Transformer实战(31)------解释Transformer模型决策
0. 前言
随着大语言模型 (Large Language Model, LLM)的广泛应用,模型输出的准确性与可解释性之间的权衡问题变得尤为重要。可解释人工智能 (explainable artificial intelligence, XAI) 研究中的最大挑战是处理深度神经网络模型中大量的网络层和参数,旨在找到一种方法来理解深度模型如何做出决策。本节将从 Transformer 模型的角度来探讨可解释人工智能,我们已经学习了如何使用多种自注意力机制可视化工具,理解 Transformer 模型如何处理输入,并解释学习到的表示。在本节中,我们将通过两种重要方法,LIME 和 SHapley Additive exPlanations (SHAP),解释 Transformer 模型如何做出决策。
1. 解释模型决策
即使我们无法完全理解大语言模型 (Large Language Model, LLM)的决策或结果,我们仍然可以理解导致这一决策的某些方面。但首先,我们需要理解在本节中试图解释的内容。解释模型主要包括以下三个分类方式:
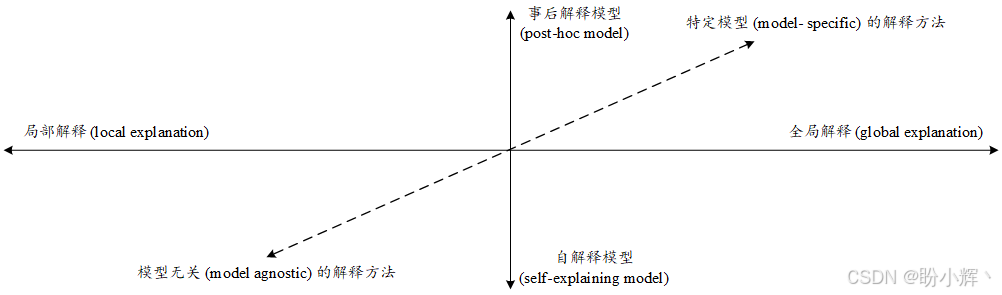
首先,根据试图理解模型如何做出整体决策,还是它在特定输入下的行为,可以分为全局解释 (global explanation) 和局部解释 (local explanation)。局部解释器处理特定输入上的决策,而全局解释器则尝试解释模型的整体预测过程。
可解释人工智能 (explainable artificial intelligence, XAI) 模型的第二个区别在于它们是自解释模型 (self-explaining) 还是事后解释模型 (post-hoc models)。在自解释模型方法中(也称为自解释器),模型不仅做出预测,还提供解释,例如自注意力机制。需要注意的是,自注意力机制用于构建上下文相关的词和句子嵌入,而不是用于做决策。决策树等传统的机器学习模型以及其他基于规则的模型是全局自解释器的典型例子。事后解释模型则需要额外的过程来理解模型的决策行为,其中通过训练一个代理模型来解释主模型。这种事后过程可以是全局的,也可以是局部的。LIME 能够利用代理模型生成局部解释,而 SHAP (SHapley Additive exPlanations) 则可以在全局和局部两种方式下工作。
XAI 的另一个方面区别是模型特定和模型无关的解释工具。模型特定工具只能与特定的模型一起使用,而模型无关工具则能够解释任何黑盒模型。
随着机器学习的最新趋势集中于基于大规模神经网络的模型,如 LLM,这些模型通常被视为黑盒模型,因此代理模型 (surrogate models) 和模型无关的方法越来越受欢迎。这些代理模型可以帮助解释神经网络模型的决策行为。
流行的开源实现包括:
SHAPLIMELITELI-5Transformers InterpretCaptum
接下来,我们介绍 LIME 和 SHAP 模型,以便理解 Transformers 模型的决策。
2. 使用 LIME 解释 Transformer 模型决策
LIME 是一个模型无关、局部和事后解释的方法。LIME 背后的主要思想是输入扰动,对输入(在本节中是一个句子)应用随机扰动,并测量它们对输出(情感或类别)的影响。这个过程使用一个简单的可训练机器学习模型作为主要的可解释人工智能 (explainable artificial intelligence, XAI) 代理模型。
在 LIME 过程中,解释定义为模型行为的局部线性近似。这是因为许多模型在全局上非常复杂,所以在特定实例的邻域内近似更容易。为了实现这一点,对待解释的实例进行扰动,并且在该实例的邻域内学习一个稀疏线性模型(也称代理模型)。
我们可以将 LIME 过程简化为以下步骤:
- 首先,选择一个待解释的预测
- 通过随机隐藏特征来扰动输入,并收集黑盒模型的结果,生成围绕原始单个样本的邻域数据
- 根据新样本与原始预测的相似度为邻域样本分配权重
- 在邻域样本上训练一个更简单、可解释的线性模型,获得一个代理模型
- 最后,使用代理模型预测此局部预测的解释
接下来,我们通过一个实际示例,使用 lime 和 transformers 库来理解 LIME 过程。
(1) 首先,使用 pip 命令安装所需库:
shell
$ pip install lime(2) 使用一个微调的土耳其语文本分类模型:
python
import lime
from lime.lime_text import LimeTextExplainer
from transformers import (AutoTokenizer, AutoModelForSequenceClassification)
model_path = 'savasy/bert-turkish-text-classification'
