✍✍计算机毕设指导师**
⭐⭐个人介绍:自己非常喜欢研究技术问题!专业做Java、Python、小程序、安卓、大数据、爬虫、Golang、大屏等实战项目。
⛽⛽实战项目:有源码或者技术上的问题欢迎在评论区一起讨论交流!
⚡⚡有什么问题可以在主页上或文末下联系咨询博客~~
⚡⚡Java、Python、小程序、大数据实战项目集](https://blog.csdn.net/2301_80395604/category_12487856.html)
⚡⚡文末获取源码
温馨提示:文末有CSDN平台官方提供的博客联系方式!
温馨提示:文末有CSDN平台官方提供的博客联系方式!
温馨提示:文末有CSDN平台官方提供的博客联系方式!
电影评分人气数据可视化分析系统-简介
本系统是一个基于Spark+Django的电影评分人气数据可视化分析系统,它整合了Hadoop生态系统的分布式存储能力,利用Spark作为核心的大数据处理引擎,并通过Django框架构建稳健的后端服务,前端采用Vue和Echarts进行动态数据呈现,实现了从数据采集、清洗、分析到可视化的完整流程。系统的核心功能聚焦于电影数据的深度洞察,涵盖了电影评分与人气度的分布统计、年度发行趋势分析、评分与投票数的相关性探究、高评分电影特征挖掘以及"叫好不叫座"影片识别等多个维度。例如,它能揭示不同年代电影质量的变化趋势,分析电影发行的季节性规律,甚至研究电影标题或概述文本长度与其成功度的潜在关联。通过这些多维度的分析,系统旨在将海量、复杂的电影数据转化为直观易懂的图表和结论,为理解电影市场规律和用户偏好提供数据支持。
电影评分人气数据可视化分析系统-技术
大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
开发语言:Python+Java(两个版本都支持)
后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
数据库:MySQL
电影评分人气数据可视化分析系统-背景
选题背景
