0 论文信息
- 论文标题: MFmamba: A Multi-function Network for Panchromatic Image Resolution Restoration Based on State-Space Model
- 中文标题:MFmamba:基于状态空间模型的全色图像分辨率恢复多功能网络
- 论文链接
- 论文代码
- 论文出处:AAAI
0 引言
遥感图像在军事、资源勘探等领域应用广泛,但单一传感器难以同时获取高空间分辨率和高光谱分辨率的图像。全色(PAN)图像空间分辨率高但为灰度,多光谱(MS)图像色彩丰富但空间分辨率低。现有方法通常将图像超分辨率(Super-Resolution, SR)与图像着色作为独立任务处理,前者无法提升光谱信息,后者无法提升空间细节,而全色锐化等融合方法又需要配准的图像对作为输入。
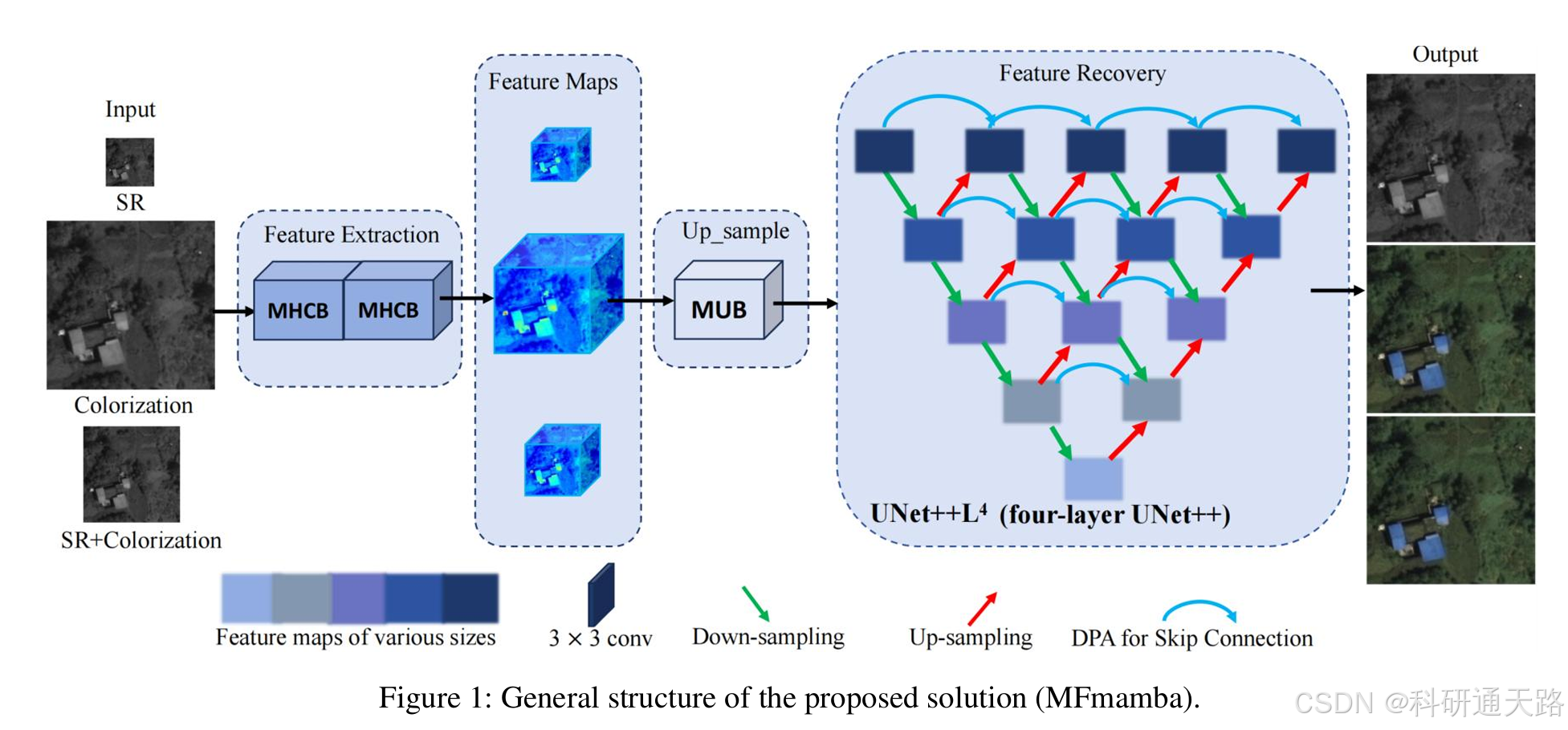
为解决这一困境,本文提出了一种名为 MFmamba 的多功能网络。该网络构建于 UNet++ 架构之上,创新性地集成状态空间模型(State-Space Model),旨在仅通过单张 PAN 图像输入,实现超分辨率、光谱恢复(即着色)、以及二者联合的高质量图像复原。
本文的主要贡献在于:设计了基于 Mamba 的高效上采样模块(MUB),提出了用于浅层特征提取的多尺度混合交叉块(MHCB),并引入双池化注意力机制(DPA)以优化特征表示,从而在一个统一框架内高效协同地完成多项分辨率复原任务。
1 Motivation
- 技术痛点:现有方法无法同时解决 PAN 图像的空间分辨率提升与光谱分辨率恢复问题,超分与彩色化技术相互独立,pansharpening 需双输入且不支持超分,难以满足实际遥感应用需求。
- 性能缺陷:传统 CNN、Transformer 或扩散模型 - based 方法,存在细节特征提取不足、颜色失真、计算效率低等问题,无法兼顾多任务性能与运行速度。
- 需求导向:遥感图像在军事、资源勘探、城市规划等领域应用广泛,亟需一种单输入、多功能、高精度的分辨率恢复方案,简化数据处理流程。
2 创新点
3.1 多尺度混合交叉块 (MHCB)
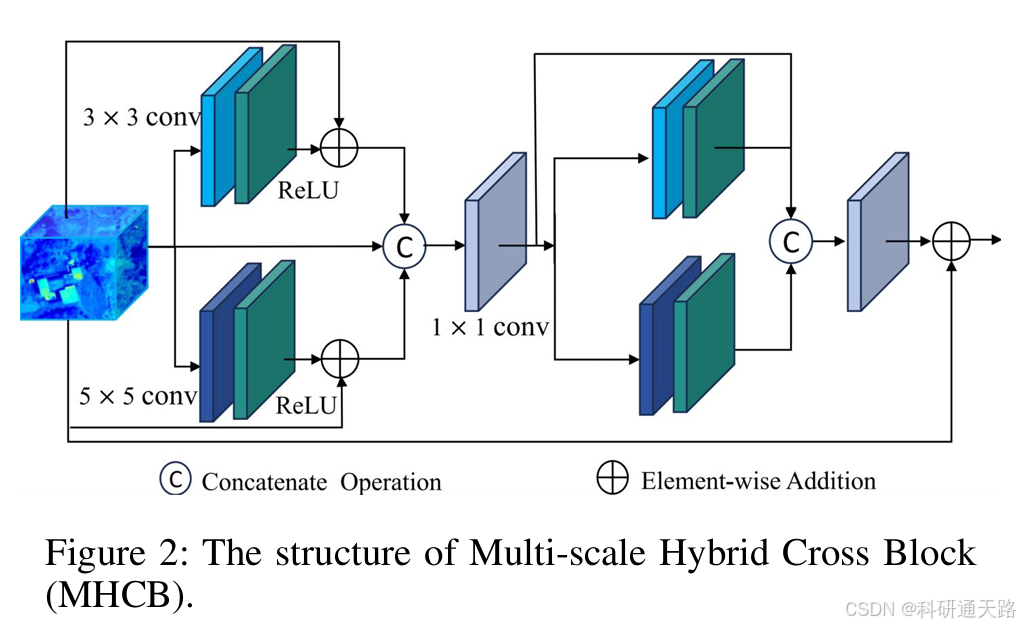
- 核心功能: 作为网络的初始特征提取单元,旨在高效捕获输入图像的局部细节和多尺度上下文信息。
- 该模块并行设置了多个不同感受野的卷积路径。具体而言,它同时使用 3x3 卷积和 5x5 卷积分别提取局部和全局特征,并结合残差连接增强信息流。随后,通过 1x1 卷积对不同尺度的特征进行融合,并再次进行多尺度提取与融合,从而强化关键特征的持久性。其核心计算过程如下:
{ X 1 = ReLU ( 3 × 3 Conv ( X ) ) ⊕ X , X 2 = ReLU ( 5 × 5 Conv ( X ) ) ⊕ X , \begin{cases} X_1 = \text{ReLU}(3 \times 3\text{Conv}(X)) \oplus X, \\ X_2 = \text{ReLU}(5 \times 5\text{Conv}(X)) \oplus X, \end{cases} {X1=ReLU(3×3Conv(X))⊕X,X2=ReLU(5×5Conv(X))⊕X,
