https://www.anyscale.com/blog/ray-direct-transport-rdma-support-in-ray-core
长话短说 (tl;dr): Ray 直接传输 (Ray Direct Transport) 功能通过基于 RDMA 的传输方式,在 Ray 中实现了快速、直接的 GPU 数据传输。本文将介绍如何使用其 API 来构建分布式系统,以满足诸如"面向大语言模型的强化学习 (RL for LLMs)"等用例的需求。
由于需要灵活地编排分布式 GPU,Ray 在"面向大语言模型的强化学习 (RL for LLMs)"领域的采用率已大规模增长。Ray 提供了一个用于分布式编排的 API,让 RL 基础设施的构建者能够组合不同的训练和推理引擎、实现不同的计算资源放置(placement)和调度策略,并在不同的框架与工具之间传输 rollout 数据和模型权重。
尽管 Ray 的 API 简化了编排工作,但许多 RL 工作负载都需要高效地处理和传输 GPU 之间的大型张量(tensor),而这一点 Ray 基于 CPU 的对象存储(object store)并不能很好地支持。Ray 的对象存储能为驻留在 CPU 内存中的对象提供高带宽的共享读取,但它无法利用像 Infiniband 和 NVLink 这种可以直接在 GPU 之间移动数据的高性能传输技术。
今天,我们正式推出 Ray 直接传输 (Ray Direct Transport, RDT) ,这是 Ray Core 的一项新功能,它允许用户轻松利用高带宽的 GPU 间通信机制,例如 NVLink 或基于 Infiniband 的 RDMA (远程直接内存访问)。使用 RDT,我们只需修改几行代码,就可以实现比 Ray 原生对象存储快 1000 倍的 GPU-GPU 传输速度。
为了展示其工作原理,我们将介绍"面向大语言模型的强化学习"的系统需求,并演示如何使用 RDT API 构建一个适用于单 GPU 环境的 RL 训练简单脚本。我们将使用 RDT 来管理工作节点(worker)之间的数据传输,并展示您如何在像 NCCL 和 NIXL 这样的库之间切换通信后端。
您现在就可以通过 Ray 2.51.1 版本来试用 RDT。请查阅此处的文档开始使用。
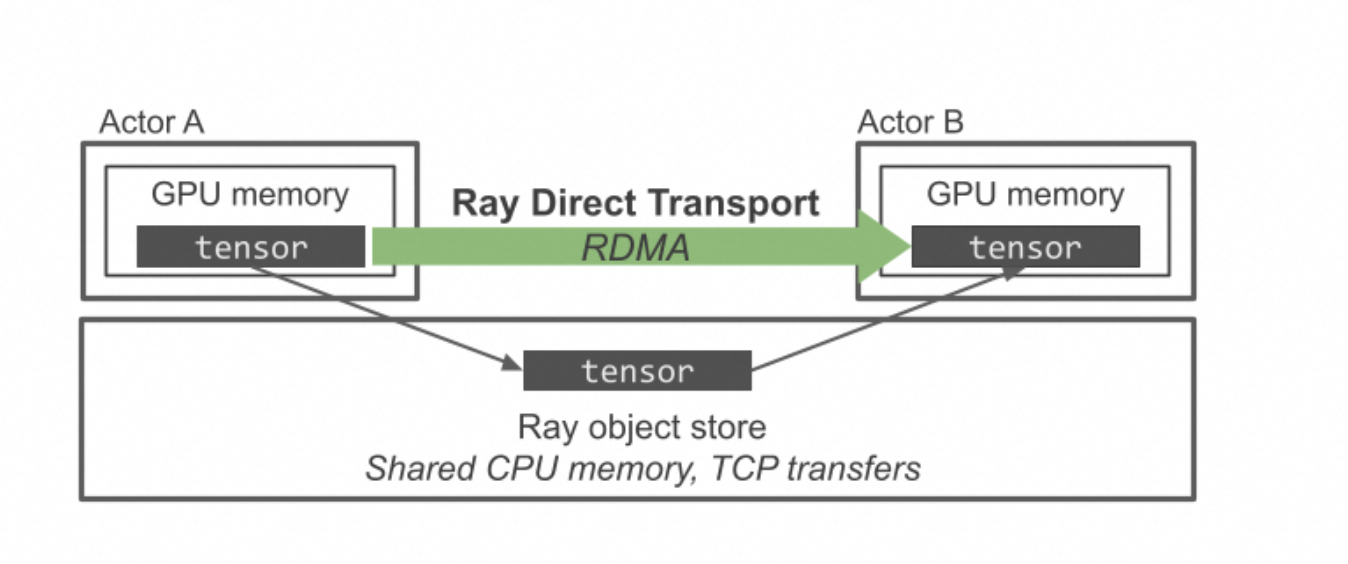
面向大语言模型的强化学习(RL for LLMs)的系统要求
与其他工作负载相比,面向大语言模型的强化学习(RL for LLMs)有一套独特的系统要求。
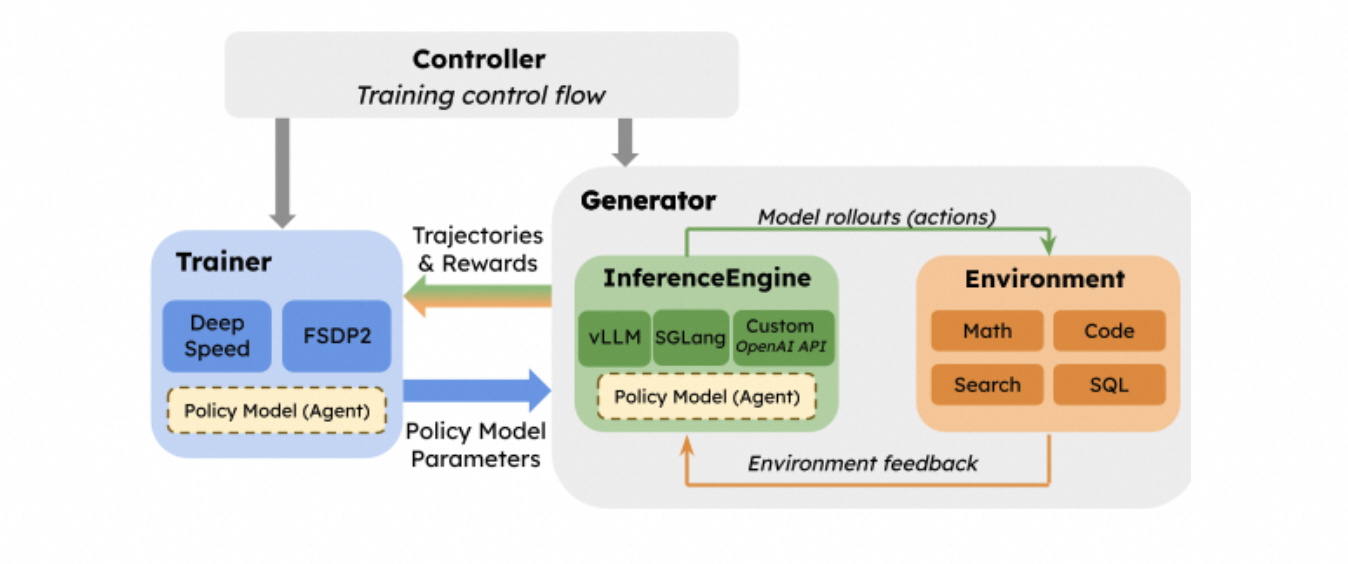
特别是,一个强化学习(RL)训练循环中有两个通信密集型(communication-heavy)的步骤:
-
从训练框架到推理框架的权重同步。 在每个训练步骤中,都会生成新的模型权重,框架需要将更新后的权重发送给每个推理引擎的副本。对于大型模型和大规模集群,这可能需要传输数百 GB 到 TB 级别的数据。
-
从推理到训练的 rollout 数据传输。 虽然纯文本模型生成的数据量相对较小,但对于多模态模型来说,这可能会成为一个性能瓶颈。
我们构建 RDT 的目的,就是为了通过专用的数据传输方式来支持大对象的高效数据传输,尤其是那些使用 RDMA 来减少软件开销的传输方式:
-
大对象: 随着模型体积的增大,每个训练步骤所需的数据传输量也迅速增加。因此,减少像不必要的数据拷贝或序列化这样的软件开销至关重要。
-
专用的数据传输方式: 现代 GPU 通常配备了高带宽的互连技术,如 NVIDIA 的 NVLink,这可以显著加速数据传输。同时,对于每个集群而言,最快的数据传输方式可能各不相同。用户应该能够轻松选择并高效利用每个节点上可用的传输技术。
RDT 通过让您使用标准的 Ray API 来指定 actor 任务之间的数据依赖关系,同时允许您选择使用何种传输方式来完成数据传输,从而支持了这些用例。目前,RDT 支持 Gloo 以及 NVIDIA 的 NCCL 和 NIXL 库;未来的版本将支持其他传输方式,如 CUDA IPC,并使传输层变得可插拔,以便您可以引入自己的传输方式。
深入了解 Ray 直接传输 (Ray Direct Transport)
首先,我们来了解一下这个 API 是如何工作的。我们将基于 Ray Core API 进行构建,但会为启用了 RDT 的对象添加注解。
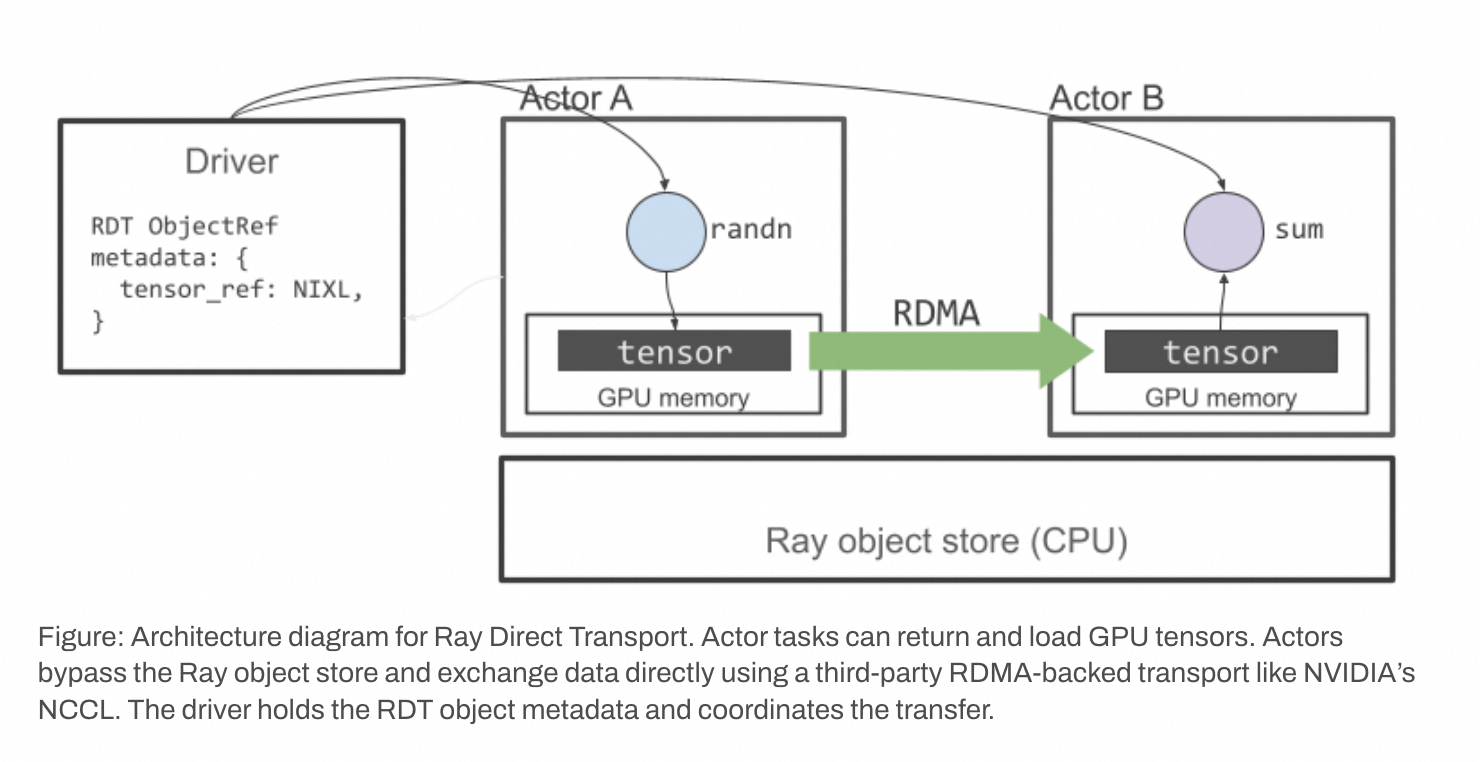
图示:Ray 直接传输的架构图。 Actor 任务可以返回和加载 GPU 张量。Actor 会绕过 Ray 的对象存储,并使用像 NVIDIA NCCL 这样基于 RDMA 的第三方传输库直接交换数据。驱动程序(driver)持有 RDT 对象的元数据并协调传输过程。
注意: 从 Ray v2.50 开始,RDT 仅适用于 Ray actor,并且只有
torch.Tensor类型的数据会通过 RDT 传输。如果torch.Tensor嵌套在 Ray 对象的内部(例如,一个 actor 产出一个torch.Tensor的列表),那么非torch.Tensor的数据仍将通过 Ray 的对象存储进行传输。
要开始使用,首先定义一个 actor 类和一个返回 torch.Tensor 的任务:
python
import torch
import ray
@ray.remote
class MyActor:
def random_tensor(self):