随着流媒体平台的普及和在线电影数据库的日益完善,我们正处在一个被海量电影信息包围的时代。观众不再仅仅是被动接受者,他们通过评分、评论等方式积极参与到电影的评价体系中,产生了庞大的用户行为数据。这些数据背后隐藏着观众的喜好、市场的风向以及电影产业发展的脉络。然而,这些原始数据往往是杂乱无章的,普通用户甚至研究者都难以直接从中获取有价值的信息。因此,如何有效地处理和分析这些数据,将其转化为有意义的洞察,便成了一个值得探索的课题,这为我们的系统提供了现实的研究背景。
选题意义
本课题的意义在于,它为计算机专业的学生提供了一个完整的大数据处理项目实践案例。通过这个项目,学生能够亲手操作从Hadoop存储、Spark计算到Django Web开发的全链路技术,这对于理解和掌握当代大数据技术栈非常有帮助。从实际应用角度看,系统虽然只是一个毕业设计,但它所实现的分析功能,比如对电影评分稳定性、人气度异常值的检测,能够帮助我们更客观地看待电影评价体系,发现一些有趣的规律。它更像是一个探索性的工具,为后续更复杂的推荐系统或市场分析研究提供了一个基础的数据分析框架和思路参考。
电影评分人气数据可视化分析系统-视频展示
基于Spark+Django的电影评分人气数据可视化分析系统
