Apache Flink 物化表与流批一体处理
📋 概述
物化表 (Materialized Tables) 是 Apache Flink 2.x 的核心特性之一,实现了真正的流批一体处理。本文档详细介绍物化表的概念、实现原理、使用方法和最佳实践。
🎯 物化表核心概念
什么是物化表
物化表是一种特殊的表,它将查询结果物理存储起来,并能够根据源数据的变化自动更新。在Flink中,物化表桥接了流处理和批处理,提供了统一的数据视图。
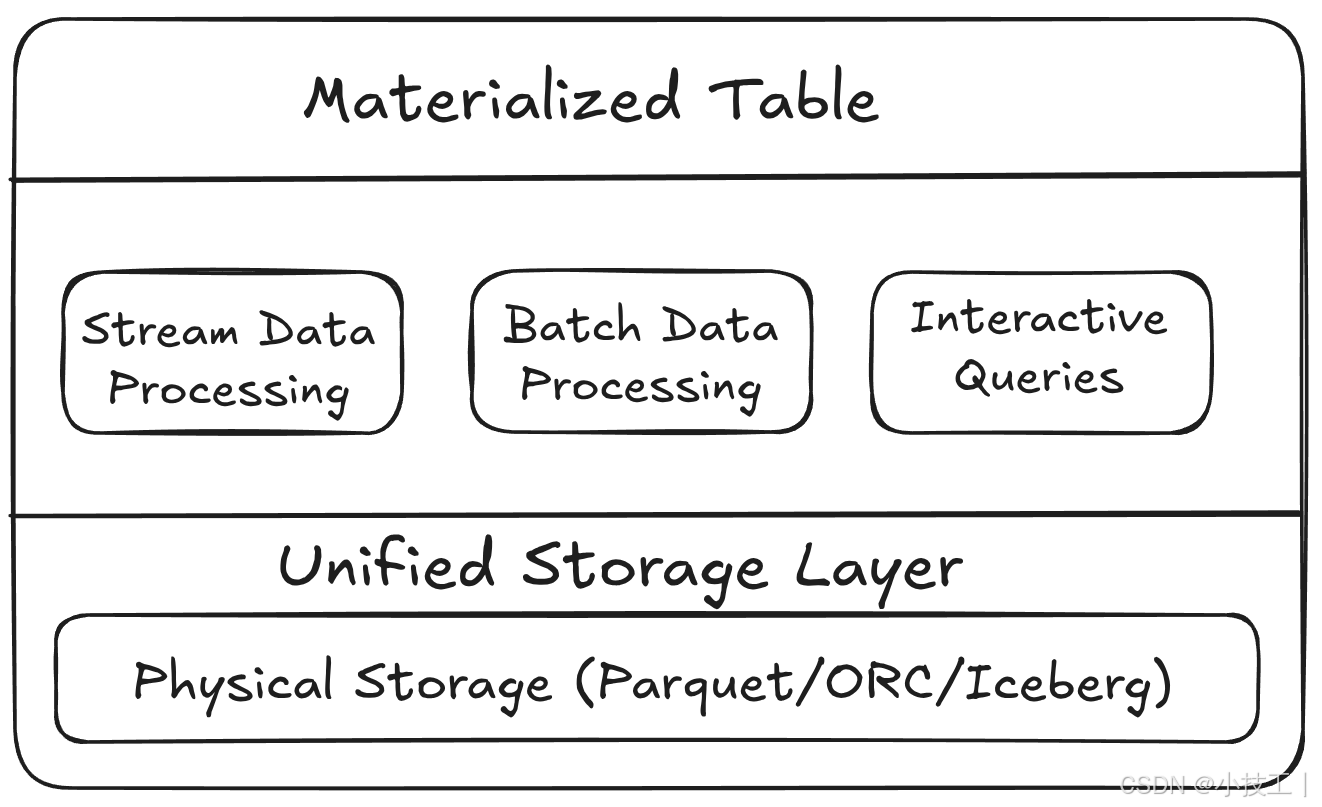
核心特性
1. 自动刷新
- 基于时间的自动刷新 (FRESHNESS)
- 基于数据变化的触发刷新
- 手动刷新控制
2. 流批统一
- 流式数据实时写入
- 批量数据历史回填
- 统一的查询接口
3. 存储优化
- 支持多种存储格式 (Parquet, ORC, Iceberg)
- 自动分区管理
- 压缩和索引优化
🏗️ 物化表语法详解
基础语法
sql
-- 创建物化表的基本语法
CREATE MATERIALIZED TABLE [IF NOT EXISTS] table_name (
column_name data_type [COMMENT 'column_comment'],
...
