允许管理员管理后台运行的 AI 模型。
- 特性 :
- 模型上传 : 支持上传新的训练好的
.pt权重文件。 - 热切换: 点击"激活"按钮,无需重启服务即可切换当前使用的检测模型(例如从"通用模型"切换到"夜间增强模型")。
- 版本控制: 记录模型的版本号和性能指标 (mAP)。
- 模型上传 : 支持上传新的训练好的
6.6 用户与权限管理
A. 管理员用户管理
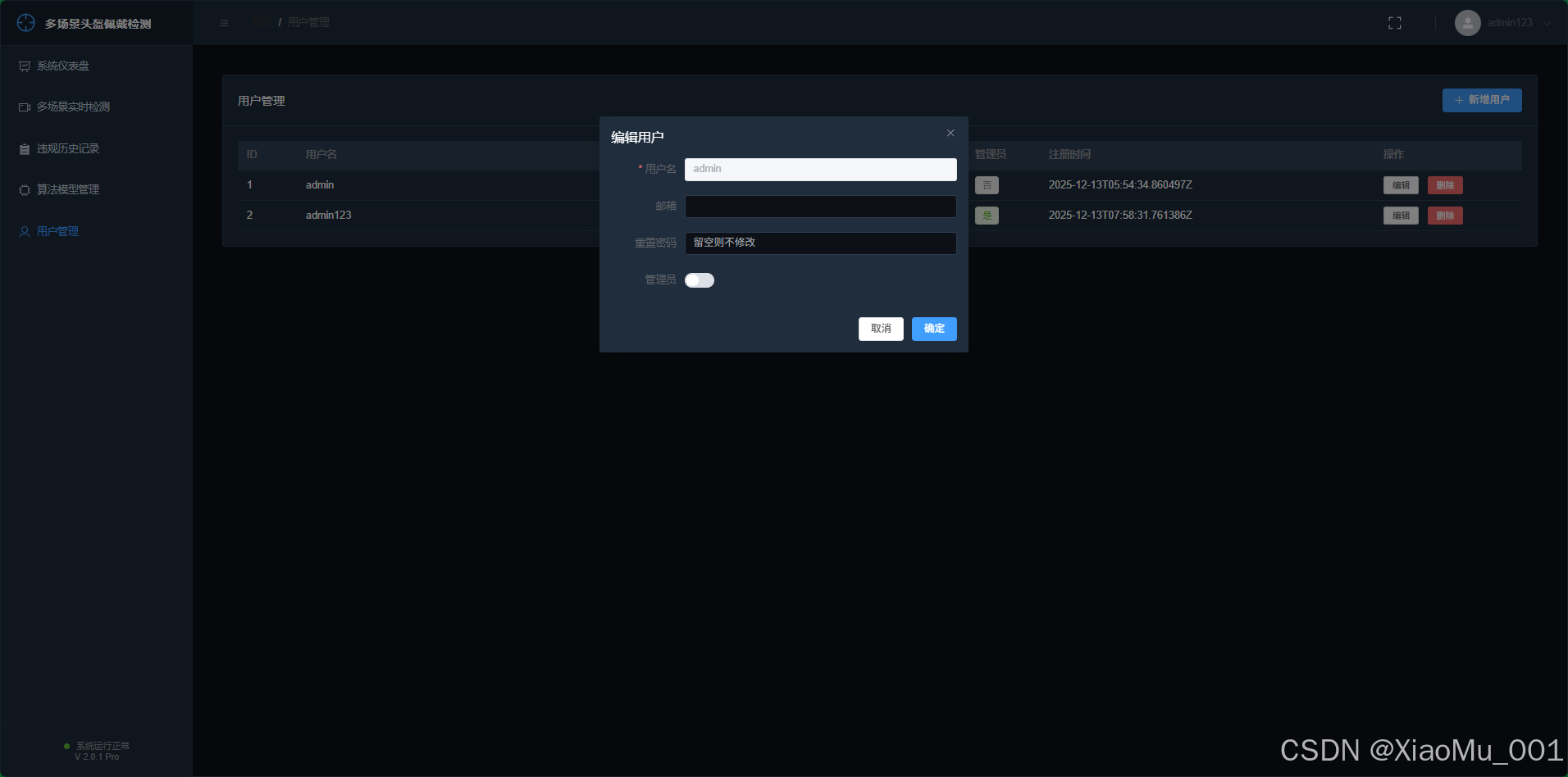
- 权限 : 仅管理员 (
is_staff=True) 可见。 - 功能 :
- 增删改查: 可以添加新用户、重置用户密码、修改用户邮箱。
- 权限分配: 可以设置用户是否为管理员。
B. 个人中心
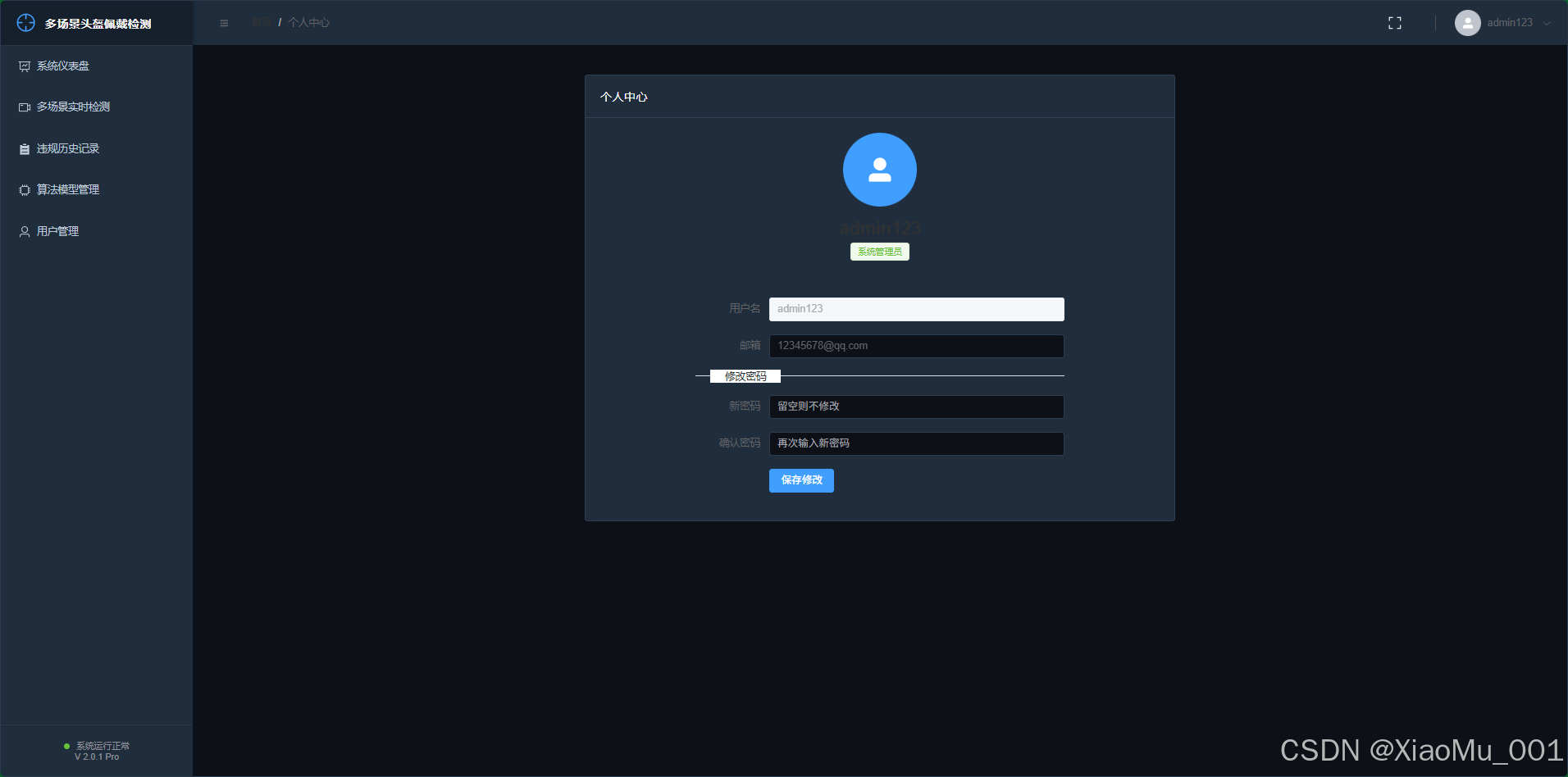
- 权限: 所有登录用户可见。
- 功能 :
- 用户查看自己的基本信息(用户名、注册时间)。
- 修改个人密码,确保账号安全。
7. 部署与环境要求 (Deployment)
7.1 硬件要求
- CPU: 推荐 Intel Core i5 或同级以上 (用于Web服务及数据预处理)。
- GPU: 推荐 NVIDIA GTX 1060 6GB 及以上 (用于加速 YOLO 推理)。无 GPU 亦可使用 CPU 模式,但 FPS 会较低。
- 内存: 8GB+ (加载模型及图像处理缓存)。
7.2 软件环境
- OS: Windows 10/11 或 Linux (Ubuntu 20.04+)。
- Python: 3.9+。
- CUDA: 11.x (如使用 GPU 加速)。
- Node.js: 16+ (用于前端构建)。
8. 总结
本系统不仅仅是一个简单的目标检测演示,而是一个具备工业级特性的完整应用。它通过深度学习技术解决了传统工地监管难、效率低的问题,实现了全天候、无死角的智能安全监控。系统界面友好,功能覆盖了从数据采集、实时检测到事后追溯的全流程,配合灵活的模型管理和权限控制,能够满足不同规模建筑工地的安全管理需求。