电影评分人气数据可视化分析系统-图片展示
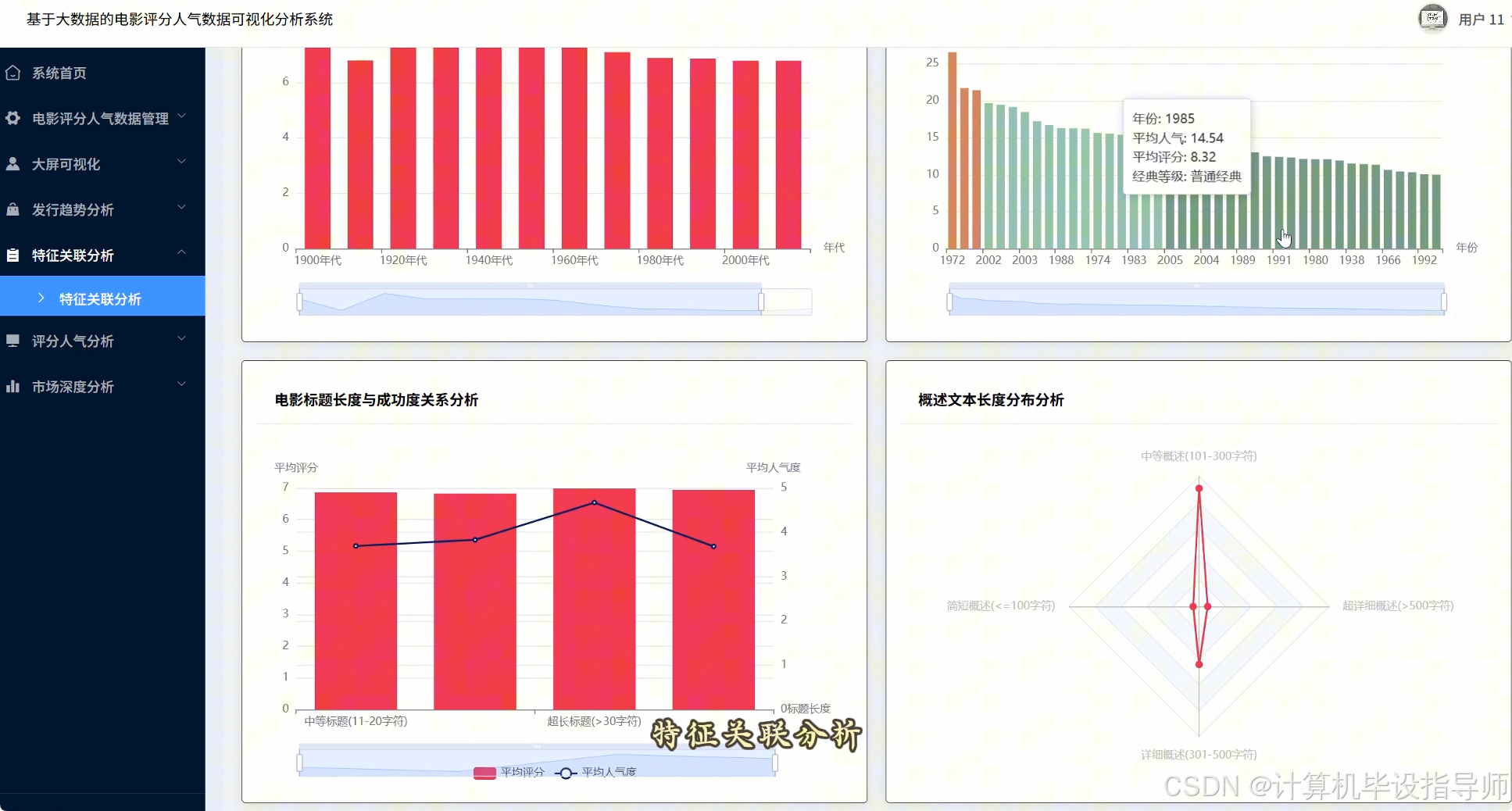
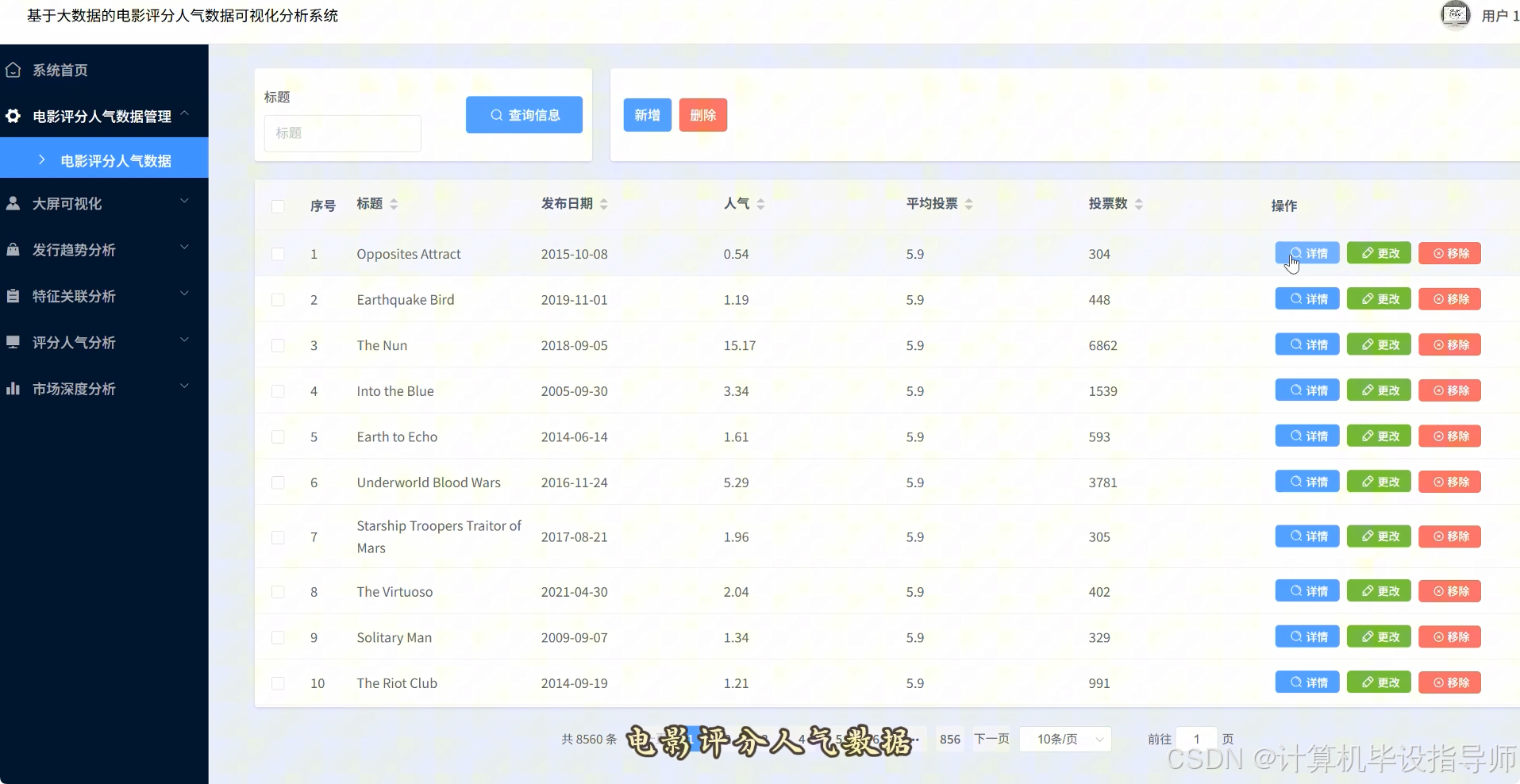

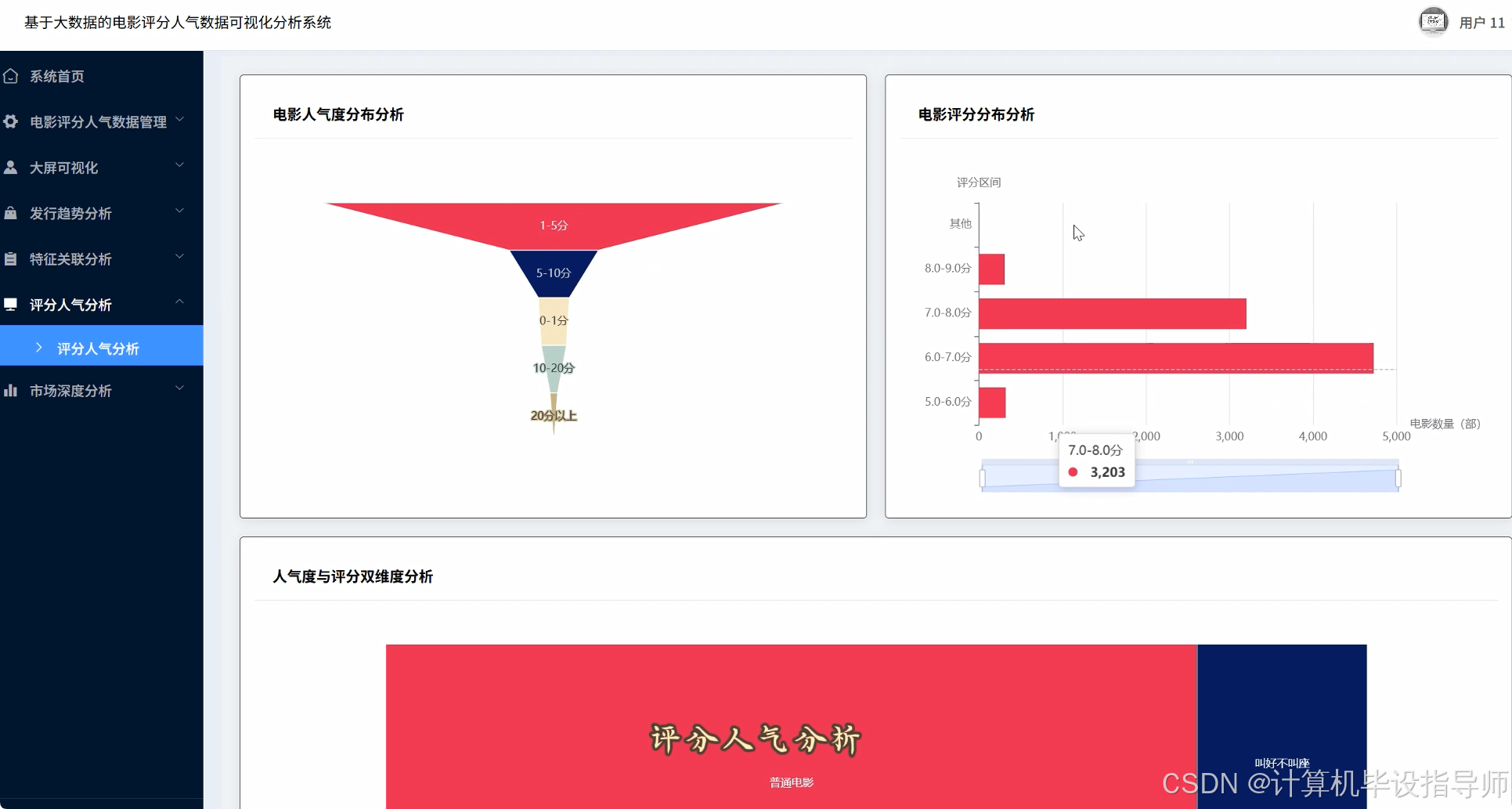
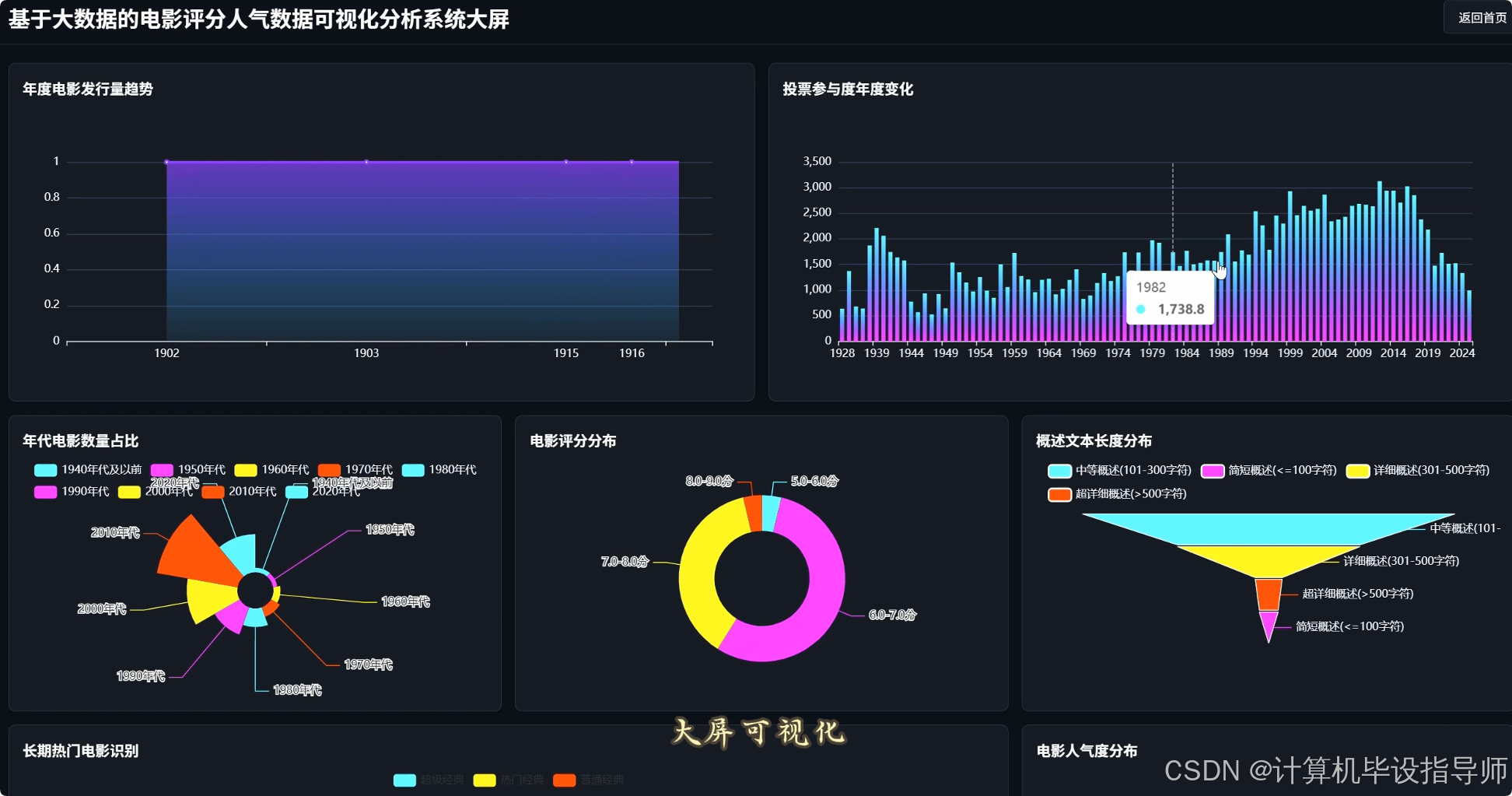
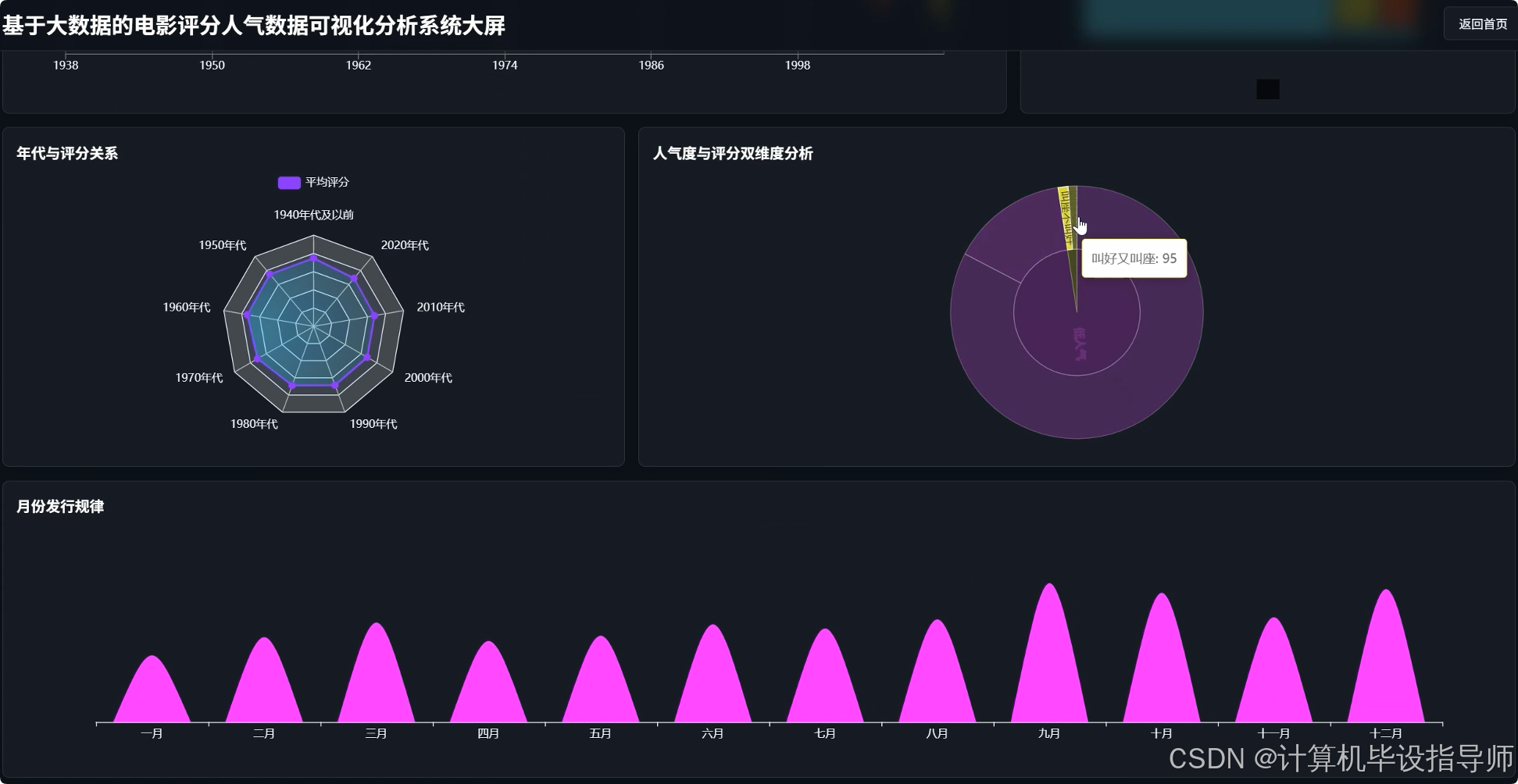
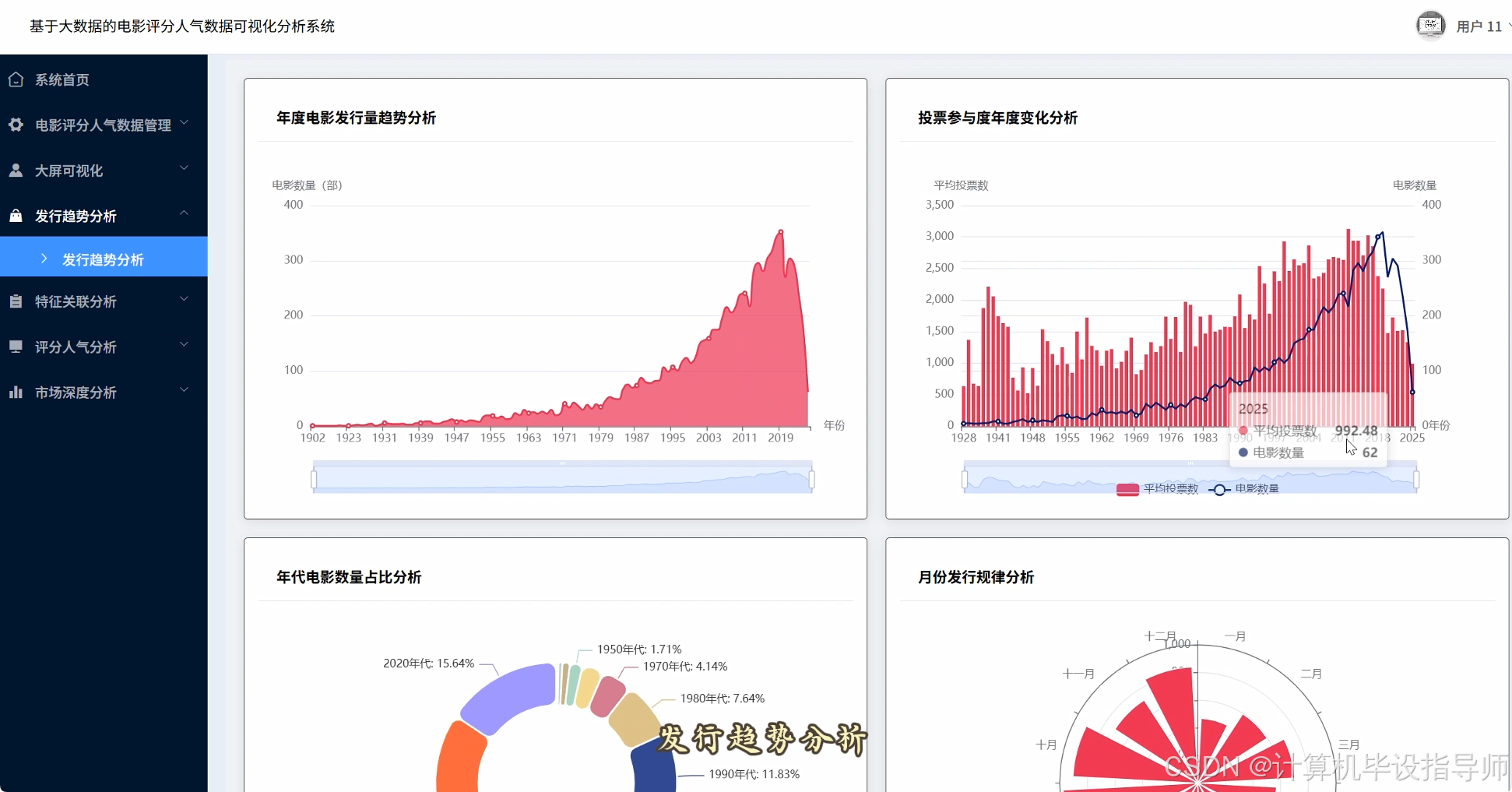
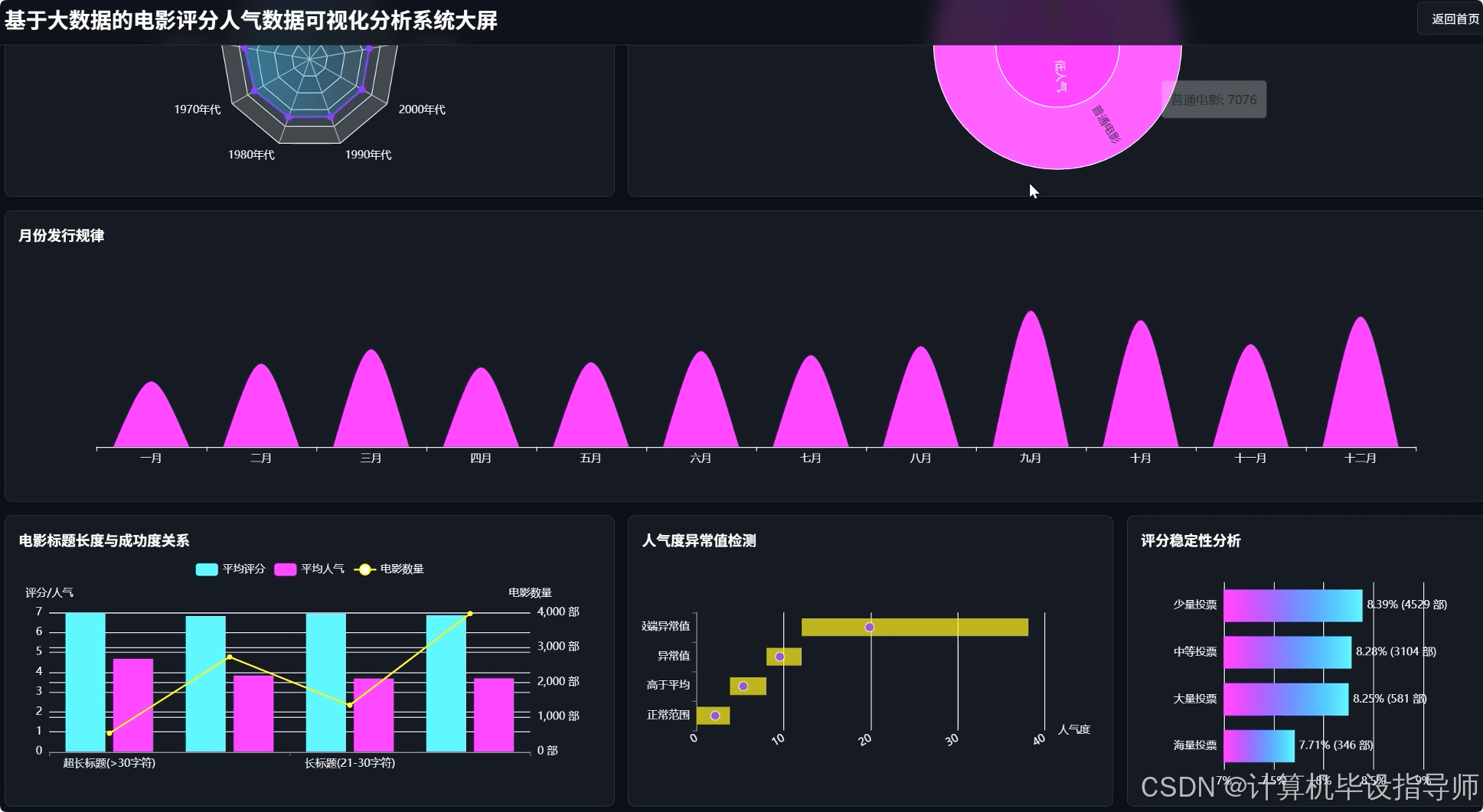
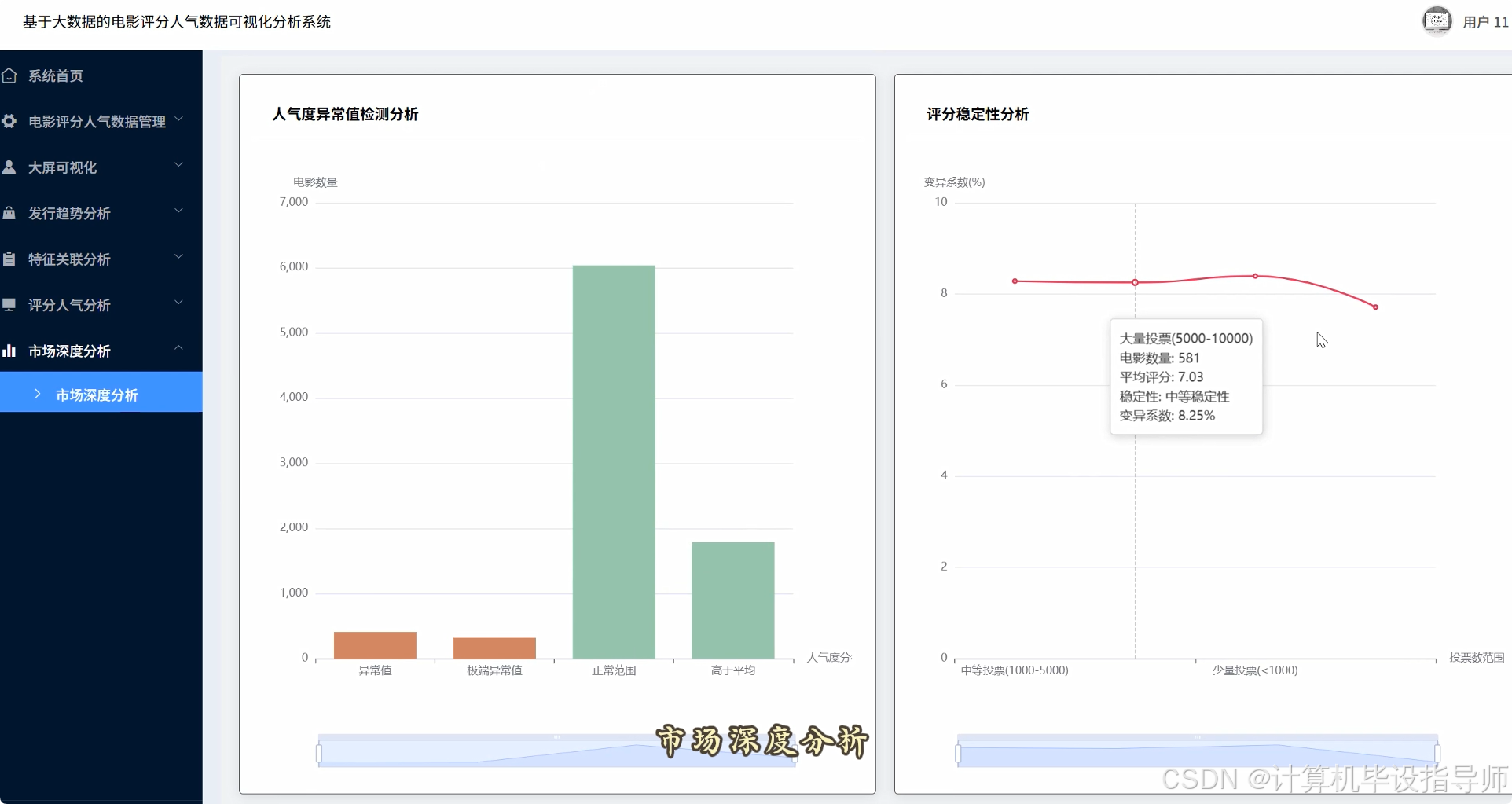
电影评分人气数据可视化分析系统-代码展示
python
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, year, when, count, avg, max as spark_max, min as spark_min