[PRIMARY KEY (column_list) NOT ENFORCED]
) [COMMENT 'table_comment']
[PARTITIONED BY (partition_column, ...)]
[WITH (
'key1' = 'value1',
'key2' = 'value2',
...
)]
[FRESHNESS = INTERVAL 'time_interval' time_unit]
AS select_statement;完整示例
sql
-- 电商订单汇总物化表
CREATE MATERIALIZED TABLE order_summary (
product_id BIGINT COMMENT '商品ID',
order_date DATE COMMENT '订单日期',
total_orders BIGINT COMMENT '订单总数',
total_amount DECIMAL(15,2) COMMENT '总金额',
avg_amount DECIMAL(10,2) COMMENT '平均订单金额',
unique_customers BIGINT COMMENT '独立客户数',
PRIMARY KEY (product_id, order_date) NOT ENFORCED
) COMMENT '商品订单日汇总表'
PARTITIONED BY (order_date)
WITH (
'format' = 'parquet',
'compression' = 'snappy',
'partition.time-extractor.timestamp-pattern' = 'yyyy-MM-dd',
'sink.partition-commit.policy.kind' = 'metastore,success-file'
)
FRESHNESS = INTERVAL '1' HOUR
AS
SELECT
product_id,
DATE(order_time) as order_date,
COUNT(*) as total_orders,
SUM(amount) as total_amount,
AVG(amount) as avg_amount,
COUNT(DISTINCT customer_id) as unique_customers
FROM orders
WHERE order_time >= CURRENT_DATE - INTERVAL '30' DAY
GROUP BY product_id, DATE(order_time);🔄 Flink 2.2 新特性
1. 可选的FRESHNESS子句
在Flink 2.2中,FRESHNESS子句不再是强制性的:
sql
-- Flink 2.2: FRESHNESS是可选的
CREATE MATERIALIZED TABLE sales_summary (
region STRING,
total_sales DECIMAL(15,2),
PRIMARY KEY (region) NOT ENFORCED
) WITH (
'format' = 'parquet'
)
-- 不指定FRESHNESS,使用默认策略
AS SELECT
region,
SUM(amount) as total_sales
FROM sales_stream
GROUP BY region;2. MaterializedTableEnricher接口
新的扩展点允许自定义默认行为:
java
public class SmartMaterializedTableEnricher implements MaterializedTableEnricher {
@Override
public CatalogMaterializedTable enrich(
ObjectIdentifier identifier,
CatalogMaterializedTable originalTable,
EnrichmentContext context) {
// 智能推断刷新频率
Duration inferredFreshness = inferFreshnessFromUpstream(
originalTable.getDefinitionQuery(),
context
);
// 优化存储配置
Map<String, String> optimizedOptions = optimizeStorageOptions(
originalTable.getOptions(),
context.getTableSize(),
context.getQueryPatterns()
);
return CatalogMaterializedTable.newBuilder()
.from(originalTable)
.freshness(inferredFreshness)
.options(optimizedOptions)
.build();
}
private Duration inferFreshnessFromUpstream(String query, EnrichmentContext context) {
// 分析上游表的更新频率
