TL;DR
- 场景:微服务解耦、异步削峰、广播通知,需要把消息"投递到对的队列"。
- 结论:Exchange 决定路由策略;direct 精确、topic 模糊、fanout 广播、headers 多条件但更吃 CPU。
- 产出:一张版本矩阵 + 一张错误速查卡,直接对照排障与选型落地。

版本矩阵
| 验证说明 | 来源 |
|---|---|
| 经典镜像队列(Classic Mirrored Queues)已弃用且在 RabbitMQ 4.0 起移除;HA 推荐 Quorum Queues/Streams | RabbitMQ 文档 ✅ |
| AMQP 0-9-1 与 AMQP 1.0 可在同监听端口进行协议协商 | RabbitMQ 文档 ✅ |
| RabbitMQ(含商业发行版 Tanzu RabbitMQ)由 VMware Tanzu 相关团队提供支持与交付 | RabbitMQ 官方站 ✅ |
RabbitMQ 架构
基本介绍
RabbitMQ 是一款开源的消息中间件(Message Broker),由 Rabbit Technologies Ltd 开发,采用 Mozilla Public License 开源协议。它最初由 LShift 公司开发,后来被 SpringSource 收购,现属于 Pivotal 公司旗下产品。
行业应用
RabbitMQ 在多个行业都有广泛应用:
- 互联网行业:用于微服务架构中的服务解耦、异步通信等场景
- 电信行业:最初就是为解决电信系统间的可靠通信而设计的
- 金融行业:处理交易消息、支付通知等
- 物联网(IoT):与传感器设备通信
- 传统企业IT系统:系统集成、数据同步等
核心特性
-
高可靠性:
- 支持消息持久化
- 提供发布确认机制
- 支持事务(Transaction)和发送方确认(Publisher Confirm)
-
易扩展性:
- 支持集群部署
- 可以方便地添加节点
- 支持镜像队列实现高可用
-
丰富的功能:
- 多种交换机类型:直连(Direct)、主题(Topic)、扇出(Fanout)、头部(Headers)
- 消息TTL(存活时间)
- 死信队列
- 优先级队列
- 消息追踪
多语言支持
RabbitMQ 提供了多种编程语言的客户端库,包括但不限于:
- Java
- Python
- .NET
- Ruby
- PHP
- Go
- Node.js
- C/C++
技术实现
-
AMQP协议:
- RabbitMQ 实现了 AMQP 0-9-1 协议
- AMQP(Advanced Message Queuing Protocol)是一个提供统一消息服务的应用层标准协议
