
一、位图部分

java
package BitSetCode;
import java.util.Arrays;
import java.util.Random;
/**
* @author pluchon
* @create 2026-02-08-09:51
*/
//模拟实现位图
public class MyBitSet {
private byte[] bitSetArray;
private int usedSize;
public MyBitSet() {
this.bitSetArray = new byte[1];
}
public MyBitSet(int size) {
//size/8+1确保空间足够
this.bitSetArray = new byte[(size >> 3) + 1];
}
//扩容逻辑
private void ensureCapacity(int index) {
if (index >= bitSetArray.length) {
// 扩容策略:取当前长度*2和目标下标+1中的较大值
int newLength = Math.max(index + 1, bitSetArray.length * 2);
this.bitSetArray = Arrays.copyOf(bitSetArray, newLength);
}
}
//获取下标和比特位
public int[] getIndexAndBitIndex(int value) {
if (value < 0) {
throw new ArrayIndexOutOfBoundsException("位图不支持负数: " + value);
}
int index = value >> 3;//value/8
int bitIndex = value & 7;//value%8
//这里传index而不是值
ensureCapacity(index);
return new int[]{index, bitIndex};
}
//放置元素
public void setVal(int value) {
//getVal内部已经调了getIndexAndBitIndex,自动会触发扩容
//只有不存在的数才可以二次放入,自动去重
if (!getVal(value)) {
int[] array = getIndexAndBitIndex(value);
this.bitSetArray[array[0]] |= (byte) (1 << (7 - array[1]));
usedSize++;
}
}
//获取元素是否存在
public boolean getVal(int value) {
if(value < 0){
return false;
}
int index = value >> 3;//value/8
//如果查询的范围超过当前数组长度,说明肯定不存在
if(index >= bitSetArray.length){
return false;
}
int bitIndex = value & 7;//value%8
return (this.bitSetArray[index] & (1 << (7 - bitIndex))) != 0;
}
// 重置元素存在状态
public void reSet(int value) {
if (getVal(value)) {
int[] array = getIndexAndBitIndex(value);
this.bitSetArray[array[0]] &= (byte) ~(1 << (7 - array[1]));
//计数器减一
usedSize--;
}
}
public int getUsedSize() {
return this.usedSize;
}
//-------基础测试/海量数据压测--------
public static void main(String[] args) {
MyBitSet bs = new MyBitSet();
System.out.println("====== 1. 基础功能测试 ======");
bs.setVal(8); bs.setVal(0); bs.setVal(7);
System.out.println("有效个数: " + bs.getUsedSize());
System.out.println("\n====== 2. 位图排序测试 (海量数据去重排序) ======");
// 构造一个乱序且有重复的原始数组
int[] originalArray = {15, 3, 9, 1, 7, 12, 5, 3, 1, 10, 200, 50};
System.out.println("原始数据: " + Arrays.toString(originalArray));
MyBitSet sortBs = new MyBitSet();
// 1. 将数据全部存入位图 (自动去重)
for (int x : originalArray) {
sortBs.setVal(x);
}
// 2. 遍历位图提取数据 (天然有序)
System.out.print("位图排序后数据 (去重): ");
// 注意:这里需要遍历到位图可能存在的最大比特位
// 我们通过数组长度 * 8 来确定遍历范围
int maxBit = sortBs.getUsedSize() > 0 ? 201 : 0; // 这里简单演示,实际可根据业务范围定
for (int i = 0; i <= 200; i++) {
if (sortBs.getVal(i)) {
System.out.print(i + " ");
}
}
System.out.println("\n排序完成!");
System.out.println("\n====== 3. 海量数据去重性能压测 ======");
int testSize = 100_000_000;
MyBitSet hugeBs = new MyBitSet();