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForSequenceClassification.from_pretrained(model_path)
class_names =model.config.id2label.values()(3) 该模型有七个类别,具体如下:
python
class_names
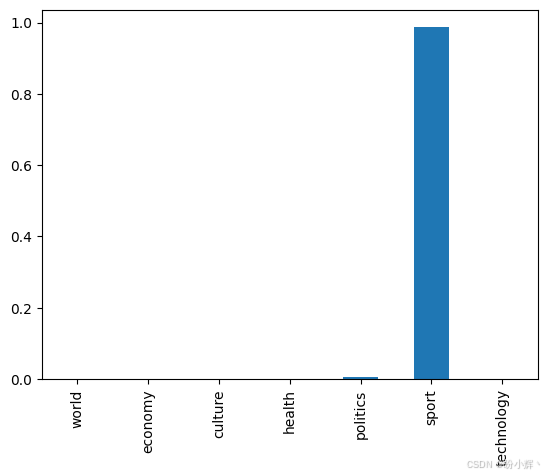
# dict_values(['world', 'economy', 'culture', 'health', 'politics', 'sport', 'technology'])接下来,我们将输入一段土耳其语文本并解释其分类结果。文本内容为 "Ünlü futbolcu Ahmet Yıldız sene sonunda yapılacak turnuva maçları hakkında konuştu",意思是:"著名足球运动员 Ahmet Yıldız 谈到了将在年底举行的锦标赛比赛"。很明显,这段文本是关于体育 (sport) 的内容。
(4) 对输入进行分类,并绘制类别概率分布图:
python
import pandas as pd
import torch.nn.functional as Func
text = 'Ünlü futbolcu Ahmet Yıldız sene sonunda yapılacak turnuva maçları hakkında konuştu'
outputs = model(**tokenizer(text,
return_tensors="pt",
padding=True))
probabilities = Func.softmax(outputs[0]).detach().numpy()
q=dict(zip(class_names,probabilities[0]))
pd.Series(q).plot(kind="bar")分布图如下,其中从七个类别标签中选择了 "sport" (体育)。
(5) 接下来,我们将为这个决策生成解释。为此,定义函数 pred_prob() 来计算类别概率分布。该函数将被 LIME XAI 模型用于生成邻域样本并训练线性 XAI 分类器:
python
def pred_prob(text):
outputs = model(**tokenizer(text,
return_tensors="pt",
padding=True))
ps = Func.softmax(outputs[0]).detach().numpy()
return ps(6) 定义 LimeTextExplainer,并传入了类别名称。然后,传入文本和 pred_prob 类别概率函数,并选择第五个标签,即 "sport" (体育)类。num_features 参数指定 LIME 模型用于解释决策的特征数,在文本分类的例子中,它指的是 LIME 模型为解释决策而选择的单词数量。num_samples 参数指定生成多少个邻域样本,我们通常会保持这个数值较高,比如 1000 或 5000,以便有效地训练线性分类器:
python
explainer = LimeTextExplainer(class_names=class_names)
exp = explainer.explain_instance(text, pred_prob,
labels= [5],
num_features=7,
num_samples=1000)执行后,输出结果如下所示,它解释了棕色的单词表示文本属于体育类别:

浅蓝色代表非体育内容。如输出所示,文本分类模型在将该文本映射到体育类别时,关注与体育相关的术语。单词的颜色越深,决策越重要。
(7) 接下来,使用一个英语的示例。加载英文的情感分类模型,这是一个多标签文本分类模型,共有 28 个标签。我们将其用作单标签分类模型,并使用 softmax 函数:
python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("SamLowe/roberta-base-go_emotions")
model = AutoModelForSequenceClassification.from_pretrained("SamLowe/roberta-base-go_emotions")
class_names =model.config.id2label.values()(8) 对文本:"I have tried different models, but I have not yet made a decision." 进行分类,模型会将其预测为 "confusion" (困惑,id=6):
python
text= "I have tried different models, but I have not yet made a decision."