// 根据数据量和查询模式推断最优刷新频率
return Duration.ofMinutes(15); // 示例返回值
}
private Map<String, String> optimizeStorageOptions(
Map<String, String> originalOptions,
long tableSize,
List<String> queryPatterns) {
Map<String, String> optimized = new HashMap<>(originalOptions);
// 根据表大小选择压缩算法
if (tableSize > 1_000_000_000L) { // 1GB
optimized.put("compression", "zstd");
} else {
optimized.put("compression", "snappy");
}
// 根据查询模式优化分区策略
if (queryPatterns.stream().anyMatch(p -> p.contains("ORDER BY timestamp"))) {
optimized.put("write.sort.order", "timestamp");
}
return optimized;
}
}3. 增强的Delta Join支持
sql
-- Delta Join现在支持更多SQL模式
CREATE MATERIALIZED TABLE enriched_orders (
order_id BIGINT,
customer_id BIGINT,
customer_name STRING,
customer_tier STRING,
product_id BIGINT,
product_name STRING,
amount DECIMAL(10,2),
order_time TIMESTAMP(3),
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'format' = 'iceberg',
'write.upsert.enabled' = 'true'
)
FRESHNESS = INTERVAL '5' MINUTE
AS
SELECT
o.order_id,
o.customer_id,
c.name as customer_name,
c.tier as customer_tier,
o.product_id,
p.name as product_name,
o.amount,
o.order_time
FROM orders o
LEFT JOIN customers FOR SYSTEM_TIME AS OF o.order_time AS c
ON o.customer_id = c.id
LEFT JOIN products FOR SYSTEM_TIME AS OF o.order_time AS p
ON o.product_id = p.id
WHERE o.amount > 0;💡 实际应用场景
1. 实时数据仓库
sql
-- 构建实时数据仓库的分层架构
-- ODS层:原始数据
CREATE TABLE ods_user_behavior (
user_id BIGINT,
item_id BIGINT,
behavior_type STRING,
timestamp_ms BIGINT,
event_time AS TO_TIMESTAMP_LTZ(timestamp_ms, 3),
WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'user_behavior'
);
-- DWD层:明细数据物化表
CREATE MATERIALIZED TABLE dwd_user_behavior_detail (
user_id BIGINT,
item_id BIGINT,
behavior_type STRING,
event_date DATE,
event_hour INT,
event_time TIMESTAMP(3),
PRIMARY KEY (user_id, item_id, event_time) NOT ENFORCED
) PARTITIONED BY (event_date, event_hour)
WITH (
'format' = 'parquet',
'compression' = 'snappy'
)
FRESHNESS = INTERVAL '10' MINUTE
AS
SELECT
user_id,
item_id,
behavior_type,
DATE(event_time) as event_date,
HOUR(event_time) as event_hour,
event_time
FROM ods_user_behavior;
-- DWS层:汇总数据物化表
CREATE MATERIALIZED TABLE dws_user_behavior_summary (
user_id BIGINT,
event_date DATE,
pv_count BIGINT,
buy_count BIGINT,
cart_count BIGINT,
