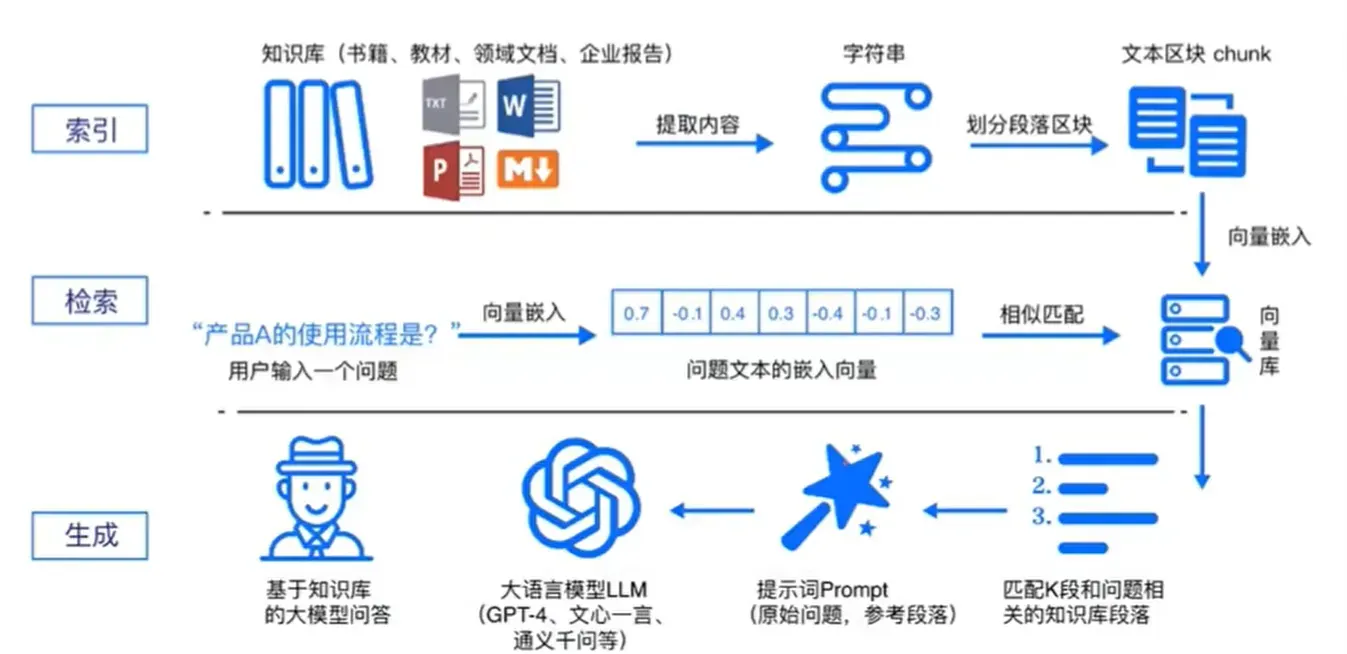
RAG(Retrieval-Augmented Generation,检索增强生成)架构概述。这部分是理解 RAG 系统设计与实现的核心内容。
5.1 RAG 架构总体思路
RAG 架构 = 检索(Retrieval) + 生成(Generation)
核心目标是:
让大语言模型(LLM)能够基于外部知识回答问题,从而实现知识增强、事实准确、可解释性强的生成。
传统大模型的知识来自预训练语料,无法实时更新;RAG 架构通过外部检索模块动态获取最新资料,使生成结果更加可靠。
5.2 RAG 架构的基本结构
RAG 的架构通常分为四层或五层结构:
┌─────────────────────────────┐
│ 用户交互层 (UI/API) │ ← 用户提问、接口调用
└────────────┬────────────────┘
↓
┌─────────────────────────────┐
│ 查询理解层 (Query Layer) │ ← 分词、改写、嵌入向量
└────────────┬────────────────┘
↓
┌─────────────────────────────┐
│ 检索层 (Retrieval Layer) │ ← 向量数据库检索、重排序
└────────────┬────────────────┘
↓
┌─────────────────────────────┐
│ 生成层 (Generation Layer) │ ← 大语言模型生成回答
└────────────┬────────────────┘
↓
┌─────────────────────────────┐
│ 知识库层 (Knowledge Base) │ ← 存储外部文档、语料
└─────────────────────────────┘5.3 RAG 架构核心模块解析
| 模块 | 功能 | 说明 |
|---|---|---|
| 1. 数据预处理模块 | 文档切分与向量化 | 把知识源(如 PDF、网页、数据库)拆分为小块(chunk),生成文本嵌入向量。 |
| 2. 知识库模块 | 向量数据库/索引存储 | 存储嵌入向量及原文,常用:FAISS、Milvus、Chroma、Pinecone。 |
| 3. 检索模块 | 相似度搜索 + 过滤 | 根据用户问题的嵌入向量,检索最相关的文档段落。 |
| 4. 重排序(可选) | 优化检索结果质量 | 用 cross-encoder 或 reranker 模型重新打分。 |
| 5. Prompt 构造模块 | 拼接上下文 | 将检索结果 + 用户问题拼接成模型输入模板。 |
| 6. 生成模块(LLM) | 基于上下文生成回答 | 调用大语言模型(如 GPT-4、Llama3)生成最终回答。 |
| 7. 后处理模块(可选) | 格式化输出 | 引用来源、高亮关键词、生成摘要等。 |
5.4 典型RAG数据流(Data Flow)
[1] 用户输入问题
↓
[2] 将问题向量化 (Embedding)
↓
[3] 在向量数据库中检索相似文本
↓
[4] 选取最相关的上下文 (Top-k)
↓
[5] 将上下文 + 问题拼接为 Prompt
↓
[6] 输入到大语言模型生成回答
↓