explainer = LimeTextExplainer(class_names=class_names)
exp = explainer.explain_instance(text,
pred_prob,
labels= [6],
num_features=7,
num_samples=1000)输出解释如下:

与上一示例一样,每种颜色都有其含义。红色代 "confusion" 标签,而绿色表示非 "confusion" 标签。为了便于可视化,裁剪了 LIME 的输出。运行代码时,可以看到许多关于颜色编码的信息。
LIME 的一个缺点是它的代理模型是基于采样数据点构建的,这使得它对所使用的采样策略非常敏感。对相同局部数据使用不同的采样方法可能导致完全不同的解释结果。其次,LIME 方法基于局部实例可以线性解释的假设。
接下来,我们使用 SHAP 模型解释 Transformers 的决策。
3. 使用 SHAP 解释 Transformer 模型决策
SHAP (Shapley Additive Explanations) 是 XAI 领域最常见和广泛使用的技术之一。它基于博弈论中的 Shapley 值概念。与 LIME 不同,SHAP 并不仅是一个局部可解释模型,而是利用黑盒模型计算每个特征对预测的边际贡献。
通过这种方式,SHAP 提供了通过识别最重要的特征,来深入了解推动模型决策过程的因素,既可以是全局的,也可以是局部的。它通过计算每个局部预测中单词的 SHAP 值来评估特征的重要性,然后通过将每个单独预测的绝对 SHAP 值相加提供全局特征重要性。由于 SHAP 技术能够为复杂的深度学习模型提供准确且可解释的解释,在 XAI 领域越来越受欢迎。
LIME 假设局部模型是线性的,而 SHAP 并不做此类假设。但,SHAP 的一个缺点是,计算 SHAP 值可能计算量大且耗时。这是因为它检查所有可能的组合,并通过蒙特卡洛模拟而非暴力计算进行处理。
接下来,学习使用 SHAP 的过程,使用与 LIME 示例中相同的方法。
(1) 使用 pip 命令安装所需库:
shell
$ pip install shap(2) 加载具有 28 个标签的多标签文本分类模型:
python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("SamLowe/roberta-base-go_emotions")
model = AutoModelForSequenceClassification.from_pretrained("SamLowe/roberta-base-go_emotions")
class_names =model.config.id2label.values()(3) 封装在管道对象中:
python
from transformers import pipeline
classifier= pipeline("text-classification",
model=model,
tokenizer=tokenizer)(4) 对文本进行分类:
python
text= "I have tried different models, but I have not yet made a decision."