-
Erlang语言:
- 采用 Erlang OTP 平台开发
- Erlang 天生支持高并发和分布式
- 提供了良好的容错机制
-
多协议支持:
- 除了原生支持 AMQP 协议外
- 还支持 MQTT(通过插件)
- STOMP(通过插件)
- HTTP(通过管理插件)
典型应用场景
- 异步处理:如用户注册后发送邮件/短信通知
- 应用解耦:如订单系统与库存系统分离
- 流量削峰:应对突发高并发场景
- 日志处理:集中收集分布式系统日志
- 消息广播:如系统配置变更通知
示例:电商系统中,订单服务生成订单后,通过RabbitMQ将订单消息发送给库存服务扣减库存,同时发送给物流服务准备发货,各服务间完全解耦。
逻辑架构
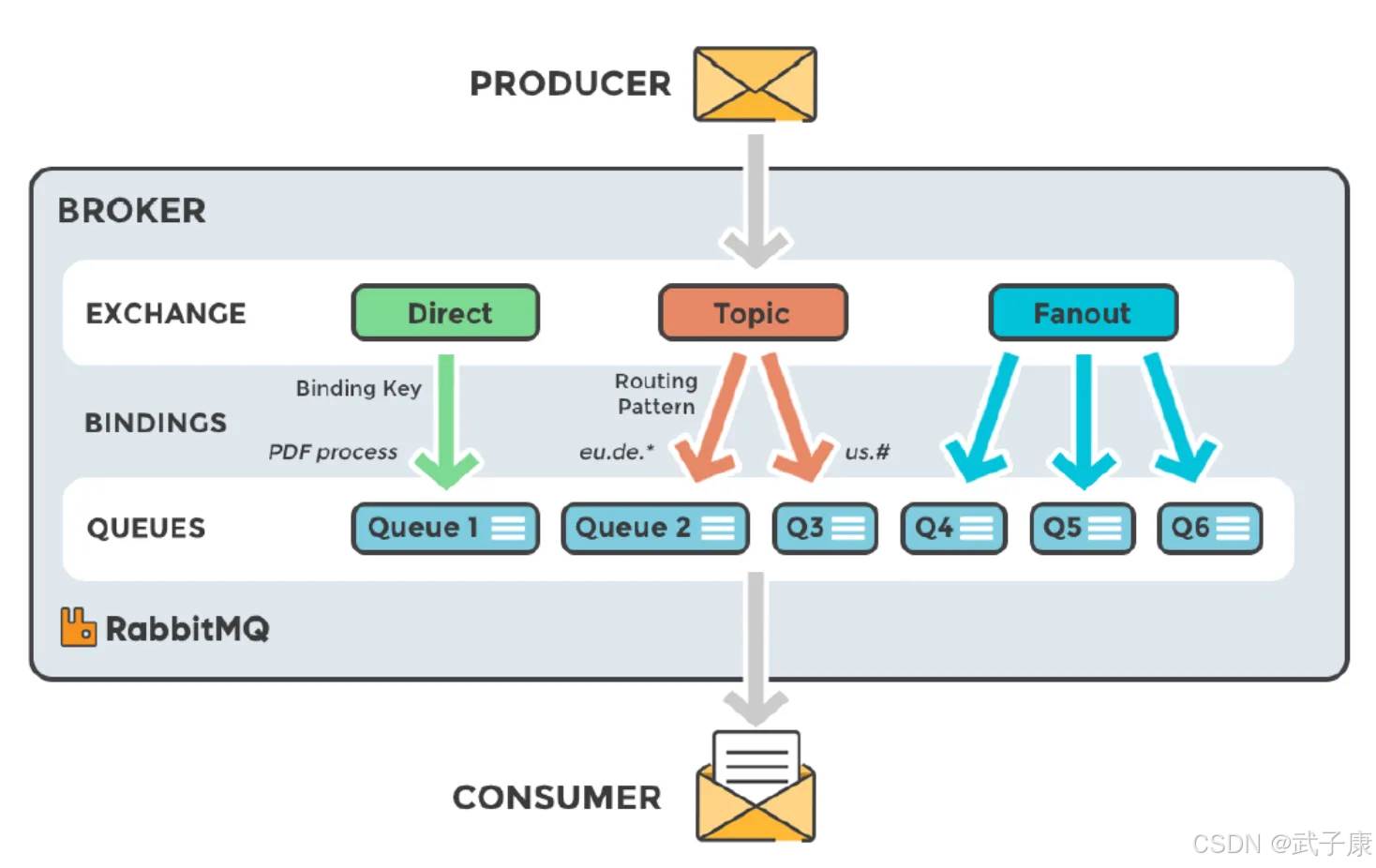
Exchange
RabbitMQ 常用的交换器类型及其应用场景:
fanout(广播模式)
- 特点:将消息路由到所有绑定的队列,忽略路由键(Routing Key)
- 应用场景:适用于需要广播消息的场景,如系统通知、日志分发
- 示例:一个订单创建事件需要同时通知库存系统、物流系统和积分系统
direct(直接模式)
- 特点:根据精确匹配的路由键将消息路由到队列
- 应用场景:适用于需要精确路由的场景,如特定业务处理
- 示例:将支付成功的订单路由到"order.payment.success"队列,支付失败的订单路由到"order.payment.failed"队列
topic(主题模式)
- 特点:支持模糊匹配的路由键(支持*和#通配符),比direct更灵活
- 应用场景:适用于需要分类处理消息的场景
- 示例 :
- "order.*"匹配所有订单相关消息
- "user.#"匹配所有用户相关消息及其子分类
headers(头模式)
- 特点:根据消息头(headers)属性进行路由匹配,忽略路由键
- 应用场景:适用于需要基于消息属性路由的特殊场景
- 匹配规则 :
- x-match=all:需匹配所有headers键值对
- x-match=any:只需匹配任意一个headers键值对
- 示例:根据消息的"region=asia"和"priority=high"头属性路由消息
Fanout
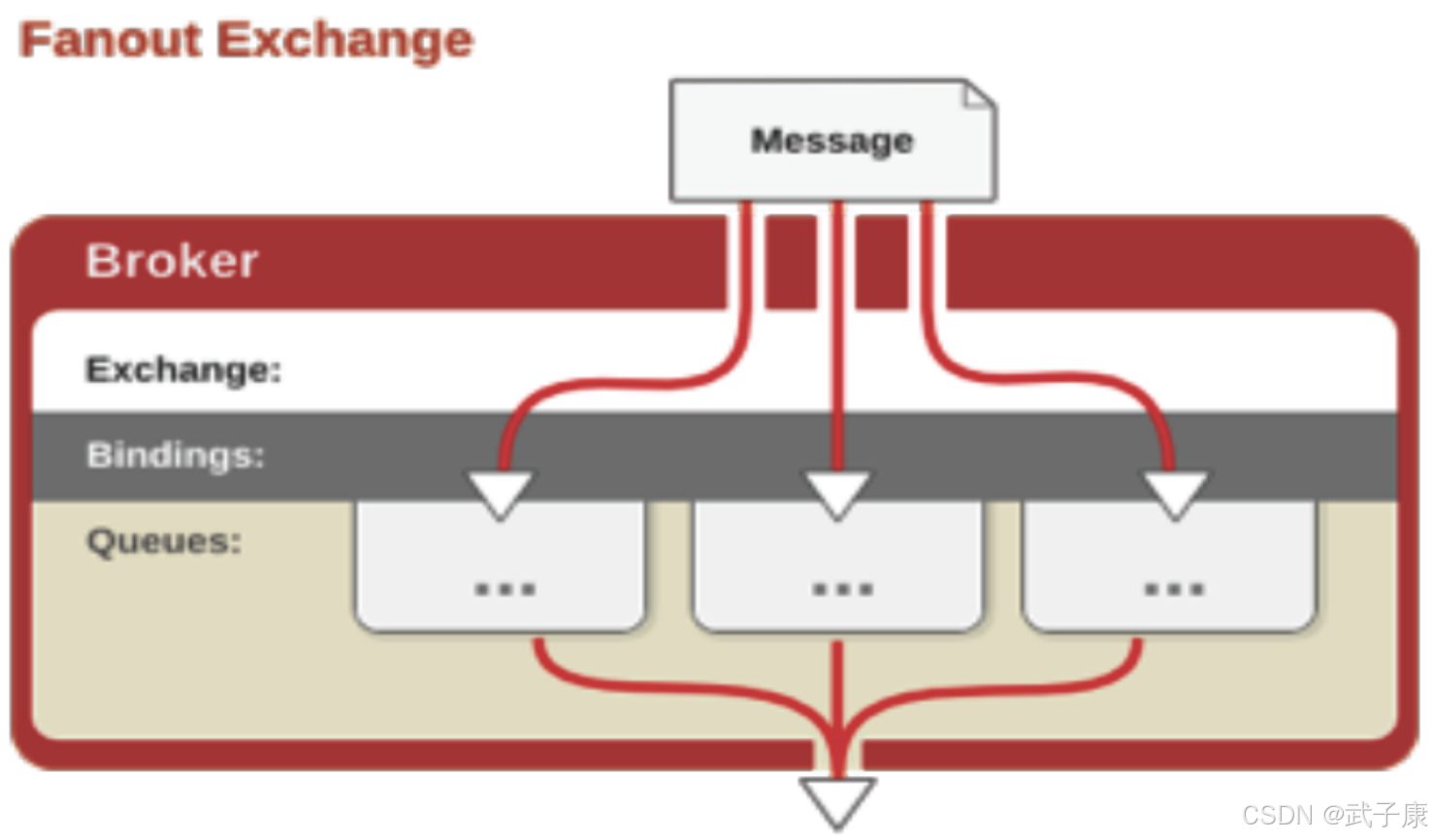
在消息队列系统中,当使用fanout类型的交换器时,所有发送到该交换器的消息都会被路由到所有与该交换器绑定的队列中。这种广播式的消息分发机制具有以下特点:
-
工作原理:
- 消息生产者将消息发送到fanout交换器
- 交换器不检查消息的路由键(routing key)