X 3 = 1 × 1 Conv ( Concat ( X 1 , X 2 , X ) ) , X_3 = 1 \times 1\text{Conv}(\text{Concat}(X_1, X_2, X)), X3=1×1Conv(Concat(X1,X2,X)),
{ X 4 = ReLU ( 3 × 3 Conv ( X 3 ) ) , X 5 = ReLU ( 5 × 5 Conv ( X 3 ) ) , \begin{cases} X_4 = \text{ReLU}(3 \times 3\text{Conv}(X_3)), \\ X_5 = \text{ReLU}(5 \times 5\text{Conv}(X_3)), \end{cases} {X4=ReLU(3×3Conv(X3)),X5=ReLU(5×5Conv(X3)),
MHCB out = 1 × 1 Conv ( ( Concat ( X 3 , X 4 , X 5 ) ) ⊕ X , \text{MHCB}_{\text{out}} = 1 \times 1\text{Conv}((\text{Concat}(X_3, X_4, X_5)) \oplus X, MHCBout=1×1Conv((Concat(X3,X4,X5))⊕X,
- 优势:相比单一尺寸的卷积核,MHCB能够同时关注不同范围的图像信息,有效提升了模型对复杂细节的提取能力,并利用密集的残差分组设计保证了梯度在网络中稳定传播。
py
import torch
import torch.nn as nn
from model import net_common as common
class MDCB(nn.Module):
def __init__(self, ch_in, ch_out, bias=True, activation=nn.ReLU(inplace=True)):
super(MDCB, self).__init__()
kernel_size_1 = 3
kernel_size_2 = 5
self.conv_3_1 = common.default_conv(ch_in=ch_in, ch_out=ch_in, kernel_size=kernel_size_1, bias=bias)
self.conv_3_2 = common.default_conv(ch_in=ch_out, ch_out=ch_out, kernel_size=kernel_size_1, bias=bias)
self.conv_5_1 = common.default_conv(ch_in=ch_in, ch_out=ch_in, kernel_size=kernel_size_2, bias=bias)
self.conv_5_2 = common.default_conv(ch_in=ch_out, ch_out=ch_out, kernel_size=kernel_size_2, bias=bias)
self.confusion_3 = nn.Conv2d(ch_in * 3, ch_out, 1, padding=0, bias=True)
self.confusion_5 = nn.Conv2d(ch_in * 3, ch_out, 1, padding=0, bias=True)
self.confusion_bottle = nn.Conv2d(ch_in * 3 + ch_out * 2, ch_out, 1, padding=0, bias=True)