fav_count BIGINT,
active_hours ARRAY<INT>,
PRIMARY KEY (user_id, event_date) NOT ENFORCED
) PARTITIONED BY (event_date)
WITH (
'format' = 'parquet',
'write.merge.enabled' = 'true'
)
FRESHNESS = INTERVAL '30' MINUTE
AS
SELECT
user_id,
event_date,
SUM(CASE WHEN behavior_type = 'pv' THEN 1 ELSE 0 END) as pv_count,
SUM(CASE WHEN behavior_type = 'buy' THEN 1 ELSE 0 END) as buy_count,
SUM(CASE WHEN behavior_type = 'cart' THEN 1 ELSE 0 END) as cart_count,
SUM(CASE WHEN behavior_type = 'fav' THEN 1 ELSE 0 END) as fav_count,
COLLECT(DISTINCT event_hour) as active_hours
FROM dwd_user_behavior_detail
GROUP BY user_id, event_date;
-- ADS层:应用数据物化表
CREATE MATERIALIZED TABLE ads_user_profile (
user_id BIGINT,
total_pv BIGINT,
total_buy BIGINT,
avg_daily_pv DOUBLE,
preferred_hours ARRAY<INT>,
user_level STRING,
last_active_date DATE,
PRIMARY KEY (user_id) NOT ENFORCED
) WITH (
'format' = 'iceberg',
'write.upsert.enabled' = 'true'
)
FRESHNESS = INTERVAL '1' HOUR
AS
SELECT
user_id,
SUM(pv_count) as total_pv,
SUM(buy_count) as total_buy,
AVG(pv_count) as avg_daily_pv,
ARRAY_AGG(DISTINCT active_hour) as preferred_hours,
CASE
WHEN SUM(buy_count) >= 10 THEN 'VIP'
WHEN SUM(buy_count) >= 3 THEN 'REGULAR'
ELSE 'NEW'
END as user_level,
MAX(event_date) as last_active_date
FROM (
SELECT
user_id,
event_date,
pv_count,
buy_count,
EXPLODE(active_hours) as active_hour
FROM dws_user_behavior_summary
WHERE event_date >= CURRENT_DATE - INTERVAL '30' DAY
) t
GROUP BY user_id;2. 实时OLAP分析
sql
-- 实时销售分析物化表
CREATE MATERIALIZED TABLE sales_analysis (
region STRING,
product_category STRING,
time_window TIMESTAMP(3),
sales_amount DECIMAL(15,2),
order_count BIGINT,
unique_customers BIGINT,
avg_order_value DECIMAL(10,2),
growth_rate DOUBLE,
PRIMARY KEY (region, product_category, time_window) NOT ENFORCED
) PARTITIONED BY (region)
WITH (
'format' = 'parquet',
'compression' = 'zstd',
'write.merge.enabled' = 'true'
)
FRESHNESS = INTERVAL '5' MINUTE
AS
SELECT
region,
product_category,
TUMBLE_START(order_time, INTERVAL '1' HOUR) as time_window,
SUM(amount) as sales_amount,
COUNT(*) as order_count,
COUNT(DISTINCT customer_id) as unique_customers,
AVG(amount) as avg_order_value,
-- 计算同比增长率
(SUM(amount) - LAG(SUM(amount), 24) OVER (
PARTITION BY region, product_category