classifier(text)
# [{'label': 'confusion', 'score': 0.5284215211868286}](8) 模型会输出 "confusion" (困惑,id=6) 标签。接下来,通过 SHAP 来解释这个决策:
python
import shap
explainer = shap.Explainer(classifier)
shap_values = explainer([text])(9) 指定目标标签为 confusion,这样我们就能看到哪些特征将模型引导向这个决策。将选择条形图可视化方式,因为它比其他方式更易于阅读:
python
shap.plots.bar(shap_values[0,:,"confusion"])输出结果如下所示:
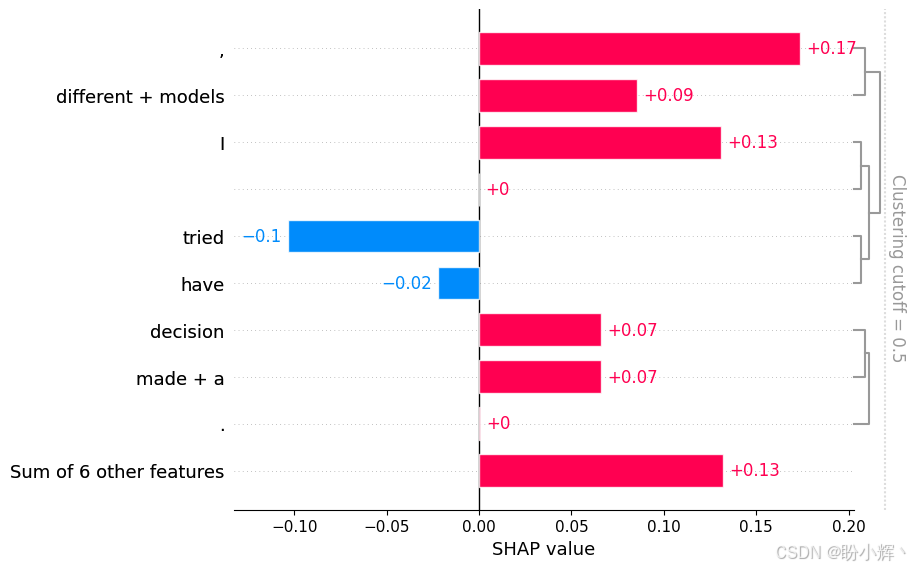
可以看到与 LIME 类似的解释。最后需要指出的是,SHAP 因其基于博弈论中 Shapley 值的理论论证及其简单性而被广泛使用。而在 LIME 中,必须定义如何考虑邻域,此外,还需要构建一个线性的局部模型,而在高度复杂的决策上,这种模型可能并不是线性的。在 SHAP 中,并不做出这样的假设。
小结
在本节中,我们讨论了人工智能面临的最重要问题之一:可解释人工智能 (explainable artificial intelligence, XAI)。随着语言模型的不断发展,可解释性成为一个严峻的问题。本节中,我们从 Transformer 的角度出发,解释了 Transformer 架构的决策过程,使用了两种模型无关的方法:LIME 和 SHAP。通过这两种技术,我们尝试解释模型在简单的文本分类过程中如何赋予输入(单词)不同的权重。
系列链接
Transformer实战(1)------词嵌入技术详解
Transformer实战(2)------循环神经网络详解
Transformer实战(3)------从词袋模型到Transformer:NLP技术演进
Transformer实战(4)------从零开始构建Transformer
Transformer实战(5)------Hugging Face环境配置与应用详解
Transformer实战(6)------Transformer模型性能评估
Transformer实战(7)------datasets库核心功能解析
Transformer实战(8)------BERT模型详解与实现
Transformer实战(9)------Transformer分词算法详解
Transformer实战(10)------生成式语言模型 (Generative Language Model, GLM)
Transformer实战(11)------从零开始构建GPT模型
Transformer实战(12)------基于Transformer的文本到文本模型
Transformer实战(13)------从零开始训练GPT-2语言模型
Transformer实战(14)------微调Transformer语言模型用于文本分类
Transformer实战(15)------使用PyTorch微调Transformer语言模型
Transformer实战(16)------微调Transformer语言模型用于多类别文本分类
Transformer实战(17)------微调Transformer语言模型进行多标签文本分类
Transformer实战(18)------微调Transformer语言模型进行回归分析
Transformer实战(19)------微调Transformer语言模型进行词元分类
Transformer实战(20)------微调Transformer语言模型进行问答任务
Transformer实战(21)------文本表示(Text Representation)
Transformer实战(22)------使用FLAIR进行语义相似性评估
Transformer实战(23)------使用SBERT进行文本聚类与语义搜索
Transformer实战(24)------通过数据增强提升Transformer模型性能
Transformer实战(25)------自动超参数优化提升Transformer模型性能
Transformer实战(26)------通过领域适应提升Transformer模型性能
Transformer实战(27)------参数高效微调(Parameter Efficient Fine-Tuning,PEFT)
Transformer实战(28)------使用 LoRA 高效微调 FLAN-T5
Transformer实战(29)------大语言模型(Large Language Model,LLM)
Transformer实战(30)------Transformer注意力机制可视化