return torch.randn(1000, 1000)接下来,用 @ray.method(tensor_transport=transport_mode) 装饰器来修饰这个 actor 任务,其中 transport_mode 可以是 "nccl", "nixl", "gloo", 或 "object_store" 之一。在这个例子中,我们将使用 NIXL,它支持 GPU-GPU 和 CPU-CPU 的传输。
python
@ray.remote
class MyActor:
@ray.method(tensor_transport="nixl")
def random_tensor(self):
return torch.randn(1000, 1000)这个装饰器可以被添加到任何返回 torch.Tensor 的 actor 任务上,或者返回嵌套了 torch.Tensor 的其他 Python 对象的任务上。添加此装饰器将通过以下方式改变 Ray 的行为:
-
当返回该张量时,Ray 将存储一个对该张量的引用,而不是将其拷贝到基于 CPU 的 Ray 对象存储中。
-
当这个
ray.ObjectRef被传递给另一个任务时,Ray 将使用 NIXL 来将该张量传输到目标任务。
请注意,要使第 (2) 点生效,@ray.method(tensor_transport) 装饰器只需要添加到返回张量的 actor 任务上 。它不应该被添加到消费(使用)该张量的 actor 任务上(除非那些任务自己也返回张量)。这个例子还假设张量的生产者和消费者都安装了 NIXL。pip install nixl 是安装 NIXL 最简单的方式;为了获得最佳性能,请查看 NIXL 的源码编译指南。
现在我们可以在 actor 之间创建并传递 RDT 对象了。这里是一个完整的例子:
python
import torch
import ray
@ray.remote
class MyActor:
@ray.method(tensor_transport="nixl")
def random_tensor(self):
return torch.randn(1000, 1000)
def sum(self, tensor: torch.Tensor):
return torch.sum(tensor)
sender, receiver = MyActor.remote(), MyActor.remote()
# 这个张量将被存储在 `sender` actor 中,而不是在 Ray 的对象存储里。
tensor = sender.random_tensor.remote()
result = receiver.sum.remote(tensor)
