文章目录
-
- [一、时代背景:为什么时序数据库是大数据与 IoT 的必选项](#一、时代背景:为什么时序数据库是大数据与 IoT 的必选项)
- 二、选型要从场景出发:我们关心什么?
-
- [1. 写入吞吐能力](#1. 写入吞吐能力)
- [2. 查询与分析效率](#2. 查询与分析效率)
- [3. 数据存储压缩率](#3. 数据存储压缩率)
- [4. Schema 灵活性与建模便利度](#4. Schema 灵活性与建模便利度)
- [5. 分布式与高可用能力](#5. 分布式与高可用能力)
- [6. 与大数据生态的集成度](#6. 与大数据生态的集成度)
- [7. 边缘计算支持](#7. 边缘计算支持)
- [三、Apache IoTDB:为 IoT 与工业大数据而生](#三、Apache IoTDB:为 IoT 与工业大数据而生)
-
- [3.1 项目起源与定位](#3.1 项目起源与定位)
- [3.2 架构全景](#3.2 架构全景)
- [3.3 树形设备模型](#3.3 树形设备模型)
- [3.4 高效的存储与压缩](#3.4 高效的存储与压缩)
- 四、与国外主流时序数据库的对比分析
- 五、从部署到应用:实战细节与代码示例
-
- [5.1 云端集群部署思路](#5.1 云端集群部署思路)
- [5.2 Python 写入与批量导入](#5.2 Python 写入与批量导入)
- [5.3 与 Spark 实时分析集成](#5.3 与 Spark 实时分析集成)
- 六、实战精要与多维经验
-
- [1. 架构演进路线:从小规模验证到全域数据平台](#1. 架构演进路线:从小规模验证到全域数据平台)
- [2. 性能调优实战:从写入到查询的全链路优化](#2. 性能调优实战:从写入到查询的全链路优化)
- [3. 边缘-云协同落地细节](#3. 边缘-云协同落地细节)
- [4. 大数据集成与冷热分层实践](#4. 大数据集成与冷热分层实践)
- 七、选型建议与决策路径
- 八、结语

一、时代背景:为什么时序数据库是大数据与 IoT 的必选项
过去十年,物联网设备的普及让世界进入了 "万物互联、数据爆炸" 的阶段。工厂里的每台机床、电网中的每个电表、智慧城市中的每盏路灯、车联网里的每辆车的 GPS 与传感器,都在持续不断地产生带有时间戳的数据。
这类数据的特点是:

- 写入强度极高:成千上万的采集点以固定频率上报,高峰时每秒可累积数百万甚至上千万个数据点。
- 查询模式集中:绝大多数查询围绕时间范围筛选、聚合统计、降采样分析。
- 冷热分布明显:最近几小时或几天的数据访问频繁,历史数据多用于离线分析或模型训练。
- 结构灵活多变:新设备、新测点随时上线,预先设计固定表结构几乎不可能。
传统关系型数据库(如 MySQL、PostgreSQL)在批量高并发写入和按时间高效检索方面存在天然瓶颈;通用 NoSQL(如 MongoDB、Cassandra)虽可扩展,但缺少针对时间维度的存储与索引优化。于是,专为时序数据设计的数据库逐渐成为大数据平台的核心组件。
据多家研究机构预测,到 2028 年,全球 IoT 设备数量将超过 400 亿台,时序数据总量将迈入 ZB 级别。这意味着,企业必须选择一款在性能、压缩、扩展性、生态集成等方面都能应对海量数据洪流的时序数据库,才能在竞争中保持数据驱动的敏捷性。
二、选型要从场景出发:我们关心什么?