self.activation = activation
def forward(self, x):
input_1 = x
output_3_1 = self.activation(self.conv_3_1(input_1))
output_3_1 += x
output_5_1 = self.activation(self.conv_5_1(input_1))
output_5_1 += x
input_2 = torch.cat([input_1, output_3_1, output_5_1], 1)
input_2_3 = self.confusion_3(input_2)
input_2_5 = self.confusion_5(input_2)
output_3_2 = self.activation(self.conv_3_2(input_2_3))
output_5_2 = self.activation(self.conv_5_2(input_2_5))
input_3 = torch.cat([input_1, output_3_1, output_5_1, output_3_2, output_5_2], 1)
output = self.confusion_bottle(input_3)
return output3.2 双池化注意力 (DPA)
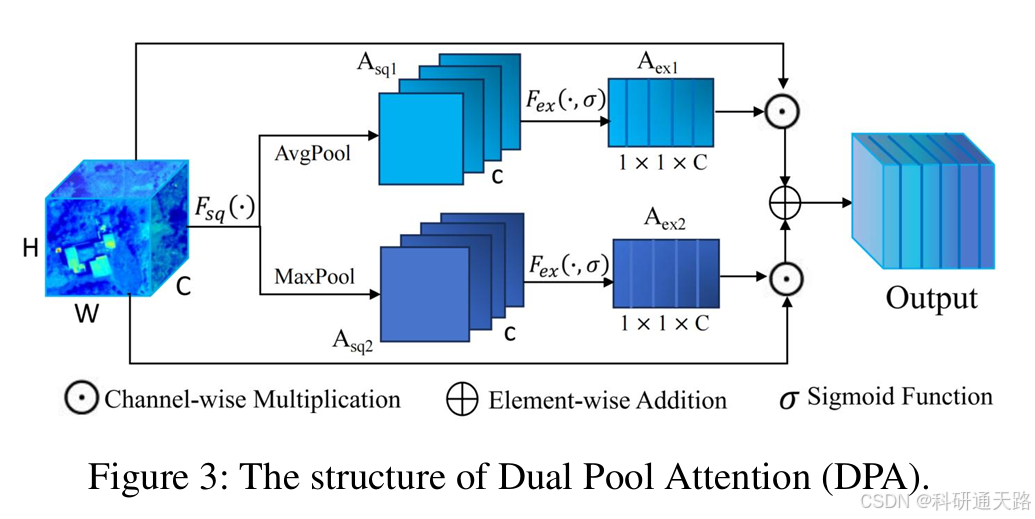
Dual Pool Attention(DPA):采用自适应全局平均池化与最大池化双分支,动态调整通道权重,聚焦关键特征通道,提升特征表示能力。
-
核心功能:用于替代UNet++中的标准跳跃连接,旨在通过动态调整通道权重来优化特征传递,使模型能聚焦于更重要的特征通道。
-
实现逻辑:DPA采用双池架构进行通道特征校准。它并行使用自适应全局平均池化(Adaptive Average Pooling)和最大池化(Maximum Pooling)压缩全局空间信息,生成两个不同的通道描述符;经Sigmoid函数激活后生成两组通道权重,分别与输入特征相乘;最后将两个加权特征图相加得到最终输出。
-
核心计算过程 :
{ A s q 1 = AP ( i , j ) = 1 H × W ∑ h = 1 H ∑ w = 1 W X h , w , c , A s q 2 = MP ( c , j ) = max p , q ∈ { 1 , . . . , h } X p , q , c \begin{cases} A_{sq1} = \text{AP}(i,j) = \frac{1}{H \times W} \sum_{h=1}^{H} \sum_{w=1}^{W} X_{h,w,c}, \\ A_{sq2} = \text{MP}(c,j) = \max_{p,q \in \{1,...,h\}} X_{p,q,c} \end{cases} {Asq1=AP(i,j)=H×W1∑h=1H∑w=1WXh,w,c,Asq2=MP(c,j)=maxp,q∈{1,...,h}Xp,q,c
{ A e x 1 = sigmoid ( A s q 1 ) , A e x 2 = sigmoid ( A s q 2 ) \begin{cases} A_{ex1} = \text{sigmoid}(A_{sq1}), \\ A_{ex2} = \text{sigmoid}(A_{sq2}) \end{cases} {Aex1=sigmoid(Asq1),Aex2=sigmoid(Asq2)