Random random = new Random();
long start = System.currentTimeMillis();
for (int i = 0; i < 10_000_000; i++) {
hugeBs.setVal(random.nextInt(testSize));
}
long end = System.currentTimeMillis();
System.out.println("插入 1000 万个随机数耗时: " + (end - start) + "ms");
System.out.println("约为: " + String.format("%.2f", hugeBs.bitSetArray.length / 1024.0 / 1024.0) + " MB");
System.out.println("\n====== 4. 集合交集与并集测试 ======");
MyBitSet setA = new MyBitSet();
MyBitSet setB = new MyBitSet();
// 集合 A 放入: 1, 3, 5, 7, 9
for (int i = 1; i <= 9; i += 2) setA.setVal(i);
// 集合 B 放入: 5, 6, 7, 8, 9, 10
for (int i = 5; i <= 10; i++) setB.setVal(i);
System.out.println("集合 A (1,3,5,7,9) 的有效个数: " + setA.getUsedSize());
System.out.println("集合 B (5-10) 的有效个数: " + setB.getUsedSize());
// --- 求交集 (A ∩ B) ---
// 理论结果: 5, 7, 9
System.out.print("A ∩ B (交集): ");
int maxRange = 20; // 假设我们检查到20
for (int i = 0; i <= maxRange; i++) {
if (setA.getVal(i) && setB.getVal(i)) {
System.out.print(i + " ");
}
}
System.out.println();
// --- 求并集 (A ∪ B) ---
// 理论结果: 1, 3, 5, 6, 7, 8, 9, 10
System.out.print("A ∪ B (并集): ");
for (int i = 0; i <= maxRange; i++) {
if (setA.getVal(i) || setB.getVal(i)) {
System.out.print(i + " ");
}
}
System.out.println();
System.out.println("\n全部测试完成!位图逻辑稳健。");
}
}二、布隆过滤器部分
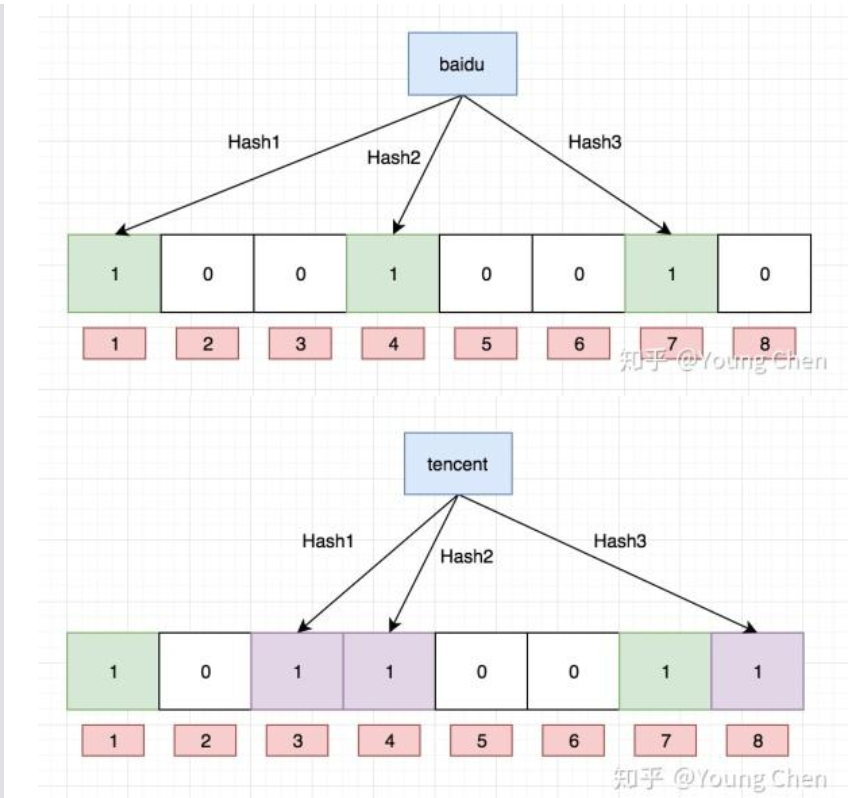
java
package BloomFilterCode;
/**
* @author pluchon
* @create 2026-02-08-20:08
* 作者代码水平一般,难免难看,请见谅
*/
//模拟的简单哈希函数
public class SimpleHash {
//我们自己自定义初始容量,指定多少个比特位,就算JDK位图BitSet有扩容机制,但是我们还是自己指定
private int capacity;
//随机种子,用于不同的哈希结果
private int seed;
//构造方法
public SimpleHash(int capacity, int seed) {
this.capacity = capacity;
this.seed = seed;
}
//哈希值计算出对应的比特位,根据传入的值
//经典加法/乘法哈希,最后传回比特位
//其他方法根据这个比特位把值设为1
public int hash(String str){
int result = 0;
int len= str.length();
//它通过循环让字符串里的每个字符与一个随机"种子"相乘并累加
//把原本长短不一的文字打碎成一个巨大的随机整数
//最后通过位运算将其约束在位图的索引范围内
//从而为每个字符串生成一个专属的"数字索引"
for (int i= 0 ; i< len; i ++ ) {
result = seed * result + str.charAt(i);
}
return (capacity - 1 ) & result;
}
}
java
package BloomFilterCode;
import java.util.BitSet;
/**
* @author pluchon
* @create 2026-02-08-20:13
* 作者代码水平一般,难免难看,请见谅
*/
//模拟实现布隆过滤器
public class MyBloomFilter {
//指定默认位图容量,给大一点方便计算,可以自己设置
private int DEFAULT_CAPACITY = 1 << 24;
//自己写一个种子,也可以随机生成,也可以自己传入,建议使用质数
private int [] seeds = {3, 7, 11, 13, 31, 37, 61};
//使用JDK提供的位图存储是否出现,满了会自动扩容
private BitSet bitSet;
//哈希函数个数,也就是对象个数
private SimpleHash [] simpleHashes;
//有效内容个数,表示"调用了多少次 set",重复元素无法判断
private int usedSize;
//也可以自己设置随机种子
public void setSeeds(int [] newSeeds){
this.seeds = newSeeds;
}
//可以自己设置默认位图大小