- 交换器会将消息的副本发送到每个绑定的队列
- 每个绑定的队列都会收到完全相同的消息
-
典型应用场景:
- 日志系统:需要将日志消息广播到多个处理程序
- 事件通知:当事件发生时需要通知多个订阅者
- 数据同步:需要在多个系统间保持数据一致
-
实现示例(以RabbitMQ为例):
python
# 声明fanout交换器
channel.exchange_declare(exchange='logs', exchange_type='fanout')
# 绑定队列
channel.queue_bind(exchange='logs', queue='queue1')
channel.queue_bind(exchange='logs', queue='queue2')
# 发布消息
channel.basic_publish(exchange='logs', routing_key='', body='Message')- 注意事项:
- 消息会被复制多份,可能影响系统性能
- 不适合对消息处理顺序有严格要求的场景
- 消费者需要处理可能重复的消息
这种模式提供了简单的发布-订阅机制,适合需要一对多消息分发的场景。
Direct
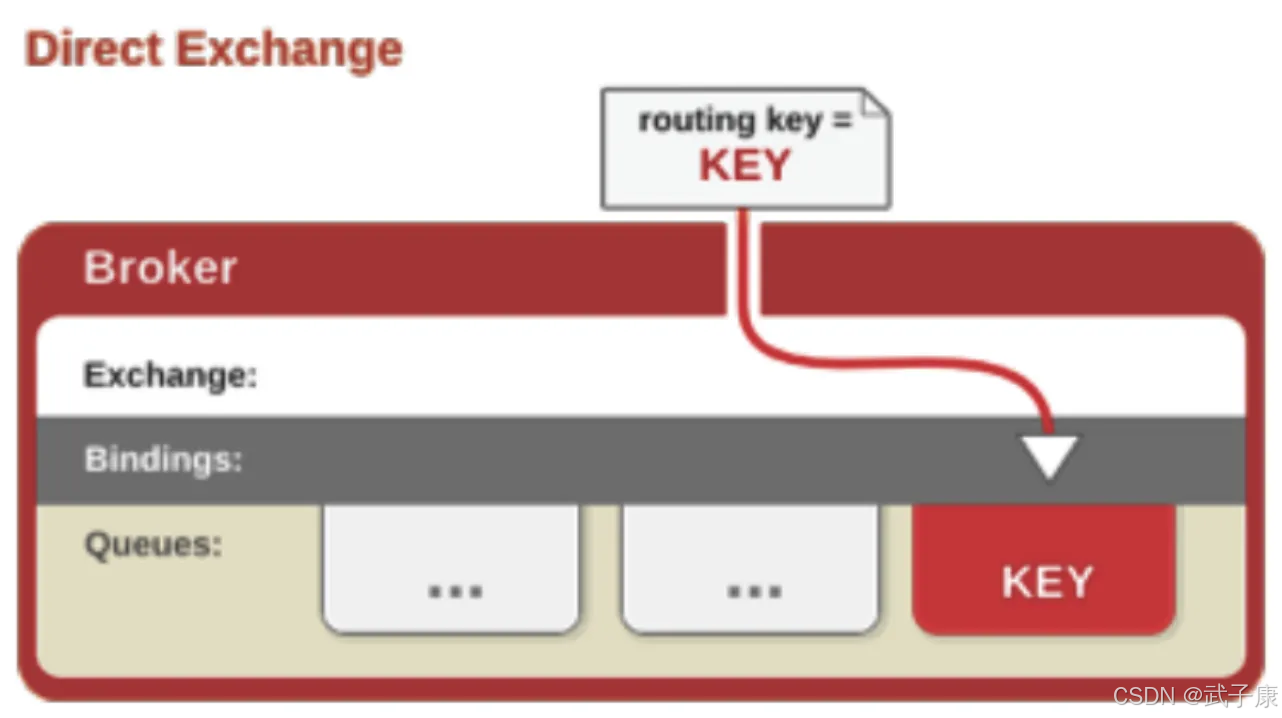
direct类型的交换器是RabbitMQ中最基本也是最常用的一种交换器类型,它采用精确匹配的路由机制。当生产者发送消息时,必须指定一个Routing Key(路由键),而消费者在创建队列并绑定到交换器时,则需要设置一个Binding Key(绑定键)。
其路由规则具有以下特点:
-
精确匹配机制:只有当消息的Routing Key和队列的Binding Key完全一致时,消息才会被路由到该队列。比如:
- 如果Routing Key是"order.created",那么只有Binding Key也是"order.created"的队列才会收到这条消息
- "order"不会匹配"order.created","order.*"也不会匹配
-
多队列绑定:允许多个队列使用相同的Binding Key绑定到同一个direct交换器。这种情况下,消息会被同时路由到所有匹配的队列,实现简单的广播功能。
-
典型应用场景:
- 订单处理系统:可以使用"order.created"、"order.paid"等不同的Routing Key来区分不同类型的订单消息
- 日志收集系统:用"log.error"、"log.warning"等Routing Key来分类不同级别的日志
- 任务分发系统:根据任务类型使用不同的Routing Key来分发到特定的处理队列