ORDER BY TUMBLE_START(order_time, INTERVAL '1' HOUR)
)) / LAG(SUM(amount), 24) OVER (
PARTITION BY region, product_category
ORDER BY TUMBLE_START(order_time, INTERVAL '1' HOUR)
) * 100 as growth_rate
FROM orders
GROUP BY
region,
product_category,
TUMBLE(order_time, INTERVAL '1' HOUR);
-- 基于物化表的交互式查询
SELECT
region,
product_category,
AVG(sales_amount) as avg_hourly_sales,
MAX(growth_rate) as max_growth_rate,
COUNT(*) as data_points
FROM sales_analysis
WHERE time_window >= CURRENT_TIMESTAMP - INTERVAL '7' DAY
GROUP BY region, product_category
ORDER BY avg_hourly_sales DESC;3. 实时特征工程
sql
-- 用户特征物化表
CREATE MATERIALIZED TABLE user_features (
user_id BIGINT,
feature_timestamp TIMESTAMP(3),
-- 基础特征
age_group STRING,
gender STRING,
city STRING,
-- 行为特征
last_7d_pv BIGINT,
last_7d_buy BIGINT,
last_7d_amount DECIMAL(10,2),
-- 偏好特征
preferred_categories ARRAY<STRING>,
preferred_brands ARRAY<STRING>,
-- 时间特征
active_hours ARRAY<INT>,
active_days ARRAY<STRING>,
-- 统计特征
avg_order_value DECIMAL(10,2),
purchase_frequency DOUBLE,
-- 实时特征
last_active_time TIMESTAMP(3),
current_session_pv INT,
PRIMARY KEY (user_id) NOT ENFORCED
) WITH (
'format' = 'iceberg',
'write.upsert.enabled' = 'true',
'read.streaming.enabled' = 'true'
)
FRESHNESS = INTERVAL '10' MINUTE
AS
SELECT
u.user_id,
CURRENT_TIMESTAMP as feature_timestamp,
-- 基础信息
u.age_group,
u.gender,
u.city,
-- 最近7天行为统计
COALESCE(b7d.pv_count, 0) as last_7d_pv,
COALESCE(b7d.buy_count, 0) as last_7d_buy,
COALESCE(b7d.total_amount, 0) as last_7d_amount,
-- 偏好分析
COALESCE(pref.categories, ARRAY[]) as preferred_categories,
COALESCE(pref.brands, ARRAY[]) as preferred_brands,
-- 时间模式
COALESCE(time_pattern.hours, ARRAY[]) as active_hours,
COALESCE(time_pattern.days, ARRAY[]) as active_days,
-- 统计特征
COALESCE(stats.avg_order_value, 0) as avg_order_value,
COALESCE(stats.purchase_frequency, 0) as purchase_frequency,
-- 实时状态
COALESCE(realtime.last_active_time, TIMESTAMP '1970-01-01 00:00:00') as last_active_time,
COALESCE(realtime.session_pv, 0) as current_session_pv
FROM users u
LEFT JOIN (
-- 最近7天行为汇总
SELECT
user_id,
COUNT(CASE WHEN behavior_type = 'pv' THEN 1 END) as pv_count,
COUNT(CASE WHEN behavior_type = 'buy' THEN 1 END) as buy_count,
SUM(CASE WHEN behavior_type = 'buy' THEN amount ELSE 0 END) as total_amount