print(ray.get(result))当这个 ray.ObjectRef 被传递给另一个任务时,Ray 将使用 Gloo(译者注:原文此处写的是Gloo,但代码示例是nixl,此处应以代码为准,即使用NIXL )直接将张量从源 actor 传输到目标 actor,而不是通过默认的对象存储。请注意,@ray.method(tensor_transport) 装饰器只添加到了返回张量的 actor 任务上;一旦添加了这个提示,接收方的 actor 任务 receiver.sum 将自动使用 Gloo 来接收该张量。在这个例子中,因为 MyActor.sum 方法没有 @ray.method(tensor_transport) 装饰器,它将使用默认的 Ray 对象存储来返回 torch.sum(tensor) 的结果。
更多示例,包括如何使用 ray.put 和基于集合通信(collective-based)的传输,请参阅文档 。
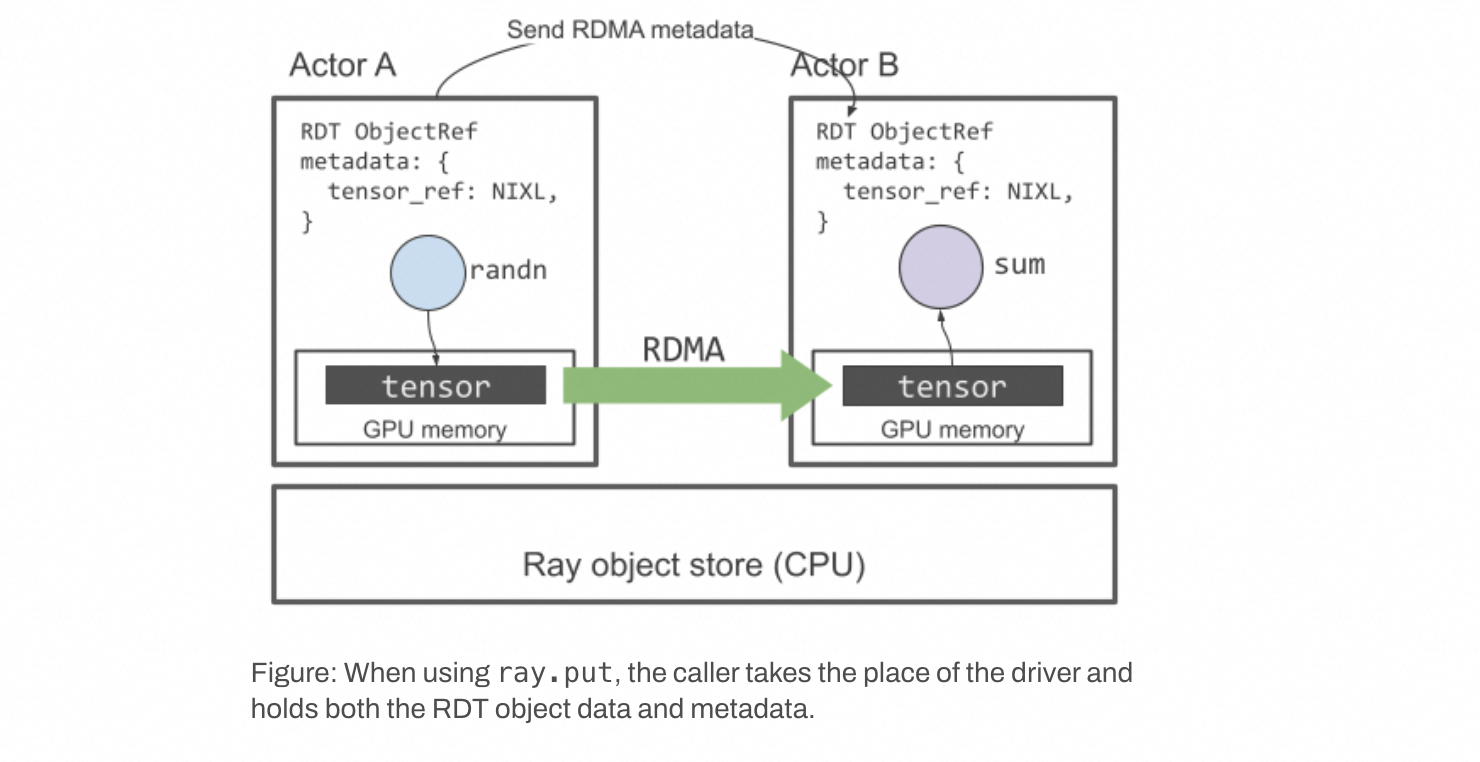
图示:当使用 ray.put 时,调用者扮演了驱动程序的角色,同时持有 RDT 对象的数据和元数据。
性能
RDT 可以显著加快 Ray actor 之间的对象传输速度。以下是一个基准测试,展示了不同 GPU 张量传输方式随对象大小变化的性能。该测试在一个 actor 上创建一个 CUDA 张量,并将其发送到同一节点上另一块 GPU 上的第二个 actor。第二个 actor 将该张量的总和返回给驱动程序。我们使用 2 块 NVIDIA H100 GPU,测量端到端完成两个 actor 任务提交和执行的时间。
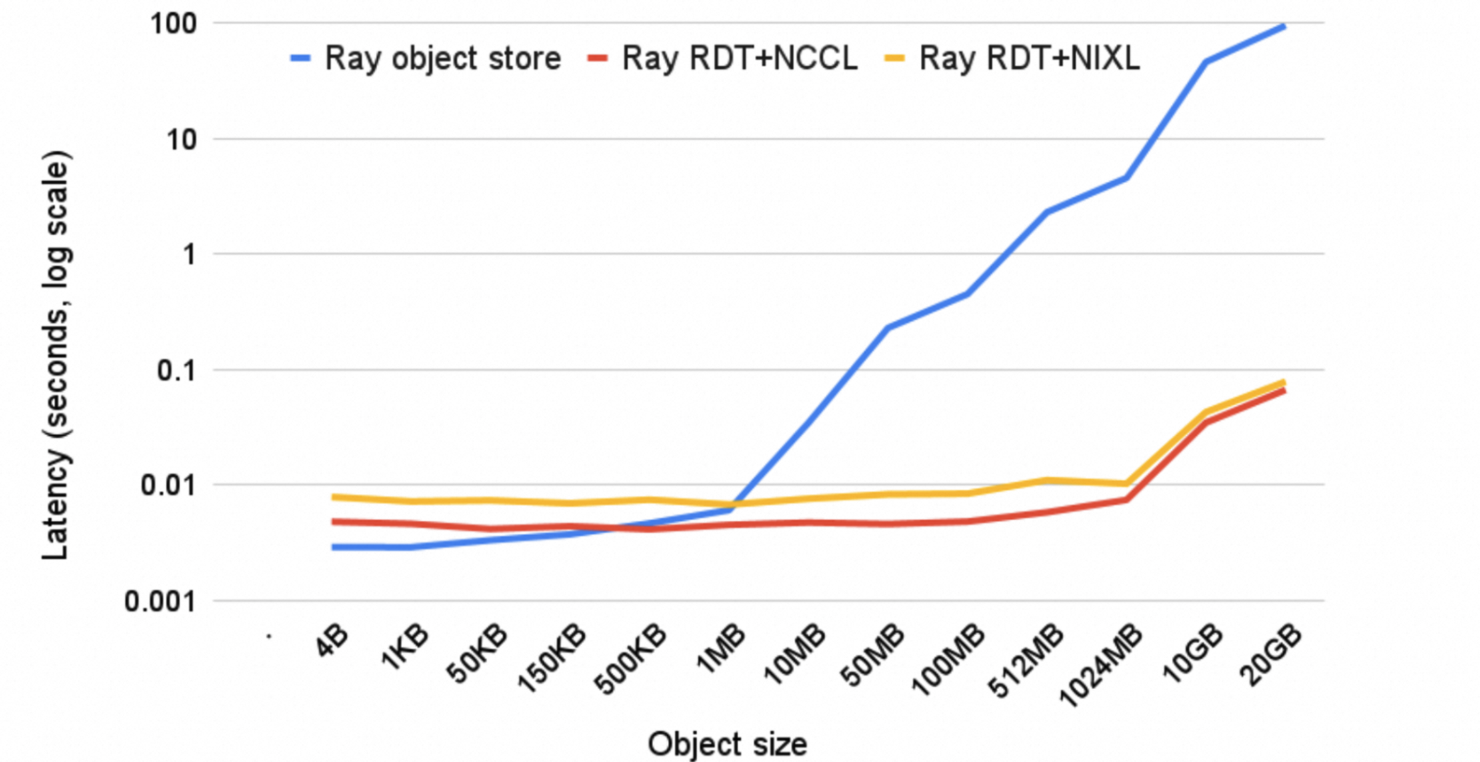
正如预期的那样,由于 CPU 和 GPU 之间的拷贝开销,Ray 对象存储的性能随着对象大小的增加而扩展性不佳,而 RDT 通过使用快速的 GPU 间链接可以显著加速传输。
强化学习(RL)示例
接下来,我们将展示如何在一个最小化的 RL 示例中使用 RDT 来加速权重同步。在后续的博客文章中,我们将扩展此示例,将 RDT 应用于 rollout 数据传输,并增加对多 GPU 大语言模型的支持。
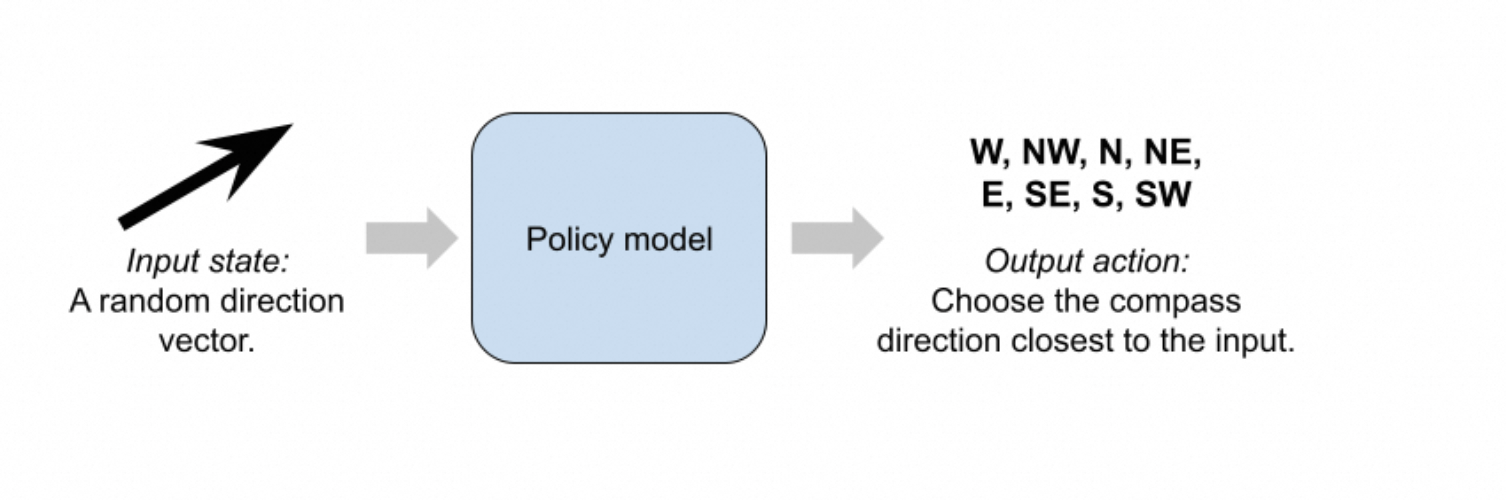
我们的最小化 RL 示例反映了使用 RL 训练大语言模型时的数据流。具体来说,我们使用组相对策略优化 (Group Relative Policy Optimization, GRPO) 算法来解决一个玩具问题。我们的"环境"会随机生成一个二维方向向量,而模型必须预测八个罗盘方向中哪一个最接近这个向量:
GRPO 是一种在训练大语言模型中变得流行的 RL 算法。它的工作原理是为每个输入生成一组输出,并计算每个输出相对于其组内平均奖励的优势(advantage)。该算法防止当前策略模型做出与同一模型先前版本差异过大的预测,以稳定训练并防止对先前经验的"灾难性遗忘"。
下图展示了此示例中涉及的不同 Ray actor 以及每个 actor 所需的资源。
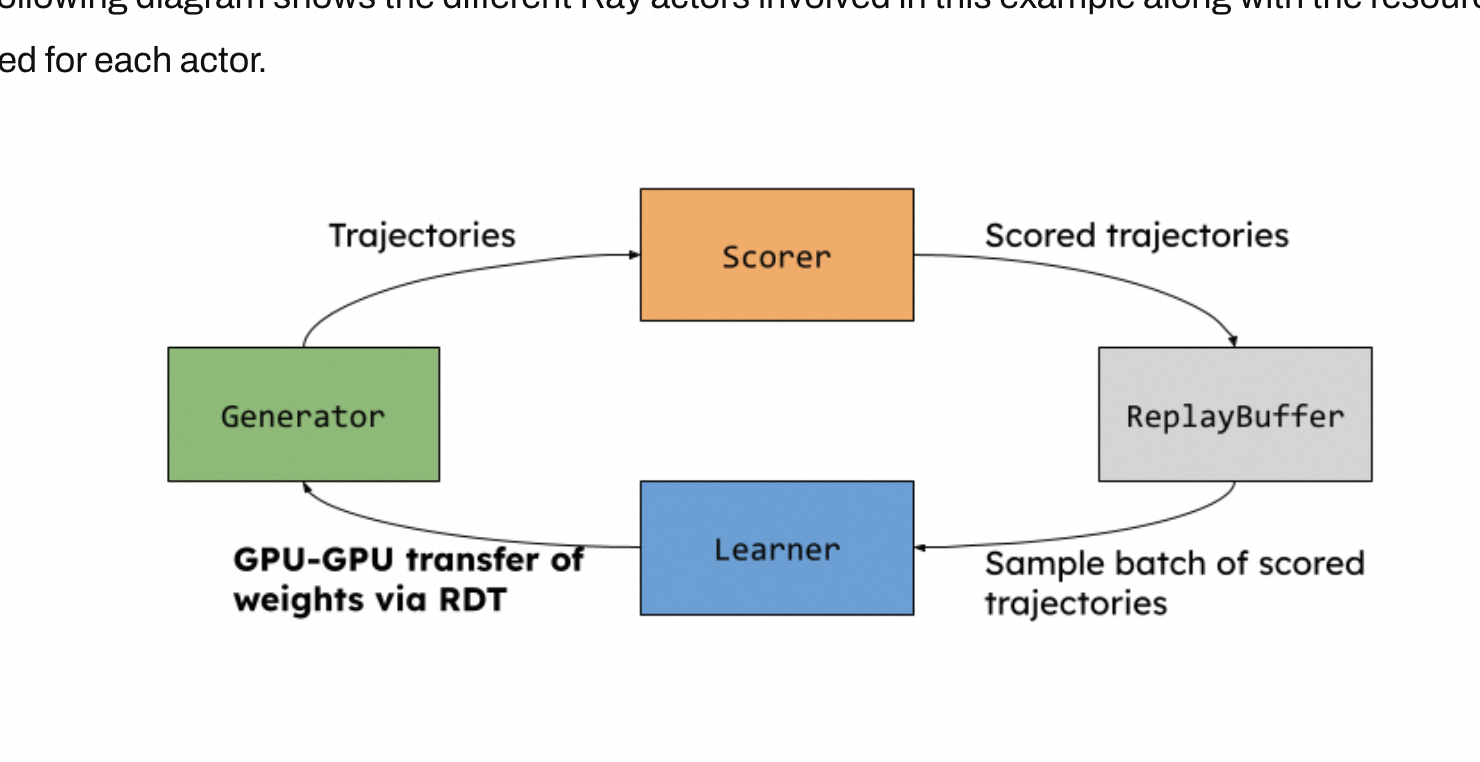
每个箭头都表示将张量从一个 actor 移动到另一个。RDT 可以应用于这些数据传输中的任何一个,但在本例中,我们仅将其应用于 Learner → Generator 的数据传输,因为这需要一次 GPU 到 GPU 的拷贝。
以下是该应用的详细步骤:
- CPU "环境"生成随机的二维向量。
- GPU Generator 策略模型预测输入向量最接近八个罗盘方向中的哪一个:W, NW, N, NE, E, SE, S, 或 SW。
- CPU Scorer 使用余弦相似度解析地计算奖励。
- CPU 带有评分的切片(slice)被添加到 ReplayBuffer 中。ReplayBuffer 允许模型从过去的经验中学习。
- GPU Learner 模型从经验回放缓冲区中采样,并使用 GRPO 算法更新其权重。
- GPU Learner 将更新后的权重发送给 Generator,完成一个训练步骤。
为简洁起见,本文中我们仅展示训练脚本的关键部分。完整的训练代码可在此处获取。
在每个训练步骤中,环境会随机采样一批二维单位向量。这些状态向量是 Generator actor 的输入。策略模型将这些二维状态作为输入,并输出在八个可能动作上的 logits。
python
# 为每个状态采样的动作数量。
GROUP_SIZE = 10
@ray.remote(num_gpus=1)
class Generator:
def __init__(self, scorer): ...
def generate(self, states: torch.Tensor):
# states 是随机采样的单位向量。
logits = self.model(states.cuda())
dist = Categorical(logits=logits)
actions = dist.sample((GROUP_SIZE,))
logps = dist.log_prob(actions)
# 将张量移至 CPU 并发送给 Scorer。
slice_batch = {
"policy_version": self.policy_version,
"state": states.detach().cpu(),
"actions": actions.transpose(0, 1).contiguous().detach().cpu(),