spark = SparkSession.builder.appName("MovieAnalysis").getOrCreate()
df = spark.read.csv("hdfs://path/to/movies.csv", header=True, inferSchema=True)
def analyze_yearly_releases(df):
df_with_year = df.withColumn("release_year", year(col("release_date")))
yearly_counts = df_with_year.filter(col("release_year").isNotNull()).groupBy("release_year").agg(count("title").alias("movie_count")).orderBy("release_year")
yearly_counts.show()
def analyze_popularity_vs_rating(df):
df_binned = df.withColumn("popularity_bin", when(col("popularity") < 1, "0-1").when((col("popularity") >= 1) & (col("popularity") < 5), "1-5").when((col("popularity") >= 5) & (col("popularity") < 10), "5-10").when((col("popularity") >= 10) & (col("popularity") < 20), "10-20").otherwise("20+")).withColumn("rating_bin", when(col("vote_average") < 6, "低分").when((col("vote_average") >= 6) & (col("vote_average") < 8), "中等").otherwise("高分"))
analysis_result = df_binned.groupBy("popularity_bin", "rating_bin").agg(count("title").alias("movie_count")).orderBy("popularity_bin", "rating_bin")
analysis_result.show()
def analyze_high_rating_features(df):
high_rated_movies = df.filter(col("vote_average") >= 8.0).filter(col("vote_count") > 1000)
feature_stats = high_rated_movies.agg(avg("popularity").alias("avg_popularity"), spark_max("popularity").alias("max_popularity"), spark_min("popularity").alias("min_popularity"), avg("vote_count").alias("avg_vote_count"), spark_max("vote_count").alias("max_vote_count"), spark_min("vote_count").alias("min_vote_count"))
feature_stats.show()电影评分人气数据可视化分析系统-结语
从数据处理到前端呈现,这个项目完整地走了一遍大数据分析的流程。虽然还有很多可以优化的地方,但它确实是一个很好的学习实践。希望这个基于Spark+Django的电影分析系统能给正在做毕设的你一些启发和帮助,祝你顺利毕业!
觉得这个大数据电影分析项目怎么样?你的毕设做的什么方向?在评论区聊聊你的想法吧!如果觉得内容对你有帮助,别忘了点赞、收藏和转发,一键三连支持一下,你的鼓励是我更新的最大动力!
⛽⛽实战项目:有源码或者技术上的问题欢迎在评论区一起讨论交流!
⚡⚡如果遇到具体的技术问题或其他需求,你也可以问我,我会尽力帮你分析和解决问题所在,支持我记得一键三连,再点个关注,学习不迷路!~~