在做技术选型时,如果只看单一性能指标容易误判,必须结合业务场景与长期运维成本综合考量。下面列出在大数据与 IoT 场景中,我们尤为关注的几个方面,并解释它们的重要性。
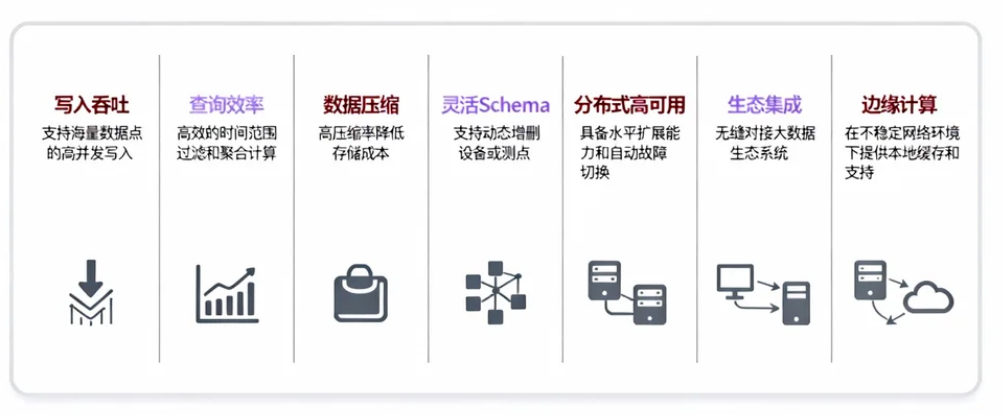
1. 写入吞吐能力
在 IoT 场景中,数据采集器往往以固定频率上报,高峰期可能瞬间涌入海量数据点。如果数据库写入能力不足,就会导致背压、丢数据或延迟飙升。对大数据平台来说,写入性能直接影响实时数据管道的可靠性。
2. 查询与分析效率
时序数据的查询大多围绕时间范围过滤、聚合计算(如均值、最大值、方差)、降采样等。如果查询引擎不能高效下推计算到存储层,就可能把大量原始数据拉到内存中运算,导致性能急剧下降。
3. 数据存储压缩率
时序数据往往存在较强的规律性与冗余,例如温度传感器的数值在短时间内波动有限。高压缩率不仅能节省磁盘与网络带宽成本,还能提升缓存命中率,间接改善查询性能。
4. Schema 灵活性与建模便利度
IoT 场景中设备型号繁多、测点各异,如果每次新增设备都要执行 DDL 修改表结构,会大幅增加运维负担。理想的时序数据库应支持动态增删设备或测点,让数据模型更贴近现实世界的层次结构。
5. 分布式与高可用能力
当数据量与设备数达到一定规模,单节点必然遇到瓶颈。此时需要数据库具备水平扩展能力,并能在节点故障时自动切换,保证服务连续性。
6. 与大数据生态的集成度
在大数据平台中,时序数据库通常不是孤立存在,而是要和 Kafka、Flink、Spark、Hadoop 等组件协同工作,实现流式处理、离线分析和数据湖存储。如果集成路径复杂或性能损耗大,就会拖累整个数据链路。
7. 边缘计算支持
很多 IoT 场景的网络环境并不稳定,比如偏远地区的风电场、海上钻井平台等。在这些场景下,能在边缘侧(网关、本地服务器)运行的轻量数据库可以保证断网缓存与低延迟响应,待网络恢复后再与云端同步。
三、Apache IoTDB:为 IoT 与工业大数据而生
3.1 项目起源与定位

Apache IoTDB 源自清华大学软件学院的科研积累,2016 年正式开源,2020 年成为 Apache 软件基金会顶级项目。它的定位非常明确------面向 IoT 与工业大数据场景的分布式时序数据库,兼顾云端集群与边缘轻量运行,提供统一的数据模型与访问接口。
3.2 架构全景
IoTDB 的架构分为多个层次,各司其职又紧密协作:
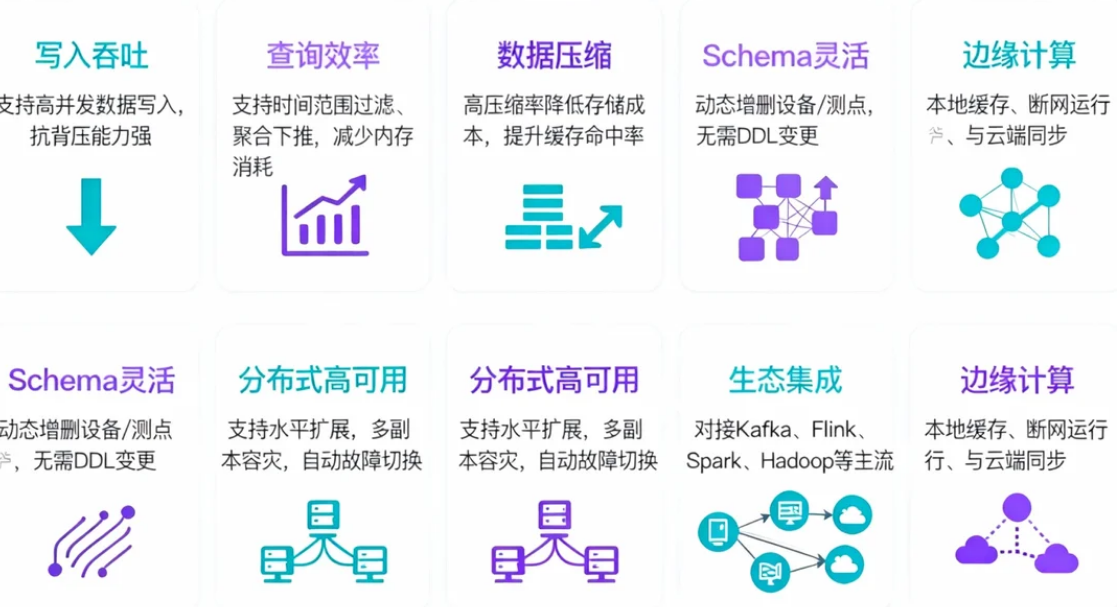
- ConfigNode:负责集群的元数据管理、DataNode 的负载协调与故障检测。
- DataNode:承担实际的数据存储与查询执行任务,支持多副本冗余。
- 查询引擎:支持类 SQL 的 IoTDB-SQL,可将计算下推到存储层以减少数据传输。
- 存储引擎 :基于自研的 TsFile 格式,采用列式布局与时间索引,配合多级压缩算法。
- 连接器体系:提供 JDBC、REST、MQTT、Hadoop FileSystem、Spark、Flink 等多种接入方式。
这样的分层设计,使得 IoTDB 既能满足云端海量数据的分布式管理,也能在边缘设备上保持轻量高效。
3.3 树形设备模型
与传统数据库需要为每个测点单独建表不同,IoTDB 用层次化树形结构映射现实世界的设备与传感器关系:
root.<group>.<device>.<sensor>例如:
root.ln.wf01.wt01.temperature表示某风电场的 1 号风机 1 号测点的温度数据。root.sgcc.wf03.wt02.voltage表示某电网的 3 号变电站 2 号测点的电压数据。
这种建模方式极大降低了 schema 维护成本,新设备上线只需在树中添加节点,无需修改数据库结构。