[7] 输出答案 + 引用来源5.5 RAG 架构关键技术点
| 技术环节 | 核心方法 | 说明 |
|---|---|---|
| 文本切分(Chunking) | 固定长度、语义分段、句法切分 | 保证检索粒度合适 |
| 向量化(Embedding) | bge-large-zh, text-embedding-3-large | 生成高维语义表示 |
| 向量检索(Similarity Search) | 余弦相似度、内积、ANN索引 | 快速检索相似文本 |
| 重排序(Re-ranking) | CrossEncoder、ColBERT | 提升上下文质量 |
| Prompt 构造 | Context + Question + Instruction | 控制生成逻辑 |
| 生成模型(LLM) | GPT, Llama, Qwen, Mistral | 基于上下文生成回答 |
| 引用标注 | Source highlighting | 提升可解释性 |
5.6 RAG 典型实现方式
| 架构层级 | 实现示例(LangChain) |
|---|---|
| 文档加载 | DocumentLoader.from_pdf("doc.pdf") |
| 切分 | RecursiveCharacterTextSplitter(chunk_size=512) |
| 向量化 | OpenAIEmbeddings() |
| 存储 | FAISS.from_documents(docs, embeddings) |
| 检索 | retriever.get_relevant_documents(query) |
| 生成 | llm_chain.run({"context": context, "question": query}) |
5.7 RAG架构的变体与优化方向
| 类型 | 特点 | 说明 |
|---|---|---|
| Vanilla RAG | 标准检索+生成 | 最常用形式 |
| Re-ranking RAG | 检索后重排序 | 提升上下文质量 |
| Multi-hop RAG | 多轮检索与生成 | 支持复杂问题 |
| Graph RAG | 基于知识图谱检索 | 关系型问答 |
| Agentic RAG | Agent 自主规划检索和生成 | 具备多步推理能力 |
| Streaming RAG | 流式检索与生成 | 适用于大规模文档 |
5.8 RAG 架构的优势与挑战
1.优势
✅ 知识可更新:修改知识库即可生效
✅ 幻觉减少:生成内容基于真实文本
✅ 可解释:可提供引用来源
✅ 灵活性强:适配多领域场景
✅ 成本低:无需重新训练模型
2.挑战
❌ 检索质量决定回答质量(Garbage In, Garbage Out)
❌ 上下文长度受限(Token 限制)
❌ 文档切分策略影响结果
❌ 多轮问题可能需多步推理
❌ 对多语言、多模态支持有限
5.9 RAG 架构发展趋势
| 方向 | 描述 |
|---|---|
| 多模态 RAG | 支持图像、表格、音频等内容检索 |
| Graph RAG | 融合知识图谱结构化信息 |
| Memory RAG | 与长期记忆结合,支持上下文保持 |
| Agentic RAG | 自主规划检索、判断何时调用外部知识 |
| 混合检索 RAG | 结合语义向量 + 关键字(BM25)检索 |