"old_logps": logps.transpose(0, 1).contiguous().detach().cpu(),
}
self.scorer.enqueue_trajectory_batch.remote(slice_batch)
def update_weights(self, cuda_weights):
# 从 Learner 接收 CUDA 张量并更新模型。
self.model.load_state_dict(cuda_weights).eval()
self.policy_version += 1Scorer actor 从 Generator 接收 CPU 张量的字典,并使用动作向量与原始状态向量的点积来计算奖励。然后,Scorer 将带有评分的轨迹发送给 ReplayBuffer actor(使用默认的 Ray 对象存储)。
python
@ray.remote(num_gpus=1)
class Scorer:
def __init__(self, replay_buffer):
self.replay_buffer = replay_buffer
def enqueue_trajectory_batch(self, batched_slices: dict):
rewards = ... # 对轨迹进行评分并发送到 ReplayBuffer。
self.replay_buffer.put.remote(dict(policy_version=policy_version,
state=batched_slices["state"],
actions=batched_slices["actions"],
old_logps=batched_slices["old_logps"],
rewards=rewards
))ReplayBuffer actor 将带有评分的切片存储在其本地堆内存中,并暴露另一个方法以允许 Learner 从该缓冲区中采样。
python
@ray.remote
class ReplayBuffer:
def __init__(self):
self.storage = []
def put(self, slice: dict[str, torch.Tensor]):
self.storage.append(slice)
def sample_from(self, n: int) -> list[dict[str, torch.Tensor]]: ...Learner actor 从 ReplayBuffer 以及当前策略中采样,以便进行 GRPO 风格的权重更新:
python
@ray.remote(num_gpus=1)
class Learner:
def __init__(self, replay_buffer): ...