DPA out = ( X ⊙ A e x 1 ) ⊕ ( X ⊙ A e x 2 ) \text{DPA}{\text{out}} = (X \odot A{ex1}) \oplus (X \odot A_{ex2}) DPAout=(X⊙Aex1)⊕(X⊙Aex2) -
优势:传统注意力机制常单独用平均池化,DPA额外引入最大池化,能更好捕捉特征图中显著、高激活度的信息(如边缘和纹理),与平均池化关注的全局平滑信息互补,实现更全面的特征信息保留和增强。
py
import torch
import torch.nn as nn
class Multi_SEAttention(nn.Module):
def __init__(self, in_planes, reduction=16):
super(Multi_SEAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Sequential(
nn.Linear(in_planes, in_planes // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(in_planes // reduction, in_planes, bias=False),
nn.Sigmoid()
)
self.fc2 = nn.Sequential(
nn.Linear(in_planes, in_planes // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(in_planes // reduction, in_planes, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc1(y).view(b, c, 1, 1)
z = self.max_pool(x).view(b, c)
z = self.fc2(z).view(b, c, 1, 1)
x1 = x * y.expand_as(x)
x2 = x * z.expand_as(x)
x_sum = x1 + x2 + x
return x_sum3.3 Mamba上采样模块(MUB)
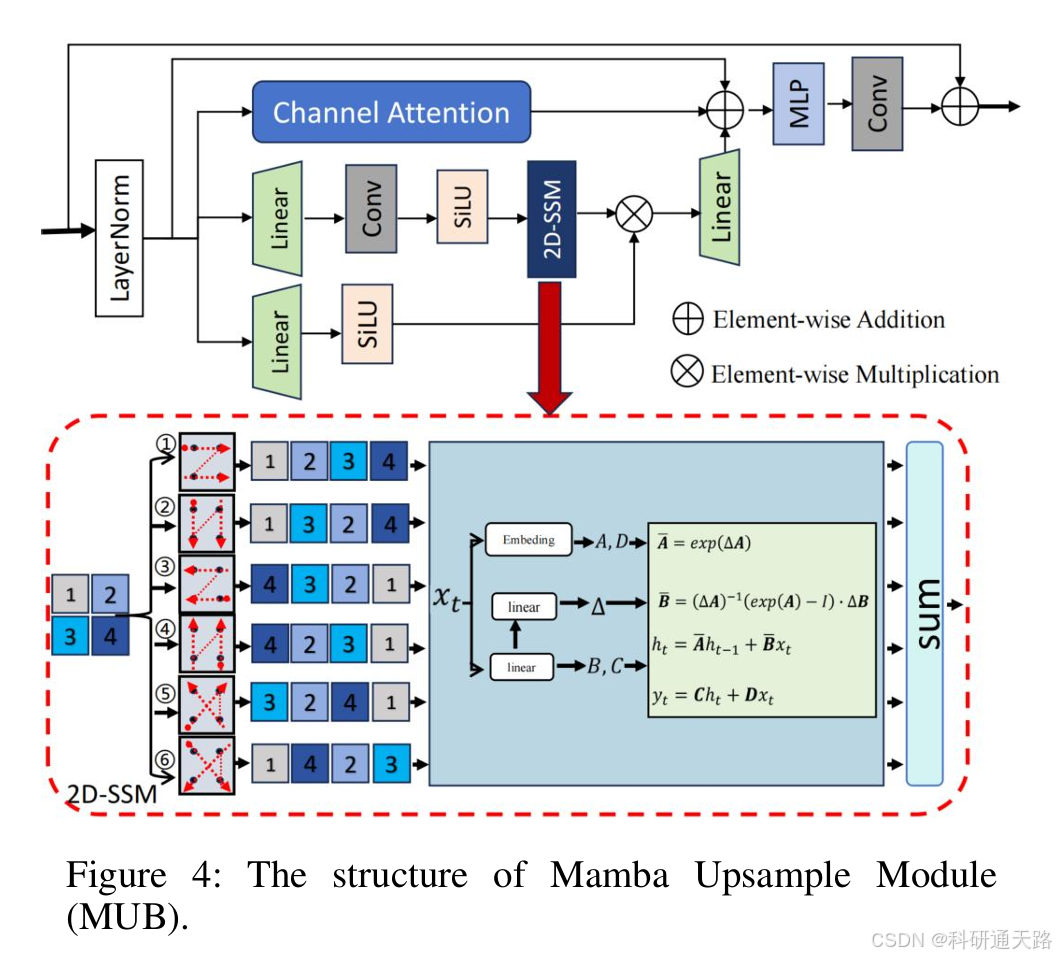
-
核心功能:承担图像的上采样和分辨率恢复任务,利用状态空间模型的长序列建模能力来提升上下文信息的感知和重建效果。
-
实现逻辑 :MUB的核心是二维选择性扫描机制(2D-SSM) ,源于Mamba模型。该机制将一维序列输入 ( x(t) ) 通过隐状态 ( h(t) ) 映射到输出 ( y(t) ),其连续形式由线性常微分方程(ODE)定义:
h ′ ( t ) = A h ( t ) + B x ( t ) , y ( t ) = C h ( t ) + D x ( t ) , h'(t) = Ah(t) + Bx(t),\quad y(t) = Ch(t) + Dx(t), h′(t)=Ah(t)+Bx(t),y(t)=Ch(t)+Dx(t),通过零阶保持(ZOH)离散化后,得到适合深度学习模型的离散形式:
h τ = A ˉ h τ − 1 + B ˉ x τ , y τ = C h τ + D x τ , h_\tau = \bar{A}h_{\tau-1} + \bar{B}x_\tau,\quad y_\tau = Ch_\tau + Dx_\tau, hτ=Aˉhτ−1+Bˉxτ,yτ=Chτ+Dxτ,在MUB中,该机制被应用于2D图像特征:将传统4个扫描方向扩展到6个(新增2个对角线方向),以更全面捕捉空间依赖关系;特征图在每个方向上被展平为1D序列处理,最终结果整合回2D特征图。
-
优势:相比Transformer处理长序列时的高计算复杂度,基于状态空间模型的Mamba具有线性计算复杂度,更高效;同时其选择性扫描机制能根据输入动态调整参数,更灵活地捕捉长距离依赖关系,有助于在分辨率恢复过程中重建更精准的全局结构和纹理。
py
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from einops import repeat
from mamba_ssm.ops.selective_scan_interface import selective_scan_fn
class SS2D(nn.Module):
def __init__(self, d_model, d_state=16, d_conv=3, expand=2., dt_rank="auto",
dt_min=0.001, dt_max=0.1, dt_init="random", dt_scale=1.0, dt_init_floor=1e-4,
dropout=0., conv_bias=True, bias=False, device=None, dtype=None, **kwargs):
super().__init__()
self.d_model = d_model
self.d_state = d_state
self.d_conv = d_conv
self.expand = expand
self.d_inner = int(self.expand * self.d_model)
self.dt_rank = math.ceil(self.d_model / 16) if dt_rank == "auto" else dt_rank
self.in_proj = nn.Linear(self.d_model, self.d_inner * 2, bias=bias)
self.conv2d = nn.Conv2d(self.d_inner, self.d_inner, groups=self.d_inner, bias=conv_bias,
kernel_size=d_conv, padding=(d_conv - 1) // 2)
self.act = nn.SiLU()
self.x_proj_weight = nn.Parameter(torch.empty(4, self.d_inner, (self.dt_rank + self.d_state * 2)))
self.dt_projs_weight = nn.Parameter(torch.empty(4, self.d_inner, self.dt_rank))
self.dt_projs_bias = nn.Parameter(torch.empty(4 * self.d_inner))