3.4 高效的存储与压缩
TsFile 是 IoTDB 的核心存储格式,采用列式组织,每个时间序列的数据块按时间顺序排列,并配有专门的时间索引,方便快速定位。压缩方面,TsFile 支持多种算法组合:
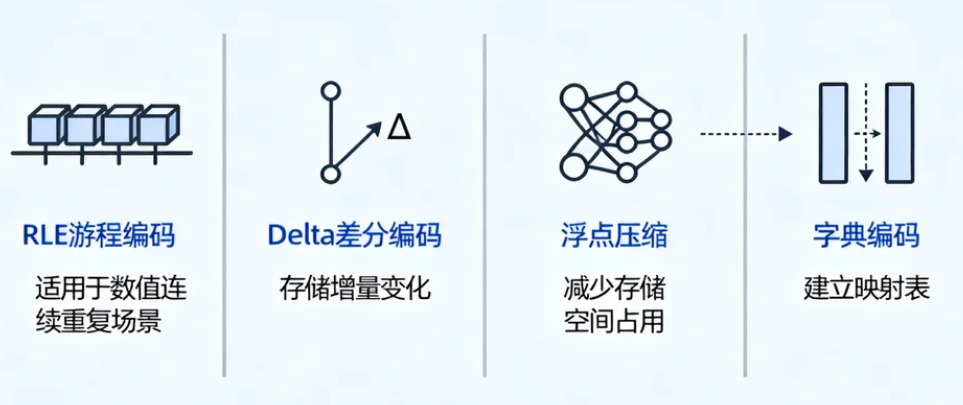
- RLE(游程编码):适合数值连续重复的场景。
- Delta 编码:利用相邻时间戳或数值的差值较小特性。
- 浮点精度压缩:在保证精度的前提下缩减存储空间。
- 字典编码:针对状态类离散值(如开关状态、模式编号)。
实际测试中,TsFile 的压缩比通常在 10:1 到 20:1 之间,这意味着原本需要数十 TB 的原始数据,在 IoTDB 中可能只需几 TB 即可存储,显著节约成本。
四、与国外主流时序数据库的对比分析
核心特性与适用场景
| 对比维度 | Apache IoTDB | TimescaleDB | InfluxDB(开源版) |
|---|---|---|---|
| 数据模型 | 树形设备与测点结构,天然贴合 IoT 场景,新增设备无需 DDL。 | 基于 PostgreSQL 的 Hypertable,需预先定义表结构,适合已有 PG 生态的团队。 | Measurement + Tags/Fields 模型,DevOps 监控领域流行,但设备层次表达不够直观。 |
| 写入性能 | 单节点优化后可达千万级 points/sec,分布式线性扩展。 | 受限于 PostgreSQL 单节点写入能力,需借助分区与扩展插件提升。 | 开源版单节点约百万级 points/sec,适合中小规模监控。 |
| 查询语言 | IoTDB-SQL,类 SQL 语法,支持时间过滤、聚合、降采样。 | 完整 PostgreSQL SQL,生态成熟,分析能力强。 | InfluxQL 或 Flux,语法独特,学习成本相对较高。 |
| 分布式架构 | 原生分布式,ConfigNode + DataNode,支持多副本与自动故障转移。 | 依赖外部扩展(如 Citus)实现分布式,原生 PG 为单节点。 | 开源版单节点,企业版提供集群功能。 |
| 大数据生态集成 | 原生支持 Hadoop、Spark、Flink、Kafka,数据可落盘至 HDFS/S3。 | 可通过 FDW 与外部系统集成,但链路相对复杂。 | 需额外插件或 ETL 工具实现与大数据平台对接。 |
| 边缘计算支持 | 提供官方 Edge 版本,可在网关或嵌入式设备运行,支持离线缓存与云同步。 | 无官方轻量版,需在边缘自行部署 PostgreSQL 实例。 | 无官方轻量版,边缘场景需自行裁剪。 |
| 压缩与存储 | TsFile 列式存储,多级压缩,压缩率高,冷热数据分层方便。 | 依赖 PostgreSQL 压缩插件,压缩率中等。 | TSM 存储引擎,压缩率中等,冷热分层需额外方案。 |
| 许可证与社区 | Apache 2.0,社区活跃,迭代快,国内生态完善。 | Apache 2.0(部分功能 Timescale License),国外社区成熟。 | MIT 许可证(开源版),企业版商业授权。 |
分析:
- 如果你的业务涉及 海量 IoT 设备、跨地域部署、边缘与云端协同,并且需要与 Spark、Flink 等大数据组件深度集成,IoTDB 的原生分布式与生态对接优势明显。
- TimescaleDB 更适合已在 PostgreSQL 上有深厚积累、数据规模中等的场景。
- InfluxDB 在 DevOps 监控与可视化方面有现成工具链,但在 IoT 层次建模与大数据集成上稍弱。
五、从部署到应用:实战细节与代码示例
5.1 云端集群部署思路