def step(self):
# 从 ReplayBuffer 采样
slices: list[TrajectorySlice] = ray.get(
self.replay_buffer.sample_from.remote(BATCH_SIZE)
)
# 执行 GRPO 更新。
...最后,我们在 Learner 上暴露一个获取当前模型权重的方法,我们将用它来与 Generator 同步权重。
python
@ray.remote(num_gpus=1)
class Learner:
@ray.method(tensor_transport="nixl")
def get_weights(self):
return self.model.state_dict()请注意,在这里,我们添加了 @ray.method(tensor_transport="nixl") 装饰器,以使用 RDT 进行权重传输。在底层,这会通过 UCX 库使用单边 RDMA 读取来绕过 CPU 内存。如果没有这个装饰器,Ray 将通过 Ray 对象存储来传输权重。
现在,将所有部分组合在一起,我们实现一个 Ray 驱动程序来执行一个"一步异策略"(one step off policy)的异步训练循环,它会在执行下一个 Learner 步骤的同时,并行地使用当前权重启动生成任务。在每次 Learner 更新之后,我们将权重同步回 Generator,以确保生成任务的策略版本最多只落后一个版本。
python
# 为每个 actor 实例化一个实例。
replay_buf = ReplayBuffer.remote()
learner = Learner.remote(replay_buf)
scorer = Scorer.remote(replay_buf)
generator = Generator.remote(scorer)
# 初始化 generator 和 replay buffer。
generator.update_weights.remote(learner.get_weights.remote())
generator.generate.remote(sample_unit_vector(BATCH_SIZE))
# 训练循环。
for i in range(total_steps):
states = sample_unit_vector(batch_size=BATCH_SIZE)
generator.generate.remote(states)
# 与生成任务并行启动下一个 learner 步骤。
learner.step.remote()
# 用新权重更新 generator。
ray.get(generator.update_weights.remote(learner.get_weights.remote()))在这里,我们依赖 Ray 的 actor 任务顺序性来确保 generator 能在更新权重和生成数据之间正确交替。为简单起见,我们使用 ray.get 阻塞 Generator.update_weights 任务,以确保在 Learner 开始下一步之前,Generator 已完全接收到来自 Learner 的权重;否则,Generator 可能会收到部分更新的权重。请参阅此处的完整训练代码,了解另一种避免在驱动程序上进行阻塞调用的方法。
在一台 NVIDIA B200 节点上,当使用默认的 Ray 对象存储完成权重传输时,每个步骤大约需要 188ms 。添加 @ray.method(tensor_transport="nixl") 装饰器后,每个步骤的运行时间减少到 81ms ,仅用一行代码改动,就实现了 2.3 倍的性能提升!
下一步计划
RDT 目前处于 alpha 阶段,我们正在积极寻求反馈!正在进行的功能包括性能增强、支持如 CUDA IPC 等替代的张量传输方式,以及支持引入您自己的传输方式。我们的目标是实现与 Ray Core API 几乎对等的功能,但目前,有一些关键的限制需要注意:
- 仅支持 Ray actor。 不支持非 actor 的 Ray 任务。
- 尚不兼容 asyncio。 请关注这个追踪 issue以获取更新。
- RDT 对象是可变的(mutable)。 这意味着 Ray 仅持有对张量的引用,在请求传输之前不会复制其值。如果用户代码在传输发生前写入该张量,接收方可能会看到部分更新的数据。这与 Ray 对象存储不同,后者总是通过值拷贝来确保不可变性。
查看文档 以获取更多关于用法的信息,提交 issue 来报告 bug 或提供反馈,并在 Ray Summit 与我们见面!在本博客系列的第二部分,我们将扩展我们的示例,以演示 RDT 在 rollout 数据传输和多 GPU 大语言模型 RL 训练中的应用。
你提出了一个非常好的问题,这正是理解 RDT 机制的关键所在!
答案是:即使 receiver.sum 方法没有被 @ray.method 装饰,数据传输依然会通过 RDT(即 nixl)在 GPU 之间直接进行!
我们来详细拆解一下这个逻辑。
@ray.method 装饰器的作用域
@ray.method(tensor_transport="...") 这个装饰器的真正作用是标记一个"输出",而不是标记一个"输入"。
它告诉 Ray:
"当这个被装饰的方法 (
random_tensor) 完成后,如果它返回了一个torch.Tensor,请不要按常规流程处理它。请给它贴上一个'RDT 特殊对象'的标签,并让它留在原地(原地指创建它的 actor 的 GPU 上)。"
所以,这个装饰器只影响数据的生产者(Producer) ,即那个返回张量的方法。它改变的是 ray.ObjectRef 的"血统",让它从一个普通的引用变成了一个特殊的、携带了 RDT 信息的引用。
receiver.sum.remote(tensor) 的执行流程
现在我们来看 receiver.sum.remote(tensor) 这一行。
-
参数
tensor是什么?- 这个
tensor变量是一个ObjectRef,我们称之为**"RDT 引用"**。它是在调用sender.random_tensor.remote()时被创建的。 - 这个"RDT 引用"内部包含了关键信息,比如:"我指向的数据是一个张量,它目前存放在
sender这个 actor 的 GPU 上,并且应该通过nixl来传输。"
- 这个
-
Ray 如何处理这次调用?
