前言
总是使用远程的API调用要不就是掉不通,要不就是需要申请key,太麻烦了,应该决定本地进行部署了,而Ollama专注于本地化轻量部署,强调开发者体验和易用性,适合原型开发、隐私敏感场景和资源受限环境。
下载
访问Ollama的官方网址:https://ollama.com/download。
下载后,安装的时候使用cmd进行安装,要不然总是默认安装在C盘中。
OllamaSetup.exe /DIR="D:\Ollama"然后即可进行安装在指定位置。
下载模型
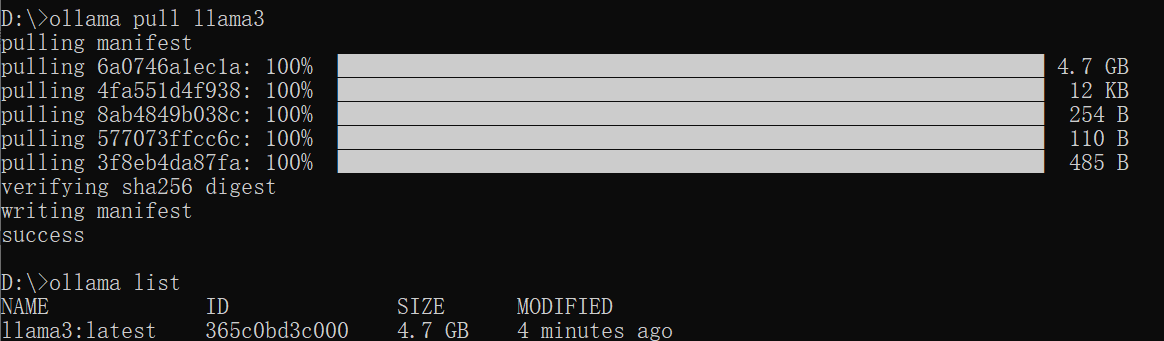
使用Ollama pull 模型即可,可以在https://ollama.com/search上找支持的模型,也可以在HuggingFace上找支持Ollama部署的模型。
运行模型
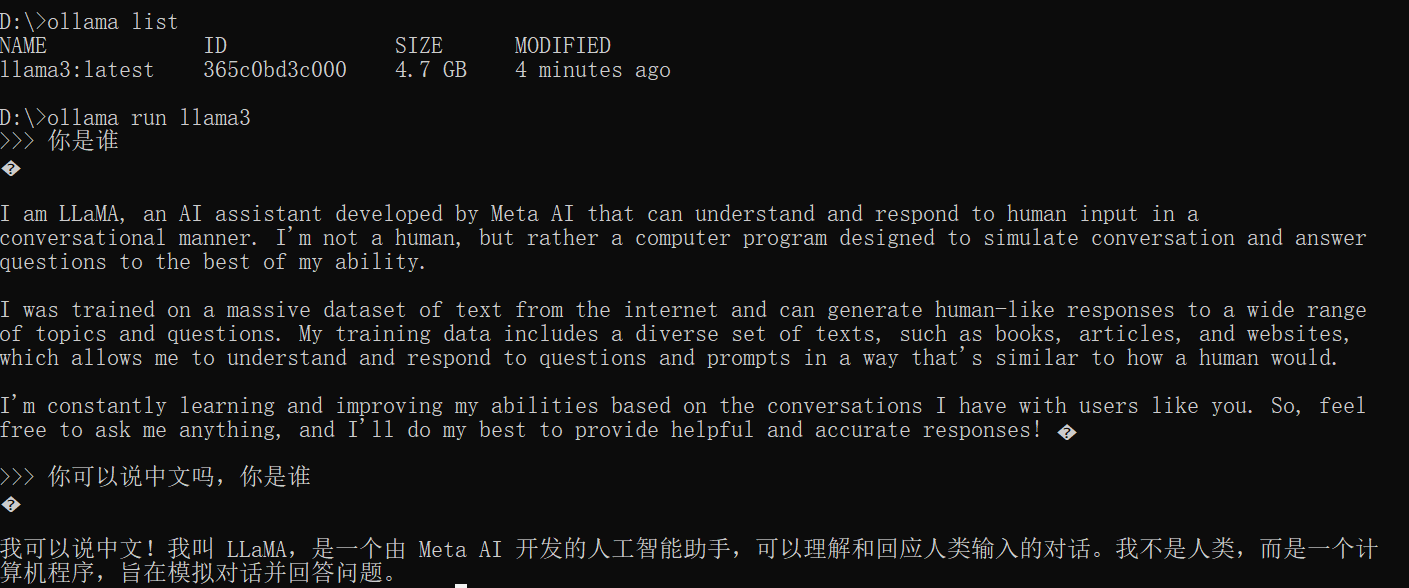
使用ollama run 模型名即可运行对应的模型。
API接口
Python调用
需要先安装ollama库,即:
bash
pip install ollama然后编写:
python
from ollama import Client
from ollama import ChatResponse
# 创建 Client 实例,并显式指定 host 地址
# 127.0.0.1 是标准的本地回环地址,11434 是 Ollama 默认端口。
client = Client(host='http://127.0.0.1:11434')
response: ChatResponse = client.chat(model='llama3:latest', messages=[
{
'role': 'user',
'content': '你是谁?请使用中文回答',
},
])
# 打印响应内容
print(response['message']['content'])运行结果:
我是 LLaMA,一个由 MetaAI 开发的人工智能模型。我可以理解和生成人类语言,能够与用户交互、回答问题和产生内容。我的目标是帮助人们更好地communicate和获取信息。我是一个基于大规模语言模型的 AI,我的能力包括:
* 理解自然语言,能够识别语义和理解用户的意图
* 生成高质量的文本,能够创作文章、回答问题和产生对话
* 学习和改进自己的人工智能能力
我可以用于各种场景,例如客服、内容生成、知识分享等。我希望通过与你的交流,提高自己的能力和帮助更多的人。