本文入选顶会ACL 2025
query意图预测包含类目、品牌等分类任务,对电子商务应用至关重要。电商query通常简短且缺乏上下文信息,标签间的信息无法利用,导致建模所需的先验信息不足。大多数现有的工业级查询分类方法依赖于用户后续的点击行为来构建训练样本,从而陷入了马太福音式的恶性循环。此外,查询分类的各个子任务缺乏统一的框架,导致算法优化效率低下。 我们提出了一种半监督可扩展统一框架(SSUF),该框架包含多个增强模块,用于统一查询分类任务。知识增强模块利用世界知识来增强查询表示,解决查询信息不足的问题。标签增强模块利用标签语义和半监督信号来降低对后验标签的依赖。结构增强模块基于复杂的标签关系来增强标签表示。每个模块都具有高度可插拔性,可以根据每个子任务的需要添加或移除输入特征。经过大量的离线和在线 A/B 实验,结果表明 SSUF 的性能明显优于业界最先进的模型。
论文链接: aclanthology.org/2025.acl-in...
一、业务背景
Query意图识别是搜索的基础模块,主要目标是准确全面的理解用户的搜索意图信息(类目、品牌、产品词等),为下游的召回/相关性/排序提供决策信息和特征。
query意图识别算法训练以用户点击sku的类目/品牌为标签。这种模型训练数据的构造方式,主要存在以下类型的query意图召回率不足问题:
•泛词的多意图:侧重知识类,词与具体商品之间需要知识关联,例如:水果,生日礼物,灯;
•歧义词的多意图:多意图query下,基于样本生成逻辑,会偏向主意图,弱化甚至丢失次意图,导致召回问题,例如:小米(粮食or手机?),苹果(水果or手机?);
•长尾类目冷启:由于用户点击数据的马太效应,使得大量的长尾类目没有曝光机会,类目下商品无法获得点击,加深了模型无法得到长尾类目训练数据的问题,例如: 服务类,健康类,工业品类;
•长尾query的多意图:由于用户背景和表达习惯不同,对同类商品需求,会有多种表达方式,产生很多长尾query。模型给出的类目不准,因此产生的点击数据也不够准确。
举例说明:
例如:用户搜"耳机",相关类目包含 862-手机耳机,842-蓝牙耳机... 等9个三级类目。由于马太效应,系统只能展现出1~2个高点击类目的商品,中长尾类目下商品无展现。
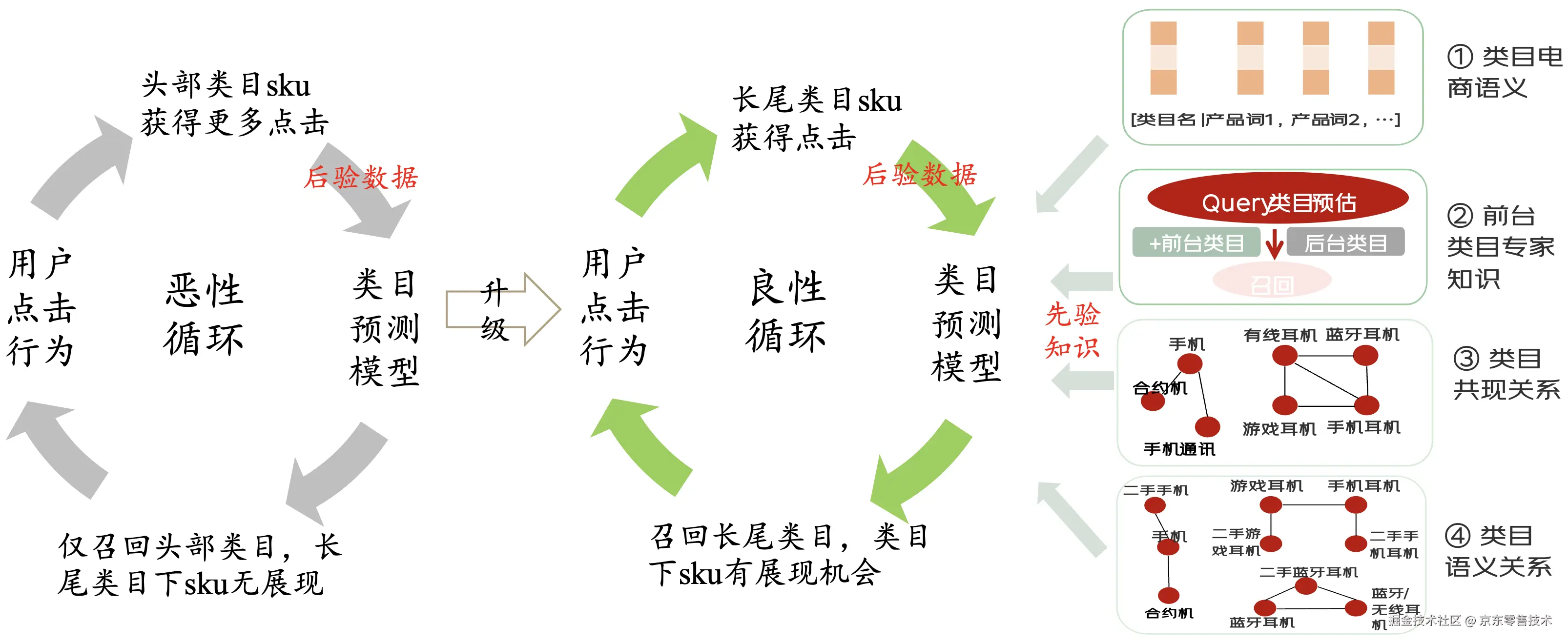