- 当 Ray 准备调度
receiver.sum任务时,它会检查这个任务所需要的参数。 - Ray 发现,
sum方法需要一个由tensor这个ObjectRef所代表的实际数据。 - Ray 接着检查
tensor这个ObjectRef的"血统",发现它是一个**"RDT 引用"**! - 这时,Ray 就明白了:"哦,我不能去中央对象存储(CPU)里找这个数据。我需要启动 RDT 流程。"
- Ray 随即协调
sender和receiver,并指示nixl库在它们之间建立一条 GPU 直连通道。 - 数据通过
nixl从sender的 GPU 直接传输到receiver的 GPU 上。 - 数据传输完成后,
receiver上的sum方法才真正开始执行,此时它操作的tensor参数已经是本地 GPU 上的数据了。
- 当 Ray 准备调度
-
sum方法本身在哪里执行?receiver是一个MyActor实例,它是一个 Ray Actor。Actor 的方法默认在它自己所在的进程和设备上执行。- 由于
receiver = MyActor.remote()在创建时没有指定num_gpus=0,Ray 通常会为它分配一个 GPU(如果可用)。 - 因此,
sum方法本身是在receiver所在的 GPU 上执行的。它接收一个 GPU 张量,计算求和,然后返回结果。
总结
- 装饰器决定"出身" :
@ray.method用在生产者 这边,决定了返回的ObjectRef是不是一个"RDT 引用"。 - 引用决定"运输方式" :当一个"RDT 引用"被用作消费者方法的参数时,Ray 就会自动触发 RDT 传输机制,无论消费方法本身是否被装饰。
- 方法执行位置不变 :
sum方法仍然在它所属的receiveractor 上执行,通常是在 GPU 上。
所以,你完全不需要(也不应该)在 receiver.sum 上添加 @ray.method 装饰器(除非 sum 方法自己也想返回一个需要通过 RDT 传输的大张量)。Ray 的设计非常聪明,它让数据的消费者对底层的传输方式"无感",只需要处理好接收到的数据即可。
太棒了!这个问题问到了最核心、最容易混淆的地方。这确实是理解 Ray Direct Transport (RDT) 工作模式的关键。
让我们用一个非常简单的比喻来解释这句话:贴快递单。
- 数据 (
torch.Tensor) :是你要寄送的包裹。 - 生产者 (返回张量的任务) :是寄件人。
- 消费者 (使用张量的任务) :是收件人。
@ray.method(tensor_transport=...)装饰器:是一张特殊的**"VIP 加急"快递单**。
现在我们来解读原文那段话:
"@ray.method(tensor_transport) 装饰器只需要添加到返回张量的 actor 任务上。"
翻译成大白话就是:
"只有寄件人(生产者)需要在包裹上贴上那张'VIP 加急'快递单。"
为什么?
因为寄送方式是在寄件时决定的 。当你作为寄件人,把包裹交给快递公司时,你告诉他们:"请用最快的专线(比如 nixl)送这个包裹"。快递公司就会在系统里记录下这个信息。
在 Ray 的世界里:
sender.random_tensor这个方法是寄件人。- 它用
@ray.method(tensor_transport="nixl")这个装饰器,就等于在它即将寄出的包裹(那个torch.Tensor)上贴了一张"VIP 加急"的快递单。 - Ray 系统看到这张快递单,就知道:"哦,这个包裹不能走普通慢速物流(CPU 对象存储),必须走
nixl这条专线。"
"它不应该被添加到消费(使用)该张量的 actor 任务上"
翻译成大白话就是:
"收件人(消费者)不需要关心包裹是怎么寄过来的,他只管收货就行了。"
为什么?
收件人 receiver.sum 的工作是接收包裹并处理它。当快递员(Ray 的调度器)把包裹送到他手上时,他不需要知道这个包裹是坐飞机来的还是坐高铁来的。包裹的运输方式在寄件时就已经决定了。
在 Ray 的世界里:
receiver.sum是收件人。- 当 Ray 把那个通过
nixl专线送达的张量数据交给他时,sum方法只管拿来用就好了。 - 如果在
sum方法上加一个@ray.method装饰器,就好像收件人对着空气说:"我希望我收到的下一个包裹是 VIP 加急件!" 这没有意义,因为包裹已经在路上了,它的运输方式早已被寄件人决定。
"(除非那些任务自己也返回张量)"
翻译成大白话就是:
"除非这个收件人处理完包裹后,自己又要变成寄件人,寄出一个新的大包裹。"
这是什么意思?
假设 receiver.sum 方法不仅计算了总和,还要创建一个新的、巨大的 张量并返回它。如果你希望这个新返回的 张量也通过 RDT 的"VIP 专线"来传输,那么你就需要在 sum 方法上添加 @ray.method 装饰器。
例子:
python
class MyActor:
# 这是生产者 A,它返回一个 RDT 对象
@ray.method(tensor_transport="nixl")
def create_tensor(self):
return torch.ones(1000, 1000)
# 这是消费者 B,同时也是生产者 C
# 它消费一个 RDT 对象 (input_tensor)
# 它自己也生产并返回一个新的 RDT 对象
@ray.method(tensor_transport="nixl")
def process_and_create_new_tensor(self, input_tensor):
# ... 做一些处理 ...
new_tensor = input_tensor * 5 # 创建了一个新的大张量
return new_tensor # 这个返回的 new_tensor 将会是一个 RDT 对象在这个例子里,process_and_create_new_tensor 方法需要装饰器,不是因为它接收了 input_tensor,而是因为它返回了 new_tensor,并且我们希望 new_tensor 也能享受 VIP 待遇。
总结
- 装饰器是给"输出"用的,不是给"输入"用的。
- 谁生产数据(返回 Tensor),谁就负责贴"快递单"(加装饰器)。
- 谁消费数据(接收 Tensor 作为参数),谁就只管用,不用关心运输方式。
所以,在最初的例子里,sender.random_tensor 是生产者,所以要加装饰器。receiver.sum 是纯粹的消费者(它返回的是一个很小的标量,不需要 VIP 运输),所以不需要加装饰器。