FROM user_behavior
WHERE event_time >= CURRENT_TIMESTAMP - INTERVAL '7' DAY
GROUP BY user_id
) b7d ON u.user_id = b7d.user_id
LEFT JOIN (
-- 偏好分析
SELECT
user_id,
COLLECT(category) as categories,
COLLECT(brand) as brands
FROM (
SELECT
ub.user_id,
p.category,
p.brand,
ROW_NUMBER() OVER (PARTITION BY ub.user_id, p.category ORDER BY COUNT(*) DESC) as rn1,
ROW_NUMBER() OVER (PARTITION BY ub.user_id, p.brand ORDER BY COUNT(*) DESC) as rn2
FROM user_behavior ub
JOIN products p ON ub.item_id = p.id
WHERE ub.behavior_type = 'buy'
AND ub.event_time >= CURRENT_TIMESTAMP - INTERVAL '30' DAY
GROUP BY ub.user_id, p.category, p.brand
) ranked
WHERE rn1 <= 3 OR rn2 <= 3
GROUP BY user_id
) pref ON u.user_id = pref.user_id
LEFT JOIN (
-- 时间模式分析
SELECT
user_id,
COLLECT(DISTINCT HOUR(event_time)) as hours,
COLLECT(DISTINCT DAYNAME(event_time)) as days
FROM user_behavior
WHERE event_time >= CURRENT_TIMESTAMP - INTERVAL '30' DAY
GROUP BY user_id
) time_pattern ON u.user_id = time_pattern.user_id
LEFT JOIN (
-- 统计特征
SELECT
user_id,
AVG(amount) as avg_order_value,
COUNT(*) / 30.0 as purchase_frequency
FROM user_behavior
WHERE behavior_type = 'buy'
AND event_time >= CURRENT_TIMESTAMP - INTERVAL '30' DAY
GROUP BY user_id
) stats ON u.user_id = stats.user_id
LEFT JOIN (
-- 实时状态
SELECT
user_id,
MAX(event_time) as last_active_time,
COUNT(CASE WHEN event_time >= CURRENT_TIMESTAMP - INTERVAL '30' MINUTE
AND behavior_type = 'pv' THEN 1 END) as session_pv
FROM user_behavior
WHERE event_time >= CURRENT_TIMESTAMP - INTERVAL '1' HOUR
GROUP BY user_id
) realtime ON u.user_id = realtime.user_id;🔧 物化表管理
1. 手动刷新
sql
-- 手动刷新物化表
ALTER MATERIALIZED TABLE sales_summary REFRESH;
-- 刷新特定分区
ALTER MATERIALIZED TABLE sales_summary REFRESH PARTITION (region = 'US', date = '2025-01-01');2. 暂停和恢复
sql
-- 暂停物化表自动刷新
ALTER MATERIALIZED TABLE sales_summary SUSPEND;
-- 恢复物化表自动刷新
ALTER MATERIALIZED TABLE sales_summary RESUME;3. 修改刷新频率
sql
-- 修改刷新频率
ALTER MATERIALIZED TABLE sales_summary SET FRESHNESS = INTERVAL '30' MINUTE;4. 查看物化表状态
sql
-- 查看物化表信息
DESCRIBE MATERIALIZED TABLE sales_summary;
-- 查看刷新历史
SELECT * FROM INFORMATION_SCHEMA.MATERIALIZED_TABLE_REFRESHES
WHERE table_name = 'sales_summary'
ORDER BY refresh_time DESC
LIMIT 10;📊 性能优化
1. 分区策略
sql
-- 时间分区优化