-
性能优势:由于采用精确匹配算法,direct交换器的路由效率很高,适合对性能要求较高的场景。
-
与其他交换器类型的区别:
- 相比fanout交换器(广播所有队列),direct是有选择性的路由
- 相比topic交换器(支持模式匹配),direct只支持完全匹配
- 相比headers交换器(基于消息头匹配),direct基于Routing Key匹配
在使用时需要注意,如果没有任何队列的Binding Key与消息的Routing Key匹配,那么该消息将会被直接丢弃,除非设置了备用交换器(alternate exchange)。
Topic
topic类型的交换器在 direct 匹配规则基础上进行了功能扩展,为消息路由提供了更灵活的匹配机制。以下是详细的匹配规则说明:
-
键名结构:
- RoutingKey(路由键)和 BindingKey(绑定键)都采用"."分割的多段式命名方式
- 例如:"stock.usd.nyse" 或 "weather.asia.china.shanghai"
-
特殊通配符:
-
星号"*":
- 精确匹配一个单词段
- 示例:BindingKey "stock.*.nyse" 可以匹配:
- "stock.usd.nyse"
- "stock.eur.nyse"
- 但不能匹配:
- "stock.nyse"(缺少一个段)
- "stock.usd.future.nyse"(多出一个段)
-
井号"#":
- 匹配零个或多个单词段
- 示例:BindingKey "weather.#" 可以匹配:
- "weather"(零个后续段)
- "weather.asia"
- "weather.asia.china"
- "weather.asia.china.shanghai"
- 是最宽松的匹配模式
-
-
典型应用场景:
- 日志分级处理:
- BindingKey "syslog.*.error" 可接收所有子系统错误日志
- BindingKey "syslog.auth.#" 可接收认证相关的所有级别日志
- 地理位置消息路由:
- "location.#.temperature" 可接收任意区域层级的温度数据
- "location.country.*.humidity" 可接收国家下任意城市的湿度数据
- 日志分级处理:
-
使用注意事项:
- 通配符必须作为独立的段存在,不能出现在单词中间
- 合法的BindingKey示例:
- "*.stock"
- "market.#"
- "order.*.completed"
- 非法的BindingKey示例:
- "st*ck"(通配符不在段首)
- "market.*.#"(连续使用通配符)
这种灵活的匹配机制使得topic交换器特别适合需要多维度消息分类的场景,如物联网设备消息路由、微服务间的事件通知等复杂路由需求。
Headers
headers 类型的交换器是 RabbitMQ 中一种特殊的交换器类型,它不依赖于传统的路由键(routing key)匹配机制,而是通过分析消息头(headers)中的属性来进行消息路由。这种交换器的工作原理与 direct、topic 等类型有显著不同。
具体工作流程如下:
-
绑定阶段:
- 在创建队列并将其绑定到headers交换器时,需要指定一组键值对作为匹配条件
- 这些键值对可以是任意自定义的header属性,如"x-match":"all"、"priority":"high"等
- 可以设置匹配模式为"all"(所有条件都必须满足)或"any"(满足任一条件即可)
-
消息路由阶段:
- 生产者发送消息时,需要在消息头中设置相应的属性
- 交换器会提取消息头中的所有属性
- 将消息头的属性与各队列绑定时指定的键值对进行比对
- 当匹配条件满足时,消息就会被路由到对应的队列
实际应用示例:
假设有一个订单处理系统,可以这样配置:
python
# 绑定队列时指定匹配条件
channel.queue_bind(
queue='high_priority_queue',
exchange='headers_exchange',
arguments={'x-match':'all', 'priority':'high', 'region':'north'}
)
# 发送消息时设置headers
properties = pika.BasicProperties(
headers={'priority': 'high', 'region': 'north'}
)
channel.basic_publish(
exchange='headers_exchange',
routing_key='', # headers交换器忽略routing key
body=message,
properties=properties
)性能注意事项:
- headers交换器需要解析每条消息的headers属性并进行复杂匹配
- 匹配操作需要消耗较多CPU资源
- 当队列数量较多时,性能下降明显
- 在实际生产环境中,除非有特殊需求,否则建议使用direct或topic交换器
适用场景:
- 需要基于多个条件进行复杂路由的情况
- 路由条件可能经常变化的场景
- 消息属性比路由键更能准确描述路由需求的情况