- 下载官方二进制包并解压。
- 配置 ConfigNode 的集群节点信息与副本策略。
- 配置 DataNode 的存储路径、端口与所属集群。
- 依次启动 ConfigNode 与多个 DataNode,观察集群状态。
- 通过
show cluster与监控指标确认节点健康。
5.2 Python 写入与批量导入
利用官方 Python 客户端,可轻松实现单点与批量写入:
python
from iotdb.Session import Session
session = Session("127.0.0.1", "6667", "root", "root")
session.open(False)
# 创建设备与测点
session.set_storage_group("root.factory")
session.create_time_series("root.factory.line1.machineA.temp", "FLOAT", "RLE")
# 批量写入
timestamps = [1700000000000 + i*1000 for i in range(100)]
temps = [23.5 + i*0.05 for i in range(100)]
session.insert_records(
["root.factory.line1.machineA"] * 100,
timestamps,
[["temp"]] * 100,
temps
)
session.close()5.3 与 Spark 实时分析集成
通过 Spark Connector,可直接将 IoTDB 作为数据源进行分析:
scala
val df = spark.read
.format("org.apache.iotdb.spark.db")
.option("iotdb.host", "192.168.1.10")
.option("iotdb.port", "6667")
.option("iotdb.user", "root")
.option("iotdb.password", "root")
.load("root.factory.line1.*")
df.createOrReplaceTempView("machine_data")
spark.sql("SELECT avg(temp) FROM machine_data WHERE time > NOW() - INTERVAL 1 HOUR").show()六、实战精要与多维经验
1. 架构演进路线:从小规模验证到全域数据平台
阶段 1:PoC 验证(单机/轻量集群)
- 目标:验证数据模型匹配度、写入/查询性能、压缩效果。
- 做法 :
- 用真实业务数据样本(至少覆盖 1~3 天的高频采集)导入单机 IoTDB。
- 测试不同压缩算法(RLE、Delta、Float Precision)对存储体积的影响。
- 用 IoTDB-SQL 跑典型查询(时间范围过滤、降采样、聚合),记录延迟。
- 经验 :PoC 阶段就要确定设备树形模型的命名规范,避免后期大规模重构。
阶段 2:边缘-云试点(小规模集群 + Edge)
- 目标:验证断网缓存、增量同步、边缘计算逻辑。
- 做法 :
- 在网关部署 IoTDB Edge,配置本地存储路径与同步策略(如按时间/按数据量触发上传)。
- 模拟网络中断,检查 Edge 缓存是否完整、恢复后是否自动续传。
- 经验 :Edge 与 Cloud 的时间同步必须可靠,否则会出现数据乱序或重复。
阶段 3:全域分布式生产集群
- 目标:支撑海量设备、跨区域写入与查询。
- 做法 :
- 按地域或业务域拆分 ConfigNode 与 DataNode 组,降低跨域延迟。