self.A_logs = nn.Parameter(torch.log(repeat(torch.arange(1, d_state + 1, dtype=torch.float32), "n -> d n", d=self.d_inner)))
self.Ds = nn.Parameter(torch.ones(4 * self.d_inner))
self.selective_scan = selective_scan_fn
self.out_norm = nn.LayerNorm(self.d_inner)
self.out_proj = nn.Linear(self.d_inner, self.d_model, bias=bias)
self.dropout = nn.Dropout(dropout) if dropout > 0. else None
def forward_core(self, x: torch.Tensor):
B, C, H, W = x.shape
L = H * W
K = 4
x_hwwh = torch.stack([x.view(B, -1, L), torch.transpose(x, 2, 3).contiguous().view(B, -1, L)], dim=1).view(B, 2, -1, L)
xs = torch.cat([x_hwwh, torch.flip(x_hwwh, dims=[-1])], dim=1)
x_dbl = torch.einsum("b k d l, k c d -> b k c l", xs.view(B, K, -1, L), self.x_proj_weight)
dts, Bs, Cs = torch.split(x_dbl, [self.dt_rank, self.d_state, self.d_state], dim=2)
dts = torch.einsum("b k r l, k d r -> b k d l", dts.view(B, K, -1, L), self.dt_projs_weight)
xs = xs.float().view(B, -1, L)
dts = dts.contiguous().float().view(B, -1, L)
Bs = Bs.float().view(B, K, -1, L)
Cs = Cs.float().view(B, K, -1, L)
Ds = self.Ds.float().view(-1)
As = -torch.exp(self.A_logs.float()).view(-1, self.d_state)
dt_projs_bias = self.dt_projs_bias.float().view(-1)
out_y = self.selective_scan(xs, dts, As, Bs, Cs, Ds, z=None, delta_bias=dt_projs_bias, delta_softplus=True,
return_last_state=False).view(B, K, -1, L)
inv_y = torch.flip(out_y[:, 2:4], dims=[-1]).view(B, 2, -1, L)
wh_y = torch.transpose(out_y[:, 1].view(B, -1, W, H), 2, 3).contiguous().view(B, -1, L)