由于性能问题,headers交换器在实际应用中较为少见,大多数情况下可以通过合理设计路由键来替代其功能。
错误速查
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| 生产者发了消息但队列里没有 | direct/topic 路由键与 binding key 不匹配;或根本没绑定队列 | 管理台看 exchange→bindings;核对 routing_key 与 binding_key | 补绑定;统一命名规范;必要时加 alternate-exchange/mandatory+return |
| 消息"凭空消失"且无报错 | 未设置 mandatory;无匹配绑定时消息被丢弃(默认行为) | 生产端开启 publisher confirms/returns;看 return 回调 | mandatory=true 并处理 return;或配置备用交换器 |
| fanout 一开吞吐掉得厉害 | 广播导致消息复制 N 份,队列/磁盘/网络放大 | 看入队速率与队列堆积是否按订阅者数线性放大 | 降低订阅者数;拆主题;改 topic 精准分发;限流与批处理 |
| headers 路由延迟上升、CPU 高 | 每条消息需要解析 headers 并做多条件匹配 | perf/CPU 火焰图;对比 direct/topic 同吞吐下 CPU | 能用 routing key 就不用 headers;简化条件;减少绑定数量 |
| HA 配置后升级失败或队列不可用 | 仍在使用 Classic Mirrored Queues,4.0 起已移除 | 看队列类型/策略;检查是否 classic mirrored | 迁移到 Quorum Queues/Streams(按官方迁移路径) |
| 消费端出现重复消费 | 至少一次投递语义 + ack 时机不当/超时重投 | 看消费端 ack 与重试日志;检查 redelivered 标记 | 业务幂等;正确 ack;用重试队列/死信队列治理 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南!
AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-196 消息队列选型:RabbitMQ vs RocketMQ vs Kafka
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ正在更新... 深入浅出助你打牢基础!
🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
🔗 大数据模块直达链接