- 配置多副本策略(如 3 副本),结合负载均衡与故障转移测试。
- 接入 Hadoop/S3 做冷数据归档,Flink/Spark 做实时分析。
- 经验 :集群规划阶段要预留 20%~30% 的节点与存储冗余,应对业务突增。
2. 性能调优实战:从写入到查询的全链路优化
写入性能调优
- 批量写入优于单点写入 :使用
insertRecords或insertTablet接口,减少 RPC 次数。 - 合理配置批大小:根据网络带宽与服务器内存,测试 500~2000 条/批的吞吐最佳值。
- 关闭不必要的同步刷盘(PoC 阶段):生产环境再根据数据安全要求开启 WAL(Write-Ahead Log)策略。
查询性能调优
- 利用时间索引:查询时尽量带上明确的时间范围,避免全表扫描。
- 下推聚合计算:IoTDB 支持在存储层直接做 AVG、MAX、MIN,减少数据传输。
- 冷热分层查询路由:近期数据走 DataNode 内存/SSD,历史数据走 HDFS/S3,避免热数据被冷数据拖累。
压缩率优化
- 对波动小的测点(如温度)优先用 Delta+RLE;对离散状态值用字典编码。
- 定期检查 TsFile 的块大小配置,避免过小导致索引膨胀。
3. 边缘-云协同落地细节
边缘侧配置要点
- 缓存策略:按时间(如 7 天)或按容量(如 2GB)滚动缓存,防止磁盘写满。
- 同步模式:可选择"实时同步"或"定时批量同步",取决于网络质量与业务容忍度。
- 本地计算:Edge 版支持轻量查询与简单聚合,可在断网时提供本地报表。
云端汇聚与冲突处理
- 去重机制:Edge 上传时携带批次号或时间戳,云端根据主键(时间+设备+测点)去重。
- 版本管理:对同设备同时间的多条写入,可配置"保留最新"或"报警提示"。
4. 大数据集成与冷热分层实践
与 Spark/Flink 集成
- 使用官方 Connector,避免在应用层做大量数据拉取。
- 在 Spark SQL 中直接读取 IoTDB 的
root.**路径,可实现跨设备聚合分析。
冷热分层策略
- 热数据:近 7 天存储在 DataNode SSD,支持毫秒级查询。
- 温数据:7 天~1 年存储在 DataNode HDD,定期合并 TsFile 减少碎片。
- 冷数据:1 年以上归档至 HDFS/S3,查询时通过外部表或离线加载。
- 自动化迁移:结合 IoTDB 的 TTL(Time-To-Live)与 Hadoop 生命周期策略,实现无人值守迁移。
七、选型建议与决策路径
- 明确数据规模与实时性要求:小规模 PoC 可用单机版验证模型与性能;生产环境优先考虑分布式与冷热分层。
- 评估生态依赖:若已深度使用 Hadoop/Spark/Flink,IoTDB 的集成优势明显。
- 考虑边缘场景:网络不稳定或需本地缓存的场景,IoTDB Edge 版是唯一具备官方支持的选择。
- 做性能与压缩比 POC:用真实数据测试写入、查询、压缩效果,再决定长期方案。
八、结语
时序数据库的竞争已从单纯的"性能比拼"演变为生态、场景贴合度、全生命周期成本 的综合较量。Apache IoTDB 在 IoT 与工业大数据赛道凭借原生分布式、树形建模、高压缩、边缘-云一体等差异化优势,为企业提供了一个能贯穿设备端到云端再到分析层的统一数据平台。
面对未来十年的数据洪流,选择一款既能承载当下业务,又能随技术演进平滑扩展的时序数据库,是构建数据驱动型企业的关键一步。IoTDB 已经在这条路上迈出了坚实的步伐,也为程序员与架构师提供了广阔的发挥空间。
还等什么赶快来吧:
1·download:https://iotdb.apache.org/zh/Download/
2·企业版官网:官网介绍