invwh_y = torch.transpose(inv_y[:, 1].view(B, -1, W, H), 2, 3).contiguous().view(B, -1, L)
view5_y = torch.transpose(out_y[:, 3].view(B, -1, W, H), 2, 3).contiguous().view(B, -1, L)
inv_view5_y = torch.flip(view5_y, dims=[-1]).view(B, -1, L)
view6_y = torch.transpose(out_y[:, 3].view(B, -1, W, H), 2, 3).contiguous().view(B, -1, L)
inv_view6_y = torch.flip(view6_y, dims=[-1]).view(B, -1, L)
return out_y[:, 0], inv_y[:, 0], wh_y, invwh_y, inv_view5_y, inv_view6_y
def forward(self, x: torch.Tensor, **kwargs):
B, H, W, C = x.shape
xz = self.in_proj(x)
x, z = xz.chunk(2, dim=-1)
x = x.permute(0, 3, 1, 2).contiguous()
x = self.act(self.conv2d(x))
y1, y2, y3, y4, y5, y6 = self.forward_core(x)
y = y1 + y2 + y3 + y4 + y5 + y6
y = torch.transpose(y, 1, 2).contiguous().view(B, H, W, -1)
y = self.out_norm(y)
y = y * F.silu(z)
out = self.out_proj(y)
if self.dropout is not None:
out = self.dropout(out)
return out3 模块适用任务
- 核心应用场景: 本方法主要针对遥感全色图像的分辨率复原。具体涵盖三个子任务: 1. 单图像超分辨率 (Single Image Super-Resolution):提升灰度PAN图像的空间分辨率。 2. 光谱恢复 (Spectral Recovery):为灰度PAN图像进行着色。 3. 联合超分与光谱恢复 (Joint SR and Spectral Recovery):同时提升PAN图像的空间分辨率和光谱分辨率,即从低分辨率灰度图生成高分辨率彩色图。
- 方法论核心: 其核心思想是在一个统一的深度网络框架内,集成多功能模块以协同解决耦合的图像复原任务。它通过专门设计的特征提取、注意力机制和基于状态空间模型的重建模块,实现了从单一输入源到多重增强输出的高效转换,避免了传统多阶段方法的误差累积。
- 启发性拓展: 1. 推广至其他医学/自然图像复原: MFmamba 的框架设计具有普适性,其集成的 MHCB、DPA 和 MUB 模块可被迁移至其他领域的图像复原任务,如医学图像去噪、常规照片的低光增强或伪影去除。 2. 轻量化与实时化: 尽管 Mamba 比 Transformer 高效,但整个网络的参数量和计算成本仍是挑战。未来的研究可以探索模型剪枝、知识蒸馏等技术,开发适用于星上实时处理或移动端应用的轻量级版本。