相比于热门类目,长尾类目下的商品很难获得流量和用户点击,存在严重的样本不均衡问题,导致识别模型无法识别用户对长尾类目下商品的意图。这反过来加重了长尾类目无法获得流量的问题,形成恶性循环。
二、动机&挑战
工业界(HCL4QC(2023 阿里)、HQC(2024 Amazon))和学术界(XML-CNN、LEAM、LSAN)query意图识别算法存在的问题:
问题一:先验信息不足
•电商query短,缺上下文;
•无法完整地建模类目间关系;
•对语义特征不明显的query,模型泛化能力弱;
•label间信息无法利用,导致相关label召回不足;
问题二:马太恶性循环
•强势商品导致马太效应;
•对样本绝对稀疏的query,现有的分类范式无能为力;
•训练依赖后验导致马太恶性循环
问题三:子任务无法统一
•query意图理解各子任务缺少统一框架,算法迭代效率低。
•子任务各自独立,无法互相增强
三、算法方案
基于半监督可扩展的意图识别统一框架:
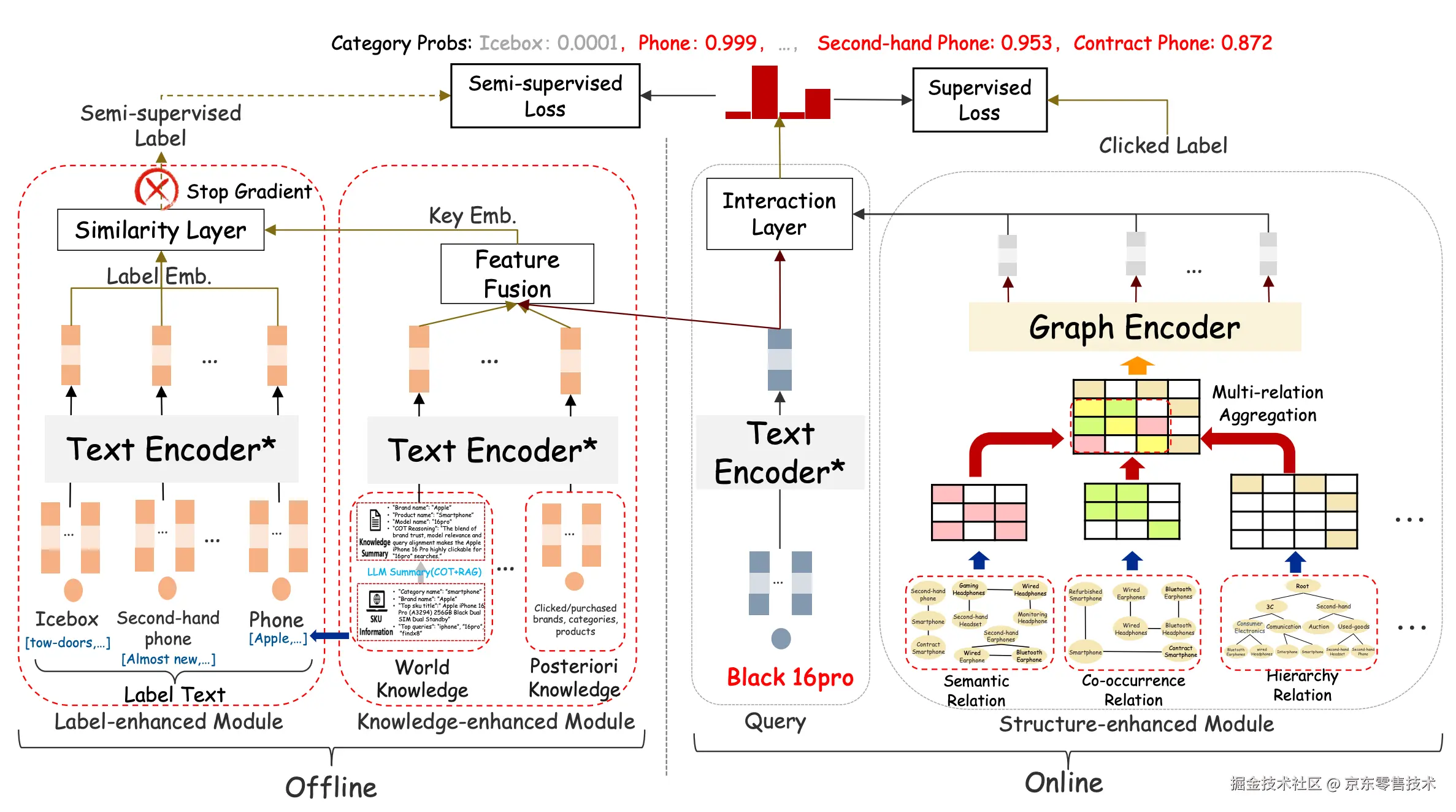
算法方案:
通过引入先验知识和模型的优化,增强模型对电商知识的感知,弱化模型对后验反馈的依赖:
(1)知识增强
增强query侧的语义表征
•LLM产出事实知识
•用户行为知识
(2)结构增强
增强label侧的关系表征
•基于标签间语义关系、共现关系、结构关系等,构建标签关系图。
(3)标签增强
打破后验马太的恶性循环
•引入label文本等,增强label侧的语义表征。
•用知识增强的先验半监督标签,打破对后验依赖。
•用graph encoder学习融合后的关系矩阵,得到label embedding。
(4)统一框架
设计可扩展意图识别统一框架
•基于各子任务的相似性,设计多标签分类的统一框架。
•基于子任务的差异性,设计可插拔的增强子模块。
•可支持意图识别多任务联合训练,各任务之间信息互相补充,相互增强。
四、实验效果
4.1 离线效果
对比方法:
•(学术界)多标签分类算法:XML-CNN、LEAM、LSAN
•(工业界)query意图分类算法:DPHA、MMAN、HCL4QC(2023 阿里)、SMGCN(2024 JD)、HQC(2024 Amazon)
•消融分析:
◦w/o KE:移除知识增强模块。
◦w/o KE & LE:移除知识增强和标签增强模块。
◦w/o SE:移除结构增强模块。
◦w/o SE-S:移除结构增强模块中的语义相似关系增强结构。
◦w/o SE-C:移除结构增强模块中的标签共现关系增强结构。
◦w/o SE-H:移除结构增强模块中的标签层次关系增强结构。
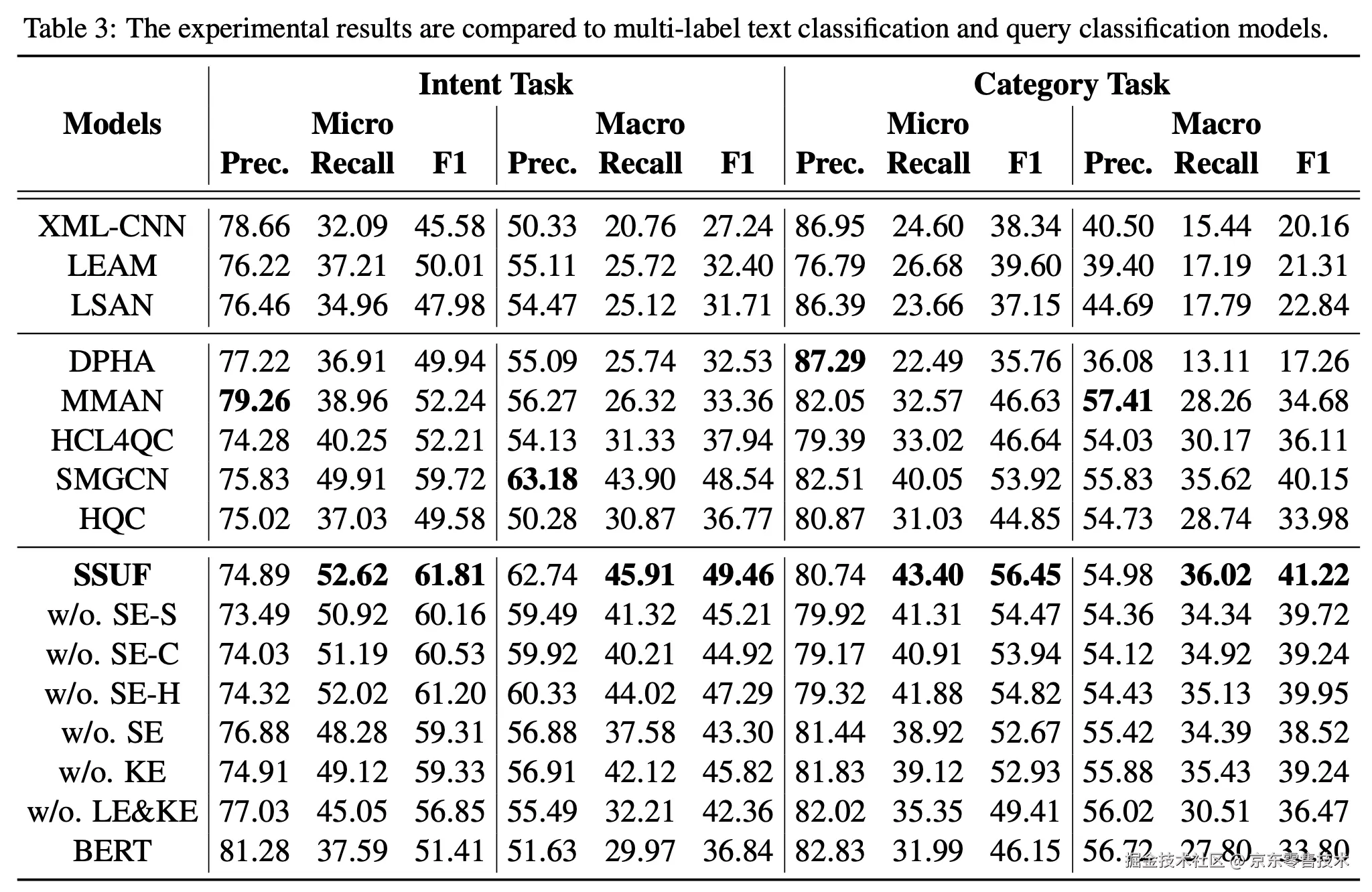
•与多标签基线模型和查询分类方法相比,SSUF 在这两个任务上F1值都表现出了显著的效果优势。
•当移除 SE 模块时,与(完整的)SSUF 相比,两个数据集上的性能均出现轻微下降。移除共现图时也观察到了类似的现象,这表明相似度图或共现图包含了后验数据中所忽略的额外信息。
•当我们同时剔除相似度图和共现图时,F1下降超过了 5%。在移除三个模块后,F1 值均下降了 8%。进一步证明,SSUF 中的所有这些组件提供了彼此互补的信息,且对于query分类任务而言是不可或缺的。
4.2 在线部署与A/B测试
线上部署:
为了降低部署延迟,SSUF 的文本编码器采用了与线上模型一致的四层 BERT 模型。此外,我们只需缓存 GCN 生成的类别向量,而无需直接部署 GCN。这样,我们就可以在不增加任何额外计算量和延迟的情况下部署 SSUF。
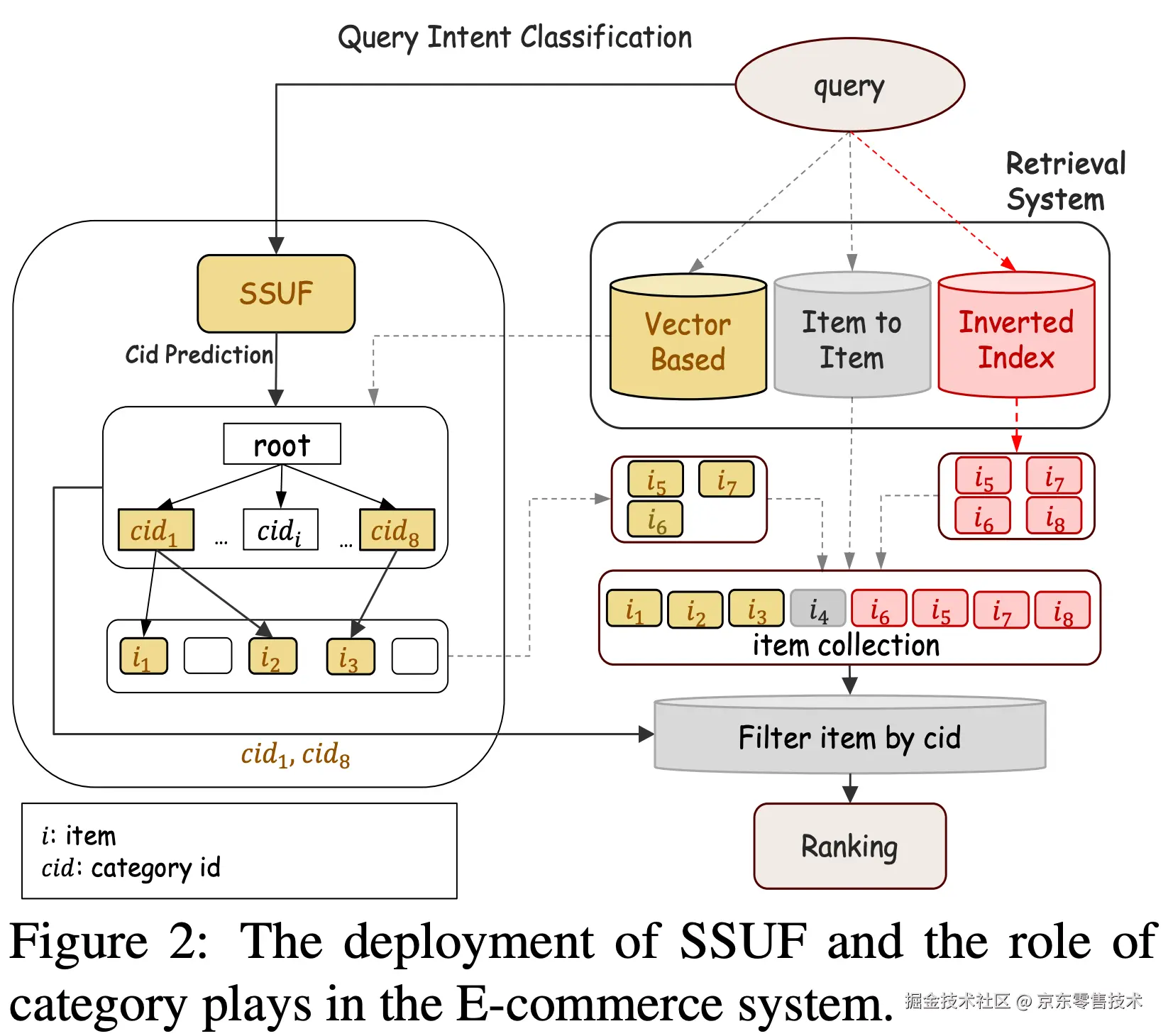
上图展示了 SSUF 在搜索系统中的作用。当用户输入query时,SSUF 首先预测用户的意图并识别相关类别,并将此信息传递给下游模块。然后,基于向量的检索模块查找与这些类别关联的条目。检索到的商品与来自其他检索源的商品相结合,并由一个子模块进行过滤,以移除与用户意图不匹配的商品。过滤后的商品随后被发送到排序模块。
A/B测试:
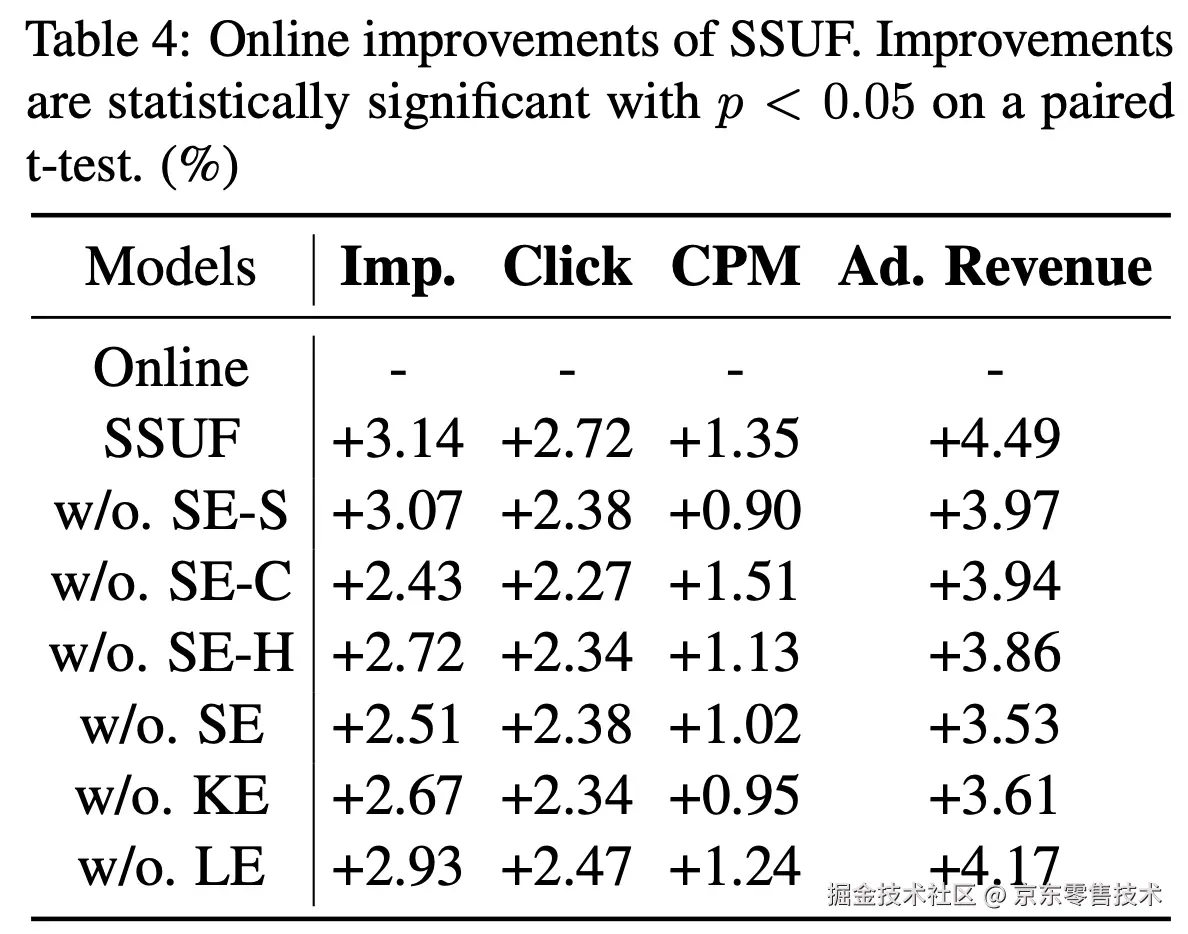
•与在线模型相比,SSUF 在业务指标上取得了显著提升。广告曝光量(Impressions)和点击量(Clicks)的增加表明,广告系统召回了更多相关的商品,且这些商品与用户的偏好及搜索意图有效契合。
•移除 SSUF 的任意子模块均会导致性能下降,这进一步验证了各模块的有效性及其在 SSUF 内部的协同整合作用。
•离线和在线实验结果均一致证明了 SSUF 的高效性、通用性与可扩展性。