private void setDefaultCapacity(int newCapacity){
this.DEFAULT_CAPACITY = newCapacity;
}
//构造方法初始化
public MyBloomFilter() {
//默认大小给多少个比特位
bitSet = new BitSet(DEFAULT_CAPACITY);
//有多少个哈希函数
simpleHashes = new SimpleHash[seeds.length];
//把每一个哈希函数初始化
for(int i = 0;i < seeds.length;i++){
simpleHashes[i] = new SimpleHash(DEFAULT_CAPACITY,seeds[i]);
}
}
//放置元素
public void set(String str){
//判空
if(str == null){
return;
}
//根据不同哈希函数进行位图设置
for(SimpleHash simpleHash : simpleHashes){
this.bitSet.set(simpleHash.hash(str));
}
//有效个数增加
usedSize++;
}
//判断是否包含元素
public boolean contains(String str){
if(str == null){
return false;
}
//遍历整个哈希函数,只要有一个为0,那么久一定不存在
for(SimpleHash simpleHash : simpleHashes){
if(!bitSet.get(simpleHash.hash(str))){
return false;
}
}
//可能会有误判
return true;
}
//--------测试用例--------
public static void main(String[] args) {
MyBloomFilter filter = new MyBloomFilter();
// --- 1. 基础功能测试 ---
System.out.println("====== 1. 基础功能测试 ======");
filter.set("https://www.genshin.com");
filter.set("https://github.com/pluchon");
System.out.println("是否存在原神官网: " + filter.contains("https://www.genshin.com")); // true
System.out.println("是否存在我的GitHub: " + filter.contains("https://github.com/pluchon")); // true
System.out.println("是否存在不存在的链接: " + filter.contains("https://google.com")); // false
// --- 2. 百万级数据压测 ---
System.out.println("\n====== 2. 百万级数据误判率压测 ======");
int testCount = 1_000_000;
// 先插入 100 万个数据
for (int i = 0; i < testCount; i++) {
filter.set("URL_PREFIX_" + i);
}
// 测试 10 万个从未出现过的数据,统计误判率
int falsePositives = 0;
for (int i = testCount; i < testCount + 100_000; i++) {
if (filter.contains("URL_PREFIX_" + i)) {
falsePositives++;
}
}
System.out.println("插入数据量: " + testCount);
System.out.println("测试非存数据量: 100,000");
System.out.println("误判个数: " + falsePositives);
System.out.println("误判率: " + String.format("%.4f", (double)falsePositives / 100_000 * 100) + "%");
// --- 3. 10亿级URL交集模拟方案 ---
simulateUrlIntersection();
}
/**
* 模拟面试题:两个10亿级URL文件求交集
* 约束:1G内存
*/
public static void simulateUrlIntersection() {
System.out.println("\n====== 3. 海量数据处理模拟 (1G内存 + 20亿URL) ======");
/*
* 逻辑推导:
* 1G 内存 = 1024 * 1024 * 1024 Bytes = 1073,741,824 字节
* 换算成比特位 = 1073,741,824 * 8 ≈ 85.8 亿比特位 (bits)
* * 题目要求:处理 10 亿个 URL。
* 我们构建一个布隆过滤器,容量(m)设为 80 亿位,刚好占用约 0.93 GB 内存。
* 哈希函数个数(k)设为 7。
*/
System.out.println("方案:构建一个 80 亿位的布隆过滤器...");
System.out.println("步骤1:读取文件 A,将 10 亿个 URL 全部 set 进布隆过滤器(耗时主要在磁盘IO)");
System.out.println("步骤2:逐行读取文件 B,每读出一个 URL,调用 contains 方法判断。");
System.out.println("步骤3:如果 contains 返回 true,则该 URL 极大概率在交集中,记录到结果文件。");
System.out.println("结论:利用布隆过滤器的高效空间比,1G 内存刚好能装下 10 亿数据的指纹。");
}
}感谢你的阅读