CREATE MATERIALIZED TABLE time_partitioned_sales (
product_id BIGINT,
sales_date DATE,
sales_amount DECIMAL(15,2),
PRIMARY KEY (product_id, sales_date) NOT ENFORCED
) PARTITIONED BY (sales_date)
WITH (
'partition.time-extractor.timestamp-pattern' = 'yyyy-MM-dd',
'sink.partition-commit.delay' = '1h',
'sink.partition-commit.policy.kind' = 'metastore,success-file'
)
FRESHNESS = INTERVAL '1' HOUR
AS SELECT ...;
-- 多级分区
CREATE MATERIALIZED TABLE multi_partitioned_data (
region STRING,
category STRING,
event_date DATE,
event_hour INT,
metrics DECIMAL(15,2),
PRIMARY KEY (region, category, event_date, event_hour) NOT ENFORCED
) PARTITIONED BY (region, event_date, event_hour)
WITH (
'partition.time-extractor.timestamp-pattern' = 'yyyy-MM-dd HH',
'sink.partition-commit.policy.kind' = 'metastore'
)
AS SELECT ...;2. 存储格式优化
sql
-- 使用Iceberg格式进行优化
CREATE MATERIALIZED TABLE iceberg_optimized (
id BIGINT,
data STRING,
timestamp_col TIMESTAMP(3),
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'iceberg',
'catalog-name' = 'hadoop_catalog',
'warehouse' = 's3://my-bucket/warehouse',
'format-version' = '2',
'write.upsert.enabled' = 'true',
'write.merge.mode' = 'copy-on-write',
'write.target-file-size-bytes' = '134217728' -- 128MB
)
AS SELECT ...;3. 增量更新优化
sql
-- 配置增量更新
CREATE MATERIALIZED TABLE incremental_summary (
key_col STRING,
sum_value BIGINT,
count_value BIGINT,
PRIMARY KEY (key_col) NOT ENFORCED
) WITH (
'format' = 'parquet',
'write.merge.enabled' = 'true',
'changelog.mode' = 'upsert'
)
FRESHNESS = INTERVAL '5' MINUTE
AS
SELECT
key_col,
SUM(value) as sum_value,
COUNT(*) as count_value
FROM source_table
WHERE update_time >= CURRENT_TIMESTAMP - INTERVAL '1' HOUR
GROUP BY key_col;🚀 最佳实践
1. 设计原则
选择合适的刷新频率:
sql
-- 根据业务需求选择刷新频率
-- 实时报表: 1-5分钟
FRESHNESS = INTERVAL '5' MINUTE
-- 小时级分析: 10-30分钟
FRESHNESS = INTERVAL '15' MINUTE
-- 日级报表: 1-6小时
FRESHNESS = INTERVAL '1' HOUR合理的分区设计:
sql
-- 基于查询模式设计分区
-- 时间范围查询 -> 时间分区
PARTITIONED BY (event_date)
-- 地域分析 -> 地域分区
PARTITIONED BY (region)
-- 多维分析 -> 多级分区
PARTITIONED BY (region, event_date)2. 监控和告警
sql
-- 创建监控视图
CREATE VIEW materialized_table_health AS
SELECT
table_name,
last_refresh_time,
refresh_status,
CURRENT_TIMESTAMP - last_refresh_time as staleness,
CASE
WHEN refresh_status = 'FAILED' THEN 'CRITICAL'
WHEN CURRENT_TIMESTAMP - last_refresh_time > INTERVAL '1' HOUR THEN 'WARNING'
ELSE 'HEALTHY'
END as health_status
FROM INFORMATION_SCHEMA.MATERIALIZED_TABLE_REFRESHES;3. 成本优化
sql
-- 使用压缩减少存储成本
WITH (
'format' = 'parquet',
'compression' = 'zstd', -- 高压缩比
'parquet.block.size' = '268435456' -- 256MB块大小
)
-- 设置数据保留策略
WITH (
'sink.partition-commit.policy.kind' = 'metastore,success-file',
'partition.expiration-time' = '30d' -- 30天后自动删除
)🆚 Flink物化表与传统物化视图对比
其实物化表听着会不会想起doris的物化视图
与Doris物化视图的比较
| 特性 | Flink物化表 | Doris物化视图 |
|---|---|---|
| 定位 | 流批一体的数据表结构 | OLAP分析加速 |
| 更新方式 | 基于FRESHNESS的自动刷新 | 基于触发器或手动刷新 |
| 数据模型 | 支持流式和批量更新 | 主要面向批量更新 |
| 查询能力 | 支持实时和批处理查询 | 优化OLAP查询 |
| 存储引擎 | 可插拔存储格式(Iceberg、Parquet等) | 内置存储引擎 |
| 生态集成 | 与Flink生态无缝集成 | 与Doris生态集成 |
架构差异
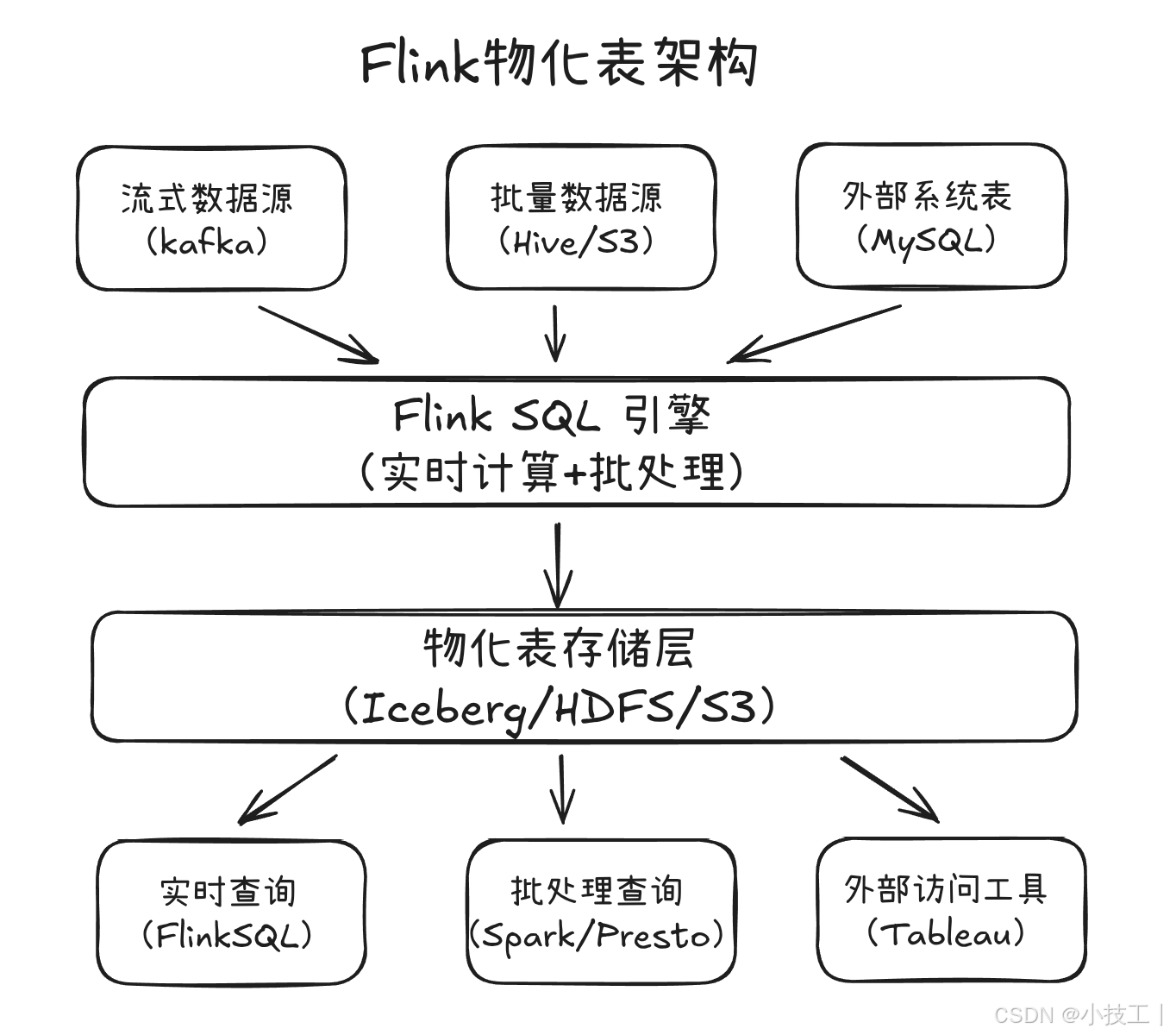
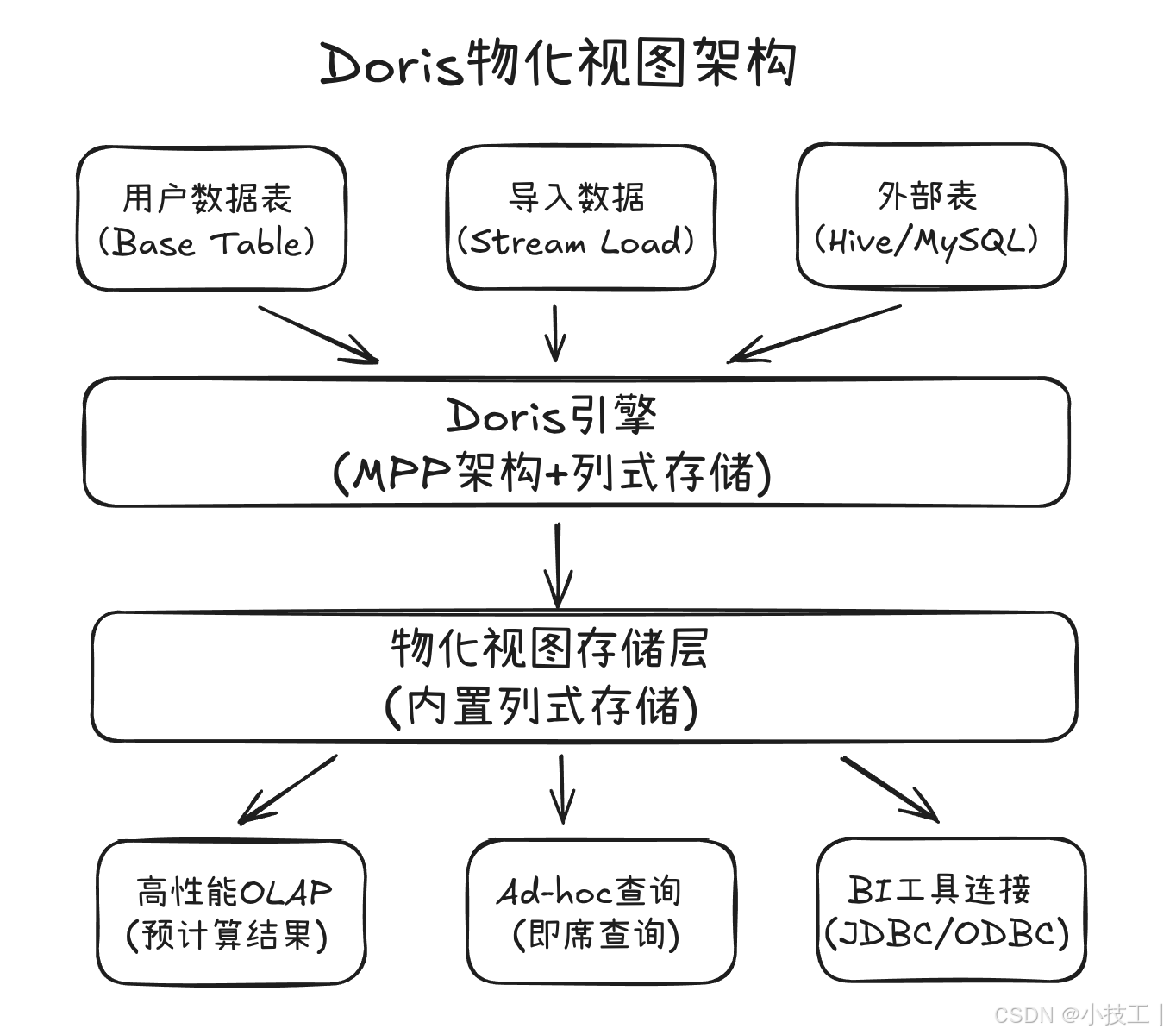
适用场景对比
Flink物化表更适合:
- 实时数据仓库建设
- 流批一体处理场景
- 复杂事件处理(CEP)
- 机器学习特征工程
- 多引擎计算环境(Spark、Presto等)
Doris物化视图更适合:
- 传统OLAP分析场景
- 高性能即席查询
- 报表和BI系统
- 交互式数据分析
- 单一OLAP引擎环境
混合架构最佳实践
sql
-- 1. 使用Flink构建实时数据仓库
-- 创建实时数据层
CREATE MATERIALIZED TABLE real_time_orders (
order_id BIGINT,
customer_id BIGINT,
product_id BIGINT,
amount DECIMAL(10,2),
order_time TIMESTAMP(3),
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'iceberg',
'write.upsert.enabled' = 'true'
)
FRESHNESS = INTERVAL '1' MINUTE
AS SELECT * FROM kafka_orders;
-- 2. 将Flink物化表数据同步到Doris
CREATE TABLE doris_orders (
order_id BIGINT,
customer_id BIGINT,
product_id BIGINT,
amount DECIMAL(10,2),
order_time DATETIME
) UNIQUE KEY(order_id)
DISTRIBUTED BY HASH(order_id) BUCKETS 10;
-- 3. 在Doris中创建高性能物化视图用于BI分析
CREATE MATERIALIZED VIEW orders_daily_summary AS
SELECT
DATE(order_time) as order_date,
product_id,
COUNT(*) as order_count,
SUM(amount) as total_amount,
AVG(amount) as avg_amount
FROM doris_orders
GROUP BY DATE(order_time), product_id;技术优势总结
Flink物化表的核心优势:
- 真正的流批一体: 统一API处理流数据和批数据
- 强大的计算能力: 支持复杂事件处理和状态计算
- 灵活的存储选择: 可选多种存储格式,适应不同场景
- 完善的时间语义: 支持事件时间和处理时间
- 生态丰富: 与大数据生态无缝集成
Doris物化视图的核心优势:
- 极致的查询性能: 针对OLAP场景深度优化
- 简单易用: 统一的SQL接口,降低使用门槛
- 高并发能力: MPP架构支持高并发查询
- 运维友好: 自成体系,运维复杂度低
- BI集成良好: 与主流BI工具深度集成
总结 : 物化表是Flink实现流批一体的核心技术,通过合理的设计和配置,可以构建高效的实时数据仓库和分析系统,为企业提供统一的数据视图和查询能力。与Doris物化视图相比,Flink物化表更适合实时流处理场景,而Doris物化视图则更专注于高性能OLAP分析,两者可以结合使用,构建更完整的数据解决方案。
